知识图谱辅助的个性化推荐系统
将从下面4个方面展开:
推荐系统的基础知识知识图谱辅助的推荐方法介绍基于embedding的知识图谱推荐方法混合型知识图谱推荐方法
推荐系统的基础知识
1、什么是推荐系统
在当前互联网时代,推荐系统是所有面向用户的互联网产品的核心技术,只要产品是面向用户的,那么就有推荐系统的需求。
推荐系统是解决信息爆炸问题,给用户推荐一个用户感兴趣的小规模集合。用户在大量商品中,不知道如何选择,推荐系统是替用户做这个选择,猜用户的兴趣,然后给用户推荐一个小规模的商品集合,这样用户就不会迷失在大量商品中。
举几个推荐系统的例子。如下图是imdb系统中的电影推荐,imdb会推荐用户可能更感兴趣的电影。
如下图是亚马逊系统中的图书推荐,给用户推荐和用户更相关,用户更感兴趣的书籍。
如下图是booking.com系统中旅游景点的推荐,给用户推荐更感兴趣景点。
如下图是我们更为熟悉的推荐系统的例子,知乎,抖音,头条等系统,都有推荐功能。

2、推荐系统的实现方法
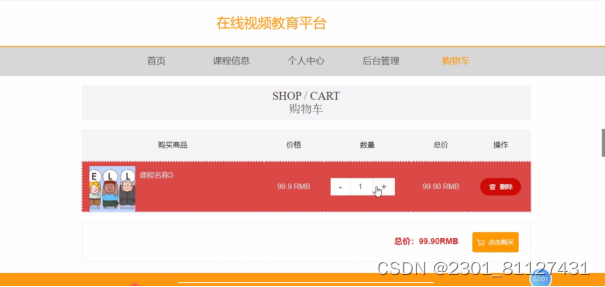
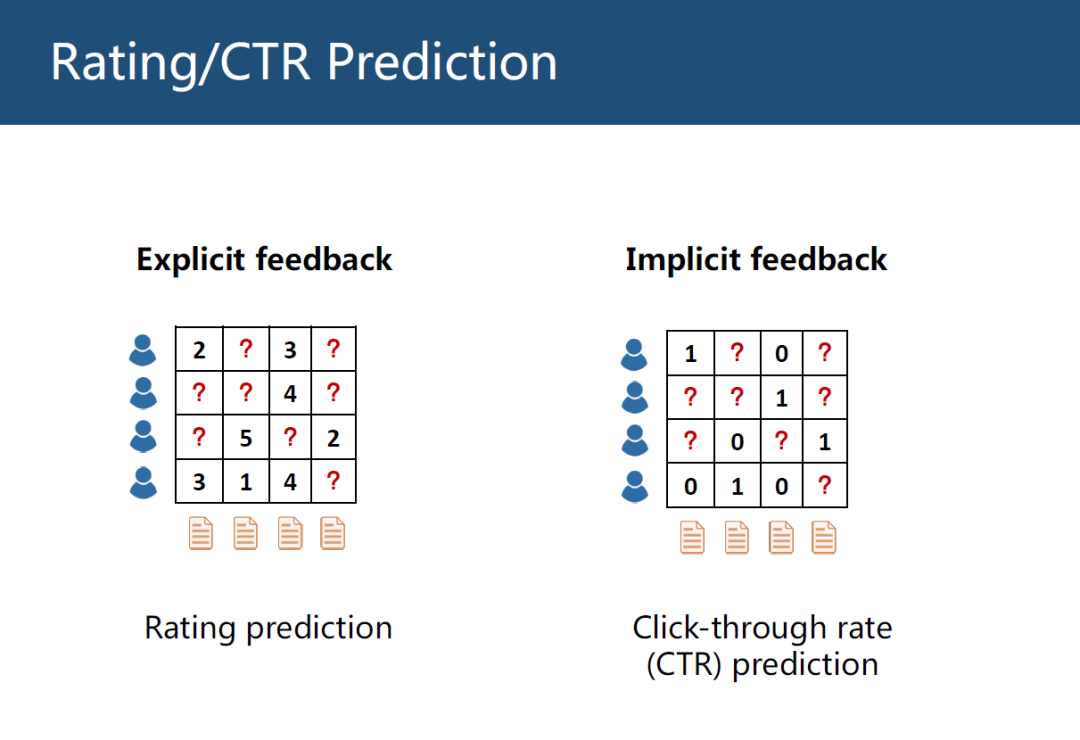
推荐系统主要有2个任务,一个是评分预测(Rating Prediction)。如下图左边是评分预测的例子,横坐标是物品,纵坐标是用户。表格是用户对物品的打分,这个评分可以显示的反应用户对物品的喜好层度,1表示很不喜欢,5表示很喜欢。推荐系统就是预测表格中问好处的缺失值,这就叫评分,这个评分叫显示反馈(Explicit feedback)。
另一个是点击预测(CTR Prediction)。右边是点击预测的例子,表格中只有0和1,0表示用户没有点击过,1表示用户点击过,这类数据叫隐式反馈(Implicit feedback),点击预测只能反映用户的非常弱的偏好层度,用户点击了不一定说明用户喜欢,比如逛淘宝,用户只是点击了某个物品就退出了,所以点击物品并不能代表用户的真实感受。
推荐系统有一个非常经典的方法叫协同过滤(Collaborative Filtering, CF),CF的核心是假设相似的用户有相似的偏好。
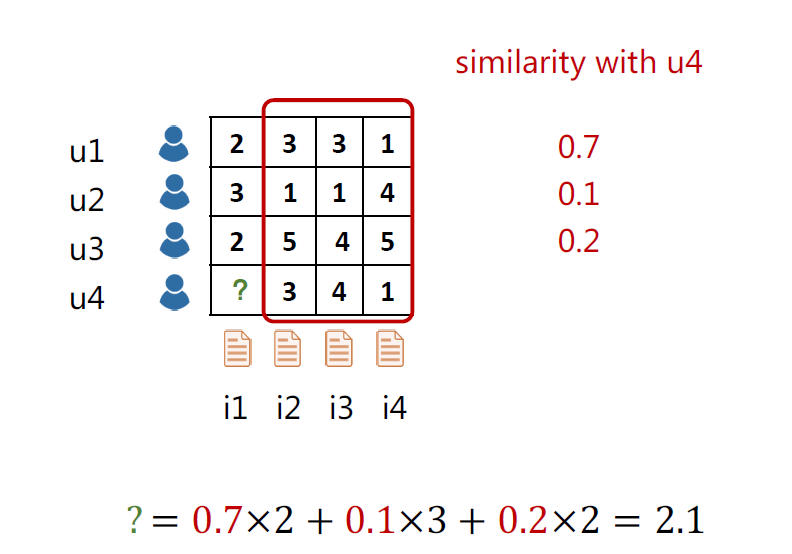
如下图为4个用户对4个物品的打分情况,来预测用户u4对物品i1的评分。通过这4个用户在其他3个商品(i2,i3,i4)的打分,计算出其他3个用户和u4用户的相似度,分别是0.7,0.1,0.2,然后用相似度加权平均其他3个用户在i1物品的打分,这样就得到了u4对i1的评分为2.1。
协同过滤CF是根据历史物品评分记录,计算出用户相似度,从而预测分数。CF是一种常见的方法,但存在以下2类问题。
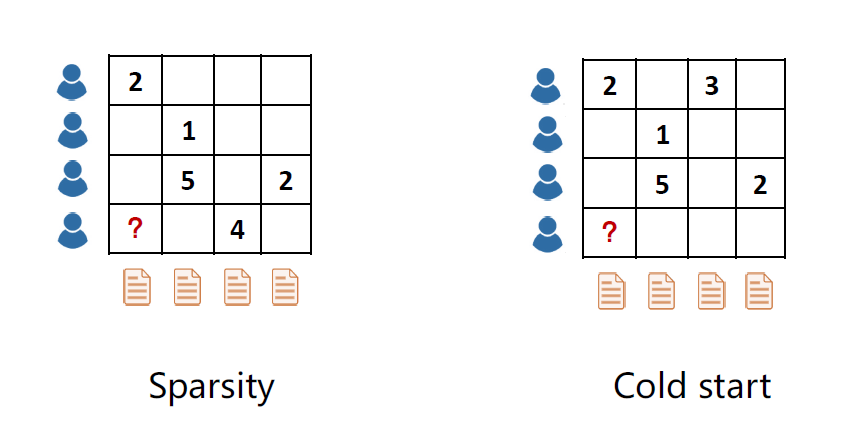
第一类是稀疏性问题(Sparsity),一般情况下评分分布是相当稀疏的,比如一个用户一辈子可能只会看几百部电影,但电影总数达百万量级,所以在计算相似度的时候会有困难。
第二类更进一步,冷启动问题(Cold start),当来了一个新的用户,这个新的用户没有历史记录,所以没法计算相似性,就没法做推荐。当注册新的app时,比如读书类的app,系统一开始会问你对哪些主题感兴趣,因为系统没有你的历史记录,刚开始没法给你推荐。
知识图谱辅助的推荐方法介绍
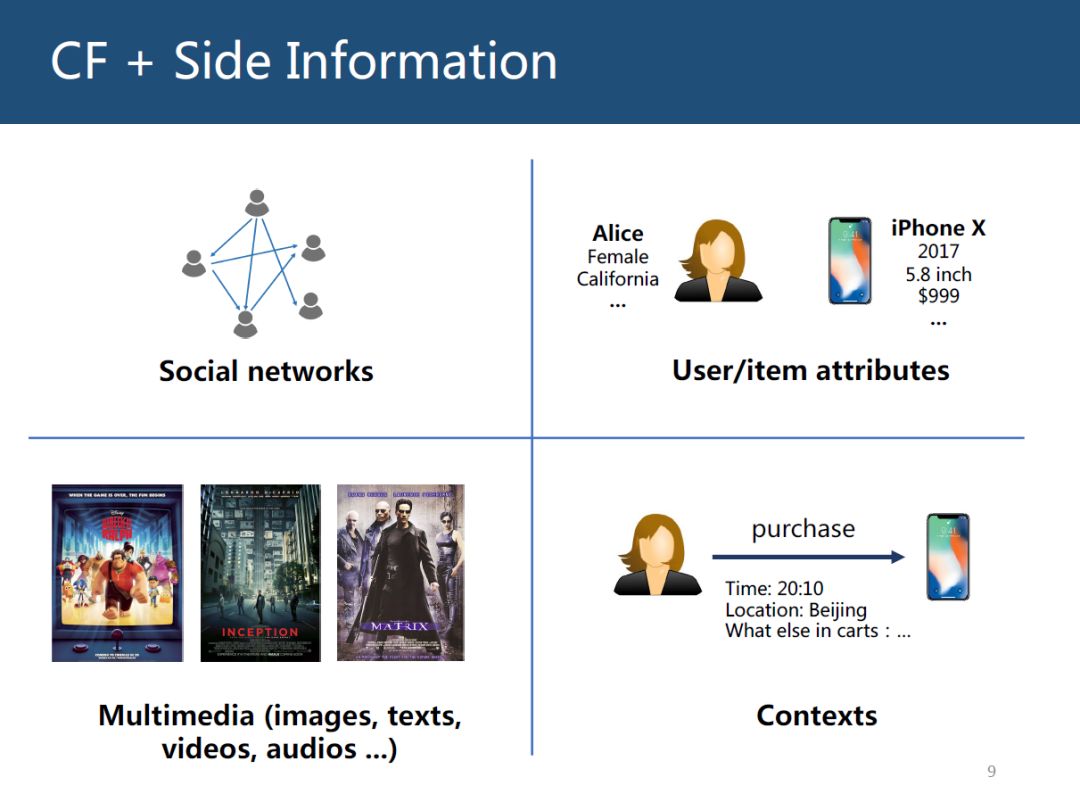
