原始文档:https://developer.arm.com/documentation/102407/0100/?lang=en
CHI 总线拓扑结构
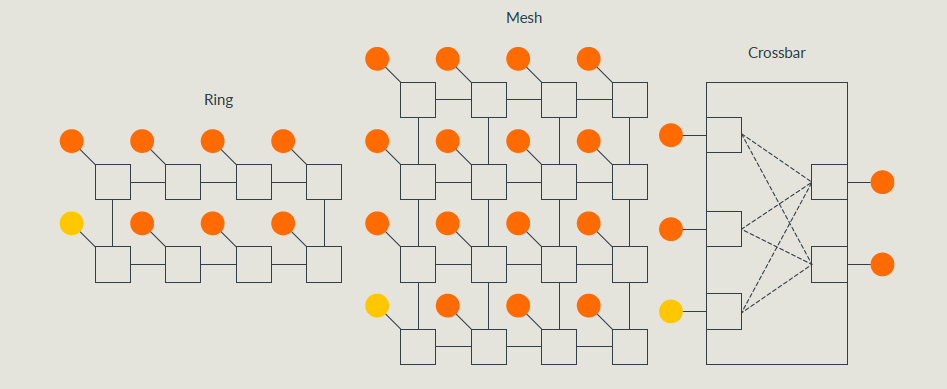
CHI总线拓扑是实现自定义的,可以是RING/MESH/CROSSBAR的类型;
- RING 一般适用于中等规模芯片
- MESH 一般适用于大规模芯片
- CROSSBAR 一般适用于小规模芯片
上面总线拓扑的选择,一般会参考访问延时和RN/SN数量
CHI cacheline状态
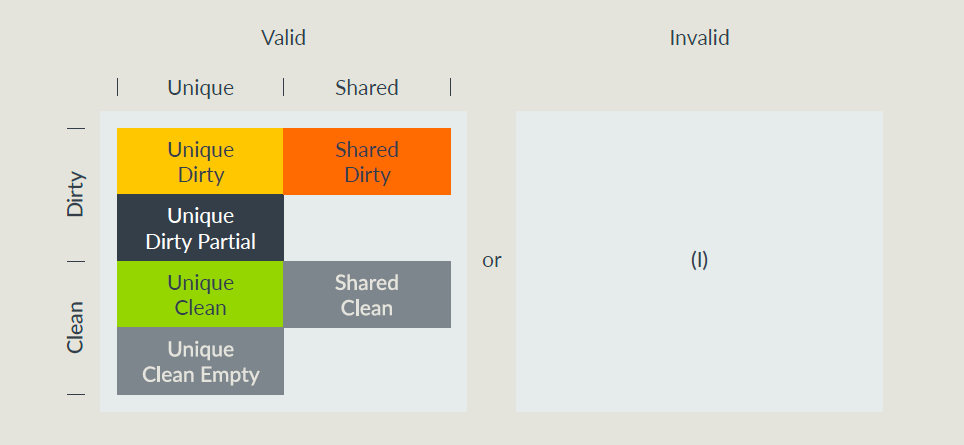
大的分类:
- Valid/Invalid来描述cacheline的状态是否有效;
- Valid的cacheline,必须是Unique或者Shared的状态;
– unique就是只有这个cache中存在,其他人(这里指RN)的cache里面都没有这个地址/数据,只有unique的状态才能被写;
– shared表示RN自己手里有这个cacheline,但是其他人(RN)手里有没有这个cacheline,不知道(可能有,也可能没有); - Valid的cacheline,必须是clean或者dirty的状态;
– clean表示这个cacheline不负责更新数据到主存,由于其他人可能刷数据到主存,所以clean的cacheline数据可能和主存不同;
– dirty指的是cahceline相对于主存已经被修改;当想把dirty的cacheline清掉时,要么把数据刷进主存,要么把dirty的责任转给其他人(RN或者HN); - cacheline可以有partial或者empty的状态:
– empty的cacheline,里面没有有效数据,但是RN有对应操作的权限/特性(比如UCE的cacheline,RN是可以直接写这个cacheline,invalid的话,还要snoop别人);
– partial状态表示有一些数据是有效的(也可能全部有效或者全部无效);有可能因为先更新状态但是数据还没来,或者是数据先变了,但是状态还没变这种状态cacheline被snoop时,CHI协议有额外的限制;
详细的cacheline状态:
Invalid(I)
cacheline是无效的(也就是这个cache没有缓存这个地址/数据)
Unique Dirty(UD)
cacheline只存在于当前cache,认为相对于主存发生了修改;RN可以直接修改cacheline的数据(因为是Unique),如果收到snoop请求,必须把cacheline的数据给出去;
Unique Dirty Partial(UDP)
和UD的区别,一个是partial的状态,另一个是被snoop的时候,不能直接把cacheline数据发给RN;
Shared Dirty(SD)
相对于主存有修改,并且有更新主存的责任;SD的cacheline也可能存在于其它人手里,但是其他人都是SC的状态;Unique cacheline才能被写,SD状态怎么来的?有可能是snoop了别人的cacheline,或者dirty的责任传递到了这里;
Unique Clean(UC)
可以不用知会别人,直接修改cacheline数据;
Unique Clean Empty(UCE)
可以不用知会别人,直接修改cacheline数据;但是如果收到snoop的时候,不能给数据到home或者其他RN;
