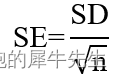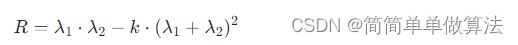目录
1 各种数据指标,分类整理
1.0 关于数据/值有3种
1.1 第1类:描述一堆数据特征的指标:集中度,离散度,形状特征
1.2 第2类:判断预测y值和观测值差距的指标
1.3 第3类:描述误差的各种指标
1.4 重点看第3堆指标:误差相关的指标
3 相关度/ 相关系数R, coefficient of correlation
3.1 相关系数定义
3.2 相关系数的公式
3.3 相关系数的意义
3.4 python实现暂缺
4 决定系数 R**2 (R-squared ) Coefficient of determination
4.1 R**2的定义
4.2 决定系数的公式
4.2.1 基本符号界定
4.2.2 决定系数的公式
4.2.3 决定系数公式的变形
4.2.4 变形的公式各个指标名词的意义
4.3 调整后R**2 ,Adjust-R-squared
4.4 决定系数的意义
4.5 决定系数R**2的python模拟,暂缺
4.6 决定系数R**2 是相关系数R的平方吗?
5 关于 SST SSR SSE
5.1 SST (离差平方和/总体平方和):Total sum of squares,TSS
5.2 SSE(和方差、残差平方和) The sum of squares due to error
5.3 SSR 回归平方和 Sum of squares of the regression
6 残差和残差平方和SSE
6.1 残差的定义
6.2 残差的公式
6.3 有了残差,才有残差平方和
6.4 最小二乘法的由来
6.5 最小二乘法的公式 = 残差公式
7 离差(deviation)和离差平方和SST
7.1 离差的定义
7.2 离差的公式
7.3 离差平方和 sums of squared deviations=SS=SST
7.3.1 定义
7.3.2 公式
8 偏差 bias
8.1 偏差的定义
8.2 偏差的公式和求法
9 方差(variance/deviation Var,D(X) )是平均值
9.1 方差的定义
9.1.1 关于平均值=期望
9.2 方差的公式:
9.2.1 总体方差
9.2.2 样本方差(实际方差 /统计方差)
9.3 方差的意义:
10 误差=方差+偏差**2+残差σ,把三者统一起来
10.1 误差的组成成分
10.2 irreducible Error
10.3 Bias:基于样本分布
10.4 Var:基于样本分布
10.5 误差的公式可以统一两者的意义
10.6 偏差和方差的区别
10.7 偏差和方差的一般性应用的区别
11 标准差(Standard Deviation,SD)
12 变异系数= 标准差/均值
13 标准误/ 标准误差(Standard Error of Mean,SE)
13.1 标准误差的定义
13.2 公式:
1 各种数据指标,分类整理
首先:数据本身也有不同的种类
其次,对数据的描述有很多不同的角度,每个不同的角度都有很多不同的指标。
1.0 关于数据/值有3种
- 真实值
- 观测值
- 预测值/拟合值
1.1 第1类:描述一堆数据特征的指标:集中度,离散度,形状特征
数据特征一般包括这3个方面:集中度,离散度,形状特征
- 描述数据分布的集中趋势:反映数据向其中心靠拢或聚集程度
- 平均数
- 中位数
- 众数
- 百分位数
- 描述数据分布的离散程度:反映数据远离中心的趋势或程度
- 极差
- 方差
- 标准差
- 四分位数间距。
- 描述数据分布的形状变化:反应数据分布的形状特征
- 变异系数= 标准差除以均值。
- 偏度
- 峰度
1.2 第2类:判断预测y值和观测值差距的指标
我们获得观测数据后,经常会用数据模型去模拟而获得很多预测值/拟合值
判断预测y值和观测值差距的指标,目的是比较,那个预测值更好,那个预测曲线模型更好有如下这种指标
- 最小二乘法误差=Σ(Y-f(xi))**2
- MSE,其中s表示squared
- RMSE
- MAE,其中a表示average
- MAPE
- WMAPE
1.3 第3类:描述误差的各种指标
- 误差 error
- 相关系数 R
- 确定系数,决定系数, R-square,
- 方差 Variance
- 偏差 bias
- 残差 Deviance
1.4 重点看第3堆指标:误差相关的指标
- 前面已经学习过前几种了,这里来看第3堆指标:误差相关的指标
2 相关度/ 相关系数R, coefficient of correlation
相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量。
2.1 相关系数定义
- 简单相关系数:又叫相关系数或线性相关系数
- 一般用字母r表示,用来度量两个变量间的线性关系。
- 相关度:
- 相关度又叫 皮尔逊相关系数 (Pearson Correlation Coefficient),衡量两个值线性相关强度的量
- 取值范围 [-1, 1]: 正向相关: >0, 负向相关:<0, 无相关性:=0
2.2 相关系数的公式
相关系数有多种定义方式,较为常用的是皮尔逊相关系数

