文件遍历
在Python中,遍历文件通常指的是逐行读取文件中的内容。这种方式对于处理大型文件特别有用,因为它不需要一次性将整个文件加载到内存中。下面是几种常见的遍历文件内容的方法:
1. 使用with语句和for循环
这是最推荐的方式,因为它会自动管理文件资源,并且代码可读性高。
file_path = 'example.txt'
with open(file_path, 'r') as file:
for line in file:
print(line.strip()) # 使用strip()去除每行末尾的换行符
2. 使用readline()方法
如果你想更细致地控制读取过程(例如,在某些条件下提前停止),可以使用readline()方法逐行读取。
file_path = 'example.txt'
with open(file_path, 'r') as file:
while True:
line = file.readline()
if not line: # 如果readline返回空字符串,则表示已到达文件末尾
break
print(line.strip())
3. 使用readlines()方法
虽然这个方法不是真正意义上的“遍历”(因为它会先读取整个文件到一个列表中),但如果你需要获取所有行并且内存足够大时,这也是一个方便快捷的选择。
file_path = 'example.txt'
with open(file_path, 'r') as file:
lines = file.readlines()
for line in lines:
print(line.strip())
请注意,对于非常大的文件,第三种方法可能会消耗大量内存。通常情况下,第一种使用迭代器直接遍历文件对象的方式最为高效和优雅。
遍历二进制文件
如果你正在处理二进制数据(如图片或视频等),可能需要以块(block)来遍历:
file_path = './data/test_pic.png'
# 复制文件到另一个文件
file_copy = open('./data/test_pic_copy.png', 'wb')
with open(file_path, 'rb') as file: # 注意模式为'rb'表示二进制模式读取
while True:
chunk = file.read(1024) # 每次读取1024字节
if not chunk:
break
# 处理chunk...
file_copy.write(chunk)
file_copy.close()
在处理文本或二进制数据时选择正确的遍历方式对于编写高效、可维护代码至关重要。
常用方法
当你使用open()函数打开一个文件后,会得到一个文件对象。这个文件对象提供了多种方法来帮助你读取、写入和操作文件。以下是一些常用的方法:
1. read(size=-1)
- 读取并返回文件中最多
size个字符(文本模式)或字节(二进制模式)。如果未指定size或指定为负数,则读取并返回整个文件。
with open('example.txt', 'r') as file:
content = file.read()
print(content)
2. readline(size=-1)
- 读取直到遇到下一个换行符为止,并返回一行字符串。如果指定了
size,则在达到size字符后停止。
with open('example.txt', 'r') as file:
while True:
line = file.readline()
if not line:
break
print(line.strip())
3. readlines(hint=-1)
- 读取并返回一个列表,其中包含文件中的行。如果提供了可选参数hint,则当读取的行数足够接近hint时停止。
with open('example.txt', 'r') as file:
lines = file.readlines()
for line in lines:
print(line.strip())
4. write(string)
- 将字符串写入文件,并返回写入的字符数(文本模式)或字节数(二进制模式)。
with open('output.txt', 'w') as file:
num_chars = file.write("Hello, World!")
print(f"Written {num_chars} characters.")
5. writelines(lines)
- 向文件写入一个字符串列表。此方法不会自动添加行结束符,因此如果需要,必须自己在每行末尾加上
\n。
lines = ["First line", "Second line", "Third line"]
with open('output.txt', 'w') as file:
# 如果需要,在每行末尾加上\n来实现换行。
lines_with_newlines = [f"{line}\n" for line in lines]
file.writelines(lines_with_newlines)
6. seek(offset, whence=0) 和 tell()
- seek() 改变当前文件操作位置。offset表示相对于whence位置的偏移量:0表示从文件开头计算(默认),1表示从当前位置计算,2表示从文件末尾计算。
- tell() 返回当前在文件中的位置。
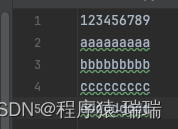
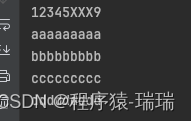
# 读取文件,将第5个字节替换为'XXX'
with open('./data/test22.txt', 'rb+') as file: # 使用二进制模式作为示例
# 移动到第五个字节(索引从0开始)
file.seek(5)
# 报告当前位置
current_position = file.tell()
print(f"Current position: {current_position}")
# 修改当前位置的内容,并回到起始位置查看更改。
# 注意:在文本模式下修改可能会因编码问题导致错误。
new_content = b'XXX' # 替换为三个字节的内容
old_content = file.read(len(new_content))
if old_content != new_content:
# 回退字节以覆盖刚才读取的内容。
seek_back = file.seek(-len(new_content), 1) # 1表示当前位置
write_byte = file.write(new_content)
seek_start = file.seek(0)
updated_content = file.read().decode("utf-8")
print(updated_content)
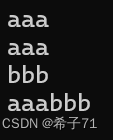
原文件:
执行后:
7. flush()
- 刷新内部缓冲区,将数据立即写入磁盘而不是等待自动刷新发生。这对于长时间运行且需要即时保存结果的程序很有用。
# 这里perform_event_processing是假定存在的处理事件函数,
# 实际使用时应替换为具体逻辑代码块或函数调用。
import threading
def perform_event_processing():
# 当前线程休眠3秒,模拟事件处理耗时
threading.Event().wait(1000)
print("Event processing started.")
