基本介绍
组基轨迹建模(Group-Based Trajectory Modeling,GBTM)(旧名称:Semiparametric mixture model)
历史:由DANIELS.NAGIN提出,发表文献《Analyzing Developmental Trajectories:A Semiparametric,Group-Based Approach》
GBTM能够将一群人的轨迹分类并生成数个具有代表性的运动轨迹模型,然后对每个轨迹模型进行分析,以了解人们的运动特征、生理水平和风险等级等。GBTM的核心思想是将人群分成几组,每组中的人员都具有类似的运动规律,这些规律被用于描述和预测他们未来的运动轨迹,从而为个人和群体的健康管理提供更科学的依据。
- 主要用于分析纵向数据,探索总体中的异质性
- 原理:假定总体存在异质性,即总体中存在若干个不同发展轨迹或模式的潜在亚组
- 目的:探索总体中包含有多少个发展趋势不同的亚组,并确定各亚组的发展轨迹
- 轨迹的等级与形状由模型的回归参数决定,模型的回归参数通过最大似然比估计
组轨迹建模流程
组轨迹模型的建立是需要不断建立、反馈、修正的过程。
1.拟合1~6组轨迹模型,每个轨迹分别拟合线性、平方和立方
2.通过模型计算模型参数估计,剔除无意义的估计项,重新拟合。
3.通过比较不同模型间的拟合评价指标和专业可解释性选择合适的轨迹。
4.评价模型内充分性。
实现方法
1. 基于Stata 【traj包】
安装包命令
new install traj, force数值格式: 目标变量的纵向指标+采集时间
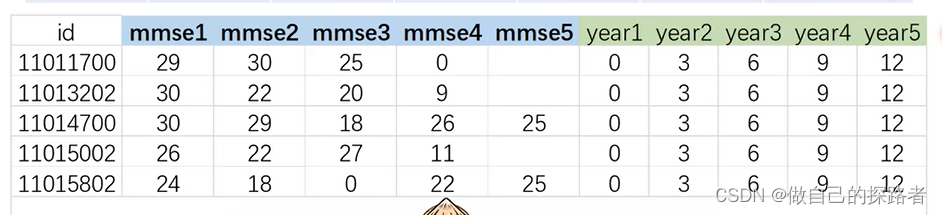
导入数据
import delimited ".\data.csv", clearGBTM分析
# GBTM分析
# s1 到 s5 和 t1 到 t5 是变量名,s1到s5作为重复测量的自变量,t1到t5作为时间变量
traj,var(s1-s5)indep(t1-t5)model(cnorm) min(0) max(30)order (3 3 2)
traj: 表示进行轨迹分析。var(s1-s5): 指定要进行轨迹分析的变量,这里使用s1到s5作为变量。indep(t1-t5): 指定作为独立变量的时间变量,这里使用t1到t5作为时间变量。model(cnorm): 指定模型类型为连续型的正态模型。min(0) max(30): 指定轨迹分析的时间范围为0到30。order(3 3 2): 指定轨迹分析中的多项式次数,这里选择三次多项式。