Shared Clean(SC)
可能存在于一个或多个cache里,也可能相对于主存有修改,但是这个cacheline evict的时候不负责刷主存;
CHI节点类型
有三大类节点:RN,HN,SN,另外还有一个MN;
-
RN节点细分:
– RNF,全一致性节点,有一致性cache,并且响应snoop请求;
– RNI,IO一致性节点,没有一致性cache,不接受snoop;
– RND,支持DVM的节点,相比RNI多了一个能接受DVM事务; -
HN节点细分:
– HNF,全一致性节点,排序一致性内存的访问以及给RNF发送snoop请求;
– HNI,非一致性HN,排序对于IO子系统的请求;
– MN,处理RN发出的DVM事务,DVM事务有时也由HND来实现; -
SN节点细分:
– SNF连接到支持一致性内存空间的内存设备;
– SNI连接IO外设或者非一致性内存;


CHI的SAM
CHI总线中每一个组件都有一个Node ID,CHI使用SAM负责物理地址到Node ID的转换;
每个RN和HN都要有SAM;
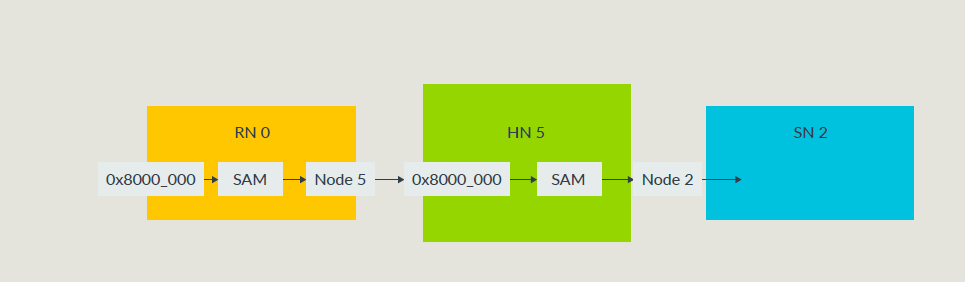
对于RN SAM的要求:
- 必须完全描述整个系统的地址空间;
- 没有组件对应的地址空间,要映射到一个能返回错误响应的节点;
- 所有RN的SAM必须是一致的,某个特定的地址只能去向特定的HN节点;
CHI通道
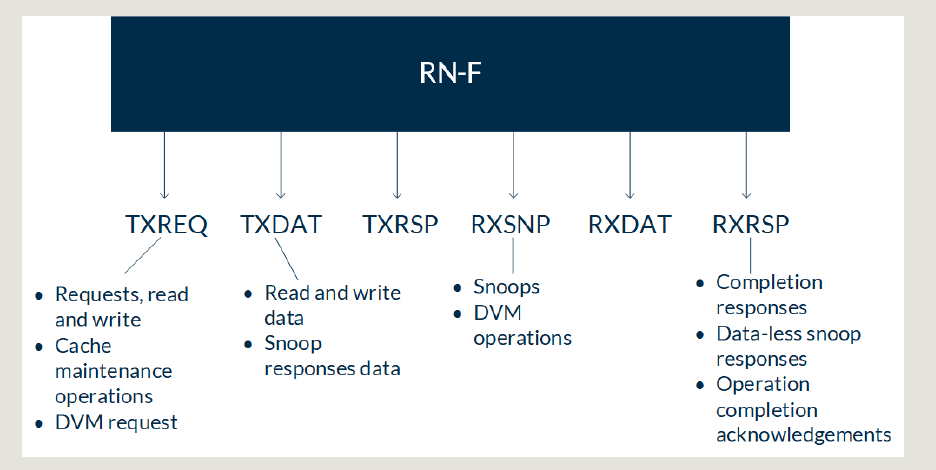
SNP通道的约束:
- 只有HNF和MN从SNP通道发起事务;
- RNF SNP通道只接收SNP事务;
- MN SNP通道只接收DVM事务;
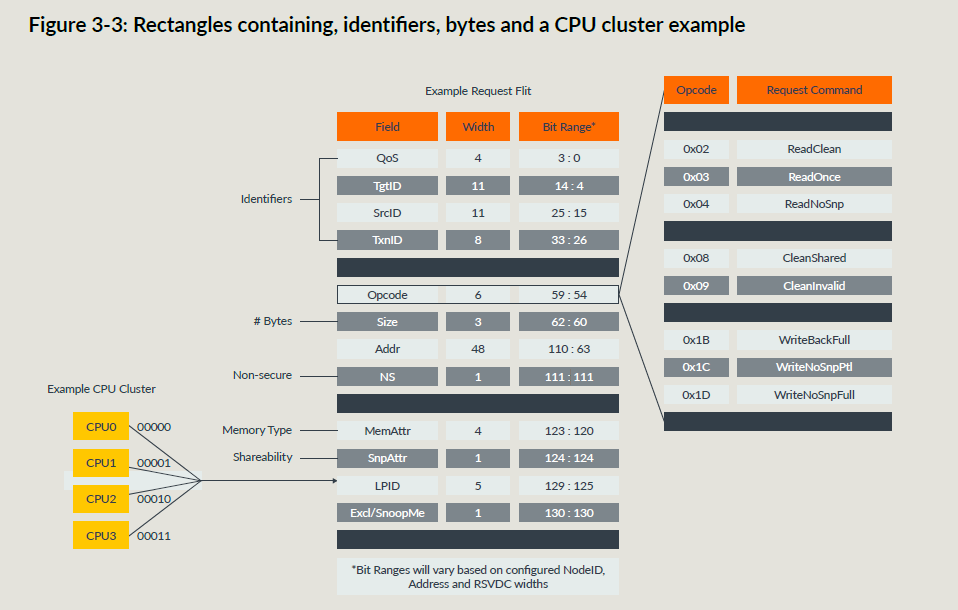
CHI FLIT
FLIT就是数据包,下面是一个REQ Flit的示例:
每个通道都有一个FLITV信号,为高时下拍FLIT有效;当发送方有接收方credit的时候才可以发送;LCRDV信号传输credit;
CHI在FLIT中定义了很多ID域段:
- SrcID:用来路由FLIT,表示发送方的ID,每一个FLIT都要有SrcID;
- TgtID:表示接收这个消息的节点ID,除了snoop的FLIT都需要TgtID(snoop发给谁是实现自定义的,snoop可以广播,也可以由SF来管理到底发给谁);
- TxnID:每个FLIT都需要,RN outstanding出去的事务必须有着唯一的TxnID,其位宽决定了RN能outstanding多少事务;
- Opcode:REQ FLIT需要,表示传输类型,并且决定了事务结构(比如区分读写事务);
- DBID:只存在于RSP或者数据FLIT,目标节点通过这个来分配写数据buffer,并且可以要求一个完成响应来释放buffer;
– 对于写,RN收到收方响应带的DBID之后才能发写数据;
– 一些需要完成响应(表示RN已经收到了读数据)的读事务,也使用读数FLIT据携带的DBID;

写事务传输流示例

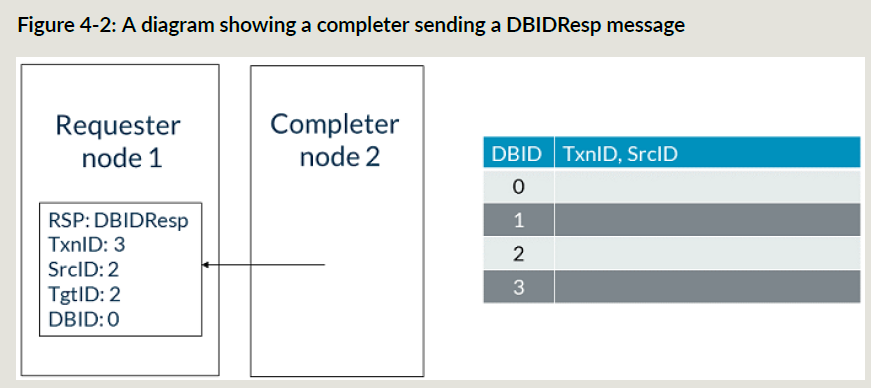
RN NodeID是1, SN NodeID是2:
- RN给SN发了个TxnID为3的写请求;
- SN为这个事务分配一个可用的数据buffer(BDID 0),关联到TxnID和SrcID;
- SN回DBIDResp给RN,TxnID为3,DBID为0;