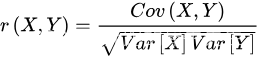
- 其中,Cov(X,Y)为X与Y的协方差,Var[X]为X的方差,Var[Y]为Y的方差
- 协方差:两个变量变化是同方向的还是异方向的。X高Y也高,协方差就是正,相反,则是负。
- 为什么要除标准差:标准化。即消除了X和Y自身变化的影响,只讨论两者之间关系。
- 从公式看,相关系数也是一种特殊的协方差
2.3 相关系数的意义
- r是相关系数,相关有很多种类型(线性和非线性)。
- 一般情况下我们用的r指的是皮尔森相关系数,它指的是一种线性相关,范围从-1到1。
- -1指负相关,1指正相关。0指的是不存在线性相关。
- 进行回归分析前,需要线分析下2个变量是否相关
- 如果两个变量有相关性,再进行回归分析。
相关系数是一个评价两个变量线性相关度的指标。
- 在线性拟合中可以通过拟合结果和实测值得相关系数来反应拟合结果和实测结果线性相关度。
- 但是如果本来就用的非线性拟合(多项式、曲线),那这个指标对于评估拟合没有任何意义。
2.4 python实现暂缺
3 决定系数 R**2 (R-squared ) Coefficient of determination
3.1 R**2的定义
- R-square,确定系数,决定系数
- Coefficient of determination,
- 反应因变量的全部变异能通过回归关系被自变量解释的比例,回归中可解释离差平方和与总离差平方和之比值,其数值等于相关系数R的平方。
- 简而言之:模型可以解释为多大程度是自变量导致因变量的改变。

3.2 决定系数的公式
3.2.1 基本符号界定
- Yi 真实值,实际观测值,
- Y^i 预测值,表示对第i个观测值的预测值
- Y_ 真实/原始数据的平均值,因变量的均值?
- Y^_ 真实/原始数据的平均值
- 预测值的平均值 =Average(y^) =E(y^)
- 没有概率的前提下,期望=概率加权平均值=平均值
3.2.2 决定系数的公式
由于R2<R,可以防止对相关系数所表示的相关做夸张的解释。
确定系数:在Y的总平方和中,由X引起的平方和所占的比例,记为R2(R的平方)
确定系数的大小决定了相关的密切程度。
- R**2 即R-squared
- R**2=1-Σ(y-y^)**2/(y-y_)**2

3.2.3 决定系数公式的变形
- R**2 即R-squared
- R**2=1-Σ(y-y^)**2/(y-y_)**2
- R**2=1-SSE/SST
- R**2=1-SSE/SST=(SST-SSE)/SST=SSR/SST
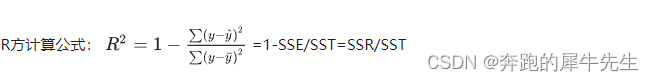
3.2.4 变形的公式各个指标名词的意义
- 第1套公式:R2=SSR/SST=1-SSE/SST
- 第1套公式:R2=ESS/TSS=1-RSS/TSS
- SST=SSR+SSE
- TSS=ESS+RSS
- SST (total sum of squares):总平方和
- SST=TSS(total sum of squares)
- TSS是执行回归分析前,响应变量固有的方差;
- SSR (regression sum of squares):回归平方和
- SSR= ESS (explained sum of squares)
- SSR是回归模型可以解释的方差。
- SSE (error sum of squares) :残差平方和。
- SSE= RSS (residual sum of squares)
- RSS是残差平方和,即回归模型不能解释的方差;
还有个SER:
- ser(Sum of Squared Errors Residuals)
- 公式:SER=SSR+RSS。
- 其中,SSR是回归模型可以解释的方差;
- RSS是残差平方和,即回归模型不能解释的方差。
3.3 调整后R**2 ,Adjust-R-squared
- Adjust-R-squared
- R**2=1-(1-R**2)*(n-1)/(n-k-1)
- 其中k=自变量个数
- 其中n=样本数量
- 调整的R方:Adjusted R-Square,调整R方的解释与R方类似
- 不同的是:调整R方同时考虑了样本量(n)和回归中自变量的个数(k)的影响
- 这使得调整R方永远小于R方,而且调整R方的值不会由于回归中自变量个数的增加而越来越接近1。
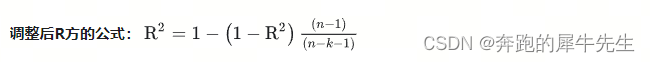
3.4 决定系数的意义
- r2是一个评价拟合好坏的指标。这里的拟合可以是线性的,也可以是非线性的。即使线性的也不一定要用最小二乘法来拟合。
- 意义:拟合优度越大,自变量对因变量的解释程度越高,自变量引起的变动占总变动的百分比高。观察点在回归直线附近越密集。
- 是评估回归模型好坏的指标。通过数据的变化来表征一个拟合的好坏。
- 确定系数的正常取值范围为[0 1],越接近1,表明方程的变量对 y 的解释能力越强,这个模型对数据拟合的也较好。
- 比如回归模型的R平方等于0.7,那么表示,此回归模型对预测结果的可解释程度为70%
3.5 决定系数R**2的python模拟,暂缺
3.6 决定系数R**2 是相关系数R的平方吗?
