Java 中常用的容器有哪些?
ArrayList 和 LinkedList 的区别?
ArrayList 是基于数组实现的,LinkedList 是基于链表实现的.
ArrayList实现了RandomAccess接口,可基于下标访问.
LinkedList 实现了Deque /dek/,可以当做双端队列使用.
插入效率对比
如果从头部插入,LinkedList更快
如果从中间插入ArrayList更快
如果从尾部插入,在不扩容的情况下ArrayList略快,扩容次数多时LinkedList更快
get(int index) ArrayList更快
遍历ArrayList更快
ArrayList新循环(迭代器)和普通循环遍历效率差不多
LinkedList 新循环(迭代器)比普通循环效率高很多(每次get(int index)都要找一次)
从头开始插
public static void addFromHeaderTest4ArrayList(int num) {
ArrayList<String> list = new ArrayList<>(num);
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.add(0, i + "王大锤");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("ArrayList从集合头部位置新增元素花费的时间" + (timeEnd - timeStart));
}
public static void addFromHeaderTest4LinkedList(int num) {
LinkedList<String> list = new LinkedList<String>();
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.addFirst(i + "王大锤");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("LinkedList从集合头部位置新增元素花费的时间" + (timeEnd - timeStart));
}
ArrayList从集合头部位置新增元素花费的时间415
LinkedList从集合头部位置新增元素花费的时间12
从中间开始插
public static void addFromMidTest4ArrayList(int num) {
ArrayList<String> list = new ArrayList<>(num);
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
int temp = list.size();
list.add(temp / 2 + "王大锤");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("ArrayList从集合中间位置新增元素花费的时间" + (timeEnd - timeStart));
}
public static void addFromMidTest4LinkedList(int num) {
LinkedList<String> list = new LinkedList<>();
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
int temp = list.size();
list.add(temp / 2, i + "王大锤");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("LinkedList从集合中间位置新增元素花费的时间" + (timeEnd - timeStart));
}
ArrayList从集合中间位置新增元素花费的时间19
LinkedList从集合中间位置新增元素花费的时间28610
从尾部开始插
public static void addFromTailTest4ArrayList(int num) {
ArrayList<String> list = new ArrayList<>(num);
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.add(i + "王大锤");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("ArrayList从集合尾部位置新增元素花费的时间" + (timeEnd - timeStart));
}
public static void addFromTailTest4LinkedList(int num) {
LinkedList<String> list = new LinkedList<>();
int i = 0;
long timeStart = System.currentTimeMillis();
while (i < num) {
list.add(i + "王大锤");
i++;
}
long timeEnd = System.currentTimeMillis();
System.out.println("LinkedList从集合尾部位置新增元素花费的时间" + (timeEnd - timeStart));
}
ArrayList从集合尾部位置新增元素花费的时间17
LinkedList从集合尾部位置新增元素花费的时间13
遍历
/**
* 10000000
* arrayList遍历耗时:50
* linkedList遍历耗时:172
*/
private static void extracted7() {
int count = 10000000;
List<String> arrayList = new ArrayList<>();
List<String> linkedList = new LinkedList<>();
for (int i = 0; i < count; i++) {
arrayList.add("lxw" + i);
linkedList.add("lxw" + i);
}
long startA = System.currentTimeMillis();
for (String s : arrayList) {
}
long endA = System.currentTimeMillis();
for (String s : linkedList) {
}
long endL = System.currentTimeMillis();
System.out.println("arrayList通过新循环遍历耗时:" + (endA - startA));
System.out.println("linkedList通过新循环遍历耗时:" + (endL - endA));
}
ArrayList添加元素流程
list.add(Object e)
- 先判断是否需要扩容,如果需要则扩容
minCapacity = size+要添加元素的个数 add(e) 为1, addAll(sublist) 为sublist.size()
minCapacity > elementData.length - 通过索引将元素添加到末尾
elementData[size++] = e
list.add(int index, Object e) 性能比较差
- 检查插入的位置是否在合理的范围之内
不合理( index > size || index < 0)则抛异常IndexOutOfBoundsException - 先判断是否需要扩容,如果需要则进行扩容
- 把index以及之后的元素复制到index之后
System.arraycopy(elementData, index, elementData, index + 1,size - index); - 将新元素添加到index位置
elementData[index] = e
LinkedList 添加元素流程
list.add(Object e)
直接将元素添加到队尾
list.add(int index, Object e)
- 检查插入的位置是否在合理的范围之内
index >= 0 && index <= size
-
如果插入的位置是队尾,则尾插
-
如果不是队尾, 寻找元素 Node node(int index) 如果index < (size >> 1) 从头开始找,否则从末尾往前找(size >> 1 size的一半向下取整)
-
将e连接到node前面
ArrayList 实现 RandomAccess 接口有何作用?为何 LinkedList 却没实现这个接口?
