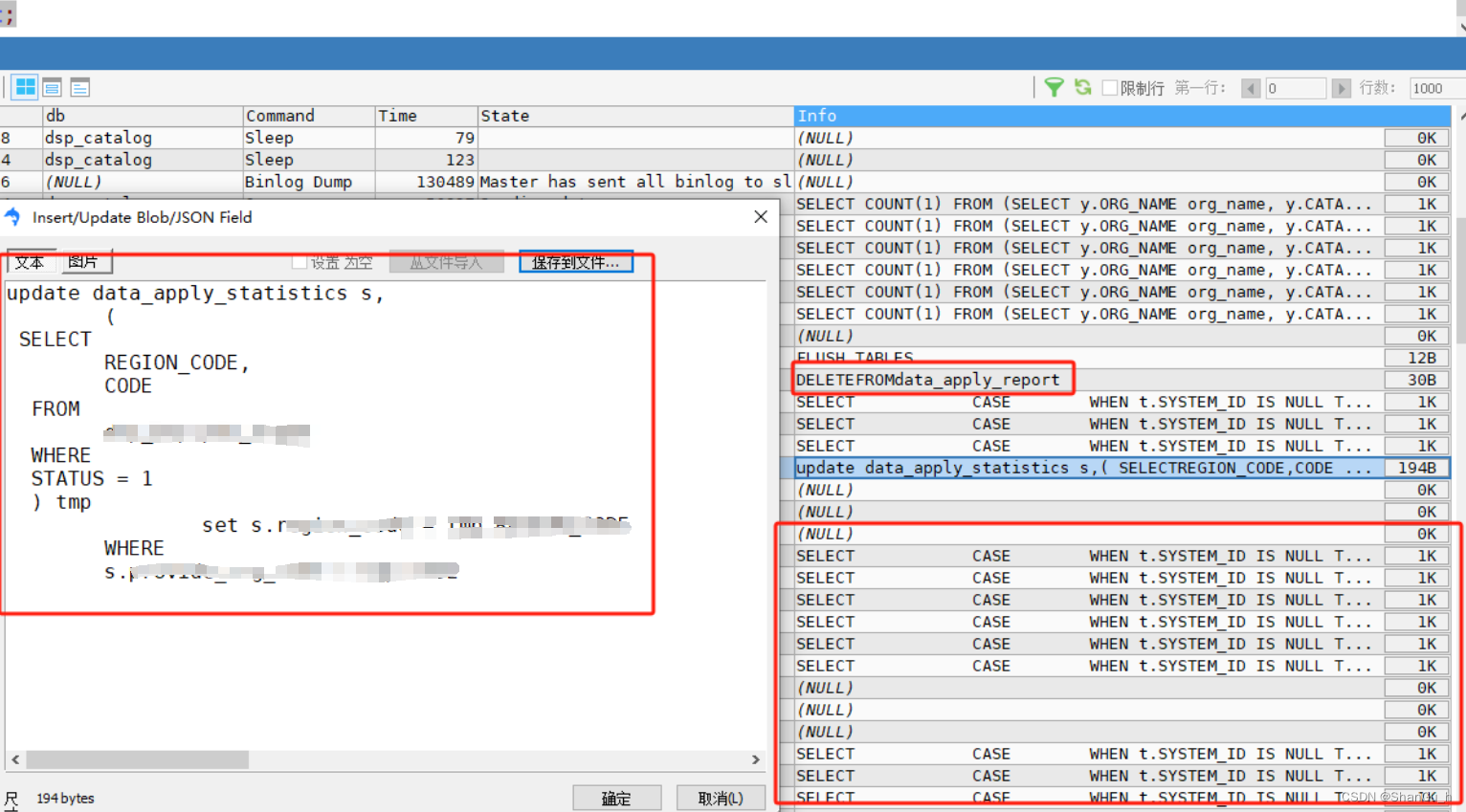
HTA:自注意力 + 通道注意力 + 重叠交叉注意力,提高细节识别、颜色表达、边缘清晰度
- 提出背景
- 框架
- 浅层特征提取
- 深层特征提取
- 图像重建
- 混合注意力块(HAB)
- 重叠交叉注意力块(OCAB)
- 同任务预训练
- 效果
- 小目标涨点
- YOLO v5 魔改
- YOLO v7 魔改
- YOLO v8 魔改
- YOLO v9 魔改
提出背景
论文:https://arxiv.org/pdf/2205.04437.pdf
代码:https://github.com/XPixelGroup/HAT
问题: 传统的基于CNN的图像SR方法虽然比早期技术有显著改进,但在处理图像时仍存在限制,特别是在表示能力和处理长距离依赖关系方面。
-
问题: CNN的方法虽然有所改进,但在捕捉图片细节方面还不够好。
-
解决方法:
- 改进网络设计:通过添加特殊的“块”(残差块和密集块),让网络更好地学习图片的特征,从而生成更清晰的图片。
- 尝试新框架:除了改进传统的CNN,还探索了新的网络设计,比如Transformer,为提升图片清晰度提供了新思路。
- 引入对抗学习:通过这种方式让网络生成的图片看起来更自然。
Transformer,最初是为了处理语言问题而设计的,但现在也被用来处理图片,特别是在提高图片清晰度方面。
-
问题: 尽管Transformer在处理图片时非常有潜力,但如何最大化其性能,尤其是在提升图片清晰度方面,还存在挑战。
-
解决方法:
3. 激活更多输入像素:尝试让Transformer注意到更多的图片细节,以生成更高质量的图片。
