针对网站中的图形验证码图片,进行反向的内容识别,支持数字和字母,不区分大小写。
数据集地址
数据格式如下:

1、依赖导入
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import numpy as np
import pickle as pkl
import matplotlib.pyplot as plt2、数据集创建
class Dataset(Dataset):
def __init__(self, img_dir):
path_list = os.listdir(img_dir)
# 获取文件夹绝对路径
abspath = os.path.abspath(img_dir)
self.img_list = [os.path.join(abspath, path) for path in path_list]
self.transform = transforms.Compose([
# 灰度化,配合 卷积网络初始通过 1
# transforms.Grayscale(),
transforms.ToTensor(),
])
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
path = self.img_list[idx]
label = os.path.basename(path).split('.')[0].lower().strip()
img = Image.open(path).convert('RGB')
img_tensor = self.transform(img)
return img_tensor, label3、创建crnn卷积循环神经网络
stride 步长
padding 完成卷积后是否填充空白
MaxPool2d :减少数据空间大小,池化窗口的大小,通常设置为2×2。减少参数数量和计算量,同时也能提高模型的鲁棒性。
BatchNorm(512):对输入数据进行归一化处理,使得每个通道的数据均值为0,方差为1,提高模型的泛化能力
dropout:随机丢弃神经元的输出来减少模型的复杂度和过拟合的风险
nn.GRU:PyTorch中的一个函数,用于创建一个双向的GRU(门控循环单元)层。
参数解释如下:
255:输入的特征维度。输入数据的特征维度为255。255:隐藏状态的维度。隐藏状态的维度为255。bidirectional=True:表示是否使用双向GRU。如果设置为True,则使用双向GRU;如果设置为False,则使用单向GRU。batch_first=True:表示输入数据的维度顺序。如果设置为True,则输入数据的维度顺序为(batch_size, sequence_length, feature_dim);如果设置为False,则输入数据的维度顺序为(sequence_length, batch_size, feature_dim)。
class CRNN(nn.Module):
def __init__(self, vocab_size, dropout=0.5):
super(CRNN, self).__init__()
self.dropout = nn.Dropout(dropout)
self.convlayer = nn.Sequential(
# 如果预处理采用Grayscale 则 channel=1
nn.Conv2d(3, 32, (3,3), stride=1, padding=1),
# 激活函数,x小于0,y=0
nn.ReLU(),
nn.MaxPool2d((2,2), 2),
nn.Conv2d(32, 64, (3,3), stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d((2,2), 2),
nn.Conv2d(64, 128, (3,3), stride=1, padding=1),
nn.ReLU(),
nn.Conv2d(128, 256, (3,3), stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d((1,2), 2),
nn.Conv2d(256, 512, (3,3), stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, (3,3), stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d((1,2), 2),
nn.Conv2d(512, 512, (2,2), stride=1, padding=0),
self.dropout
)
self.mapSeq = nn.Sequential(
nn.Linear(1024, 256),
self.dropout
)
self.lstm_0 = nn.GRU(256, 256, bidirectional=True)
self.lstm_1 = nn.GRU(512, 256, bidirectional=True)
self.out = nn.Sequential(
nn.Linear(512, vocab_size),
)
def forward(self, x):
x = self.convlayer(x)
x = x.permute(0, 3, 1, 2)
x = x.view(x.size(0), x.size(1), -1)
x = self.mapSeq(x)
x, _ = self.lstm_0(x)
x, _ = self.lstm_1(x)
x = self.out(x)
return x.permute(1, 0, 2)4、创建模型
class OCR:
def __init__(self):
self.device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
self.crnn = CRNN(VOCAB_SIZE).to(self.device)
print('Model loaded to ', self.device)
self.critertion = nn.CTCLoss(blank=0)
self.char2idx, self.idx2char = self.char_idx()
def char_idx(self):
char2idx = {}
idx2char = {}
characters = CHARS.lower() + '-'
for i, char in enumerate(characters):
char2idx[char] = i + 1
idx2char[i+1] = char
return char2idx, idx2char
def encode(self, labels):
length_per_label = [len(label) for label in labels]
joined_label = ''.join(labels)
joined_encoding = []
for char in joined_label:
joined_encoding.append(self.char2idx[char])
return (torch.IntTensor(joined_encoding), torch.IntTensor(length_per_label))
def decode(self, logits):
tokens = logits.softmax(2).argmax(2).squeeze(1)
tokens = ''.join([self.idx2char[token]
if token !=0 else '-'
for token in tokens.numpy()])
tokens = tokens.split('-')
text = [char
for batch_token in tokens
for idx, char in enumerate(batch_token)
if char != batch_token[idx-1] or len(batch_token) == 1]
text = ''.join(text)
return text
def calculate_loss(self, logits, labels):
encoded_labels, labels_len = self.encode(labels)
logits_lens = torch.full(
size=(logits.size(1),),
fill_value = logits.size(0),
dtype = torch.int32
).to(self.device)
return self.critertion(
logits.log_softmax(2), encoded_labels,
logits_lens, labels_len
)
def train_step(self, optimizer, images, labels):
logits = self.predict(images)
optimizer.zero_grad()
loss = self.calculate_loss(logits, labels)
loss.backward()
optimizer.step()
return logits, loss
def val_step(self, images, labels):
logits = self.predict(images)
loss = self.calculate_loss(logits, labels)
return logits, loss
def predict(self, img):
return self.crnn(img.to(self.device))
def train(self, num_epochs, optimizer, train_loader, val_loader, print_every = 2):
train_losses, valid_losses = [],[]
for epoch in range(num_epochs):
tot_train_loss = 0
self.crnn.train()
for i, (images, labels) in enumerate(train_loader):
logits, train_loss = self.train_step(optimizer, images, labels)
tot_train_loss += train_loss.item()
with torch.no_grad():
tot_val_loss = 0
self.crnn.eval()
for i, (images, labels) in enumerate(val_loader):
logits, val_loss = self.val_step(images, labels)
tot_val_loss += val_loss.item()
train_loss = tot_train_loss / len(train_loader.dataset)
valid_loss = tot_val_loss / len(val_loader.dataset)
train_losses.append(train_loss)
valid_losses.append(valid_loss)
if epoch % print_every == 0:
print('Epoch [{:5d}/{:5d}] | train loss {:6.4f} | val loss {:6.4f}'.format(
epoch + 1, num_epochs, train_loss, val_loss
))
return train_losses, valid_losses5、开启训练
TRAIN_DIR = '../data/train'
VAL_DIR = '../data/val'
# batch_size lr 参数值训练,得到的结果较合适
BATCH_SIZE = 8
N_WORKERS = 0
EPOCHS = 20
CHARS ='abcdefghijklmnopqrstuvwxyz0123456789'
VOCAB_SIZE = len(CHARS) + 1
lr = 0.02
# 权重衰减
weight_decay = 1e-5
# 下降幅度
momentum = 0.7
train_dataset = Dataset(TRAIN_DIR)
val_dataset = Dataset(VAL_DIR)
train_loader = DataLoader(
train_dataset, batch_size = BATCH_SIZE,
num_workers = N_WORKERS, shuffle=True
)
val_loader = DataLoader(
val_dataset, batch_size=BATCH_SIZE,
num_workers=N_WORKERS, shuffle=False
)
ocr = OCR()
optimizer = optim.SGD(
ocr.crnn.parameters(), lr =lr, nesterov=True,
weight_decay=weight_decay, momentum=momentum
)
train_losses, val_losses = ocr.train(EPOCHS, optimizer, train_loader, val_loader, print_every=1)

