准备工作
Xshell安装包
Xftp7安装包
虚拟机安装包
Ubuntu镜像源文件
Hadoop包
![]()
Java包
![]()
一、安装虚拟机


创建ubuntu系统
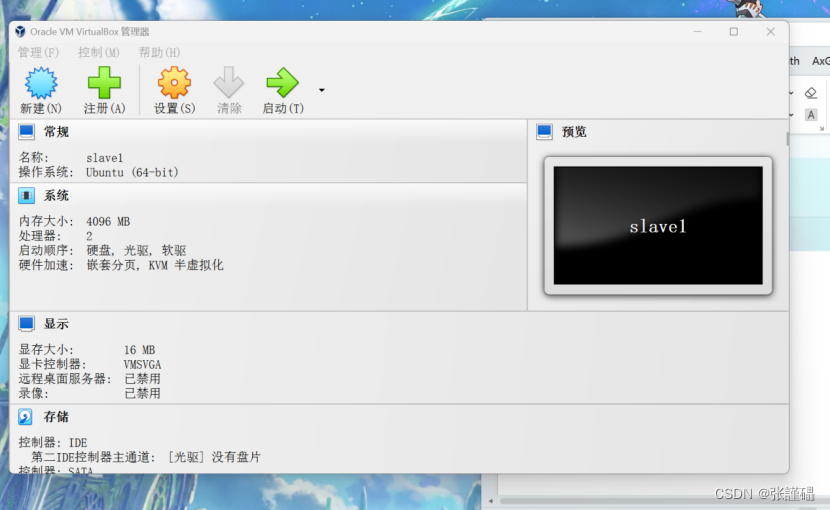

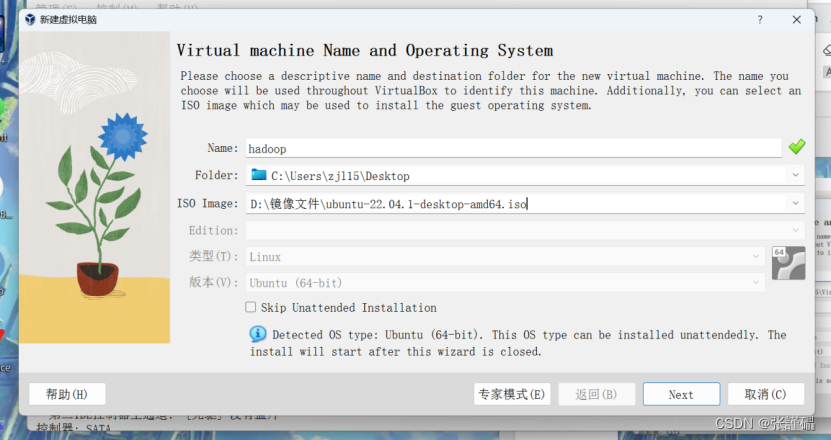


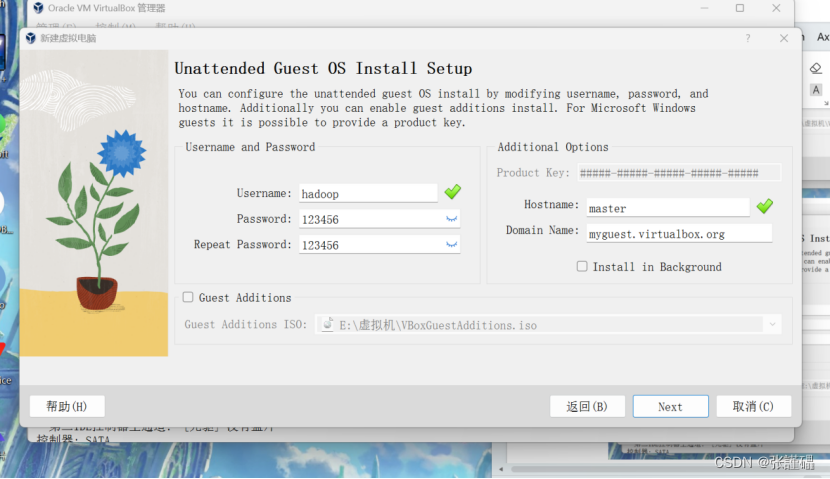
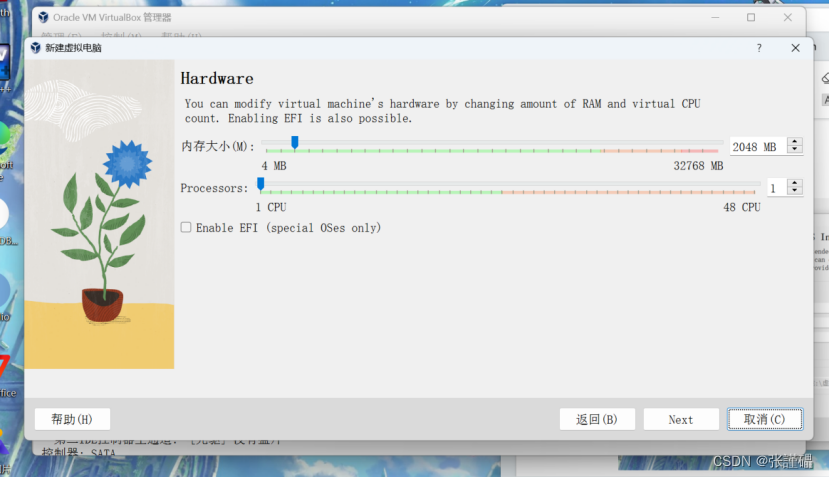
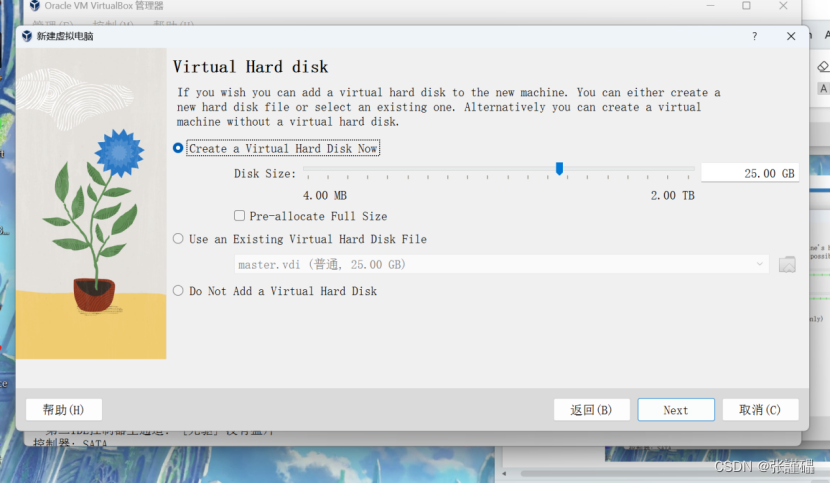
完成之后会弹出一个新的窗口



跑完之后会重启一下
按住首先用ctrl+alt+f3进入命令界面,输入root,密码登录管理员账号