研究者发现,虽然最新的一种叫做Swin Transformer的技术在把模糊图片变清晰(即图像超分辨率)方面做得很好,但是它具体是怎么做到的,特别是它为什么比之前的技术(比如CNN)更好,还不是很清楚。
他们使用了一种工具(LAM)来分析,结果发现这种新技术并没有像预期的那样使用更多的图片信息。
因此,研究者想要设计一个新的网络,能够更好地利用图片信息,同时避免之前技术中存在的一些问题,比如在图片的一些部分出现不自然的效果。
他们提出了一种新的设计(叫做HAT),这个设计包含几个关键部分:
-
基本结构:他们的网络设计包括三大部分:提取图片的基本特征、进一步深入提取特征、最后根据这些特征重建高清图片。
之所以用这个子解法,是因为这种分层的架构设计在先前的工作中已被广泛使用,有效提取和利用图像特征。
-
注意力机制:俩种注意力机制
之所以用这个混合注意力块(HAB) ,是因为通过将通道注意力集成到标准Transformer块中,可以提高网络对全局信息的感知能力和表示能力。
之所以用这个残差混合注意力组(RHAG),是因为它结合了混合注意力块和重叠交叉注意力块,以及卷积层,以增强网络对图像特征的学习和表示能力。
-
改进连接方式:为了让网络更好地理解图片的整体信息,他们引入了一种新的方法(重叠交叉注意力块OCAB)来改进不同部分之间的连接。
之所以用这个重叠交叉注意力块(OCAB),是为了直接建立窗口间的连接,增强窗口自注意力的表示能力,利用更多有用的信息进行查询。
最后,为了让这个网络在处理图片时更加高效,他们还采用了一种特别的训练方法:在一个很大的图片集上先进行预训练,然后再在特定的任务上进行微调。
