索引是帮助存储引擎快速获取数据的一种数据结构,形象的说就是索引是数据的目录。
索引创建的时机:
索引并不是越多越好的,虽然他再查询时会提高效率,但是保存索引和维护索引也需要一定的空间和时间成本的。
不创建索引:
- 当字段是类似于男/女这种的就没必要创建索引了,因为这样查询索引还是会查询到很多数据,没有给我们提升什么效率,而且MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 当字段经常更新时也最好不要建立索引,因为随着数据的更新,为了维护B+树的有序性,B+树也要进行更新调整,经常性的更新太浪费数据库性能了。
- 如果经常再查询语句中经常用不到的字段也不要创建索引了,反而浪费。
- 数据库数据少的时候也不用创建
创建索引:
- 字段具有唯一性,如学号等,这样查询提高效率很高。
- 经常被where作为查询条件的字段,可以创建索引。
- 经常被Order By、Group By 使用的字段,因为B+树本身具有有序性,当使用这两个查询语句时无需再对字段进行排序了。
优化索引的方法:
前缀索引优化:
前缀索引是拿某个字段的字符串的前几个字符建立索引。
- 只拿前几个字符作为索引节点,那就减小了索引的节点大小,降低了索引所占据的空间,
- 一个页内存储更多的索引节点更多,提高了查询效率。
- 但是前缀索引无法运用再Order By语句中,且无法把前缀索引作为索引覆盖。
覆盖索引优化:
Select sex From student where name = ‘张三’
索引覆盖:如果只根据name创建索引的话,那么再这个索引只能查询到张三的id,此时需要拿着这个id去主键索引中查询sex,进行回表操作。而当根据name、和sex创建了联合索引后,就不需要进行回表操作了,直接再这个索引中查询到sex,这一步就叫做索引覆盖。
所以当我们经常根据一个非主键字段查询另一个非主键字段的话,可以建立联合索引,避免回表操作。
主键索引最好是自增:
InnoDB 创建主键索引默认为聚簇索引,数据被存放在了 B+Tree 的叶子节点上。也就是说,同一个叶子节点内的各个数据是按主键顺序存放的,因此,每当有一条新的数据插入时,数据库会根据主键将其插入到对应的叶子节点中。
如果我们使用自增主键,那么每次插入的新数据就会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,就会自动开辟一个新页面。因为每次插入一条新记录,都是追加操作,不需要重新移动数据,因此这种插入数据的方法效率非常高。
