一、本文介绍
本文给大家带来的改进机制是轻量级的变换器模型:Illumination Adaptive Transformer (IAT),用于图像增强和曝光校正。其基本原理是通过分解图像信号处理器(ISP)管道到局部和全局图像组件,从而恢复在低光或过/欠曝光条件下的正常光照sRGB图像。具体来说,IAT使用注意力查询来表示和调整ISP相关参数,例如颜色校正、伽马校正。模型具有约90k参数和约0.004s的处理速度,能够在低光增强和曝光校正的基准数据集上持续实现优于最新技术(State-of-The-Art, SOTA)的性能,我们将其用于YOLOv8上来改进我们模型的暗光检测能力,同时本文的内容不影响其它的模块改进。
欢迎大家订阅我的专栏一起学习YOLO!

专栏目录:YOLOv8改进有效系列目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制
目录
一、本文介绍
二、基本原理
2.1 IAT原理
2.2 IAT的核心模块
三、核心代码
四、手把手教你添加IAT低照度图像增强网络
4.1 修改一
4.2 修改二
4.3 修改三
4.4 修改四
五、IAT的yaml文件和运行记录
5.1 IAT的yaml文件
5.2 训练代码
5.3 IAT的训练过程截图
五、本文总结
二、基本原理
 论文地址:官方论文地址点击此处即可跳转
论文地址:官方论文地址点击此处即可跳转
代码地址:官方代码地址点击此处即可跳转
2.1 IAT原理
本文提出了一个轻量级的变换器模型:Illumination Adaptive Transformer (IAT),用于图像增强和曝光校正。其基本原理是通过分解图像信号处理器(ISP)管道到局部和全局图像组件,从而恢复在低光或过/欠曝光条件下的正常光照sRGB图像。具体来说,IAT使用注意力查询来表示和调整ISP相关参数,例如颜色校正、伽马校正。模型具有约90k参数和约0.004s的处理速度,能够在低光增强和曝光校正的基准数据集上持续实现优于最新技术(State-of-The-Art, SOTA)的性能。
Illumination Adaptive Transformer (IAT)的基本原理如下:
1. 轻量级变换器架构:IAT设计为一个轻量级的模型,具有大约90,000个参数,专注于图像增强和曝光校正任务。这使得它在处理速度和资源消耗上非常高效,适用于实时或资源受限的应用场景。
2. 图像信号处理器(ISP)管道分解:IAT的核心原理是模拟并改进传统的ISP管道。通过分解ISP处理过程中的局部和全局图像成分,IAT能够针对特定的光照条件调整图像的视觉表现。
3. 适应性光照调整:IAT能够根据输入图像的光照条件动态调整处理策略,有效地处理低光、过曝光和欠曝光等情况,恢复正常光照下的sRGB图像。
下面为大家展示Illumination Adaptive Transformer (IAT)的结构分为两个主要部分:局部分支和全局分支。

1. 局部分支 (Local Branch):处理图像的局部特征。这一分支通过多次使用参数增强模块(PEM)来提取局部特征,并通过卷积层来进一步处理这些特征。
2. 全局分支 (Global Branch):处理图像的全局信息。它同样包含多个PEM和卷积层,不过处理的是全局图像内容。
3. 参数生成 (黑色线条):黑色线条表示参数生成路径,即如何通过网络生成ISP管道中需要的参数,如颜色矩阵和伽马值。
4. 图像处理 (黄色线条):黄色线条表示实际的图像处理路径。图像经过局部和全局分支的处理后,获得的特征会被用于调整图像的颜色和曝光。
5. 交叉注意力 (Cross Attention):这一组件在全局分支中,负责整合局部和全局分支的信息,以更准确地调整颜色矩阵和伽马值。
6. 最终输出:处理过的图像特征通过一个重塑操作和卷积层的处理,将局部和全局的调整应用到原始输入图像上,最终输出增强后的图像。
2.2 IAT的核心模块
下面这张图为大家直观地展示了Illumination Adaptive Transformer (IAT)中的两个核心模块:像素级增强模块(Pixel-wise Enhancement Module, PEM)和全局预测模块(Global Prediction Module, GPM)。

(a)像素级增强模块(PEM):
输入: 大小为 \( B \times C \times H \times W \) 的特征图,其中 \( B \) 表示批次大小,\( C \) 表示通道数,\( H \times W \) 表示特征图的高和宽。
流程:
1. 通过一系列的1x1卷积层,对特征图进行逐点的线性变换,以增强或调整特定像素点的特性。
2. 每个1x1卷积层之后,进行元素级的相乘(表示为黄色的圆圈和相乘符号)。
3. 操作结束后,特征图被重塑成原始的 \( B \times C \times H \times W \) 形状。
(b)全局预测模块(GPM):
流程:
1. 特征图首先经过一个全连接层(FC),产生 ,代表全局信息的值向量。
2. 另一个全连接层生成,代表键向量。
3. 和
通过交叉注意力机制与查询
相结合,查询
通常来自于局部特征。
4. 结果通过重塑操作,形成颜色校正矩阵和伽马校正值。
两个模块共同工作,PEM负责增强局部特征细节,而GPM则负责生成全局调整参数,两者合作为图像增强提供更精细的控制。通过这种方法,IAT能够在处理不同光照条件下的图像时提供细腻的调整,实现出色的图像增强效果。
三、核心代码
核心代码的使用方式看章节四!
