前面几节进行了各种组件的学习和编码,本节将组件组成transformer,并对其进行测试
EncoderDecoder 编码器解码器构建
使用EnconderDecoder实现编码器-解码器结构
# 使用EncoderDeconder类实现编码器和解码器
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, sourc_embed, target_embed, generator) -> None:
"""
encoder: 编码器对象
decoder: 解码器对象
sourc_embed: 源数据嵌入函数
target_embed: 目标数据嵌入函数
generator: 输出部分的类别生成器
"""
super(EncoderDecoder,self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = sourc_embed
self.tgt_embed = target_embed
self.generator = generator
def encode(self,source, source_mask):
"""
source: 源数据
source_mask: 源数据的mask
"""
return self.encoder(self.src_embed(source), source_mask)
def decode(self, memory, source_mask, target,target_mask):
return self.decoder(self.tgt_embed(target), memory, source_mask,target_mask)
def forward(self,source, target, source_mask, target_mask):
return self.decode(self.encode(source, source_mask), source_mask,target,target_mask)
测试代码放在最后,测试结果如下:
ed_result.shape: torch.Size([2, 4, 512])
ed_result: tensor([[[ 2.2391, -0.1173, -1.0894, ..., 0.9693, -0.9286, -0.4191],
[ 1.4016, 0.0187, -0.0564, ..., 0.9323, 0.0403, -0.5115],
[ 1.3623, 0.0854, -0.7648, ..., 0.9763, 0.6179, -0.1512],
[ 1.6840, -0.3144, -0.6535, ..., 0.7420, 0.0729, -0.2303]],
[[ 0.8726, -0.1610, -0.0819, ..., -0.6603, 2.1003, -0.4165],
[ 0.5404, 0.8091, 0.8205, ..., -1.4623, 2.5762, -0.6019],
[ 0.9892, -0.3134, -0.4118, ..., -1.1656, 1.0373, -0.3784],
[ 1.3170, 0.3997, -0.3412, ..., -0.6014, 0.7564, -1.0851]]],
grad_fn=<AddBackward0>)Transformer模型构建
# Tansformer模型的构建过程代码
def make_model(source_vocab, target_vocab, N=6,d_model=512, d_ff=2048, head=8, dropout=0.1):
"""
该函数用来构建模型,有7个参数,分别是源数据特征(词汇)总数,目标数据特征(词汇)总数,编码器和解码器堆叠数,
词向量映射维度,前馈全连接网络中变换矩阵的维度,多头注意力结构中的多头数,以及置零比率dropout
"""
c = copy.deepcopy
#实例化多头注意力
attn = MultiHeadedAttention(head, d_mode)
# 实例化前馈全连接层 得到对象ff
ff = PositionalEncoding(d_mode, dropout)
# 实例化位置编码类,得到对象position
position = PositionalEncoding(d_mode,dropout)
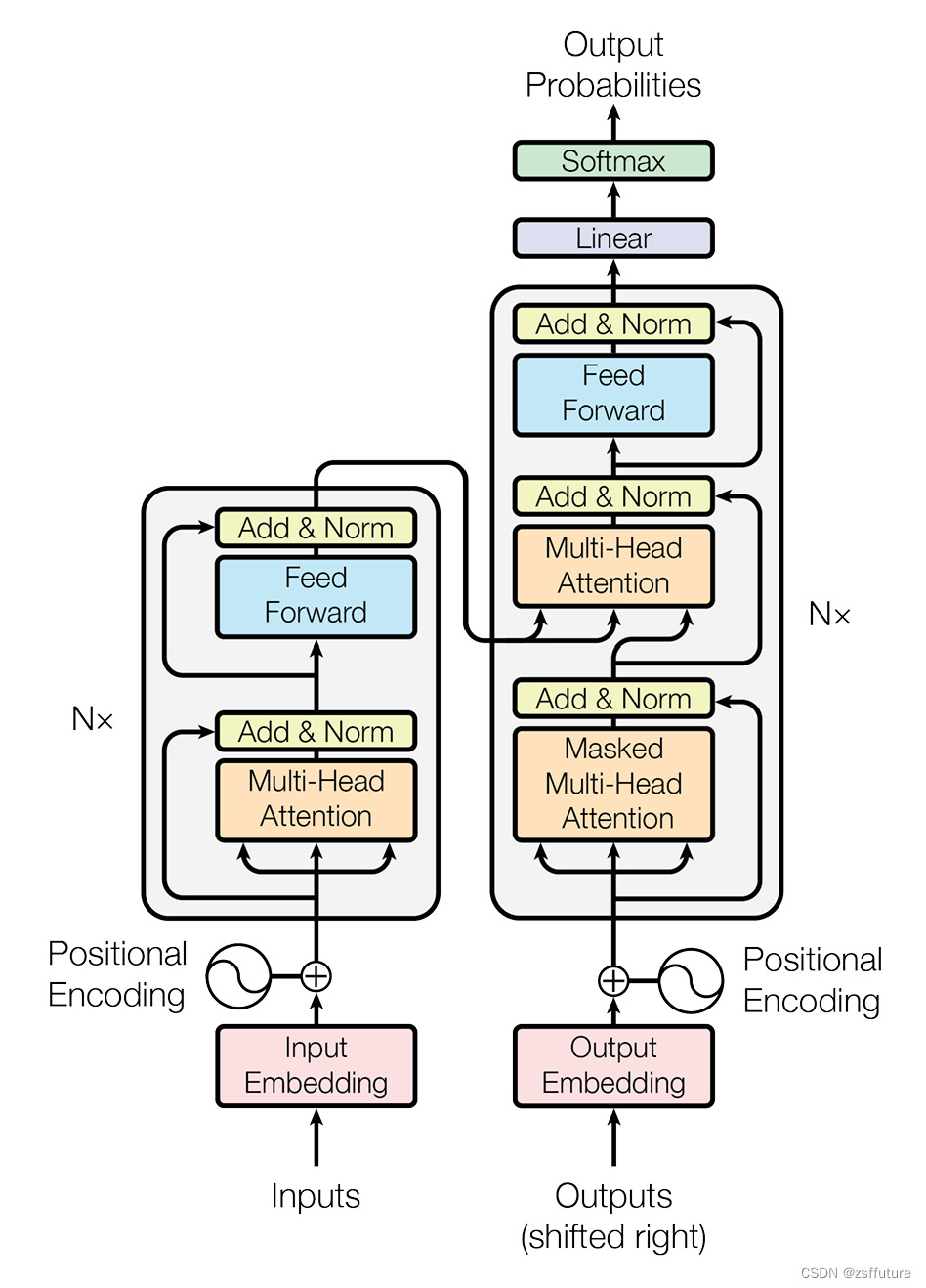
# 根据结构图,最外层是EncoderDecoder,在EncoderDecoder中,
# 分别是编码器层,解码器层,源数据Embedding层和位置编码组成的有序结构
# 目标数据Embedding层和位置编码组成的有序结构,以及类别生成器层。在编码器层中有attention子层以及前馈全连接子层,
# 在解码器层中有两个attention子层以及前馈全连接层
model =EncoderDecoder(Encoder(EncoderLayer(d_mode, c(attn), c(ff), dropout),N),