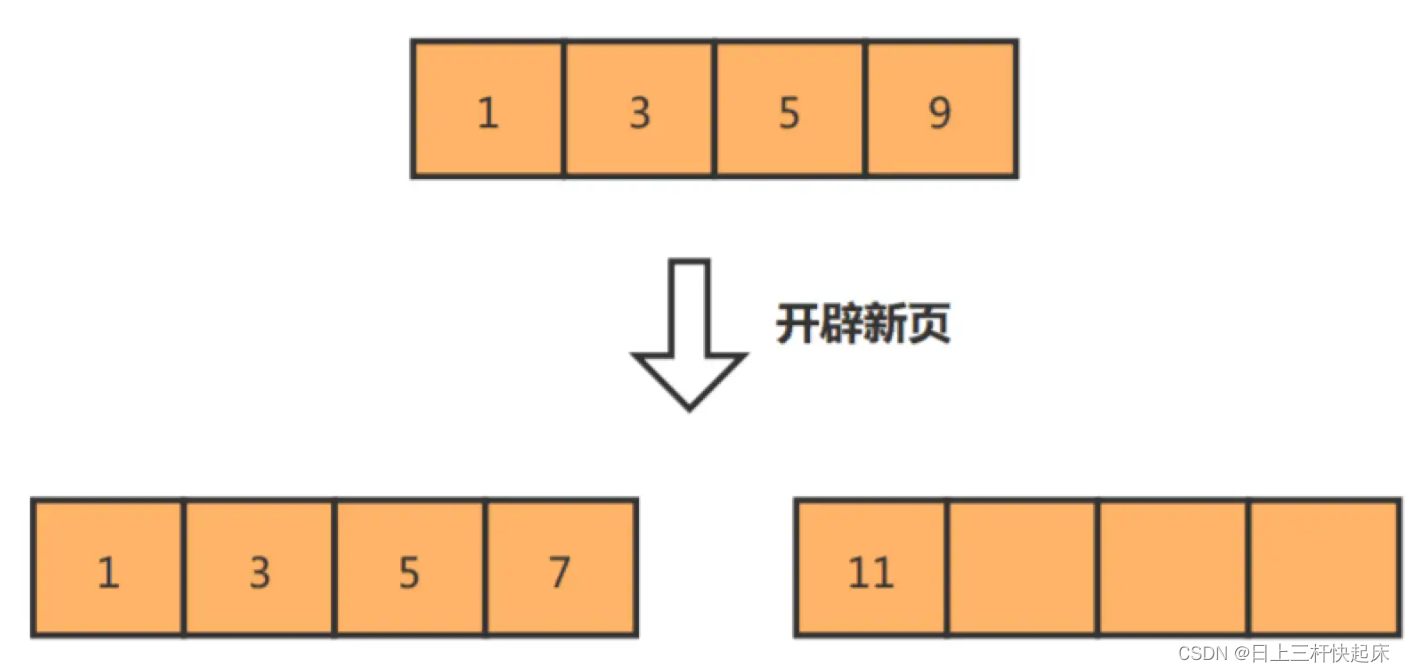
如果我们使用非自增主键,由于每次插入主键的索引值都是随机的,因此每次插入新的数据时,就可能会插入到现有数据页中间的某个位置,这将不得不移动其它数据来满足新数据的插入,甚至需要从一个页面复制数据到另外一个页面,我们通常将这种情况称为页分裂。页分裂还有可能会造成大量的内存碎片,导致索引结构不紧凑,从而影响查询效率。
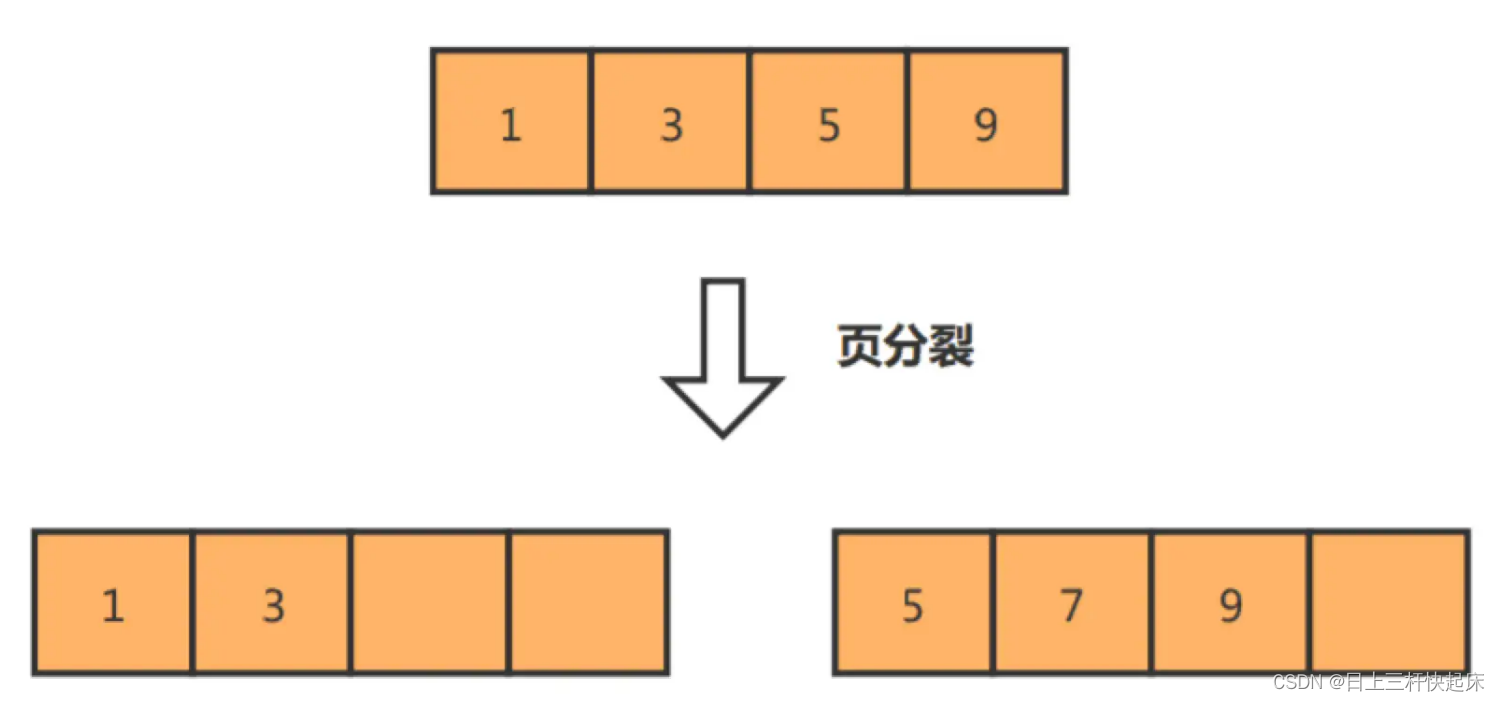
是不是一定要自增呢?
当某一个业务量增长非常快,数据量非常大,数据库性能无法满足业务需求的时候通常会实施分库分表,这个时候自增主键就不适用了,比如订单表,分成16个表,如果都使用自增的话,肯定会造成订单id重复,所以此时的解决方案就是分布式id,保证趋势递增即可。
主键字段的长度不要太大,因为主键字段长度越小,意味着二级索引的叶子节点越小(二级索引的叶子节点存放的数据是主键值),这样二级索引占用的空间也就越小。
索引最好设置为 NOT NULL:
-
索引列存在 NULL 就会导致优化器在做索引选择的时候更加复杂,更加难以优化,因为可为 NULL 的列会使索引、索引统计和值比较都更复杂,比如进行索引统计时,count 会省略值为NULL 的行。
-
NULL 值是一个没意义的值,但是它会占用物理空间,所以会带来的存储空间的问题,因为 InnoDB 存储记录的时候,如果表中存在允许为 NULL 的字段,那么行格式 中至少会用 1 字节空间存储 NULL 值列表。

防止索引失效:
我们设置了索引并不意味着一定会用上索引,再某些情况下索引也会失效。
- 当我们使用左或者左右模糊匹配的时候,也就是 Link %x 或者 Link %x% 这两种方式都会造成索引失效;
- 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 or 前的条件列是索引列,而在 or 后的条件列不是索引列,那么索引会失效。








![[Python人工智能] 四十二.命名实体识别 (3)基于Bert+BiLSTM-CRF的中文实体识别万字详解(异常解决中)](https://img-blog.csdnimg.cn/bf1659094a5b4541a19a93c14fafa5d1.png#pic_center)
![[C语言][详解指针][指针的思维导图][超详细!!!](一)](https://img-blog.csdnimg.cn/direct/f8cf5d363f5f4bd69341840c7184b019.jpeg)