- RN使用接收到的DBID 0和TxnID 3发给SN写数据;
- 当传输完成的时候,SN的SBID 0对应的buffer空间可以释放;
ReadNoSnp事务流示例
下面是ReadNoSnp事务;RN0发送ReadNoSnp请求,SN5提供读数据:
-
RN发送ReadNoSnp到ICN,TgtID是HN3:
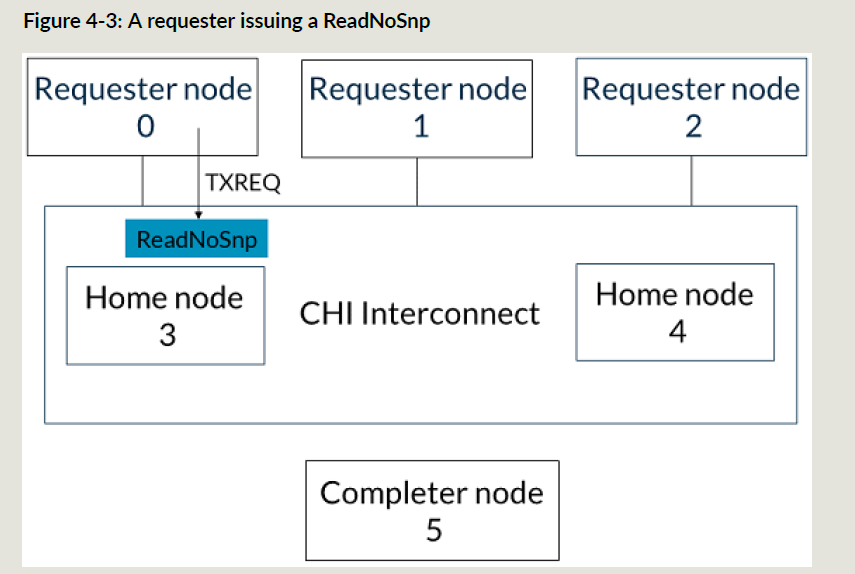
-
HN发ReadNoSnp到SN5来取回数据:
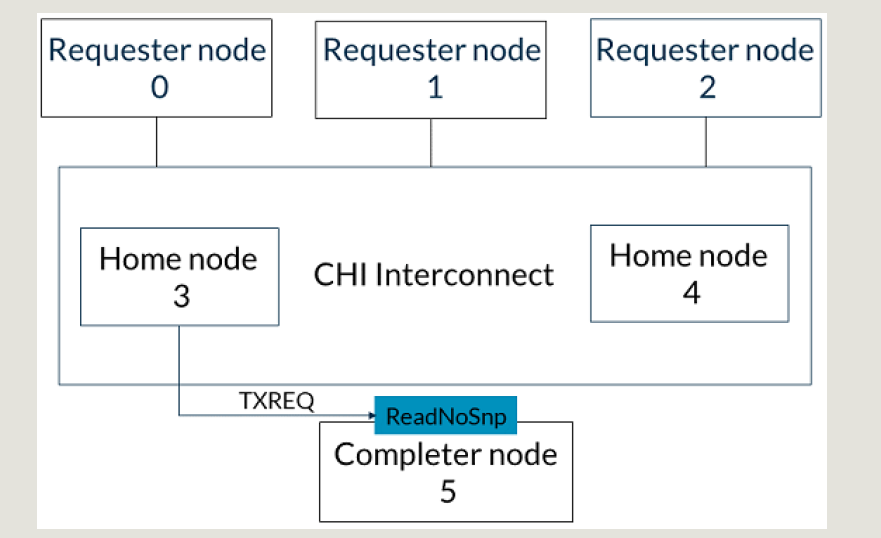
-
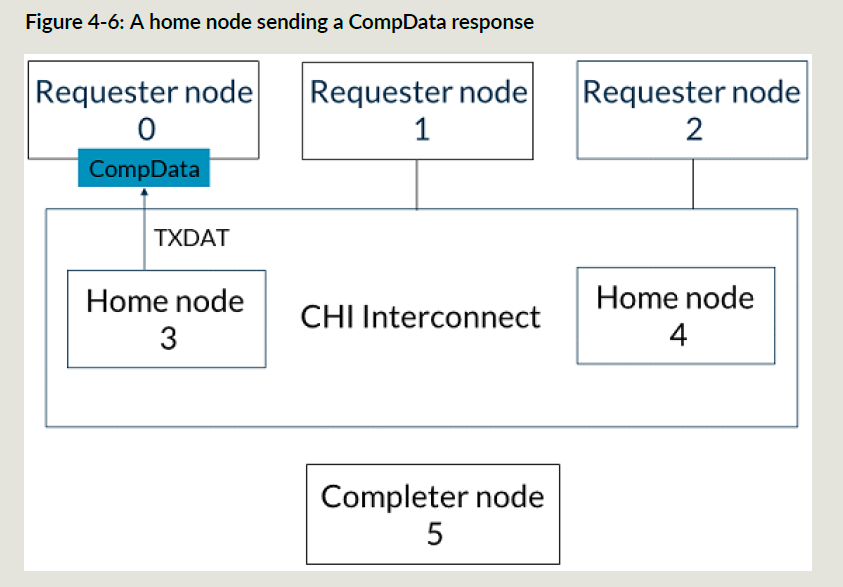
SN5使用CompData响应把数据回给HN3:
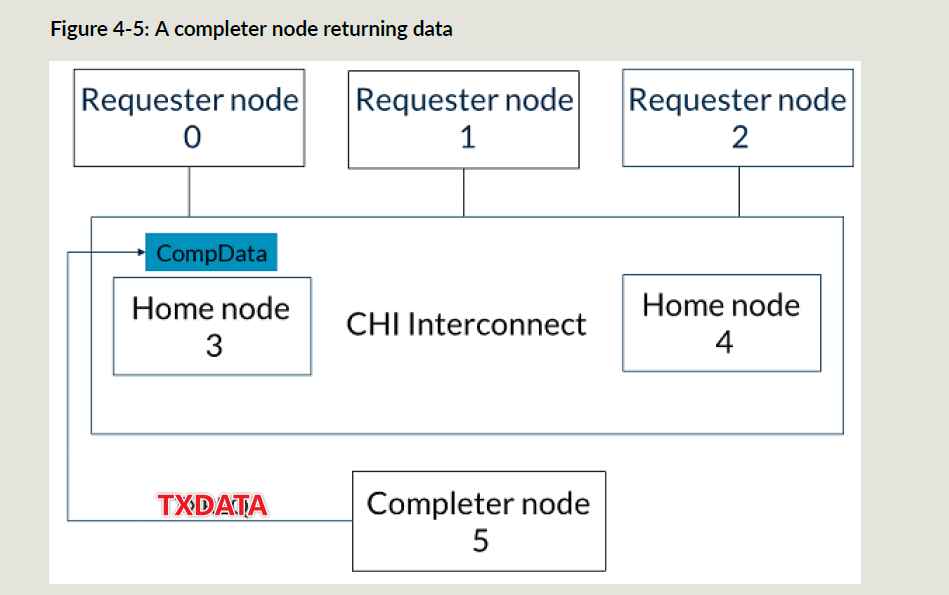
-
HN3把CompData给RN0:
WriteNoSnp事务流示例
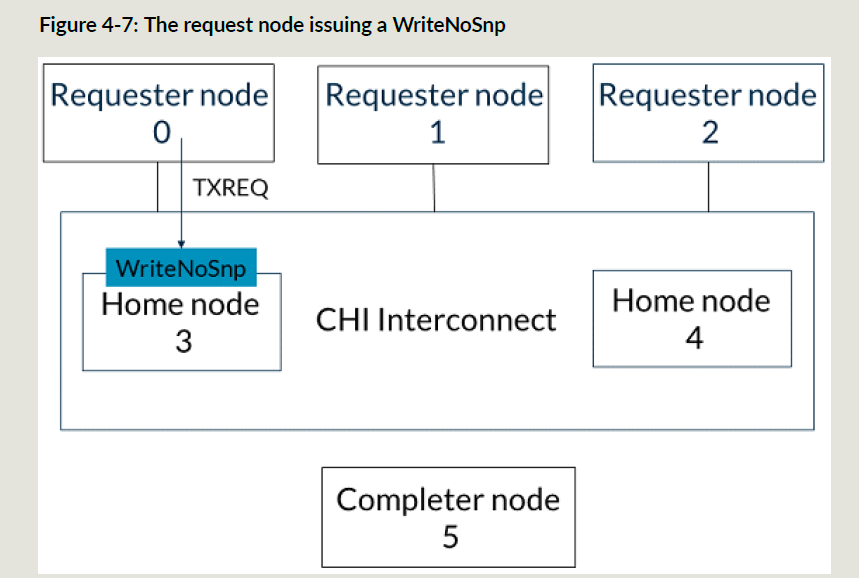
下面是WriteNoSnp事务,RN0发给SN5:
-
RN0发给HN3 WriteNoSnp事务:
-
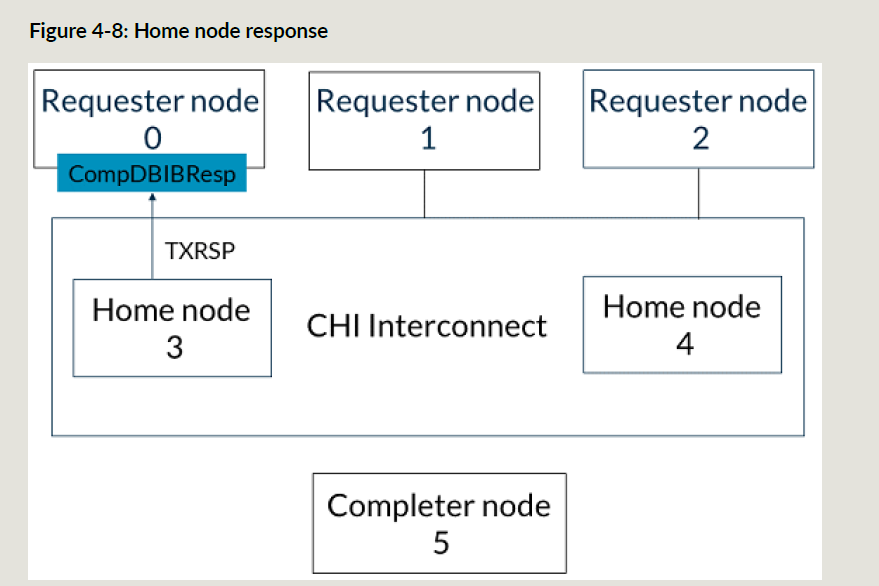
HN3返回CompDBIDResp事务给RN0,这表示HN3可以接收写数据并且其它RN均可观测到这个写事务;
-
下面两步是独立的,可乱序:
a. HN3把WriteNoSnp发到SN5,接收CompDBIDResp响应:
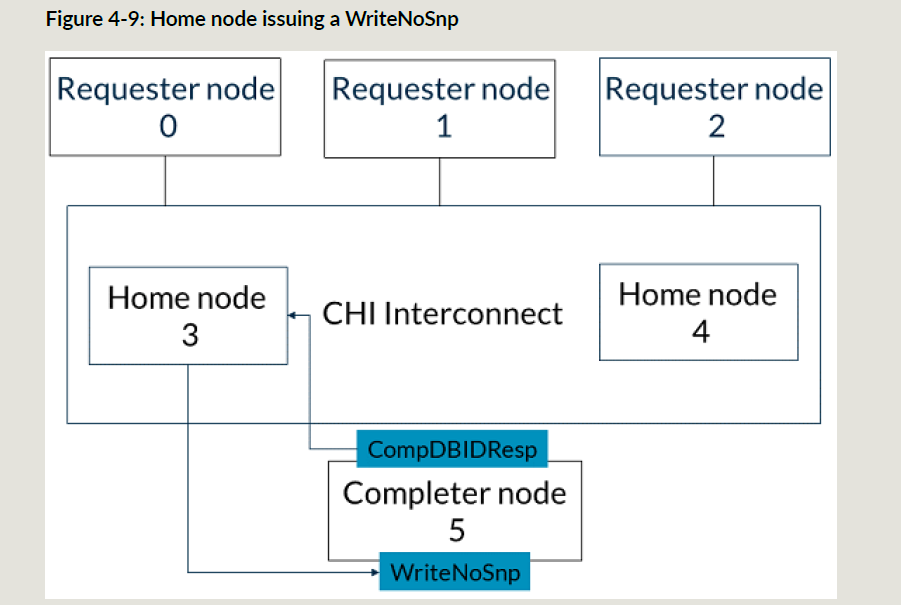
b. RN0给HN3发送写数据
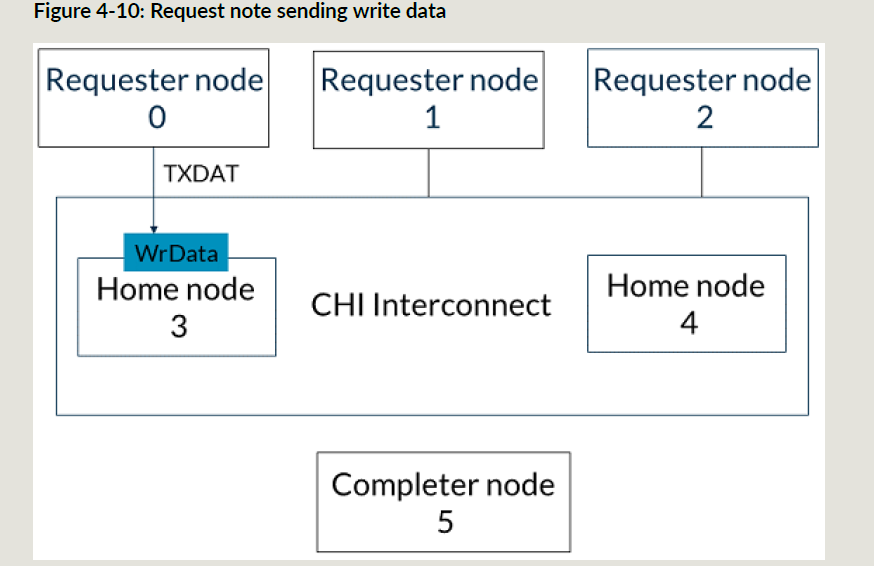
-
HN3接收到SN5的CompDBIDResp和RN0的写数据以后,HN3给SN5发送写数据:
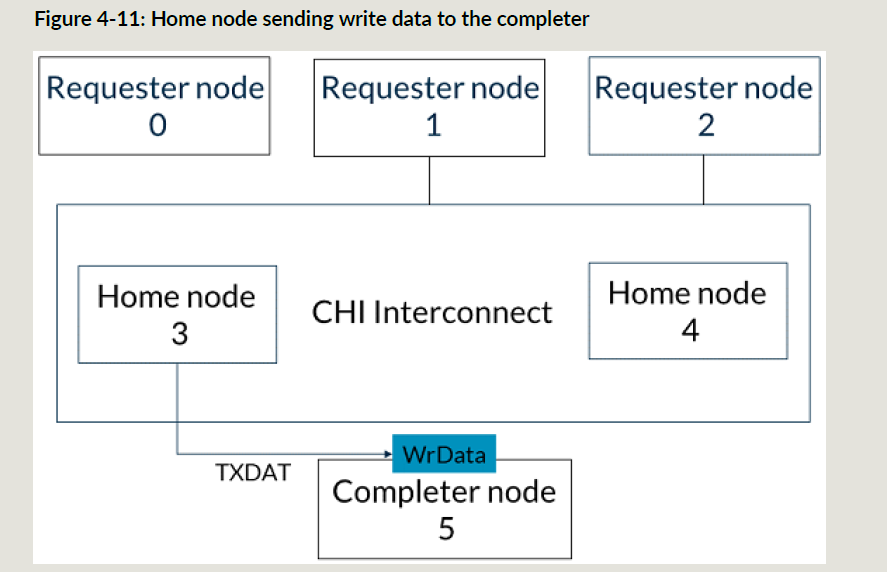
CHI的完成响应
CHI使用完成响应来维护下面事务的顺序:
- RNF发出的事务
- RNF事务导致的Snoop
完成响应确保snoop事务和他前面的RNF的一致性事务,只有一致性事务完成之后,snoop事务才能被接收;
HNF是维护cache一致性和保序的中心点,比如:一个RNF正在outstanding访问一个特定的cacheline,如果其它RN的请求导致需要snoop这个cacheline,HNF会暂停后面的这个事务;当第一个RNF的一次性操作完了之后,它会给HNF发送完成响应;这样HNF就可以让后面的snoop继续往下走;
不是所有事务都需要完成响应,请求FLIT中包含ExpCompAck来标识是否需要完成响应;
下面是发送需要完成响应的读事务:

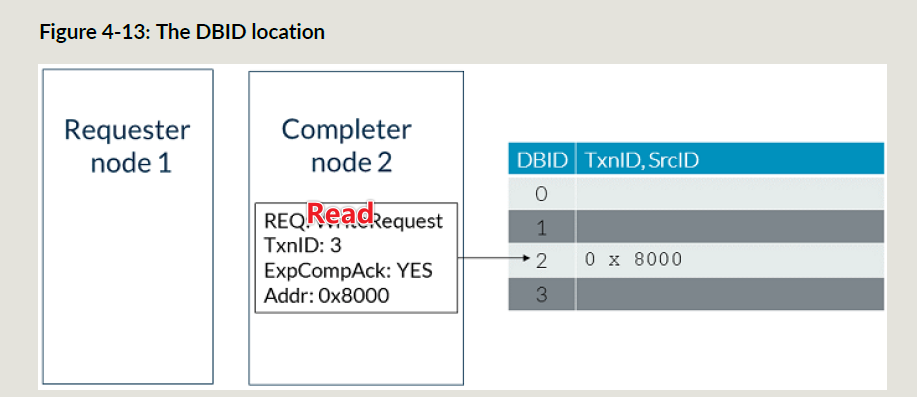
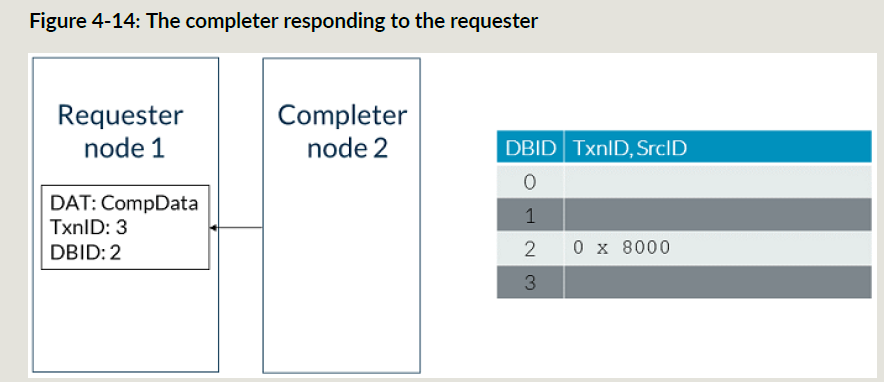

snoop事务的CompAck
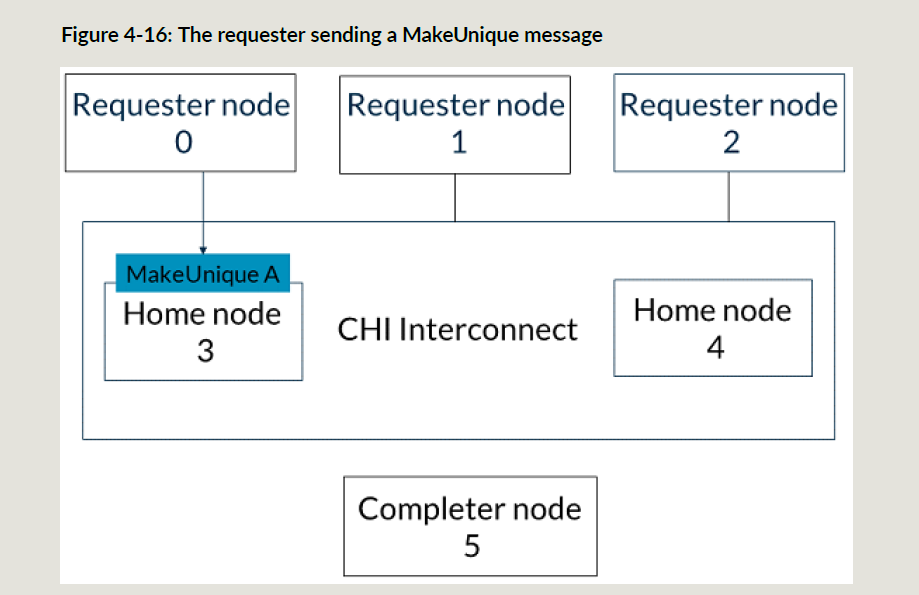
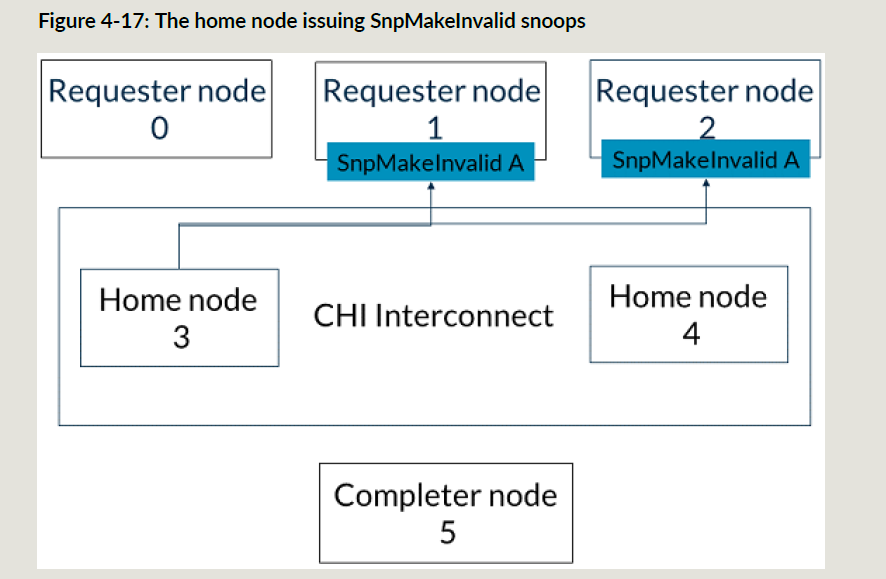
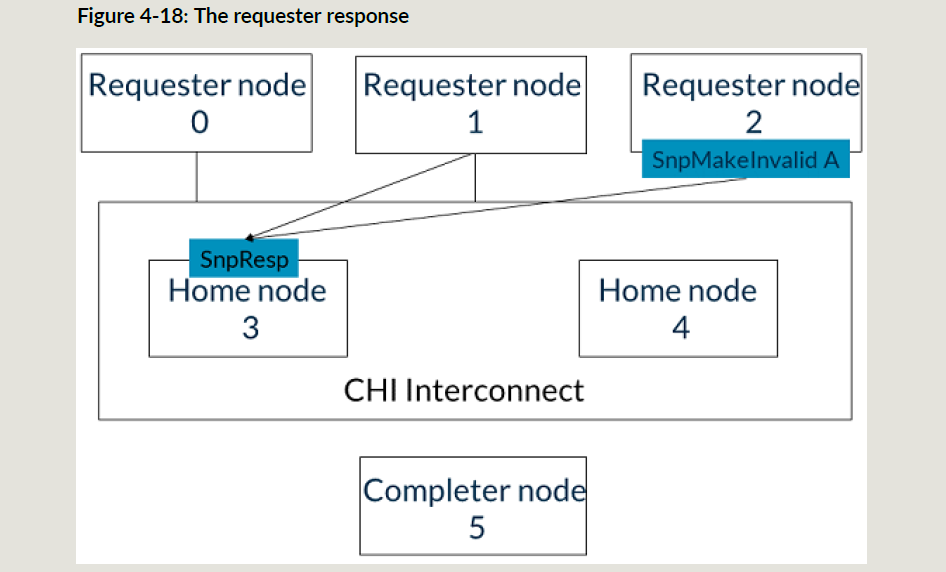
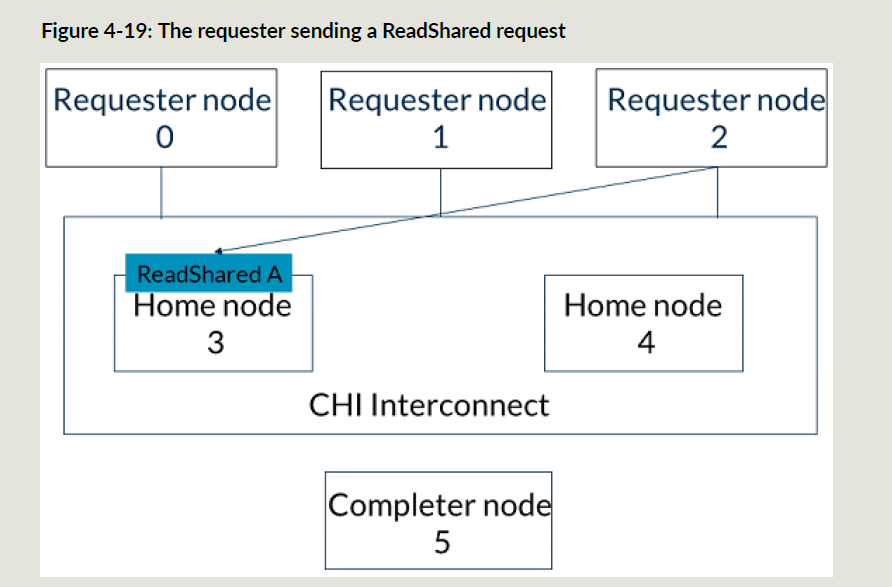
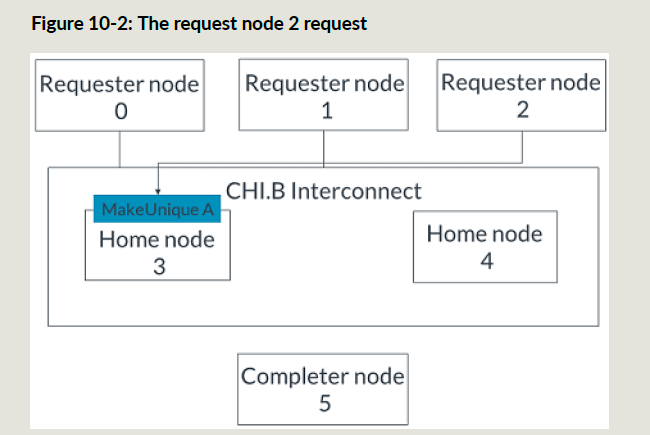
