文章目录
- Jupyter 和 Colab 笔记本
- Python
- Python 版本
- 基础数据类型
- 数字Numbers
- 布尔值Booleans
- 字符串Strings
- 容器
- 列表List
- 字典Dictionaries
- 集合Sets
- 元组Tuples
- 函数
- 类
- Numpy
- 数组Array
- 数组索引Array indexing
- 数据类型Datatypes
- Array math
- 广播Broadcasting
- Scipy
- 图像操作
- MATLAB文件
- 点之间距离
- Matplotlib
- 绘图
- 子图
- 图像
- 参考
Jupyter 和 Colab 笔记本
在深入探讨 Python 之前,简要地谈谈笔记本。Jupyter 笔记本允许在网络浏览器中本地编写并执行 Python 代码。Jupyter 笔记本使得可以轻松地调试代码并分段执行,因此它们在科学计算中得到了广泛的应用。另一方面,Colab 是 Google 的 Jupyter 笔记本版本,特别适合机器学习和数据分析,完全在云端运行。Colab 可以说是 Jupyter 笔记本的加强版:它免费,无需任何设置,预装了许多包,易于与世界共享,并且可以免费访问硬件加速器,如 GPU 和 TPU(有一些限制)。
在 Jupyter 笔记本中运行教程。如果希望使用 Jupyter 在本地运行笔记本,请确保虚拟环境已正确安装(按照设置说明操作),激活它,然后运行 pip install notebook 来安装 Jupyter 笔记本。接下来,打开笔记本并将其下载到选择的目录中,方法是右键单击页面并选择“Save Page As”。然后,切换到该目录并运行 jupyter notebook。
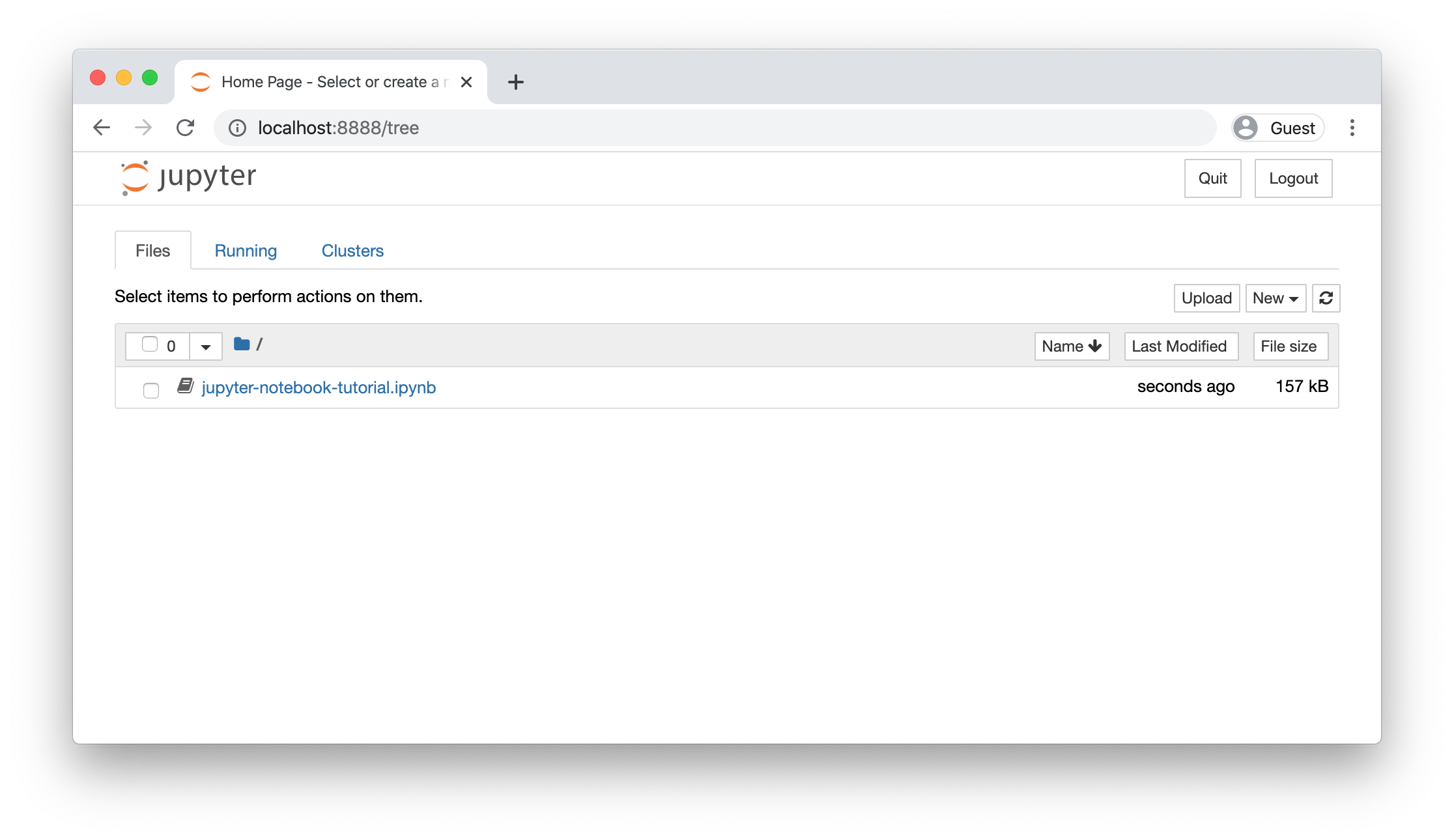
这应该会自动启动一个笔记本服务器,地址为 http://localhost:8888。如果一切正常,应该会看到一个屏幕,显示当前目录中所有可用的笔记本。
Python
Python 是一种高级的、动态类型的多范式编程语言。Python 代码常被说成几乎就像伪代码一样,因为它允许你用非常少的代码行表达非常强大的想法,同时代码的可读性也非常高。
作为例子,下面是快速排序算法在 Python 中的实现:
def quicksort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quicksort(left) + middle + quicksort(right)
# 示例使用
array = [3, 6, 8, 10, 1, 2, 1]
sorted_array = quicksort(array)
print(sorted_array)
#> [1, 1, 2, 3, 6, 8, 10]
Python 版本
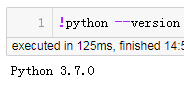
截至 2020 年 1 月 1 日,Python 官方已经停止对 Python 2 的支持。在本课程中,所有代码都将使用 Python 3.7。在进行本教程之前,请确保已经按照设置说明正确安装了 Python 3 的虚拟环境。可以在激活环境后,通过在命令行运行 python --version 来检查您的 Python 版本。
基础数据类型
像大多数语言一样,Python 包含一些基本类型,包括整数、浮点数、布尔值和字符串。这些数据类型的行为方式与其他编程语言中的类似。
数字Numbers
数字:整数和浮点数的工作方式与其他语言中的预期相同:
x = 3
print(type(x)) # 打印 "<class 'int'>",表示 x 是一个整数
print(x) # 打印 "3"
print(x + 1) # 加法,打印 "4"
print(x - 1) # 减法,打印 "2"
print(x * 2) # 乘法,打印 "6"
print(x ** 2) # 指数,打印 "9"
x += 1
print(x) # 打印 "4",因为 x = x + 1
x *= 2
print(x) # 打印 "8",因为 x = x * 2
y = 2.5
print(type(y)) # 打印 "<class 'float'>",表示 y 是一个浮点数
print(y, y + 1, y * 2, y ** 2) # 打印 "2.5 3.5 5.0 6.25"
注意,与许多其他语言不同,Python 没有一元递增(x++)或递减(x–)运算符。
Python 还内置了复数类型;可以在文档中找到所有详细信息。
布尔值Booleans
布尔值:Python 实现了所有标准的布尔逻辑运算符,但使用的是英文单词而不是符号(&&、|| 等.)
在 Python 中,布尔值是用来表示真(True)或假(False)的值。布尔值可以用于条件语句、循环和逻辑运算。下面是一个简单的例子,展示了如何使用布尔值:
t = True
f = False
