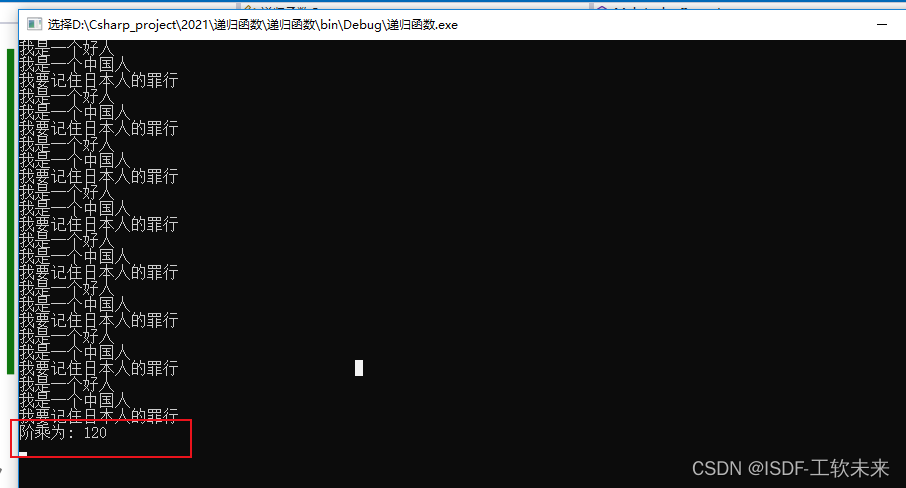
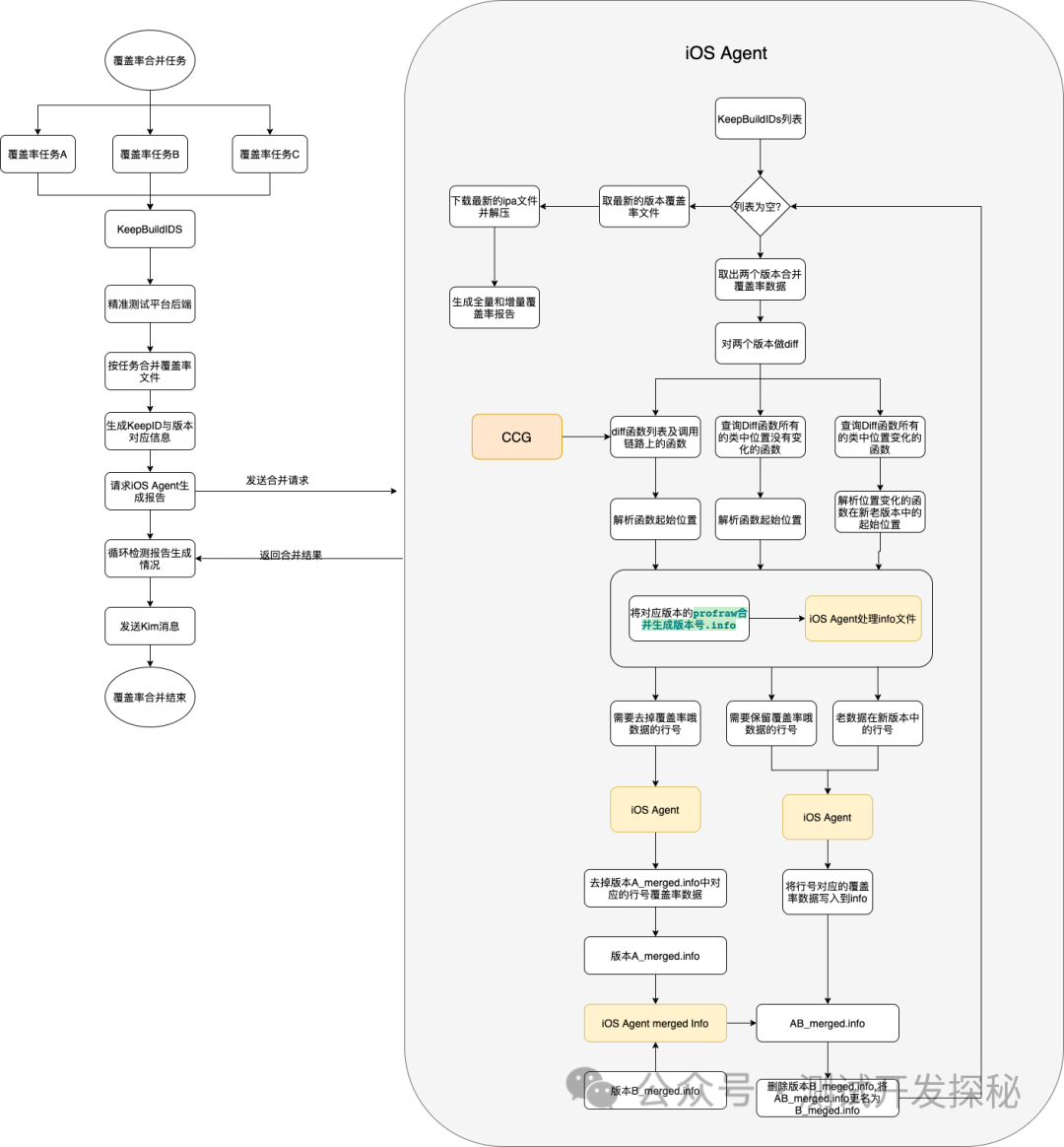
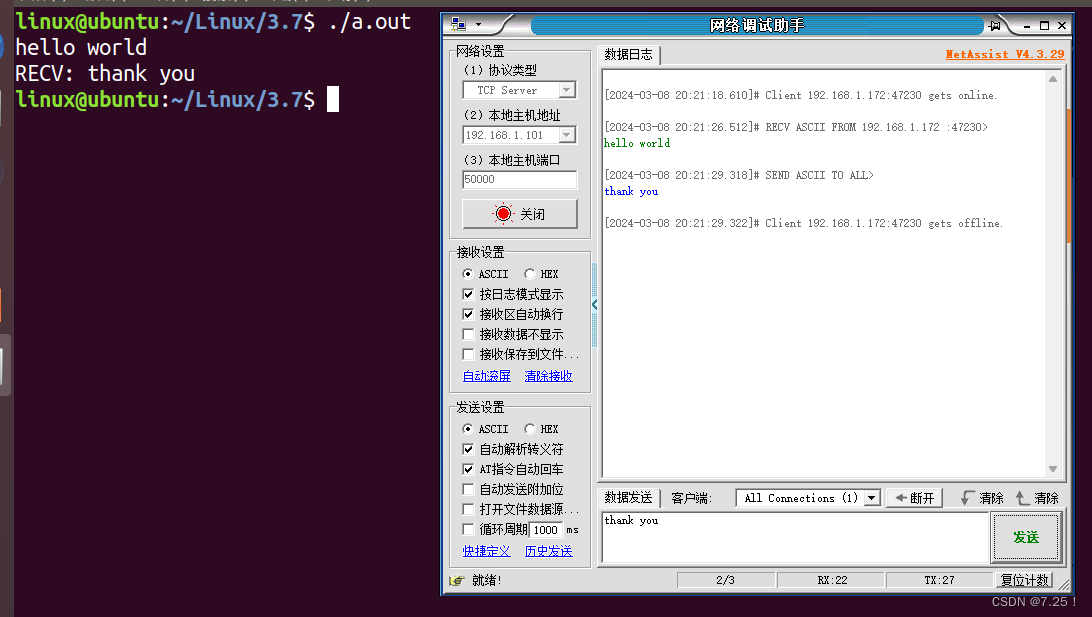
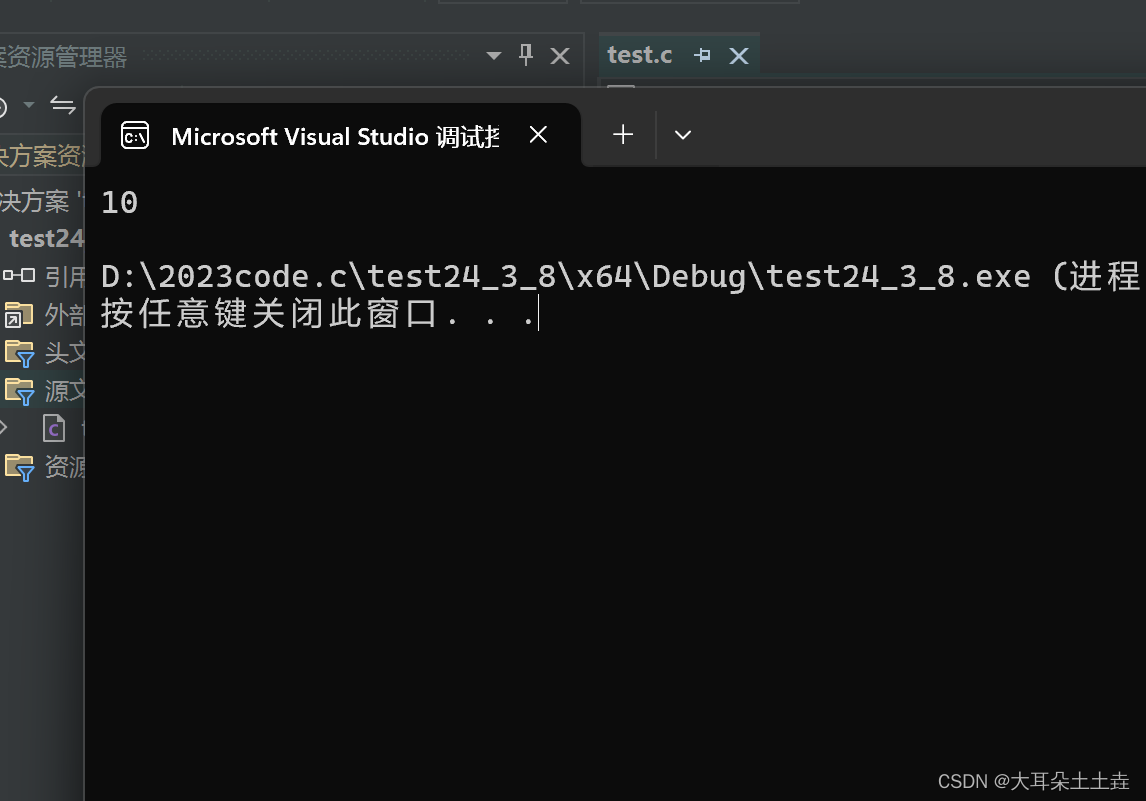
步骤都在注释里写清楚了,可以自己调整循环的次数观察输出的w与b和loss的值
import torch
#学习率,用来进行w和b的更新
learning_rate = 0.01
#1. 准备数据
