学习笔记自,慕课网 《Python3 入门人工智能》
https://https://coding.imooc.com/lesson/418.html#mid=32776
决策树、异常检测、主成分分析
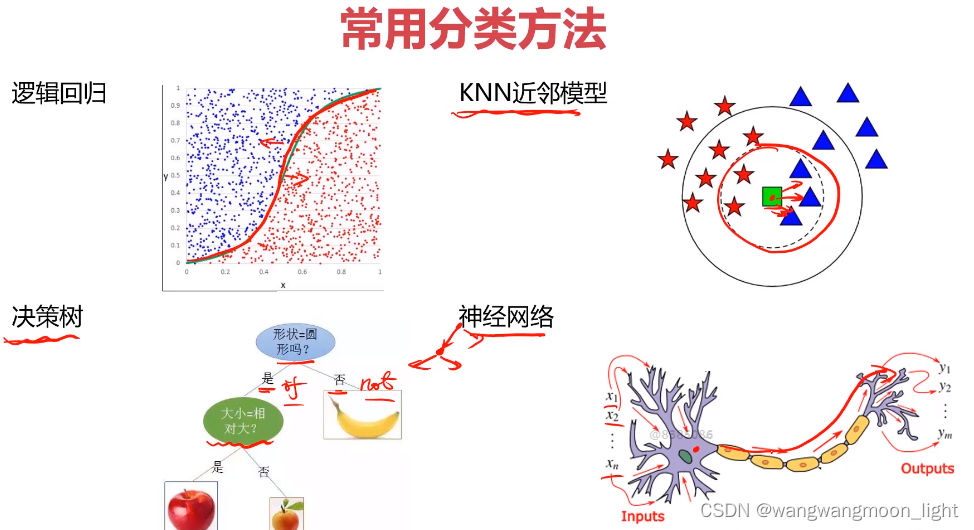
常用的分类方法:
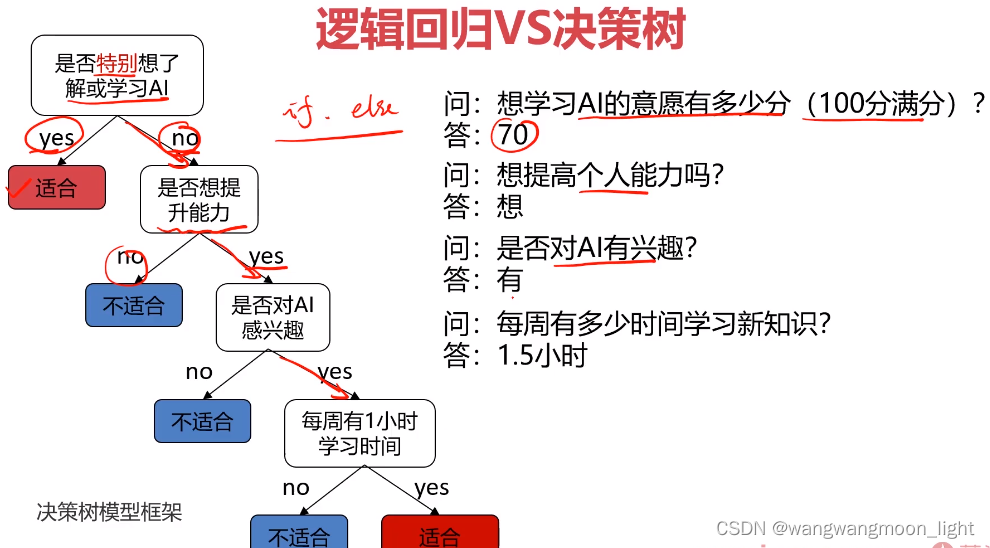
逻辑回归的思路:
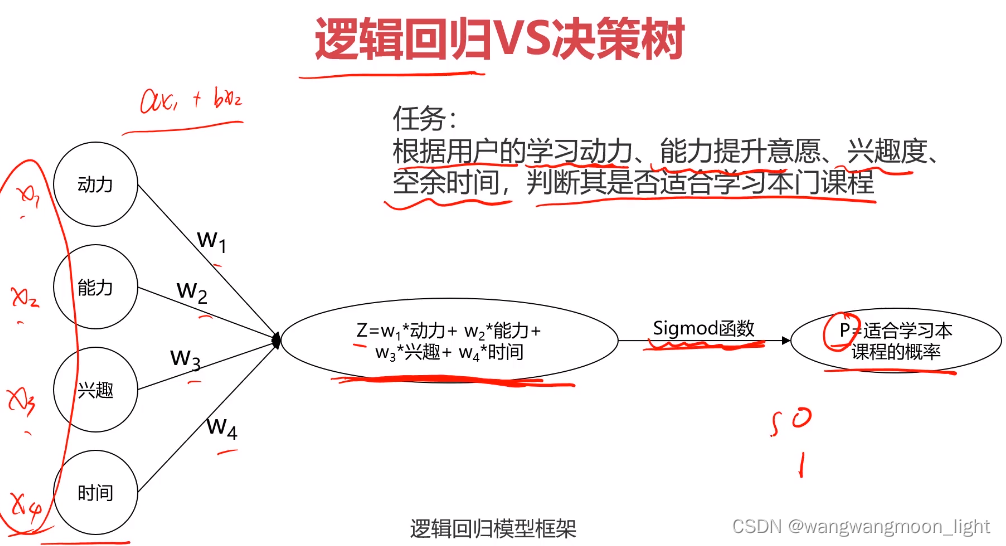
决策树的思路:
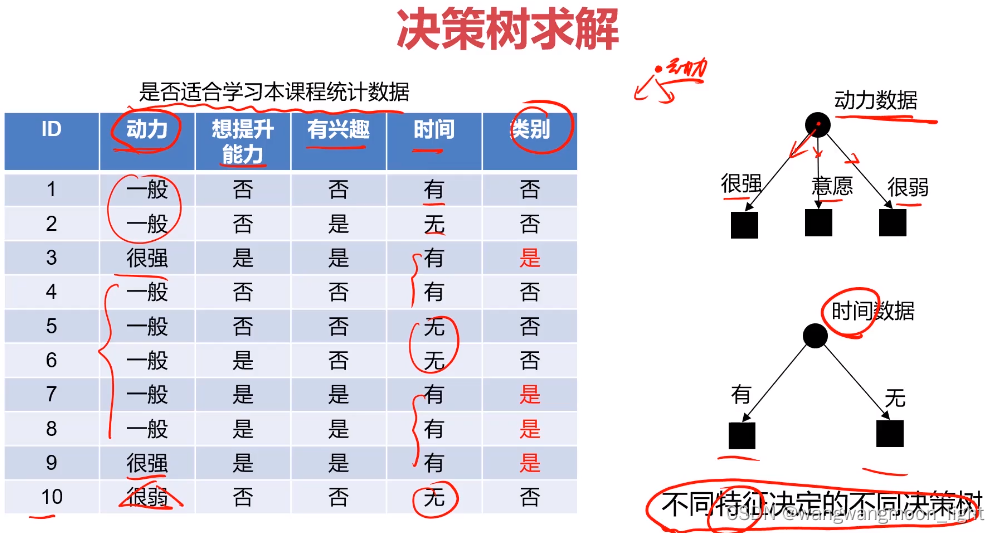
1. 决策树
