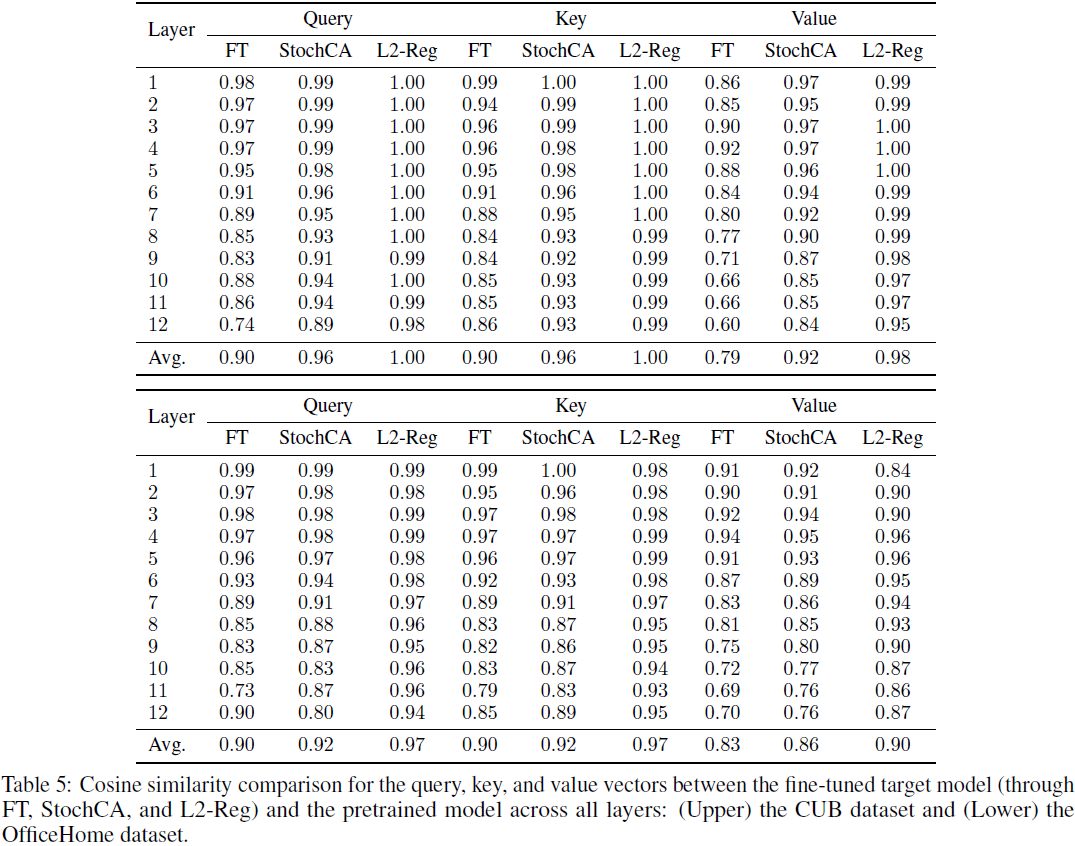
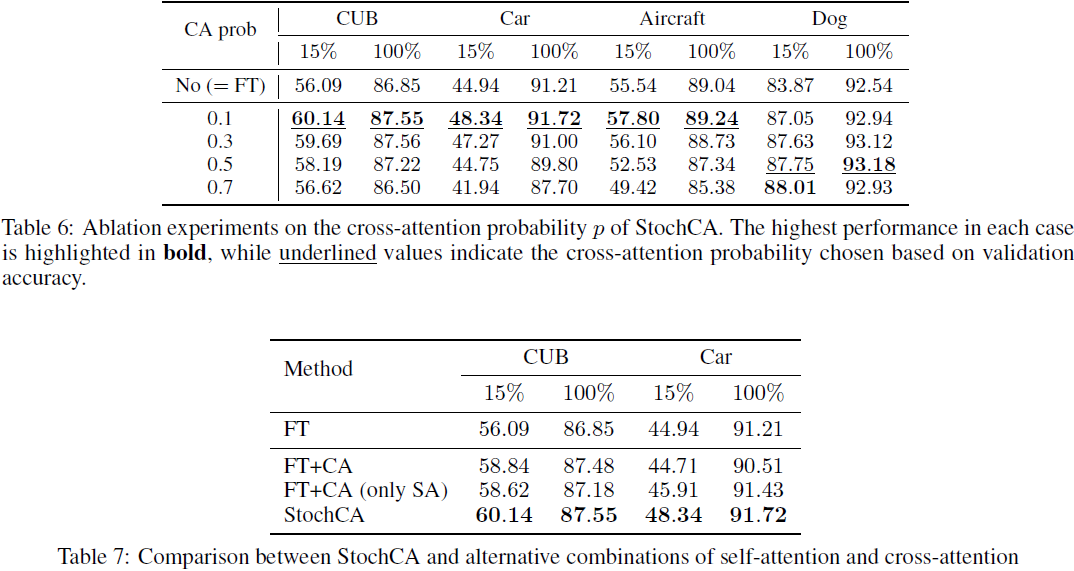
StochCA: A Novel Approach for Exploiting Pretrained Models with Cross-Attention

公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
0. 摘要
3. 方法
3.1 问题陈述
3.1.1 迁移学习
3.1.2 领域泛化
3.2 Vision Transformer 的自注意力机制
3.3 随机交叉注意力
4. 实验
0. 摘要
利用大规模预训练模型是增强在各种目标任务上性能的一种众所周知的策略。通常通过对目标任务进行预训练模型的微调来实现。然而,朴素的微调可能无法充分利用预训练模型中嵌入的知识。在这项研究中,我们引入了一种新颖的微调方法,称为随机交叉注意力(stochastic cross-attention,StochCA),专用于 Transformer 架构。该方法修改了 Transformer 的自注意机制,以在微调期间有选择地利用预训练模型的知识。具体而言,在每个块中,不是进行自注意,而是根据预定义的概率随机执行交叉注意力,其中 key 和 value 从预训练模型的相应块中提取。