Decoder(DecoderLayer(d_mode, c(attn), c(attn),c(ff),dropout),N),
nn.Sequential(Embeddings(d_mode,source_vocab), c(position)),
nn.Sequential(Embeddings(d_mode, target_vocab), c(position)),
Generator(d_mode, target_vocab)
)
# 模型结构完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵,这里一但判断参数的维度大于1,
# 则会将其初始化成一个服从均匀分布的矩阵
for p in model.parameters():
if p.dim()>1:
nn.init.xavier_uniform(p)
return model测试代码
import numpy as np
import torch
import torch.nn.functional as F
import torch.nn as nn
import matplotlib.pyplot as plt
import math
import copy
from inputs import Embeddings,PositionalEncoding
from encoder import subsequent_mask,attention,clones,MultiHeadedAttention,PositionwiseFeedForward,LayerNorm,SublayerConnection,Encoder,EncoderLayer
# encode 代码在前面几节
# 解码器层的类实现
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward,dropout) -> None:
"""
size : 词嵌入维度
self_attn:多头自注意对象,需要Q=K=V
src_attn:多头注意力对象,这里Q!=K=V
feed_forward: 前馈全连接层对象
"""
super(DecoderLayer,self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
# 根据论文图使用clones克隆三个子层对象
self.sublayer = clones(SublayerConnection(size,dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
"""
x : 上一层的输入
memory: 来自编码器层的语义存储变量
source_mask: 源码数据掩码张量,针对就是输入到解码器的数据
target_mask: 目标数据掩码张量,针对解码器最后生成的数据,一个一个的推理生成的词
"""
m = memory
# 将x传入第一个子层结构,第一个子层结构输入分别是x和self_attn函数,因为是自注意力机制,所以Q=K=V=x
# 最后一个参数是目标数据掩码张量,这时要对目标数据进行掩码,因为此时模型可能还没有生成任何目标数据,
# 比如在解码器准备生成第一个字符或词汇时,我们其实已经传入第一个字符以便计算损失
# 但是我们不希望在生成第一个字符时模型能利用这个信息,因为我们会将其遮掩,同样生成第二个字符或词汇时
# 模型只能使用第一个字符或词汇信息,第二个字符以及以后得信息都不允许被模型使用
x = self.sublayer[0](x, lambda x: self.self_attn(x,x,x,target_mask))
# 紧接着第一层的输出进入第二个子层,这个子层是常规的注意力机制,但是q是输入x;k、v是编码层输出memory
# 同样也传入source_mask, 但是进行源数据遮掩的原因并非是抑制信息泄露,而是遮蔽掉对结果没有意义的的字符而产生的注意力
# 以此提升模型的效果和训练速度,这样就完成第二个子层的处理
x = self.sublayer[1](x, lambda x: self.src_attn(x,m,m,source_mask))
# 最后一个子层就是前馈全连接子层,经过他的处理后就可以返回结果,这就是解码器层的结构
return self.sublayer[2](x,self.feed_forward)
# 解码器
class Decoder(nn.Module):
def __init__(self,layer,N) -> None:
""" layer: 解码器层, N:解码器层的个数"""
super(Decoder,self).__init__()
self.layers = clones(layer,N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory,source_mask, target_mask):