ArrayList 的扩容机制?
minCapacity=size+要添加元素的个数(add(E e)与addAll(Collection<? extends E> c))
扩容条件 minCapacity>elementData.length
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩容1.5倍(向下取整)
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 扩容后新容量还存不下 list.addAll(subList) 原始容量 10 扩容后newCapacity = 15 minCapacity = 100
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
Array 和 ArrayList 有何区别?什么时候更适合用 Array?
-
Array:申明数组的时候就要初始化并确定长度,长度不可变,而且它只能存储同一类型的数据,(Array可以存储基本类型)只对外提供了一个length属性.
-
ArrayList 是基于Array实现的可以动态扩容的集合类,提供了更丰富的方法.ArrayList 不能存储基本类型(包装类)
-
当能确定长度并且数据类型一致的时候就可以用数组,其他时候使用ArrayList
HashMap 的实现原理/底层数据结构?JDK1.7 和 JDK1.8
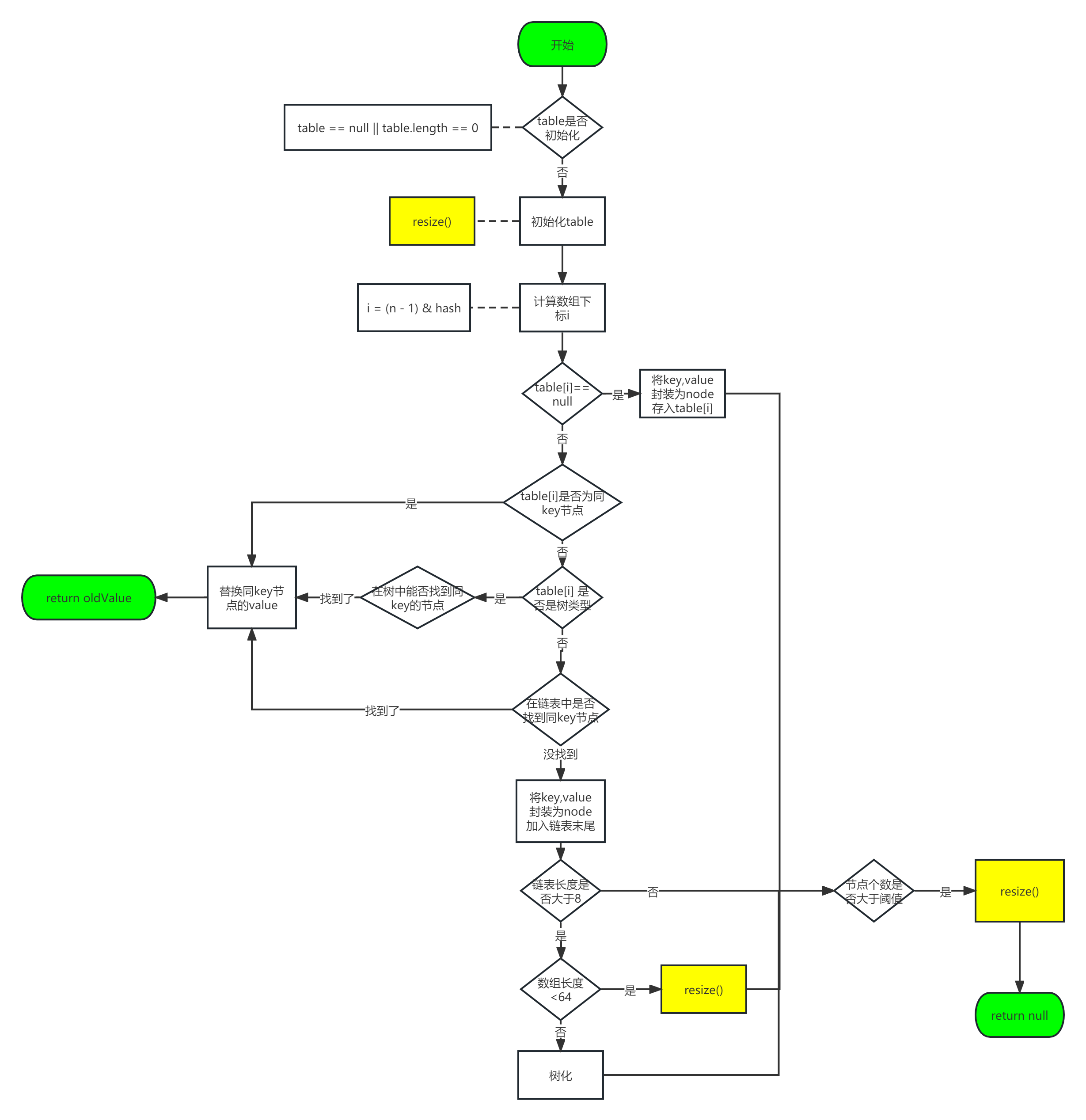
HashMap 的 put 方法的执行过程?