通过这样做,目标模型的 query 和通道混合多层感知器层(channel-mixing multi-layer perceptron layers)被微调到目标任务,从而学会有效地利用预训练模型的丰富表示。为验证 StochCA 的有效性,在迁移学习和领域泛化领域进行了大量实验,其中对预训练模型的利用至关重要。我们的实验结果显示 StochCA 在这两个领域中优于最先进的方法。此外,我们证明了 StochCA 与现有方法是互补的,即可以与它们结合以进一步提高性能。
项目页面:https://github.com/daintlab/stochastic_cross_attention
3. 方法
3.1 问题陈述
3.1.1 迁移学习
由于我们专注于分类任务,一个网络 f 由特征提取器 F 和分类器 C 组成。给定一个在大规模源数据集
![]()
上进行预训练的模型 f_0,迁移学习的目标是通过使用目标数据集
![]()
进行微调,以在目标任务上表现良好的模型 f_t。在迁移学习的背景下,Ds 和 Dt 通常共享相似的输入空间,但在类别空间上存在差异。例如,在计算机视觉任务中,Ds 通常代表大规模数据集,如 ImageNet [36],而 Dt 是指感兴趣的特定视觉分类数据集 [28]。鉴于 Ds 和 Dt 的标签空间不同,预训练模型 f0 不能直接应用于目标数据集 Dt。为解决这个问题,f0 的任务特定模块(即分类器 C)被替换为一个新的分类器 C',该分类器是随机初始化的,并且专门定制以适应目标任务的标签空间。然后,配备有目标特定分类器 C' 的 f0 的特征提取器 F 进行微调,以获得目标模型 f∗:
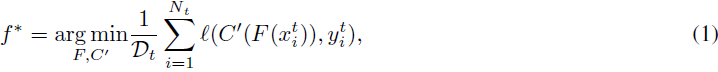
其中 ℓ(·, ·) 是诸如交叉熵之类的损失函数。
3.1.2 领域泛化
在领域泛化中,用于目标任务的数据集由多个领域组成。设 Ds = {D1,D2, ...,Dn} 为源领域,其中每个 Dk 代表一个包含
![]()
的领域。领域泛化的目标是通过仅访问源领域来训练在未见过的目标领域
![]()
上表现良好的模型。与迁移学习不同,Ds 和 Dt 都共享相同的标签空间,但由于领域漂移(例如图像风格的变化)等原因,它们在输入分布上存在差异。在领域泛化的训练过程中,不能访问来自特定目标领域 Dt 的数据:模型只能使用来自源领域 Ds 的数据。因此,对于模型来说,学习包含跨所有源领域共享的基础知识的领域不变表示是至关重要的。 类似于迁移学习,通常使用在大规模数据集(如 ImageNet [36])上预训练的模型 f0 作为起点。然后,将这个预训练模型进一步训练到 Ds 以适应领域泛化任务。领域泛化的普通微调的目标是优化模型参数,以最小化所有源领域上的损失值,可以表示为:
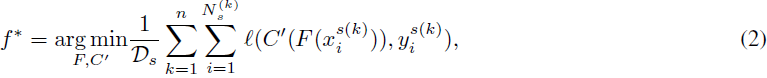
其中,ℓ(·, ·) 代表损失函数,如交叉熵。
3.2 Vision Transformer 的自注意力机制