# x:目标数据的嵌入表示
# memory:编码器的输出
# source_mask: 源数据的掩码张量
# target_mask: 目标数据的掩码张量
for layer in self.layers:
x = layer(x,memory,source_mask,target_mask)
return self.norm(x)
# 输出
class Generator(nn.Module):
def __init__(self,d_mode, vocab_size) -> None:
"""
d_mode: 词嵌入
vocab_size: 词表大小
"""
super(Generator,self).__init__()
self.project = nn.Linear(d_mode, vocab_size)
def forward(self, x):
return F.log_softmax(self.project(x),dim=-1)
# 使用EncoderDeconder类实现编码器和解码器
class EncoderDecoder(nn.Module):
def __init__(self, encoder, decoder, sourc_embed, target_embed, generator) -> None:
"""
encoder: 编码器对象
decoder: 解码器对象
sourc_embed: 源数据嵌入函数
target_embed: 目标数据嵌入函数
generator: 输出部分的类别生成器
"""
super(EncoderDecoder,self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = sourc_embed
self.tgt_embed = target_embed
self.generator = generator
def encode(self,source, source_mask):
"""
source: 源数据
source_mask: 源数据的mask
"""
return self.encoder(self.src_embed(source), source_mask)
def decode(self, memory, source_mask, target,target_mask):
return self.decoder(self.tgt_embed(target), memory, source_mask,target_mask)
def forward(self,source, target, source_mask, target_mask):
return self.decode(self.encode(source, source_mask), source_mask,target,target_mask)
# Tansformer模型的构建过程代码
def make_model(source_vocab, target_vocab, N=6,d_model=512, d_ff=2048, head=8, dropout=0.1):
"""
该函数用来构建模型,有7个参数,分别是源数据特征(词汇)总数,目标数据特征(词汇)总数,编码器和解码器堆叠数,
词向量映射维度,前馈全连接网络中变换矩阵的维度,多头注意力结构中的多头数,以及置零比率dropout
"""
c = copy.deepcopy
#实例化多头注意力
attn = MultiHeadedAttention(head, d_mode)
# 实例化前馈全连接层 得到对象ff
ff = PositionalEncoding(d_mode, dropout)
# 实例化位置编码类,得到对象position
position = PositionalEncoding(d_mode,dropout)
# 根据结构图,最外层是EncoderDecoder,在EncoderDecoder中,
# 分别是编码器层,解码器层,源数据Embedding层和位置编码组成的有序结构
# 目标数据Embedding层和位置编码组成的有序结构,以及类别生成器层。在编码器层中有attention子层以及前馈全连接子层,
# 在解码器层中有两个attention子层以及前馈全连接层
model =EncoderDecoder(Encoder(EncoderLayer(d_mode, c(attn), c(ff), dropout),N),
Decoder(DecoderLayer(d_mode, c(attn), c(attn),c(ff),dropout),N),
nn.Sequential(Embeddings(d_mode,source_vocab), c(position)),
nn.Sequential(Embeddings(d_mode, target_vocab), c(position)),
Generator(d_mode, target_vocab)
)
# 模型结构完成后,接下来就是初始化模型中的参数,比如线性层中的变换矩阵,这里一但判断参数的维度大于1,
# 则会将其初始化成一个服从均匀分布的矩阵
for p in model.parameters():