import math
import torch
import torch.nn as nn
from timm.models.layers import trunc_normal_, DropPath, to_2tuple
__all__ = ['IAT']
class query_Attention(nn.Module):
def __init__(self, dim, num_heads=2, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Parameter(torch.ones((1, 10, dim)), requires_grad=True)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q = self.q.expand(B, -1, -1).view(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, 10, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class query_SABlock(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = norm_layer(dim)
self.attn = query_Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
x = x.flatten(2).transpose(1, 2)
x = self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class conv_embedding(nn.Module):
def __init__(self, in_channels, out_channels):
super(conv_embedding, self).__init__()
self.proj = nn.Sequential(
nn.Conv2d(in_channels, out_channels // 2, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(out_channels // 2),
nn.GELU(),
# nn.Conv2d(out_channels // 2, out_channels // 2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
# nn.BatchNorm2d(out_channels // 2),
# nn.GELU(),
nn.Conv2d(out_channels // 2, out_channels, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)),
nn.BatchNorm2d(out_channels),
)
def forward(self, x):
x = self.proj(x)
return x
class Global_pred(nn.Module):
def __init__(self, in_channels=3, out_channels=64, num_heads=4, type='exp'):
super(Global_pred, self).__init__()
if type == 'exp':
self.gamma_base = nn.Parameter(torch.ones((1)), requires_grad=False) # False in exposure correction
else:
self.gamma_base = nn.Parameter(torch.ones((1)), requires_grad=True)
self.color_base = nn.Parameter(torch.eye((3)), requires_grad=True) # basic color matrix
# main blocks
self.conv_large = conv_embedding(in_channels, out_channels)
self.generator = query_SABlock(dim=out_channels, num_heads=num_heads)
self.gamma_linear = nn.Linear(out_channels, 1)
self.color_linear = nn.Linear(out_channels, 1)
self.apply(self._init_weights)
for name, p in self.named_parameters():
if name == 'generator.attn.v.weight':
nn.init.constant_(p, 0)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
#print(self.gamma_base)
x = self.conv_large(x)
x = self.generator(x)
gamma, color = x[:, 0].unsqueeze(1), x[:, 1:]
gamma = self.gamma_linear(gamma).squeeze(-1) + self.gamma_base
#print(self.gamma_base, self.gamma_linear(gamma))
color = self.color_linear(color).squeeze(-1).view(-1, 3, 3) + self.color_base
return gamma, color
# ResMLP's normalization
class Aff(nn.Module):
def __init__(self, dim):
super().__init__()
# learnable
self.alpha = nn.Parameter(torch.ones([1, 1, dim]))
self.beta = nn.Parameter(torch.zeros([1, 1, dim]))
def forward(self, x):
x = x * self.alpha + self.beta
return x
# Color Normalization
class Aff_channel(nn.Module):
def __init__(self, dim, channel_first = True):
super().__init__()
# learnable
self.alpha = nn.Parameter(torch.ones([1, 1, dim]))
self.beta = nn.Parameter(torch.zeros([1, 1, dim]))
self.color = nn.Parameter(torch.eye(dim))
self.channel_first = channel_first
def forward(self, x):
if self.channel_first:
x1 = torch.tensordot(x, self.color, dims=[[-1], [-1]])
x2 = x1 * self.alpha + self.beta
else:
x1 = x * self.alpha + self.beta
x2 = torch.tensordot(x1, self.color, dims=[[-1], [-1]])
return x2
class Mlp(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CMlp(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CBlock_ln(nn.Module):
def __init__(self, dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=Aff_channel, init_values=1e-4):
super().__init__()
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
#self.norm1 = Aff_channel(dim)
self.norm1 = norm_layer(dim)
self.conv1 = nn.Conv2d(dim, dim, 1)
self.conv2 = nn.Conv2d(dim, dim, 1)
self.attn = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
#self.norm2 = Aff_channel(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.gamma_1 = nn.Parameter(init_values * torch.ones((1, dim, 1, 1)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((1, dim, 1, 1)), requires_grad=True)
self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
B, C, H, W = x.shape
#print(x.shape)
norm_x = x.flatten(2).transpose(1, 2)
#print(norm_x.shape)
norm_x = self.norm1(norm_x)
norm_x = norm_x.view(B, H, W, C).permute(0, 3, 1, 2)
x = x + self.drop_path(self.gamma_1*self.conv2(self.attn(self.conv1(norm_x))))
norm_x = x.flatten(2).transpose(1, 2)
norm_x = self.norm2(norm_x)
norm_x = norm_x.view(B, H, W, C).permute(0, 3, 1, 2)
x = x + self.drop_path(self.gamma_2*self.mlp(norm_x))
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
#print(x.shape)
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
## Layer_norm, Aff_norm, Aff_channel_norm
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, num_heads=2, window_size=8, shift_size=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=Aff_channel):
super().__init__()
self.dim = dim
self.num_heads = num_heads
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
#self.norm1 = norm_layer(dim)
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
#self.norm2 = norm_layer(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
B, C, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
x = x.transpose(1, 2).reshape(B, C, H, W)
return x
class Local_pred(nn.Module):
def __init__(self, dim=16, number=4, type='ccc'):
super(Local_pred, self).__init__()
# initial convolution
self.conv1 = nn.Conv2d(3, dim, 3, padding=1, groups=1)
self.relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
# main blocks
block = CBlock_ln(dim)
block_t = SwinTransformerBlock(dim) # head number
if type == 'ccc':
# blocks1, blocks2 = [block for _ in range(number)], [block for _ in range(number)]
blocks1 = [CBlock_ln(16, drop_path=0.01), CBlock_ln(16, drop_path=0.05), CBlock_ln(16, drop_path=0.1)]
blocks2 = [CBlock_ln(16, drop_path=0.01), CBlock_ln(16, drop_path=0.05), CBlock_ln(16, drop_path=0.1)]
elif type == 'ttt':
blocks1, blocks2 = [block_t for _ in range(number)], [block_t for _ in range(number)]
elif type == 'cct':
blocks1, blocks2 = [block, block, block_t], [block, block, block_t]
# block1 = [CBlock_ln(16), nn.Conv2d(16,24,3,1,1)]
self.mul_blocks = nn.Sequential(*blocks1, nn.Conv2d(dim, 3, 3, 1, 1), nn.ReLU())