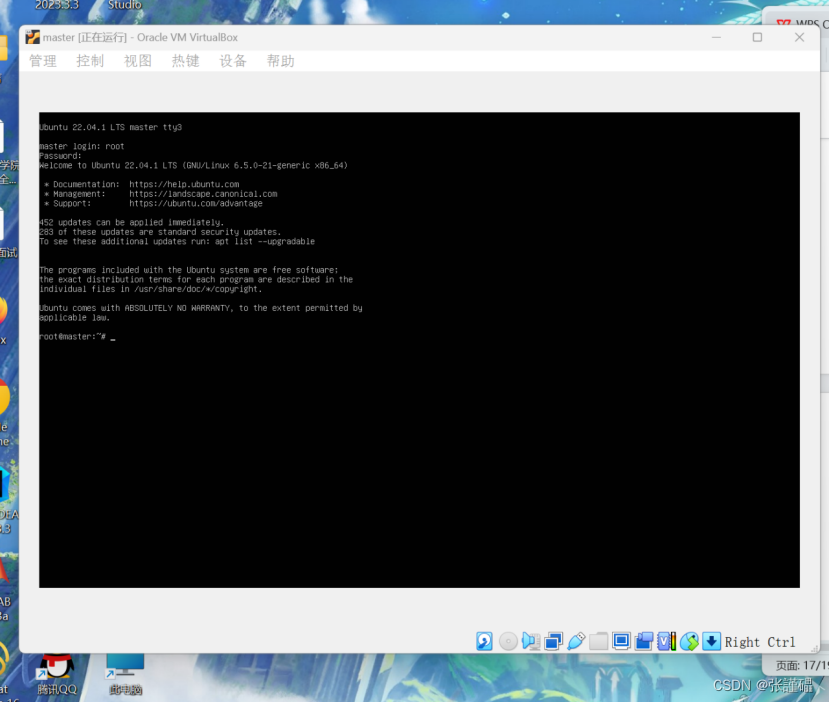


按Esc
然后输入
:wq
冒号也要输入
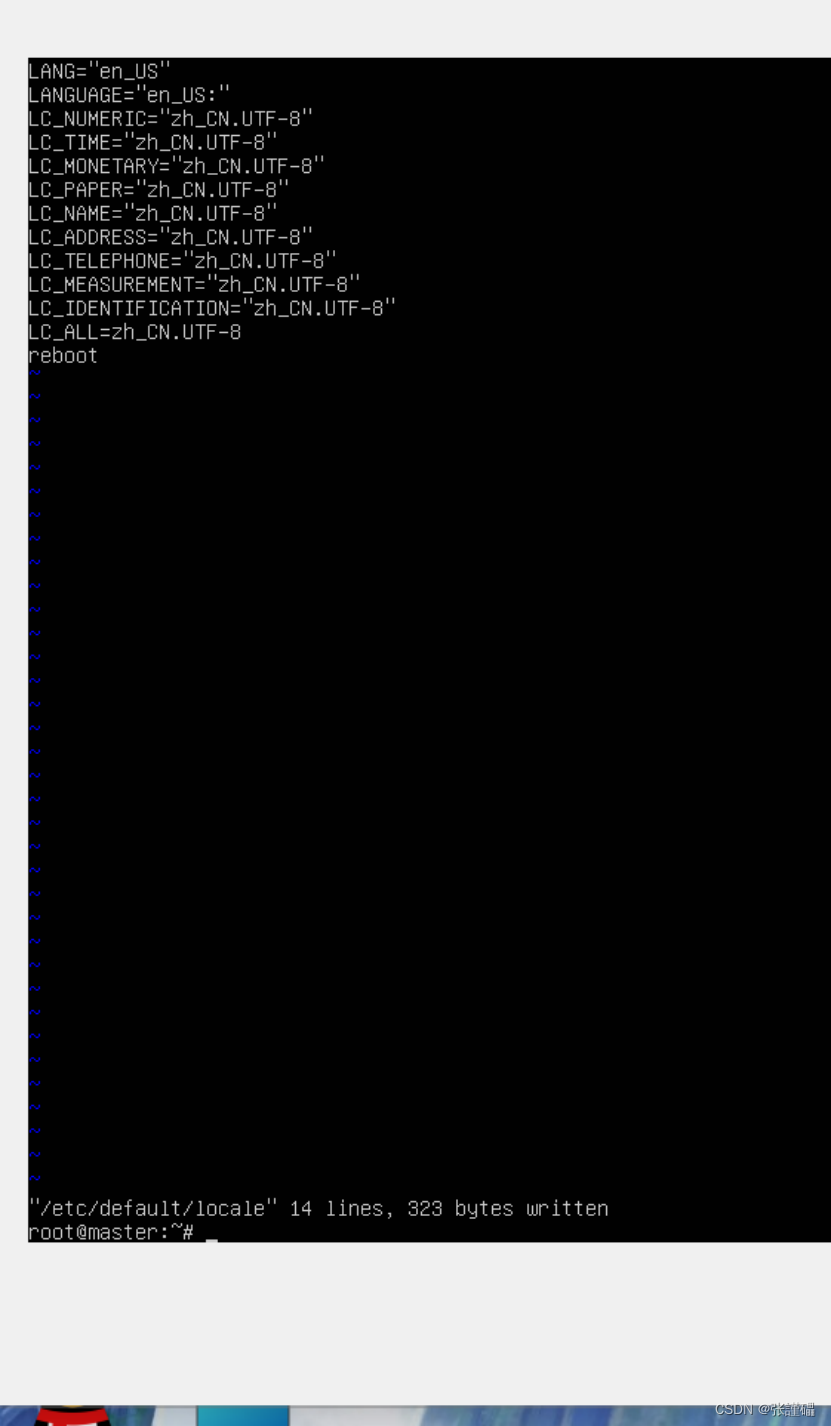
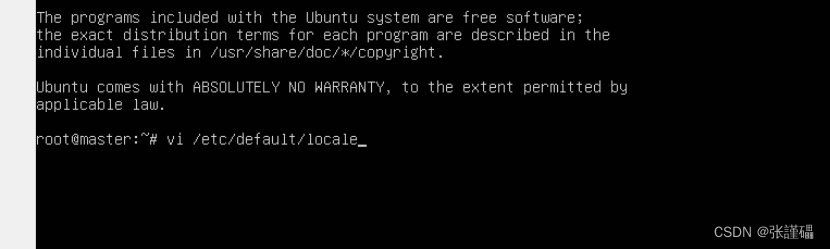
然后找到语言文件
vi /etc/default/locale最后一行加上以下语句后保存
LC_ALL=zh_CN.UTF-8
reboot完成之后
在按ctrl+alt+f1进入图形界面
配置完成之后先关闭虚拟机
先配置网络结构
点击设置
之后点击网络

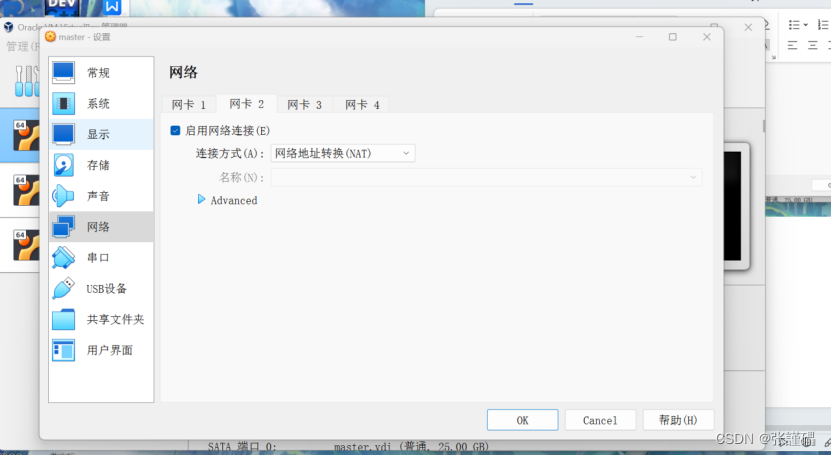
修改完网络配置之后在重启ubuntu