6、随机采样,验证模型
sample_result = []
for i in range(10):
idx = np.random.randint(len(val_dataset))
img, label = val_dataset.__getitem__(idx)
logits = ocr.predict(img.unsqueeze(0))
pred_text = ocr.decode(logits.cpu())
sample_result.append((img, label, pred_text))
fig = plt.figure(figsize=(17,5))
for i in range(10):
ax = fig.add_subplot(2, 5, i+1, xticks=[], yticks=[])
img, label, pred_text = sample_result[i]
title = f'Truth: {label} | Pred: {pred_text}'
ax.imshow(img.permute(1,2, 0))
ax.set_title(title)
plt.show()
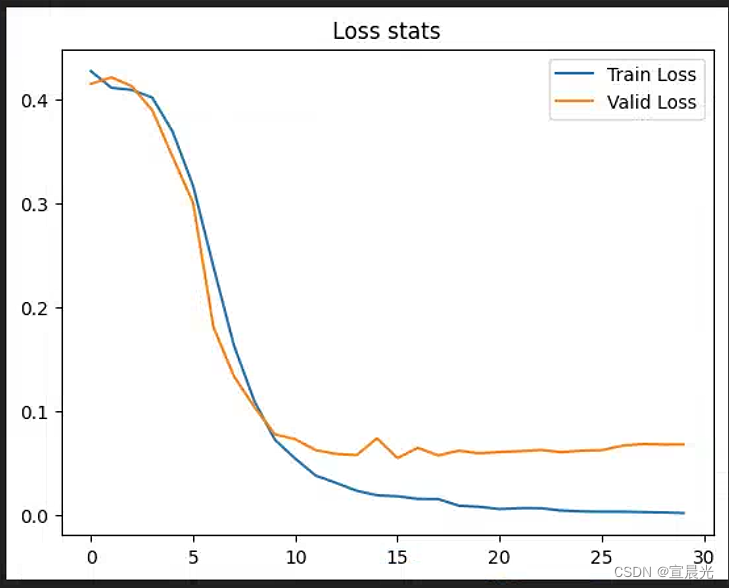
7、输出统计图
plt.plot(train_losses, label='Train Loss')
plt.plot(val_losses, label='Valid Loss')
plt.title('Loss stats')
plt.legend()
plt.show()
8、外部数据验证
trans = transforms.Compose([
# 取决于与处理中是否也做相同处理
transforms.Grayscale(),
# 原始数据集图片尺寸
transforms.Resize([50, 200]),
transforms.ToTensor(),
])
image = Image.open('../data/123.png').convert('RGB')
tensor_img = trans(image)
result = ocr.predict(tensor_img.unsqueeze(0))
text = ocr.decode(result.cpu())
print(text)








![作业1-32 P1059 [NOIP2006 普及组] 明明的随机数](https://img-blog.csdnimg.cn/direct/92ffcd379e954502a30b43d53cf1a583.png)