import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
warnings.filterwarnings("ignore") # 忽略警告信息
# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)train.csv 链接:https://pan.baidu.com/s/1Vnyvo5T5eSuzb0VwTsznqA?pwd=fqok 提取码:fqok import pandas as pd
# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()
# 构建数据集迭代器
def coustom_data_iter(texts, labels):
for x, y in zip(texts, labels):
yield x, y
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])1.构建词典:
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba
# 中文分词方法
tokenizer = jieba.lcut
def yield_tokens(data_iter):
for text, in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])调用vocab(词汇表)对一个中文句子进行索引转换,这个句子被分词后得到的词汇列表会被转换成它们在词汇表中的索引。
print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))
生成一个标签列表,用于查看在数据集中所有可能的标签类型。
label_name = list(set(train_data[1].values[:]))
print(label_name)创建了两个lambda函数,一个用于将文本转换成词汇索引,另一个用于将标签文本转换成它们在label_name列表中的索引。
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)
print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))2.生成数据批次和迭代器
from torch.utils.data import DataLoader
def collate_batch(batch):
label_list, text_list, offsets = [], [], [0]
for (_text, _label) in batch:
# 标签列表
label_list.append(label_pipeline(_label))
# 文本列表
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
# 偏移量,即词汇的起始位置
offsets.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.int64)
text_list = torch.cat(text_list)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和
return text_list.to(device), label_list.to(device), offsets.to(device)
# 数据加载器,调用示例
dataloader = DataLoader(train_iter,
batch_size=8,
shuffle=False,
collate_fn=collate_batch)collate_batch函数用于处理数据加载器中的批次。它接收一个批次的数据,处理它,并返回适合模型训练的数据格式。
在这个函数内部,它遍历批次中的每个文本和标签对,将标签添加到label_list,将文本通过text_pipeline函数处理后转换为tensor,并添加到text_list。
offsets列表用于存储每个文本的长度,这对于后续的文本处理非常有用,尤其是当你需要知道每个文本在拼接的大tensor中的起始位置时。
text_list用torch.cat进行拼接,形成一个连续的tensor。
offsets列表的最后一个元素不包括,然后使用cumsum函数在第0维计算累积和,这为每个序列提供了一个累计的偏移量。
3.搭建模型与初始化
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
num_class = len(label_name) # 类别数,根据label_name的长度确定
vocab_size = len(vocab) # 词汇表的大小,根据vocab的长度确定
em_size = 64 # 嵌入向量的维度设置为64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device) # 创建模型实例并移动到计算设备
4.模型训练及评估函数
train 和 evaluate分别用于训练和评估文本分类模型。
训练函数 train 的工作流程如下:
将模型设置为训练模式。
初始化总准确率、训练损失和总计数变量。
记录训练开始的时间。
遍历数据加载器,对每个批次:
进行预测。
清零优化器的梯度。
计算损失(使用一个损失函数,例如交叉熵)。
反向传播计算梯度。
通过梯度裁剪防止梯度爆炸。
执行一步优化器更新模型权重。
更新总准确率和总损失。
每隔一定间隔,打印训练进度和统计信息。
评估函数 evaluate 的工作流程如下:
将模型设置为评估模式。
初始化总准确率和总损失。
不计算梯度(为了节省内存和计算资源)。
遍历数据加载器,对每个批次:
进行预测。
计算损失。
更新总准确率和总损失。
返回整体的准确率和平均损失。
代码实现:
import time
def train(dataloader):
model.train() # 切换到训练模式
total_acc, train_loss, total_count = 0, 0, 0
log_interval = 50
start_time = time.time()
for idx, (text, label, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
optimizer.zero_grad() # 梯度归零
loss = criterion(predicted_label, label) # 计算损失
loss.backward() # 反向传播
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪
optimizer.step() # 优化器更新权重
# 记录acc和loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches '
'| accuracy {:8.3f} | loss {:8.5f}'.format(
epoch, idx, len(dataloader),
total_acc/total_count, train_loss/total_count))
total_acc, train_loss, total_count = 0, 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval() # 切换到评估模式
total_acc, total_count = 0, 0
with torch.no_grad():
for idx, (text, label, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label) # 计算loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc/total_count, total_count5.模型训练