这种方法可以让网络更好地学习如何提高图片清晰度。
通过这些创新的设计和训练策略,产生的新网络(HAT),让网络能够更好地利用图片中的信息,从而生成更清晰、更自然的图片。
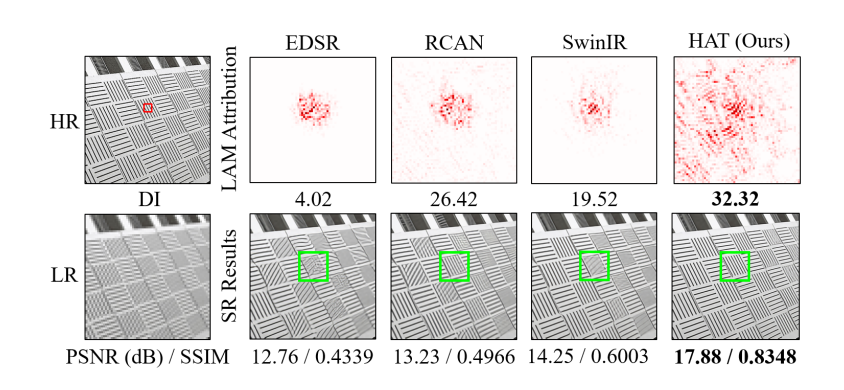
这幅图比较了不同网络的局部属性图(LAM)结果,其中包括高分辨率(HR)图像,低分辨率(LR)图像,以及EDSR、RCAN、SwinIR和HAT(我们的方法)网络的LAM结果。
LAM结果显示每个像素在输入低分辨率图像中的重要性,尤其是在重建被盒子标记的区域时。扩散指数(DI)反映了参与的像素范围。一个更高的DI值表示使用了更广泛的像素范围。
结果表明,与RCAN相比,SwinIR利用的信息更少,而HAT使用了最多的像素进行重建。
假设你有一张模糊的旧照片,想要让它变得清晰,以便更好地欣赏其中的细节,比如人物的表情、背景的景物等。
你决定使用新的图像超分辨率技术(HAT)来处理这张照片。
下面是这项技术如何运用上述三个方法来实现这一目标的:
-
结合自注意力和通道注意力机制:
- 当HAT开始工作时,它首先使用自注意力机制来分析照片中的每个像素,并理解这些像素之间的关系。
- 例如,它会注意到人物脸部的不同区域之间的联系,从而更好地重建面部特征。
- 同时,通道注意力机制帮助算法识别出照片中哪些颜色(红、绿、蓝)对重建图像尤为重要。这样,如果背景是蓝天,算法就会确保天空的蓝色看起来既自然又鲜明。
-
引入重叠交叉注意力模块:
- 接下来,HAT通过重叠交叉注意力模块处理照片,这一步骤让算法能够更好地连接图片中紧密相邻的部分。
