拓展:贾扬清:深度学习框架caffe(Convolutional Architecture for Fast Feature Embedding)
主要贡献:
深度可分离卷积(Depthwise separable convolution)+逐点卷积(Pointwise convolution):保证各类视觉任务准确度不变的条件下,将计算量、参数量压缩30倍。引入网络宽度和输入图像分辨率超参数,进一步控制网络尺寸。
拓展:空间可分离卷积(效果远远不足深度可分离卷积)
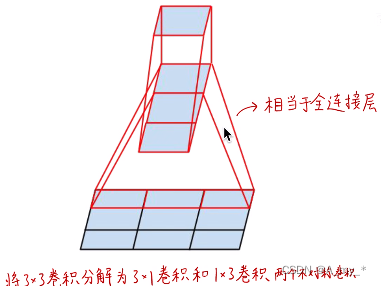
传统卷积:一个卷积核生成一个feature map(卷积核的通道数和输入的通道数应相同,各通道卷积后再对应相加,生成一个feature map),Dout个卷积核生成Dout个feature map,即输出的通道数为Dout。要使输出与输入通道数相同,则卷积核个数应与输入通道数相同,即下一步卷积核的个数应为Dout,其中一个卷积核的通道数也应为Dout。
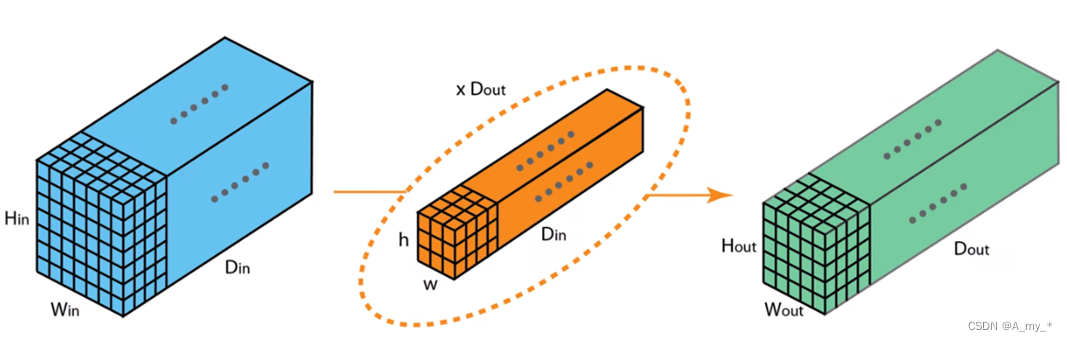