针对推荐系统出现的问题,我们的思路是既然用户和物品交互很稀少,甚至没有,那可以引入其他的一些信息,这些引入的信息叫辅助信息(Side Information)。如下图是4类非常常见的辅助信息:社交网络;用户或商品属性特征;多媒体信息,比如电影的海报,文本信息,视频音频信息等;上下文信息,假设一个用户购买了一个商品,购买记录的一些信息,比如时间、地点、当前用户购物车的其他物品信息等。
。
1、什么是知识图谱
知识图谱(Knowledge Graphs, KG)也是一种辅助信息。KG是一个有向异构图(heterogeneous graph),图中节点表示实体(entity),边表示关系(relation)。
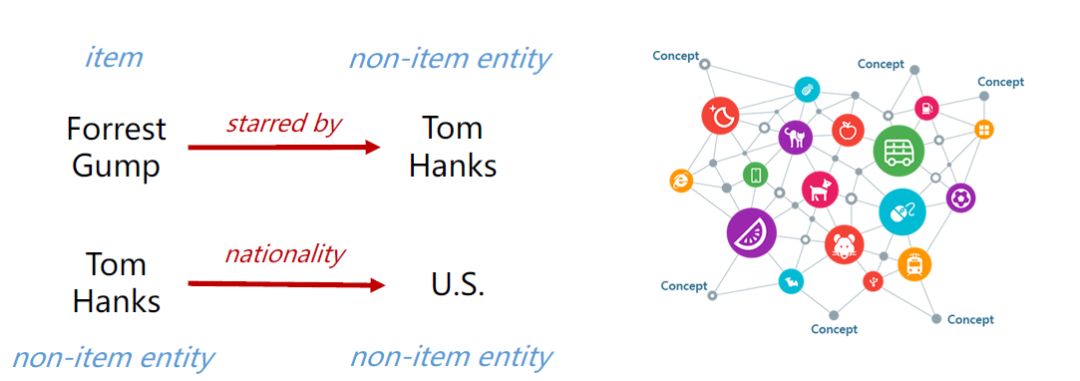
一个KG通常包含很多对三元组triple(head,relation,tail),其中head和tail是2个实体(entity),relation就是边。
如下图,推荐系统的item是电影,所以Forrest Gump是推荐系统的item,同时也是KG中的实体,KG中其他的实体并不是推荐系统的item, Forrest Gump这部电影的主演是Tom Hanks,虽然Tom Hanks是KG的实体(entity),但并不是item。把图中左边这些三元组(triples)组合起来,就变成了右边的一个很大的KG。
2、为什么要在推荐系统中使用KG
如下图,假设一个用户(最左边)看过3部电影(item),Cast Away, Back to the Future, TheGreen Mile,在KG中,可以将这3部电影连接到其他的一些事情上,比如Cast Away 这部电影的类别(genre)是冒险形(Adventure),Back to the Future的导演(directed)是Robert Zemeckis等,可以连接到很多其他non-item实体上,再从这些non-item实体又连接到item电影实体上,比如最右边的Interstellar, Forrest Gump,Raiders of the Lost Ark。
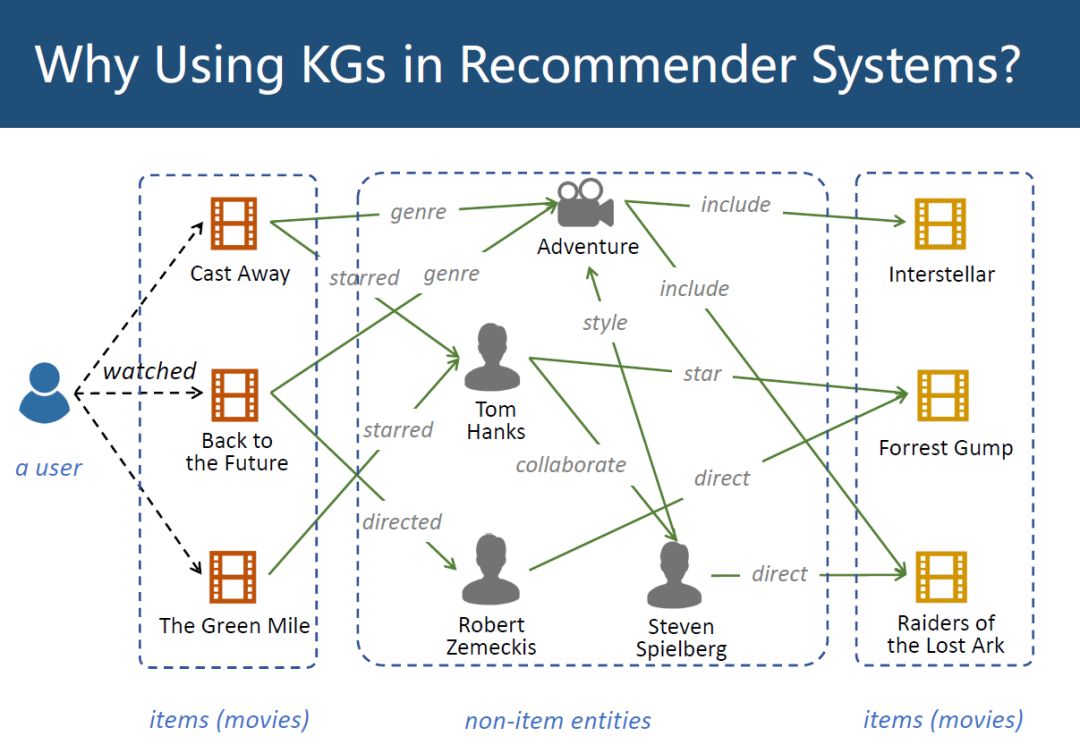
KG建立一个从用户已经看过的电影到没看过的电影的连接,而这些连接不是由用户的观看记录得来的。在CF里,实际上是把中间这块替换成了其他用户,用其他用户历史观看记录得到这些连接。KG提供了另外一种关于物品连接的信息来源的方法。
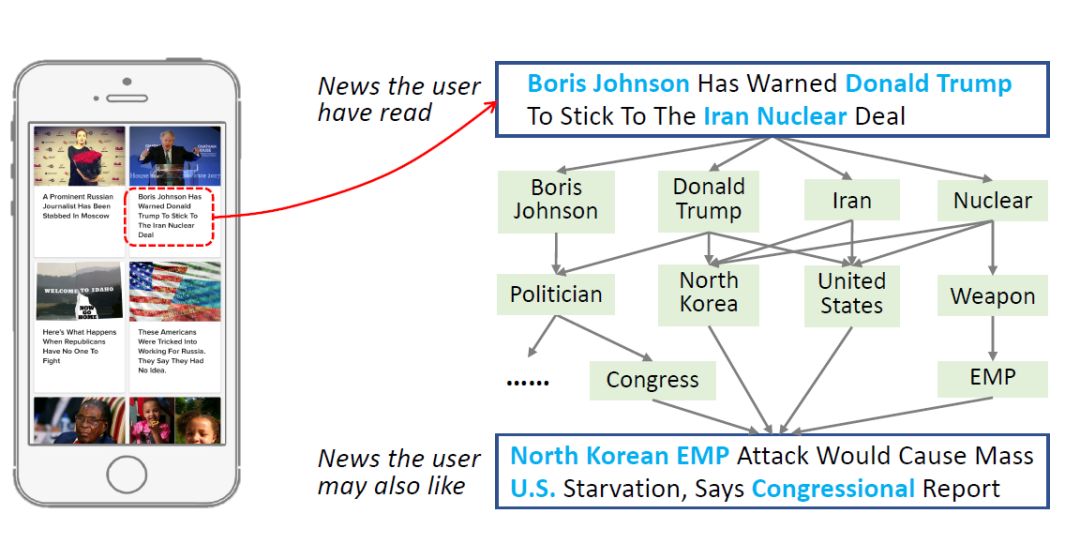
如上图是一个新闻推荐的例子,假设某个用户看过一条新闻,这个新闻的内容是:Boris Johnson Has Warned Donald Trump To Stick ToThe Iran Nuclear Deal。
从这条新闻中提取了4个实体,在KG中,可以对这些实体做进一步的扩展,做2次,做3次扩展,又会发现这些实体都指向另外一条新闻:North Korean EMP Attack Would Cause Mass U.S.Starvation, Says Congressional Report。
这2条新闻在字面上没有任何相似度,新闻的单词都不一样,但他们是很相关的,这个相关性体现在KG上,他们在低层是相关的,但这种相关性没法从字面意义上得到,这也是为什么要用KG,KG提供了一种item相似度的计算方式。
