文章目录
- 引发思考的一道算法题
- slice
- make初始化
- 切片扩容原理
- 切片截取原理
- 切片复制原理
- 算法题的正解
- 补充
- string和[]byte互转
- string 与[]byte相互转换
引发思考的一道算法题
链接:组合
给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
大致的思路就是递归+回溯:
- res [][]int存储所有可能的结果,temp []int存储一种可能的结果
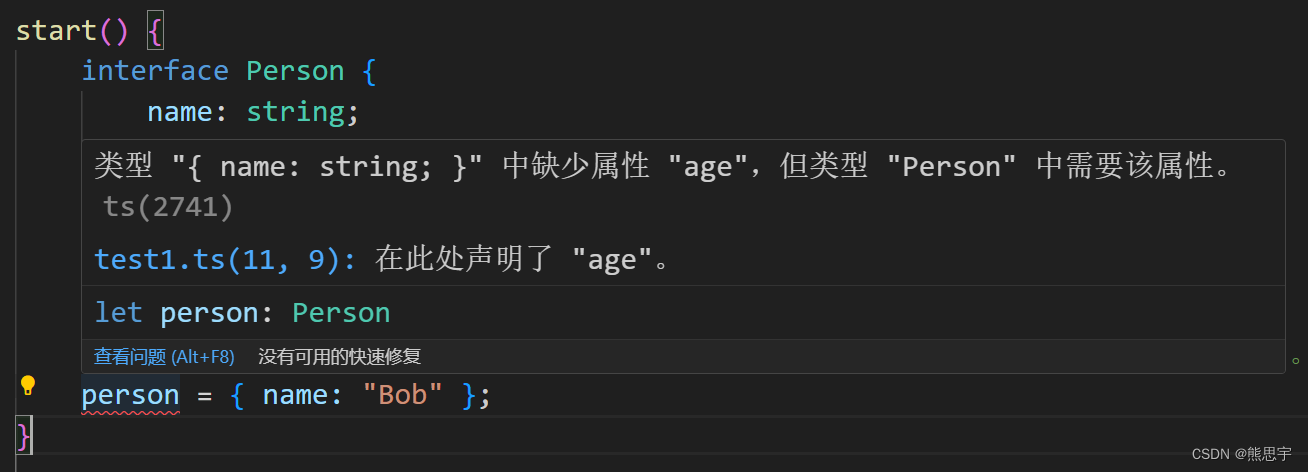
- 首先确定递归参数和返回值。对于这道题目不需要有返回值,参数的话,传入n,k表示从n个数选出k个数,传入in表示当前处理的第几个数字.[由于闭包可以捕获变量所以n,k不需要作为参数传入]
- 递归边界就是,当切片temp中的元素个数到达k的时候,将其存储到res中
- 核心处理逻辑,从in–n中选择一个数字加入temp,然后递归,回溯
代码如下:
//这里使用到了闭包
func combine(n int, k int) [][]int {
var res [][]int
var tem []int
var dfs func (int)
dfs=func(in int){
if len(tem)==k{
res=append(res,tem)
}
for i:=in;i<=n;i++{
tem=append(tem,i)
dfs(i+1)
tem=tem[:len(tem)-1]
}
}
dfs(1)
return res
}
看一下运行结果

- 通过运行结果发现,结果中的值被覆盖掉了。要解释这个现象,还需要了解一下slice的底层构成。
slice
源码位置
src\runtime\slice.go
- slice其实是一个struct
type slice struct {
//指向底层数组的指针
array unsafe.Pointer
//数组长度
len int
//为数组分配的总空间大小
cap int
}
make初始化
slice:=make([]int,3,4)
利用"make"初始化一个slice会调用"makeslice函数"[src\runtime\slice.go]
func makeslice(et *_type, len, cap int) unsafe.Pointer {
//et.size表示的是切片内数据类型的大小,math.MulUinptr计算两个数的乘积,并返回这个乘积和一个表示是否溢出的bool型变量
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
//要么是用cap申请的内存溢出或者超出最大限制,要么是len和cap的关系有问题
if overflow || mem > maxAlloc || len < 0 || len > cap {
//再次计算用len申请的内存大小
mem, overflow := math.MulUintptr(et.size, uintptr(len))
//内存溢出。或者超出最大限制或者len<0
if overflow || mem > maxAlloc || len < 0 {
//panic("len out of range ")
panicmakeslicelen()
}
//panic("cap out of range ")len>cap的情况
panicmakeslicecap()
}
//如果申请cap*size大小的内存可以的话就申请cap*size大小的内存,不然的话申请len*size大小的内存
return mallocgc(mem, et, true)
}
如果make函数初始化一个很大的切片,该切片会逃逸到堆上。如果分配了一个比较小的切片会直接在栈中分配。没有发生逃逸调用的是"makeslice"函数,发生逃逸调用的是"makeslice64"函数
func makeslice64(et *_type, len64, cap64 int64) unsafe.Pointer {
//首先会判断要申请的内存大小是否超出了理论上系统可以分配的内存大小
len := int(len64)
if int64(len) != len64 {
panicmakeslicelen()
}
cap := int(cap64)
if int64(cap) != cap64 {
panicmakeslicecap()
}
//没有超出,理论上可以申请内存
return makeslice(et, len, cap)
}
看一下“mallogc”分配内存的函数,这个函数就不展开来看了,看看源代码上的解释