print(type(t)) # 打印 "<class 'bool'>",表示 t 是一个布尔值
print(t and f) # 逻辑 AND,如果两个值都为真,则结果为真;打印 "False"
print(t or f) # 逻辑 OR,如果两个值中至少有一个为真,则结果为真;打印 "True"
print(not t) # 逻辑 NOT,如果值为真,则结果为假;打印 "False"
print(t != f) # 逻辑 XOR,如果两个值不同,则结果为真;打印 "True"
字符串Strings
字符串:Python 对字符串的支持非常强大
Python 中的字符串是一个不可变的序列,用于表示文本数据。字符串可以用单引号(')或双引号(")表示,两者是等价的。下面是一个简单的例子,展示了如何使用字符串:
hello = 'hello' # 使用单引号定义字符串
world = "world" # 使用双引号定义字符串
print(hello) # 打印字符串 "hello"
print(len(hello)) # 打印字符串的长度 "5"
hw = hello + ' ' + world # 使用加号进行字符串拼接
print(hw) # 打印 "hello world"
hw12 = '%s %s %d' % (hello, world, 12) # 使用 % 进行格式化字符串
print(hw12) # 打印 "hello world 12"
Python 中的字符串对象拥有一系列有用的方法,这些方法可以用于执行各种字符串操作。下面是一些常用的字符串方法及其示例
s = "hello"
print(s.capitalize()) # 将字符串中的第一个字符大写;打印 "Hello"
print(s.upper()) # 将字符串中的所有字符转换为大写;打印 "HELLO"
print(s.rjust(7)) # 将字符串右对齐,并用空格填充;打印 " hello"
print(s.center(7)) # 将字符串居中对齐,并用空格填充;打印 " hello "
print(s.replace('l', '(ell)')) # 将字符串中所有出现的子字符串 'l' 替换为 '(ell)';打印 "he(ell)(ell)o"
# 去除字符串首尾的空格
print(' world '.strip()) # 打印 "world"
可以在文档中找到所有字符串方法的列表。
容器
Python 包含几种内置的容器类型:列表、字典、集合和元组。
列表List
列表是 Python 中的一种可调整大小且可包含不同类型元素的数组等价物。下面是一些基本的列表操作示例:
xs = [3, 1, 2] # 创建一个列表
print(xs, xs[2]) # 打印 "[3, 1, 2] 2"
print(xs[-1]) # 负索引从列表的末尾开始计数;打印 "2"
xs[2] = 'foo' # 列表可以包含不同类型的元素
print(xs) # 打印 "[3, 1, 'foo']"
xs.append('bar') # 将新元素添加到列表的末尾
print(xs) # 打印 "[3, 1, 'foo', 'bar']"
x = xs.pop() # 删除并返回列表的最后一个元素
print(x, xs) # 打印 x 的值和新的 xs 列表
可以在文档中找到有关列表的所有详细信息。
切片:除了逐个访问列表元素外,Python 还提供了一种简洁的语法来访问子列表,这被称为切片:
nums = list(range(5)) # range 是一个内置函数,用于创建一个整数列表
print(nums) # 打印 "[0, 1, 2, 3, 4]"
print(nums[2:4]) # 从索引 2 到 4(不包括 4)获取一个切片;打印 "[2, 3]"
print(nums[2:]) # 从索引 2 到列表末尾获取一个切片;打印 "[2, 3, 4]"
print(nums[:2]) # 从列表开始到索引 2(不包括 2)获取一个切片;打印 "[0, 1]"
print(nums[:]) # 获取整个列表的一个切片;打印 "[0, 1, 2, 3, 4]"
print(nums[:-1]) # 切片索引可以是负数;打印 "[0, 1, 2, 3]"
nums[2:4] = [8, 9] # 将一个新的子列表赋值给一个切片
print(nums) # 打印 "[0, 1, 8, 9, 4]"
循环:可以像这样循环遍历列表的元素:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)
# 依次打印
# cat
# dog
# monkey
如果想在循环体的内部访问每个元素的索引,请使用内置的 enumerate 函数:
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# 依次打印
# #1: cat
# #2: dog
# #3: monkey
列表推导式:在编程中,经常需要将一种数据类型转换为另一种类型。作为一个简单的例子,考虑以下计算平方数的代码:
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:
squares.append(x ** 2)
print(squares)
#> [0, 1, 4, 9, 16]
可以使用列表表达式简化上述代码:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares)
#> [0, 1, 4, 9, 16]
列表推导式还可以包含条件:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares)
#> [0, 1, 4, 9, 16]
列表推导式还可以包含条件:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares)
#> [0, 4, 16]
字典Dictionaries
字典(Dictionary)存储(键,值)对,类似于 Java 中的 Map 或 JavaScript 中的对象。可以像这样使用它:
d = {'cat': 'cute', 'dog': 'furry'} # 创建一个包含一些数据的新字典
print(d['cat']) # 从字典中获取一个条目;打印 "cute"
print('cat' in d) # 检查字典是否包含给定的键;打印 "True"
d['fish'] = 'wet' # 在字典中设置一个条目
print(d['fish']) # 打印 "wet"
# print(d['monkey']) # KeyError: 'monkey' 不是 d 的键
print(d.get('monkey', 'N/A')) # 获取一个带有默认值的元素;打印 "N/A"
print(d.get('fish', 'N/A')) # 获取一个带有默认值的元素;打印 "wet"
del d['fish'] # 从字典中删除一个元素
print(d.get('fish', 'N/A')) # "fish" 不再是键;打印 "N/A"
可以在文档中找到有关字典的所有信息。
循环:在字典中遍历键是非常简单的:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print('A %s has %d legs' % (animal, legs))
# 依次打印
# A person has 2 legs
# A cat has 4 legs
# A spider has 8 legs
如果想要访问键及其对应的值,请使用 items() 方法:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal, legs in d.items():
print('A %s has %d legs' % (animal, legs))
# 依次打印
# A person has 2 legs
# A cat has 4 legs
# A spider has 8 legs
字典推导式:这些与列表推导式相似,允许轻松构建字典。
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square)
#> {0: 0, 2: 4, 4: 16}
集合Sets
集合是一个无序的独特的元素集合。作为一个简单的例子,考虑以下内容:
animals = {'cat', 'dog'}
print('cat' in animals) # 检查一个元素是否在集合中;打印 "True"
print('fish' in animals) # 打印 "False"
# 将一个新元素添加到集合中
animals.add('fish')
print('fish' in animals) # 打印 "True"
# 打印集合中的元素数量
print(len(animals)) # 集合中的元素数量;打印 "3"
# 尝试添加一个已经存在于集合中的元素,这将不会有任何效果
animals.add('cat')
print(len(animals)) # 打印 "3"
# 从集合中移除一个元素
animals.remove('cat')
print(len(animals)) # 打印 "2"
想了解的有关集合的所有信息都可以在文档中找到。
循环:遍历集合的语法与遍历列表相同;然而,由于集合是无序的,不能假设按特定顺序访问集合中的元素:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# 依次输出
# #1: fish
# #2: dog
# #3: cat
由于集合是无序的,每次运行这段代码时,元素的顺序可能都会不同。
集合推导式:与列表和字典类似,可以使用集合推导式轻松构建集合:
from math import sqrt
nums = {int(sqrt(x)) for x in range(30)}
print(nums)
#> {0, 1, 2, 3, 4, 5}
元组Tuples