3、KG能给推荐系统带来什么
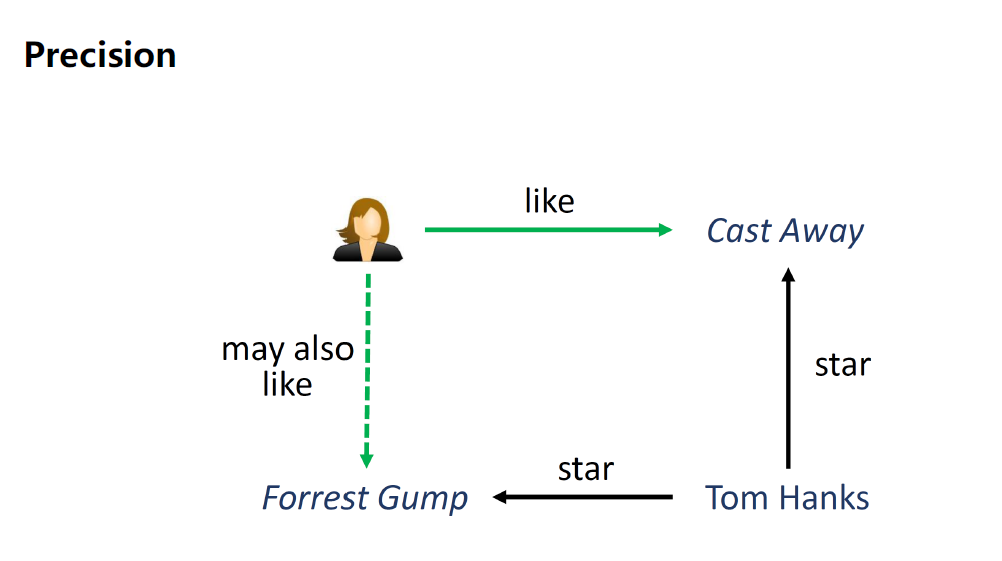
第1个提高推荐系统的精度(Precision),更准确的发现item之间的相似性,如下图2部电影,能通过Tom Hanks做个连接。
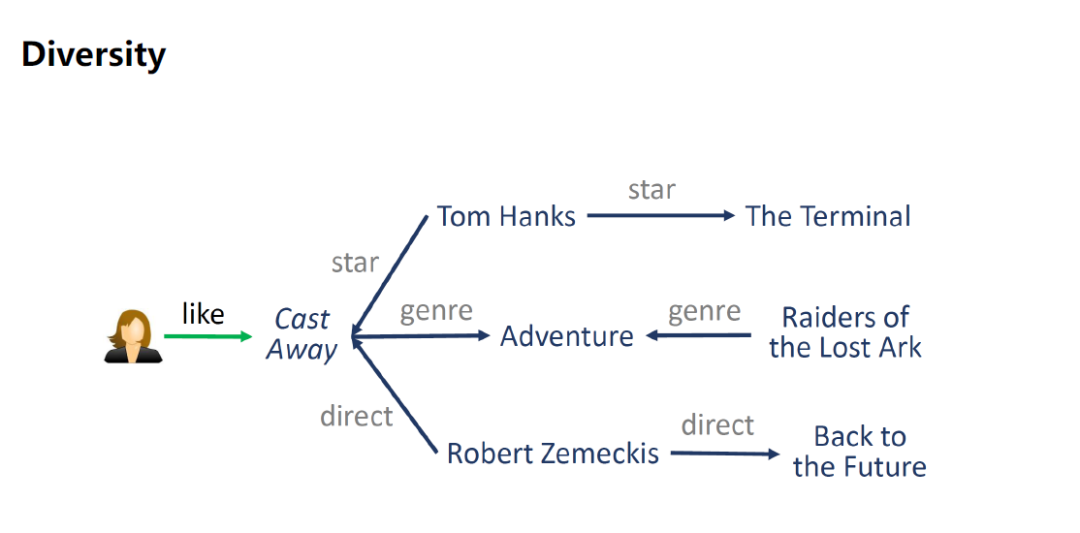
第2个提高推荐系统的多样性(Diversity),可以通过主演扩展,可以通过电影类别扩展,也可以通过导演扩展,总有一款是用户非常喜欢的。
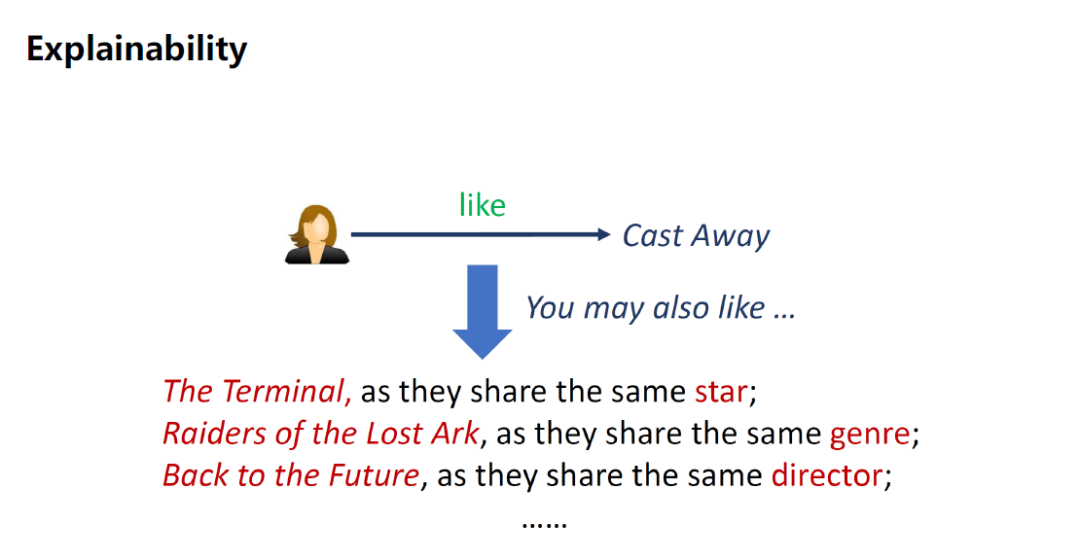
第3个是可解释性(Explainability),可以用KG的path来解释系统为什么会推荐这部电影,如下图某个用户喜欢Cast Away这部电影,系统会推荐The Terminal这部电影,因为他们有相同的主演。
4、知识图谱处理方法
KG 的处理方法中有一类方法叫KnowledgeGraph Embedding,KGE。KGE主要是对KG的每个实体(entity)和每个关系(relation)学习一个低维的特征。在KGE中有一个基于翻译的距离模型,Translational distancemodels。
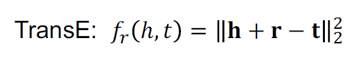
如上公式为TransE算法模型,对KG中的每一个tuple(h,r,t),学习到的entity embedding,relation embedding,使h+r约等于t,这的r相当于翻译作用,把h翻译成t,f函数对每个tuple的真实分值越小越好。
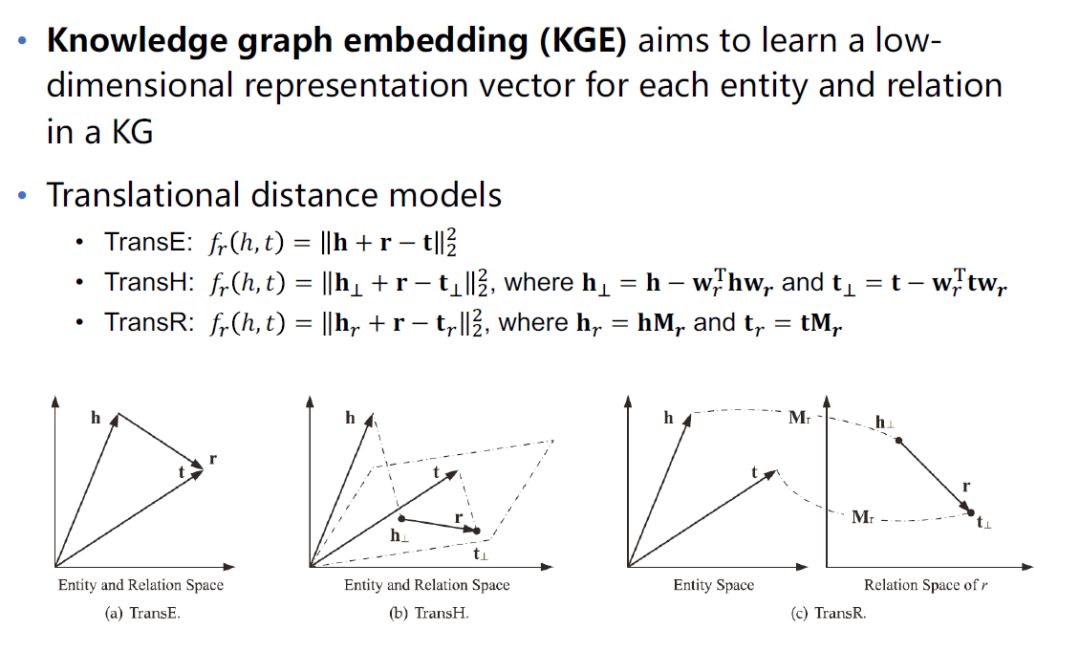
如图(a)是TransE模型,假设head对应的embedding加上relation对应的embedding等于tail对应的embedding。基于TransE有很多扩展模型,比如TransH, TransR。
TransH解决的是一对多的问题,某一个head和relation可能会对应多个tail,如图(b),把head和tail都投影到一个平面上,然后让它们在相对应的平面上做转换。TransR是把head和tail都投影到另外一个空间中,在新的空间里让h+r=t。 KG-aware Recommender Systems正式方法大概可以分为3类。
第一类是Embedding-based methods,基于embedding的方法,embedding是前面介绍的KG embedding,关于这类方法,下图列举了5篇论文,今天将会介绍第2篇和第5篇。

第二类是Path-based methods,基于KG计算路径的推荐方法,今天不会涉及这类方法。

第三类是Hybrid methods,结合embedding和path的方法,今天将介绍一下第1、3、4篇,第3、4是比较统一的方法。

5、知识图谱辅助的推荐系统问题定义
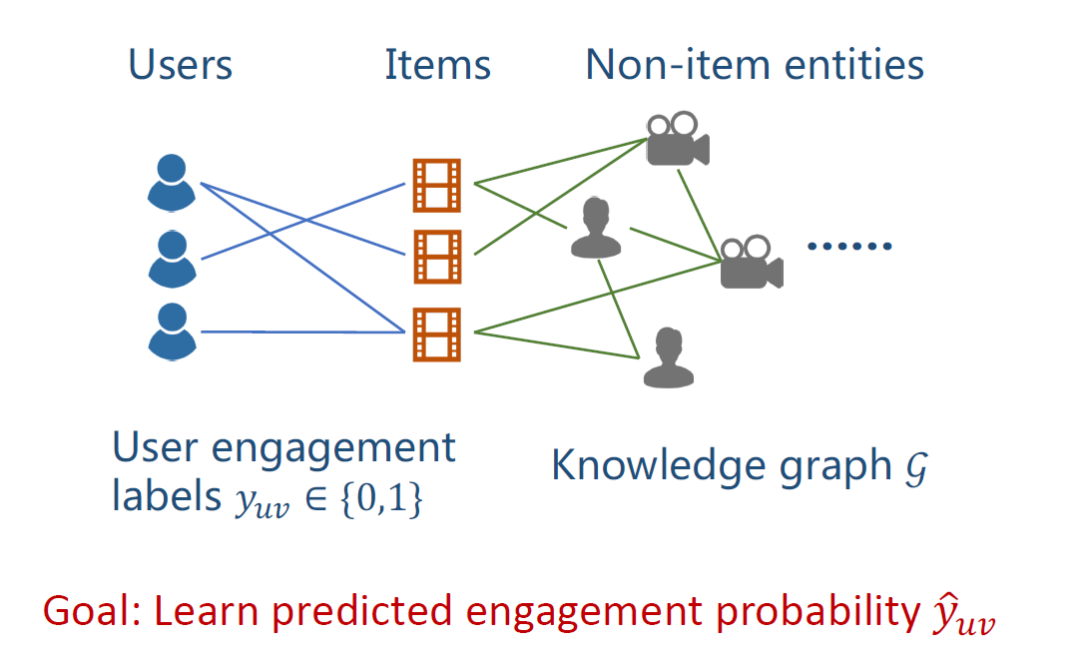
已知一个用户的集合Users,一个物品的集合Items,用户和物品之间的交互(relations,yuv),一个包括很多non-item实体的KG。图中yuv表示用户u对物品v的一个隐式反馈,即用户有没有点击过这个物品,目标是给定一个新的u-v对,预测点击率yuv。