HashMap 的 get 方法的执行过程?
HashMap 的 resize 方法的执行过程?
/**
* 1.计算新容量
* 2.计算新阈值
* 3.根据新容量创建新数组,并将新数组赋值给table
* 4.将老数组中的元素转移到新数组
*/
final HashMap.Node<K, V>[] resize() {
HashMap.Node<K, V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
// 不再扩容,修改阈值
threshold = Integer.MAX_VALUE;
return oldTab;
} else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
} else if (oldThr > 0) // initial capacity was placed in threshold 初始化容量被临时存储在阈值里面了
// 指定容量的情况 会初始化阈值 临时将容量存到阈值里, 否则没法区分是初始化扩容还是初始化后的扩容
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int) (DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float) newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float) MAXIMUM_CAPACITY ?(int) ft : Integer.MAX_VALUE);
}
// 给新阈值赋值
threshold = newThr;
@SuppressWarnings({"rawtypes", "unchecked"})
// 创建新数组
HashMap.Node<K, V>[] newTab = (HashMap.Node<K, V>[]) new HashMap.Node[newCap];
// 重新给table赋值
table = newTab;
// 将oldTab里面的元素赋值给tab
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
HashMap.Node<K, V> e;
if ((e = oldTab[j]) != null) {
// 转移 类似于剪贴
oldTab[j] = null;
// hash桶中只有一个元素
if (e.next == null)
// 相当于rehash
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((HashMap.TreeNode<K, V>) e).split(this, newTab, j, oldCap);
else { // preserve order
// loHead 低位的头元素 loTail低位的为元素
HashMap.Node<K, V> loHead = null, loTail = null;
// hiHead高位的头元素 hiTail高位的尾元素
HashMap.Node<K, V> hiHead = null, hiTail = null;
//
HashMap.Node<K, V> next;
// 将原链表拆成2个子链表
do {
// 为了在while条件中用
next = e.next;
// (e.hash & oldCap) == 0 计算高低位
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
} else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 将低位链表复制给新数组的j位置
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 将高位链表赋值给新数组的j+oldCap
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
HashMap 的 size 为什么必须是 2 的整数次方?
为了利用&运算计算节点在数组中的下标
HashMap 多线程死循环问题?
HashMap 的 get 方法能否判断某个元素是否在 map 中?
不能,HashMap允许value为null,返回null无法区分是不存在还是value为null
HashMap 与 HashTable 的区别是什么?
1. HashTable 继承自 Dictionary 类实现了Map接口, HashMap 继承自AbstractMap实现了Map接口。
2. HashTable 是线程安全的,HashMap 不是。
3. HashMap允许将 null key和null value,而 Hashtable 不允许null key和null value。
4. HashMap 只有containsKey(Object key)和containsValue(Object value), Hashtable 额外提供了contains(Object value)( contains 方法容易让人引起误解)。
HashMap 与 ConcurrentHashMap 的区别是什么?
1. HashMap 线程不安全,ConcurrentHashMap 线程安全.
2. HashMap允许null key和null value,ConcurrentHashMap不允许null key和null value
HashTable 和 ConcurrentHashMap 的区别?
1. 底层数据结构: JDK1.7 的 ConcurrentHashMap 底层采用 分段数组+链表 实现,而 JDK1.8 的 ConcurrentHashMap 实现跟 HashMap1.8 的数据结构一样,都是 数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似,都是采用 数组+链表 的形式。数组是 HashMap 的主体,链表则是为了解决哈希冲突而存在的;
2. 实现线程安全的方式: ① 在 JDK1.7 的时候,ConcurrentHashMap(分段锁) 对整个桶数组进行了分割分段( Segment ),每一把锁只锁容器其中的一部分数据,这样多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高了并发访问率。 到了 JDK1.8,摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作,(JDK1.6 以后对 synchronized 锁做了很多的优化) 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② Hashtable (同一把锁) :使用 synchronized 来保证线程安全,效率非常低下。一个线程访问同步方法时,当其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程就不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈,效率就越低。
ConcurrentHashMap 的实现原理是什么?
