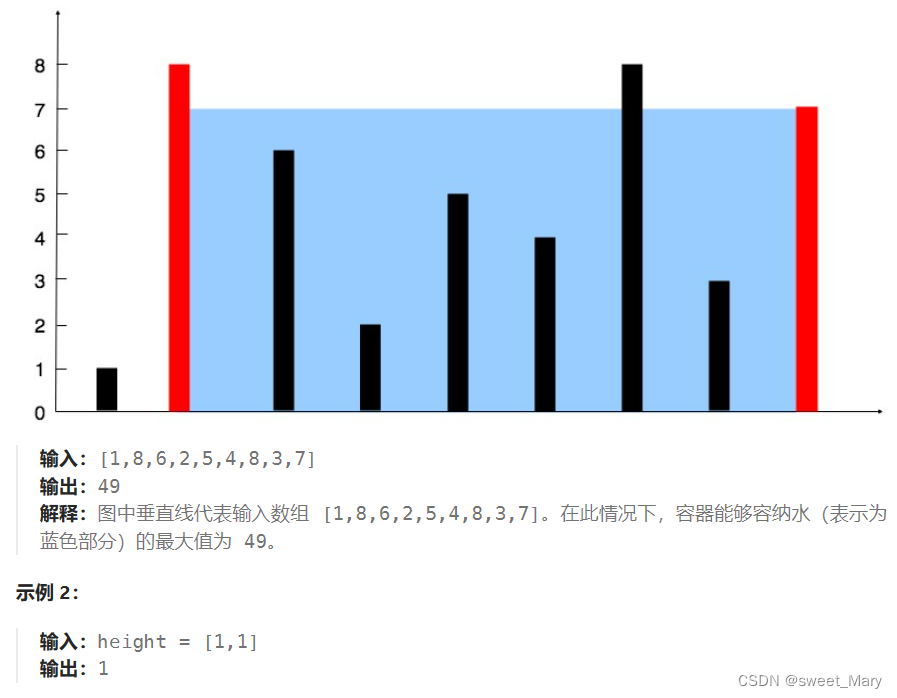
图源:文心一言
听课笔记简单整理,供小伙伴们参考~🥝🥝
- 第1版:听课的记录代码~🧩🧩
编辑:梅头脑🌸
审核:文心一言
目录
🐳课程来源
🐳静态数组
🐋6.1 一维数组应用举例
🐋6.2 数组作为函数参数
🐋6.3 对象数组初始化
🐋6.4 基于范围的for循环
🐳指针的定义
🐋6.5 指针的概念、定义与运算
🐋6.6 void类型、const类型、智能指针
🐳指针与数组
🐋6.10 指向数组类型的指针
🐋6.11 指向常量的指针做形参
🐳指针与函数
🐋6.12 指针类型的函数
🐋6.13 函数类型的指针
🐳指针与对象
🐋6.14 对象类型的指针
🐳动态数组
🐋6.16 动态分配与释放内存
🐋6.17 申请和释放动态数组
🐋6.18 动态创建多维数组
🐋6.19 动态数组类
🐋6.20 vector的应用举例
🐳对象的复制与移动
🐋6.22 对象的深层复制
🐋6.23 对象的移动构造
🐳字符串
🐋6.24 比较运算符与连接运算符
🐋6.25 C风格的字符串
🐋6.26 用getline输入字符串
🔚结语
🐳课程来源
- 郑莉、李超老师的公开课:🌸C++语言程序设计基础 - 清华大学 - 学堂在线
🐳静态数组
🐋6.1 一维数组应用举例
🧩题目
统计选择题答案的正确率。
⌨️代码
#include <iostream>
using namespace std;
int main()
{
const char key[] = {'a', 'b', 'c', 'a', 'd'}; // 标准答案
const int NUM_QUES = 5; // 问题数量
char c;
int ques = 0, numCorrect = 0;
cout << "Enter the " << NUM_QUES << " question test:" << endl; // 输入考生答案
while (cin.get(c)) { // 从输入流中提取一个标准字符
if (c != '\n') { // 未遍历到数组末尾(输出不是回车)
if (c == key[ques]) { // 考生答案正确
numCorrect++; cout << " ";
}
else { // 考生答案错误
cout << "*";
ques++;
}
}
else { // 成功遍历到数组末尾(输出是回车)
cout << " Score " << static_cast<float>(numCorrect) / NUM_QUES * 100 << "%"; // 输出正确率
ques = 0; numCorrect = 0; cout << endl; // 重新赋值
}
}
}📇执行结果
键盘输入:aabbc 回车,得到正确率(60%)与错误题号(*)数据:

📇相关概念
数组
数组是一种容纳批量数据的容器,适用于使用同一种算法循环数据数据元素,如下~
#include <iostream> using namespace std; int main() { int a[10], b[10]; // 使用同一种算法循环处理数据元素 for (int i = 0; i < 10; i++) { // 数组通常以0起始 a[i] = i * 2 - 1; // 正向为数组a[10]赋值 b[10 - i - 1] = a[i]; // 将a[10]的内容逆序排列 } // 依次输出数组的元素 for (int i = 0; i < 10; i++) { cout << "a[" << i << "] = " << a[i] << " "; cout << "b[" << i << "] = " << b[i] << endl; } return 0; }