元组是(不可变的)有序值列表。元组在很多方面与列表相似。最重要的区别之一是元组可以用作字典中的键和集合的元素,而列表则不能。这是一个简单的例子:
d = {(x, x + 1): x for x in range(10)} # 创建一个字典,其键是元组
t = (5, 6) # 创建一个元组
print(type(t)) # 打印 "<class 'tuple'>",表示 t 是一个元组
print(d[t]) # 打印 "5",因为 t 的第一个元素是 5
print(d[(1, 2)]) # 打印 "1",因为 (1, 2) 的第一个元素是 1
该文档提供了有关元组的更多信息。
函数
Python 函数使用 def 关键字定义。例如:
def sign(x):
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print(sign(x))
# 依次打印
# negative
# zero
# positive
经常定义函数来接受可选的关键字参数,如下所示:
def hello(name, loud=False):
if loud:
print('HELLO, %s!' % name.upper())
else:
print('Hello, %s' % name)
hello('Bob') # 打印 "Hello, Bob"
hello('Fred', loud=True) # 打印 "HELLO, FRED!"
更多关于 Python 函数的信息可见文档。
类
在 Python 中定义类的语法很简单:
class Greeter(object):
# 构造函数
def __init__(self, name):
self.name = name # 创建实例变量
# 实例方法
def greet(self, loud=False):
if loud:
print('HELLO, %s!' % self.name.upper())
else:
print('Hello, %s' % self.name)
g = Greeter('Fred') # 创建 Greeter 类的实例
g.greet() # 调用实例方法;打印 "Hello, Fred"
g.greet(loud=True) # 调用实例方法;打印 "HELLO, FRED!"
可以在文档中阅读有关 Python 类的更多信息。
Numpy
NumPy 是 Python 中进行科学计算的核心库。它提供了一个高性能的多维数组对象,以及用于处理这些数组的工具。如果已经熟悉 MATLAB,那么这个教程对于开始使用 NumPy 可能会有用。
数组Array
NumPy 数组是一个由相同类型的值组成的网格,这些值通过非负整数元组进行索引。数组的维度数称为其秩;数组的形状是一个整数元组,给出了数组在每条维度上的大小。
可以从嵌套的 Python 列表初始化 NumPy 数组,并且使用方括号访问元素:
import numpy as np
a = np.array([1, 2, 3]) # 创建一个一维数组
print(type(a)) # 打印 "<class 'numpy.ndarray'>",表示 a 是一个 NumPy 数组
print(a.shape) # 打印 "(3,)",表示数组 a 的形状是一个包含一个元素的元组
print(a[0], a[1], a[2]) # 打印 "1 2 3",表示数组 a 的前三个元素
a[0] = 5 # 修改数组 a 的第一个元素
print(a) # 打印 "[5, 2, 3]",表示数组 a 的新值
# 创建一个二维数组
b = np.array([[1,2,3],[4,5,6]])
print(b.shape) # 打印 "(2, 3)",表示数组 b 的形状是一个包含两个元素的元组
print(b[0, 0], b[0, 1], b[1, 0]) # 打印 "1 2 4",表示数组 b 的前两个元素的值
NumPy 还提供了许多函数来创建数组:
import numpy as np
# 创建一个全零数组
zeros = np.zeros((2, 2))
print(zeros)
# 创建一个全一数组
ones = np.ones((2, 2))
print(ones)
# 创建一个具有特定值的数组
full = np.full((2, 2), 7)
print(full)
# 创建一个具有特定范围内值的数组
arange = np.arange(0, 10, 2)
print(arange)
# 创建一个等差数组
linspace = np.linspace(0, 10, 5)
print(linspace)
# 创建一个单位矩阵
eye = np.eye(2)
print(eye)
# 创建一个随机数组
random = np.random.rand(2, 2)
print(random)
输出
[[0. 0.]
[0. 0.]]
[[1. 1.]
[1. 1.]]
[[7. 7.]
[7. 7.]]
[0 2 4 6 8]
[ 0. 1. 2. 3. 4.]
[[1. 0.]