Allocate an object of size bytes.
Small objects are allocated from the per-P cache’s free lists.
Large objects (> 32 kB) are allocated straight from the heap.
小对象(<=32KB)可以直接分配在P拥有的cache的空闲链表中[这里的P是指GMP中的P,cache和go的内存管理有关,指的是mcache],大对象(>32KB)直接在堆上分配
需要注意的是每个版本的阈值可能不一样,我的版本是go version go1.20.8 windows/amd64
切片扩容原理
slice通过append进行扩容,先用代码演示一下
func main() {
//调用makesilice进行内存的分配
s := make([]int, 3, 4)
fmt.Println(len(s), cap(s)) //3 4
s = append(s, 1)
fmt.Println(len(s), cap(s))//4 4
s = append(s, 2)
fmt.Println(len(s), cap(s))//5 8
}
- 当插入元素时发现,没有可用的空间[len==cap],会先进行扩容,然后插入新的元素。
扩容的核心逻辑位于“slice.go\growslice”函数中
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
oldLen := newLen - num
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(oldPtr, uintptr(oldLen*int(et.size)), callerpc, abi.FuncPCABIInternal(growslice))
}
if msanenabled {
msanread(oldPtr, uintptr(oldLen*int(et.size)))
}
if asanenabled {
asanread(oldPtr, uintptr(oldLen*int(et.size)))
}
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve oldPtr in this case.
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
newcap := oldCap
doublecap := newcap + newcap
if newLen > doublecap {
newcap = newLen
} else {
const threshold = 256
if oldCap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < newLen {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = newLen
}
}
}
//根据内存对齐计算分配的内存大小
var overflow bool
var lenmem, newlenmem, capmem uintptr
switch {
case et.size == 1:
lenmem = uintptr(oldLen)
newlenmem = uintptr(newLen)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == goarch.PtrSize:
lenmem = uintptr(oldLen) * goarch.PtrSize
newlenmem = uintptr(newLen) * goarch.PtrSize
capmem = roundupsize(uintptr(newcap) * goarch.PtrSize)
overflow = uintptr(newcap) > maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if goarch.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.TrailingZeros64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.TrailingZeros32(uint32(et.size))) & 31
}
lenmem = uintptr(oldLen) << shift
newlenmem = uintptr(newLen) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