公式定义如上图。用户集合U={u1,u2,...},物品集合V={v1,v2,...},交互矩阵(隐式反馈)Y矩阵Y={yuv ? {0,1} | u?U, v?V},KG包括实体(entity)和关系(relation),由很多三元组组成。
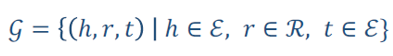
每个物品v在KG中可能对应一个或多个实体。物品是实体的一个子集。
目的是学习一个预测函数F,给定一对u,v,可以输出一个预测分值?uv,θ是目前的一个参数。
基于embedding的知识图谱推荐方法
1、DKN方法
DKN: Deep knowledge-aware network for newsrecommendation, 属于基于embedding的知识图谱推荐方法,是2018年发表的论文,这篇论文是关于新闻推荐。
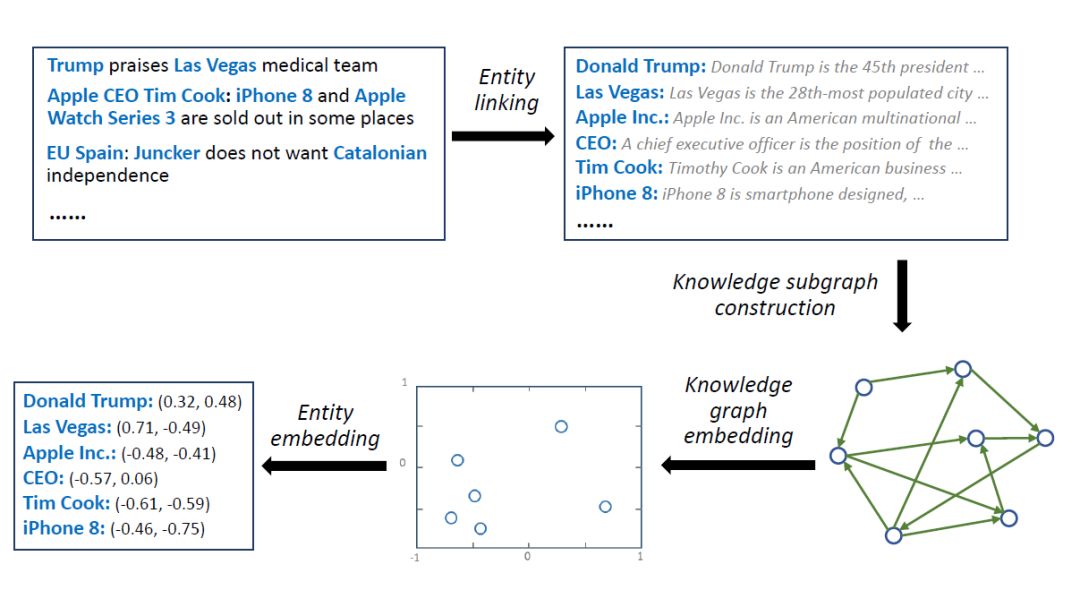
如上图,给出一段新闻,提取新闻中的实体,根据这些实体,构建一个知识图谱的子图,对知识图谱做embedding映射,得到每个实体的embedding,最后就得到每个实体的特征向量。
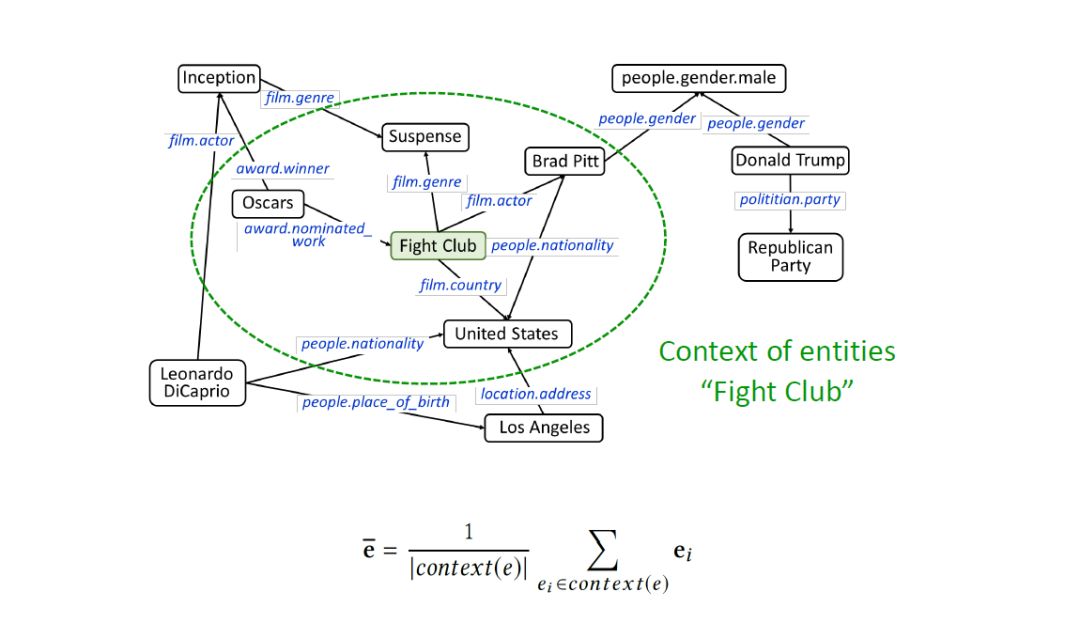
如上图,对于某个实体Fight Club,只有其对应的embedding还不够,在KG中每个实体,连接着好多其他的实体,那这些临近实体就是该实体的上下文,将这些上下文中的每个实体的embedding相加平均,就得到该实体的上下文embedding。如上图公式中ē就是实体ei的上下文embedding。
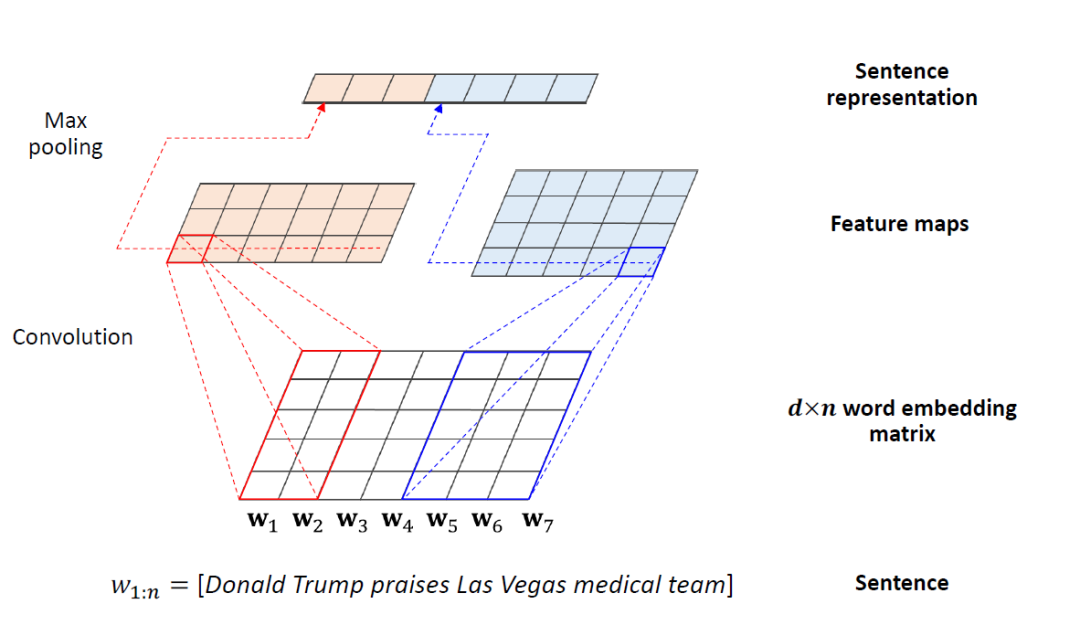
在NLP中有一个模型叫KimCNN,主要是给定一个sentence,返回一个特征向量。如上图给定一个n个单词的sentence(图中n为7),对每个单词做embedding映射,embedding的长度为d(图中d为5),得到一个d*n的wordembedding矩阵。用7个卷积核做卷积进行featuremaps,得到7个1维向量,对每个向量做池化(Max pooling),得到该sentence的word embedding。
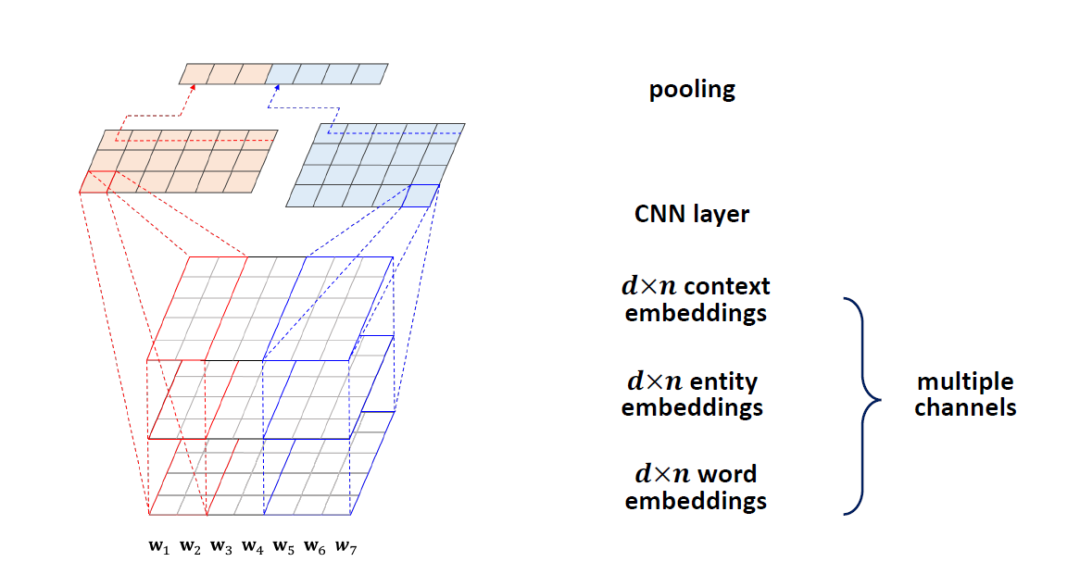
前面介绍中已有3种特征向量,分别是实体embeddings, 上下文embeddings, word embedings,我们的方法是把这3种embeddings做一个累加,卷积,池化,最后得到这个sentence的embeddings,这种方法叫KCNN。
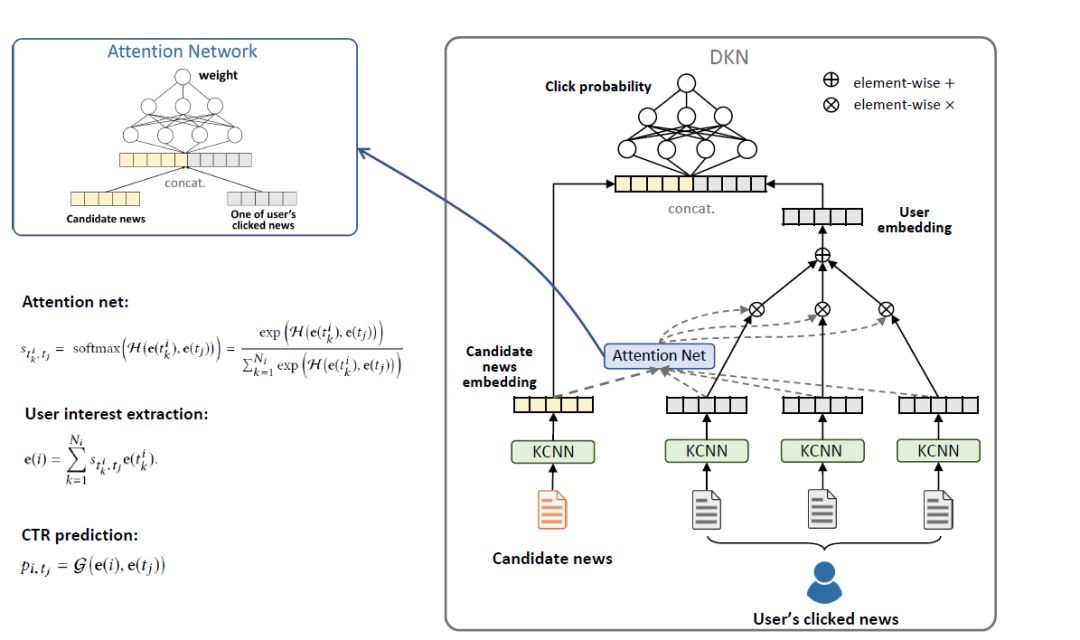
接下来介绍基于KCNN做推荐的方法。如上图假设某个用户已经点击过了3条新闻,来了一个候选新闻,预测该用户对候选新闻的点击率。对这4条新闻做KCNN的embedding映射,得到4个特征向量。因为用户看过的新闻的重要性对候选新闻是不一样的,用Attention Net计算用户看过的每一条新闻和候选新闻的决策分值。用得到的分值加权观看记录,得到User embedding。将user embedding和candidate news embedding拼接,输出一个预测的点击概率,这个就是做预测的DKN模型。
2、MKR方法
