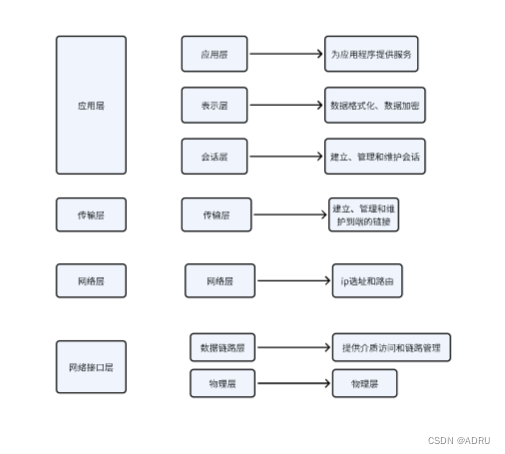
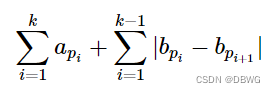FlashAttention是一种用于Transformer模型的近似注意力机制,旨在减少注意力计算和内存需求。引入FlashAttention是因为传统Transformer模型中的自注意力机制在处理长序列时存在时间和存储复杂度上的挑战,需要大量的计算资源和内存来处理更长的上下文背景。
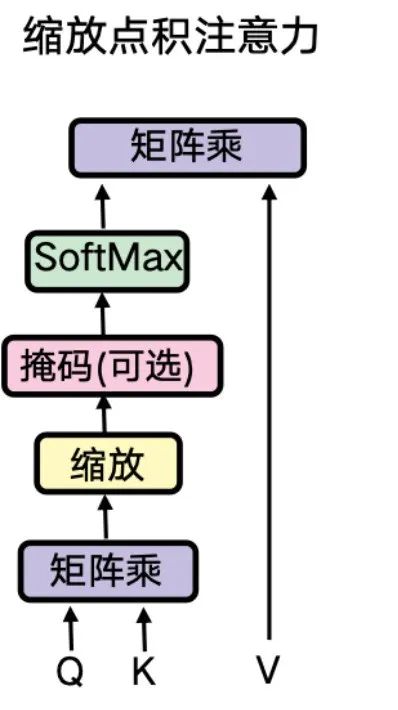
我们知道Transformer的注意力机制的计算过程为:矩阵乘法 --> 缩放点积 --> 掩码 --> softmax --> dropout --> 矩阵乘法。
因为Transformer的自注意力机制(self-attention)的计算的时间复杂度和空间复杂度都与序列长度有关,所以在处理长序列的时候会变的更慢,同时内存会增长更多,Transformer模型的计算量和内存占用是序列长度N的二次方。所以受内存的限制,大语言模型的最大序列长度大多为一个限制值(比如2048或4096)。
为什么引入FlashAttention:
-
减少计算和内存需求:FlashAttention旨在降低注意力计算的复杂度,特别是关注减少内存访问的开销,从而提高模型的效率和速度。
-
提高运行速度:通过减少GPU内存读取/写入,FlashAttention相比传统的注意力机制能够更快地执行计算,提升模型的训练和推理速度。
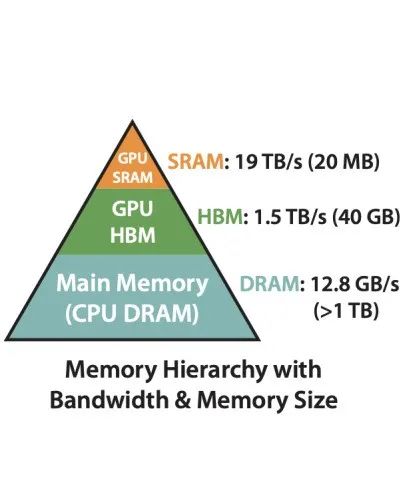
attention算法也是IO敏感的,从上面的图可以看出,通过对GPU显存访问的改进来对attention算法的实现进行优化,可以减少高带宽内存(High Bandwidth Memory,HBM)的访问,来提升模型的训练和推理速度。
FlashAttention算法实现的关键主要有:softmax的tiling展开,可以支持softmax的拆分并行计算,从而提升计算效率;反向过程中的重计算,减少大量的显存占用,节省显存开销;通过CUDA编程实现fusion kernel。