- 比如,在重建一座桥的图像时,这项技术能够确保桥的每一部分都与相邻的水面和背景自然地融为一体,避免出现不自然的分界线。
-
采用大规模数据同任务预训练策略:
- 在处理你的照片之前,HAT已经在成千上万的相似照片上进行了训练,这些照片涵盖了各种各样的场景、颜色和细节。
- 这种大规模的预训练让HAT学会了如何准确地从低分辨率图像中恢复出高分辨率的细节。
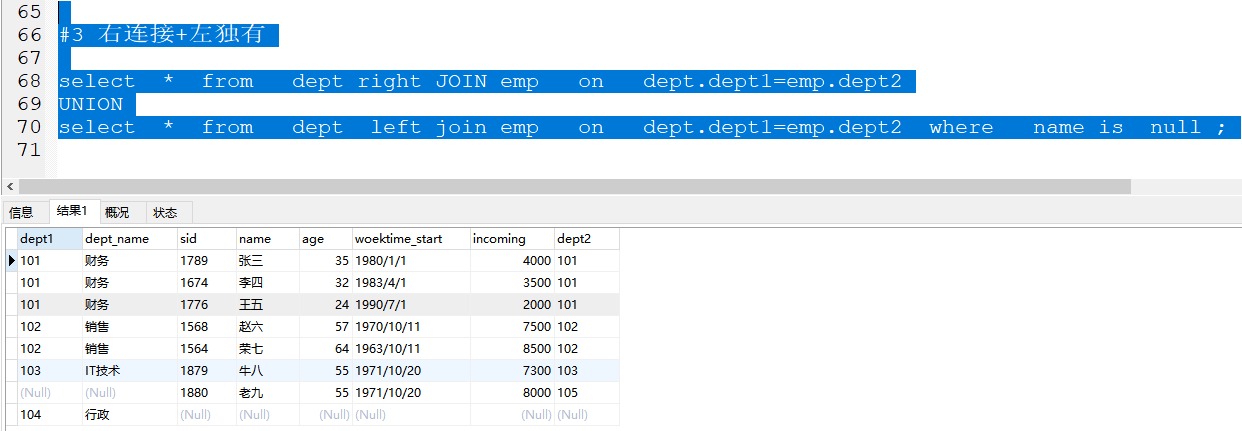
- 当它开始工作在你的旧照片上时,算法能够利用之前学到的知识,更准确地预测每个像素的正确位置和颜色,即使在原始照片中这些细节几乎不可见。
最终,当HAT完成对你的模糊旧照片的处理后,你会得到一张清晰、自然、细节丰富的高分辨率照片。
通过这种方式,人物的面部表情、背景的景物,甚至是衣物的纹理都会变得清晰可见,就像是用高质量相机拍摄的新照片一样。
总结:
-
问题:在图像超分辨率中,现有的 Transformer 网络只能利用输入信息的有限空间范围,未能发挥自身全部潜力
-
通道注意力用于全局信息
解决 CNN 在处理图像时仍存在限制,特别是在表示能力和处理长距离依赖关系方面。
-
窗口自注意力,增强窗口间的信息交互,减少中间特征中的阻塞伪影。

这幅图展示了在不同层级(Layer 1、Layer 2、Layer 3)的中间特征中出现的阻塞伪影。
顶部的图像显示了SwinIR在Urban100数据集中的三个图像中的中间特征,而底部的图像则展示了我们的HAT网络在相同图像中的中间特征。
注意到在SwinIR的特征图中,一些层出现了明显的块状伪影,而在HAT的特征图中伪影较少。
-
重叠交叉注意力改善相邻窗口间的信息交互