capmem = uintptr(newcap) << shift
default:
lenmem = uintptr(oldLen) * et.size
newlenmem = uintptr(newLen) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
capmem = uintptr(newcap) * et.size
}
if overflow || capmem > maxAlloc {
panic(errorString("growslice: len out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem-et.size+et.ptrdata)
}
}
//将旧数组的数据完全拷贝到新数组
memmove(p, oldPtr, lenmem)
return slice{p, newLen, newcap}
}
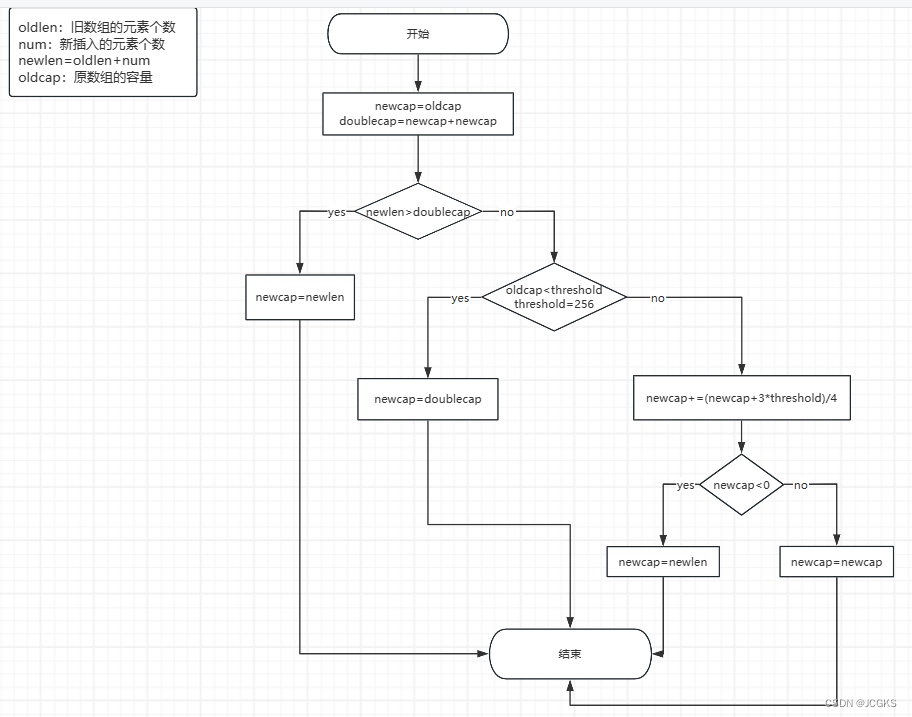
看核心代码如何计算扩容之后的新的容量的:
/*
oldLen:指的是旧数组的元素个数
num:指的是加入的元素的个数
newLen:指的是oldLen+num,新数组的元素个数
oldCap:指的是原数组的容量
*/
//首先将newCap赋值为oldCap
newcap := oldCap
//doubleCap等于原cap的两倍
doublecap := newcap + newcap
//新数组的长度大于原数组容量的两倍
if newLen > doublecap {
//新容量等于新的长度
newcap = newLen
} else {
//新长度小于等于旧容量的2倍
//阈值设为256
const threshold = 256
//旧容量小于阈值
if oldCap < threshold {
//新容量等于旧容量的两倍
newcap = doublecap
} else {
//旧容量大于等于阈值
//持续增加newcap[初始值是oldcap]直到newcap大于等于newLen或者newcap<=0[这种情况是发生了溢出]
for 0 < newcap && newcap < newLen {
//小切片[oldcap<256]以2倍的速度增长
//大切片[oldcap>=256]以1.25倍的速度增长
newcap += (newcap + 3*threshold) / 4
}
//经过计算之后newcap发生溢出
if newcap <= 0 {
//溢出的话,将新容量设置为新长度
newcap = newLen
}
}
}
综上述来看,扩容的策略如下:
- 新数组的长度大于旧容量的两倍,新容量等于新数组长度
- 新数组的长度小于旧容量的两倍
- 旧容量小于阈值256,新容量等于旧容量的两倍
- 旧容量大于等于阈值256,新容量用oldcap作为初始值以1.25倍的速度增长直到大于等于新长度
- 经过计算新容量发生了溢出,将新容量设置为新长度
为了内存对齐,申请的内存可能大于实际算出的内存大小,这涉及到内存管理的知识。
func main() {
//调用makesilice进行内存的分配
s := make([]int64, 99, 99)
fmt.Println(len(s), cap(s)) //99 99
s = append(s, 1)
fmt.Println(len(s), cap(s)) //100 224
s = append(s, 2)
fmt.Println(len(s), cap(s)) //101 224
}
根据不同的类型执行不同的逻辑
if et.ptrdata == 0 {
//没有指针类型的数据
p = mallocgc(capmem, nil, false)
//分配内存之后,将newlen之后的多出来的内存进行清空
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
//含有指针类型的数据
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
//分配内存之后需要开启写屏障,对旧指针指向的对象进行标记[这里涉及到垃圾回收]
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(oldPtr), lenmem-et.size+et.ptrdata)
}
}
//将oldPtr中的元素复制到p中
memmove(p, oldPtr, lenmem)
切片截取原理