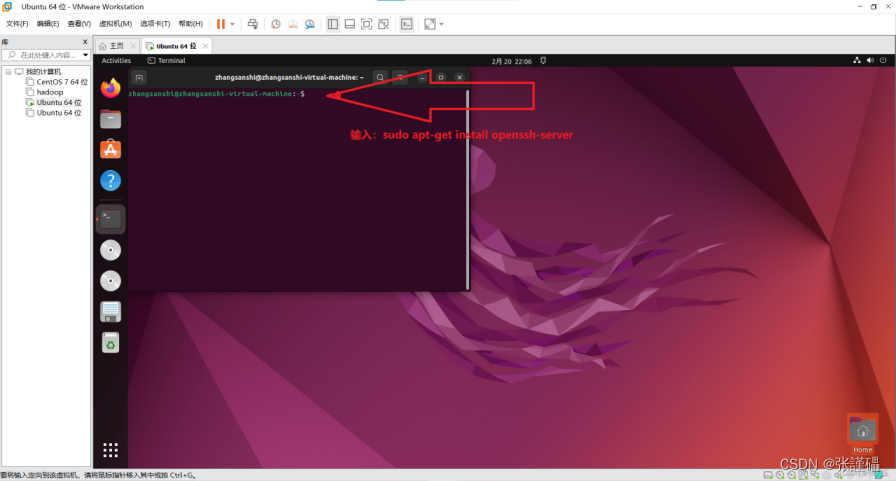
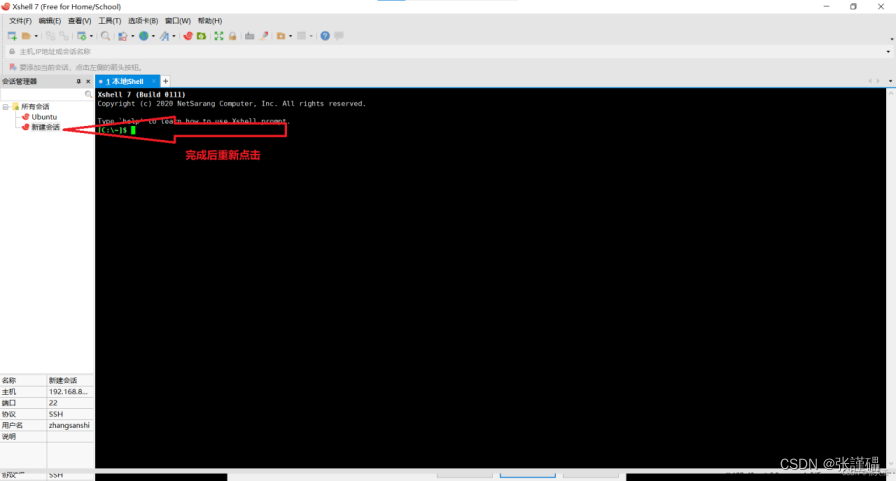
连接Xshell
说明:需要提前先安装好 Xshell 和 Xftp
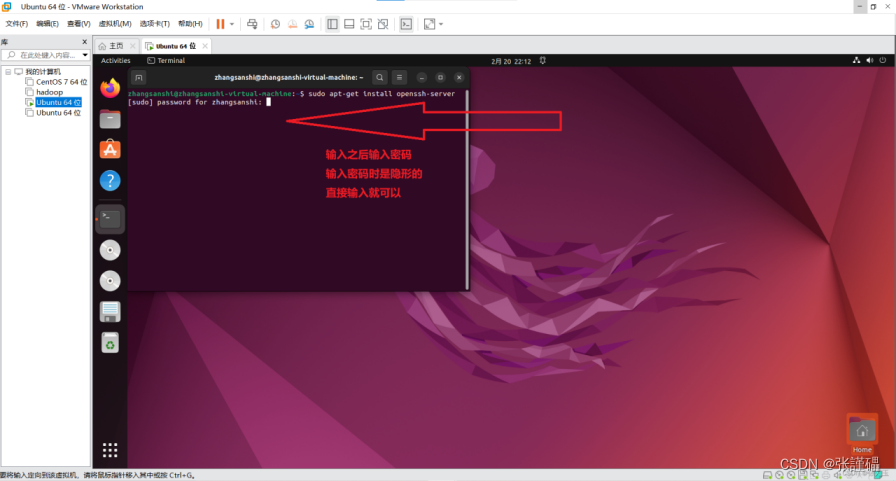
输入之后,可能中间会中断一次,不要担心,按enter继续就可以了


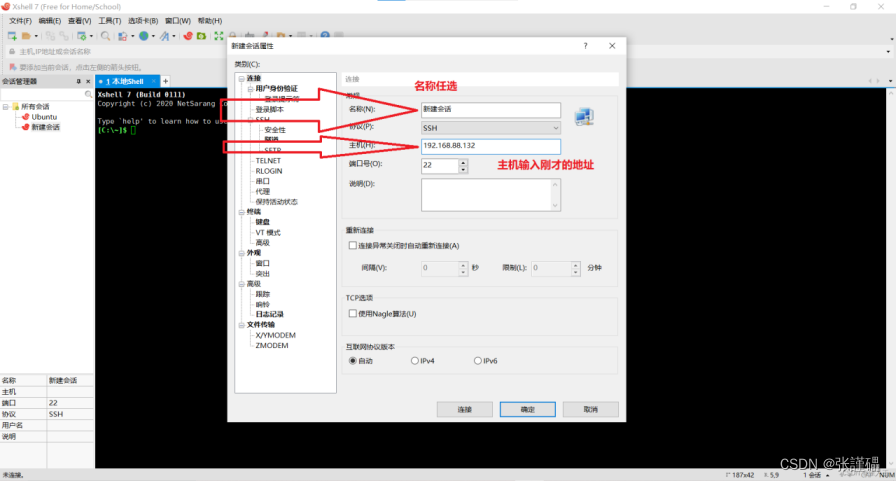
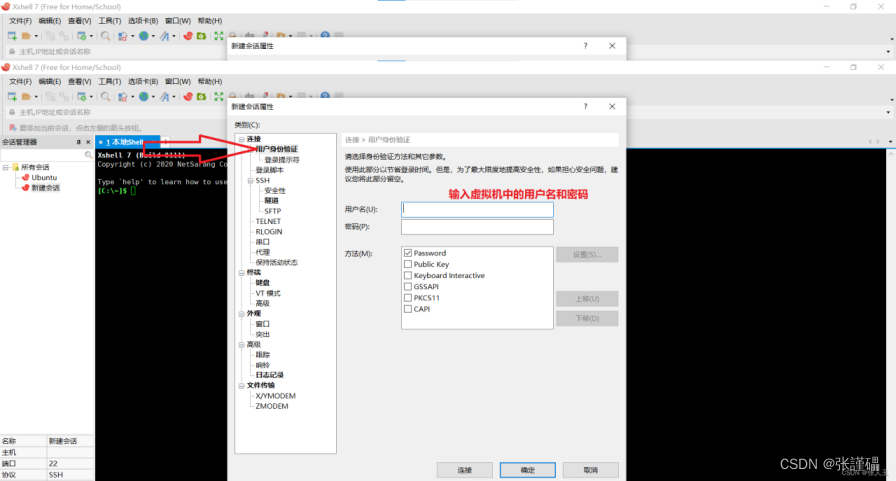

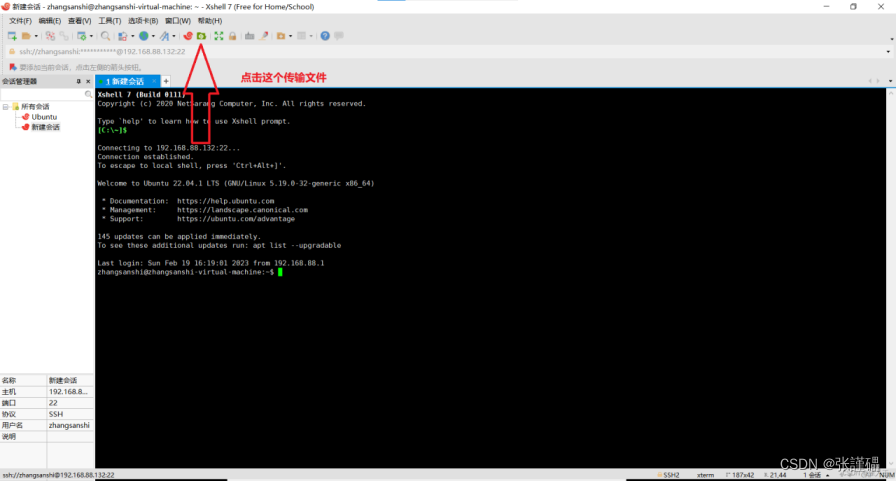
编辑

将 jdk的包(Linux版)
Hadoop的镜像文件(Hadoop的包)