Swin Transformer 中的窗口划分机制导致中间特征出现明显的阻塞伪影,表明基于窗口的自注意力方法中的移动窗口机制在构建跨窗口连接时效率不高。
通过增强窗口间的信息交互,可以显著减少中间特征中的阻塞伪影,从而改善图像的重建质量。
-
通过整合不同注意力机制,激活了更多的输入像素
不同的注意力机制可能会关注输入数据的不同方面。
例如,有的注意力机制可能侧重于空间维度,识别图像中哪些区域最重要;而有的则可能侧重于通道维度,确定哪些特征通道最为关键。
通过整合这些不同的注意力机制,一个模型就能同时从多个角度识别和利用输入数据中的关键信息,从而“激活了更多的输入像素”
框架
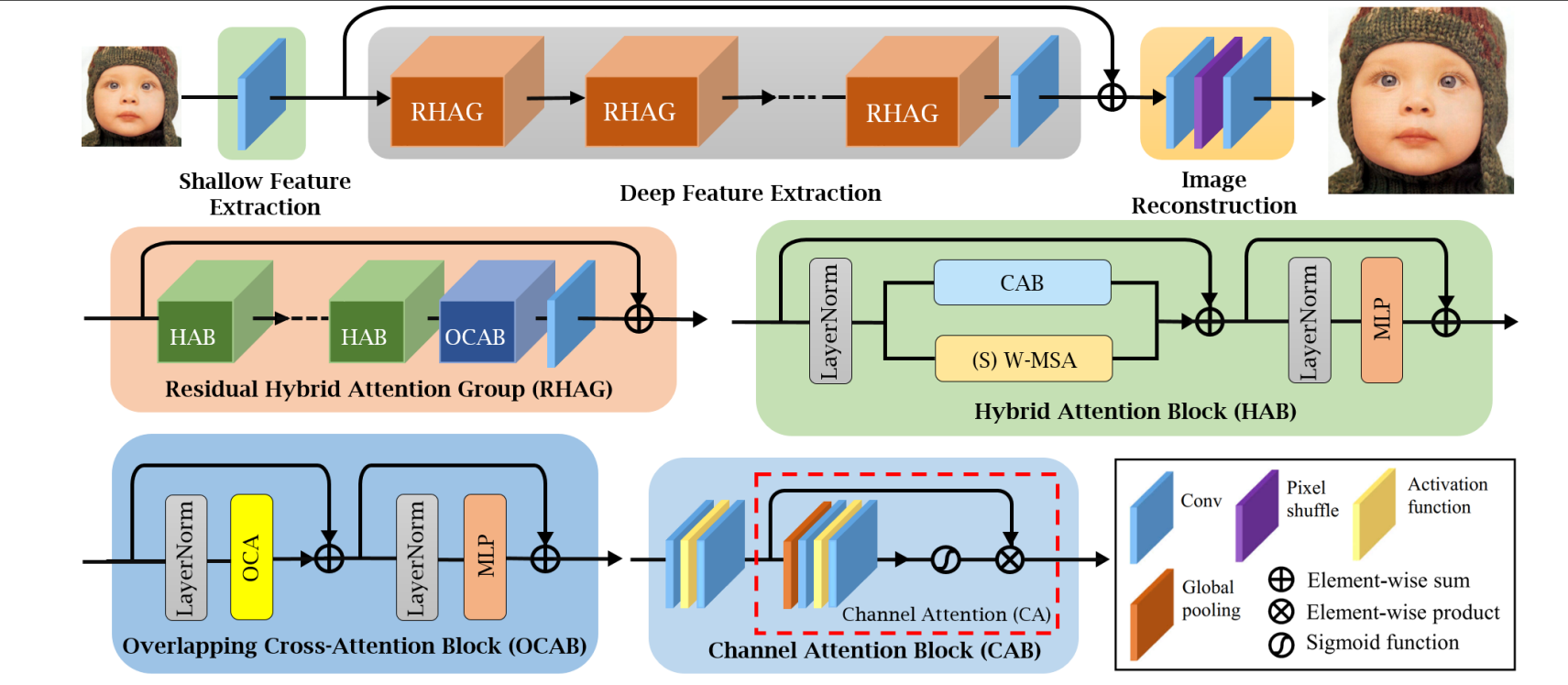
这幅图详细展示了HAT网络的整体架构,包括浅层特征提取、深层特征提取(RHAG和HAB)和图像重建。
每个RHAG包含几个混合注意力块(HAB)、一个重叠交叉注意力块(OCAB)和一个具有残差连接的3x3卷积层。
图中也展示了OCAB和CAB的内部结构。
浅层特征提取
- 子特征: 利用一个卷积层从低分辨率输入图像中提取浅层特征。
- 原因: 之所以使用这个子解法,是因为初步提取的浅层特征可以为后续的深层特征提取提供基础信息。
深层特征提取
- 子特征1: 使用一系列的残差混合注意力组(RHAG)进行深层特征的提取。
- 原因1: 之所以使用残差混合注意力组,是因为注意力机制能够使网络更加聚焦于重要的特征信息,而残差连接有助于信息的传递和学习的稳定性。
- 子特征2: 在RHAG后使用一个3x3卷积层进一步处理特征。
- 原因2: 之所以使用3x3卷积层,是因为卷积操作可以在保持空间信息的同时进行特征融合和强化。
图像重建