# 绘图
traj plot,x title(YearsSince Baseline) y title(MMSEscore)cix label(0(3) 12) ylabel
(0(5)30)
traj: 表示进行轨迹分析。var(s1-s5): 指定要进行轨迹分析的变量,这里使用s1到s5作为变量。indep(t1-t5): 指定作为独立变量的时间变量,这里使用t1到t5作为时间变量。model(cnorm): 指定模型类型为连续型的正态模型。min(0) max(30): 指定轨迹分析的时间范围为0到30。order(3 3 2): 指定轨迹分析中的多项式次数,这里选择三次多项式,多次重复拟合

order参数的设定【重要】
确定亚组数及其轨迹需要多次重复拟合,才能获得最佳轨迹数目及形状。一般先从较少亚组数开始拟合,每一亚组先从高阶开始,若高阶参数无统计学意义则去除继续拟合低阶参数
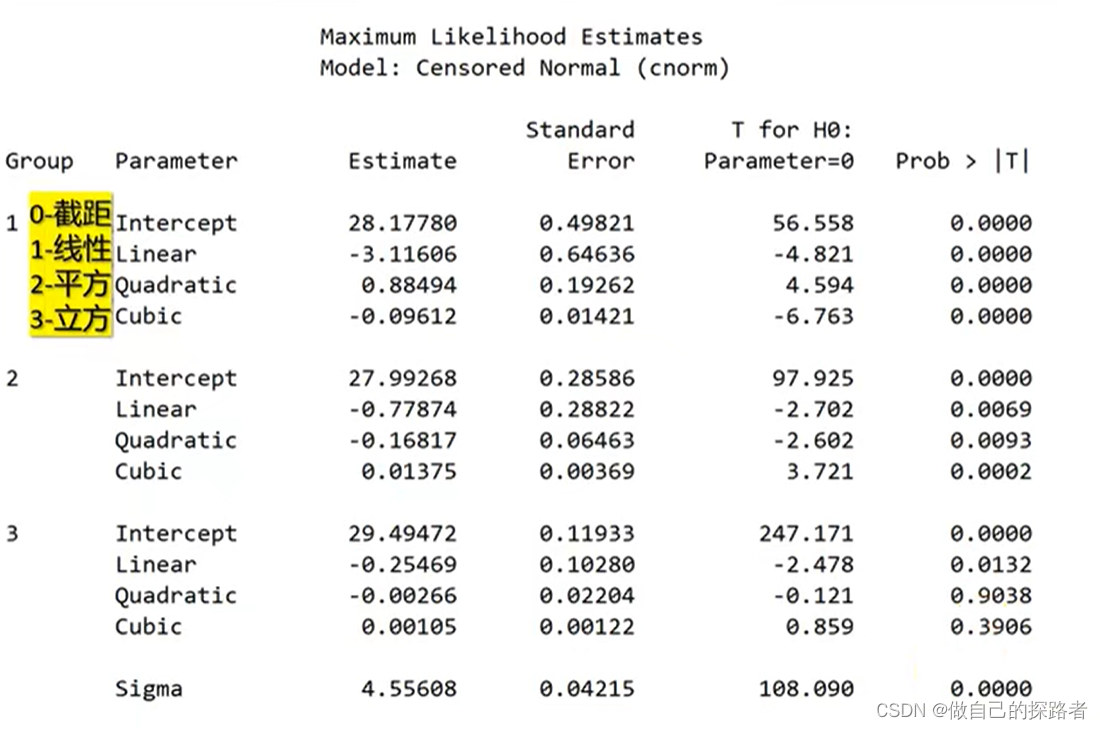
多次尝试寻找最佳参数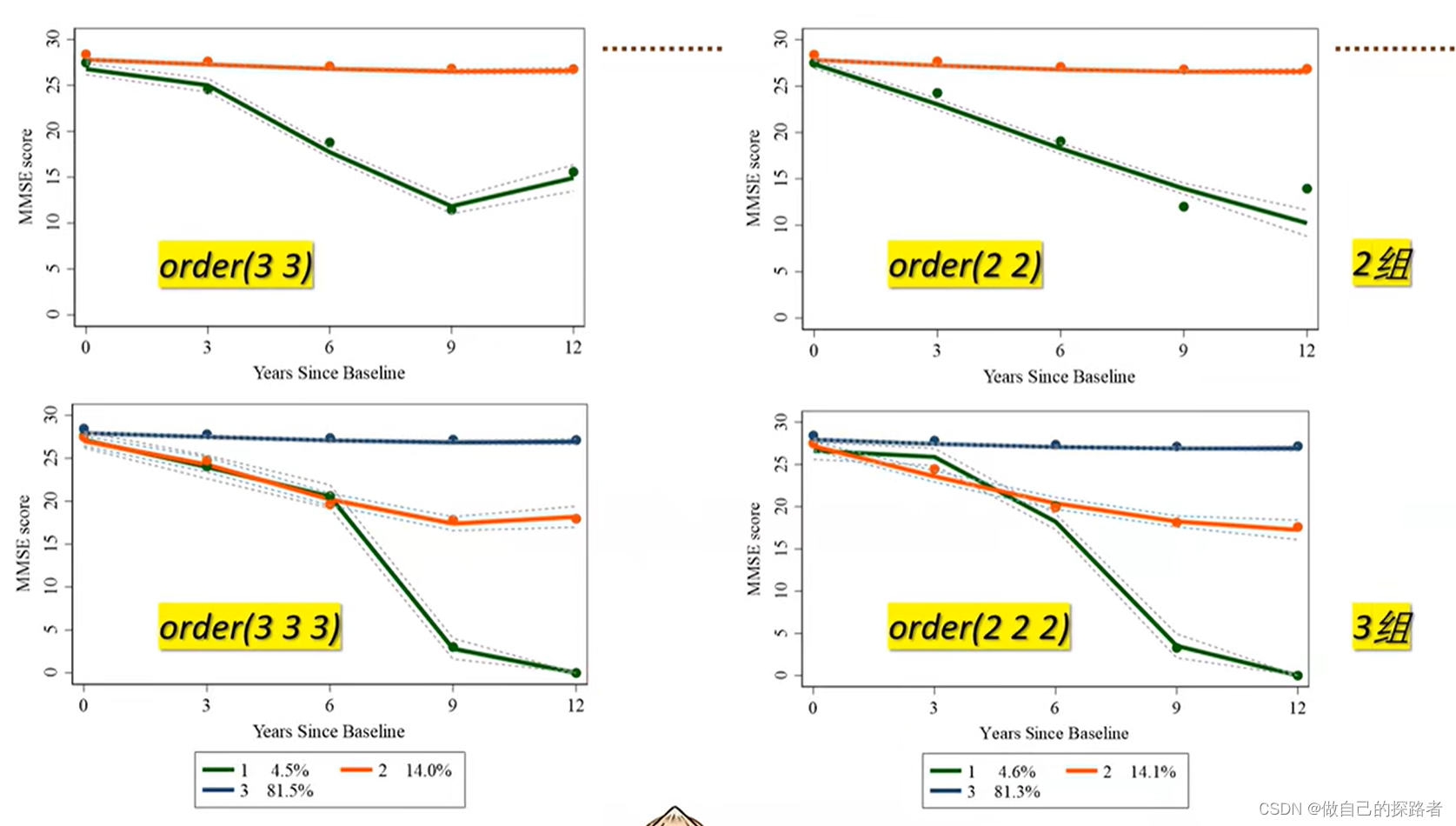 参考指标: 查看Maximum Likelihood Estimates Model:Censored Normal(c norm) 的输出表格
参考指标: 查看Maximum Likelihood Estimates Model:Censored Normal(c norm) 的输出表格
通过查看Prob > |T| 【即P值】,一般需要选取该分组的最高阶具有统计学意义。
最佳分组数量如何确定?
贝叶斯信息标准(Bayesianinformationcriterion,BIC)
- BIC值绝对值越小--趋0, 表示模型拟合程度越好
- 查看方式:查看Maximum Likelihood Estimates Model:Censored Normal(c norm) 的输出表格的最下方
平均验后分组概率(average posterioror ob ability,AvePP)
- 判定每一个体被归属为特定轨迹的概率,越接近1越好
- 反映每一个体被分到相应亚组的后验概率
- >0.7时,作为模型可以接受的标准
- 查看方式:需要命令实现
list_traj_Group-_traj_ProbG1
2. 基于R 【trajeR包】
TrajeR 支持几种数据分布
- 删失(或常规)正态分布 【Censored (or regular) Normal distribution】代码中简称为CNORM ;
- 零膨胀泊松分布 【Zero Inflated Poisson distribution】;
- 泊松分布【Poisson 】;
- 伯努利分布【Bernouilli 】;