![]()
eclipse(linux版)
![]()
这几个包从winws转到虚拟机中
开始下一步操作
设置 hostname(3 个虚拟机都设置)
hostname 设置计划
主节点:master
从节点 1:slave1
从节点 2:slave2
切换到 root 用户
su - //切换root用户
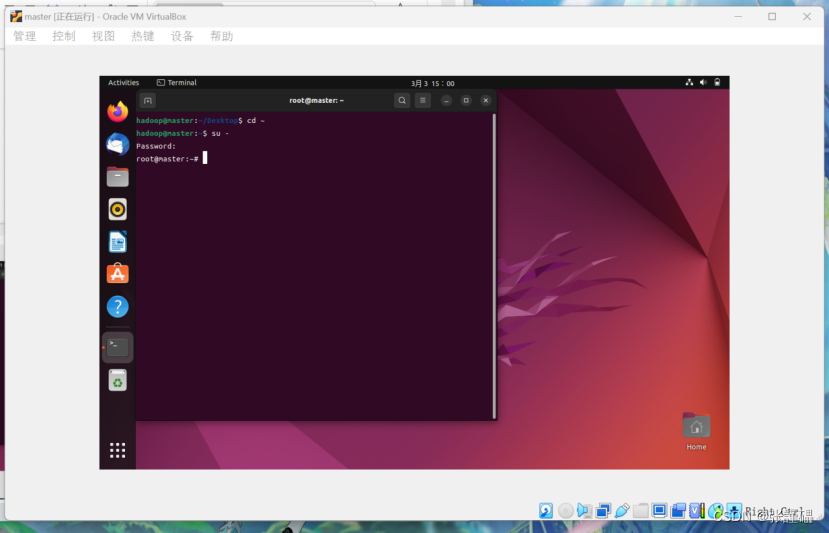
修改 hostname
vi /etc/hostname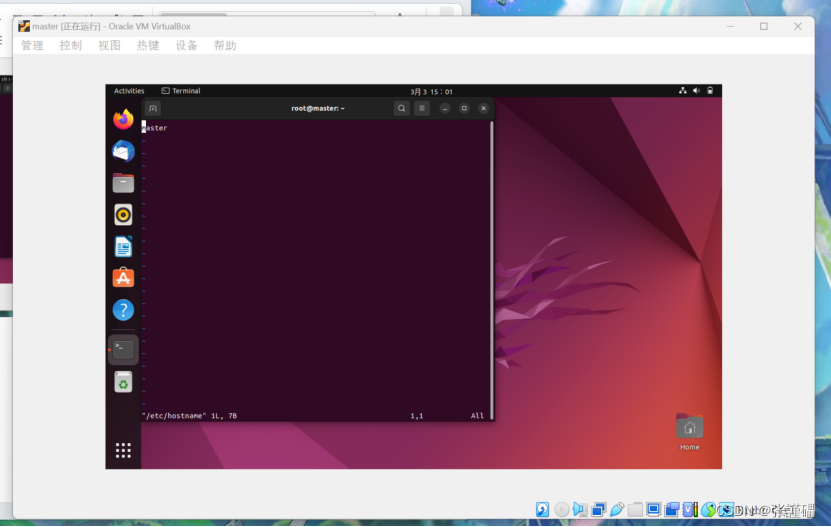
删掉原有内容,写入:master
按ESC
输入 :wq 分号也要输入
重启后显示新的 hostname
切换到hadoop用户