切片截取会复制slice struct中的三个字段:array[unsafe.Pointer]、len[int]、cap[int],所以由一个切片截取出来的切片会指向同一个底层数组。
但是需要注意的是,切片之间共享的是底层的数组,len和cap变量的值是没有共享的。所以对于同样的数据,切片a可以访问到,但是切片b访问不到
func case2() {
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8}
printLengthAndCap(s1)
s2 := s1[1:]
printLengthAndCap(s2)
fmt.Printf("addr(s1)=%p,addr(s2)=%p\n", s1, s2)
}
/*
运行结果如下:
[1 2 3 4 5 6 7 8]
len=8 cap=8
[2 3 4 5 6 7 8]
len=7 cap=7
addr(s1)=0xc000010380,addr(s2)=0xc000010388
*/
可以看到s1和s2指向同一个底层数组,只是起始位置不一致。
func case3() {
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8}
printLengthAndCap(s1)
s2 := s1[:]
printLengthAndCap(s2)
fmt.Printf("addr(s1)=%p,addr(s2)=%p\n", s1, s2)
}
/*
[1 2 3 4 5 6 7 8]
len=8 cap=8
[1 2 3 4 5 6 7 8]
len=8 cap=8
addr(s1)=0xc000010380,addr(s2)=0xc000010380
*/
func case4() {
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8}
printLengthAndCap(s1)
s2 := s1[:6]
printLengthAndCap(s2)
fmt.Printf("addr(s1)=%p,addr(s2)=%p\n", s1, s2)
}
/*
[1 2 3 4 5 6 7 8]
len=8 cap=8
[1 2 3 4 5 6]
len=6 cap=8
addr(s1)=0xc000010380,addr(s2)=0xc000010380
*/
接下来对其中一个slice进行修改看看另外一个slice能不能看得到
func case5() {
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8}
s2 := s1[:6]
s2[0] = 0
s2 = append(s2, 9)
printLengthAndCap(s1)
printLengthAndCap(s2)
}
/*
[0 2 3 4 5 6 9 8]
len=8 cap=8
[0 2 3 4 5 6 9]
len=7 cap=8
*/
- 从运行结果来看,s2的修改引起的s1的修改,因为s2和s1指向同一个底层数组。而且s2=append(s2,9)导致s1原本的元素被覆盖,这也能解释刚开始的算法题为什么出现了值被覆盖的情况,因为在向上回溯的过程中,对一个slice的修改影响了其它的slice。
- 如果append操作引起了扩容,那么对该slice的修改不会影响其它的slice。因为上面介绍过,扩容就是分配一块新的内存将原先的数据全部拷贝过来,然后插入新的数据。
package main
import "fmt"
func main(){
s:=[]int{1,2,3}
s1:=s[:2]
fmt.Println("s:",s,"s1:",s1)
s1=append(s1,4)
fmt.Println("s:",s,"s1:",s1)
s1=append(s1,6)
fmt.Println("s:",s,"s1:",s1)
}
/*
s: [1 2 3] s1: [1 2]
s: [1 2 4] s1: [1 2 4]
s: [1 2 4] s1: [1 2 4 6]
*/
那有什么方法可以解决呢?当时是希望在拷贝的过程中不只是简单的拷贝slice struct三个字段的值,而是将底层数组进行深拷贝。go中的copy函数可以做到这个,接下来看看切片复制的原理。
切片复制原理
截取切片,只会复制切片结构中的三个字段,指向的底层数组还是同一个。如果想要建立一个全新的与原来的切片拥有不同的数据源,可以使用copy(dst,src)函数
copy函数在运行时调用了memmove函数,实现基于内存的复制
// slicecopy is used to copy from a string or slice of pointerless elements into a slice.