- Beta分布(只包括可能性) ;
- 非线性回归 【Non linear regression】
每个亚组的运动轨迹采用多项式建模,也可以采用非线性模型。
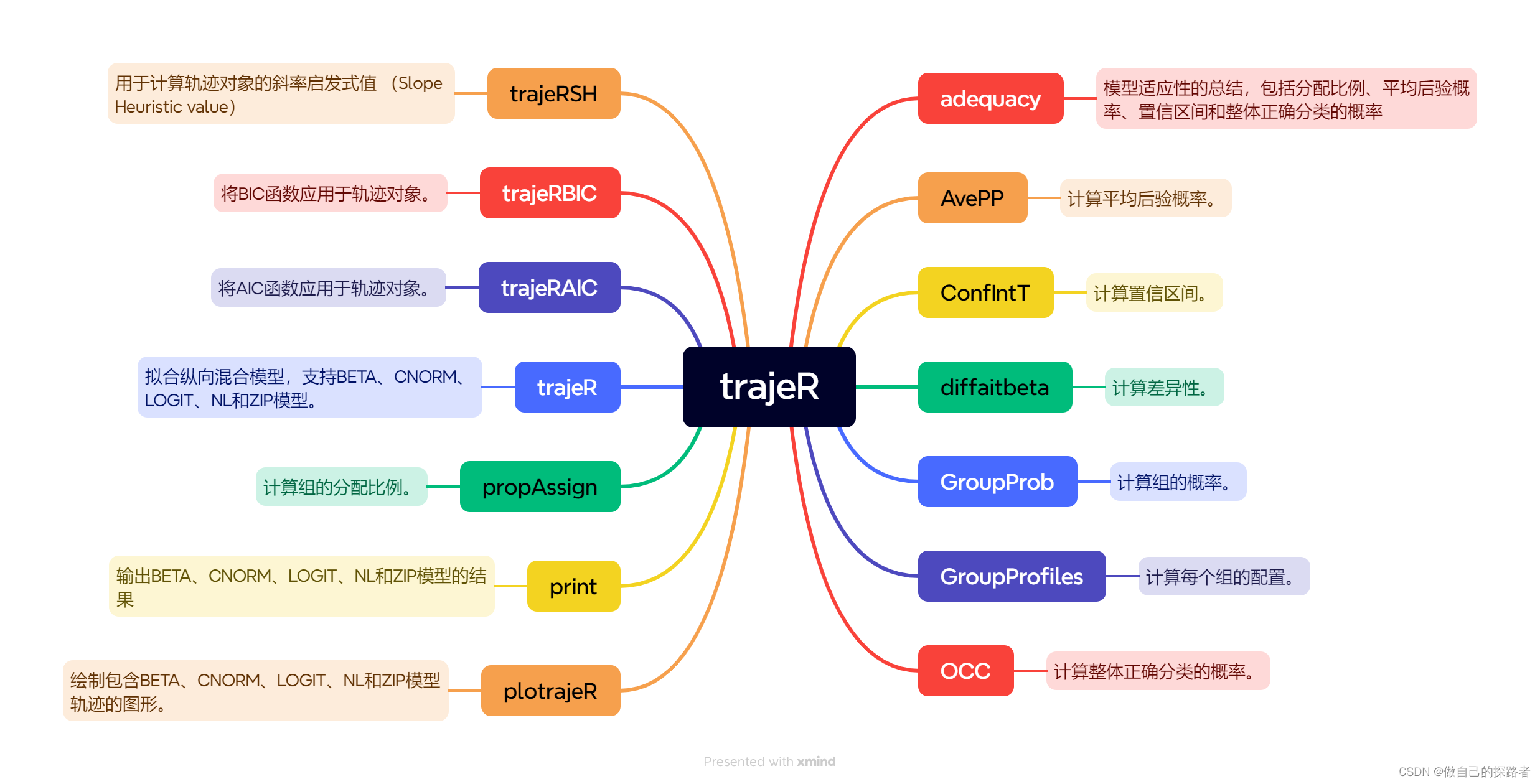
包的主要函数
安装与加载
## install dev version of trajeR from github
devtools::install_github("gitedric/trajeR")
## load trajeR package
library(trajeR)trajeR() 最重要的函数
trajeR(
Y,
A,
Risk = NULL,
TCOV = NULL,
degre = NULL,
degre.nu = 0,
degre.phi = 0,
Model,
Method = "L",
ssigma = FALSE,
ymax = max(Y, na.rm = TRUE) + 1,
ymin = min(Y, na.rm = TRUE) - 1,
hessian = TRUE,
itermax = 100,
paraminit = NULL,
ProbIRLS = TRUE,
refgr = 1,
fct = NULL,
diffct = NULL,
nbvar = NULL,
ng.nl = NULL,
nls.lmiter = 50
)参数
Y: 模型中自变量的矩阵。
A:模型中时间变量的矩阵。
Risk:一个可选的矩阵,修改属于群的概率。默认情况下,它的值是一个矩阵,其中一列的值为1
TCOV:一个可选的矩阵,包含影响轨迹本身的时间协变量。默认值为 NULL。
degre:整数向量,每个多项式中最高次幂的指数,即order参数的设定。degre的个数表示设定的组别数量,degre中第 i 个数字分别代表 第 i 组的最高次幂的指数degre.nu:整数向量。 ZIP 模型中所有泊松部分的度。
degre.phi:整数向量。 BETA 模型中 β 参数的度。
Model: 指定模型,该值为 LOGIT :混合模型的 LOGIT;截尾正态混合模型的 CNORM 或零膨胀泊松混合模型的 ZIP。
Method:指定用于查找模型参数的方法。最大似然估计法则为 L,内含拟牛顿法的期望最大化方法的值为 EM,迭代加权最小二乘法的期望最大化方法的值为 EMIWRLS。
sigma:默认情况下,它的值为 FALSE。对于 CNORM 模型,指出我们是否需要对所有正态分布函数使用相同的 σ。
ymax:对于 CNORM 模型,指示数据的最大值。它只关注有删失数据的模型。默认情况下,它的值是数据加1的最大值。