self.add_blocks = nn.Sequential(*blocks2, nn.Conv2d(dim, 3, 3, 1, 1), nn.Tanh())
def forward(self, img):
img1 = self.relu(self.conv1(img))
mul = self.mul_blocks(img1)
add = self.add_blocks(img1)
return mul, add
# Short Cut Connection on Final Layer
class Local_pred_S(nn.Module):
def __init__(self, in_dim=3, dim=16, number=4, type='ccc'):
super(Local_pred_S, self).__init__()
# initial convolution
self.conv1 = nn.Conv2d(in_dim, dim, 3, padding=1, groups=1)
self.relu = nn.LeakyReLU(negative_slope=0.2, inplace=True)
# main blocks
block = CBlock_ln(dim)
block_t = SwinTransformerBlock(dim) # head number
if type == 'ccc':
blocks1 = [CBlock_ln(16, drop_path=0.01), CBlock_ln(16, drop_path=0.05), CBlock_ln(16, drop_path=0.1)]
blocks2 = [CBlock_ln(16, drop_path=0.01), CBlock_ln(16, drop_path=0.05), CBlock_ln(16, drop_path=0.1)]
elif type == 'ttt':
blocks1, blocks2 = [block_t for _ in range(number)], [block_t for _ in range(number)]
elif type == 'cct':
blocks1, blocks2 = [block, block, block_t], [block, block, block_t]
# block1 = [CBlock_ln(16), nn.Conv2d(16,24,3,1,1)]
self.mul_blocks = nn.Sequential(*blocks1)
self.add_blocks = nn.Sequential(*blocks2)
self.mul_end = nn.Sequential(nn.Conv2d(dim, 3, 3, 1, 1), nn.ReLU())
self.add_end = nn.Sequential(nn.Conv2d(dim, 3, 3, 1, 1), nn.Tanh())
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, img):
img1 = self.relu(self.conv1(img))
# short cut connection
mul = self.mul_blocks(img1) + img1
add = self.add_blocks(img1) + img1
mul = self.mul_end(mul)
add = self.add_end(add)
return mul, add
class IAT(nn.Module):
def __init__(self, in_dim=3, with_global=True, type='lol'):
super(IAT, self).__init__()
# self.local_net = Local_pred()
self.local_net = Local_pred_S(in_dim=in_dim)
self.with_global = with_global
if self.with_global:
self.global_net = Global_pred(in_channels=in_dim, type=type)
def apply_color(self, image, ccm):
shape = image.shape
image = image.view(-1, 3)
image = torch.tensordot(image, ccm, dims=[[-1], [-1]])
image = image.view(shape)
return torch.clamp(image, 1e-8, 1.0)
def forward(self, img_low):
# print(self.with_global)
mul, add = self.local_net(img_low)
img_high = (img_low.mul(mul)).add(add)
if not self.with_global:
return img_high
else:
gamma, color = self.global_net(img_low)
b = img_high.shape[0]
img_high = img_high.permute(0, 2, 3, 1) # (B,C,H,W) -- (B,H,W,C)
img_high = torch.stack(
[self.apply_color(img_high[i, :, :, :], color[i, :, :]) ** gamma[i, :] for i in range(b)], dim=0)
img_high = img_high.permute(0, 3, 1, 2) # (B,H,W,C) -- (B,C,H,W)
return img_high
if __name__ == "__main__":
img = torch.Tensor(1, 3, 640, 640)
net = IAT()
imghigh = net(img)
print(imghigh.size())
print('total parameters:', sum(param.numel() for param in net.parameters()))
_, _, high = net(img)
四、手把手教你添加IAT低照度图像增强网络
4.1 修改一
第一还是建立文件,我们找到如下ultralytics/nn/modules文件夹下建立一个目录名字呢就是'Addmodules'文件夹(用群内的文件的话已经有了无需新建)!然后在其内部建立一个新的py文件将核心代码复制粘贴进去即可。

4.2 修改二
第二步我们在该目录下创建一个新的py文件名字为'__init__.py'(用群内的文件的话已经有了无需新建),然后在其内部导入我们的检测头如下图所示。
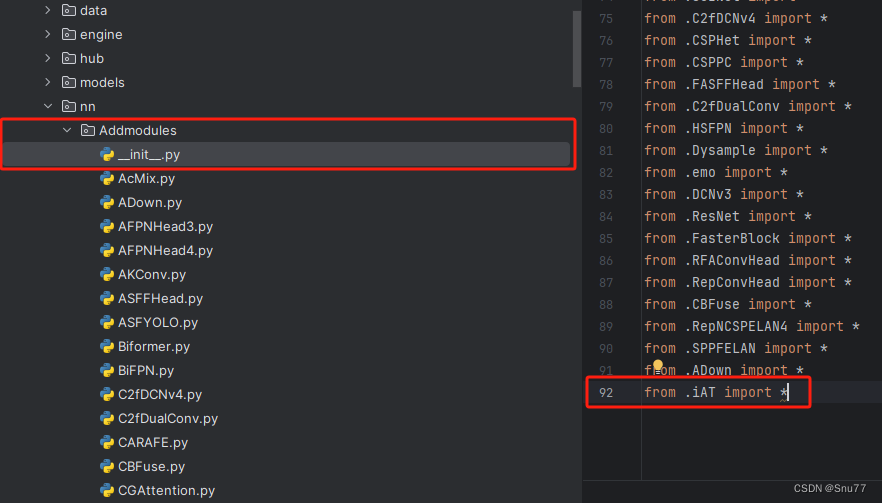
4.3 修改三
第三步我门中到如下文件'ultralytics/nn/tasks.py'进行导入和注册我们的模块(用群内的文件的话已经有了无需重新导入直接开始第四步即可)!
从今天开始以后的教程就都统一成这个样子了,因为我默认大家用了我群内的文件来进行修改!!