MKR:Multi-TaskFeature Learning for Knowledge Graph Enhanced Recommendation,属于基于embedding的知识图谱推荐方法,是2019年发表在WWW的论文,是一个多任务的模型。
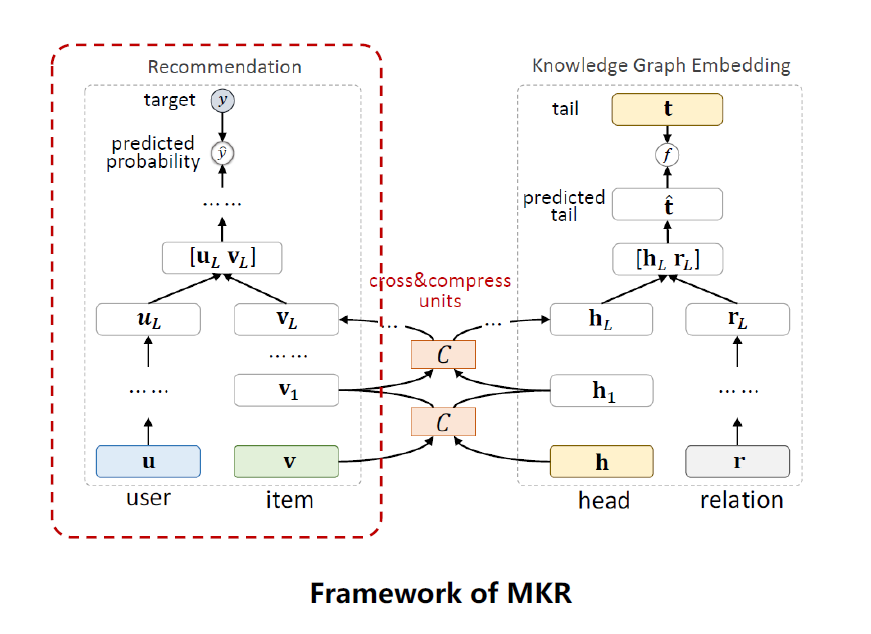
如上图为MKR框架,包括3个模块,一个是推荐模块,一个是knowledge graph embedding, KGE模块,还有一个是以上2个模块的桥梁,cross&compress units,交叉压缩单元,下面将分别阐述这3个模块。
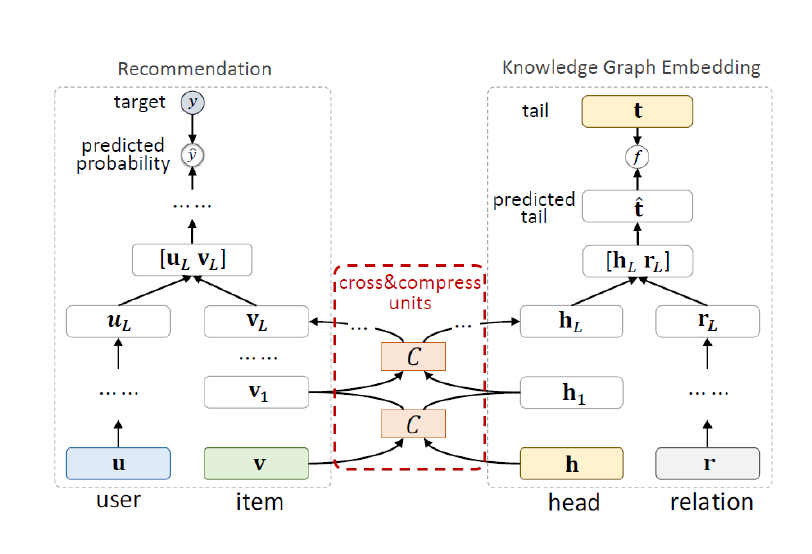
推荐系统模块,输入是user, item,输出是用户对物品的点击率。模块分2块,一个是low-level的部分,一个是high-level的部分。在low-lever部分,用了一个MLP(multi-layer perceptron)来处理用户的特征UL,item是cross&compressunits做的处理,返回一个物品的特征VL,把UL和VL拼接起来,用一个recommendation system函数fRS,输出一个点击预测值。
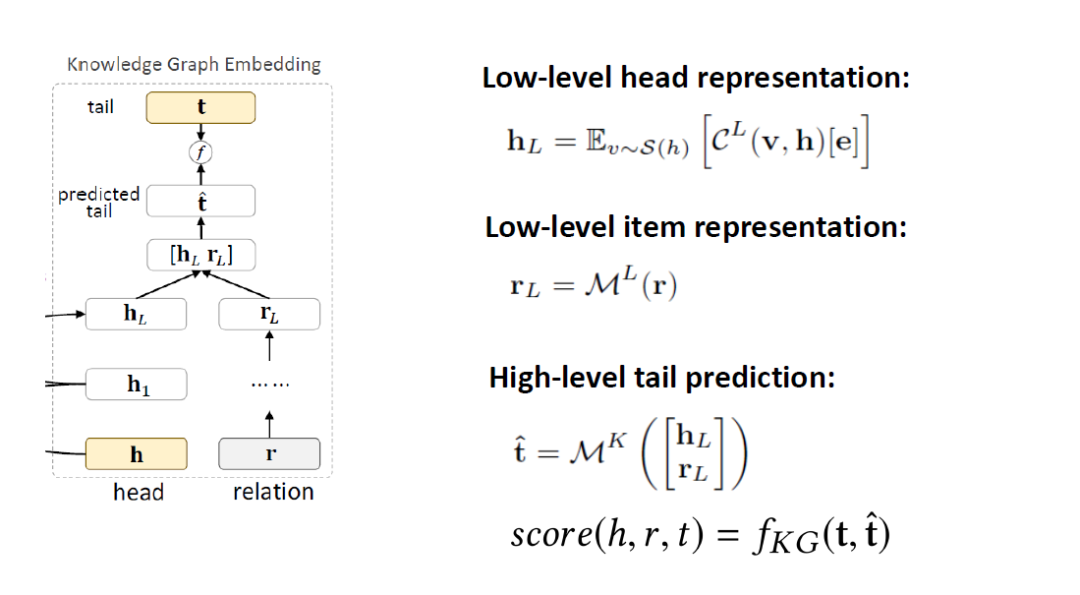
KGE模块,也分成low-lever和high-level部分,输入head,用cross&compress unites来做特征处理,relation用MLP做特征处理,把这2个处理结果拼接起来,经过一个K层的MLP,得到一个predictedtail,预测的tail和真实的tail用一个函数fKG算一个分值,这样就可以优化这个score值。
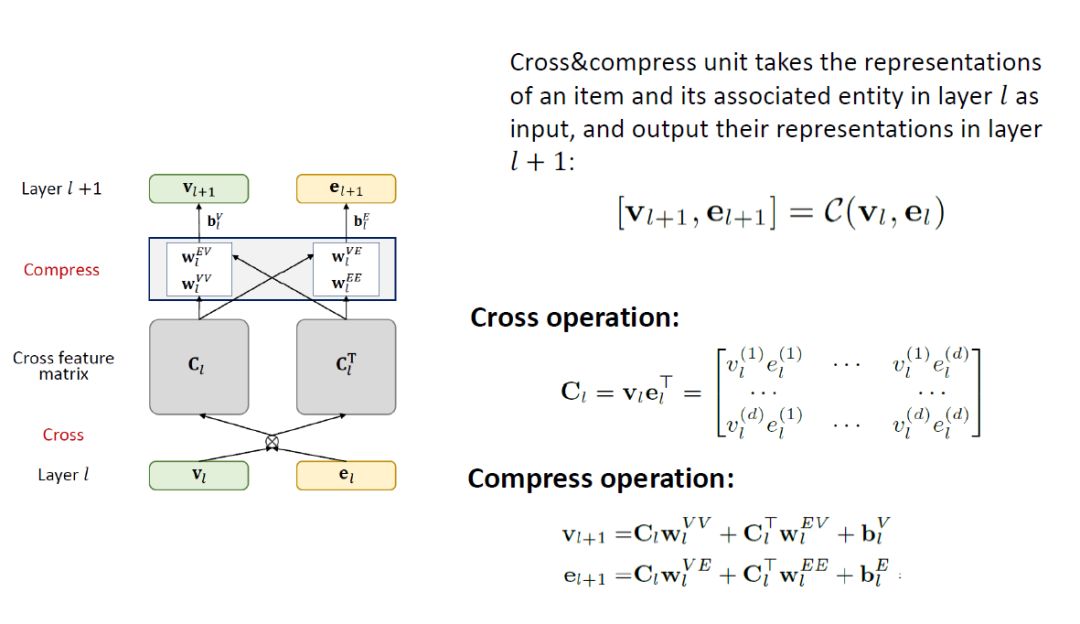
这个多任务之所以能做起来,主要是推荐系统模块的物品(item)和KGE模块的实体(entity)是对应的,很多item可以在KGE中找到对应的entity,item和entity是对同一个物品的描述,他们的embedding在某种层度上是相似的,是可以被连接的。中间的cross&compressunits就是这个连接结合,这个模块是在每一层都有,在l层,输入是item的embedding vl和entity的embedding el,输出是下一层的embedding。
这个模块计算分2步,第一步是cross,第二步是compress。
cross操作是将vl,el做一个cross,vl是一个d*1的向量,elT是1*d的向量,矩阵相乘后得到一个d*d的矩阵Cl。
compress是将交叉后的矩阵Cl重新压缩回embedding space,这块细节部分可以参考论文。通过参数wl压缩输出vl+1,el+1。

学习算法中loss的计算公式如上图。LRS是推荐系统的loss,预测user-item的分值uv和真实分值yuv的差距。LKG是KG的loss,对于真实tuple(h,r,t),预测分值score越大越好,而对于随机替换tuple(h’, r, t’)(负样本),预测的分值越小越好。LREG是正则项。
算法实现第1块是推荐系统的任务,第2块是KGE任务,交替训练2者。在每次循环里面,做t次的RS的任务训练,做1次的KGE任务训练,做t次RS训练是因为更关注RS任务,这个t是可以调整的,这就是MKR模型。
混合型知识图谱推荐方法
1、RippleNet方法