自注意力(Self-Attention,SA)模块是 ViT 中的关键组成部分,负责捕捉图像补丁(patch)之间的长程依赖关系。这通过为图像中不同的空间位置(即图像补丁)分配重要性权重来实现,使模型能够在训练过程中专注于相关特征。通过利用自注意力,ViT 能够有效地建模图像补丁之间的关系,并在各种计算机视觉任务中取得了最先进的性能。 考虑 X ∈ R^(n×d) 作为 SA 层的输入序列,其中 n 表示 token 数量,d 是隐藏(hidden)维度。query Q ∈ R^(n×d_q),key K ∈ R^(n×d_k) 和 value V ∈ R^(n×d_v) 分别定义并处理如下:
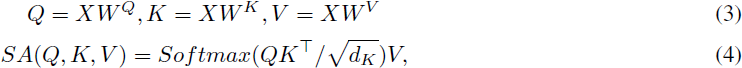
其中 W^Q ∈ R^(d×dq),W^K ∈ R^(d×dk) 和 W^V ∈ R^(d×dv) 分别是计算 Q、K 和 V 的权重矩阵。为简化说明,此解释考虑单头自注意力,其中 d_q = d_k = d_v = d。因此,自注意力模块通过从相同输入生成 query、key 和 value,学会在输入序列内部聚焦。
3.3 随机交叉注意力
自注意力模块的一个特点是查询、键和值(query、key 和 value)是从相同的输入序列 X 导出的。相反,交叉注意力(Cross-Attention,CA)已被应用于各种研究中,通过从不同的输入计算 query、key 和 value,使其适用于特定应用 [31, 32, 33, 34, 35, 23]。