下面RN2要发一个地址A的ReadShared事务,这个时候HN3还没有完成RN0的MakeUnique事务,所以ReadShared事务的snoop操作都被阻塞住;
HN3完成第一个事务的snoop操作之后,给RN0发送Comp_UC消息;RN0给HN3发送CompAck消息;
此时HN3可以执行RN2的事务所产生的snoop操作;
端点顺序和请求顺序
-
Endpoint Order:
- 定义: 维持从单个RN到单一SN的事务顺序。
- 例子: 多个设备访问一个可编程的寄存器区间,是Endpoint Order。
-
Request Order:
- 定义: 维持从单个RN到相同地址的事务顺序。
- 例子: 一个SN对于有交叠的non_cacheable空间(Normal NC, Device-GRE 和Device-nGRE)的多笔操作需要保序;Request Order需要保序的地址空间粒度,是实现自己定义的;
如果设置了Endpoint Order,也就意味着Request Order;
只有一部分事务可以使用Request Order和Endpoint Order:
- ReadNoSnp和所有的ReadOnce事务
– RN发起ReadNoSnp或者ReadOnce类型事务需要保序;
– SN接收上述REQ,并回ReadReceipt消息,ReadReceipt表示可以发下一个需要保序的事务;
– 发送ReadReceipt之后,SN需要保证执行保序(按照接收的事务顺序); - WriteNoSnp和WriteUnique类型事务:
– RN发起WriteNoSnp或者WriteUnique类型的事务要求保序;
– SN响应DBIDResp表示他可以接收这个消息,他的databuffer可以接收写数据,并且RN可以发送下一个保序的REQ;
– 发完DBIDResp,SN需要保证执行保序;
保序举例如下:
- RN给SN发起读请求1,ReqOrder为1;
- RN给SN发读请求2,ReqOrder为1,但是发不出去,因为前面这个读还没完成;
- SN回ReadReceipt给RN,表明第一个读已经接收了;
- 下面两个可以乱序:
a. RN发读请求2给SN;
b. SN回给RN读请求1的数据;
请求retry
有时候目标节点没有资源来接收请求,为了不阻塞ICN,CHI提供了retry机制,SN需要依照请求来决定和记录其对应的Pcrd;
可以使用不同类型的Pcrd来记录不同的资源,比如读写使用分离的databuffer,那么每个buffer都可以使用不同的credit来标识;不同的Pcrd值是实现自定义的;
详细流程不介绍了,看协议的2.3.8章节;
DVM事务
CHI使用DVM事务来维护虚拟内存;
DVM操作有如下事务:
- TLB清除;
- 指令cache清除
- 分支预测清除
- DVM同步
CHI中,所有的DVM事务分两部分给MN,下面是顺序要求:
- 第一部分是给MN发DVMOp请求,请求FLIT使用地址域段来编码操作选项;
- 第二部分是当RN接收到MN的DBIDResp之后,通过data FLIT发送DVM消息;这一步携带了DVM事务目标地址;
当MN收齐了两步DVM事务,MN给相关一致性domain的RN发起SVM snoop请求,也是分两步,两步必须使用相同的TxnID和opcode SnpDVMOp:
- 第一部分使用地址域段编码操作属性和目标地址高位;
- 第二部分使用地址域段发送剩余的地址;