# 假设我们正在记录一些重要事件,希望确保即使程序崩溃也能保存日志信息。
log_file_path = './data/test_log_example.log'
event_log = open(log_file_path, 'a')
try:
event_log.write("Event started.\n")
# 注释掉下面这行代码,以观察不同,在线程休眠期间,日志是否会被写入文件
event_log.flush()
perform_event_processing()
except Exception as e:
event_log.write(f"Error occurred: {e}\n")
finally:
event_log.close()
print("Event processing simulated.")
需求练习
示例文本文件
在Python中,文件操作主要涉及打开、读取、写入和关闭文件。
这是一门基础且重要的技能,因为它使得程序能够持久化数据,或者处理磁盘上的数据文件。
Python提供了一个内建的open函数用于文件的打开,以及文件对象提供的方法用于读取和写入。
使用open函数打开文件时,可以指定文件的路径和模式。模式指定了文件是用于读取、写入还是追加,以及文件是文本模式还是二进制模式。
初步实现
打开一个文本文件,将其中的’文件’字符替换为’文档’
with open('./data/test23.txt', 'r+') as file:
text = file.read()
replace_text = text.replace("文件", "文档")
# 将当前操作位置移动到文件开头。这一步是必须的,因为在之前已经通过 .read() 方法将指针移动到了文件末尾。如果不重新定位到开始位置,接下来写入时会直接从末尾开始添加内容。
file.seek(0)
file.write(replace_text)
# 防止替换后的文本比原始文本短,则新内容之后可能会保留旧数据残余部分。truncate 可以截断多余部分。
file.truncate()
结果

注意
- 这种方式在处理大型文本时可能不够高效,因为它一次性加载整个文本进内存。
- 由于使用了’r+'模式,在不存在指定路径或者无法找到相应名称(
test23.txt)时会抛出错误而非创建新文件。
改进实现
当处理大型文件时,一次性读取整个文件到内存确实可能导致效率低下甚至内存溢出。为了解决这个问题,可以采用分批处理的方法,逐行(或按一定大小的块)读取和写入文件。这样可以大大减少内存的使用。以下是一种改进方法,适用于逐行处理文本文件的场景:
分批处理替换文本
由于直接在原文件上进行逐行读写可能会复杂且易出错(特别是当替换后的文本长度与原文不同时),建议的方法是将修改后的内容写入一个临时文件,处理完成后再替换原文件。
import os
source_file_path = './data/test23.txt'
temp_file_path = './data/test23_temp.txt'
with open(source_file_path, 'r', encoding='utf-8') as read_file, \
open(temp_file_path, 'w', encoding='utf-8') as write_file:
for line in read_file:
modified_line = line.replace("文件", "文档")
write_file.write(modified_line)
# Replace the original file with the modified one
os.replace(temp_file_path, source_file_path)
解决方案解析
-
逐行读取:通过在
with语句中同时打开源文件(用于读取)和临时文件(用于写入),可以逐行对源文件进行读取。这样就不需要一次性将整个文件内容加载到内存中。 -
逐行替换和写入:对于源文件的每一行,执行所需的替换操作,然后将结果写入临时文件。这个过程中,内存中仅需存储当前处理的行。
-
替换原文件:处理完成后,使用
os.replace()方法将临时文件替换原文件。这个操作会自动删除原文件,并将临时文件重命名为原文件的名称。
注意事项
- 这种方法适用于文本文件的逐行处理,可以有效减少内存消耗,特别是处理大文件时。
- 完成替换操作后,原文件将被临时文件替代。确保在操作前做好相应的备份,以防数据丢失。
- 如果处理过程中出现错误,可能需要手动清理临时文件或采取其他错误处理措施。
- 对于更复杂的替换逻辑或大型二进制文件的处理,可能需要采用不同的策略。





![[项目设计] 从零实现的高并发内存池(五)](https://img-blog.csdnimg.cn/c446ebae288e480d84f5d14d494c88bb.gif)