在这项工作中,我们利用交叉注意力在训练给定目标任务时有选择地访问大规模预训练模型中的相关知识。 设 f 表示正在训练的目标模型,f0 是目标模型参考的预训练模型。我们假设目标和预训练模型共享相同的架构。用于在第 l 层自注意力中引用预训练模型特征的交叉注意力机制计算如下:
![]()
其中 Qlf 是从目标模型 f 的第 l 层注意力中获得的 query,而 Klf0 和 Vlf0 是从预训练模型 f0 的第 l 层注意力中的 key 和 value。通过这种交叉注意力,目标模型 f 的查询学会有效地从预训练模型 f0 的键和值中提取与目标任务相关的有用信息。因此,它使目标模型 f 有选择地利用嵌入在预训练模型 f0 中的知识。基于这些表示,目标模型中的 MLP 层被微调,重点学习与目标任务特别相关的通道混合策略。图 1 描绘了带有预训练模型的自注意力和交叉注意力的过程,提供了这些概念的可视化表示。
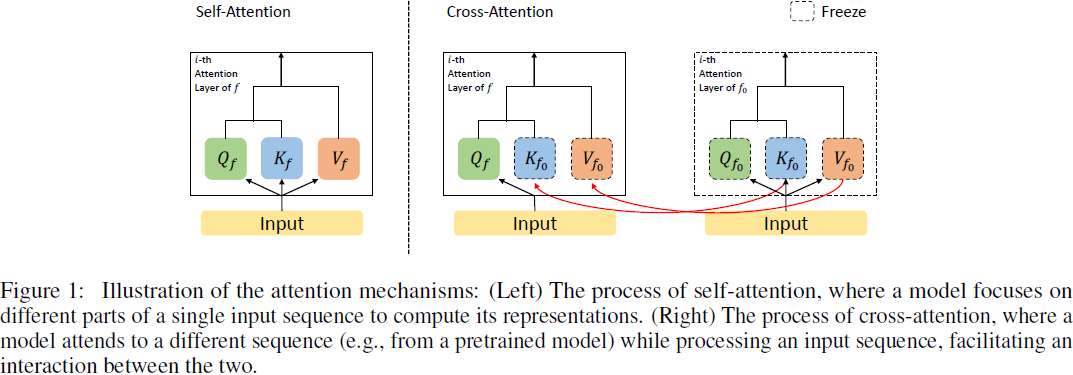
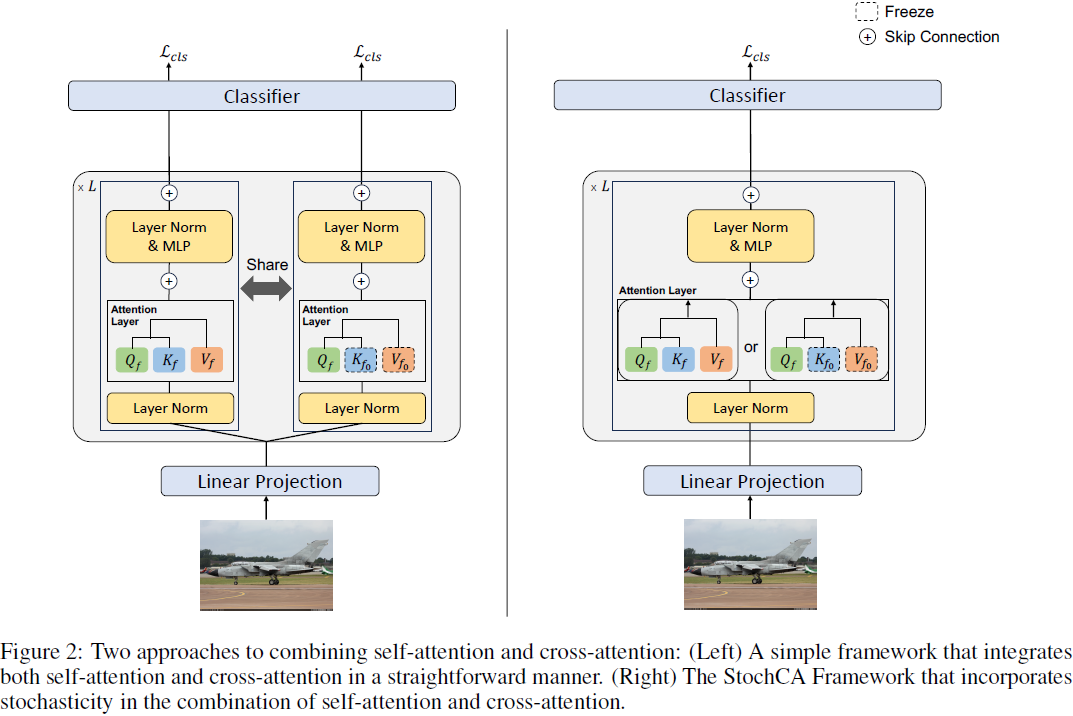
然而,如果目标模型 f 中的所有自注意力层都被交叉注意力替换,由于过度依赖预训练模型 f0,可能导致对目标任务的学习不足。为了平衡这一点,需要适当地同时利用自注意力和交叉注意力。