- 子特征: 将浅层特征和深层特征通过全局残差连接融合后,通过重建模块来输出高分辨率图像。
- 原因: 之所以使用这个子解法,是因为融合浅层和深层特征可以充分利用从不同层次提取的信息,而重建模块(如像素洗牌)则负责将这些特征转换为高分辨率图像。
混合注意力块(HAB)
- 子特征: 在标准Swin Transformer块中集成一个基于通道注意力的卷积块,以增强网络的表征能力。
- 原因: 之所以使用混合注意力块,是因为通道注意力能够强调全局信息对通道权重的影响,而结合卷积操作能够帮助Transformer更好地进行视觉表征和优化。
重叠交叉注意力块(OCAB)
- 子特征: 通过OCAB建立跨窗口的连接,增强窗口自注意力的表征能力。
- 原因: 之所以使用重叠交叉注意力块,是因为通过不同窗口大小的分区可以提取更加丰富和具有代表性的特征信息,从而增强模型处理不同空间区域信息的能力。

这幅图解释了重叠交叉注意力(Overlapping Cross-Attention, OCA)层中重叠窗口分区的概念。
展示了标准窗口分区和重叠窗口分区的差异,其中标准窗口分区用于计算查询(Q),而重叠窗口分区用于计算键(K)和值(V)。
同任务预训练
- 子特征: 在大规模数据集(如ImageNet)上进行同任务(如超分辨率)的预训练,然后在特定数据集上进行微调。
- 原因: 之所以采用同任务预训练策略,是因为预训练能够让模型学习到更广泛和通用的知识,而大规模和多样性的数据集能够显著提高预训练的有效性,进一步通过微调适应特定任务的需求。
效果

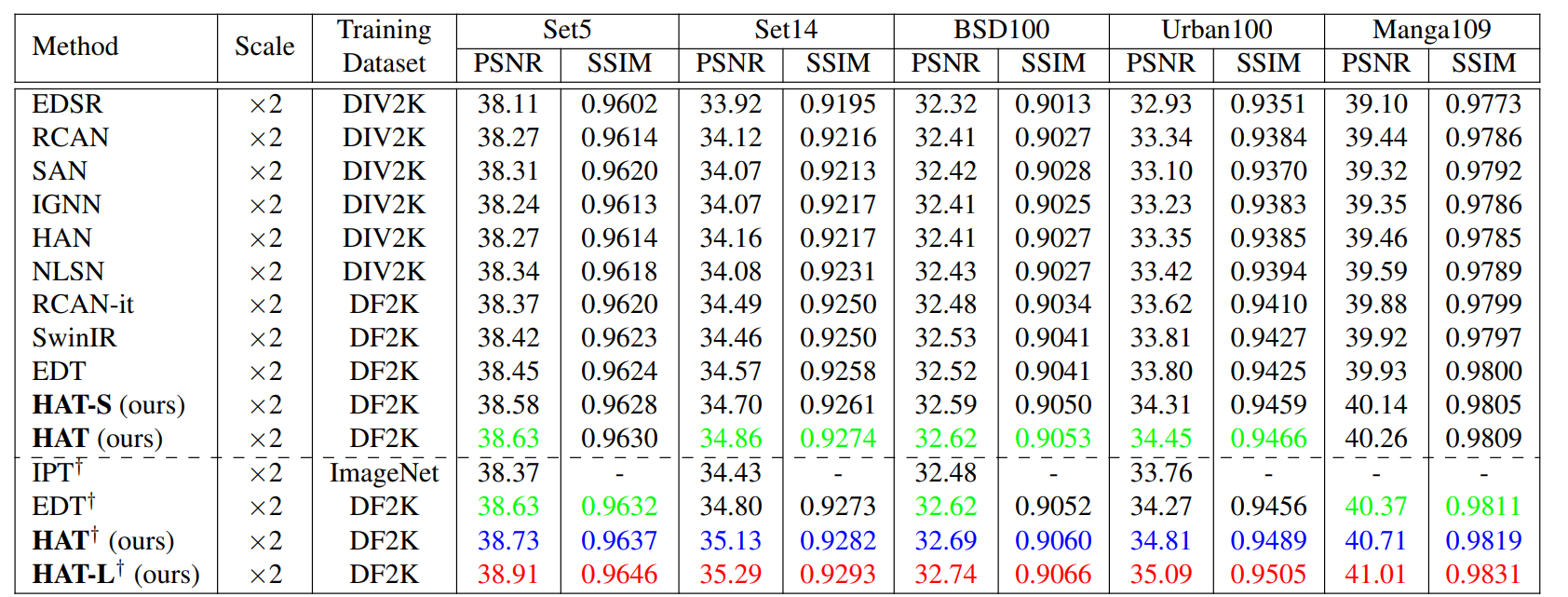
小目标涨点
更新中…