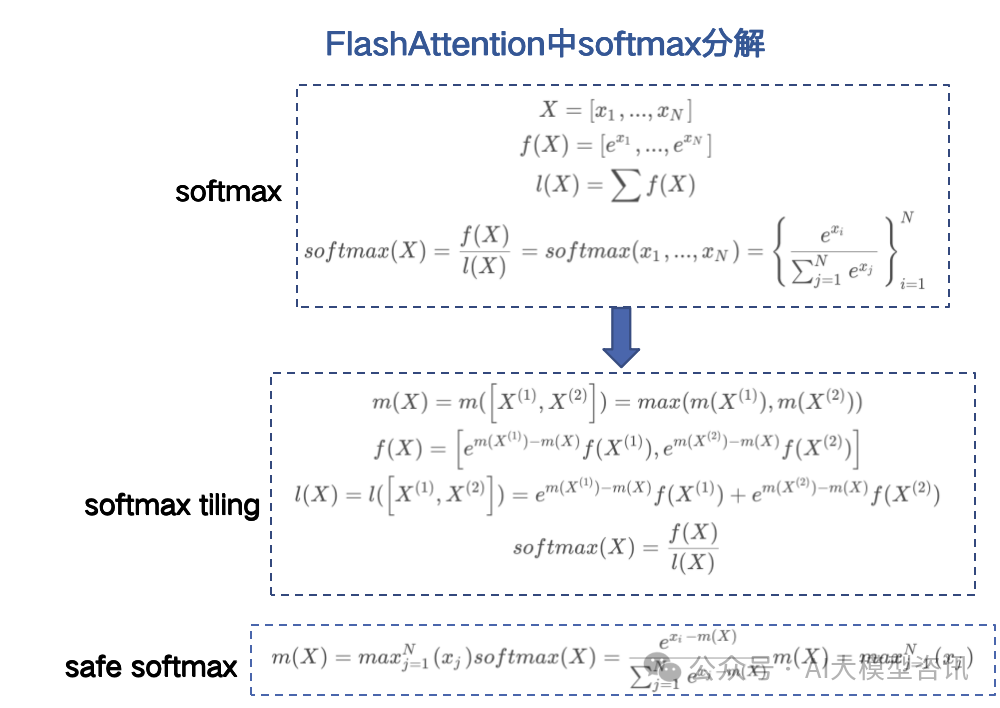
主要讲解一下softmax的tiling展开,由于普通的softmax中e^{x_i}很容易溢出, 比如FP16支持范围是 2^{-24} 约等于 655042 ,当 x_i ≥ 11的时候,e^{x_i}会超过float16的有效位。为解决这个问题提出 safe softmax, 对每个x_i都减去一个 m = max^N_{j=1}(x_j), 使得 x_i - m ≪0, 这时幂操作符对负数输入的计算是准确且安全的。
FlashAttention的优点:
-
快速计算:FlashAttention能够在不访问整个输入和不存储大型注意力矩阵的情况下计算softmax函数的缩减,从而提高计算效率。
-
内存效率:FlashAttention减少了对高带宽显存(HBM)的读取或写入操作,降低了内存需求,使模型在较少的内存空间下运行。
FlashAttention的缺点:
-
近似性:作为近似注意力机制,FlashAttention可能会引入一定程度的信息损失,导致模型在某些情况下性能略有下降。
-
复杂性:实现FlashAttention可能需要对传统的注意力机制进行修改和调整,这可能增加了模型的复杂性和实现难度。
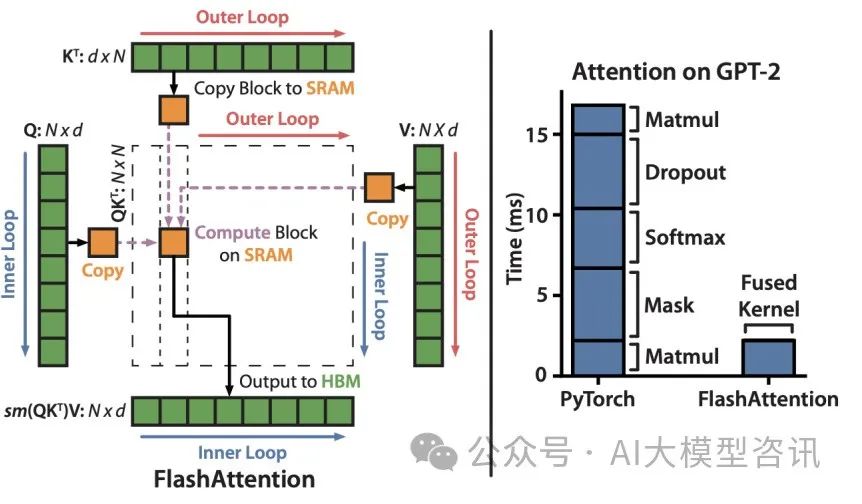
FlashAttention主要是可以加速计算、节省显存、精确的注意力。加快计算:没有减少计算量FLOPs,而是减少了HBM访问次数;节省显存:通过引入统计量,避免了实例化注意力矩阵,将显存复杂度从O(N^2)降低到O(N);精确注意力:不同于稀疏注意力,是分块计算,而不是近似计算,与原生注意力等价.
总的来说,引入FlashAttention在一定程度上解决了传统Transformer模型中的计算和内存瓶颈问题,提高了模型的效率和速度,但也需要权衡近似性和复杂性带来的影响。在特定场景下,选择是否采用FlashAttention取决于对速度和内存效率的需求以及对模型性能损失的容忍度。
PS:欢迎扫码头像关注公众号^_^.