- HashSet 的实现原理?
HashSet 怎么保证元素不重复的?
HashSet 保证元素不重复是利用HashMap 的put 方法实现的,在存储之前先根据key 的hashCode 和equals 判断是否已存在,如果存在就不在重复插入了,这样就保证了元素的不重复。
LinkedHashMap 的实现原理?
LinkedHashMap 继承自HashMap,重写了newNode,afterNodeAccess,afterNodeInsertion,afterNodeRemoval等方法.
在newNode方法中维护了双向链表
默认是插入属性,也可以通过LinkedHashMap(int initialCapacity, float loadFactor,boolean accessOrder)的accessOrder指定访问属性.
LinkedHashMap里并没有重写put方法,只是重写了put中调用的部分方法(模板方法模式)
Iterator 怎么使用?有什么特点?
Iterator 和 ListIterator 有什么区别?
ListIterator 继承自Iterator.
Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
Iterator对集合只能是单向移动前向遍历,ListIterator既可以前向也可以后向。
ListIterator 在迭代过程中不光可以删除元素,还能新增元素,修改元素.Iterator 只能删除元素
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("1");
list.add("2");
list.add("3");
ListIterator<String> listIterator = list.listIterator();
while (listIterator.hasPrevious()){
String previous = listIterator.previous();
System.out.println("previous = " + previous);
}
System.out.println("------------");
while (listIterator.hasNext()){
String next = listIterator.next();
if ("1".equals(next)) {
listIterator.set("11");
}
if ("2".equals(next)) {
listIterator.remove();
}
if ("3".equals(next)) {
listIterator.add("4");
}
System.out.println("next = " + next);
}
System.out.println("====================");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String next = iterator.next();
System.out.println("next = " + next);
}
}
-
Iterator 和 Enumeration 接口的区别?
-
fail-fast 与 fail-safe 有什么区别?
Collection 和 Collections 有什么区别?
Collection 是集合接口
Collections 是集合的工具类
https://zhuanlan.zhihu.com/p/92481037
-
table 的初始化时机是什么时候,初始化的 table.length 是多少、阀值(threshold)是多少,实际能容下多少元素
new HashMap<>() 初始化时机是第一次put元素的时候,table.length是16,threshold是12,时机能容下12个元素 -
什么时候触发扩容,扩容之后的 table.length、阀值各是多少?
第一次添加元素的时候(tab == null) tab.length<64 && 链表长度>8 ++size > threshold -
table 的 length 为什么是 2 的 n 次幂
为了利用&运算求key在数组中的下标 -
求索引的时候为什么是:h&(length-1),而不是 h&length,更不是 h%length
h%length 效率不如位运算快 h&length hash碰撞多,会导致 table 的空间得不到利用(有的桶里放了很多,有的桶里空着)、降低 table 的操作效率 h&(length-1) hash碰撞少 &右边为1或者连续的1时&左边的和=右边的相同(只要左边相对分散(由hash控制),结果就相对分散) 1&1=1; 0&1=0; 1&0=0; 0&0=0; 1010&1111=1010; => 10&15=10; 1011&1111=1011; => 11&15=11; 01010&10000=00000; => 10&16=0; 01011&10000=00000; => 11&16=0; 2^n-1 低位为连续的1,length刚好为2^n -
Map map = new HashMap(1000); 当我们存入多少个元素时会触发map的扩容; Map map1 = new HashMap(10000); 我们存入第 10001个元素时会触发 map1 扩容吗
Map map = new HashMap(1000); 当我们存入多少个元素时会触发map的扩容 此时的 table.length = 2^10 = 1024; threshold = 1024 * 0.75 = 768; 所以存入第 768 个元素时进行扩容 Map map1 = new HashMap(10000); 我们存入第 10001个元素时会触发 map1 扩容吗 此时的 table.length = 2^14 = 16384; threshold = 16384 * 0.75 = 12288; 所以存入第 10001 个元素时不会进行扩容 -
为什么加载因子的默认值是 0.75,并且不推荐我们修改
为什么加载因子的默认值是 0.75,并且不推荐我们修改 如果loadFactor太小,那么map中的table需要不断的扩容,扩容是个耗时的过程 如果loadFactor太大,那么map中table放满了也不不会扩容,导致冲突越来越多,解决冲突而起的链表越来越长,效率越来越低 而 0.75 这是一个折中的值,是一个比较理想的值