🎉🎉欢迎光临,终于等到你啦🎉🎉
🏅我是苏泽,一位对技术充满热情的探索者和分享者。🚀🚀
🌟持续更新的专栏《Spring 狂野之旅:从入门到入魔》 🚀
本专栏带你从Spring入门到入魔
这是苏泽的个人主页可以看到我其他的内容哦👇👇
努力的苏泽![]() http://suzee.blog.csdn.net/
http://suzee.blog.csdn.net/
Spring Batch的应用场景和作用
批处理是企业级业务系统不可或缺的一部分,spring batch是一个轻量级的综合性批处理框架,可用于开发企业信息系统中那些至关重要的数据批量处理业务.SpringBatch基于POJO和Spring框架,相当容易上手使用,让开发者很容易地访问和利用企业级服务.spring batch具有高可扩展性的框架,简单的批处理,复杂的大数据批处理作业都可以通过SpringBatch框架来实现。
先来个例子
假设一家电商公司,每天从不同渠道收集大量的销售数据。这些数据包含了各种商品的销售记录,但是格式和质量可能不一致。您希望将这些销售数据进行清洗和转换,以便进行后续的分析和报告生成。
使用Spring Batch,可以创建一个批处理作业来处理销售数据。作业的步骤可以包括从不同渠道读取销售数据,对数据进行清洗和转换,例如去除无效数据、修复格式错误、计算额外的指标等。然后,将清洗和转换后的数据写入数据库,以备后续的分析和报告生成使用。
先来介绍其架构
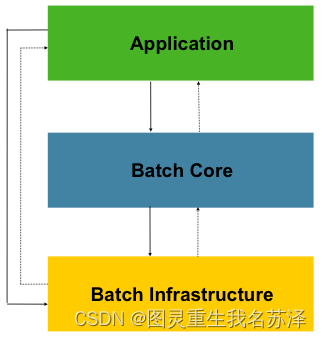
Application应用层:包含了所有任务batch jobs和开发人员自定义的代码,主要是根据项目需要开发的业务流程等。Batch Core核心层:包含启动和管理任务的运行环境类,如JobLauncher等。Batch Infrastructure基础层:上面两层是建立在基础层之上的,包含基础的读入reader和写出writer、重试框架等。
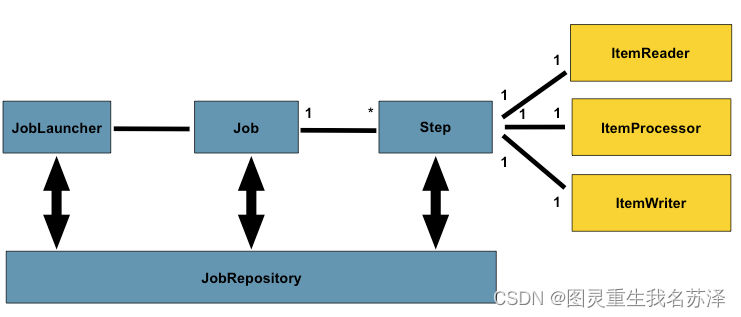
为什么它能够如此优秀?
Chunk 的中文意思是:大块、厚块;大部分,大量。Chunk 在Spring Batch 中就是“批量操作”的概念的抽象。它本身是一个类,这个类就是用来将原本的单条操作改成批量进行。
在Spring Batch 中就提出了chunk 的概念。首先我们设定一个chunk 的size,随后Spring Batch 一条条地区处理数据,但是到ItemWriter 阶段,Spirng Batch 不会选择立刻将数据提交到数据库,只有在处理的数据累积数量达到了之前设置的chunk 的size 之后,才会进行提交操作。
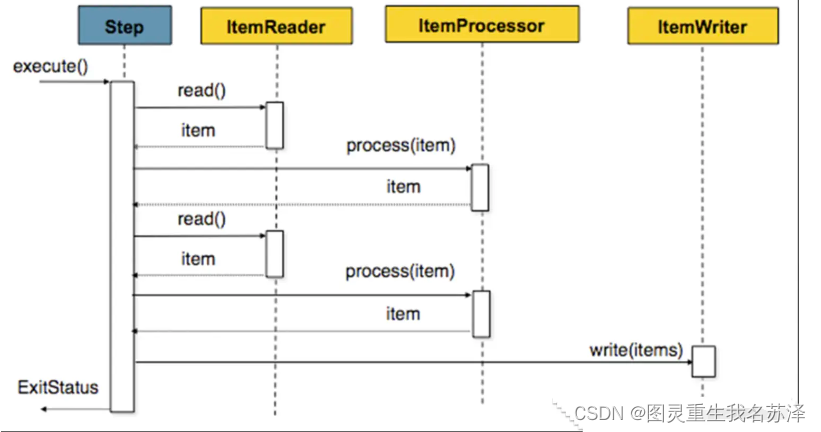
实战详细操作
引入 依赖
首先,引Spring Batch的依赖项。在Maven项目中,在pom.xml文件中添加以下依赖项:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
</dependencies>创建一个Spring配置文件(例如batch-config.xml),并配置Spring Batch的相关组件和属性。
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:task="http://www.springframework.org/schema/task"
xmlns:util="http://www.springframework.org/schema/util"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd
http://www.springframework.org/schema/util http://www.springframework.org/schema/util/spring-util.xsd">
<!-- 数据源配置 -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver" />
<property name="url" value="jdbc:mysql://localhost:3306/mydb" />
<property name="username" value="root" />
<property name="password" value="password" />
</bean>
<!-- JobRepository配置 -->
<bean id="jobRepository" class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="transactionManager" ref="transactionManager" />
<property name="databaseType" value="mysql" />
</bean>
<!-- 并发任务执行器配置 -->
<task:executor id="taskExecutor" pool-size="10" />
<!-- 事务管理器配置 -->
<bean id="transactionManager" class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<!-- JobLauncher配置 -->
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
<property name="taskExecutor" ref="taskExecutor" />
</bean>
</beans>定义数据模型:
根据需求,定义需要清洗和转换的数据模型。例如,假设数据模型是一个简单的用户对象,包含id、姓名和年龄字段。创建一个名为User的Java类,如下所示:
public class User {
private Long id;
private String name;
private Integer age;
// 省略构造函数、getter和setter方法
}创建ItemReader:
创建一个实现ItemReader接口的自定义类,用于从数据源中读取数据。以下是一个读取数据库中用户数据的示例:
public class UserItemReader implements ItemReader<User> {
private JdbcTemplate jdbcTemplate;
private int rowCount = 0;
private int currentRow = 0;