设置训练的轮数、学习率和批次大小。
定义交叉熵损失函数、随机梯度下降优化器和学习率调度器。
将训练数据转换为一个map样式的数据集,并将其分成训练集和验证集。
创建训练和验证的数据加载器。
开始训练循环,每个epoch都会训练模型并在验证集上评估模型的准确率和损失。
如果验证准确率没有提高,则按计划降低学习率。
打印每个epoch结束时的统计信息,包括时间、准确率、损失和学习率。
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小
# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None
# 准备数据集
train_iter = coustom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_, split_valid_ = random_split(train_dataset,
[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
# 训练循环
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
val_acc, val_loss = evaluate(valid_dataloader)
# 更新学习率的策略
lr = optimizer.state_dict()['param_groups'][0]['lr']
if total_accu is not None and total_accu > val_acc:
scheduler.step()
else:
total_accu = val_acc
print('-' * 69)
print('| end of epoch {:3d} | time: {:4.2f}s | '
'valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(
epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))
print('-' * 69)运行结果:
| epoch 1 | 50/ 152 batches | accuracy 0.423 | loss 0.03079
| epoch 1 | 100/ 152 batches | accuracy 0.700 | loss 0.01912
| epoch 1 | 150/ 152 batches | accuracy 0.776 | loss 0.01347
---------------------------------------------------------------------
| end of epoch 1 | time: 1.53s | valid accuracy 0.777 | valid loss 2420.000 | lr 5.000000
| epoch 2 | 50/ 152 batches | accuracy 0.812 | loss 0.01056
| epoch 2 | 100/ 152 batches | accuracy 0.843 | loss 0.00871
| epoch 2 | 150/ 152 batches | accuracy 0.844 | loss 0.00846
---------------------------------------------------------------------
| end of epoch 2 | time: 1.45s | valid accuracy 0.842 | valid loss 2420.000 | lr 5.000000
| epoch 3 | 50/ 152 batches | accuracy 0.883 | loss 0.00653
| epoch 3 | 100/ 152 batches | accuracy 0.879 | loss 0.00634
| epoch 3 | 150/ 152 batches | accuracy 0.883 | loss 0.00627
---------------------------------------------------------------------
| end of epoch 3 | time: 1.44s | valid accuracy 0.865 | valid loss 2420.000 | lr 5.000000
| epoch 4 | 50/ 152 batches | accuracy 0.912 | loss 0.00498
| epoch 4 | 100/ 152 batches | accuracy 0.906 | loss 0.00495
| epoch 4 | 150/ 152 batches | accuracy 0.915 | loss 0.00461
---------------------------------------------------------------------
| end of epoch 4 | time: 1.50s | valid accuracy 0.876 | valid loss 2420.000 | lr 5.000000
| epoch 5 | 50/ 152 batches | accuracy 0.935 | loss 0.00386
| epoch 5 | 100/ 152 batches | accuracy 0.934 | loss 0.00390
| epoch 5 | 150/ 152 batches | accuracy 0.932 | loss 0.00362
---------------------------------------------------------------------
| end of epoch 5 | time: 1.59s | valid accuracy 0.881 | valid loss 2420.000 | lr 5.000000
| epoch 6 | 50/ 152 batches | accuracy 0.947 | loss 0.00313
| epoch 6 | 100/ 152 batches | accuracy 0.949 | loss 0.00307
| epoch 6 | 150/ 152 batches | accuracy 0.949 | loss 0.00286
---------------------------------------------------------------------
| end of epoch 6 | time: 1.68s | valid accuracy 0.891 | valid loss 2420.000 | lr 5.000000
| epoch 7 | 50/ 152 batches | accuracy 0.960 | loss 0.00243
| epoch 7 | 100/ 152 batches | accuracy 0.963 | loss 0.00224
| epoch 7 | 150/ 152 batches | accuracy 0.959 | loss 0.00252
---------------------------------------------------------------------
| end of epoch 7 | time: 1.53s | valid accuracy 0.892 | valid loss 2420.000 | lr 5.000000