func slicecopy(toPtr unsafe.Pointer, toLen int, fromPtr unsafe.Pointer, fromLen int, width uintptr) int {
//src原切片和dst目标切片的长度都为0,无需复制
/*
从这一行代码也可以看出,以源切片和目的切片的最小长度为准,
源切片的长度为0表示没有数据,没有数据也就无法将数据拷贝到目的切片;
目的切片的长度为0表示没有可用的空间,源切片就算有数据也无法拷贝到目的切片。
*/
if fromLen == 0 || toLen == 0 {
return 0
}
//只会复制fromlen[src slice长度]和tolen[dst slice]中最小的长度
//n存储的是min(fromLen,toLen)
n := fromLen
if toLen < n {
n = toLen
}
//width指的是size of single element
if width == 0 {
return n
}
//计算需要分配的内存大小
size := uintptr(n) * width
if raceenabled {
callerpc := getcallerpc()
pc := abi.FuncPCABIInternal(slicecopy)
racereadrangepc(fromPtr, size, callerpc, pc)
racewriterangepc(toPtr, size, callerpc, pc)
}
if msanenabled {
msanread(fromPtr, size)
msanwrite(toPtr, size)
}
if asanenabled {
asanread(fromPtr, size)
asanwrite(toPtr, size)
}
/*
如果需要分配的内存只有1byte,那么不需要进行内存的分配,只需将fromptr[src slice]转换为byte复制给toptr
*/
if size == 1 {
*(*byte)(toPtr) = *(*byte)(fromPtr) // known to be a byte pointer
} else {
//memmove copies n bytes from "from" to "to".
//从fromPtr指向的底层数组复制size bytes到toptr指向的底层数组
memmove(toPtr, fromPtr, size)
}
//返回复制的元素个数
return n
}
算法题的正解
分析到这里,就可以正确的修改开篇提到的算法题。
我们只需要在递归终止边界哪里,利用copy函数,复刻出一份完全不同的slice将其append到结果集中即可。
func combine(n int, k int) [][]int {
var res [][]int
var tem []int
var dfs func (int)
dfs=func(in int){
if len(tem)==k{
te:=make([]int,k)
copy(te,tem)//深度拷贝原切片的数据
res=append(res,te)
}
for i:=in;i<=n;i++{
tem=append(tem,i)
dfs(i+1)
tem=tem[:len(tem)-1]
}
}
dfs(1)
return res
}
补充
上面提到扩容会引起,内存的重新分配和元素的移动。所以如果append操作引起了扩容操作,那么这个时候所做的修改另一个slice是感知不到的。
func case6() {
s1 := []int{1, 2, 3, 4}
s2 := s1[:]
s2[0] = 0
s2 = append(s2, 9)
printLengthAndCap(s1)
printLengthAndCap(s2)
fmt.Printf("addr(s1)=%p,addr(s2)=%p\n", s1, s2)
}
/*
[0 2 3 4]
len=4 cap=4
[0 2 3 4 9]
len=5 cap=8
addr(s1)=0xc00001c120,addr(s2)=0xc000010380
*/
需要注意的是slice共享的是底层的buf数组,但是没有共享字段"len和cap"。
string和[]byte互转
首先介绍一下reflect包里的"sliceHeader"和"stringHeader"
sliceHeader
// SliceHeader is the runtime representation of a slice.