ymin:对于 CNORM 模型,指示数据的最小值。它只关注有删失数据的模型。默认情况下,它的值是数据的最大值减1。
hessian:指出我们是否要计算hessian 矩阵。默认是FALSE。如果使用的方法是似然的,hessian 是通过反转信息的费舍尔矩阵计算。为了避免数值奇异矩阵,我们利用 MASS 包中的 ginv 函数求出伪逆矩阵。如果方法是 EM 或 EMIWRLS,则采用路易斯法计算hessian 。
itermax:表示优化函数或 EM 算法的最大迭代次数。
paraminit:初始参数向量。在默认情况下,trajeR 根据范围或标准差计算初始值。
ProbIRLS:指出了预测器概率搜索中的起诉方法。如果 TRUE (默认)我们使用 IRLS 方法,如果 FALSE 我们使用优化方法。
refgr:引用组的数目。默认为1。
fct:非线性模型中函数 f 的定义
diffct:非线性模型中函数 f 的微分
nbvar:非线性模型中变量的个数。
ng.nl:非线性模型的亚组数
nls.l miter:非线性模型的组数
输出结果
beta:参数 β 的向量delta:时间协变量theta:用时间协变量sd:参数的标准差的向量。tab:一个包含所有参数和标准差的矩阵Likelihood:由参数得到的似然的实数ng,:由参数得到的似然的实数model:由参数得到的似然的实数method:所用方法的字符串。
# 代码示例
solL = trajeR(data[,1:5], data[,6:10], ng = 3, degre=c(2,2,2),
Model="CNORM", Method = "L", ssigma = FALSE,
hessian = TRUE)
拟合模型
#读取数据
data = read.csv(system.file("extdata", "CNORM2gr.csv", package = "trajeR"))
data = as.matrix(data)
# 拟合模型:拟合2个组,第一个组的最高次方为平方,第2个组的最高次方也为平方。
sol = trajeR(Y = data[, 2:6], A = data[, 7:11], degre = c(2,2), Model = "CNORM", Method = "EM")
# 结果输出
print(sol)
# 绘图 【如下】
plotrajeR(sol)# 结果输出
> print(sol)
Call TrajeR with 2 groups and a 2,2 degrees of polynomial shape of trajectory.
Model : Censored Normal