| epoch 8 | 50/ 152 batches | accuracy 0.972 | loss 0.00186
| epoch 8 | 100/ 152 batches | accuracy 0.974 | loss 0.00184
| epoch 8 | 150/ 152 batches | accuracy 0.967 | loss 0.00201
---------------------------------------------------------------------
| end of epoch 8 | time: 1.43s | valid accuracy 0.895 | valid loss 2420.000 | lr 5.000000
| epoch 9 | 50/ 152 batches | accuracy 0.981 | loss 0.00138
| epoch 9 | 100/ 152 batches | accuracy 0.977 | loss 0.00165
| epoch 9 | 150/ 152 batches | accuracy 0.980 | loss 0.00147
---------------------------------------------------------------------
| end of epoch 9 | time: 1.48s | valid accuracy 0.900 | valid loss 2420.000 | lr 5.000000
| epoch 10 | 50/ 152 batches | accuracy 0.987 | loss 0.00117
| epoch 10 | 100/ 152 batches | accuracy 0.985 | loss 0.00121
| epoch 10 | 150/ 152 batches | accuracy 0.984 | loss 0.00121
---------------------------------------------------------------------
| end of epoch 10 | time: 1.45s | valid accuracy 0.902 | valid loss 2420.000 | lr 5.000000
---------------------------------------------------------------------6.模型评估
test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))7.模型测试
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = model(text, torch.tensor([0]))
return output.argmax(1).item()
# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"
model = model.to("cpu")
print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])8.全部代码(部分修改):
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
warnings.filterwarnings("ignore") # 忽略警告信息
# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import pandas as pd
# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()
# 构建数据集迭代器
def custom_data_iter(texts, labels):
for x, y in zip(texts, labels):
yield x, y
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba
# 中文分词方法
tokenizer = jieba.lcut
def yield_tokens(data_iter):
for text,_ in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])
print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))
label_name = list(set(train_data[1].values[:]))
print(label_name)
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)
print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))
from torch.utils.data import DataLoader
def collate_batch(batch):
label_list, text_list, offsets = [], [], [0]
for (_text, _label) in batch:
# 标签列表
label_list.append(label_pipeline(_label))
# 文本列表
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
# 偏移量,即词汇的起始位置
offsets.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.int64)
text_list = torch.cat(text_list)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和
return text_list.to(device), label_list.to(device), offsets.to(device)
# 数据加载器,调用示例
dataloader = DataLoader(train_iter,
batch_size=8,
shuffle=False,
collate_fn=collate_batch)
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)
import time
def train(dataloader):
model.train() # 切换到训练模式
total_acc, train_loss, total_count = 0, 0, 0
log_interval = 50
start_time = time.time()
for idx, (text, label, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
optimizer.zero_grad() # 梯度归零
loss = criterion(predicted_label, label) # 计算损失
loss.backward() # 反向传播
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪
optimizer.step() # 优化器更新权重
# 记录acc和loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches '
'| accuracy {:8.3f} | loss {:8.5f}'.format(
epoch, idx, len(dataloader),
total_acc/total_count, train_loss/total_count))