public UserItemReader(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public User read() throws Exception {
if (currentRow < rowCount) {
String sql = "SELECT id, name, age FROM users LIMIT ?, 1";
User user = jdbcTemplate.queryForObject(sql, new Object[]{currentRow}, (rs, rowNum) -> {
User u = new User();
u.setId(rs.getLong("id"));
u.setName(rs.getString("name"));
u.setAge(rs.getInt("age"));
return u;
});
currentRow++;
return user;
} else {
return null;
}
}
public void setRowCount(int rowCount) {
this.rowCount = rowCount;
}
}在此示例中,我们使用JdbcTemplate来执行数据库查询,并在read方法中逐行读取用户数据。
这里就可以根据你的业务需求设置各种各样的任务
创建ItemProcessor:
创建一个实现ItemProcessor接口的自定义类,用于对读取的数据进行清洗和转换。
temProcessor的作用是在Spring Batch的批处理作业中对读取的数据进行处理、清洗和转换。它是Spring Batch框架中的一个关键接口,用于执行中间处理逻辑,并将处理后的数据传递给ItemWriter进行写入操作。
以下是一个对用户数据进行简单处理的示例:
public class UserProcessor implements ItemProcessor<UserData, ProcessedUserData> {
@Override
public ProcessedUserData process(UserData userData) throws Exception {
// 获取用户数据
String input = userData.getData();
// 去除首尾空格
String trimmedInput = input.trim();
// 过滤敏感信息
String filteredInput = filterSensitiveData(trimmedInput);
// 转换为大写
String upperCaseInput = filteredInput.toUpperCase();
// 创建处理后的用户数据对象
ProcessedUserData processedUserData = new ProcessedUserData();
processedUserData.setProcessedData(upperCaseInput);
return processedUserData;
}
private String filterSensitiveData(String input) {
// 在这里可以根据实际需求实现敏感信息过滤逻辑
// 使用正则表达式、敏感词库或其他方法进行过滤
// 这里是过滤手机号码和邮箱地址
String filteredInput = input
.replaceAll("\\b\\d{11}\\b", "[PHONE_NUMBER]")
.replaceAll("\\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}\\b", "[EMAIL]");
return filteredInput;
}
}我们做了以下处理和转换:
- 使用
trim方法去除用户数据字符串首尾的空格。- 使用
filterSensitiveData方法过滤敏感信息,例如手机号码和邮箱地址。在示例中,我们使用了简单的正则表达式来过滤手机号码和邮箱地址,并将其替换为占位符。- 使用
toUpperCase方法将字符串转换为大写形式。- 创建一个
ProcessedUserData对象,将处理后的数据设置到输出对象中。
创建ItemWriter:
创建一个实现ItemWriter接口的自定义类,用于将处理后的数据写入目标位置。以下是一个将用户数据写入数据库的示例:
public class UserItemWriter implements ItemWriter<User> {
private JdbcTemplate jdbcTemplate;
public UserItemWriter(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public void write(List<? extends User> users) throws Exception {
for (User user : users) {
String sql = "INSERT INTO processed_users (id, name, age) VALUES (?, ?, ?)";
jdbcTemplate.update(sql, user.getId(), user.getName(), user.getAge());
}
}
}在此示例中,我们使用JdbcTemplate将处理后的用户数据插入到名为processed_users的数据库表中。
创建作业配置:
创建一个包含作业配置的类,用于将ItemReader、ItemProcessor和ItemWriter组合在一起,定义一个批处理作业。以下是一个示例的作业配置类:
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Autowired
private DataSource dataSource;
@Bean
public ItemReader<User> userItemReader() {
return new UserItemReader(dataSource);
}
@Bean
public ItemProcessor<User, User> userItemProcessor() {
return new UserItemProcessor();
}
@Bean
public ItemWriter<User> userItemWriter() {
return new UserItemWriter(dataSource);
}
@Bean
public Step step1(ItemReader<User> reader, ItemProcessor<User, User> processor, ItemWriter<User> writer) {