su hadoop允许hadoop用户使用超级权限(superprivileges,也称root权限)
注意:默认情况下,不允许普通用户使用超级权限,如果以sudo
作为开头输入指令,会出现如下提示,告知当前用户不在允许使用超级权限的文件内。
需要将当前用户添加到sudoers文件中。
切换到root用户
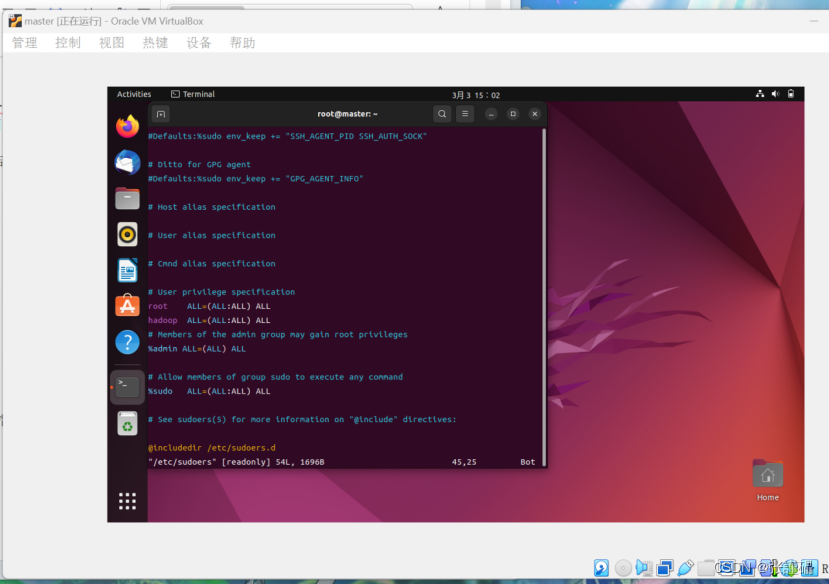
su -编辑/etc/sudoers文件
vi /etc/sudoers移动到文件底部,在rootALL=(ALL) ALL下添加:
[username]ALL=(ALL) ALL
添加后强制保存:wq! 退出。使用exit指令退出root用户(会返回到hadoop用户)
exit
4. 关闭防火墙(3个虚拟机都设置)