type SliceHeader struct {
Data uintptr
Len int
Cap int
}
- sliceHeader的结构和slice struct很类似,都是包含三个字段:指向底层数组的指针,len,cap;
接着利用SliceHeader和reflect包,验证一下是否不同的切片共享底层的数组
func main() {
a1 := [2]string{"fei", "xue"}
s1 := a1[:]
s2 := a1[0:1]
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&s1)).Data)
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&s2)).Data)
}
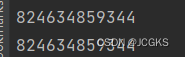
- 可以发现这两个切片共用一个数组,在切片赋值的时候使用的是同一个数组,没有复制原来的元素,这样可以减少内存的占用,提高效率。
stringHeader
// StringHeader is the runtime representation of a string.
type StringHeader struct {
Data uintptr
Len int
}
- stringHeader和sliceHeader的结构很类似,都包含指向底层数组的指针和表示数据长度的len字段。
- 不同的是,sliceHeader比stringHeader多一个cap字段。也正因为如此,slice是可以修改的但是string是不可以修改的。
string 与[]byte相互转换
[]byte与string相互转换,并打印出其初始地址。最直接的方式就是通过强制类型转换来完成。
func main() {
s := "小狗真可爱"
b := []byte(s)
ss := string(b)
fmt.Println(s, b, ss)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&s)).Data)
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&ss)).Data
)

- go语言通过先分配内存后复制内容的方式,实现string和[]byte之间的强制转换。
- 由于要分配一块新的内存并将数据拷贝过来,在数据量很大的情况下开销是很大的。
程序在运行的时候,字符串和切片的本质就是StringHeader和SliceHeader。这两个结构都有一个Data字段,用于存放指向真实数据的指针。[所以可以通过打印Data字段的值判断string和[]byte强制转换后是否重新分配了内存。]
有没有什么方式可以优化呢?
如何优化呢?避免内存的重新分配就可以提高转换的效率.
SliceHeader具有StringHeader含有的Data字段和Len字段,所以可以通过unsafe.Pointer把*SliceHeader转换为 *StringHeader,也就是*[]byte转化为*string完成slice到string之间的转换。
func main() {
s := "小狗真可爱"
b := []byte(s)
s1 := *((*string)(unsafe.Pointer(&b)))
ss := string(b)
fmt.Println(s, b, s1, ss)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&s)).Data)
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&s1)).Data)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&ss)).Data)

- 上述示例中。s1中存储的内容和b中存储的内容是一样的,不但如此起始地址还是一样的。说明从[]byte类型的b转化为string类型的ss并没有申请新的内存。
- 但其实这样做存在一个问题,string本质上是不能修改的,但是通过上述的转换,[]byte和string指向的是一个底层数组,这样对[]byte的修改,string也能看到。可能会发生不在预期之内的事情。
SliceHeader有Data 、Len、Cap三个字段,StringHeader有Data、Len两个字段,所以*SliceHeader通过unsafe.Pointer转换为*StringHeader的时候没有问题,因为*SliceHeader可以提供*StringHeader所需的Data和Len字段。但是反过来就不行了,因为*StringHeader中没有*SliceHeader需要的Cap字段。但是可以手动补充。
func main() {
s := "小狗真可爱"
//将string转换为[]byte之前先手动填充Cap字段
((*reflect.SliceHeader)(unsafe.Pointer(&s))).Cap = len(s)
bb := *((*[]byte)(unsafe.Pointer(&s)))
//string强制转换为[]byte
b := []byte(s)
//通过共享的方式转换为string
s1 := *((*string)(unsafe.Pointer(&b)))
//[]byte强制转换为string
ss := string(b) //字符串不能修改
fmt.Println(s, bb, b, s1, ss)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&s)).Data)
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&bb)).Data)
fmt.Println((*reflect.SliceHeader)(unsafe.Pointer(&b)).Data)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&s1)).Data)
fmt.Println((*reflect.StringHeader)(unsafe.Pointer(&ss)).Data)
)

- 通过这种方式得到的[]byte是无法修改的,因为此时的[]byte指向string中的Data,而string是无法被修改的。