上面两部分是通过Address的bit[3]来标识;0表示第一步,1表示第二步;这两步可以乱序;
DVM操作类型
CHI定义了两类DVM事务:DVM Non-Sync和DVM Sync;这决定了RN是否先等当前操作完成再响应DVM snoop;
同步DVM只做同步动作;
非同步DVM非同步DVM就是 TLB/指令cache/分支预测 无效的操作;非同步DVM事务可以outstanding;
下面一个outstanding的例子:
- RNF/RND接收一个DVM Non-Sync的snoop操作;
- RNF/RND给MN发snoop响应,这只表明他接收了DVM事务,但不表示DVM事务的执行;
- MN给最初发DVM事务的RNF/RNI完成响应,表示别人已经收到DVM事务;
为了确保所有outstanding的DVM已经执行,看下面的例子:
- RNF发起同步DVM事务给MN,需要DVM Sync同步的outstanding的DVM事务,需要先回完成响应,才能发起DVM Sync;
- MN给所有的RNF和RND发起 DVM Sync的snoop;
- 每个RN需要确保前面收到的outstanding的DVM事务都已经执行;
- 所有RN给MN回snoop响应,表示所有的DVM操作已经执行完成;
- MN在给发DVM Sync的RN发起完成响应;
ARM核的DSB指令会产生DVM Sync操作,但是实现如果确认没有需要同步的DVM操作时,可以不用发DVM Sync;
DVM操作流
下面是一个TLB无效的DVM事务 + DVM Sync;
- RN0给Mn发TLB无效的DVM事务;
- MN响应DBIDResp,表示他可以接收DVM事务的第二步;
- RN0给MN发起写数据消息,作为DVM事务的第二步;
- MN给RN1发起两步DVM事务;
- RN1通过给MN发送snoop响应表示已经接收DVM请求;
- MN接收snoop响应;
- MN给RN0发完成响应;
- RN0给MN发起DVM Sync;
- MN给RN0回DBIDResp;
- RN0给MN发写数据消息, 作为DVM事务的第二步;
- MN给RN1发DVM Sync snoop;
- RN1执行完所有outstanding的DVM操作;
- RN1给MN发snoop响应,表示已经执行完所有操作;
- MN给RN0发完成响应,作为DVN Sync的响应;
Cache stashing
cache stash是把数据放在系统特定cache中的机制,通过把数据放在临近将来要用的位置,减少访问延时来提升系统的性能;
一般情况下,RNI和RND会发stash操作,stash请求只是一个建议,并不是强制的要求;一个设备收到stash类型的操作,也可以忽略掉;
CHI有两种cache stash事务:带数据的和不带数据的;
stash传输流
基础的传输示例:
- RN通过REQ通道发起stash请求;
- stash请求发给HNF;
- HNF可以有如下方式:
- 忽略stash事务,把它当成非stash的操作;
- 支持stash,给RNF发snoopRNF把cacheline预取至自己cache中;
- stash目标RNF收到一个Stashing Snoop;
RNF可以有如下方式:
- 回Snoop响应,就像收到使用datapull机制的cacheline读一样;
- 不使用datapull回snoop响应,然后发起那个cacheline的读;
- 回snoop响应,不预取这个cacheline,忽略掉stash的提示;