查看防火墙运行状态,返回running表示防火墙正在运行中。
sudo ufw status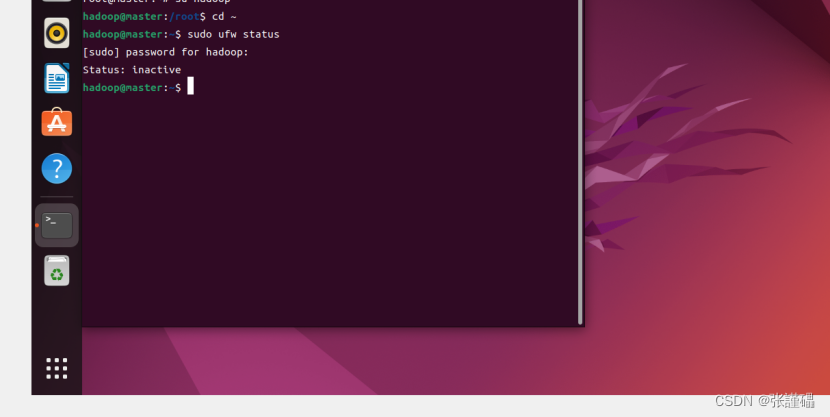
临时关闭防火墙(系统重启后防火墙又会自动启动)
sudo systemctl stop ufw.service需要禁止防火墙自动启动(永久关闭)
sudo systemctl disable ufw.service查看防火墙运行状态,返回running表示防火墙正在运行中。
sudo ufw status如果终端输出“Status: inactive”,则表示防火墙已成功关闭。

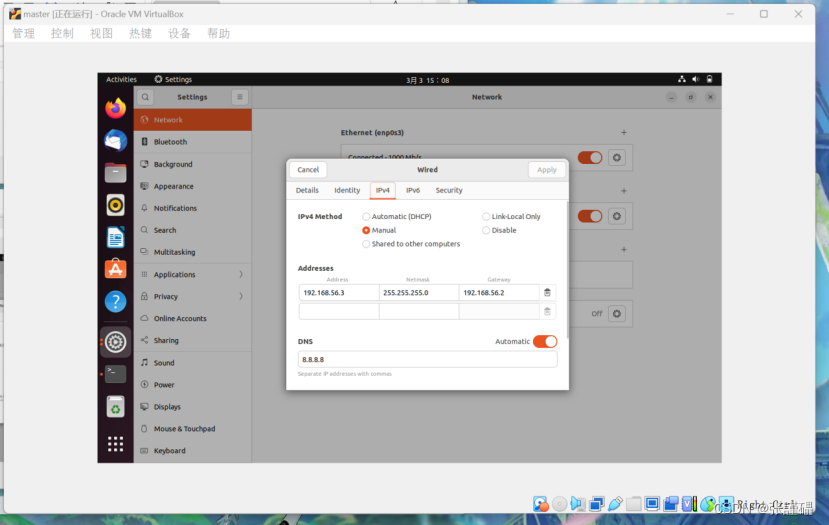
(5)设置IP地址(3个虚拟机都设置)