[0. 1.]]
[[0.31226426 0.55709283]
[0.29710956 0.82499999]]
可以在文档中阅读有关数组创建的其他方法。
数组索引Array indexing
Numpy 提供了多种对数组进行索引的方法。
切片Slicing:与Python列表类似,numpy数组可以被切片。由于数组可能是多维的,因此必须为数组的每个维度指定一个切片:
import numpy as np
# 创建一个 3x4 的二维数组
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# 使用切片来获取前两行和第二、三列的子数组
# b 是一个形状为 (2, 2) 的数组:
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
# 打印原始数组的第二个元素(索引为 (0, 1))
print(a[0, 1]) # 打印 "2"
# 修改子数组的第一个元素(实际上是修改原始数组的第二个元素)
b[0, 0] = 77 # b[0, 0] 与 a[0, 1] 是相同的数据
# 再次打印原始数组的第二个元素,现在它应该变为 "77"
print(a[0, 1]) # 打印 "77"
还可以混合使用整数索引和切片索引。然而,这样做会产生一个低于原始数组秩的数组。请注意,这与 MATLAB 处理数组切片的方式非常不同:
import numpy as np
# 创建一个形状为 (3, 4) 的二维数组
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# 两种方式访问数组中间行的数据。
# 使用混合整数索引和切片会产生一个低秩数组,
# 而只使用切片会产生与原始数组相同秩的数组:
row_r1 = a[1, :] # 第二行的秩 1 视图
row_r2 = a[1:2, :] # 第二行的秩 2 视图
print(row_r1, row_r1.shape) # 打印 "[5 6 7 8] (4,)"
print(row_r2, row_r2.shape) # 打印 "[[5 6 7 8]] (1, 4)"
# 当访问数组的列时,我们可以做出同样的区分:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape) # 打印 "[ 2 6 10] (3,)"
print(col_r2, col_r2.shape) # 打印 "[[ 2]
# [ 6]
# [10]] (3, 1)"
整数数组索引:当使用切片索引 NumPy 数组时,结果数组视图总是原始数组的子数组。相比之下,整数数组索引允许使用另一个数组的数据构造任意数组。下面是一个例子:
import numpy as np
# 创建一个二维数组
a = np.array([[1,2], [3, 4], [5, 6]])
# 整数数组索引的例子。返回的数组将具有形状 (3,)
print(a[[0, 1, 2], [0, 1, 0]]) # 打印 "[1 4 5]"
# 上面的整数数组索引例子等价于这个:
print(np.array([a[0, 0], a[1, 1], a[2, 0]])) # 打印 "[1 4 5]"
# 使用整数数组索引时,可以从源数组中重复使用相同的元素:
print(a[[0, 0], [1, 1]]) # 打印 "[2 2]"
# 等价于前面的整数数组索引示例
print(np.array([a[0, 1], a[0, 1]])) # 打印 "[2 2]"
-
在第一个例子中,选择了第一行、第二行和第三行的第一列和第二列的元素。
-
在第二个例子中,选择了第一行、第二行和第三行的第一列的元素。
-
在第三个例子中,选择了第一行和第一列的元素,并重复使用了第一行的第二列的元素。
整数数组索引的一个有用技巧是选择或修改矩阵中每一行的一个元素:
import numpy as np
# 创建一个新数组,我们将从中选择元素
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10,11,12]])
print(a) # 打印 "array([[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9],
# [10, 11, 12]])"
# 创建一个索引数组
b = np.array([0, 2, 0, 1])
# 使用 b 中的索引从 a 中选择每一行的一个元素
print(a[np.arange(4), b]) # 打印 "[ 1 6 7 11]",这是通过 b 中的索引选择的结果
# 使用 b 中的索引从 a 中修改每一行的一个元素
a[np.arange(4), b] += 10
print(a) # 打印 "array([[11, 2, 3],
# [ 4, 5, 16],
# [17, 8, 9],
# [10, 21, 12]])",这是修改后的结果
布尔数组索引允许选择数组中的任意元素。这种索引经常用于选择满足某些条件的数组元素。下面是一个例子:
import numpy as np
# 创建一个二维数组
a = np.array([[1,2], [3, 4], [5, 6]])
# 创建一个布尔数组,指示哪些元素大于 2
bool_idx = (a > 2)
# 打印布尔数组
print(bool_idx) # 打印 "[[False False]
# [ True True]
# [ True True]]"
# 使用布尔数组索引构造一个由 a 中对应于 bool_idx 中 True 值的元素组成的秩 1 数组
print(a[bool_idx]) # 打印 "[3 4 5 6]"
# 可以在一个简洁的语句中完成上述所有操作:
print(a[a > 2]) # 打印 "[3 4 5 6]"
为了简洁起见,省略了很多关于 NumPy 数组索引的细节;如果想了解更多,可以阅读文档。
数据类型Datatypes
NumPy 提供了一组丰富的数值数据类型,可以使用这些数据类型来构建数组。当创建数组时,NumPy 会尝试猜测一个数据类型,但是构造数组的函数通常还包含一个可选参数,用于明确指定数据类型。下面是一个例子:
import numpy as np
# 创建一个包含整数的数组,让 NumPy 选择数据类型
x = np.array([1, 2])
print(x.dtype) # 打印 "int64"
# 创建一个包含浮点数的数组,让 NumPy 选择数据类型
x = np.array([1.0, 2.0])
print(x.dtype) # 打印 "float64"
# 创建一个包含整数的数组并指定数据类型为 int64
x = np.array([1, 2], dtype=np.int64)
print(x.dtype) # 打印 "int64"
可以在文档中阅读有关 numpy 数据类型的所有内容。
Array math
在 NumPy 中,基本的数学运算符如 +、-、*、/ 和 ** 都是逐元素的,并且既作为运算符重载,也作为 NumPy 模块中的函数提供:
import numpy as np
# 创建两个二维数组
x = np.array([[1, 2], [3, 4]], dtype=np.float64)
y = np.array([[5, 6], [7, 8]], dtype=np.float64)
# 逐元素加法
print(x + y) # 打印 "[[ 6.0 8.0]
# [10.0 12.0]]"
print(np.add(x, y)) # 打印 "[[ 6.0 8.0]
# [10.0 12.0]]"
# 逐元素减法
print(x - y) # 打印 "[[-4.0 -4.0]
# [-4.0 -4.0]]"
print(np.subtract(x, y)) # 打印 "[[-4.0 -4.0]
# [-4.0 -4.0]]"
# 逐元素乘法
print(x * y) # 打印 "[[ 5.0 12.0]
# [21.0 32.0]]"
print(np.multiply(x, y)) # 打印 "[[ 5.0 12.0]
# [21.0 32.0]]"
# 逐元素除法
print(x / y) # 打印 "[[ 0.2 0.33333333]
# [ 0.42857143 0.5]"
print(np.divide(x, y)) # 打印 "[[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]"
# 逐元素平方根
print(np.sqrt(x)) # 打印 "[[ 1. 1.41421356]
# [1.73205081 2. ]]"
请注意,与 MATLAB 不同,NumPy 中的 * 运算符表示逐元素乘法,而不是矩阵乘法。要计算向量的内积、将向量乘以矩阵或乘以矩阵,使用 dot 函数。dot 函数既可以作为 NumPy 模块中的函数使用,也可以作为数组对象的实例方法使用。
import numpy as np
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# 向量的内积,结果为219
print(v.dot(w))
print(np.dot(v, w))
# 矩阵与向量的乘法;两者都产生一维数组 [29 67]
print(x.dot(v))
print(np.dot(x, v))
# 矩阵乘法;两者都产生二维数组
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))
Numpy提供了许多在数组上进行计算的有用函数;其中最有用的是sum:
import numpy as np
x = np.array([[1,2],[3,4]])
print(np.sum(x)) # 计算所有元素的总和;打印 "10"
print(np.sum(x, axis=0)) # 计算每列的总和;打印 "[4 6]"
print(np.sum(x, axis=1)) # 计算每行的总和;打印 "[3 7]"
可以在Numpy文档中找到它提供的完整数学函数列表。
除了使用数组计算数学函数外,经常需要重塑或以其他方式处理数组中的数据。这类操作的最简单例子是转置矩阵;要转置矩阵,只需使用数组对象的T属性:
import numpy as np
x = np.array([[1,2], [3,4]])
print(x) # 打印 "[[1 2]
# [3 4]]"
print(x.T) # 打印 "[[1 3]
# [2 4]]"
# 注意,对等级1数组进行转置没有任何效果:
v = np.array([1,2,3])
print(v) # 打印 "[1 2 3]"
print(v.T) # 打印 "[1 2 3]"
Numpy提供了许多用于操作数组的函数,可以在其文档中查看完整列表。
广播Broadcasting
广播是一种强大的机制,它允许Numpy在进行算术运算时处理不同形状的数组。通常会遇到一个较小的数组和较大的数组,希望多次使用小数组对大数组执行某些操作。
例如,假设希望将一个常量向量加到矩阵的每一行,可以这样做:
import numpy as np
# 将向量v加到矩阵x的每一行,
# 结果存储在矩阵y中
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # 创建一个与x形状相同的空矩阵
# 使用显式循环将向量v加到矩阵x的每一行
for i in range(4):
y[i, :] = x[i, :] + v
# 现在y的内容如下
# [[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]
print(y)
这种方法是有效的;但是,当矩阵x非常大时,在Python中使用显式循环进行计算可能会很慢。请注意,将向量v添加到矩阵x的每一行等同于通过垂直堆叠多个v的副本来创建矩阵vv,然后对x和vv进行逐元素相加。可以这样实现这个方法:
import numpy as np
# 将向量v加到矩阵x的每一行,
# 结果存储在矩阵y中
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
vv = np.tile(v, (4, 1)) # 将v垂直堆叠4次
print(vv) # 打印 "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