应该说,在某些情况下是的
- r2是相关系数r的平方。我们通常说的r2是把皮尔森相关系数的这个r平方得到的r2。,这里r2指的是在最佳拟合线(线性关系)中可以解释的比例。
- 在带有截距项的线性最小二乘多元回归中, R2R^2 等于实测值 yy 和拟合值 ff 的相关系数的平方。
- 相关系数的平方即为决定系数。它与相关系数的区别在于除掉|R|=0和1情况,
5 关于 SST SSR SSE
其中
- SST=SSE+SSR
- SSR较大,SSE较小,模型拟合程度好,解释度强
- SSR较小,SSE较大,模型拟合程度差
5.1 SST (离差平方和/总体平方和):Total sum of squares,TSS
- 因变量的总体变异程度
- 即原始数据和原始数据均值之差的平方和。
- 描述原始数据本身的离散程度
- SST=Σ(y-y_)**2
- SST=SSE+SSR
5.2 SSE(和方差、残差平方和) The sum of squares due to error
- 残差平方和
- The sum of squares due to error,该统计参数计算的是拟合数据和原始数据对应点的误差的平方和。
- 模型不能解释的部分,这个越大,拟合效果越差
- SSE=Σ(y-y^)**2
- SSE越接近于0,说明模型选择和拟合更好,数据预测也越成功。
- SSR衡量了 预测模型所无法解释的 因变量/真实值的变异程度。
5.3 SSR 回归平方和 Sum of squares of the regression
- SSR=Σ(y^-y_)**2
- 表示模型可以解释的方差。
- 回归平方和,即预测数据与原始数据均值之差的平方和。
- SSR衡量了 预测模型所解释的 因变量/真实值的变异程度。
6 残差和残差平方和SSE
6.1 残差的定义
残差(residual):实际值与观察值之间的差异。
6.2 残差的公式
残差=Σ(Yi-f(Xi))
6.3 有了残差,才有残差平方和
- 残差平方和 ,SSE=Σ(y-y^)**2
- 残差平方和,是不是就是最小二乘法计算所得?
6.4 最小二乘法的由来
- 假设我们的自变量X,因变量Y,
- 我们有预测函数 f(X) 去模拟Y
- 然后预测函数和真实值之间有误差,Y=f(X)+ ε
- 真实值:Y ,真实值可能有多个
- 预测值:Y^=f(x) ,对应每一个真实值,对应的预测值根据预测函数可做出多个
- 然后现在怎么判断,预测值是否准确呢?