注意:网段必须与VMnet8子网IP的网段保持一致,网段中xxx.xxx.xxx.1和xxx.xxx.xxx.2(网关(GATEWAY))这两个地址不能使用。例:本机的VMnet8网段为192.168.56.0,则192.168.56.1和192.168.56.2不能使用。可选的IP地址范围为:192.168.56.3-192.168.56.255。
IP地址分配计划
master 192.168.56.3
slave1 192.168.56.4
slave2 192.168.56.5
有命令和窗口页面两种操作方式
窗口页面操作
点击设置(setting)
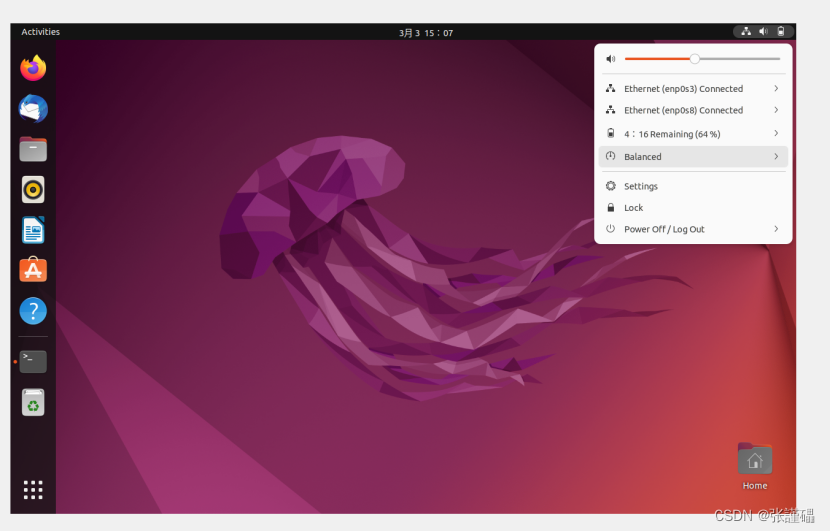

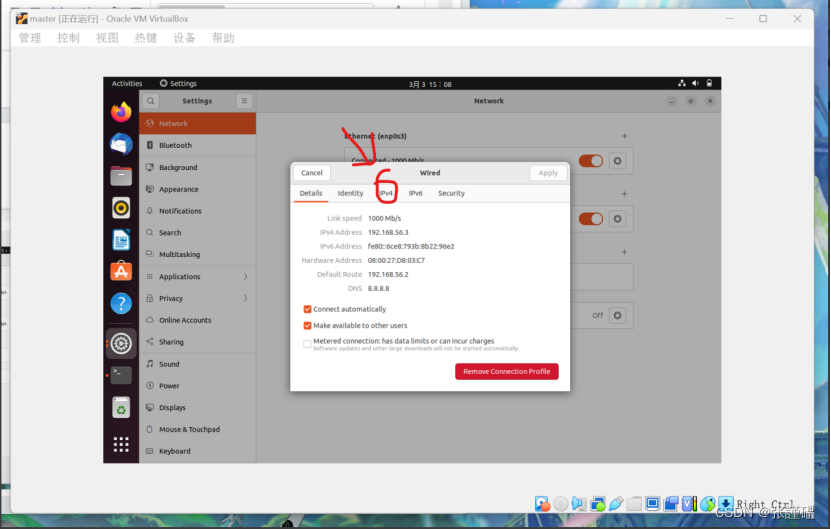
按照下面的图片内容填写