return stepBuilderFactory.get("step1")
.<User, User>chunk(10)
.reader(reader)
.processor(processor)
.writer(writer)
.build();
}
@Bean
public Job dataCleanupJob(Step step1) {
return jobBuilderFactory.get("dataCleanupJob")
.incrementer(new RunIdIncrementer())
.flow(step1)
.end()
.build();
}
}在此示例中,我们通过Spring Batch的注解@EnableBatchProcessing启用批处理功能,并定义了一个名为dataCleanupJob的作业,其中包含一个名为step1的步骤。
运行作业:
创建Job和Step配置:使用Spring Batch的配置文件,配置Job和Step。使用JobParametersBuilder创建一个包含当前时间戳的Job参数,然后通过jobLauncher.run()方法启动作业。
import org.springframework.batch.core.Job;
import org.springframework.batch.core.JobParameters;
import org.springframework.batch.core.JobParametersBuilder;
import org.springframework.batch.core.launch.JobLauncher;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class BatchApplication {
public static void main(String[] args) {
// 创建Spring应用上下文
ApplicationContext context = new AnnotationConfigApplicationContext(BatchConfiguration.class);
// 获取JobLauncher和Job实例
JobLauncher jobLauncher = context.getBean(JobLauncher.class);
Job job = context.getBean("dataCleanupJob", Job.class);
try {
// 创建Job参数
JobParameters jobParameters = new JobParametersBuilder()
.addLong("time", System.currentTimeMillis())
.toJobParameters();
// 启动作业
jobLauncher.run(job, jobParameters);
} catch (Exception e) {
e.printStackTrace();
}
}
}监听Listener
可以通过Listener接口对特定事件进行监听,以实现更多业务功能。比如如果处理失败,就记录一条失败日志;处理完成,就通知下游拿数据等。
import org.springframework.batch.core.*;
import org.springframework.batch.core.listener.JobExecutionListenerSupport;
public class MyJobListener extends JobExecutionListenerSupport {
@Override
public void beforeJob(JobExecution jobExecution) {
// 在作业执行之前执行的逻辑
System.out.println("作业开始执行");
}
@Override
public void afterJob(JobExecution jobExecution) {
// 在作业执行之后执行的逻辑
if (jobExecution.getStatus() == BatchStatus.COMPLETED) {
System.out.println("作业执行成功");
} else if (jobExecution.getStatus() == BatchStatus.FAILED) {
System.out.println("作业执行失败");
}
}
@Override
public void onSkipInRead(Throwable t) {
// 在读取过程中发生跳过记录的逻辑
System.out.println("跳过读取记录");
}
@Override
public void onSkipInProcess(Object item, Throwable t) {
// 在处理过程中发生跳过记录的逻辑
System.out.println("跳过处理记录");
}
@Override
public void onSkipInWrite(Object item, Throwable t) {
// 在写入过程中发生跳过记录的逻辑
System.out.println("跳过写入记录");
}
}将这个自定义的监听器添加到作业配置中:
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
// 省略其他配置
@Bean
public Job dataCleanupJob(Step step1, JobExecutionListener jobListener) {
return jobBuilderFactory.get("dataCleanupJob")
.incrementer(new RunIdIncrementer())
.listener(jobListener) // 添加自定义的监听器
.flow(step1)
.end()
.build();
}
@Bean
public JobExecutionListener jobListener() {
return new MyJobListener();
}
// 省略其他配置
}这样 我们就能很清晰的看到 任务运行的情况啦
Spring Batch 使用内存缓冲机制,将读取的数据记录暂存于内存中,然后批量处理这些数据。通过减少对磁盘或数据库的频繁访问,内存缓冲可以提高读取和处理的效率,而且Spring Batch 提供了批量读取的机制,允许一次性读取和处理多个数据记录,这两点都减轻 I/O 压力。