y = x + vv # 对x和vv进行逐元素加法
print(y) # 打印 "[[ 2 2 4
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
Numpy的广播功能能够执行这个计算,而无需真正复制v多次。看看这个使用广播功能的版本:
import numpy as np
# 将向量v加到矩阵x的每一行,
# 结果存储在矩阵y中
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # 通过广播将v加到x的每一行
print(y) # 打印 "[[ 2 2 4]
# [ 5 5 7]
# [ 8 8 10]
# [11 11 13]]"
即使x的形状是(4, 3),而v的形状是(3,),由于广播机制,y = x + v 这行代码仍然有效;其作用就像v实际上有一个形状为(4, 3)的数组,其中每一行都是v的副本,然后进行逐元素的加法。
进行数组广播时遵循以下规则:
- 如果两个数组的秩rank不同,将在较低rank数组的形状前面补1,直到两个形状的长度相同。
- 如果两个数组在某个维度上大小相同,或者其中一个数组在该维度的大小为1,则这两个数组在该维度上是兼容的。
- 如果两个数组在所有维度上都兼容,则它们可以一起广播。
- 广播之后,每个数组的行为就像其形状是两个输入数组形状的逐元素最大值。
- 在任何维度上,如果一个数组的大小为1而另一个数组的大小大于1,则第一个数组的行为就像它沿着那个维度被复制。
支持广播的函数被称为通用函数,可以在Numpy的文档中找到所有通用函数的列表。
以下是一些广播的应用实例:
import numpy as np
# 计算两个向量的外积
v = np.array([1,2,3]) # v的形状是(3,)
w = np.array([4,5]) # w的形状是(2,)
# 为了计算外积,先将v重塑为一个形状为(3, 1)的列向量;
# 接着,可以通过广播将其与w相乘,得到一个形状为(3, 2)的输出,这就是v和w的外积:
# [[ 4 5]
# [ 8 10]
# [12 15]]
print(np.reshape(v, (3, 1)) * w)
# 将一个向量加到矩阵的每一行
x = np.array([[1,2,3], [4,5,6]])
# x的形状是(2, 3),v的形状是(3,),它们可以广播到(2, 3),
# 从而产生以下矩阵:
# [[2 4 6]
# [5 7 9]]
print(x + v)
# 将一个向量加到矩阵的每一列
# x的形状是(2, 3),w的形状是(2,)。
# 如果转置x,其形状变为(3, 2),可以与w广播
# 以得到一个形状为(3, 2)的结果;再次转置这个结果
# 就得到了最终形状为(2, 3)的矩阵,即每列都加上了向量w。得到以下矩阵:
# [[ 5 6 7]
# [ 9 10 11]]
print((x.T + w).T)
# 另一种方法是先将w重塑为一个形状为(2, 1)的列向量;
# 然后直接将其与x广播,也能得到相同的输出。
print(x + np.reshape(w, (2, 1)))
# 将矩阵乘以一个常数:
# x的形状是(2, 3)。在Numpy中,标量被视为形状为()的数组;
# 这些可以广播到形状(2, 3),得到以下数组:
# [[ 2 4 6]
# [ 8 10 12]]
print(x * 2)
广播通常会使代码更加简洁和更快,因此应该尽可能地使用它。
Scipy
Numpy提供了一个高性能的多维数组以及一些基本的工具来计算和操作这些数组。SciPy在此基础上进行了扩展,提供了一系列在numpy数组上操作的函数,这些函数对于各种科学和工程应用都非常有用。
要深入了解SciPy,最好的方法是浏览其文档。这里将介绍一些常用的SciPy功能部分。
图像操作
SciPy提供了一些基础的图像处理函数。例如,它包含了从磁盘读取图像到numpy数组的函数,将numpy数组写入磁盘作为图像的函数,以及调整图像大小的函数。下面是一个简单的例子,展示了这些函数的使用:
from scipy.misc import imread, imsave, imresize
# 读取JPEG图像到numpy数组
img = imread('assets/cat.jpg')
print(img.dtype, img.shape) # 打印 "uint8 (400, 248, 3)"
# 可以通过缩放每个颜色通道的不同的标量常数来给图像着色。
# 图像的形状是(400, 248, 3);将它乘以形状为(3,)的数组[1, 0.95, 0.9];
# numpy的广播意味着这将保持红色通道不变,
# 并将绿色和蓝色通道分别乘以0.95和0.9。
img_tinted = img * [1, 0.95, 0.9]
# 将着色的图像调整大小为300x300像素。
img_tinted = imresize(img_tinted, (300, 300))
# 将着色的图像写回磁盘
imsave('assets/cat_tinted.jpg', img_tinted)


scipy的上述功能在最新版本已经被去掉了,在版本1.3.0以下还是可以的,如果版本高于该版本,可以采用下面的代码:
# imresize is deprecated in SciPy 1.0.0, and will be removed in 1.3.0
import cv2
from PIL import Image
from imageio import imread, imwrite
# 读取JPEG图像到numpy数组
img = imread('./cat.jpg')
print(img.dtype, img.shape) # 打印 "uint8 (400, 248, 3)"
# 可以通过缩放每个颜色通道的不同的标量常数来给图像着色。
# 图像的形状是(400, 248, 3);将它乘以形状为(3,)的数组[1, 0.95, 0.9];
# numpy的广播意味着这将保持红色通道不变,
# 并将绿色和蓝色通道分别乘以0.95和0.9。
img_tinted = img * [1, 0.95, 0.9]