stash snoop请求
所有的cache stash请求发给HNF节点,HNF处理cache stash请求,他会给RNF发stashing snoop;
CHI有四种类型的cache stash事务:

cache stash控制域段
stash事务REQ,snoop,response,data FLIT均有下面域段:
- stash目的节点NodeID
- RNF中的逻辑处理器cache,比如L2$
- 是否会使用datapull机制
stash事务REQ FLIT使用下面域段:
- StashNID
- StashNIDValid,标识是否有用StashNID
- StashLPID
- StashLPIDValid,标识StashLPID是否有使用;
snoop FLIT有如下域段:
- StashLPID和StashLPIDValid
- DoNotDataPull
写数据的传输
RN发起WriteUniqueStash来写一个新数据并且希望Target来stash这个数据;写的cacheline可以是full或者partial;
下面是一个RNI发起stash操作的例子,目标节点是RNF:
- RNI发起WriteUniqueFullStash,为了简化流程,例子不给RNF的DBIDResp
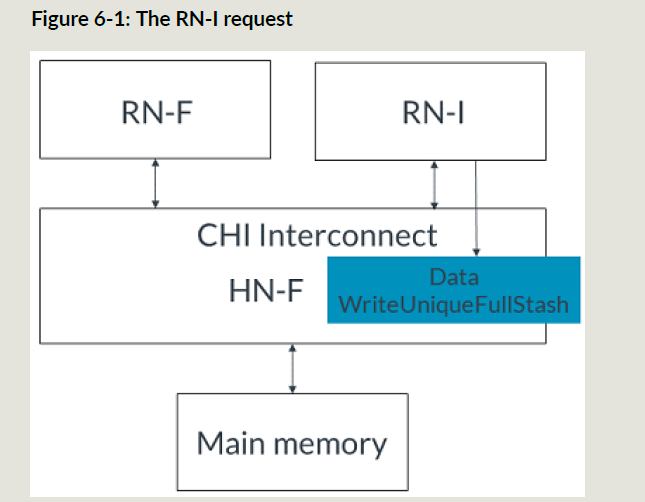
- HNF收到stash事务后发送SnpMakeInvalidStash给HNF
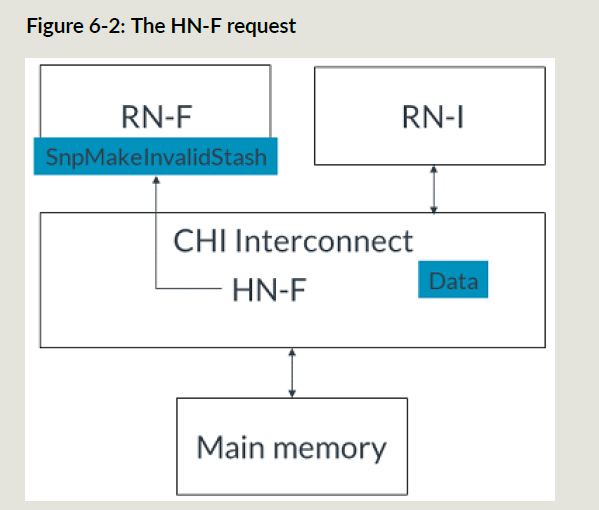
- RNF接收HNF的snoop
- RNF接收stash并且返回snoop resp
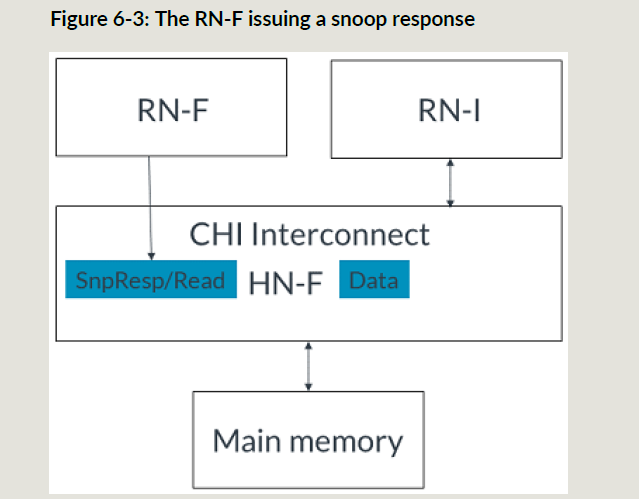
5. 如果使用datapull,RNF要么发起一个带implicit读请求的snoop响应,或者一个snoop响应和一个单独的读请求,这里是一个implicit snoop响应和读请求,不是完整的datapull流程;
6. HNF发送从RNI收到的写数据给RNF;
无写数据的传输
- RNI发起StashOnceUnique请求到HNF;
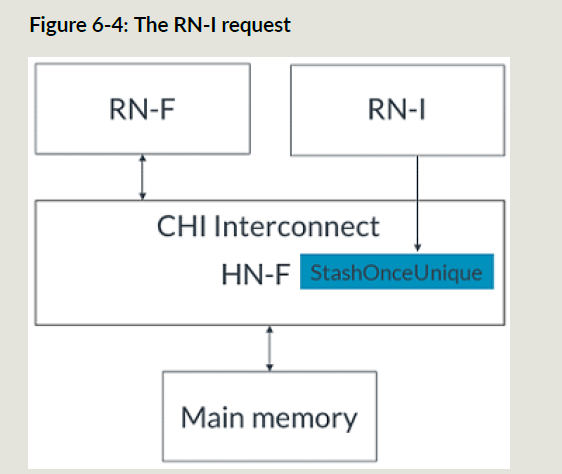
- HNF接收stash请求;
- HNF给主存发ReadNoSnp来获取cacheline,同时发起SnpStashUnique给RNF;
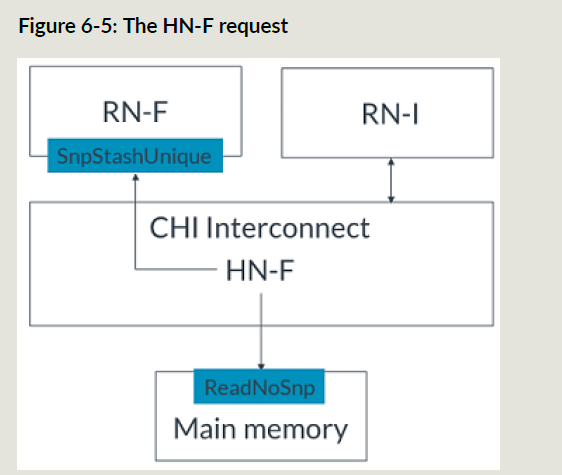
- 主存把cacheline数据给到HNF;
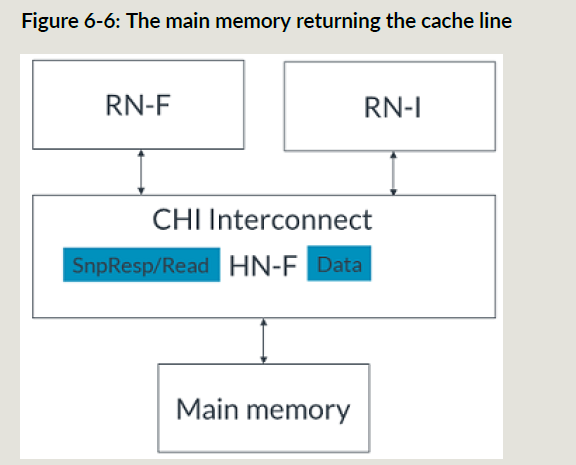
- RNF响应snoop,请求cacheline;
- HNF把cacheline数据给到RNF;
如果stash没有对应的Target,那么HNF就是stash target;如果HNF要做stash,就发起ReadNoSnp到主存,拿到数据之后存到自己的cache里;
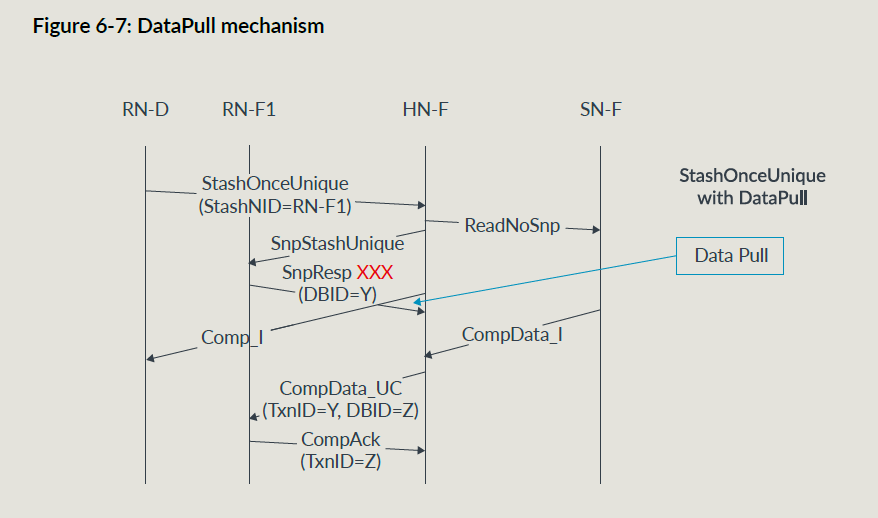
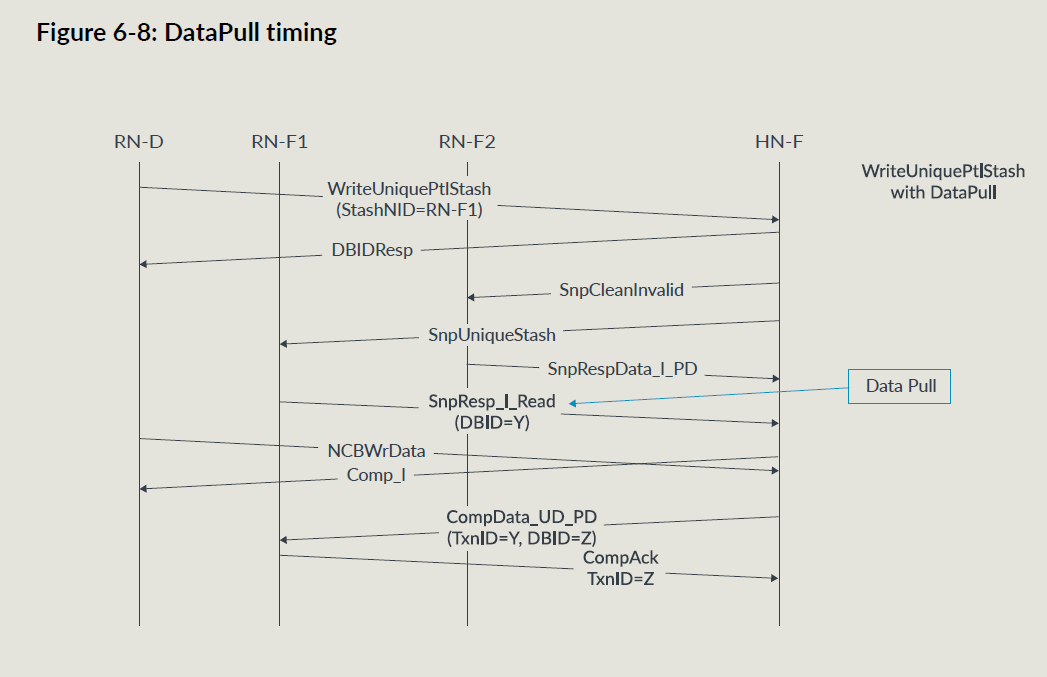
datapull机制
datapull机制是可以在snoop响应中带一个读请求,这样可以少发一个读请求;只在stash snoop中可以用;
RNF收到要求datapull的snoop,可以使用datapull或者单独发一个读请求;