- 就到了最小二乘法了。
- 最小二乘法:应该叫 最小乘方法。
- 取得是 Σ(Y-f(xi))**2
6.5 最小二乘法的公式 = 残差公式


7 离差(deviation)和离差平方和SST
离差,偏差(deviation),变异(variation)
7.1 离差的定义
- 别称:常见的名称有离差,偏差,离均差,距平,一般都是指deviation。
- 定义:是变量的一个观测值与某个特定的参照值之间差异的度量。参照值通常指变量的平均值,此时称为离均差或距平。而一变量的各数值对于其平均值的偏离,称为变异(variation)。
7.2 离差的公式
- (f(Xi)-特定的f(Xi)) ,Σ(f(Xi)-特定的f(Xi))
- (Yi-特定的YI) ,Σ (Yi-特定的YI)
- 特点:有正负
- 一一对应和一多对应
- 一对应多,一个观测值,会有多个预测值/拟合值
- 多多对应,多个观测值,会有多个预测值/拟合值
7.3 离差平方和 sums of squared deviations=SS=SST
sums of squared deviations=SS=SST
- 因变量的总体变异程度
- 即原始数据和原始数据均值之差的平方和。
- 描述原始数据本身的离散程度
7.3.1 定义
- 别称:平方和
- 定义:是变量各项与变量平均值之差的平方的总和,称为离差平方和,也简称平方和。
-
SS=sums of squared deviations
-
SST=TSS=Total sum of squares,TSS
7.3.2 公式
- 离差有正负,
- 离差和不能反映变量整体的偏离。因为会有抵消效果
- 离差经过平方之后只有正值,离差平方和可以反应与均值的偏离程度。
( 通常用离差平方和来描述变异程度)

- 计算:
- 离差平方和通常表示为SS:
- 离差平方和可以用来计算方差,标准差等。
- 离差,是同一个变量的属性描述
- 可能是关于 真实值的离差,也可能是预测值的离差
- 可能是,真实值的离差,求平均数,就是真实值的方差
- 也可能是预测值的离差,求平均数,就是预测值的方差
8 偏差 bias
8.1 偏差的定义
- 偏差:描述的是预测值(估计值)的期望与真实值之间的差距。
- 偏差越大,越偏离真实数据。
- 每一个真实值,可能有N个估计值/预测值
- 而这N个估计值只有1个期望值,
- 所以偏差是比较每1个真实值和其估计值的期望之间的误差。
- Bias=E(f(xi))-Y
8.2 偏差的公式和求法
- Bias=E(f(xi))-Y
- 其中i=1~n,E(f(xi))是n个 f(xi)的期望
- 每一个真实值,可能有N个估计值/预测值,而这N个估计值只有1个期望值,
- 所以偏差是比较每1个真实值和其n个估计值的期望之间的误差。
9 方差(variance/deviation Var,D(X) )是平均值
9.1 方差的定义
定义1:是离差平方和的期望/平均值。
定义2:方差, 即预测数据与预测数据均值之差的平方和,代表拟合数据本身得分散程度
- 方差:描述的是预测值的变化范围,离散程度,也就是离其(预测值整体)期望值的距离。
- 方差越大,数据的分布越分散
- 预测值和真实值完全没关系。
- 方差小只是一群估计值自身的属性,够不够聚拢,发散是否厉害。
- 有可能方差很大也可能很小,但偏离真实值很远的情况。
9.1.1 关于平均值=期望
- 一般意义上,期望=平均值
- 期望=平均值
- 期望=概率加权平均值
- 期望=加权平均值
- 计算为,每个样本值与全体样本均值的差的平方和的平均值。
9.2 方差的公式:
因为离差里可以选不同的的标准值,而方差选的标准值就是 平均值。
- 方差=Σ(y^-y^_)**2/n 或者 Σ(y^-y^_)**2/(n-1)
- 统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数。
- 概率论中方差用来度量随机变量和其数学期望(即均值)之间的偏离程度。
- 根据离差平方(SS)可以描述为:
- 总体方差=SS/n
- 样本方差=SS/(n-1)
- 通俗点讲就是如果计算的数据集不是总体, 只是部分样本, 使用分母是n公式计算的样本方差通常会小于总体方差, 使用分母是n-1的公式计算的样本方差与总体方差更接近。
- 说的更专业一点就是,n-1是自由度,1是变量数量。在计算RMSE的时候变量是两个,那么样本RMSE的无偏估计的分母就是自由度(n-2)。
9.2.1 总体方差
- δ**2=Σ(xi-U)**2/N,其中i=1~n
- 如果还是我们要看的目标是预测值f(xi) ,那么把f(xi) 替换xi就得到
- 如下对预测值f(xi)的方差
- δ**2=Σ(f(Xi)-average(f(Xi)))**2/n
- #从公式里看和真实值没有丝毫关系,只和 预测值 f(xi) 这一群数据有关系
9.2.2 样本方差(实际方差 /统计方差)
- 实际中,总体平均数很难获得
- 统计中的方差(样本方差)是每个样本值与全体样本值的平均数之差的平方值的平均数
- 如果还是我们要看的目标是预测值f(xi) ,那么把f(xi) 替换xi就得到
- 如下对预测值f(xi)的方差
- S**2=Σ(xi-Ux)**2/(n-1)
- S**2=Σ(f(Xi)- average(f(Xi)))**2/(n-1)
- #从公式里看和真实值没有丝毫关系,只和 预测值 f(xi) 这一群数据有关系
9.3 方差的意义:
- 离差平方和的大小受到样本总量大小的影响,不利于不同数据集的比较。
- 离差平方和的期望(方差)可以表示数据离散程度。
-
方差 variance 本质是一个平均值,一个平方和的均值
- 方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。
- 方差越大,数据的分布越分散,
- 方差小只是一群估计值自身的属性,够不够聚拢,发散是否厉害。
- 有可能方差很大也可能很小,但偏离真实值很远的情况。
- 标准差= sqrt(方差)
10 误差=方差+偏差**2+残差σ,把三者统一起来
残差与误差的区别
残差和误差的区别在于一个是估计值一个是真值。
10.1 误差的组成成分
- 误差Err / 偏差Bias / 方差Var / 不可避免的误差σ之间,是什么关系?