Method : Expectation-maximization
group Parameter Estimate Std. Error T for H0: Prob>|T|
param.=0
--------------------------------------------------------------------
1 Intercept 11.04411 2.45556 4.49759 1e-05
Linear -9.31101 1.88182 -4.94787 0
Quadratic 0.94224 0.30679 3.07128 0.00237
2 Intercept -6.00923 2.61924 -2.29426 0.02261
Linear 6.98117 1.99415 3.50082 0.00055
Quadratic -1.14198 0.32309 -3.5345 0.00049
--------------------------------------------------------------------
1 sigma1 4.96653 0.37773 13.14835 0
2 sigma2 6.60139 0.38434 17.17574 0
--------------------------------------------------------------------
1 pi1 0.38688 0.0697 5.55096 0
2 pi2 0.61312 0.0697 8.79716 0
--------------------------------------------------------------------
Likelihood : -830.0071 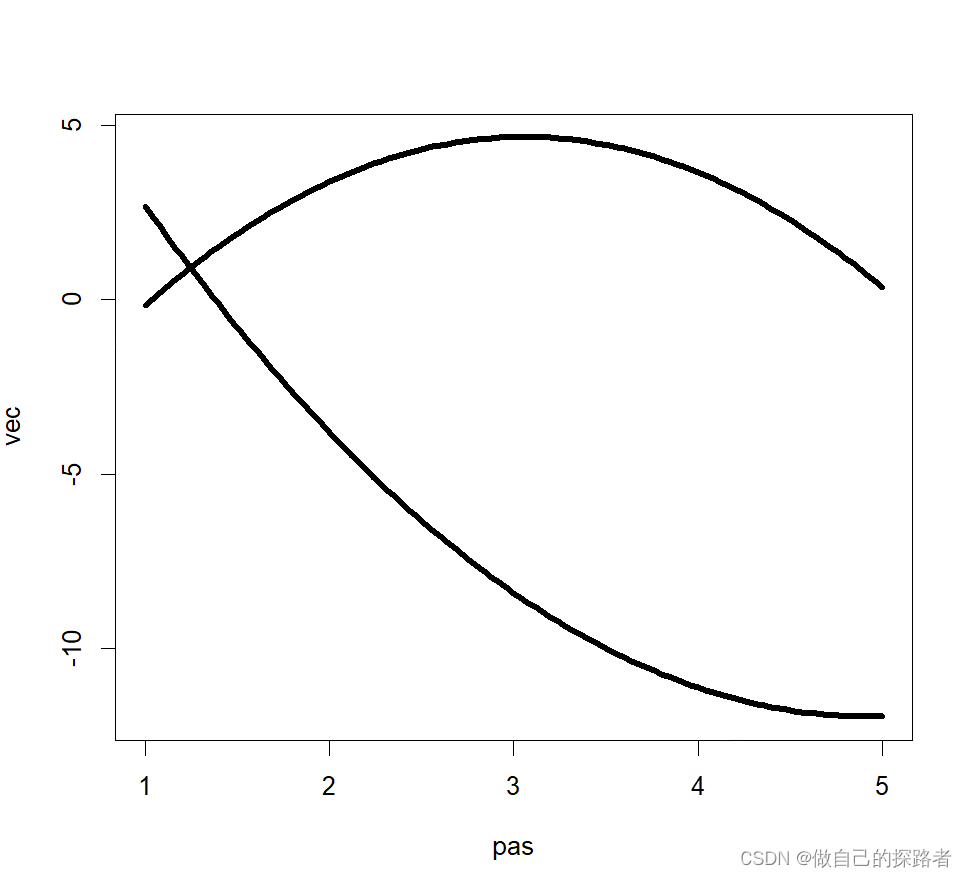
模型评估
用于评估模型的充分性(Adequacy of the model)。adequacy() 函数可以计算五种方法的总结结果,包括:分配比例(assignment proportion)、平均后验概率(average posterior probability)、置信区间(confidence interval)、正确分类的几率(odds of Correct Classification)。
adequacy(sol, Y = data[, 2:6], A = data[, 7:11])