I/O Deallocation
CHI提供了IO请求者释放全一致性节点cacheline的提示操作;I/O Deallocation操作可以提示一个cacheline应当invalid掉,脏数据可以踢下去或者直接丢掉;因为是提示性操作,一致性节点也可以只回数据而不无效掉cacheline;注意提示性操作不能替代CMO;
CHI有两种I/O deallocation事务:ReadOnceCleanInvalid和ReadOnceMakeInvalid;这俩对于防止cache被不在用的数据污染很有效(防止命中率下降),MakeInvalid和CleanInvalid的区别是,MakeInvalid是不踢入主存,直接把数据丢掉,所以使用时要小心一些;
I/O Deallocation示例
ReadOnceCleanInvalid的例子:
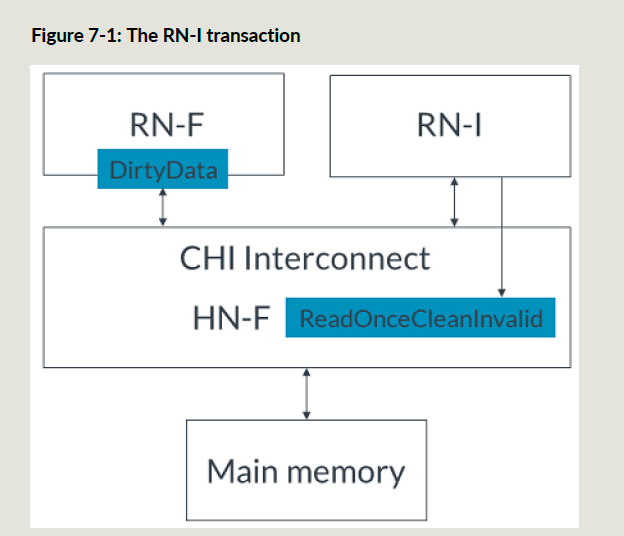
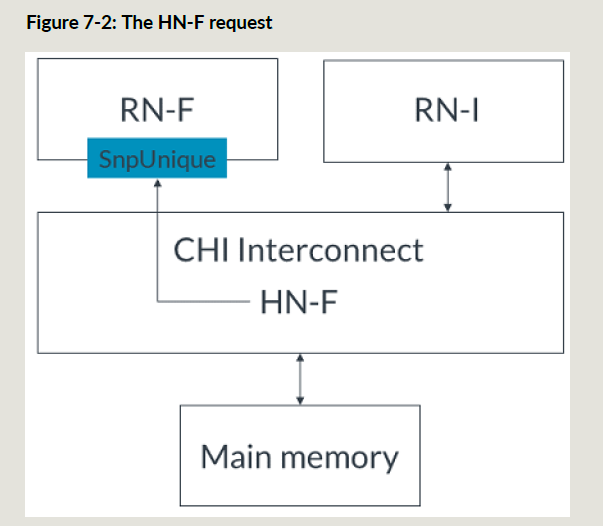
然后RNF无效掉自己的脏cacheline并刷到HNF中,HNF把数据给到RNI,并写入主存;
DMT,DCT和PrefetchTgt
DMT和DCT可以让数据直接在RN和SN之间传输,省的中间经过HN的转发拖慢性能;但是传输完成的时候,HN仍然需要收到CompAck来确认传输已经完成;
PrefetchTgt事务可以减少内存访问的延时,PrefetchTgt可以直接由RNF送到SNF,不需要返回数据,MC可以把这个作为一提示,提前把数据放到读buffer中;这样后面普通的读下来的时候,数据可以很快回去;
DMT
对于读事务的DMT传输,见下图:
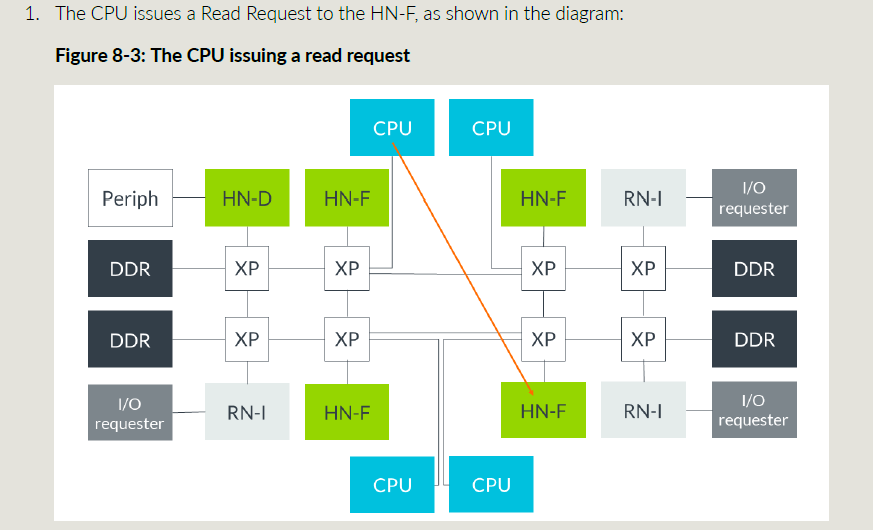
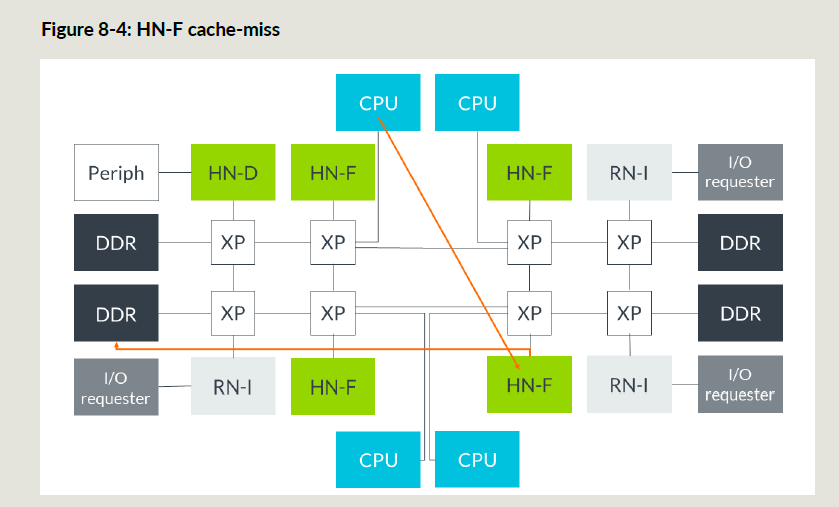
MC取回数据后直接把数据给到CPU;
使用DMT之后ICN的效率高了很多,绝大多数的读操作都可以使用DMT,cache stash导致的DataPull也可以使用DMT;
不能使用DMT的请求:
- EX操作;
- ReadNoSnp并且ExpCompAck = 0并且Order != 0
- ReadOnce并且ExpCompAck = 0并且Order != 0
为了支持DMT,CHI包含了如下ID域段:
- REQ FLIT使用ReturnNID和ReturnTxnID
- DATA FLIT使用HomeNID
DMT传输流示例:
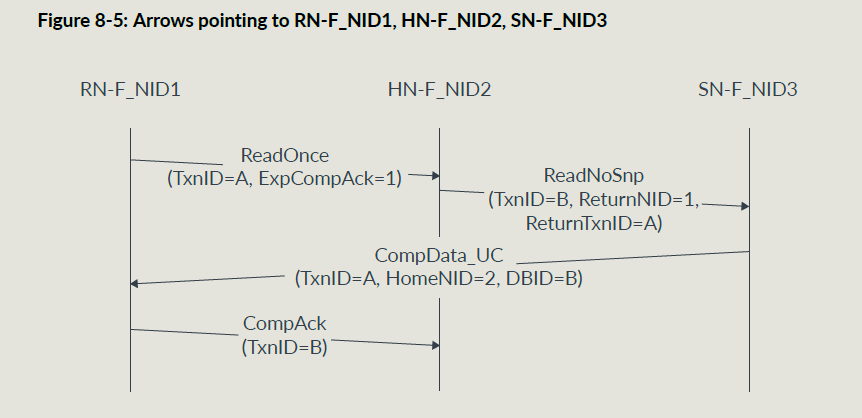
有order要求的DMT传输示例:
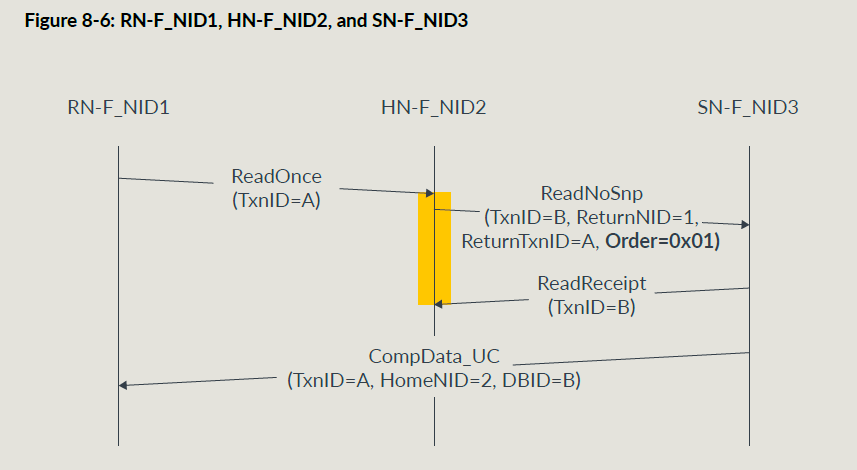
当HNF收到Read Receipt之后就可以把自己的资源释放了;
Prefetch Target
PrefetchTgt可以提升DMT的效率,其由RN直接发给SNF,不需要响应,不需要TxnID,不计入outstanding,SNF也可以选择忽略掉这个事务;
如果SNF决定预取数据,它会一直buffer住数据,直到发生了对这个地址的读操作;一般情况下认为很快就有一个读事务走常规路径(RN->HN->SN)过来;
DATA FLIT的DataSource域段,可以用来指示RNPrefetchTgt事务是否有用:
— 0bR0110 PrefetchTgt 对于本次传输有用.