if p.dim()>1:
nn.init.xavier_uniform(p)
return model
if __name__ == "__main__":
# 词嵌入
dim = 512
vocab =1000
emb = Embeddings(dim,vocab)
x = torch.LongTensor([[100,2,321,508],[321,234,456,324]])
embr =emb(x)
print("embr.shape = ",embr.shape)
# 位置编码
pe = PositionalEncoding(dim,0.1) # 位置向量的维度是20,dropout是0
pe_result = pe(embr)
print("pe_result.shape = ",pe_result.shape)
# 编码器测试
size = 512
dropout=0.2
head=8
d_model=512
d_ff = 64
c = copy.deepcopy
x = pe_result
self_attn = MultiHeadedAttention(head,d_model,dropout)
ff = PositionwiseFeedForward(d_model,d_ff,dropout)
# 编码器层不是共享的,因此需要深度拷贝
layer= EncoderLayer(size,c(self_attn),c(ff),dropout)
N=8
mask = torch.zeros(8,4,4)
en = Encoder(layer,N)
en_result = en(x,mask)
print("en_result.shape : ",en_result.shape)
print("en_result : ",en_result)
# 解码器层测试
size = 512
dropout=0.2
head=8
d_model=512
d_ff = 64
self_attn = src_attn = MultiHeadedAttention(head,d_model,dropout)
ff = PositionwiseFeedForward(d_model,d_ff,dropout)
x = pe_result
mask = torch.zeros(8,4,4)
source_mask = target_mask = mask
memory = en_result
dl = DecoderLayer(size,self_attn,src_attn,ff,dropout)
dl_result = dl(x,memory,source_mask,target_mask)
print("dl_result.shape = ", dl_result.shape)
print("dl_result = ", dl_result)
# 解码器测试
size = 512
dropout=0.2
head=8
d_model=512
d_ff = 64
memory = en_result
c = copy.deepcopy
x = pe_result
self_attn = MultiHeadedAttention(head,d_model,dropout)
ff = PositionwiseFeedForward(d_model,d_ff,dropout)
# 编码器层不是共享的,因此需要深度拷贝
layer= DecoderLayer(size,c(self_attn),c(self_attn),c(ff),dropout)
N=8
mask = torch.zeros(8,4,4)
source_mask = target_mask = mask
de = Decoder(layer,N)
de_result = de(x,memory,source_mask, target_mask)
print("de_result.shape : ",de_result.shape)
print("de_result : ",de_result)
# 输出测试
d_model = 512
vocab =1000
x = de_result
gen = Generator(d_mode=d_model,vocab_size=vocab)
gen_result = gen(x)
print("gen_result.shape :", gen_result.shape)
print("gen_result: ", gen_result)
# encoderdeconder 测试
vocab_size = 1000
d_mode = 512
encoder = en
decoder= de
source_embed = nn.Embedding(vocab_size, d_mode)
target_embed = nn.Embedding(vocab_size, d_mode)
generator = gen
source = target = torch.LongTensor([[100,2,321,508],[321,234,456,324]])
