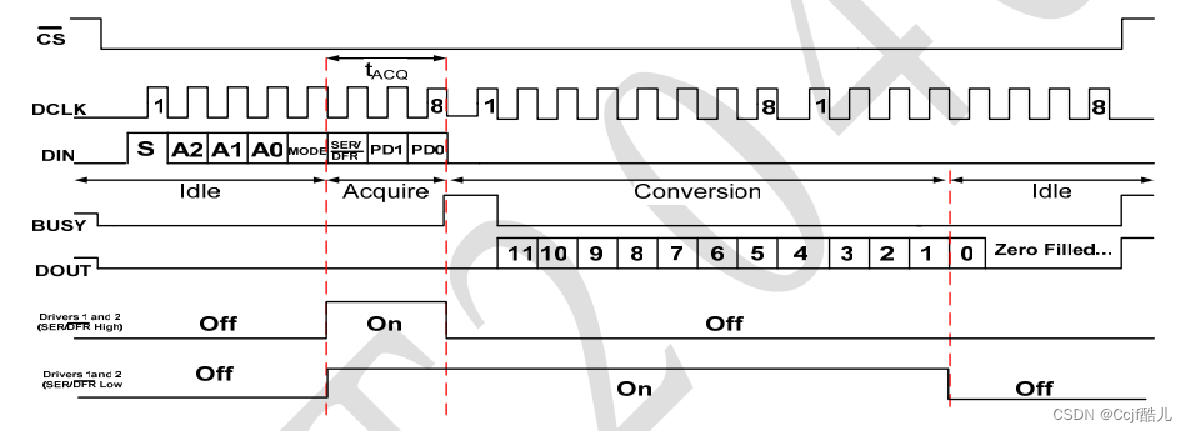
这篇论文是在Hinton的那篇开山之作《Distilling the Knowledge in a Neural Network》为背景提出来的,主要思想是使用一个宽而浅的教师模型来训练一个窄而深的学生模型。之前的知识蒸馏方法主要是训练教师网络到更浅更宽的网络,没有充分利用深度。而该文章进行了尝试,利用中间特征进行知识蒸馏,因此这篇文章算是蒸馏中间特征图的始祖。
这是知识蒸馏的第二篇文章,文章认为 Hinton 提出的 knowledge distillation 方法 (KD) 简单的拟合 Teacher 模型的输出并不能使 Student 达到和 Teacher 一样的泛化性能。对此,作者提出了 hint(隐藏层的输出)的概念。此外,作者认为在 thin 的条件下使得网络更 deep 可以在降低参数量的同时提升 Student 网络的性能。
https://arxiv.org/abs/1412.6550
基本理论
To the best of our knowledge,KD is designed such that student networksmimic teacher architectures of similar depth. Although we found the KD framework to achieve encouraging results even when student networks have slightly deeper architectures, as we increase the depth of the student network,KD training still suffers from the difficulty of optimizing deep nets (see Section 4.1).
相对于hinton的原始蒸馏系统来说,仅仅是加深student net的深度可能对于本论文来说有点“肤浅”,文章也提到了原KD中使用更深的学生网络也能达到很好的效果,但是这样会存在优化深度网络的困难。所以这篇文章的工作不仅仅是尝试更深的学生网络。
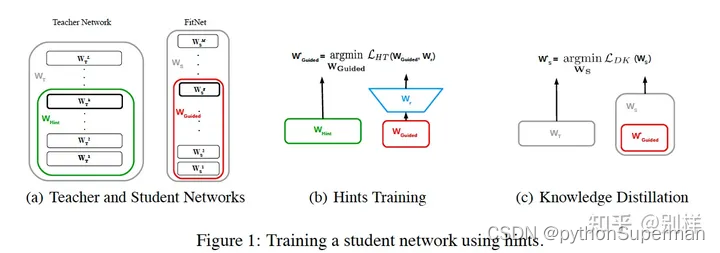
A hint is defined as the output of a teacher’s hidden layer responsible for guiding the student’s learning process. Analogously, we choose a hidden layer of the FitNet, the guided layer, to learn from the teacher’s hint layer. We want the guided layer to be able to predict the output of the hint layer.
该文章将教师的hint layer作为监督,学生的guided layer作为被监督的对象,希望guided layer可以尽可能地去预测到hint layer的输出。
Given that the teacher network will usually be wider than the FitNet, the selected hint layer may have more outputs than the guided layer. For that reason, we add a regressor to the guided layer
但是对于教师网络和学生网络来说,hint layer 和 guide layer这两个中间特征输出的大小并不一致,为了弥补教师网络的hint layer输出比学生网络guide layer更宽这一问题,设计了一个 回归层 结构,用来对齐特征的shape,也就是Figure1 (b)中的Wr (即是用于匹配的层)。
在进行hint引导时,提出使用一个层来匹配hint层和guided层的输出shape,这在后人的工作里面常被称为adaptation layer
HT Loss表示:

文章中重点提到:
Note that having hints is a form of regularization and thus, the pair hint/guided layer has to be chosen such that the student network is not over-regularized. The deeper we set the guided layer, the less flexibility we give to the network and, therefore, FitNets are more likely to suffer from over-regularization. In our case, we choose the hint to be the middle layer of the teacher network.
即认为使用hint来进行引导是一种正则化手段,学生guided层越深,那么正则化作用就越明显,为了避免过度正则化,需要仔细选择hint和guided。
蒸馏算法

第一阶段:
使用训练好的教师网络和初始化的学生网络,用教师网络的hint来预训练学生网络guide layer以及之前的层
第二阶段:
使用经典的KD知识蒸馏来训练整个网络,经典KD loss如下:
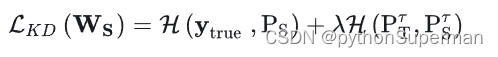
其中:

实现核心
对中间层进行蒸馏的开山之作,通过将学生网络的feature map扩展到与教师网络的feature map相同尺寸以后,使用均方误差MSE Loss来衡量两者差异。
class HintLoss(nn.Module):
"""Fitnets: hints for thin deep nets, ICLR 2015"""
def __init__(self):
super(HintLoss, self).__init__()
self.crit = nn.MSELoss()
def forward(self, f_s, f_t):
loss = self.crit(f_s, f_t)
return loss代码
https://github.com/yoshitomo-matsubara/torchdistill/blob/main/README.md
这个代码介绍了一个名叫torchdistill的包。