# 结果输出
# 1 2
# Prob. est. 0.4436785 0.5563215
# CI inf. 0.2230186 0.4482696
# CI sup. 0.5462226 0.7746488
# Prop. 0.3800000 0.6200000
# AvePP 0.9837616 0.9789556
# OCC 96.0110285 29.3529000
分组概率情况
# 每个个体分别分配到每个组的概率
GroupProb(sol, Y=data[, 2:6], A=data[, 7:11])
head(GroupProb(sol, Y=data[, 2:6], A=data[, 7:11]))
# Gr1 Gr2
# [1,] 2.205715e-09 0.9999999978
# [2,] 9.985604e-01 0.0014396289
# [3,] 1.121664e-09 0.9999999989
# [4,] 9.510136e-03 0.9904898637
# [5,] 9.996207e-01 0.0003792992
# [6,] 4.502507e-06 0.9999954975
# 计算每个亚组的个体的比例
propAssign(sol, Y = data[, 2:6], A = data[, 7:11])
# 1 2
# [1,] 0.38 0.62批量建模参考
data = read.csv(system.file("extdata", "CNORM2gr.csv", package = "trajeR"))
data = as.matrix(data)
degre = list(c(2,2), c(1,1), c(1,2), c(2,1), c(0,0), c(0,1), c(1,0), c(0,0), c(0,2), c(2,0))
sol = list()
for (i in 1:10){
sol[[i]] = trajeR(Y = data[, 2:6], A = data[, 7:11],
degre = degre[[i]], Model = "CNORM", Method = "EM")
}
资料来源
GitHub - gitedric/trajeR: Group Based Modeling Trajectory
trajeR: Fitting longitudinal mixture models in trajeR: Group Based Modeling Trajectory
纵向数据分析之组轨迹模型(GBTM)_哔哩哔哩_bilibili
如何利用重复测量的数值变量,评估其发展轨迹/变化趋势——基于Stata软件的组基轨迹建模Group-Based Trajectory Modeling方法介绍_哔哩哔哩_bilibili