source_mask = target_mask = torch.zeros(8,4,4)
ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
ed_result = ed(source, target, source_mask, target_mask)
print("ed_result.shape: ", ed_result.shape)
print("ed_result: ", ed_result)
# transformer 测试
source_vocab = 11
target_vocab = 11
N=6
# 其他参数使用默认值
res = make_model(source_vocab, target_vocab,6)
print(res)
打印模型层结构:
EncoderDecoder(
(encoder): Encoder(
(layers): ModuleList(
(0): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(2): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(3): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(4): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(5): EncoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(decoder): Decoder(
(layers): ModuleList(
(0): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(2): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(3): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(4): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(5): DecoderLayer(
(self_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadedAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNorm()
)
(src_embed): Sequential(
(0): Embeddings(
(lut): Embedding(11, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(tgt_embed): Sequential(
(0): Embeddings(
(lut): Embedding(11, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(generator): Generator(
(project): Linear(in_features=512, out_features=11, bias=True)
)
)测试Transformer运行
我们将通过一个小的copy任务完成模型的基本测试工作
copy任务介绍:
任务描述:
针对数字序列进行学习,学习的最终目标是使输出与输入的序列相同.如输入[1,5,8,9,3],输出也是[1,5,8,9,3].
任务意义:
copy任务在模型基础测试中具有重要意义,因为copy操作对于模型来讲是一条明显规律,因此模型能否在短时间内,小数据集中学会它,可以帮助我们断定模型所有过程是否正常,是否已具备基本学习能力.
使用copy任务进行模型基本测试的四步曲:
第一步: 构建数据集生成器
第二步: 获得Transformer模型及其优化器和损失函数
第三步: 运行模型进行训练和评估
第四步: 使用模型进行贪婪解码
code
from transformer import make_model
import torch
import numpy as np
from pyitcast.transformer_utils import Batch
# 第一步: 构建数据集生成器
def data_generator(V, batch, num_batch):
# 该函数用于随机生成copy任务的数据,它的三个输入参数是V:随机生成数字的最大值+1,
# batch:每次输送给模型更新一次参数的数据量,num_batch:-共输送num_batch次完成一轮
for i in range(num_batch):
data = torch.from_numpy(np.random.randint(1,V, size=(batch,10),dtype="int64"))
data[:,0]=1