数组的初始化
数组的初始化有很多不同的方式,例如分别构建一维矩阵和二维矩阵的初始化方式:
// demo1: 一维数组初始化 static int a[10] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; // 列出全部元素初始值 static int a[10] = { 0, 1, 2, 3, 4 }; // 列出部分元素初始值 static int a[] = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 }; // 列出全部元素初始值,不指定数组长度 // demo2: 二维数组初始化 static int a[3][4] = { {1, 2, 3 ,4},{5, 6, 7, 8},{9, 10, 11, 12} }; // 列出二维数组的全部初始值 static int a[3][4] = { {1},{0,6},{0,0,11} }; // 列出二维数组的部分初始值 static int a[][4] = { {1, 2, 3 ,4},{5, 6, 7, 8},{9, 10, 11, 12} }; // 列出全部元素初始值,省略一维下标 static int a[][4] = { 1, 2, 3 ,4 , 5, 6, 7, 8 , 9, 10, 11, 12 };
🐋6.2 数组作为函数参数
🧩题目
计算每行元素的和,计入每行的第1个元素。
⌨️代码
#include <iostream>
using namespace std;
void rowSum(int a[][4], int nRow) {
for (int i = 0; i < nRow; i++) { // 计算二维数组A 每行元素值的和
for (int j = 1; j < 4; j++) {
a[i][0] += a[i][j];
}
}
}
int main()
{
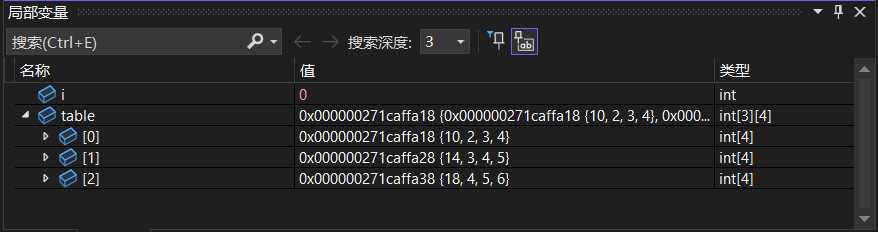
int table[3][4] = { {1, 2, 3, 4 }, {2, 3, 4, 5 }, {3, 4, 5, 6 } };
for (int i = 0; i < 3; i++) { // 输出数组元素
for (int j = 0; j < 4; j++)
cout << table[i][j] << " ";
cout << endl;
}
rowSum(table, 3); // 调用子函数,计算各行和
for (int i = 0; i < 3; i++) // 输出计算结果
cout << " Sum of row " << i << " is " << table[i][0] << endl;
return 0;
}📇执行结果
📇代码解释
数组作为函数参数
通过上述代码,我们可以看到,数组能够作为函数的参数进行运算,通过void rowSum(int a[][4], int nRow),我们接受到了nRow(本题为3)行元素每行的第1列,并且调用函数也可以修改数组的值,这种基于数组的修改并不需要return。
注意:
- 为什么它不像形参一样在调用函数执行完成后消失,而是真正的传回给了主函数呢?这是因为我们传递过去的,并非是数组的副本,而是数组首元素的地址,这允许调用函数通过该地址访问和修改原始数组的内容~
- 这种直接修改数组的方式有点危险,如果想避免数组被修改,可以在数组前增加const关键字~
图片是table被修改后的矩阵值~
可以使用下面的代码,避免原数组被修改~
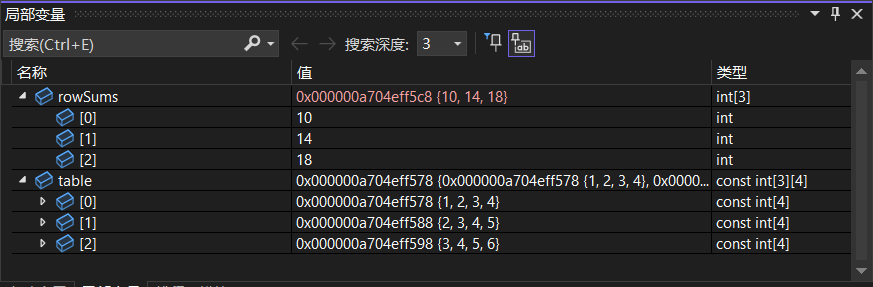
#include <iostream> using namespace std; void rowSum(const int a[][4], int nRow, int rowSums[]) { for (int i = 0; i < nRow; i++) { // 计算二维数组A 每行元素值的和 rowSums[i] = 0; for (int j = 0; j < 4; j++) { rowSums[i] += a[i][j]; } } } int main() { const int table[3][4] = { {1, 2, 3, 4 }, {2, 3, 4, 5 }, {3, 4, 5, 6 } }; // 修改为const int rowSums[3]; // 新增统计数组 for (int i = 0; i < 3; i++) { // 输出数组元素 for (int j = 0; j < 4; j++) cout << table[i][j] << " "; cout << endl; } rowSum(table, 3, rowSums); // 调用子函数,计算各行和 for (int i = 0; i < 3; i++) // 输出计算结果 cout << " Sum of row " << i << " is " << rowSums[i] << endl; return 0; }图片是rowSums被修改后的矩阵值~
const关键字是什么东西,可参考: 🌸C++入门06 数据的共享与保护-CSDN博客 ~
🐋6.3 对象数组初始化
🧩题目
创建Point类的两个对象,实现点的移动。
⌨️代码
#include <iostream>
#include "Point.h"
using namespace std;
Point::Point() : x(0), y(0) {
cout << "Default Constructor called." << endl;
}
Point::Point(int x, int y) : x(x), y(y) {
cout << "Constructor called." << endl;
}
Point::~Point() {
cout << "Destructor called." << endl;
}
void Point::move(int newX, int newY) {
cout << "Moving the point to (" << newX << ", " << newY << ")" << endl;
x = newX;
y = newY;
}
int main()
{
cout << "Entering main..." << endl;
Point a[2]; // 调用默认构造函数,初始化2个点
for (int i = 0; i < 2; i++) {
a[i].move(i + 10, i + 20); // 调用类函数,移动2个坐标
}
cout << "Exiting main..." << endl;
return 0;
}📇执行结果

📇代码解释
代码首先通过类Point的默认构造函数创建了两个点 a[0] = (0, 0),a[1] = (0, 0);
再通过调用point的move函数,使得a[0]的坐标移动到(10, 20),而a[1]的坐标移动到(11, 21)。
🐋6.4 基于范围的for循环
📇相关概念
有很多时候我们需要遍历长度未知的数组,此时比较普通的for循环与基于范围的for循环写法~
普通的for循环
#include <iostream> // demo1 int main() { int array[3] = { 1, 2, 3 }; int* p; for (p = array; p < array + sizeof(array) / sizeof(int); ++p) { // 使用指针遍历,数组大小未知时 *p += 2; std::cout << *p << std::endl; } return 0; }
基于范围的for循环
#include <iostream> // demo2 int main() { int array[3] = { 1, 2, 3 }; for (int &e : array) { e += 2; std::cout << e << std::endl; } return 0; }
🐳指针的定义
🐋6.5 指针的概念、定义与运算
🧩题目
指针ptr 指向 变量i 的地址。
⌨️代码
#include <iostream>
using namespace std;
int main() {
int i;
int* ptr = &i;
i = 10;
cout << "i = " << i << endl; // 输出 i 的值
cout << "*ptr = " << *ptr << endl; // 输出 ptr 指针的内容
cout << "&i = " << &i << endl; // 输出 i 的地址
cout << "ptr = " << ptr << endl; // 输出 ptr 所指向的地址(即变量 i 的地址)
return 0;
}📇执行结果
📇代码解释
注意上面的代码,i 的值是在指针 ptr 被赋予 i 的地址之后进行修改的,而由于 ptr 指向 i,因此通过 ptr 可以访问和更新 i 所对应地址空间的内容~
📇相关概念
指针
指针是一种特殊的数据类型,其值为内存地址,通过这个地址可以访问对应内存中的数据。指针在编程中有多种用途:
- 提高程序的编译效率和执行速度:指针可以直接访问内存地址,因此可以减少不必要的内存访问和数据复制,从而提高程序的执行效率。
- 实现动态内存分配:指针可以与动态内存分配函数(如malloc、calloc等)结合使用,实现在运行时动态分配内存空间,使程序能够更灵活地管理内存资源。
- 实现函数间的双向通信:通过指针,函数可以修改调用它的函数中的变量,从而实现函数间的双向通信。这是因为指针可以指向变量的地址,通过修改指针所指向地址的内容,可以改变变量的值。
- 表示和实现复杂的数据结构:指针可以用于表示和实现各种复杂的数据结构,如链表、树、图等。这些数据结构在编程中非常有用,可以用于解决各种实际问题。
- 直接操纵内存地址:指针可以直接操纵内存地址,这对于一些需要直接访问物理内存或进行底层硬件操作的应用程序来说非常有用。
指针使用时一些值得注意的点
(1)除了修改变量,也可以通过访问指针,修改指针指向的内容~
int main() { int i; int* ptr = &i; *ptr = 3; cout << "i = " << i << endl; // 输出 i 的值 cout << "*ptr = " << *ptr << endl; // 输出 ptr 指针的内容 cout << "&i = " << &i << endl; // 输出 i 的地址 cout << "ptr = " << ptr << endl; // 输出 ptr 所指向的地址(即变量 i 的地址) return 0; }
(2)指针是不能直接被常数赋值的,编译器大概率会报错,除了0可以被赋值,此时表示指针是个空指针~
int main() { int i = 10; // int* ptr = 3; // 编译器不接受直接赋值,会报错 int* ptr = 0; // 除非它是0 // int* ptr = nullptr; // 或者使用nullptr代替0来表示空指针(C++11及以后的标准) cout << "i = " << i << endl; // 输出 i 的值 // cout << "*ptr = " << *ptr << endl; // 输出 ptr 指针的内容,空指针是没办法输出内容的 cout << "&i = " << &i << endl; // 输出 i 的地址 cout << "ptr = " << ptr << endl; // 输出 ptr 所指向的地址(即变量 i 的地址) return 0; }


