概述
在云原生领域,基础设施即代码 (IaC) 对于开发人员和 DevOps 团队来说是一种不可避免的实践。
最近,Amazon Bedrock 上线了 Claude 3 Sonnet 模型和这个模型的图像转文本能力。这无疑开启了一个新时代,也就是实现架构图与 IaC 工具的无缝融合,如亚马逊云科技云开发工具包 (CDK) 或 Terraform。 这篇博文将探讨如何使用 Amazon Bedrock 上的 Claude 3 Sonnet 来简化基础设施预配和管理流程。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
架构图
架构图以可视化方式呈现系统组件、各组件之间的关系以及应用程序或基础设施的整体结构,是团队成员之间沟通、协作和决策所依据的蓝图。但是,手动将架构图转换为代码非常耗时且容易出错,尤其是在复杂的环境中。
Amazon Bedrock 上的 Claude 3 Sonnet
Anthropic 推出的 Claude 3 系列新一代 AI 模型,迅速成为了热门话题。这个系列包括三种模型: Claude 3 Opus、Claude 3 Sonnet 和 Claude 3 Haiku,是具有强大能力的新一代模型。 这个系列模型能够从图像中解析文本。在下面介绍的解决方案中,我们将要使用这个功能。Introducing the next generation of Claude \ Anthropic
在性能方面,对于大多数工作负载而言,Sonnet 模型可谓是全能选手。无论是输入还是输出,它都比 Anthropic 之前的 Claude 2 和 2.1 模型的速度要快,并且在人工智能水平上更胜一筹。除此之外,Claude 3 Sonnet 更易于控制,这意味着我们可以得到预测性更高、质量更佳的结果。真可谓双赢!
更可喜的事情
Amazon Bedrock 宣布支持 Anthropic Claude 3 系列。Amazon Bedrock adds Claude 3 Anthropic AI models
Amazon Bedrock 是一项全托管的服务,为生成式 AI 相关需求提供一站式解决方案。我们可以在 Amazon Bedrock 上选择使用 Anthropic 等一流人工智能公司提供的多款高性能基础模型。Amazon Bedrock 还提供其他很多功能,帮助我们轻松构建和扩展生成式 AI 应用。
解决方案
现在,我们来看看解决方案。下面是构建架构提取器的操作步骤。
-
在 Amazon Bedrock 中,选用 Anthropic Claude 3。
-
复制以下脚本,创建 claude_vision.py 文件
import base64
import json
import os
import boto3
import click
from botocore.exceptions import ClientError
def call_claude_multi_model(bedrock_runtime, model_id, input_text, image, max_tokens):
"""
Streams the response from a multimodal prompt.
Args:
bedrock_runtime: The Amazon Bedrock boto3 client.
model_id (str): The model ID to use.
input_text (str) : The prompt text
image (str) : The path to an image that you want in the prompt.
max_tokens (int) : The maximum number of tokens to generate.
Returns:
None.
"""
with open(image, "rb") as image_file:
encoded_string = base64.b64encode(image_file.read())
body = json.dumps(
{
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": max_tokens,
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": input_text},
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": encoded_string.decode("utf-8"),
},
},
],
}
],
}
)
response = bedrock_runtime.invoke_model_with_response_stream(
body=body, modelId=model_id
)
for event in response.get("body"):
chunk = json.loads(event["chunk"]["bytes"])
if chunk["type"] == "content_block_delta":
if chunk["delta"]["type"] == "text_delta":
print(chunk["delta"]["text"], end="")
@click.command()
@click.option("--image_path", prompt="path to image", help="Image you want to parse")
def main(image_path):
"""
Entrypoint for Anthropic Claude Sonnet multimodal prompt example.
"""
model_id = "anthropic.claude-3-sonnet-20240229-v1:0"
input_text = """
You are a AWS solution architect,
The image provided is an architecture diagram. Use two heading to explain below.
1. Explain the technical data flow in detail.
2. Provide cdk typescript code to implement using aws-cdk-lib
Do not:
1. use preambles.
2. make assumptions.
"""
max_tokens = 4000
try:
bedrock_runtime = boto3.client("bedrock-runtime")
call_claude_multi_model(
bedrock_runtime,
model_id,
input_text,
os.path.abspath(image_path),
max_tokens,
)
except ClientError as err:
message = err.response["Error"]["Message"]
logger.error("A client error occurred: %s", message)
print("A client error occured: " + format(message))
if __name__ == "__main__":
main()-
创建并保存如下架构图。注意:记录下图像的保存路径。
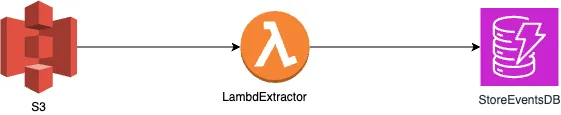
S3_extractor
-
运行脚本:
python src/utils/claude_vision.py --image_path ~/Desktop/s3_extractor.png
运行脚本后的响应
$ python src/utils/claude_vision.py --image_path ~/Desktop/s3_extractor.png
Technical Data Flow Explanation
The architecture diagram depicts a serverless data pipeline using AWS services. The data flow can be described as follows:
-
An Amazon S3 bucket is the source of data, which likely contains files or objects that need to be processed.