深度可分离卷积+逐点卷积:之前是一个卷积核负责三个通道,现在是每个卷积核只负责一个通道。Depthwise只处理长宽方向的空间信息,Pointwise只处理跨通道的信息融合
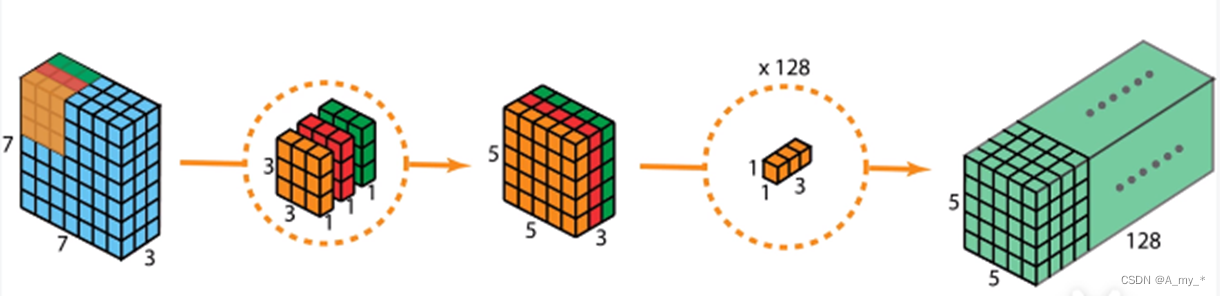
拓展:Xception中先Pointwise再Depthwise(区别不大)
计算量、参数量分析:


![]()

还引入两个控制网络大小的超参数:a,网络宽度超参数,控制卷积核的个数;p,输入图像分辨率超参数,控制输入图像的尺寸,进而控制中间层feature map的大小。那么所有的M、N乘a,所有乘p,计算量、参数量变得更小
![]()
计算性能分析:
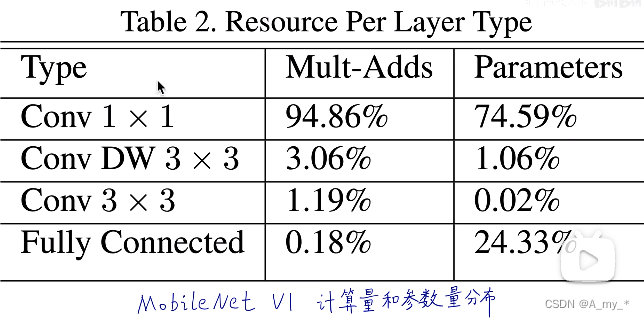
乘法加法计算量,参数量都集中在1*1卷积,计算核心在于加速1*1卷积(跨层通信,引入额外非线性,利用卷积核的个数进行降维或者升维)
拓展:实现标准卷积代码,长宽移动需要两个循环,对应元素相乘需要一个循环,循环非常耗时;改进:将卷积运算变为矩阵乘法运算(im2col)。而1*1卷积本来就是一个向量,很容易加速
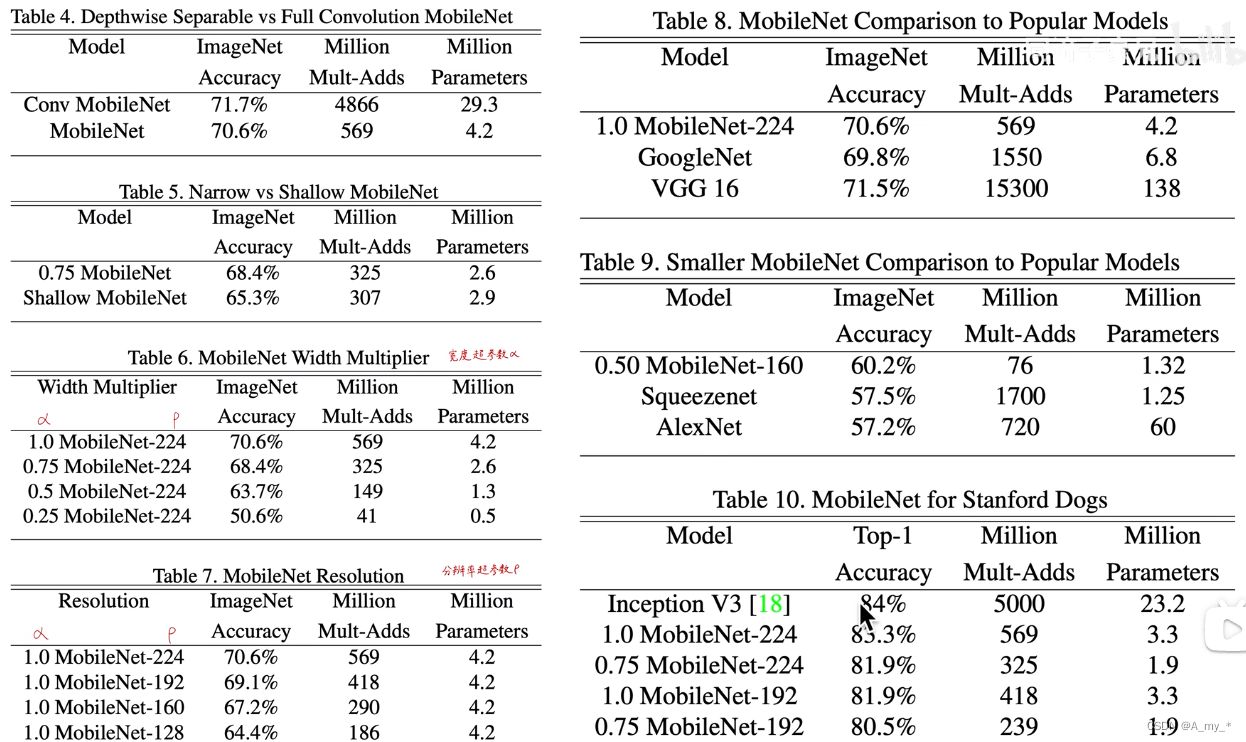
由上表可见,计算性能大大提升
参考1