🐋6.6 void类型、const类型、智能指针
📇相关概念
void类型的指针
虽然在C++中不支持生成void类型的变量(具体来说,
void类型表示“无类型”,编译器会不晓得这个变量到底占用多少内存空间),但是可以生成void类型的指针,并且void类型的指针还可以转化为int类型的指针,代码如下~#include <iostream> using namespace std; int main() { // !void voidObeject; // 不能声明void类型的变量,本身占据内存空间不确定 void *pv; // 可以声明void类型的指针,本身是指针,指向的对象不确定 int i = 5; pv = &i; // void类型指针指向整型变量 int* pint = static_cast<int*>(pv); // void指针转换为int指针 cout << "*pint = " << *pint << endl; return 0; }
请注意,void类型的指针本身是不能引用与输出的,例如我们不转化指针,代码写成这个样子,编译器在“ cout << "*pv = " << *pv << endl;”就开始编译报错了——
#include <iostream> using namespace std; int main() { void *pv; // 可以声明void类型的指针,本身是指针,指向的对象不确定 int i = 5; pv = &i; // void类型指针指向整型变量 cout << "*pv = " << *pv << endl; return 0; }

const类型的指针
指向常量的指针(const int *p):指针指向的内容不能被修改。
const int x = 10; // 常量x const int y = 20; // 常量y const int *p = &x; // 指向常量的指针p,指向x // 下面的赋值是合法的,因为改变的是指针p所指向的地址,而不是它所指向的内容 p = &y; // 现在p指向y // 下面的赋值是不合法的,因为p指向的内容是常量,不能被修改 // *p = 30; // 编译错误:表达式必须是可修改的左值常量指针(int *const q = &a;):指针本身的值(即它所存储的地址)不能被修改,但它指向的内容可以修改。
指向常量的常量指针(const int *const r):指针本身和它指向的内容都不能被修改。
int a = 10; int b = 20; // 常量指针,指向的地址不能被修改,但指向的内容可以修改 int *const q = &a; // q = &b; // 编译错误:q是一个常量指针,它的值不能被修改 *q = 30; // 合法:修改q所指向的内容 // 指向常量的常量指针,既不能修改指向的地址,也不能修改指向的内容 const int *const r = &a; // r = &b; // 编译错误:r是一个常量指针,它的值不能被修改 // *r = 40; // 编译错误:r指向的内容是常量,不能被修改
链接提供了更多 const 的用法: 🌸C++入门06 数据的共享与保护-CSDN博客 ~
智能指针
这段我没有好好听课,嗯,所以以下都是AI写的~
std::unique_ptr:它是一种独占式智能指针,它拥有对其所指向对象的唯一所有权。当std::unique_ptr被销毁时,它所指向的对象也会被销毁。由于其独占性,std::unique_ptr不能被拷贝,只能被移动。std::shared_ptr:它是一种共享式智能指针,它可以被多个指针共享。每个指针都维护一个引用计数,当引用计数为0时,所指向的对象会被销毁。std::shared_ptr可以被拷贝和移动。std::weak_ptr:它是为了解决std::shared_ptr相互引用时产生的死锁问题而设计的。std::weak_ptr是对对象的一种弱引用,它不会增加对象的引用计数,而是当需要时可以从std::weak_ptr提升为std::shared_ptr。#include <iostream> #include <memory> struct MyWeakPtrObject { MyWeakPtrObject(int value) : value_(value) { std::cout << "MyWeakPtrObject constructed with value " << value_ << std::endl; } ~MyWeakPtrObject() { std::cout << "MyWeakPtrObject destroyed with value " << value_ << std::endl; } int value_; }; int main() { // 创建shared_ptr std::shared_ptr<MyWeakPtrObject> sharedPtr = std::make_shared<MyWeakPtrObject>(20); // 创建weak_ptr,它不增加引用计数 std::weak_ptr<MyWeakPtrObject> weakPtr = sharedPtr; // 可以通过weak_ptr来创建shared_ptr,但这会增加引用计数 if (auto tempSharedPtr = weakPtr.lock()) { std::cout << "Object is still alive, value: " << tempSharedPtr->value_ << std::endl; } else { std::cout << "Object has been destroyed" << std::endl; } // 当shared_ptr离开作用域并销毁对象时,weak_ptr不会阻止对象销毁 // 但试图通过已销毁对象的weak_ptr来获取shared_ptr将会失败 sharedPtr.reset(); // 销毁对象 if (weakPtr.lock()) { std::cout << "Object is still alive" << std::endl; // 这段代码不会被执行 } else { std::cout << "Object has been destroyed" << std::endl; // 输出这个信息 } return 0; }
话说,我还问到了AI,智能指针在什么场景比较常用呢?我都没怎么见过...
AI回复:“如果你觉得自己在实际编程中很少见到智能指针,可能是因为你还没有接触到需要动态内存管理的复杂项目,或者你正在使用的库或框架已经内部使用了智能指针来管理内存。然而,在现代C++编程中,智能指针已经成为了管理动态内存的标准做法之一,因此了解并熟练使用它们是非常重要的。”
AI的回复浓缩成一句话可能就是:“你没见过,就是因为你太菜了,练好了再来打吧。”

🐳指针与数组
🐋6.10 指向数组类型的指针
🧩题目
利用指针数组存放矩阵。
⌨️代码
#include <iostream>
using namespace std;
int main()
{
int line1[] = { 1, 0, 0 }; // 矩阵的第一行
int line2[] = { 0, 1, 0 }; // 矩阵的第二行
int line3[] = { 0, 0, 1 }; // 矩阵的第三行
// 定义整型指针数组并初始化
int* pLine[3] = { line1, line2, line3 };
cout << "Matrix test:" << endl;
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 3; j++) {
cout << pLine[i][j] << " ";
}
cout << endl;
}
return 0;
}📇执行结果
📇代码解释
这个3 x 3 的二维矩阵是由3个整数数组(代表3行)通过指针数组拼接而成的,同样可以实现矩阵的功能。
相比普通矩阵,使用指针数组构成的矩阵具有以下特点:
- 矩阵每行的长度可以不同,这在处理稀疏矩阵或每行长度差异很大的矩阵时,可以节省存储空间;
- 每行数组(如
line1,line2,line3)在内存中是连续存放的,但指针数组pLine所指向的这些行数组在内存中可能不是连续存放的。尽管如此,pLine仍然支持随机访问,即可以通过pLine[i][j]访问矩阵中的任意元素。这种随机访问是通过两次间接引用实现的:一次是通过指针数组pLine找到正确的行,另一次是通过该行指针找到正确的元素;
🐋6.11 指向常量的指针做形参
🧩题目
通过指针遍历输出数组(共含有6个元素)的值。
⌨️代码
#include <iostream>
using namespace std;
const int N = 6;
void print(const int* p, int n);
int main()
{
int array[N];
for (int i = 0; i < N; i++)
cin >> array[i];
print(array, N);
return 0;
}
void print(const int*p, int n){
cout << "{" << *p;
for (int i = 1; i < n; i++)
cout << "," << *(p + i);
cout << "}" << endl;
}📇执行结果
输入 1 2 3 4 5 6之后的输出结果:

📇代码解释
这次传参,从 print(array, N); 到 void print(const int*p, int n),直接诠释了数组就是在传首地址的观点,本例题可以与 博文 6.2 的例子作为对比~
如果不希望看到显式的指针,我们可以修改成这样:
#include <iostream>
#include <array>
using namespace std;
const int N = 6;
void print(const array<int, N> arr);
int main()
{
array<int, N> array;
for (int i = 0; i < N; i++)
cin >> array[i];
print(array);
return 0;
}
void print(const array<int, N> arr) {
cout << "{";
for (int i = 0; i < N; i++) {
if (i > 0) cout << ","; // 在非第一个元素前输出逗号
cout << arr[i];
}
cout << "}" << endl;
}🐳指针与函数
🐋6.12 指针类型的函数
📇相关概念
函数的类型与返回值除了是数据类型,也可以是指针类型。使用指针类型可以避免在处理数据时来回的复制,节省时间与内存开销,但是使用指针需要注意内存管理,以避免悬挂指针与内存泄漏。
还要注意尽量不要返回非主函数的局部变量,这样编译器会很懵:“不是,你子函数调用完变量都没了,你想让我干啥,干啥?!”
⌨️代码(错误示例)
// 错误的例子
#include <iostream>
int main()
{
int *function();
int* ptr = function();
std::cout << "* ptr = " << * ptr << std::endl;
std::cout << " ptr = " << ptr << std::endl;
*ptr = 5; // 危险的访问,不可以将局部地址返回到主函数
return 0;
}
int* function() {
int local = 0; // 非静态局部变量作用域和寿命都仅限于本函数体内
std::cout << "local = " << local << std::endl;
std::cout << "&local = " << &local << std::endl;
return &local;
}上面这段代码,可以通过编译,但是具体执行起来没有什么意义,有种人面不知何处去,桃花依旧笑春风的既视感~~