RippleNet: Propagating User Preferenceson the Knowledge Graph for Recommender Systems,属于混合型知识图谱推荐方法,是2018发表在CIKM的一篇论文。
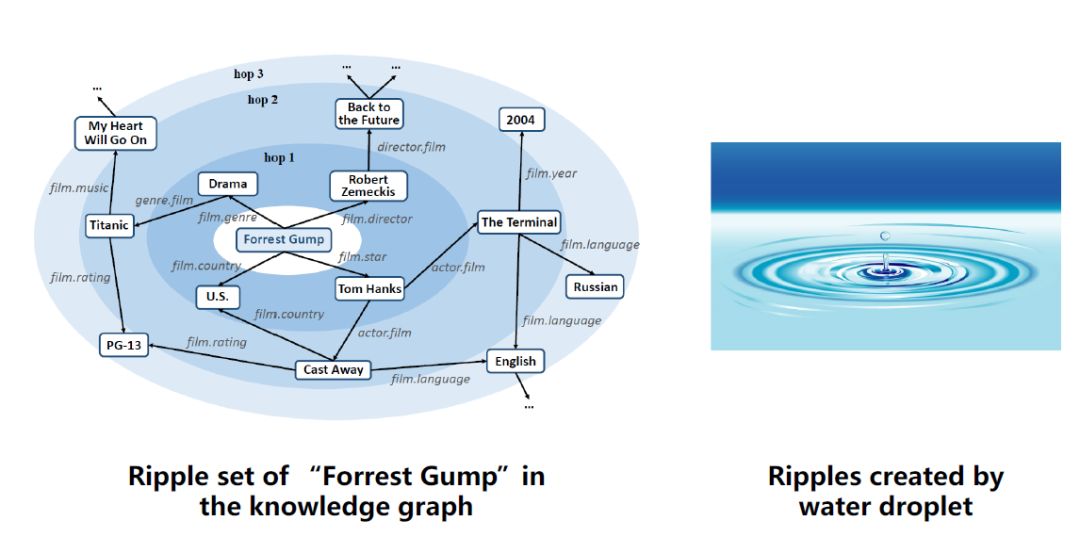
Ripple从名字上理解是水波的意思,水波是一层一层的,那这个算法是指在KG中某个实体,和该实体相连的其他实体也有一跳,二跳,三跳的关系,如上图列出了ForrestGump这部电影对应的3跳的临近实体。
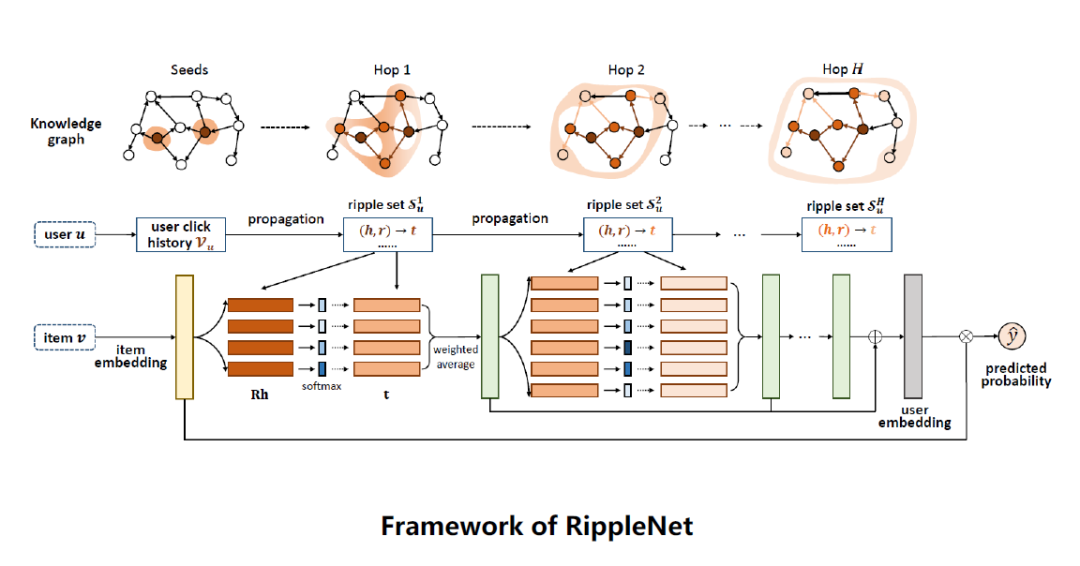
如上图是RippleNet框架,输入是一对user-item,输出是用户对物品的点击预测值。
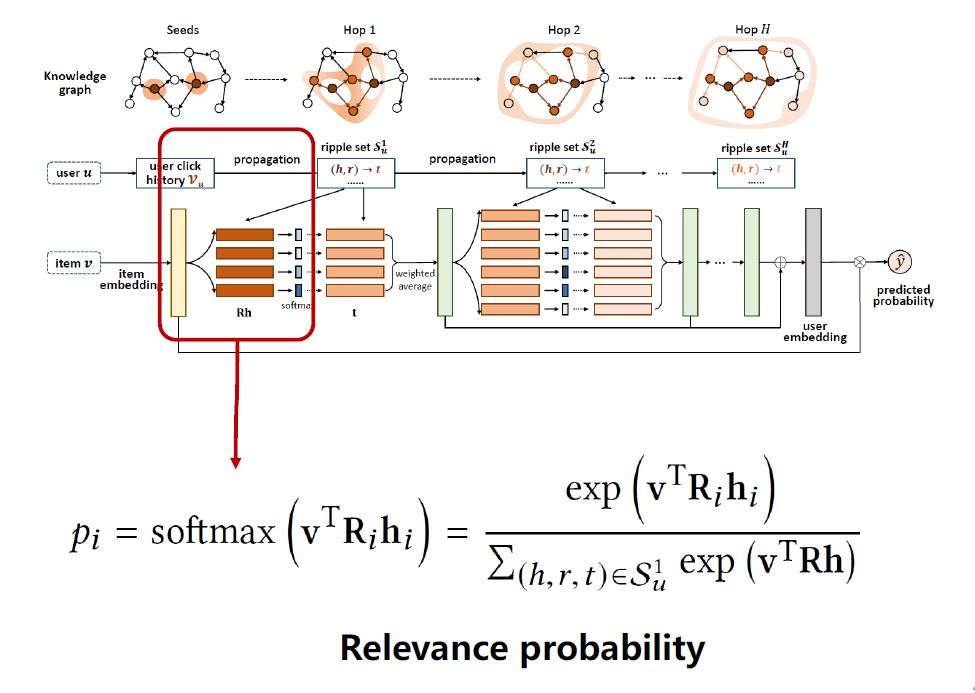
对输入用户u,获取用户的点击记录Vu,在KG中找到对应的Vu,比如图中有2个对应实体,获取这些实体对应的tuple,把实体一跳的集合拿出来。对输入物品v做embedding映射。如上公式,将item embedding v和这些head hi在R空间中做一个softmax,得到v相对于每个head的分值pi。
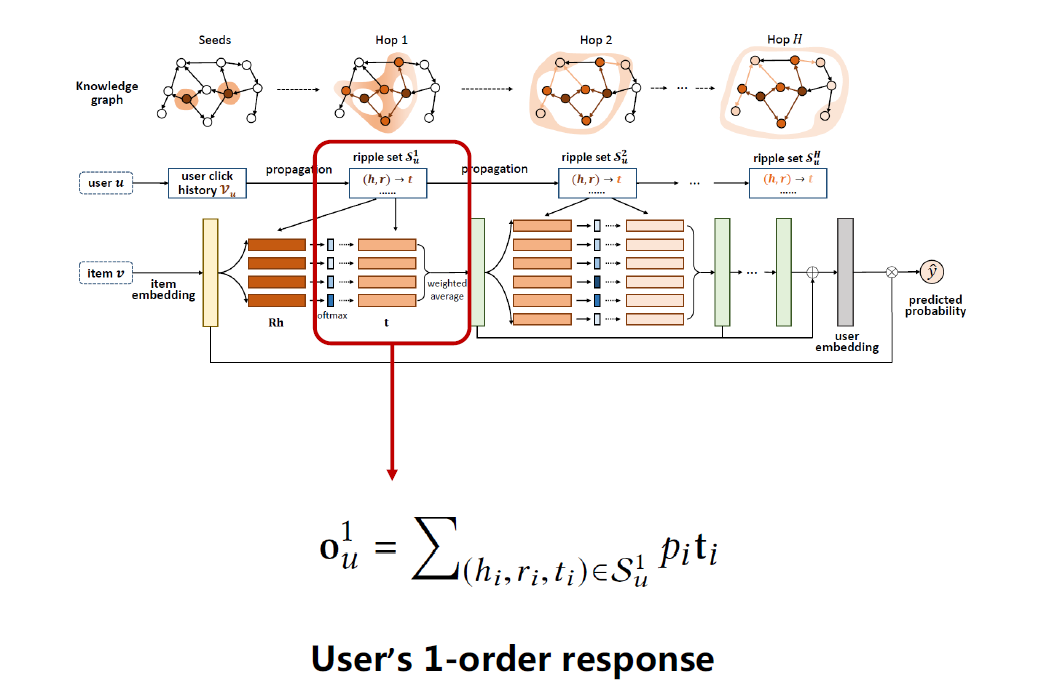
如上图公式,用pi加权平均对应的tail embedding ti,得到输出ou1,即当前用户u的一跳的特征,对应图中绿色竖条,可以看成该用户对当前物品的一阶响应(User's1-order response)。
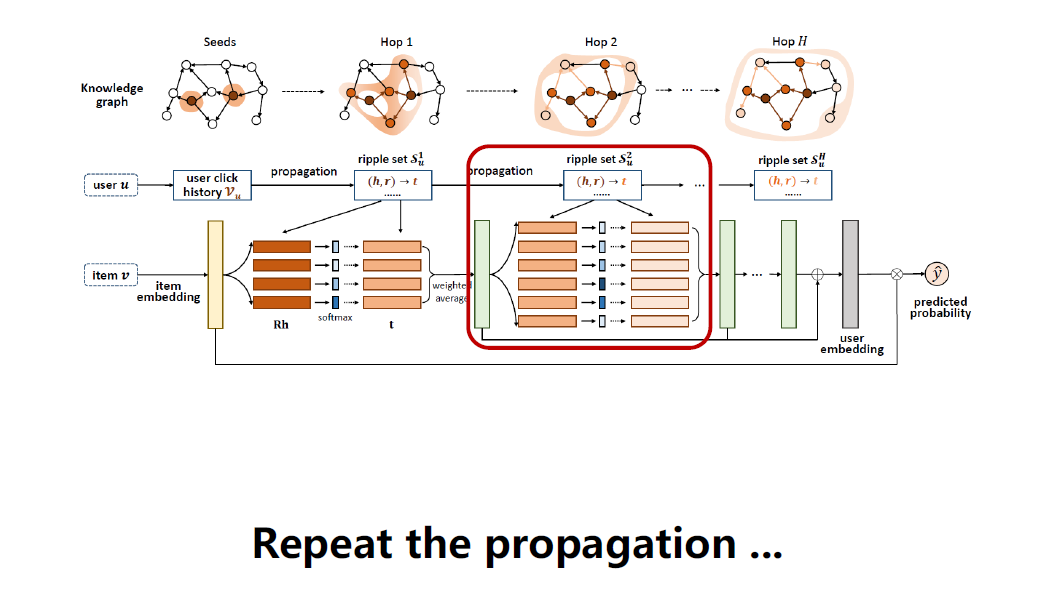
继续拿ou1特征重复之前的操作,拿ou1和物品二跳的tuple算一个p值,加权对应的tail embedding,得到ou2。
重复做下去,得到很多跳的响应值oui,把这些响应值加起来,得到用户最终的embedding。
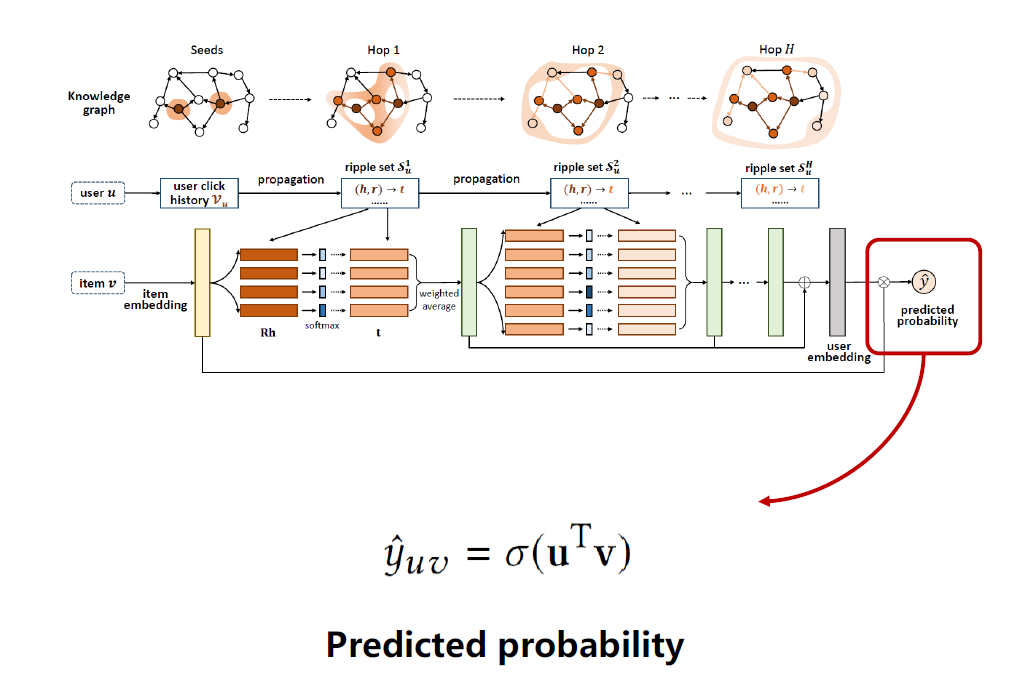
用这个用户embedding和物品最初的embedding做内积,再用一个sigmoid函数得出点击预测值。

学习算法如上图,在已知KG和RippleNet系统情况下,学习参数,最大化后验概率。通过贝叶斯定理,可以把该公式拆成3个值。第1项是参数的先验分布,用上面这个公式来刻画这个先验概率分布p(θ),这项对应的是正则项loss。

第2项给定参数θ,KG的概率,这项对应的是KG的embedding部分。当(h,r,t)是正样本,Ih,r,t接近1,反之为0,希望hTRt能接近真实的tuple值。

第3项已知参数θ和KG,用户和物品交互的似然函数。这个似然函数是一个伯努利分布,关于用户和物品内积的伯努力分布。
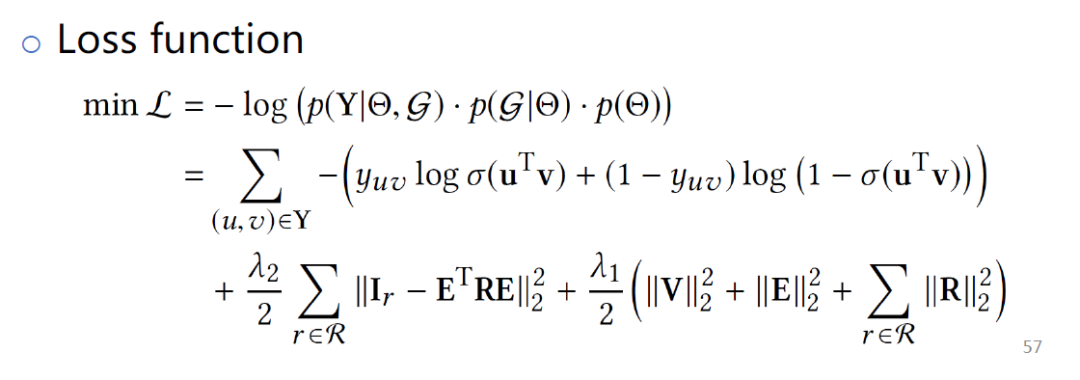
把这3项用负log做处理,得到loss函数,优化这个模型。
2、KGCN和KGCN-LS方法
KGCN:Knowledge GraphConvolutional Networks for Recommender Systems,是发表在2019年WWW上的一篇论文。KGNN-LS:Knowledge-awareGraph Neural Networks with Label Smoothness Regularization for RecommenderSystems,是发表在2019年KDD上的一篇论文,这篇是基于第1篇的扩展,这2篇论文一块讲解。核心思想是基于KG辅助的推荐,但引入了一个新的模型GCN(图神经网络),方法是基于GCN对KG扩展一个模型。