提前预取数据对于数据传输而言延时降低;
— 0bR0111 PrefetchTgt 本次传输没有用
和普通的读而言,本次数据预取没有改善延时;
RN可以根据上面的反馈来调整是否发送PrefetchTgt;
流程比较好理解,这里就不详细描述了;对于RN而言,就是在知道会miss的情况下先发PrefetchTgt再发读事务;
DCT
为了减少snoop hit的延时,引入DCT;和DMT类似,DCT是用于snoop数据传输的;
对于信号量和生产者-消费者这种类型的工作负载(常见的并发控制和同步机制。这些用例从数据一致性技术中受益,因为它们通常涉及多个进程或线程共享和修改共同资源),DCT可以带来性能提升。
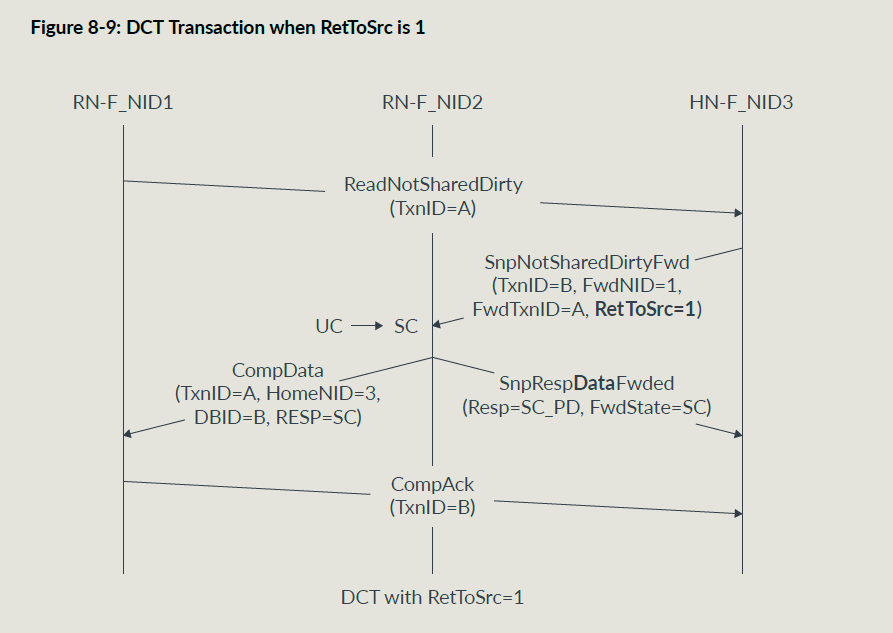
Forward Snoop Requests
Forward Snoop 请求告诉被snoop的RNF把snoop数据直接给到原始的RN,除了原子事务和EX事务,均可使用DCT;
Forward Snoop需要下面域段:
- FwdNID
- FwdTxnID
- RetToSrc 为1要求snoopee把cacheline给到HN节点,防止后面访问这个地址又要snoop;
DATA FLIT和RESP FLIT需要一个FwdState域段,这个域段告诉HNF DCT数据的cache状态以供SF维护一致性; 同时cache状态通常会在RESP域段中给到原始RNF;
和普通的读一样,原始RN通过CompData消息来接受snoop数据;
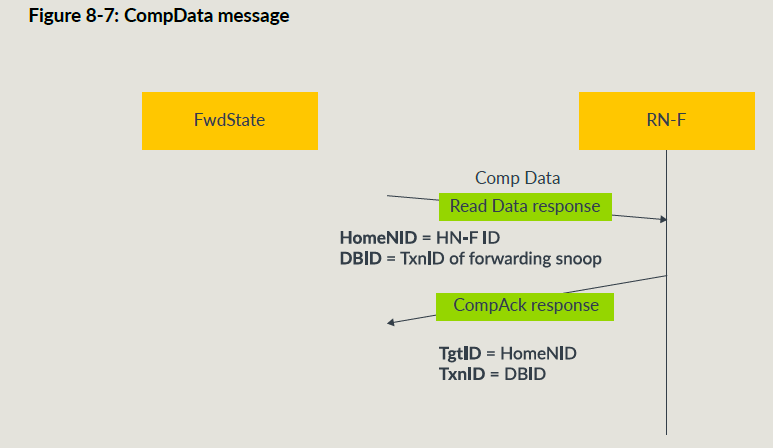
RetToSrc = 0的传输流图:
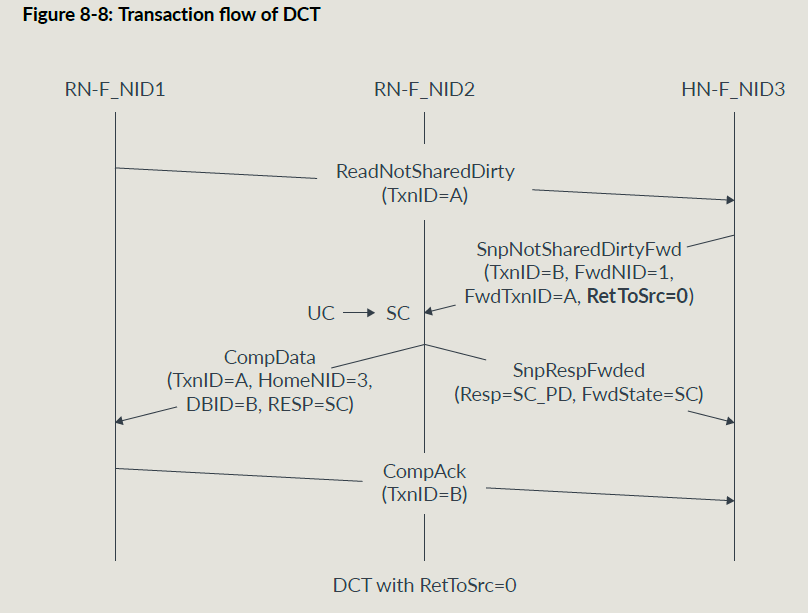
RetToSrc = 1的传输流图:
原子操作
使用原子操作,相比EX操作可以节省大量时间;原子事务可以一次执行多个原子性的操作不被打断;
原子操作类型有四个:
- AtomicStore
- AtomicLoad
- AtomicSwap
- AtomicCompare
对于AtomicStore ,支持如下细分操作:
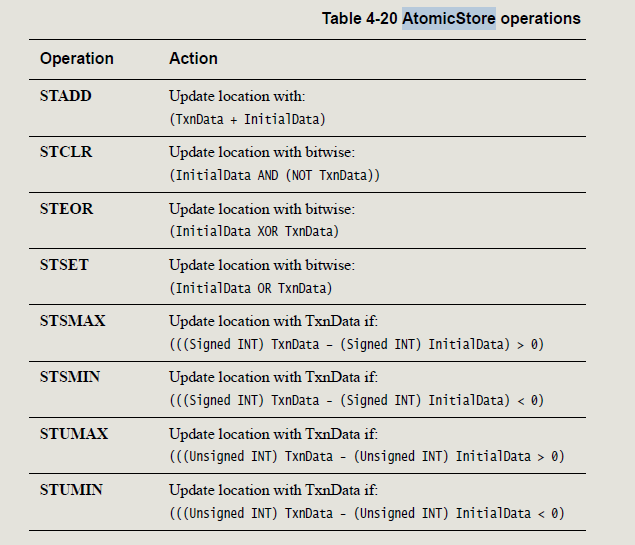
对于AtomicLoad,支持如下细分操作:

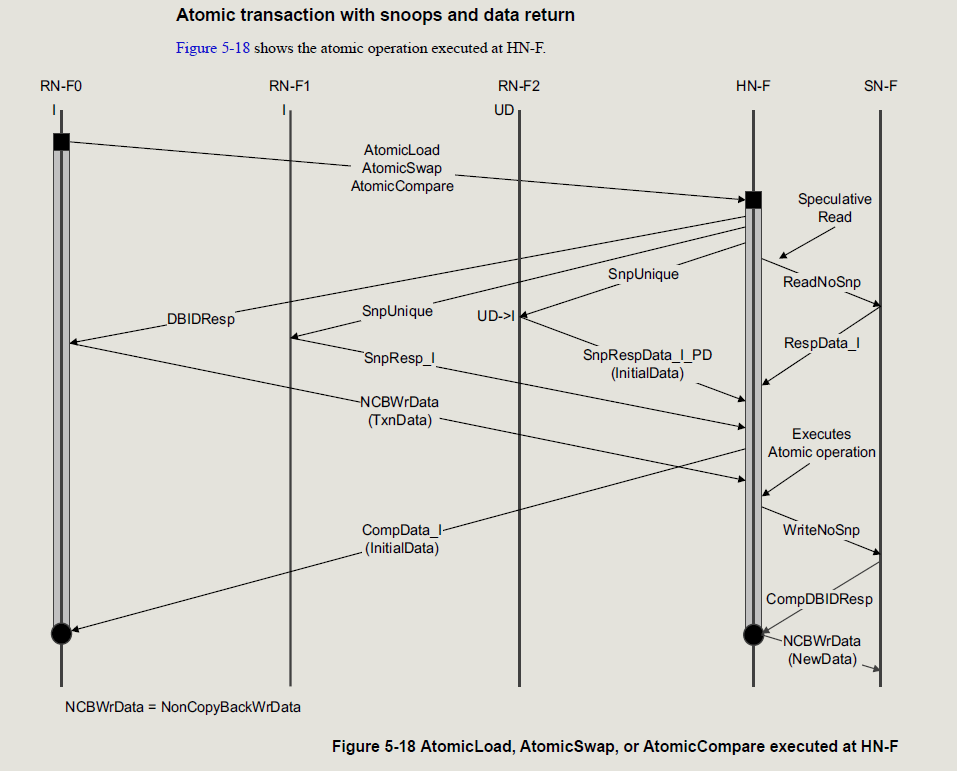
对于AtomicSwap,target把原始数据和事务携带数据相交换,再返回原始数据;
对于AtomicCompare,事务会携带两个值,比较值和交换值,target拿比较值和原始数据进行比较,如果数据相等,target把swap值写进去,如果不相等,target不会写目标地址;返回数据为目标地址的原始数据;
下面是一个有数据返回的原子操作传输流,其他场景见协议5.4章节;
RAS特性
CHI支持下面RAS特性:
- 数据poison和datacheck来标识失效数据
- Trace Tag来帮助分析和调试
poison和datacheck
一般ECC算法都是纠一检二,超过1bit错误哦叫做不可久错误(UR或者UCE,注意根据上下文和cache状态相区别),把数据标记为有毒的,poison标识会和数据一起传递直到数据被消费,这允许即使数据错了也可以让系统使用;
poison的粒度可以是64或者128bit;
数据被消费的含义:
- 数据被用来做计算了;
- 数据被给到了不支持poison的地方;这种情况需要进入异常;
datacheck提供data域段的奇偶校验,8bit粒度对应1bit的datacheck校验位;
TraceTag
CHI每个通道都有1bit的TraceTag,TraceTag为1表示这个FLIT被标记来做trace,所有后面的FLIT也要打上trace标记,RN事务导致后面新产生的事务;比如导致HNF产生额外的命令;
TraceTag可以在初始RN节点置1,也可以在ICN的中间节点置1;比如中间的观测节点可以把TraceTag置1;也可以中间的观测节点被设置为所有路过去往地址A的事务都把TraceTag置1;
传输流示例:
- RN0发送地址A的MakeUnique请求到HN3:
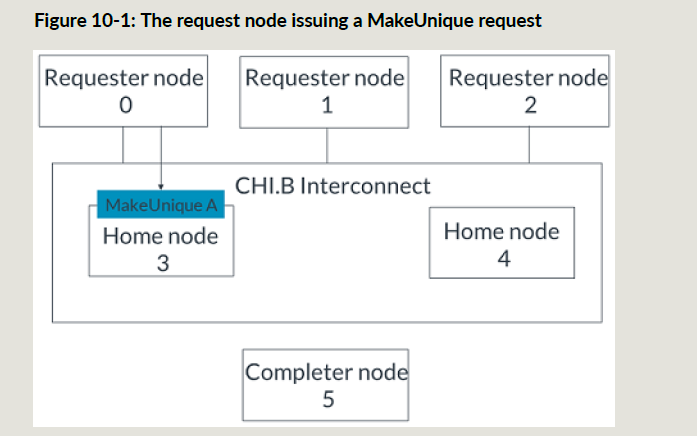
- ICN把snoop和snoop的响应的TraceTag都置1;
- RN2发送ReadShared事务给HN3,ReadShared事务产生的snoop的TraceTag为0;
4. HNF给RN0发送完成响应,TraceTag为1;