import requests
import time
import csv
f = open('小红书评论.csv',mode = 'a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=['内容','点赞数量','发布时间','昵称','头像链接','用户id'])
csv_writer.writeheader()
def spider(url):
headers = {
"Cookie":"abRequestId=5f54ec59-544b-52c0-b01d-62d56402dd95; webBuild=4.3.7; xsecappid=xhs-pc-web; a1=18e0498a02cmjc4tzjhx0oil63new9kjrehuuqtkh50000105941; webId=a640f94763a3e178d4f030bdf060b231; websectiga=29098a4cf41f76ee3f8db19051aaa60c0fc7c5e305572fec762da32d457d76ae; sec_poison_id=cebf9dc6-c4ca-45ad-9630-1db3121f1fcc; gid=yYd84jY0YDF2yYd84jY08dA9JS6VS49uVxC8xTxl31KqI728dEjTV7888y82j4y8fDjjDDS8; unread={%22ub%22:%2265c2bd1d0000000008020eb8%22%2C%22ue%22:%2265dbe0660000000007025c7c%22%2C%22uc%22:29}; cache_feeds=[]; web_session=040069b11b6dee561a0637c9d1374b217e6e5a",
"Accept":"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers).json()
return response
def get_time(ctime):
timeArray = time.localtime(int(ctime/1000))
otherStyleTime = time.strftime("%Y.%m.%d",timeArray)
return str(otherStyleTime)
def get_sub_comments(note_id,root_comment_id,sub_comment_cursor):
while True:
url = f"https://edith.xiaohongshu.com/api/sns/web/v2/comment/sub/page?note_id={note_id}&root_comment_id={root_comment_id}&num=10&cursor={sub_comment_cursor}&image_formats=jpg,webp,avif"
time.sleep(1)
sub_comment_data = spider(url)
for index in sub_comment_data['data']['comments']:
dit_1 = {
'内容': index['content'].strip(),
'点赞数量': index['like_count'],
'发布时间': get_time(index['create_time']),
'昵称': index['user_info']['nickname'].strip(),
'头像链接': index['user_info']['image'],
'用户id': index['user_info']['user_id'],
}
print(dit_1)
csv_writer.writerow(dit_1)
if not sub_comment_data['data']['has_more']:
break
sub_comment_cursor = sub_comment_data['data']['cursor']
def get_comments(note_id):
cursor = ''
page = 0
while True:
time.sleep(1)
url = f"https://edith.xiaohongshu.com/api/sns/web/v2/comment/page?note_id={note_id}&cursor={cursor}&top_comment_id=&image_formats=jpg,webp,avif"
json_data = spider(url)
for index in json_data['data']['comments']:
dit = {
'内容':index['content'].strip(),
'点赞数量':index['like_count'],
'发布时间':get_time(index['create_time']),
'昵称':index['user_info']['nickname'].strip(),
'头像链接': index['user_info']['image'],
'用户id': index['user_info']['user_id'],
}
print(dit)
csv_writer.writerow(dit)
print('正在打印副评论:')
get_sub_comments(note_id,index['id'],index['sub_comment_cursor'])
if not json_data['data']['has_more']:
break
cursor = json_data['data']['cursor']
page = page+1
print(f'正在打印第{page}页数据:--------------------------------------')
get_comments("65ad0ecf000000000c004941")结果展现:
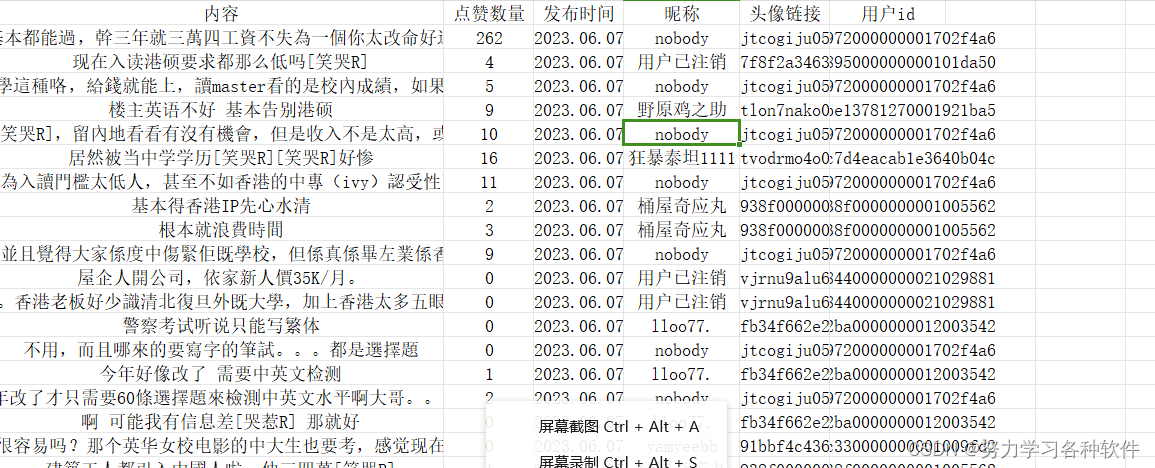
总结:
学到了如何处理时间戳函数
将时间戳变成正常时间函数:
def get_time(ctime): # ctime为爬取到的时间戳
timeArray = time.localtime(int(ctime/1000))
otherStyleTime = time.strftime("%Y.%m.%d",timeArray)
return str(otherStyleTime)









![[环境配置]ssh连接报错“kex_exchange_identification: read: Connection reset by peer”](https://img-blog.csdnimg.cn/img_convert/4fdcb21f62feda4e197867c0bda7eeeb.png)