#这里使用y=3x+0.8.也就是w=3,b=0.8.创造一个500行1列的数据
x=torch.rand([500,1])
y_true=x*0.3+0.8
#2. 通过模型计算y_predict。x*w,所以w是1行1列的.torch.matmul是矩阵乘法.只有浮点数才能使用grad。修改dtype
w = torch.rand([1,1],requires_grad=True)
b = torch.tensor(0,requires_grad=True,dtype=torch.float32)
#4. 通过循环,反向传播,更新参数
for i in range(5000):
y_predict = torch.matmul(x, w) + b
# 3. 计算loss.用平方来处理,这里mean不太清楚是什么意思。均方误差?这是什么?....每次都需要更新损失,所以把他放在循环里
loss = (y_true - y_predict).pow(2).mean()
#每次backward之前梯度置为0
if w.grad is not None:
w.grad.data.zero_()
if b.grad is not None:
b.grad.data.zero_()
loss.backward() #反向传播.这时w和b的梯度就算出来了w.grad,b.grad
w.data = w.data - learning_rate * w.grad
b.data = b.data - learning_rate * b.grad #要注意左边不要写成grad,写成grad之后b的内容就一直是0
print("w,b,loss",w.item(),b.item(),loss.item())
输出:
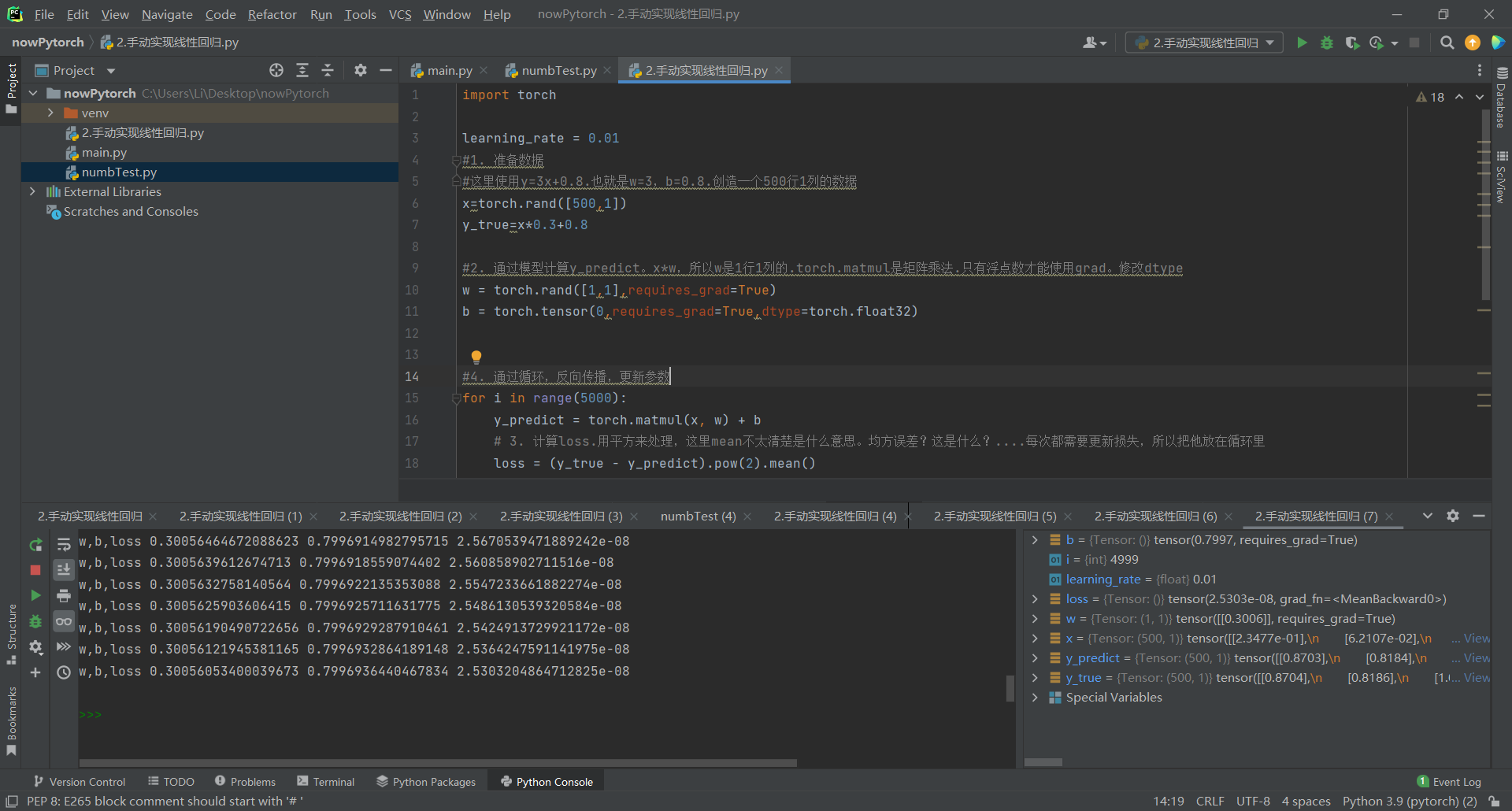
可以观察到w接近0.3,b接近0.8。和预想值十分接近了。
问题:

这里的理解有欠缺。。。