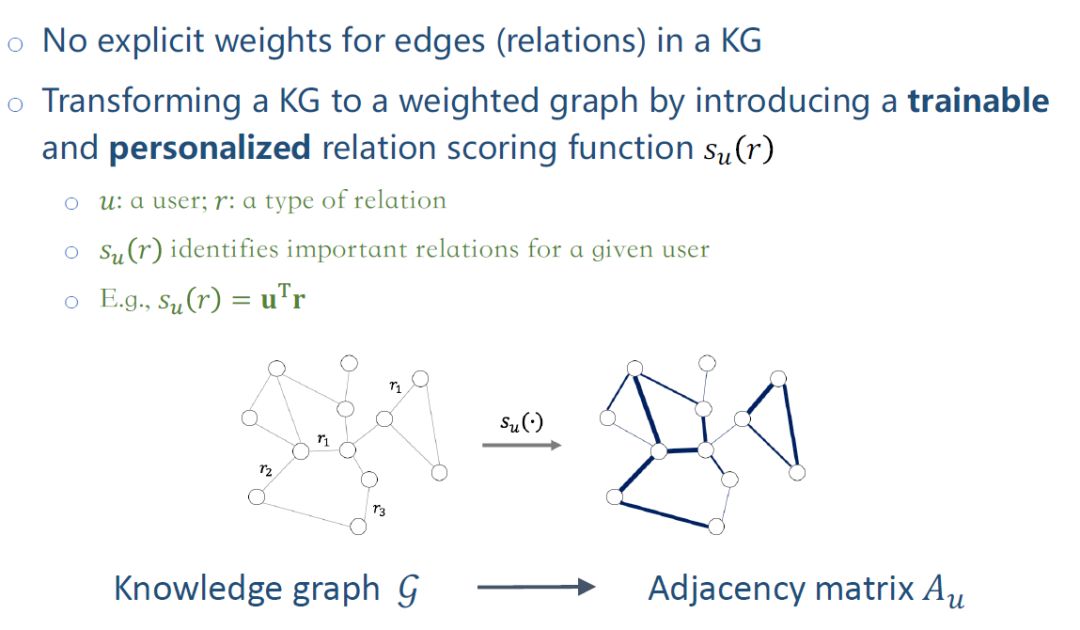
在KG中的边没有显示权值,只是一个关系类型。引入一个relation scoring function su(r),对每个relation打分,从而把KG转换成weightedgraph。函数su(r)的输入是user和relation,输出一个分值。核心思想是识别用户关注的类型,比如有些用户偏好同种类的电影,有些用户偏好某个主演的电影。su(r)用来刻画不同用户对不同relation的偏好层度,将user embeding和relation embedding内积,算出相应的分值。把异构KG转换成weighted graph,这样一个graph对应邻接矩阵Au,下标为u是因为每个用户对应的邻接矩阵是不一样的,su(r)是取决于用户。
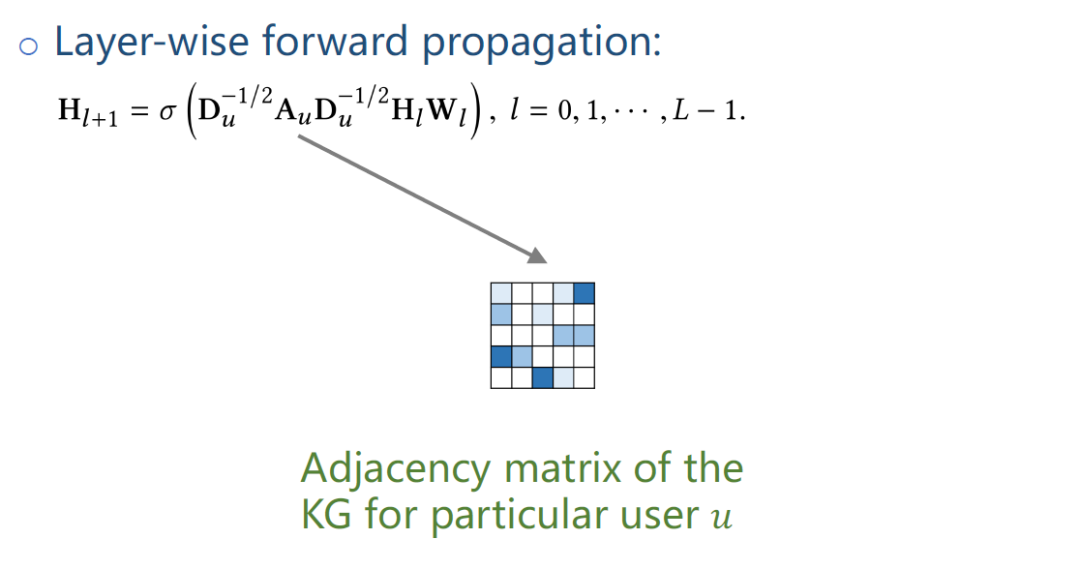
把KG中实体信息通过GNN做一个融合,如上图公式是一个标准的GNN的公式,Au是用户对应的邻接矩阵。
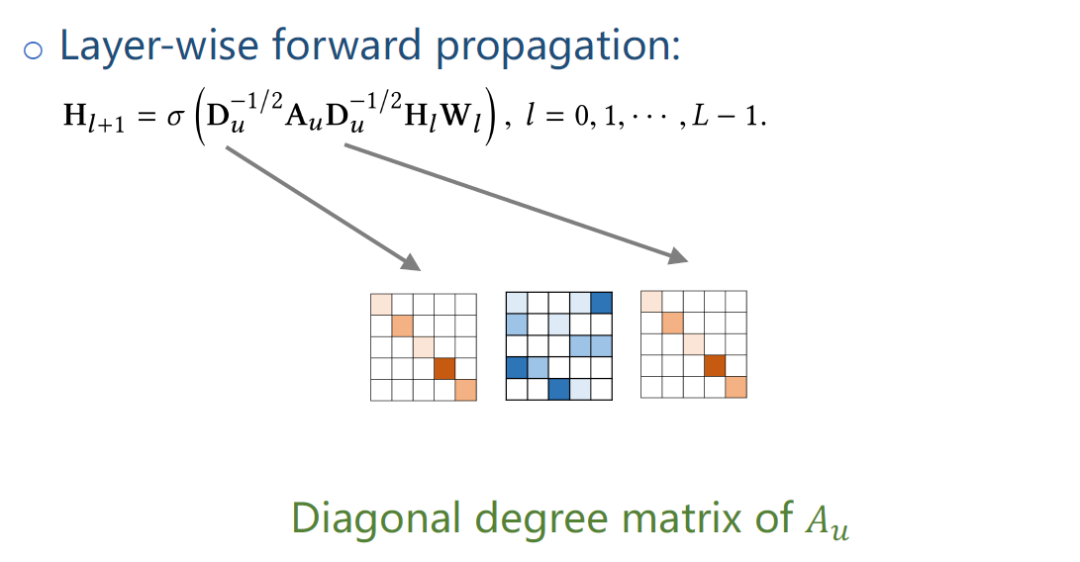
Du是Au的三角对称矩阵diagonal degree matrix。
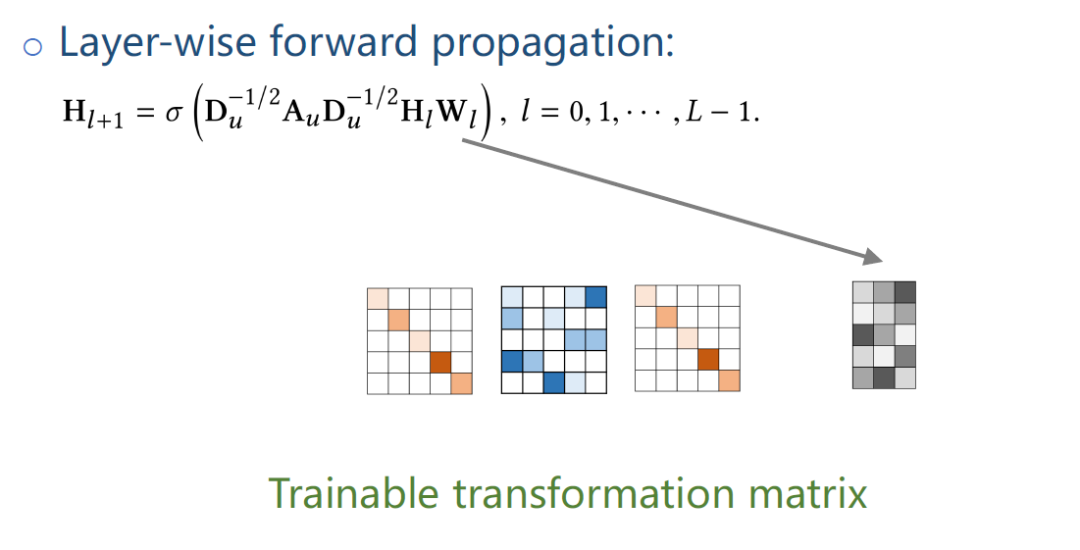
Wl就是训练传输参数矩阵。
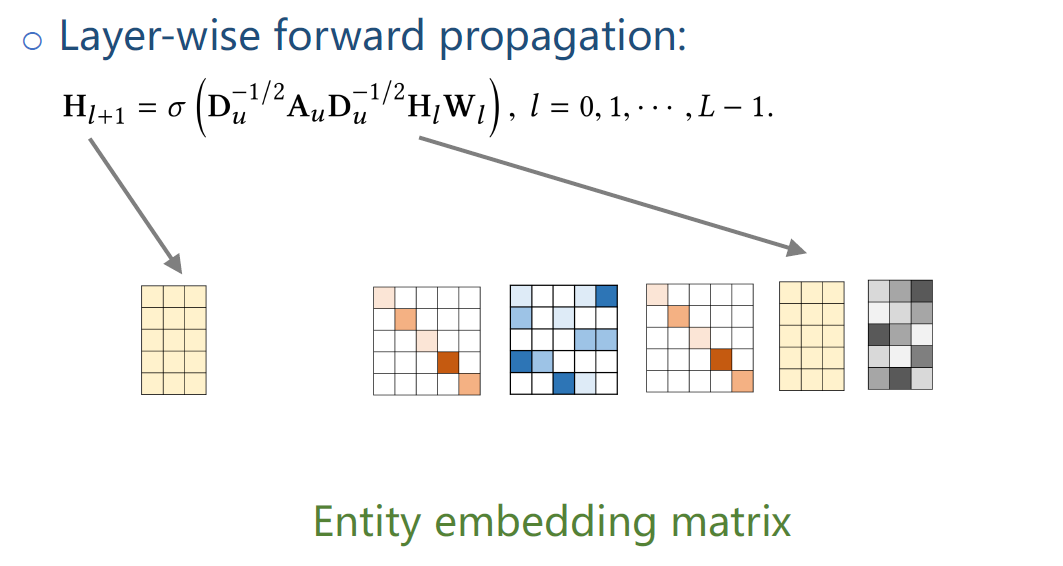
Hl,Hl+1是entity对应的embedding矩阵。
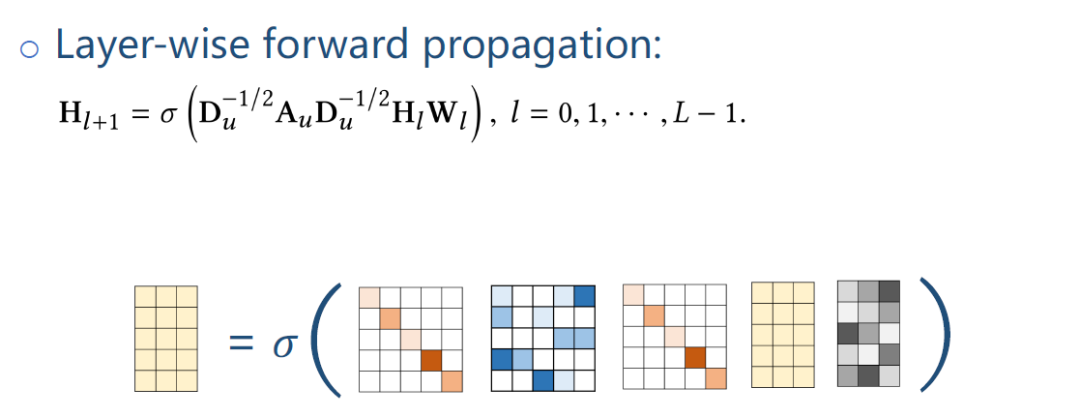
σ是一个非线性函数。
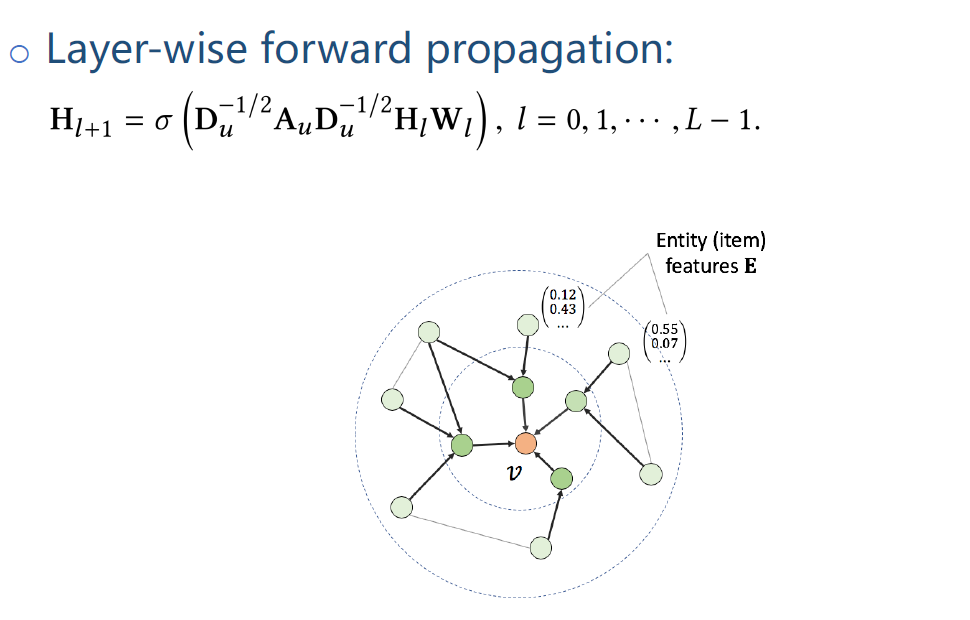
这个式子本质是在KG上做了一个多跳的message passing,把实体周围的那些临近点的特征向中间聚集,最后一层学到的特征是融合了多跳的临近点的特征。当得到最后一层embedding Hl后,就可以做点击预测。
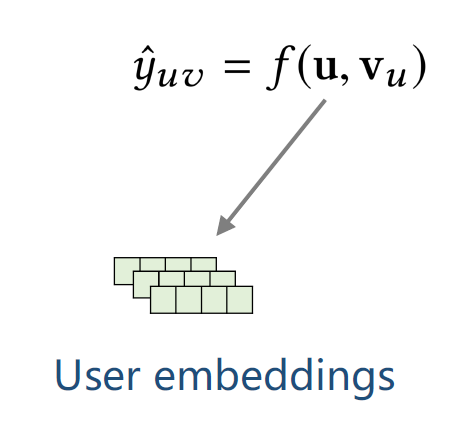
上图公式中u对应的是Userembedding。
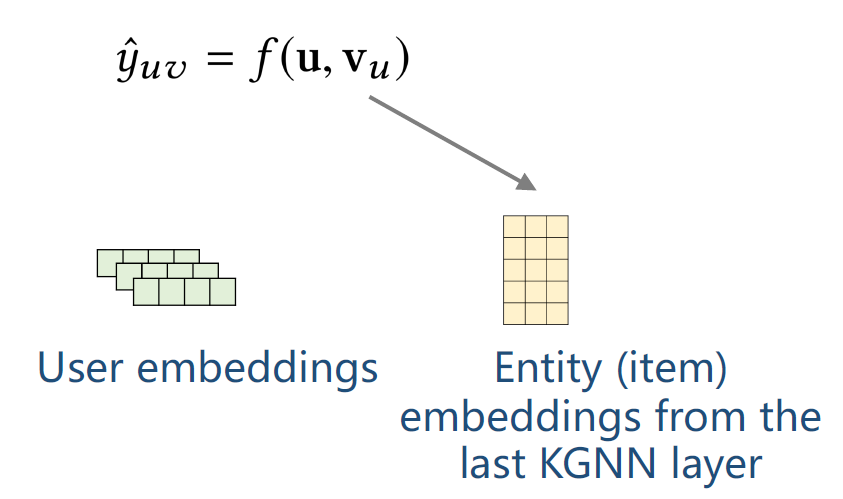
vu是根据前面KGNN计算得出的关于用户的entity embedding。
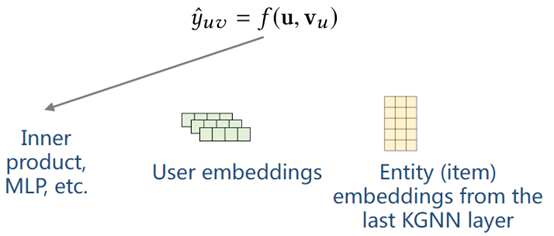
通过f函数得到预测值,f函数可以取内积,或MLP等。到这是第1篇论文的KGCN模型。
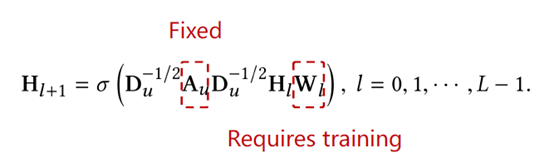
如上公式,在传统GNN模型中,Au是固定的,只需要训练Wl。

但在我们的模型中,Au和Wl都需要训练,Au是通过relation scoring function计算,图的结构需要训练,导致模型参数很多,容易过拟合。
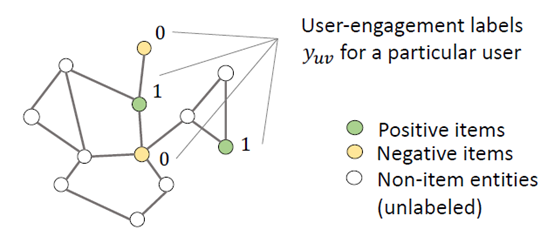
为了防止过拟合的问题,引入一个正则项,给模型一个约束。用label做约束,user engagement labels,指的是用户对物品的打分值,yuv是用户对某个物品的评分,这个评分是一个已知值,所以可以在KG中对这些点打一个标签。用户看过某部电影,对应的标签是1,没看过的电影对应的标签是0,对non-item实体没有标签。