⌨️代码(正确示例1)
// 正确的例子1
#include <iostream>
using namespace std;
int main() {
int array[10];
int* search(int* a, int num);
for (int i = 0; i < 10; i++) {
cin >> array[i];
}
int* zeroptr = search(array, 10);
cout << "zeroptr = " << zeroptr << endl;
if(zeroptr != nullptr) cout << "* zeroptr = " << * zeroptr << endl;
return 0;
}
int* search(int* a, int num) {
for (int i = 0; i < num; i++) {
if (a[i] == 0)
return &a[i];
}
return nullptr;
}相比错误代码返回子函数的值,这段代码检查main函数搜索输入的数组内容中有没有值为0的元素,并返回这个数的地址,这是可行的~
⌨️代码(正确示例2)
// 正确的例子2
#include <iostream>
using namespace std;
int main() {
int* newintvar();
int* intptr = newintvar();
std::cout << "* intptr = " << *intptr << std::endl;
std::cout << " intptr = " << intptr << std::endl;
delete intptr; // 如果不在这里释放,会造成内存泄漏
return 0;
}
int* newintvar() {
int* p = new int(5); // new 是动态分配
std::cout << "* p = " << *p << std::endl;
std::cout << " p = " << p << std::endl;
return p; // 返回的地址指向的是动态分配的空间
} // 函数运行结束时,p中的地址仍有效
这段正确示例,虽然看起来和错误示例没有什么区别,但注意 int(5) 是new出来的(new是动态分配的),相比错误示例(处理栈上分配的内存),这处理的是堆上分配的内存。栈上的内存自动管理(当函数返回时自动释放),而堆上的内存需要手动管理(使用 delete 释放)~
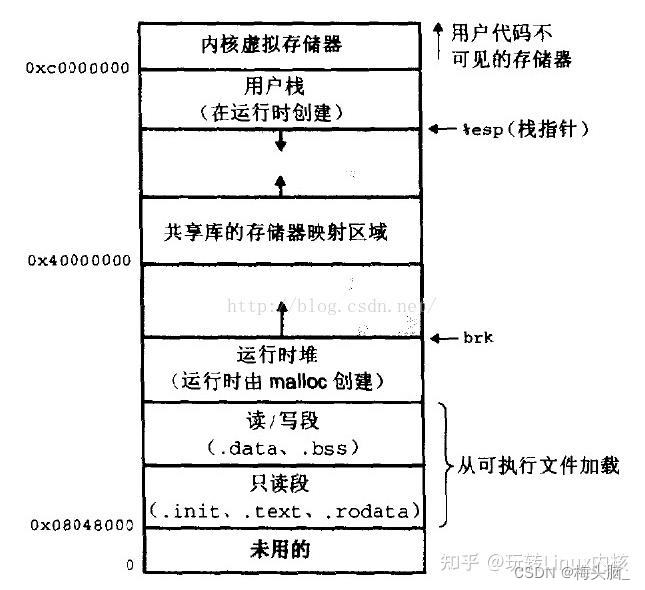
下面这张内存映像图图有栈和堆的位置,堆在从下到上第4个位置,栈在从上到下第2个位置:
对内存感兴趣可以看向这里:🌸计组+系统02:30min导图复习 存储系统~~
🐋6.13 函数类型的指针
🧩题目
通过调用compute函数实现取最大值、最小值,求和的功能。
⌨️代码
// 指向函数的指针
// 注释需要AI审核
#include <iostream>
using namespace std;
// 调用同一个函数,实现3种功能(利用函数指针调用其他函数,利用其他函数作为实参)
// 注意,int(*func) 是指向函数的指针,(int int)是参数表,int compute 是返回值,而若去掉括号,写为int *func 是返回整数类型的指针的函数
int compute(int a, int b, int(*func)(int, int)) {
return func(a, b);
}
int max(int a, int b) {
return ((a > b) ? a : b);
}
int min(int a, int b) {
return ((a < b) ? a : b);
}
int sum(int a, int b) {
return a + b;
}
int main()
{
int a, b, res;
cout << "请输入整数a:"; cin >> a;
cout << "请输入整数b:"; cin >> b;
res = compute(a, b, &max); // 写为 res = compute(a, b, max); 也是可以运行的,但不如 &max 更清晰一些
cout << "Max of " << a << " and " << b << " is " << res << endl;
res = compute(a, b, &min);
cout << "Min of " << a << " and " << b << " is " << res << endl;
res = compute(a, b, &sum);
cout << "Sum of " << a << " and " << b << " is " << res << endl;
return 0;
}
📇执行结果
输入:3, 5后的结果:

📇代码解释
来不及为指针类型的函数(用于返回指针类型的值)悲伤,立刻登场的是函数类型的指针!
这个指针int (*func)可以调用很多不同的小弟为他服务,具体来说,只要他有这个小弟(max, min ,sum),小弟符合老大的要求(接受两个int参数并返回一个int值),他就可以随时呼叫小弟来一段专属服务~
当然,注意:
- 老大呼叫函数时要戴上小括号,好比皇帝一定要有一个虎符,没有这个虎符他就是个普通的指针小弟 int *func,没有函数大佬会听它讲话的;
- 另外,呼叫函数时无论有没有地址操作符&,由于函数名本身就是一个指向函数的指针,所以在底层的原理都是获取函数的首地址,这一点和数组传参是完全类似的~
🐳指针与对象
🐋6.14 对象类型的指针
🧩题目
定义对象指针,输出指针的值~
⌨️代码
#include <iostream>
using namespace std;
class Point {
public:
Point(int x = 0, int y = 0): x(x), y(y){}
int getX() const { return x; }
int getY() const { return y; }
private:
int x, y;
};
int main()
{
Point a(4, 5);
Point* p1 = &a; // 定义对象指针,用a 的地址初始化
cout << p1->getX() << endl; // 用指针访问对象成员
cout << a.getX() << endl; // 用对象名访问对象成员
}指针的类型除了是基本数据类型、void以外,还可以是个类,总之晓得有这个功能就可以了~