1.1 ID3决策树:利用信息增益来划分节点
信息熵是度量样本集合纯度最常用的一种指标。假设样本集合D中第k类样本所占的比重为pk,那么信息熵的计算则为下面的计算方式
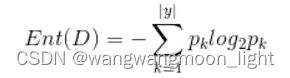
当这个Ent(D)的值越小,说明样本集合D的纯度就越高
有了信息熵,当我选择用样本的某一个属性a来划分样本集合D时,就可以得出用属性a对样本D进行划分所带来的“信息增益”
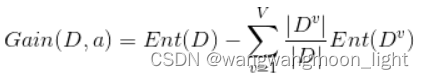
一般来讲,信息增益越大,说明如果用属性a来划分样本集合D,那么纯度会提升,因为我们分别对样本的所有属性计算增益情况,选择最大的来作为决策树的一个结点,或者可以说那些信息增益大的属性往往离根结点越近,因为我们会优先用能区分度大的也就是信息增益大的属性来进行划分。当一个属性已经作为划分的依据,在下面就不在参与竞选了,我们刚才说过根结点代表全部样本,而经过根结点下面属性各个取值后样本又可以按照相应属性值进行划分,并且在当前的样本下利用剩下的属性再次计算信息增益来进一步选择划分的结点,ID3决策树就是这样建立起来的。
1.2 使用ID3举例
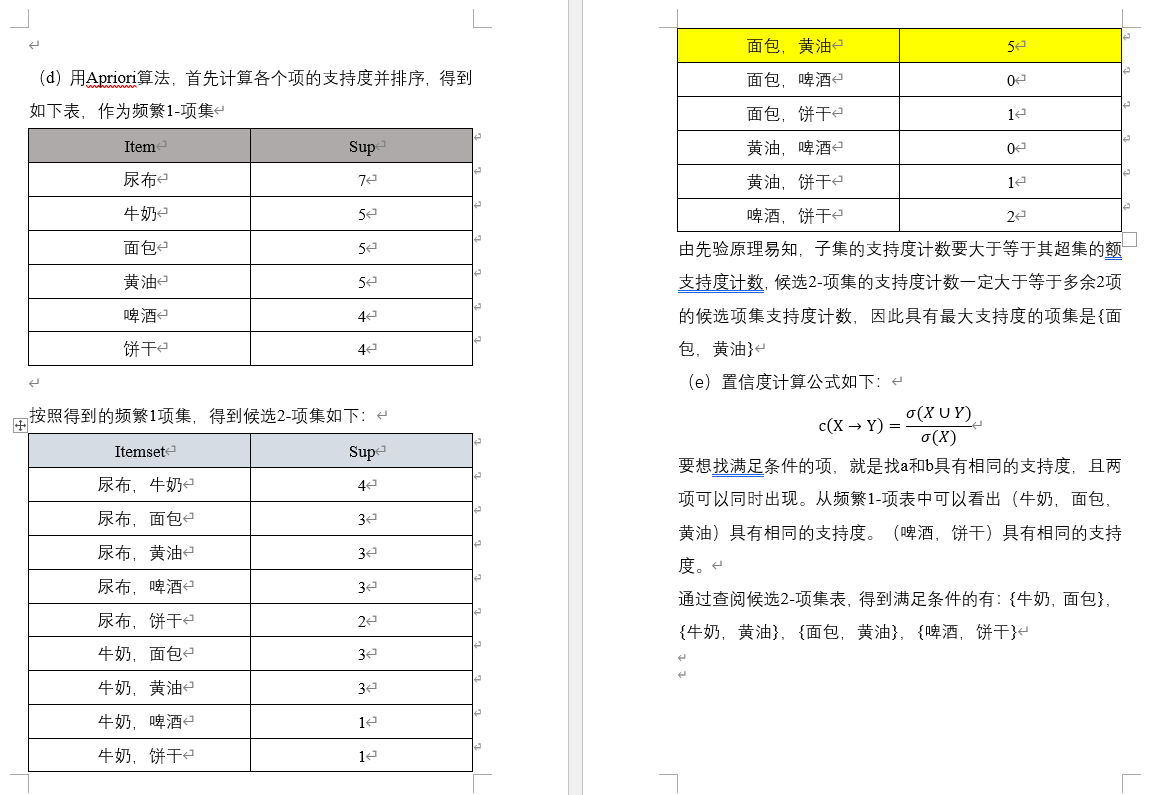
以兴趣为节点计算信息增益