# 将着色的图像调整大小为300x300像素。
img_tinted = cv2.resize(img_tinted, (300, 300))
# 将着色的图像写回磁盘
cv2.imwrite('./cat_tinted.jpg', img_tinted)
MATLAB文件
函数scipy.io.loadmat和scipy.io.savemat允许读取和写入MATLAB文件。可以在文档中了解它们。
点之间距离
SciPy定义了一些用于计算点集之间距离的有用函数。
scipy.spatial.distance.pdist 函数计算给定集合中所有点对之间的距离:
import numpy as np
from scipy.spatial.distance import pdist, squareform
# 创建以下数组,其中每一行都是2D空间中的一个点:
# [[0 1]
# [1 0]
# [2 0]]
x = np.array([[0, 1], [1, 0], [2, 0]])
print(x)
# 计算x中所有行之间的欧几里得距离。
# d[i, j] 表示 x[i, :] 和 x[j, :] 之间的欧几里得距离,
# 并且 d 是一个以下数组:
# [[ 0. 1.41421356 2.23606798]
# [ 1.41421356 0. 1. ]
# [ 2.23606798 1. 0. ]]
d = squareform(pdist(x, 'euclidean'))
print(d)
可以在文档中找到关于这个函数的详细信息。
还有一个类似的函数(scipy.spatial.distance.cdist)用于计算两个点集之间所有点对之间的距离;
Matplotlib
Matplotlib是一个绘图库。在本节中,将简要介绍matplotlib.pyplot模块,它提供了一个与MATLAB类似的绘图系统。
绘图
在Matplotlib中,最重要的函数是plot,它允许你绘制2D数据。下面是一个简单的例子:
import numpy as np
import matplotlib.pyplot as plt
# 计算正弦曲线上的点坐标
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)
# 使用matplotlib绘制点
plt.plot(x, y)
plt.show() # 必须调用plt.show()才能显示图形。
只需稍加一些额外的努力,就可以轻松地一次绘制多条线,并且可以添加标题、图例和坐标轴标签:
import numpy as np
import matplotlib.pyplot as plt
# 计算正弦和余弦曲线的点坐标
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# 使用matplotlib绘制点
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
plt.show()
子图
可以使用subplot功能在同一个图表中绘制不同的内容。下面是一个例子:
import numpy as np
import matplotlib.pyplot as plt
# 计算正弦和余弦曲线的点坐标
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# 设置一个2行1列的子图网格,
# 并将第一个子图设置为活动状态。
plt.subplot(2, 1, 1)
# 绘制第一个图
plt.plot(x, y_sin)
plt.title('Sine')
# 设置第二个子图为活动状态,并绘制第二个图。
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# 显示图形。
plt.show()
可以在文档中了解更多关于subplot函数的信息。
图像
可以使用imshow函数来显示图像。下面是一个例子:
import numpy as np
from scipy.misc import imread, imresize
import matplotlib.pyplot as plt
img = imread('./cat.jpg')
img_tinted = img * [1, 0.95, 0.9]
# 显示原始图像
plt.subplot(1, 2, 1)
plt.imshow(img)
# 显示着色的图像
plt.subplot(1, 2, 2)
# imshow的一个小陷阱是,如果给它提供不是uint8的数据,它可能会给出奇怪的结果。
# 为了解决这个问题,在显示图像之前明确地将图像转换为uint8。
plt.imshow(np.uint8(img_tinted))
plt.show()

scipy的上述功能在最新版本已经被去掉了,在版本1.3.0以下还是可以的,如果版本高于该版本,可以采用下面的代码:
import cv2
import numpy as np
from imageio import imread, imwrite
import matplotlib.pyplot as plt
img = imread('./cat.jpg')
img_tinted = img * [1, 0.95, 0.9]
# Show the original image
plt.subplot(1, 2, 1)
plt.imshow(img)
# Show the tinted image
plt.subplot(1, 2, 2)
# A slight gotcha with imshow is that it might give strange results
# if presented with data that is not uint8. To work around this, we
# explicitly cast the image to uint8 before displaying it.
plt.imshow(np.uint8(img_tinted))
plt.show()
参考
- https://cs231n.github.io/python-numpy-tutorial/