source = torch.tensor(data,requires_grad=False)
target = torch.tensor(data, requires_grad=False)
yield Batch(source, target)
# 第二步: 获得Transformer模型及其优化器和损失函数
# 导入优化器工具包get_std_opt,该工具用于获得标准的针对Transformer模型的优化器
# 该标准优化器基于Adam优化器,使其对序列到序列的任务更有效
from pyitcast.transformer_utils import get_std_opt
# 导入标签平滑工具包,该工具用于标签平滑,标签平滑的作用就是小幅度的改变原有标签值的值域
# 因为在理论上即使是人工的标注数据也可能并非完全正确,会受到一些外界因素的影响而产生一些微小的偏差
# 因此使用标签平滑来弥补这种偏差,减少模型对某一条规律的绝对认知,以防止过拟合。通过下面示例了解更清晰
from pyitcast.transformer_utils import LabelSmoothing
# 导入损失计算工具包,该工具能够使用标签平滑后的结果进行损失的计算,
# 损失的计算方法可以认为是交叉熵损失函数。
from pyitcast.transformer_utils import SimpleLossCompute
# 将生成0-10的整数
V = 11
# 每次喂给模型20个数据进行更新参数
batch = 20
# 连续喂30次完成全部数据的遍历,也就是一轮
num_batch = 30
# 使用make_model构建模型
model = make_model(V,V,N=2)
print(model.src_embed[0])
# 使用get_std_opt获得模型优化器
model_optimizer = get_std_opt(model)
# 使用labelSmoothing获得标签平滑对象
# 使用LabelSmoothing实例化一个crit对象。
# 第一个参数size代表目标数据的词汇总数,也是模型最后一层得到张量的最后一维大小
# 这里是5说明目标词汇总数是5个,第二个参数padding_idx表示要将那些tensor中的数字
# 替换成0,一般padding_idx=0表示不进行替换。第三个参数smoothing,表示标签的平滑程度
# 如原来标签的表示值为1,则平滑后它的值域变为[1-smoothing,1+smoothing].
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获取到标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator,criterion,model_optimizer)
# 第三步: 运行模型进行训练和评估
from pyitcast.transformer_utils import run_epoch
def run(model, loss, epochs=10):
for epoch in range(epochs):
# 进入训练模式,所有参数更新
model.train()
# 训练时batchsize是20
run_epoch(data_generator(V,8,20),model,loss)
model.eval()
run_epoch(data_generator(V,8,5),model,loss)
if __name__ == "__main__":
# 将生成0-10的整数
V = 11
# 每次喂给模型20个数据进行更新参数
batch = 20
# 连续喂30次完成全部数据的遍历,也就是一轮
num_batch = 30
res = data_generator(V,batch, num_batch)
run(model, loss)
如果直接跑上面的可能会报错,报错的主要原因是 pyitcast主要是针对pytorch 的版本很低,但是好像这个库也不升级了,所以你如果想要跑通,就需要修改下面两个地方:
第一个错误:'Embeddings' object has no attribute 'd_model'

从上面可以看到,get_std_opt需要用到嵌入向量的维度,但是没有这个值,这个时候可以从两个地方修改,一个是我们embeding的类增加这个属性即:
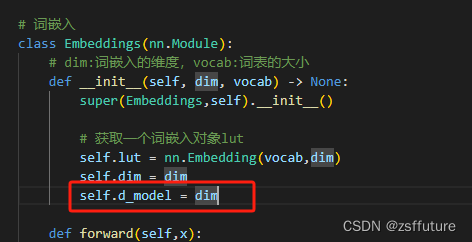
第二种方法,直接进入 get_std_opt函数里面,修改这个参数

以上两个都可以解决问题
第二个问题:RuntimeError: scatter(): Expected dtype int64 for index
这个属于数据类型的问题,主要是在生成训练数据时的问题,如下修改:

这样就可以正常训练了
输出:
Epoch Step: 1 Loss: 3.169641 Tokens per Sec: 285.952789
Epoch Step: 1 Loss: 2.517479 Tokens per Sec: 351.509888