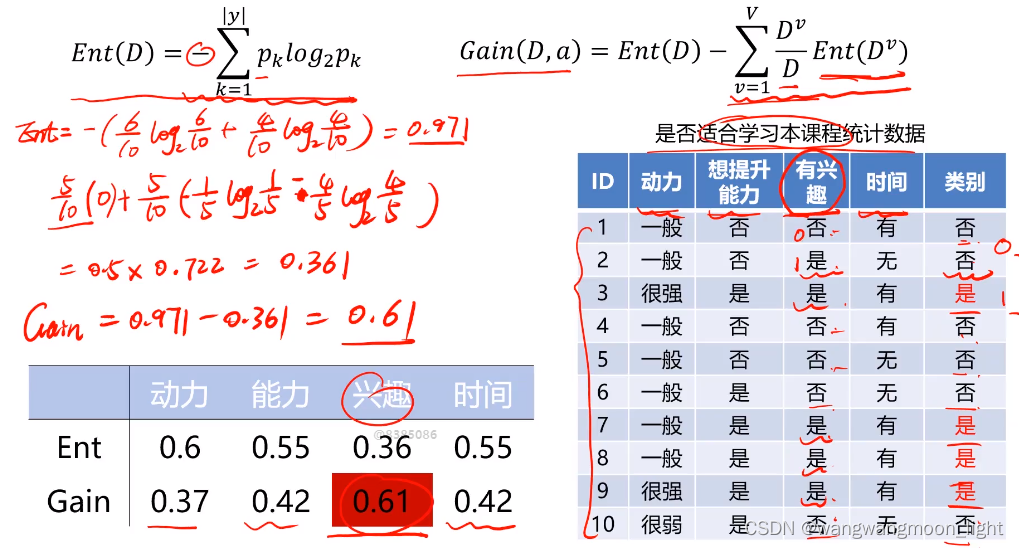
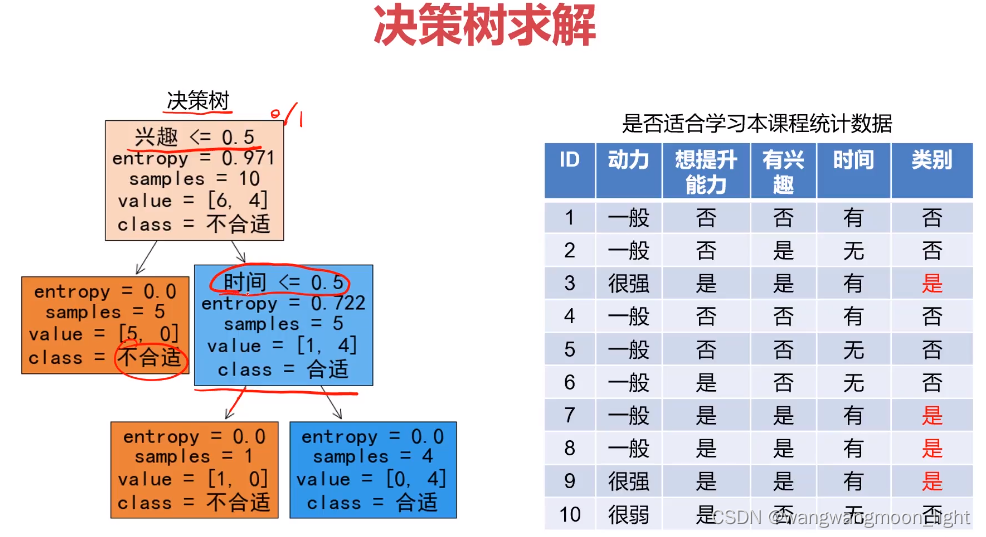
1、 计算表格中使用ID3算法建立决策树时各节点的信息增益
2、 根据信息增益画出决策树
3、 编程建立决策树模型
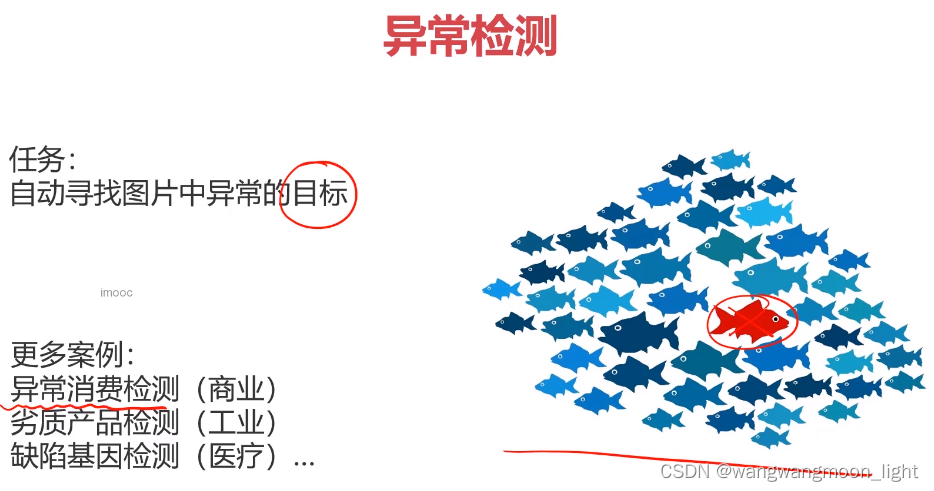
2. 异常检测
识别数据里的异常点





![LeetCode[703]数据流中的第K大元素](https://img-blog.csdnimg.cn/img_convert/19af8564ccb7483cbf6fbcf42cf69c77.png)