total_acc, train_loss, total_count = 0, 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval() # 切换到评估模式
total_acc, total_count = 0, 0
with torch.no_grad():
for idx, (text, label, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label) # 计算loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc/total_count, total_count
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小
# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None
# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_, split_valid_ = random_split(train_dataset,
[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
# 训练循环
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
val_acc, val_loss = evaluate(valid_dataloader)
# 更新学习率的策略
lr = optimizer.state_dict()['param_groups'][0]['lr']
if total_accu is not None and total_accu > val_acc:
scheduler.step()
else:
total_accu = val_acc
print('-' * 69)
print('| end of epoch {:3d} | time: {:4.2f}s | '
'valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(
epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))
print('-' * 69)
test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = model(text, torch.tensor([0]))
return output.argmax(1).item()
# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"
model = model.to("cpu")
print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])9.代码改进及优化
9.1优化器: 尝试不同的优化算法,如Adam、RMSprop替换原来的SGD优化器部分
9.1.1使用Adam优化器:
import torch
import torch.nn as nn
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
warnings.filterwarnings("ignore") # 忽略警告信息
# win10系统
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
import pandas as pd
# 加载自定义中文数据集
train_data = pd.read_csv('D:/train.csv', sep='\t', header=None)
train_data.head()
# 构建数据集迭代器
def custom_data_iter(texts, labels):
for x, y in zip(texts, labels):
yield x, y
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
import jieba
# 中文分词方法
tokenizer = jieba.lcut
def yield_tokens(data_iter):
for text,_ in data_iter:
yield tokenizer(text)
vocab = build_vocab_from_iterator(yield_tokens(train_iter), specials=["<unk>"])
vocab.set_default_index(vocab["<unk>"])
print(vocab(['我', '想', '看', '书', '和', '你', '一起', '看', '电影', '的', '新款', '视频']))
label_name = list(set(train_data[1].values[:]))
print(label_name)
text_pipeline = lambda x: vocab(tokenizer(x))
label_pipeline = lambda x: label_name.index(x)
print(text_pipeline('我想看新闻或者上网站看最新的游戏视频'))
print(label_pipeline('Video-Play'))
from torch.utils.data import DataLoader
def collate_batch(batch):
label_list, text_list, offsets = [], [], [0]
for (_text, _label) in batch:
# 标签列表
label_list.append(label_pipeline(_label))
# 文本列表
processed_text = torch.tensor(text_pipeline(_text), dtype=torch.int64)
text_list.append(processed_text)
# 偏移量,即词汇的起始位置
offsets.append(processed_text.size(0))
label_list = torch.tensor(label_list, dtype=torch.int64)
text_list = torch.cat(text_list)
offsets = torch.tensor(offsets[:-1]).cumsum(dim=0) # 累计偏移量dim中维度元素的累计和
return text_list.to(device), label_list.to(device), offsets.to(device)
# 数据加载器,调用示例
dataloader = DataLoader(train_iter,
batch_size=8,
shuffle=False,
collate_fn=collate_batch)
from torch import nn
class TextClassificationModel(nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super(TextClassificationModel, self).__init__()
self.embedding = nn.EmbeddingBag(vocab_size, embed_dim, sparse=False)
self.fc = nn.Linear(embed_dim, num_class)
self.init_weights()
def init_weights(self):
initrange = 0.5
self.embedding.weight.data.uniform_(-initrange, initrange)