Epoch Step: 1 Loss: 2.595001 Tokens per Sec: 294.475616
Epoch Step: 1 Loss: 2.108872 Tokens per Sec: 476.050293
Epoch Step: 1 Loss: 2.229053 Tokens per Sec: 387.324188
Epoch Step: 1 Loss: 1.810681 Tokens per Sec: 283.639557
Epoch Step: 1 Loss: 2.047313 Tokens per Sec: 394.773773
Epoch Step: 1 Loss: 1.724596 Tokens per Sec: 415.394714
Epoch Step: 1 Loss: 1.850358 Tokens per Sec: 421.050873
Epoch Step: 1 Loss: 1.668582 Tokens per Sec: 368.275421
Epoch Step: 1 Loss: 2.005047 Tokens per Sec: 424.458466
Epoch Step: 1 Loss: 1.632835 Tokens per Sec: 408.158966
Epoch Step: 1 Loss: 1.698805 Tokens per Sec: 441.689392
Epoch Step: 1 Loss: 1.567691 Tokens per Sec: 392.488251
Epoch Step: 1 Loss: 1.765411 Tokens per Sec: 428.815796
Epoch Step: 1 Loss: 1.492155 Tokens per Sec: 426.288910
Epoch Step: 1 Loss: 1.541114 Tokens per Sec: 411.078918
Epoch Step: 1 Loss: 1.469818 Tokens per Sec: 454.231476
Epoch Step: 1 Loss: 1.677189 Tokens per Sec: 431.382690
Epoch Step: 1 Loss: 1.377327 Tokens per Sec: 433.725250
引入贪婪解码,并进行了训练测试
from transformer import make_model
import torch
import numpy as np
from pyitcast.transformer_utils import Batch
# 第一步: 构建数据集生成器
def data_generator(V, batch, num_batch):
# 该函数用于随机生成copy任务的数据,它的三个输入参数是V:随机生成数字的最大值+1,
# batch:每次输送给模型更新一次参数的数据量,num_batch:-共输送num_batch次完成一轮
for i in range(num_batch):
data = torch.from_numpy(np.random.randint(1,V, size=(batch,10),dtype="int64"))
data[:,0]=1
source = torch.tensor(data,requires_grad=False)
target = torch.tensor(data, requires_grad=False)
yield Batch(source, target)
# 第二步: 获得Transformer模型及其优化器和损失函数
# 导入优化器工具包get_std_opt,该工具用于获得标准的针对Transformer模型的优化器
# 该标准优化器基于Adam优化器,使其对序列到序列的任务更有效
from pyitcast.transformer_utils import get_std_opt
# 导入标签平滑工具包,该工具用于标签平滑,标签平滑的作用就是小幅度的改变原有标签值的值域
# 因为在理论上即使是人工的标注数据也可能并非完全正确,会受到一些外界因素的影响而产生一些微小的偏差
# 因此使用标签平滑来弥补这种偏差,减少模型对某一条规律的绝对认知,以防止过拟合。通过下面示例了解更清晰
from pyitcast.transformer_utils import LabelSmoothing
# 导入损失计算工具包,该工具能够使用标签平滑后的结果进行损失的计算,
# 损失的计算方法可以认为是交叉熵损失函数。
from pyitcast.transformer_utils import SimpleLossCompute
# 将生成0-10的整数
V = 11
# 每次喂给模型20个数据进行更新参数
batch = 20
# 连续喂30次完成全部数据的遍历,也就是一轮
num_batch = 30
# 使用make_model构建模型
model = make_model(V,V,N=2)
# 使用get_std_opt获得模型优化器
model_optimizer = get_std_opt(model)