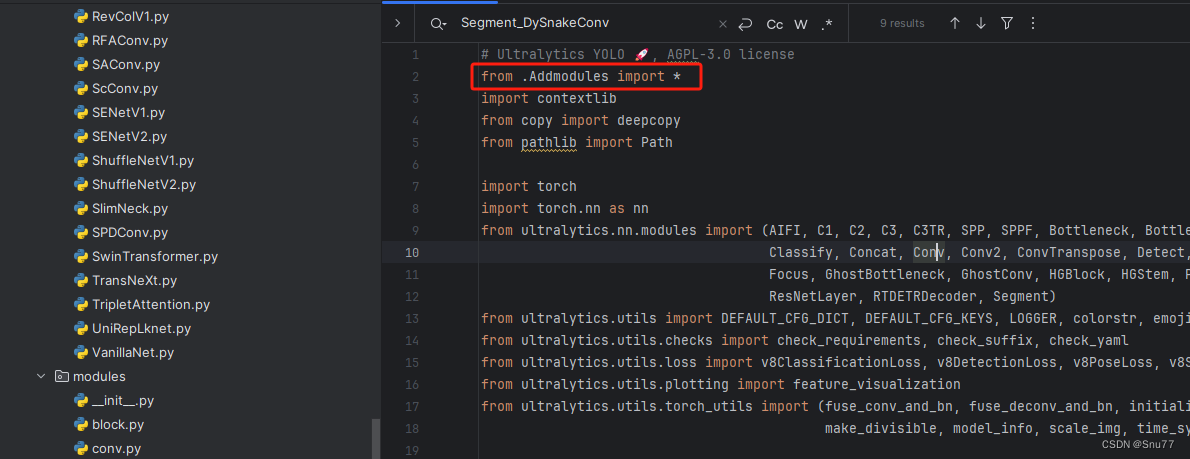
4.4 修改四
按照我的添加在parse_model里添加即可,红框内的添加即可,没有的都是其它文章里的改进机制。

到此就修改完成了,大家可以复制下面的yaml文件运行。
五、IAT的yaml文件和运行记录
5.1 IAT的yaml文件
主干和Neck全部用上该卷积轻量化到机制的yaml文件。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, IAT, []] # 0-P1/2
- [-1, 1, Conv, [64, 3, 2]] # 1-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 2-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 4-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 6-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 8-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 7], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 5], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
5.2 训练代码
大家可以创建一个py文件将我给的代码复制粘贴进去,配置好自己的文件路径即可运行。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/v8/yolov8-C2f-FasterBlock.yaml')
# model.load('yolov8n.pt') # loading pretrain weights
model.train(data=r'替换数据集yaml文件地址',
# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, pose
cache=False,
imgsz=640,
epochs=150,
single_cls=False, # 是否是单类别检测
batch=4,
close_mosaic=10,
workers=0,
device='0',
optimizer='SGD', # using SGD
# resume='', # 如过想续训就设置last.pt的地址
amp=False, # 如果出现训练损失为Nan可以关闭amp
project='runs/train',
name='exp',
)5.3 IAT的训练过程截图
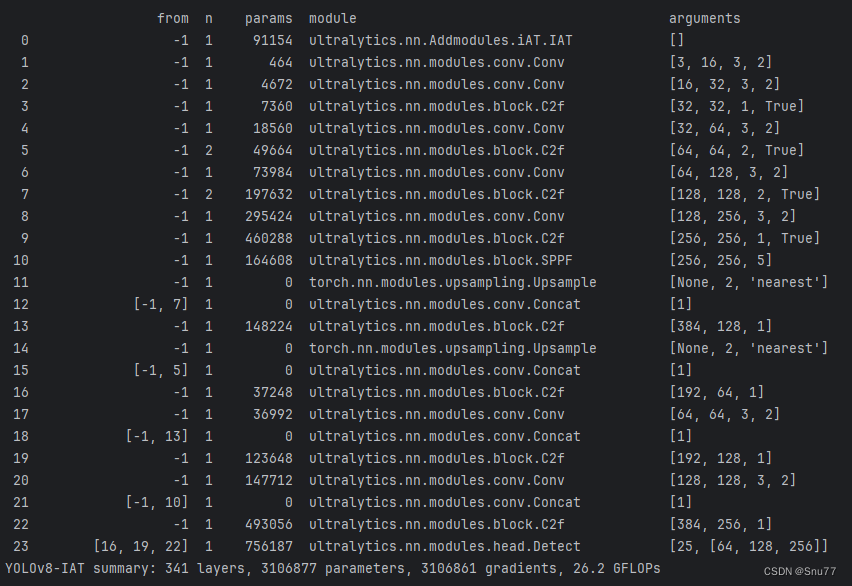
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv8改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏目录:YOLOv8改进有效系列目录 | 包含卷积、主干、检测头、注意力机制、Neck上百种创新机制