- 误差Err = 偏差Bias^2+ 方差Var +不可避免的误差σ
- Error=Bias^2+Variance+Irreducible Error
10.2 irreducible Error
Irreducible Error,用ε / σ 表示
即不可避免误差部分,刻画了当前任务任何算法所能达到的期望泛化误差的下限,即刻画了问题本身的难度;
- irreducible Error,基于总体分布
- 因为是总体分布的离散度,所以Irreducible不可避免;
- 总体用模型Y=f(X)+ε描述。
10.3 Bias:基于样本分布
- Bias,即偏差部分,刻画了算法的拟合能力,Bias偏高表示预测函数与真实结果相差很大;
- 总体点和样本点 : 预测值样本的期望值 和观测值之间的差距
- Bias,即偏差部分,刻画了算法的拟合能力
- Bias偏高表示预测函数与真实结果相差很大;
10.4 Var:基于样本分布
- 预测点集/样本点集的离散度:预测值本身的离散程度,和观测值无关。
- Variance,即方差部分,则代表 “同样大小的不同数据集训练出的模型” 与 “这些模型的期望输出值” 之间的差异。
- 训练集变化导致性能变化,Var高表示模型很不稳定。
10.5 误差的公式可以统一两者的意义
偏差和方差可以统一在一起
- 误差=偏差**2+方差+ irreducible error
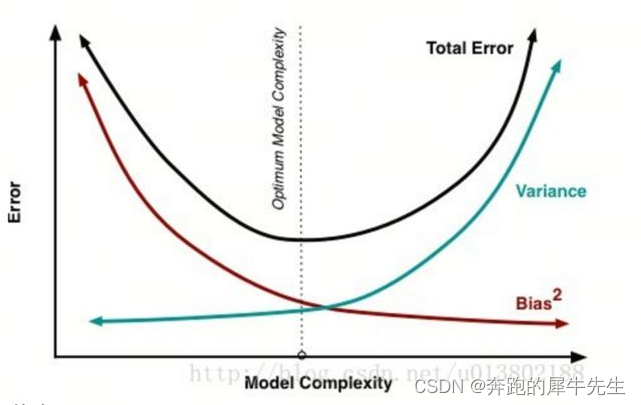
10.6 偏差和方差的区别
网上流传了很多的图,解释的很清楚了

10.7 偏差和方差的一般性应用的区别
测各种预测模型的比较来说
- 一般来说,如果模型越复杂,参数越多,偏差越小,但方差可能会越大,可能存在过拟合情况
- 一般来说,如果模型越简单,参数越小,偏差越大,但方差可能会越小,可能存在拟合不够的情况。
- 而理论上理想中的模型是,偏差低,方差也低的模型。
11 标准差(Standard Deviation,SD)
- 定义:是方差的平方根。
- 意义:由于方差是离差平方和的均值,平方后数值大小与原数值大小范围相差太大,所以常用方差开根号换算回来。平均数相同的,标准差未必相
- 如是总体(即估算总体方差),根号内除以n(对应excel函数:STDEVP);
- 如是抽样(即估算样本方差),根号内除以(n-1)(对应excel函数:STDEV);
- 函数:std
- 标准差= sqrt(方差)
12 变异系数= 标准差/均值
计算为 标准差与均值的比。
其中,分子是总体标准差,分母指数据的平均数。

13 标准误/ 标准误差(Standard Error of Mean,SE)
13.1 标准误差的定义
定义:是多个样本平均数的标准差。
意义: 是描述均数抽样分布的离散程度及衡量均数抽样误差大小的尺度,反映的是样本均数之间的变异。
注意:
- 1. 标准误不是标准差。
- 2. 标准误能够通过标准差计算。
- 3. 在实验中单次测量总是难免会产生误差,为此我们经常测量多次,然后用测量值的平均值表示测量的量,并用误差条来表征数据的分布,其中误差条的高度为±标准误差。
13.2 公式:
虽然标准误是平均值的标准差。
理论上一定是有多组数据,比如多次抽样,有多组数据对应的均值
但实际上,经常也只做1次抽样检测,用公式计算标准误。