一种简单的方法如图 2(左侧)所示,涉及在每个注意力层中同时执行自注意力和交叉注意力,最终预测是来自两个路径的输出的平均值。然而,这种方法在推断期间需要使用预训练模型进行交叉注意力路径,从而增加内存和计算需求。此外,它要求每个图像进行双重传播(分别用于自注意力和交叉注意力路径),导致训练过程中的计算成本增加。
为增强计算效率,我们提出了块级随机交叉注意力(StochCA)方法,该方法有选择地引用预训练模型的表示。在 StochCA 中,目标模型 f 的每个注意力层都被分配一个概率 p,用于执行交叉注意力。根据此概率,模型在每个训练步骤中随机选择执行自注意力或交叉注意力。具体而言,第 l 层注意力的输出计算如下:
![]()
其中 β 是伯努利分布概率为 p 的随机变量。与普通的 ViT 相比,每个注意力层在每个训练步骤中以概率 p 而不是总是执行自注意力,因此在每个注意力层中以概率 p 随机执行交叉注意力。在推断期间,不再需要预训练模型 f0,并且仅使用通过自注意力计算的输出进行最终预测(即 p = 0),从而避免了额外的计算需求。超参数 p 调整目标模型对 f0 的依赖性。StochCA 的整体框架如图 2(右侧)所示,并在算法 1 中详细描述。

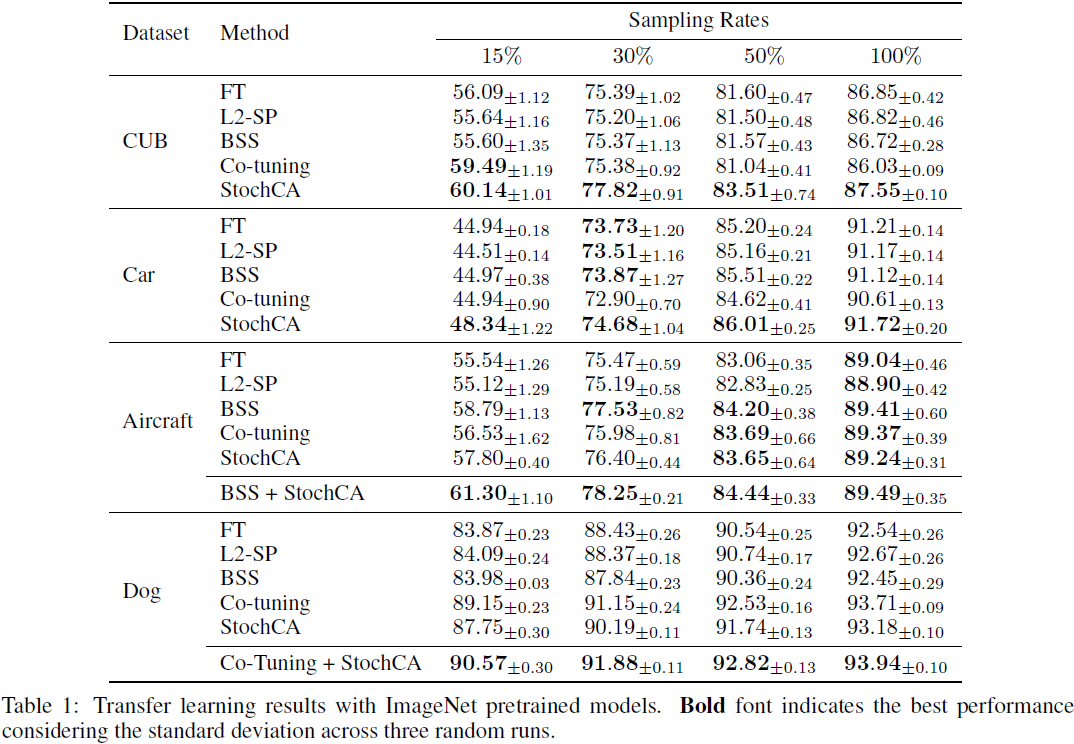
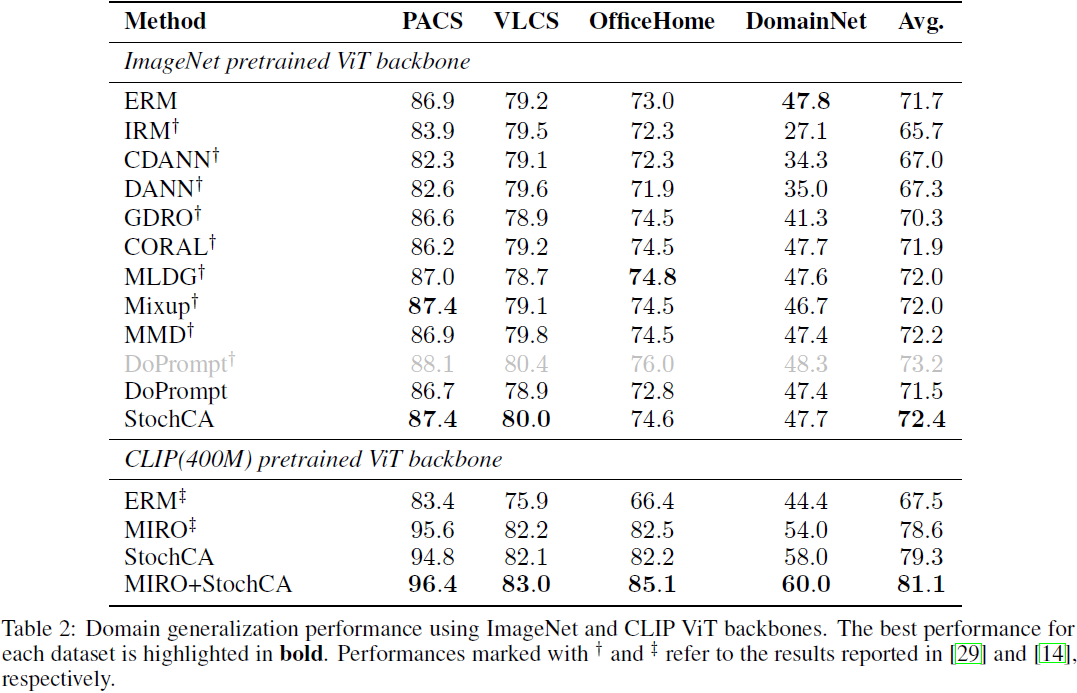
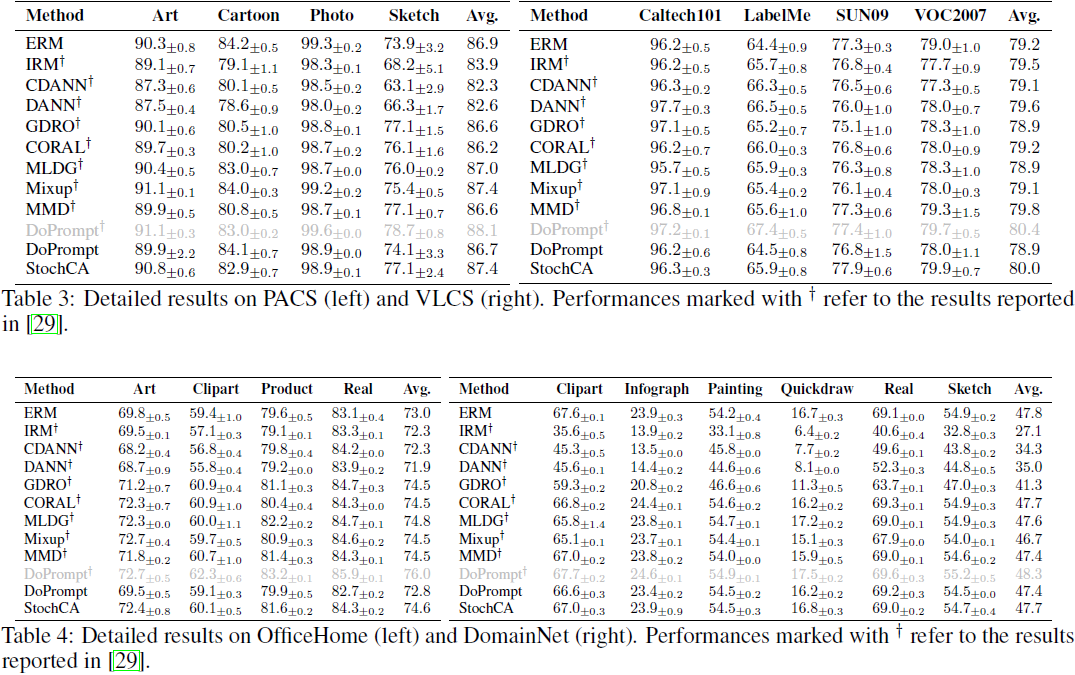
4. 实验