-
When a new object is uploaded or modified in the S3 bucket, it triggers an AWS Lambda function named "LambdaExtractor."
-
The LambdaExtractor function is responsible for extracting relevant data or events from the input files or objects in the S3 bucket.
-
After processing, the extracted data or events are stored in an Amazon DynamoDB table named "StoreEventsDB."
CDK Typescript Code Implementation
To implement this architecture using the AWS Cloud Development Kit (CDK) and TypeScript, you can use the following code:
import * as cdk from 'aws-cdk-lib';
import * as lambda from 'aws-cdk-lib/aws-lambda';
import * as s3 from 'aws-cdk-lib/aws-s3';
import * as dynamodb from 'aws-cdk-lib/aws-dynamodb';
import * as lambdaEventSources from 'aws-cdk-lib/aws-lambda-event-sources';
const app = new cdk.App();
const stack = new cdk.Stack(app, 'DataPipelineStack');
// Create the S3 bucket
const sourceBucket = new s3.Bucket(stack, 'SourceBucket');
// Create the DynamoDB table
const eventsTable = new dynamodb.Table(stack, 'StoreEventsDB', {
partitionKey: { name: 'id', type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
});
// Create the Lambda function
const lambdaExtractor = new lambda.Function(stack, 'LambdaExtractor', {
runtime: lambda.Runtime.NODEJS_14_X,
code: lambda.Code.fromAsset('path/to/lambda/code'),
handler: 'index.handler',
environment: {
EVENTS_TABLE_NAME: eventsTable.tableName,
},
});
// Grant permissions for the Lambda function to access the DynamoDB table
eventsTable.grantWriteData(lambdaExtractor);
// Create the S3 event source and associate it with the Lambda function
lambdaExtractor.addEventSource(
new lambdaEventSources.S3EventSource(sourceBucket, {
events: [s3.EventType.OBJECT_CREATED, s3.EventType.OBJECT_REMOVED],
recursive: true,
})
);In this code:
-
An S3 bucket named "SourceBucket" is created to serve as the source of data.
-
A DynamoDB table named "StoreEventsDB" is created with a partition key "id" of type string.
-
A Lambda function named "LambdaExtractor" is created with the provided source code and environment variables.
-
The Lambda function is granted write permissions to the DynamoDB table.
-
An S3 event source is created and associated with the Lambda function, triggering the function when objects are created or removed from the "SourceBucket."
Note: You need to replace 'path/to/lambda/code' with the actual path to your Lambda function code, and provide the necessary logic in the Lambda function to extract data from the S3 objects and store it in the DynamoDB table.%
架构图转 IaC 的优势
-
一致性和准确性:转换过程自动化可以消除人为错误风险,确保基础设施代码符合你的架构设计。
-
更快迭代和部署:根据架构图快速生成代码能力帮助我们快速迭代基础设施、测试改动和部署更新。
-
协作和标准化:架构图是团队有效沟通和协作的基础依据。通过将架构图转换为 IaC,你可以在整个组织内建立一致的标准化基础设施管理方法。
-
版本控制和可审计性:亚马逊云科技 CDK 和 Terraform 均支持代码版本控制,便于全面审计跟踪基础设施更改,从而更好地实现治理和合规。
总结
Claude 3 Sonnet 与 Amazon Bedrock 的集成,以及架构图转 CDK 或 Terraform 代码的能力,大大方便了开发人员和 DevOps 团队。 采用这种方法,我们就可以充分利用 IaC 的强大能力,简化工作流程,加快交付可靠且可扩展的云基础设施。让我们一起踏上这段旅程,体验可视化设计与自动代码生成的无缝集成,高效构建和管理云环境。
下一篇文章中,我将介绍一种基于 streamlit web UI 的构建方法。不熟悉命令行界面 (CLI) 的用户可以使用交互式 UI 来实现这个解决方案。
本文中的任何观点仅代表作者个人的观点,不代表亚马逊云科技的观点。
文章来源:使用 Amazon Bedrock 上的 Claude 3 将架构图转换为 CDK/Terraform 代码