self.fc.weight.data.uniform_(-initrange, initrange)
self.fc.bias.data.zero_()
def forward(self, text, offsets):
embedded = self.embedding(text, offsets)
return self.fc(embedded)
num_class = len(label_name)
vocab_size = len(vocab)
em_size = 64
model = TextClassificationModel(vocab_size, em_size, num_class).to(device)
import time
def train(dataloader):
model.train() # 切换到训练模式
total_acc, train_loss, total_count = 0, 0, 0
log_interval = 50
start_time = time.time()
for idx, (text, label, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
optimizer.zero_grad() # 梯度归零
loss = criterion(predicted_label, label) # 计算损失
loss.backward() # 反向传播
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.1) # 梯度裁剪
optimizer.step() # 优化器更新权重
# 记录acc和loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
train_loss += loss.item()
total_count += label.size(0)
if idx % log_interval == 0 and idx > 0:
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches '
'| accuracy {:8.3f} | loss {:8.5f}'.format(
epoch, idx, len(dataloader),
total_acc/total_count, train_loss/total_count))
total_acc, train_loss, total_count = 0, 0, 0
start_time = time.time()
def evaluate(dataloader):
model.eval() # 切换到评估模式
total_acc, total_count = 0, 0
with torch.no_grad():
for idx, (text, label, offsets) in enumerate(dataloader):
predicted_label = model(text, offsets)
loss = criterion(predicted_label, label) # 计算loss
total_acc += (predicted_label.argmax(1) == label).sum().item()
total_count += label.size(0)
return total_acc/total_count, total_count
from torch.utils.data.dataset import random_split
from torchtext.data.functional import to_map_style_dataset
# 参数设置
EPOCHS = 10 # epoch数量
LR = 5 # 学习速率
BATCH_SIZE = 64 # 训练的batch大小
# 设置损失函数、优化器和调度器
criterion = torch.nn.CrossEntropyLoss()
#optimizer = torch.optim.SGD(model.parameters(), lr=LR)
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.1)
total_accu = None
# 准备数据集
train_iter = custom_data_iter(train_data[0].values[:], train_data[1].values[:])
train_dataset = to_map_style_dataset(train_iter)
split_train_, split_valid_ = random_split(train_dataset,
[int(len(train_dataset)*0.8), int(len(train_dataset)*0.2)])
train_dataloader = DataLoader(split_train_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
valid_dataloader = DataLoader(split_valid_, batch_size=BATCH_SIZE,
shuffle=True, collate_fn=collate_batch)
# 训练循环
for epoch in range(1, EPOCHS + 1):
epoch_start_time = time.time()
train(train_dataloader)
val_acc, val_loss = evaluate(valid_dataloader)
# 更新学习率的策略
lr = optimizer.state_dict()['param_groups'][0]['lr']
if total_accu is not None and total_accu > val_acc:
scheduler.step()
else:
total_accu = val_acc
print('-' * 69)
print('| end of epoch {:3d} | time: {:4.2f}s | '
'valid accuracy {:4.3f} | valid loss {:4.3f} | lr {:4.6f}'.format(
epoch, time.time() - epoch_start_time, val_acc, val_loss, lr))
print('-' * 69)
test_acc, test_loss = evaluate(valid_dataloader)
print('模型的准确率: {:5.4f}'.format(test_acc))
def predict(text, text_pipeline):
with torch.no_grad():
text = torch.tensor(text_pipeline(text))
output = model(text, torch.tensor([0]))
return output.argmax(1).item()
# 示例文本字符串
# ex_text_str = "例句输入——这是一个待预测类别的示例句子"
ex_text_str = "这不仅影响到我们的方案是否可行13号的"
model = model.to("cpu")
print("该文本的类别是: %s" % label_name[predict(ex_text_str, text_pipeline)])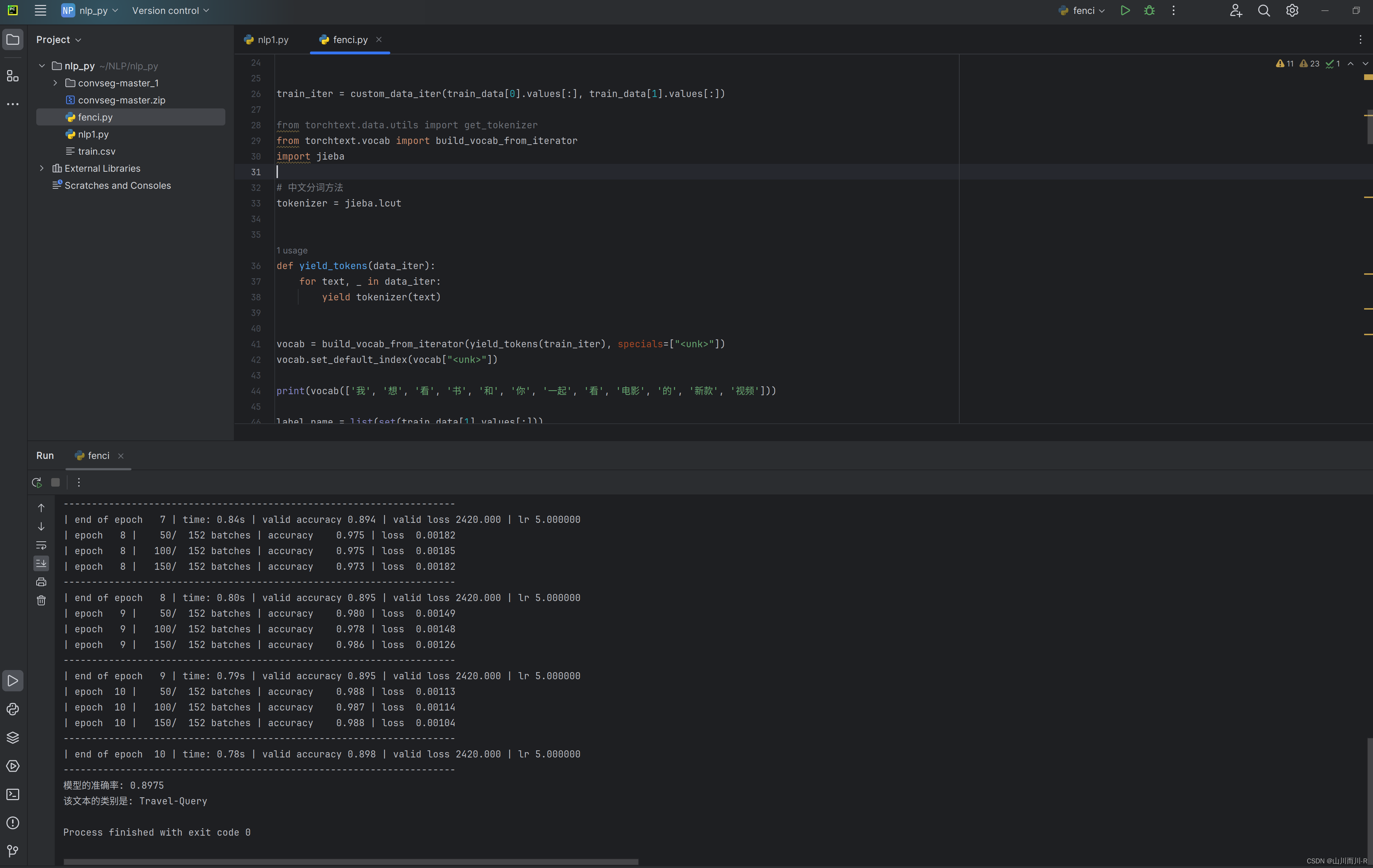
需要下载的库
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simplepip install torchtext -i https://pypi.tuna.tsinghua.edu.cn/simple