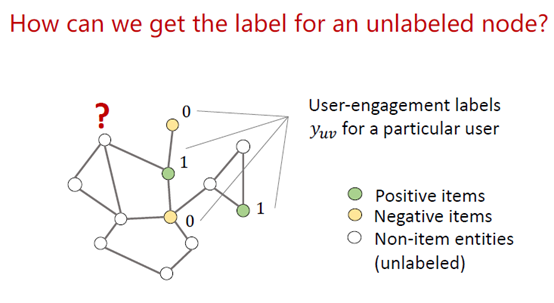
下一步是预测某个点的label,有一类算法叫标签传播算法(label propagation algorithm, LPA),这个算法是优化下面这个函数。

遍历所有的边,Au是边的权值。如果i,j节点有边,说明这2个节点联系比较强,那这2个节点的label会比较相近。这2个节点的边权值越大,那这2个节点的label就越一致。这是算法LPA的一个假设,标签过度是平滑的。
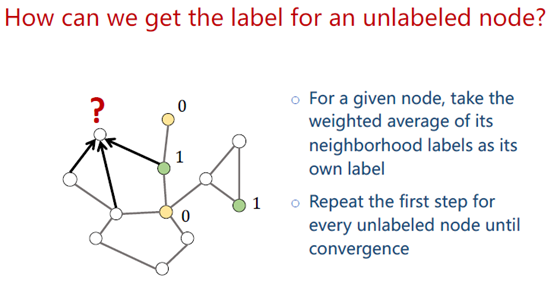
预测一个无标签的节点,将其周围节点的label加权平均,重复该操作直到收敛,这就是label propagation。
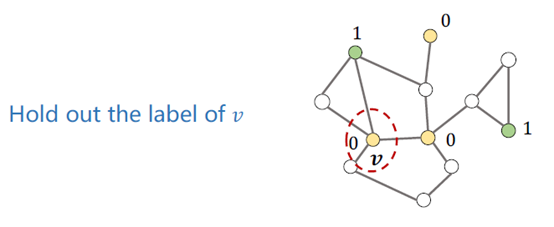
利用label propagation做正则项,对于一个节点v,其真实lable是yuv(图中为0)。
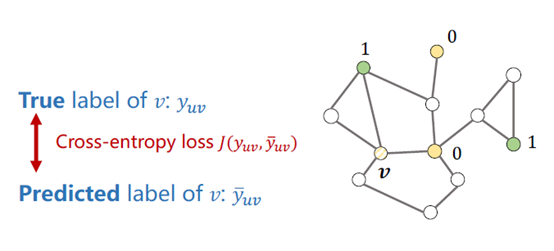
利用LPA算法预测这个v的label,得到预测值?uv,算出预测值和真实值之间的损失J。
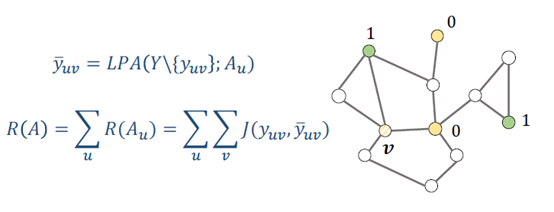
在做label propagation时,标签传播是取决于边权值,所以最终预测值是关于边权值的函数,损失J也是一个关于边权值的函数。损失函数R(A)是一个关于A的函数,所以可以把梯度往这个损失函数中传播,起到一个正则项的作用。
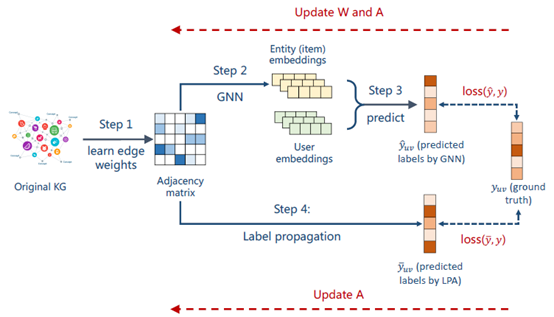
如上图,回顾一下整个模型,把原始异构KG转成weighted graph,学习边的权值,得到一个邻接矩阵,用GNN得到entity embedding,用这个entity embedding 和user embedding来做这个预测,得到预测值?uv,用?和真实值y得到一个loss,反向传播,将误差梯度向前传播,更新Au和参数W。
下面部分是正则项,邻接矩阵为参数,做一个labelpropagation,得到预测值?uv,用?和y得到一个loss,反向传播,更新Au。

的作用。

如上图,回顾一下整个模型,把原始异构KG转成weighted graph,学习边的权值,得到一个邻接矩阵,用GNN得到entity embedding,用这个entity embedding 和user embedding来做这个预测,得到预测值?uv,用?和真实值y得到一个loss,反向传播,将误差梯度向前传播,更新Au和参数W。
下面部分是正则项,邻接矩阵为参数,做一个labelpropagation,得到预测值?uv,用?和y得到一个loss,反向传播,更新Au。

总结一下,本文主要介绍了3个部分的内容,第1部分介绍了知识图谱是推荐系统的一种新的辅助信息。另外2个部分介绍了两类知识图谱推荐方法,一类是基于embedding的知识图谱推荐方法,包括DKN和MKR,一类是混合型知识图谱推荐方法,包括RippleNet、KGCN和KGNN-LS。
![《剑指offer》14--剪绳子(整数拆分)[C++]](https://img-blog.csdnimg.cn/direct/1ef9d40c62ab40498b1944a8edfc0e3c.png)