# 使用labelSmoothing获得标签平滑对象
# 使用LabelSmoothing实例化一个crit对象。
# 第一个参数size代表目标数据的词汇总数,也是模型最后一层得到张量的最后一维大小
# 这里是5说明目标词汇总数是5个,第二个参数padding_idx表示要将那些tensor中的数字
# 替换成0,一般padding_idx=0表示不进行替换。第三个参数smoothing,表示标签的平滑程度
# 如原来标签的表示值为1,则平滑后它的值域变为[1-smoothing,1+smoothing].
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
# 使用SimpleLossCompute获取到标签平滑结果的损失计算方法
loss = SimpleLossCompute(model.generator,criterion,model_optimizer)
# 第三步: 运行模型进行训练和评估
from pyitcast.transformer_utils import run_epoch
def run(model, loss, epochs=10):
for epoch in range(epochs):
# 进入训练模式,所有参数更新
model.train()
# 训练时batchsize是20
run_epoch(data_generator(V,8,20),model,loss)
model.eval()
run_epoch(data_generator(V,8,5),model,loss)
# 引入贪婪解码
# 导入贪婪解码工具包greedy_decode,该工具将对最终结进行贪婪解码贪婪解码的方式是每次预测都选择概率最大的结果作为输出,
# 它不一定能获得全局最优性,但却拥有最高的执行效率。
from pyitcast.transformer_utils import greedy_decode
def run_greedy(model, loss, epochs=10):
for epoch in range(epochs):
# 进入训练模式,所有参数更新
model.train()
# 训练时batchsize是20
run_epoch(data_generator(V,8,20),model,loss)
model.eval()
run_epoch(data_generator(V,8,5),model,loss)
model.eval()
# 假定输入张量
source = torch.LongTensor([[1,8,3,4,10,6,7,2,9,5]])
# 定义源数据掩码张量,因为元素都是1,在我们这里1代表不遮掩因此相当于对源数据没有任何遮掩.
source_mask = torch.ones(1,1,10)
# 最后将model,src,src_mask,解码的最大长度限制max_len,默认为10
# 以及起始标志数字,默认为1,我们这里使用的也是1
result = greedy_decode(model, source, source_mask, max_len=10,start_symbol=1)
print(result)
if __name__ == "__main__":
# # 将生成0-10的整数
# V = 11
# # 每次喂给模型20个数据进行更新参数
# batch = 20
# # 连续喂30次完成全部数据的遍历,也就是一轮
# num_batch = 30
# res = data_generator(V,batch, num_batch)
# run(model, loss)
run_greedy(model, loss,50)
输出部分结果:
Epoch Step: 1 Loss: 0.428033 Tokens per Sec: 389.530670
Epoch Step: 1 Loss: 0.317753 Tokens per Sec: 399.060852
Epoch Step: 1 Loss: 0.192723 Tokens per Sec: 387.384308
Epoch Step: 1 Loss: 0.257650 Tokens per Sec: 379.354736
Epoch Step: 1 Loss: 0.487521 Tokens per Sec: 410.506714
Epoch Step: 1 Loss: 0.136969 Tokens per Sec: 388.222687
Epoch Step: 1 Loss: 0.119838 Tokens per Sec: 375.405731
Epoch Step: 1 Loss: 0.250391 Tokens per Sec: 408.776367
Epoch Step: 1 Loss: 0.376862 Tokens per Sec: 419.787231
Epoch Step: 1 Loss: 0.163561 Tokens per Sec: 393.896088
Epoch Step: 1 Loss: 0.303041 Tokens per Sec: 395.884857
Epoch Step: 1 Loss: 0.126261 Tokens per Sec: 386.709167
Epoch Step: 1 Loss: 0.237891 Tokens per Sec: 376.114075
Epoch Step: 1 Loss: 0.139017 Tokens per Sec: 405.207336
Epoch Step: 1 Loss: 0.414842 Tokens per Sec: 389.219666
Epoch Step: 1 Loss: 0.207141 Tokens per Sec: 392.840820
tensor([[ 1, 8, 3, 4, 10, 6, 7, 2, 9, 5]])从上面的代码可以看出测试输入的 是 source = torch.LongTensor([[1,8,3,4,10,6,7,2,9,5]])
推理出来的结果是完全正确的,因为我把epoch设置为50了,如果是10就会有错误的情况,大家可以尝试






![[Python人工智能] 四十二.命名实体识别 (3)基于Bert+BiLSTM-CRF的中文实体识别万字详解(异常解决中)](https://img-blog.csdnimg.cn/bf1659094a5b4541a19a93c14fafa5d1.png#pic_center)
![[C语言][详解指针][指针的思维导图][超详细!!!](一)](https://img-blog.csdnimg.cn/direct/f8cf5d363f5f4bd69341840c7184b019.jpeg)