当然,与函数、数组类似的是,我们在调用类的时候,其实也是传递类的首地址指针(在非静态成员函数中,这个指针的名字叫做this),所以可以实现对类的直接修改(写到这里,忽然感觉除了变量平时传副本,其它的数据类型都是在传地址的样子,虽然变量也是可以传地址的)~~
类的指针这个功能最厉害的地方是处理前向引用的问题,之前我们介绍过前向引用(🌸C++入门05 类与对象-CSDN博客)是没办法相互引用对象的,但是引入指针以后就可以了~
比如在类没有完全定义就需要相互引用的问题,因为不知道类Fred到底占用多少空间,所以没办法在类Barney定义对象x;
// demo2:错误
class Fred; // 前向引用声明
class Barney {
Fred x; // 错误,类Fred的声明尚不完善
};
class Fred {
Barney y;
};但是现在指针不存在这个问题,它不需要数据类型就可以定义,完美实现了对象的前向应用:
// 前向引用修改, 虽然现实中很少有需要相互包含的例子
class Fred;
class Barney {
Fred* x;
};
class Fred {
Barney y;
};虽然我也不晓得这个功能什么时候能用上,设计的时候还是尽量避免相互引用吧,凭借我为数不多的打代码经验,感觉这个功能容易埋bug~~
🐳动态数组
🐋6.16 动态分配与释放内存
📇相关概念
虽然我们在之前已经断断续续接触到了动态分配,例如:
我曾傻傻问过AI什么是动态变量:🌸C++入门06 数据的共享与保护-CSDN博客,
- AI的表面: 通常,“动态变量”这个词并不是用来描述变量作用域或存储期的标准术语。然而,在编程中,动态内存分配通常指的是使用
malloc、calloc、realloc(在C中)或new(在C++中)等函数在堆(heap)上分配的内存。 - AI的内心:嗯?动态变量是什么,你是不是看见静态变量就想多了?!
以及动态分配的作用:
- 通过本文6.12,我们知道传指针的时候,想返回被调用函数中创建的指针变量时,只能new一个对象,否则,在子函数执行完时,在栈上定义的指针就会自行消失,指针会返回乱七八糟的值;进一步讲,指针就是动态内存分配的关键,指针存储了动态分配的地址,使我们能够在函数之间传递地址与释放内存。
- 更重要的是,有时我们需要处理的不只是单个变量,而是长度不确定的数组,此时动态内存分配相比静态内存分配更加灵活,更有效率,不会占用过多的空间;之后的内容中我们会介绍动态数组,详细地说明这个问题~~
动态分配与静态分配的区别:
- new对象很方便,毕竟这个变量就好像是成年了一样,可以有自己的想法,掌握自己的人生,再也不需要编译器时时刻刻看管着了~~
- 但是作为一个成熟的对象,执行完任务是需要用delete自行消亡的,不然被黑客捉到了可能会造成内存泄漏的问题。至于这个问题有多严重,可以参考前两天挂在官方文档的描述:🌸美国政府敦促开发者:停止使用 C、C++-CSDN博客~
这段代码介绍了怎样new与delete一个类的对象,可以用上一道题的Point类拼接执行~
int main()
{
cout << "Step one:" << endl;
Point* ptr1 = new Point; // 调用默认析构函数
delete ptr1; // 删除对象,自动调用析构函数(而不是删除指针自己,指针自己作为局部变量,在函数运行完成后自动消失)
cout << "Step two:" << endl;
ptr1 = new Point(1, 2);
delete ptr1;
return 0;
}
🐋6.17 申请和释放动态数组
🧩题目
定义对象数组指针,移动数组的成员~
⌨️代码
#include <iostream>
using namespace std;
class Point {
public:
Point() : x(0), y(0) {
cout << "Default Constructor called." << endl;
}
Point(int x, int y) : x(x), y(y) {
cout << "Constructor called." << endl;
}
~Point() { cout << "Destructor called." << endl; }
int getX() const { return x; }
int getY() const { return y; }
void move(int newX, int newY) {
x = newX;
y = newY;
}
private:
int x, y;
};
int main()
{
Point* ptr = new Point[2]; // 创建对象数组
ptr[0].move(5, 10); // 通过指针访问数组元素的成员
ptr[1].move(15, 20); // 通过指针访问数组元素的成员
cout << "Deleting..." << endl;
delete[] ptr; // 删除整个对象数组。注意1,如果写为 delete ptr,仅会删除首个数组;注意2,养成写new以后delete的好习惯~~
return 0;
}📇执行结果

📇代码解释
这段代码定义了数组的指针,通过指针访问数组,并删除指针的代码。
注意,删除数组的时候要加大括号,像这样“delete[] ptr; ”,否则它可能只会删除数组的首个元素~
🐋6.18 动态创建多维数组
🧩题目
创建三维数组,赋值并打印~
⌨️代码
#include <iostream>
using namespace std;
int main()
{
int (*cp)[9][8] = new int[7][9][8]; // *cp是指向数组的指针
for (int i = 0; i < 7; i++)
for (int j = 0; j < 9; j++)
for (int k = 0; k < 8; k++)
//*(*(*(cp + i) + j) + k) = (i * 100 + j * 10 + k); // 写法一
cp[i][j][k] = (i * 100 + j * 10 + k); // 写法二
for (int i = 0; i < 7; i++) {
for (int j = 0; j < 9; j++) {
for (int k = 0; k < 8; k++)
cout << cp[i][j][k] << " ";
cout << endl;
}
cout << endl;
}
delete[] cp;
return 0;
}📇执行结果

📇代码解释
我有点怀疑这个int (*cp)[9][8] = new int[7][9][8]; 它可以让代码一次跨越一个二维矩阵,那我们改成 int (*cp)[8] = new int[7][9][8]; 以后会不会一次跨越一行呢?
修改之后发现并不会,编译直接报错了:"int (*)[9][8]" 类型的值不能用于初始化 "int (*)[8]" 类型的实体 ;看来定义数组的指针就是要少一个维度的样子。
与6.10 初始化略有区别(6.10 的初始化“int* pLine[3] = { line1, line2, line3 };”),6.18 这个三维矩阵,应该在7个9 x 8的二维是矩阵内部是连续存储的,在7个9 x 8的二维矩阵之间也是连续存储的(“new int[7][9][8]; ”直接分配了连续的三维空间),可以使用随机访问,因此支持直接输出“cp[i][j][k]”~
🐋6.19 动态数组类
🧩题目
创建Point类的动态对象数组(对象数量根据用户需要确定)~
⌨️代码
#include <iostream>
#include <cassert>
using namespace std;
class Point {
public:
Point() : x(0), y(0) {
cout << "Default Constructor called." << endl;
}
Point(int x, int y) : x(x), y(y) {
cout << "Constructor called." << endl;
}
~Point() { cout << "Destuctor called." << endl; }
int getX() const { return x; }
int getY() const { return y; }
void move(int newX, int newY) {
x = newX;
y = newY;
}
private:
int x, y;
};
class ArrayOfPoints { // 动态数组类
public:
ArrayOfPoints(int size) : size(size) {
points = new Point[size];
}
~ArrayOfPoints() {
cout << "Deleting..." << endl;
delete[] points;
}
Point& element(int index) { // 此处有引用,希望point 是个左值,可以直接被修改,而非右值(副本)
assert(index >= 0 && index < size); // 要求下标不能越界
return points[index]; // 寻找下标为Index的point数组直接return回去
}
private:
Point* points; // 指向动态数组首地址
int size; // 数组大小
};
int main()
{
int count;
cout << "Please enter the count of points:";
cin >> count;
ArrayOfPoints points(count); // 创建数组对象
points.element(0).move(5, 0); // 访问数组元素的成员
points.element(1).move(15, 20); // 访问数组元素的成员
return 0;
}📇执行结果
例如输入5以后,这段代码就创建了5个点:

📇代码解释
ArrayofPoints类使用动态内存分配来创建一个Point类的数组,也就是实现根据用户输入的大小来确定数据下标的过程~
动态数组类的构造:
- 首先,调用“ArrayOfPoints(int size) : size(size) ”1 次,创建名为points的数组;
- 其次,调用构造函数“Point(int x, int y) ”或默认构造函数 “Point() ” size次(用户输入的数值),创建数组内名为point的元素;本例没有显示初始化,均调用默认构造函数;
move函数调用:
- 首先,调用了类ArrayOfPoints中的函数element获取下标的引用,并检查下标是否合法;其中assert(),它的功能有点像if(),检查数组下标是否越界,如果满足判断条件,就继续向下执行;
- 其次,调用了类Point的函数move,执行具体功能;在本例中仅移动了2个点的坐标,如果有批量移动的需求,可以改成循环来遍历数组;
动态数组类的析构:
- 析构顺序与构造顺序是相反的,当ArrayofPoints对象离开其作用域或被显式删除时,先构造的后析构,后构造的先析构;
- 在析构过程中,先调用类ArrayofPoints的析构函数,执行delete[] points释放内存(new的数组对象需要手动释放),同时输出"Deleting...",这会自动触发类Point的析构函数,同时分别输出"Destuctor called.";
🐋6.20 vector的应用举例
🧩题目
求数组的平均数(数组元素个数与数值由用户确定)~
⌨️代码
#include <iostream>
#include <vector>
using namespace std;
double average(const vector <double>& arr) {
double sum = 0;
for (unsigned i = 0; i < arr.size(); i++)
sum += arr[i];
return sum / arr.size();
}
int main()
{
unsigned n;
cout << "n = "; // 输入数组元素个数
cin >> n;
vector<double> arr(n);
cout << "Please input " << n << " real numbers:" << endl;
for (unsigned i = 0; i < n; i++)
cin >> arr[i];
cout << "Average = " << average(arr) << endl;
return 0;
}📇执行结果
先输入5,再输入 1 2 3 4 5 后,执行结果如图:

📇相关概念
vector简介:
- std::vector是C++库内自带的动态数组,无论是自己写代码还是刷力扣,基本vector数组就是使用标准了,使用习惯和数组没有什么太大区别,而且还有以下优点:
- vector可以根据数组元素动态调整大小,自动处理内存分配和释放;
- vector自带了成员函数,例如:
push_back()用于在末尾添加元素,pop_back()用于删除末尾元素,size()用于获取元素数量,empty()用于检查是否为空,等等;其中,push_back()的用法可以看这个:🌸数组01 Vector中的push_back[C++]; - vector提供了迭代器(iterator),这使得你可以使用标准库中的算法来操作
vector中的元素。例如,你可以使用std::sort()来对vector进行排序,或使用std::find()来查找特定元素; - vector是C++标准库的一部分,因此它与C++的其他特性(如异常处理、STL算法等)紧密集成,使得在C++环境中使用
vector更加自然和高效;
- 例如,写for循环和普通数组也是差别不大的,例如我们可以用3种写法使用for循环,比回的写法仅仅少了1种!ヾ(◍°∇°◍)ノ゙
#include <vector>
#include <iostream>
using namespace std;
int main() {
std::vector<int>v = { 1, 2, 3 };
for (auto i = 0; i < v.size(); ++i) // for循环,遍历元素
std::cout << v[i] << "\t";
std::cout << std::endl;
for (auto i = v.begin(); i != v.end(); ++i) // for循环,可以将.begin(),.end()视为指针
std::cout << *i << "\t";
std::cout << std::endl;
for (auto e : v) // 基于范围的for循环
std::cout << e << "\t";
std::cout << std::endl;
}
vector与arr的转化:
- vector是数组,arr也是数组,但是亲兄弟明算账,他们之间的类型是不可以直接相互转化的;
- 如果想实现vector与arr之间的传值,那么可以使用data成员函数获取其内部数组的指针,但这样做有一定的风险,因为函数
fun并不知道数组的实际大小;如果可能的话,最好传递数组的大小或者使用标准库中的容器和迭代器来避免这种风险。
#include <vector>
#include <iostream>
void fun(int a[]){
std::cout << a[2] << std::endl;
}
int main() {
std::vector<int> vec = {1, 2, 3};
// fun(vec); // 编译错误:不存在从 "std::vector<int, std::allocator<int>>" 到 "int *" 的适当转换函数
fun(vec.data()); // 正确:使用vec.data()获取指向内部数组的指针
return 0;
}vector指针内存管理:
- 如果没有特殊需求(比如有算法要求双指针遍历数组什么的),尽量不要让两个指针指向同一块内存,并在不确定的情况下多次删除该内存,不然在回收空间时,如果两个指针指向同一块内存,删除其中一个指针后,那块内存就被释放了,此时再通过另一个指针访问或删除那块内存,可能会导致程序崩溃或者其他奇怪的错误;
- 另外,为了避免这种错误,当使用
new分配内存并将指针赋值给另一个指针时,应该确保在删除内存后,将两个指针都设置为nullptr。这样,即使不小心尝试再次删除它们,程序也不会崩溃(尽管这仍然是一个逻辑错误)。
#include <iostream>
using namespace std;
int main() {
int* first, * second;
first = new int[5];
second = first;
// 省略对于数组的操作
delete[] second; // 删除数组内存(运行正确)
// delete[] first; // 删除数组内存(运行错误,两个指针指向同一片内存)
second = nullptr; // 将second设置为nullptr,防止成为悬挂指针
first = nullptr; // 将first设置为nullptr,防止再次删除同一块内存
if (first == nullptr && second == nullptr) { // 现在可以安全地检查first和second是否为nullptr,而不会导致未定义行为
cout << "Both pointers are nullptr." << endl;
}
return 0;
}🐳对象的复制与移动
🐋6.22 对象的深层复制
🧩题目
创建Point对象数组,执行数组元素移动的功能,并析构数组~
⌨️代码
#include <iostream>
#include <cassert>
using namespace std;
class Point {
public:
Point() : x(0), y(0) {
cout << "Default Constructor called." << endl;
}
Point(int x, int y) : x(x), y(y) {
cout << "Constructor called." << endl;
}
~Point() { cout << "Destuctor called." << endl; }
int getX() const { return x; }
int getY() const { return y; }
void move(int newX, int newY) {
x = newX;
y = newY;
}
private:
int x, y;
};
class ArrayOfPoints { // 动态数组类
public:
ArrayOfPoints(int size) : size(size) {
points = new Point[size];
}
ArrayOfPoints(const ArrayOfPoints& v) { // 深层复制构造函数
size = v.size;
points = new Point[size];
for (int i = 0; i < size; i++)
points[i] = v.points[i];
}
~ArrayOfPoints() {
cout << "Deleting..." << endl;
delete[] points;
}
Point& element(int index) { // 此处有引用,希望point 是个左值,可以直接被修改,而非右值(副本)
assert(index >= 0 && index < size); // 要求下标不能越界
return points[index]; // 寻找下标为Index的point数组直接return回去
}
private:
Point* points; // 指向动态数组首地址
int size; // 数组大小
};
int main()
{
int count;
cout << "Please enter the count of points:";
cin >> count;
ArrayOfPoints pointsArray1(count); // 创建对象数组
pointsArray1.element(0).move(5, 0); // 访问数组元素的成员
pointsArray1.element(1).move(15, 20); // 访问数组元素的成员
ArrayOfPoints pointsArray2(pointsArray1); // 创建副本
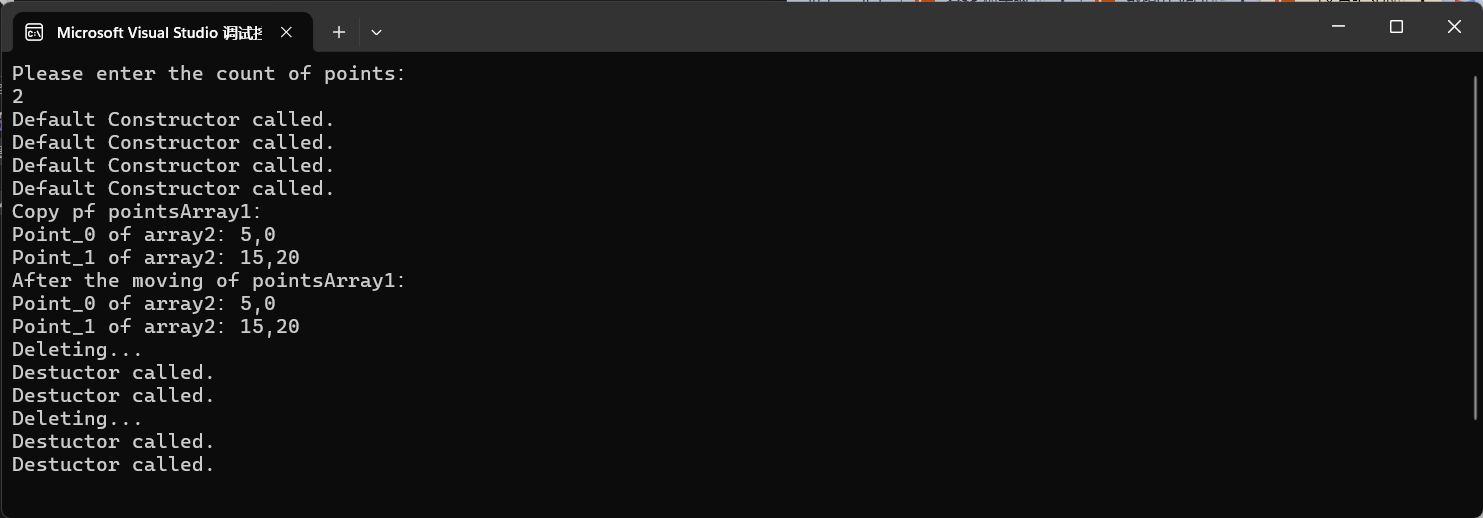
cout << "Copy pf pointsArray1:" << endl;
cout << "Point_0 of array2:" << pointsArray2.element(0).getX() << "," << pointsArray2.element(0).getY() << endl;
cout << "Point_1 of array2:" << pointsArray2.element(1).getX() << "," << pointsArray2.element(1).getY() << endl;
pointsArray1.element(0).move(25, 30);
pointsArray1.element(1).move(35, 40);
cout << "After the moving of pointsArray1:" << endl; // 注意,这一步在复制以后,两个类的指针会指向同一片内存空间
cout << "Point_0 of array2:" << pointsArray2.element(0).getX() << "," << pointsArray2.element(0).getY() << endl;
cout << "Point_1 of array2:" << pointsArray2.element(1).getX() << "," << pointsArray2.element(1).getY() << endl;
return 0;
}📇执行结果
输入2(反正示例代码里会移动2个点),执行结果如图:
📇代码解释
深层复制构造函数相对应的概念是浅层复制构造函数,也就是我们在之前介绍过的内容:🌸C++入门05 类与对象-CSDN博客。在未写浅层复制构造函数或写了一个仅有名称的浅层复制构造函数时,编译器自动生成一个复制对象,变量会有相同的名称,指针会有相同的地址,数组会有相同的首地址~
我们来展示一下浅层复制构造函数的代码(这个代码没有写浅层复制构造函数,此时编译器就会默默自动生成一个浅层复制构造函数):
#include <iostream>
#include <cassert>
using namespace std;
class Point {
public:
Point() : x(0), y(0) {
cout << "Default Constructor called." << endl;
}
Point(int x, int y) : x(x), y(y) {
cout << "Constructor called." << endl;
}
~Point() { cout << "Destuctor called." << endl; }
int getX() const { return x; }
int getY() const { return y; }
void move(int newX, int newY) {
x = newX;
y = newY;
}
private:
int x, y;
};
class ArrayOfPoints { // 动态数组类
public:
ArrayOfPoints(int size) : size(size) {
points = new Point[size];
}
~ArrayOfPoints() {
cout << "Deleting..." << endl;
delete[] points;
}
Point& element(int index) { // 此处有引用,希望point 是个左值,可以直接被修改,而非右值(副本)
assert(index >= 0 && index < size); // 要求下标不能越界
return points[index]; // 寻找下标为Index的point数组直接return回去
}
private:
Point* points; // 指向动态数组首地址
int size; // 数组大小
};
int main()
{
int count;
cout << "Please enter the count of points:";
cin >> count;
ArrayOfPoints pointsArray1(count); // 创建数组对象
pointsArray1.element(0).move(5, 0); // 访问数组元素的成员
pointsArray1.element(1).move(15, 20); // 访问数组元素的成员
ArrayOfPoints pointsArray2(pointsArray1); // 创建副本
cout << "Copy pf pointsArray1:" << endl;
cout << "Point_0 of array2:" << pointsArray2.element(0).getX() << "," << pointsArray2.element(0).getY() << endl;
cout << "Point_1 of array2:" << pointsArray2.element(1).getX() << "," << pointsArray2.element(1).getY() << endl;
pointsArray1.element(0).move(25, 30);
pointsArray1.element(1).move(35, 40);
cout << "After the moving of pointsArray1:" << endl; // 注意,这一步在复制以后,两个类的指针会指向同一片内存空间
cout << "Point_0 of array2:" << pointsArray2.element(0).getX() << "," << pointsArray2.element(0).getY() << endl;
cout << "Point_1 of array2:" << pointsArray2.element(1).getX() << "," << pointsArray2.element(1).getY() << endl;
return 0; // 这一步记得设置断点,不然会大大大大大...大大大大大批量报错
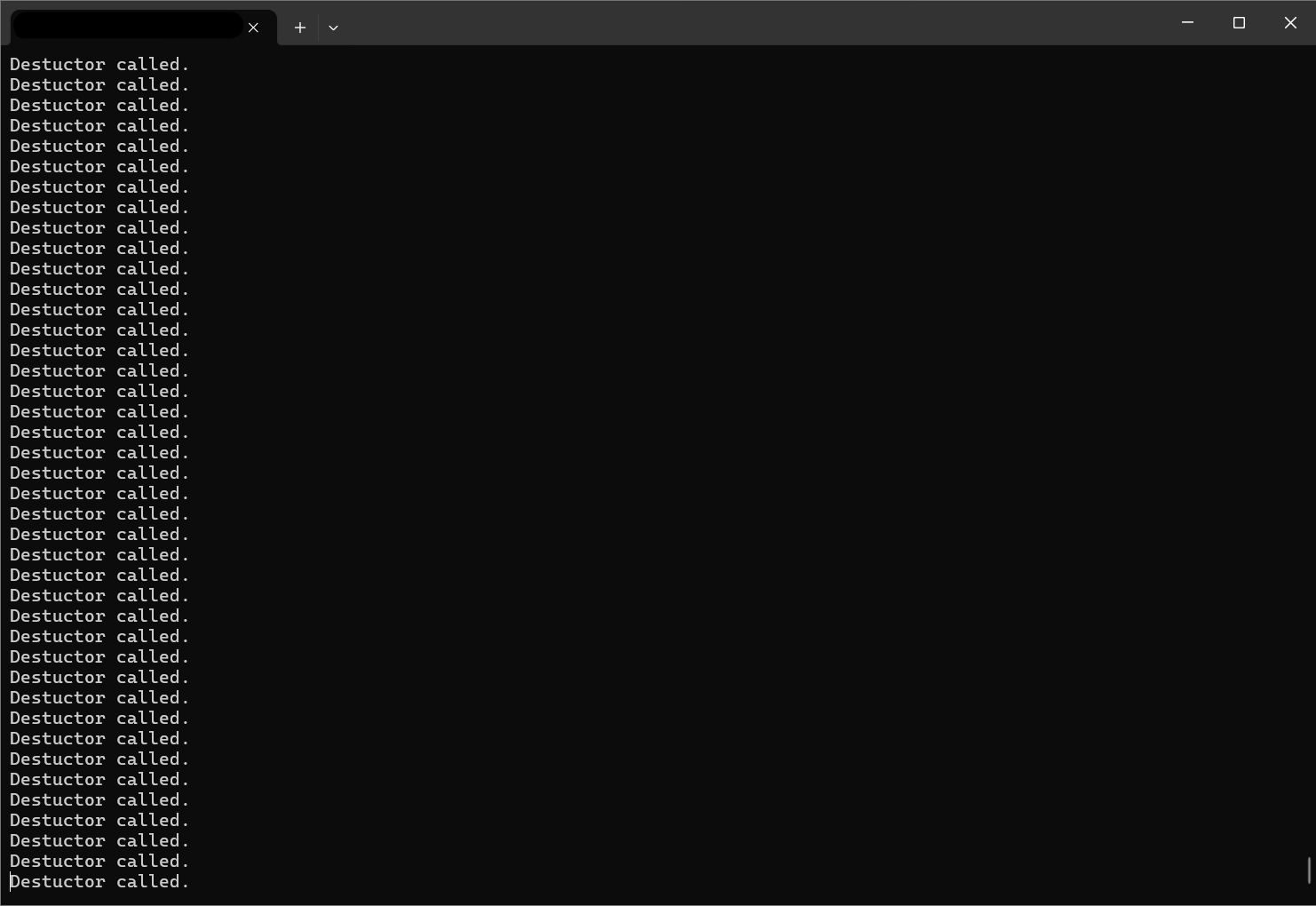
} 以上代码如果在return 0 这一行设置断点,那么执行结果就是这样的:

最后两行:“Point_0 of array2:25,30,Point_1 of array2:35,40”,pointsArray1数组的点(element(0),element(1))在移动以后,pointsArray2数组的点也跟在pointsArray1数组后面变化了,而且变化的坐标是一模一样的~
这就是因为,编译器自己生成的复制构造函数会无脑把两个数组放在同一个内存地址,并且编译器在调用move函数处理数据的时候,不是根据数组名称区分操作数据,而是根据数据的地址去操作数据,导致他把两个数组pointsArray1、pointsArray2的点统一搬到了(25,30),(35,40)~
而且,析构的时候会更要命,如果继续执行程序,那么大概率屏幕显示是这样的。首先pointsArray2的数据被析构,此时pointsArray1在同一内存地址的数据其实也被析构了,然后编译器不晓得两个数组都被析构了,还是去傻傻找pointsArray1的数据,导致了执行出错~
所以,在出现指针、数组、类、函数、地址引用、动态分配的资源这种依靠地址传参的数据类型,我们就不要把复制函数这种事情交给编译器了,而是需要构造复制函数,在函数里new一个对象(重新分配地址),就像这样~
ArrayOfPoints(const ArrayOfPoints& v) { // 深层复制构造函数
size = v.size;
points = new Point[size];
for (int i = 0; i < size; i++)
points[i] = v.points[i];
}AI提醒,为了实现真正的深层复制,还需要考虑类的赋值运算符的重载:首先要检查自赋值的情况(即一个对象赋值给它自己)。如果不做这样的检查,直接释放原有资源并重新分配,会导致对象在释放资源后无法正确访问其原有内容,从而引发问题~
ArrayOfPoints& ArrayOfPoints::operator=(const ArrayOfPoints& v) {
if (this != &v) {
delete[] points; // 释放原有资源
size = v.size;
points = new Point[size];
for (int i = 0; i < size; i++)
points[i] = v.points[i];
}
return *this;
}但是我暂时还没有学到类的赋值运算符重载,相关的知识点可能以后会慢慢补充~
🐋6.23 对象的移动构造
📇相关概念
这道题目比较无奈。代码的原意可能是想展示一下通过函数调用类的构造函数与类的函数,但是编译器经过了十年的更新,已经很机智了,可以绕过复制构造函数与移动构造函数,通过构造函数+析构函数就完成了代码的执行...
// 版本1,使用复制构造,构造1次,复制构造1次,析构2次(实际运行显示,调用构造1次,析构1次)
#include <iostream>
using namespace std;
class IntNum {
public:
IntNum(int x = 0) : xptr(new int(x)) { // 构造函数
cout << "Calling constructor..." << endl;
}
IntNum(const IntNum &n) : xptr(new int(*n.xptr)) { // 复制构造函数,构造一个新的int对象
cout << "Calling copy constructor..." << endl;
}
~IntNum() { // 析构函数
delete xptr;
cout << "Destructing..." << endl;
}
int getInt() { return *xptr; }
private:
int* xptr;
};
IntNum getNum() { // 返回值为IntNum类对象
IntNum a;
return a; // 在函数运行结束前,调用了拷贝构造函数
}
int main()
{
cout << getNum().getInt() << endl;
return 0;
}// 版本2,使用移动构造,构造1次,析构1次(实际运行显示,调用构造1次,析构1次)
#include <iostream>
using namespace std;
class IntNum {
public:
IntNum(int x = 0) : xptr(new int(x)) { // 构造函数
cout << "Calling constructor..." << endl;
}
IntNum(const IntNum& n) : xptr(new int(*n.xptr)) { // 复制构造函数,构造一个新的int对象
cout << "Calling copy constructor..." << endl;
}
IntNum(IntNum&& n) : xptr(n.xptr) { // 移动构造函数,实现浅层复制,其中&&是右值引用(即将消亡的值就是右值,函数的返回值就是右值)
n.xptr = nullptr; // 原来的对象置为空指针
cout << "Calling move constructor..." << endl;
}
~IntNum() { // 析构函数
delete xptr;
cout << "Destructing..." << endl;
}
int getInt() { return *xptr; }
private:
int* xptr;
};
IntNum getNum() { // 返回值为IntNum类对象
IntNum a;
return a; // 在函数运行结束前,调用了移动构造函数,理论是这样,但是实际发现人家并没有调用,不知道为什么...
}
int main()
{
cout << getNum().getInt() << endl;
return 0;
}询问AI,给到的回复是:
这主要是因为C++编译器进行了返回值优化(Return Value Optimization, RVO)或命名返回值优化(Named Return Value Optimization, NRVO)。这些优化技术允许编译器省略不必要的复制或移动操作,从而提高效率。
在你的第二个版本中,getNum()函数创建了一个名为a的局部对象,并试图返回它。在没有优化的情况下,这将涉及到复制或移动构造函数来创建一个新的对象来返回。但是,由于RVO或NRVO,编译器可以优化掉这个复制或移动操作。
具体来说,编译器可能会直接在getNum()的调用者(在这里是main()函数)中构造返回的对象,从而避免了复制或移动。这就是为什么你看不到移动构造函数的调用。
🐳字符串
🐋6.24 比较运算符与连接运算符
📇相关概念
C++的string类支持一些简单的操作,比如使用“+”来连接两个字符串,以及使用“>”、“<”、“==”、“>=”、“<=”来比较字符串的大小。比较规则是基于字符的ASCII值进行的。
#include <string>
#include <iostream>
using namespace std;
inline void test(const char* title, bool value) {
cout << title << " returns " << (value ? "true" : "false") << endl;
}
int main()
{
string s1 = "DEF";
cout << "s1 is " << s1 << endl;
string s2;
cout << "Please enter s2:";
cin >> s2;
cout << "length of s2:" << s2.length() << endl;
// 比较运算符的测试
test("s1 <= \"ABC\"", s1 <= "ABC");
test("\"DEF\" <= s1", "DEF" <= s1); // 注意这里使用了C++14的字面量操作符""s来构造string对象进行比较
// 或者显式地构造string对象进行比较(适用于所有C++版本)
// test("\"DEF\" <= s1", string("DEF") <= s1);
// 连接运算符的测试
s2 += s1;
cout << "s2 = s2 + s1:" << s2 << endl;
cout << "length of s2:" << s2.length() << endl;
return 0;
}例如以上代码,输入 ABC 的执行结果为:

🐋6.25 C风格的字符串
祖传代码可能也会出现用char型数组存放C风格字符串(虽然现在用C++的程序员绝大多数都不会这样写),不过注意,C风格字符串的存储需要以\0结尾~
#include <iostream>
using namespace std;
void F() {
//char str[7] = { 'p', 'r', 'o', 'g', 'r', 'a', 'm' }; // 没有 \0,会输出program烫烫烫烫烫烫烫烫烫烫烫烫烫烫蘚
char str[8] = { 'p', 'r', 'o', 'g', 'r', 'a', 'm', '\0' };
std::cout << str << std::endl;
}
int main() {
F();
return 0;
}相比之下,C++调用string类这么写就可以了~
#include <iostream>
#include <string>
using namespace std;
void F() {
string str = "program";
std::cout << str << std::endl;
}
int main() {
F();
return 0;
}🐋6.26 用getline输入字符串
以下代码的功能是根据输入的 城市 国家,分别显示输出数据:
#include <iostream>
#include <string>
using namespace std;
int main()
{
for (int i = 0; i < 2; i++) {
string city, state;
getline(cin, city, ','); // (cin)从键盘读入(city)字符串,逗号是分隔符
getline(cin, state); // 没有给出分隔符时,默认以行结束为分隔符
cout << "City:" << city << " State:" << state << endl;
}
return 0;
}输入shanghai,china,输出的结果是:

getline按行执行,每次允许用户输入一行,getline函数会读取数据直到遇到指定的分隔符(在第一个调用中是逗号),或直到达到行尾(在第二个调用中);这意味着如果用户在同一行中输入多个逗号分隔的值,第一个getline只会读取到第一个逗号为止。
🔚结语
博文到此终于结束了,第一次写2.7w字的笔记,打字页面已经卡顿得让我回忆起十几年前打网页游戏中人影都加载不全,世界频道总有人在刷屏“KAAAA”的时代...🫥🫥
总之,写得模糊或者有误之处,期待小伙伴留言讨论与批评,督促博主优化内容{例如有错误、难理解、不简洁、缺功能}等,博主会顶锅前来修改~~😶🌫️😶🌫️
我是梅头脑,本片博文若有帮助,欢迎小伙伴动动可爱的小手默默给个赞支持一下,感谢点赞小伙伴对于博主的支持~~🌟🌟
同系列的博文:🌸数据结构_梅头脑_的博客-CSDN博客
同系列的博文:🌸容器_梅头脑_的博客-CSDN博客
同系列的博文:🌸字符串_梅头脑_的博客-CSDN博客
同博主的博文:🌸随笔03 笔记整理-CSDN博客