查看IP地址
ip addr show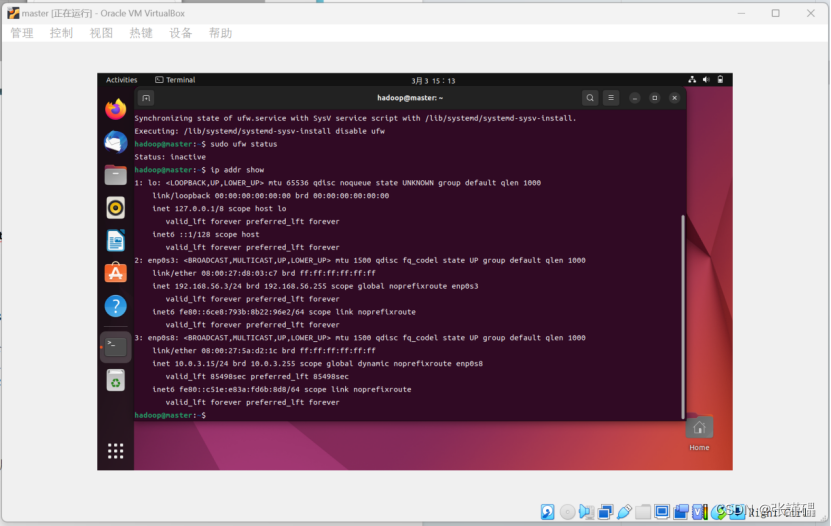
6)设置每台主机hostname到IP的映射关系3个虚拟机都设置)
sudo vi /etc/hosts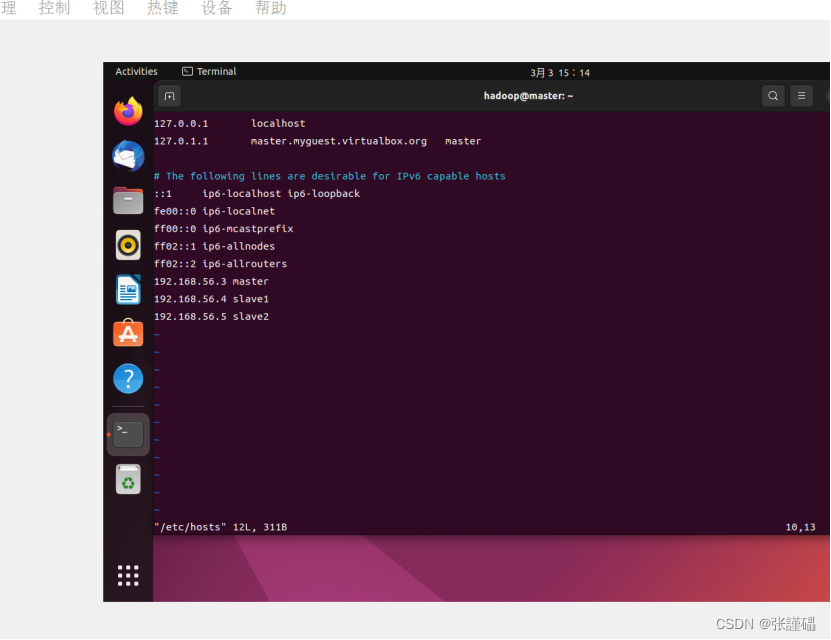
(在配置文件中追加3行
192.168.126.3 master
192.168.126.4 slave1
192.168.126.5 slave2
测试hostname是否可用
sudo vi /etc/hosts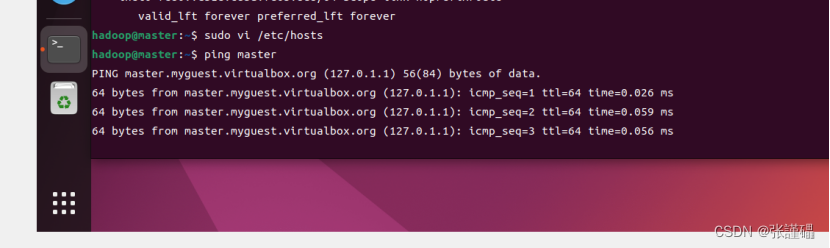
终止按钮
ctrl c

配置SSH免密登录
(1)生成秘钥对
ssh-keygen -t rsa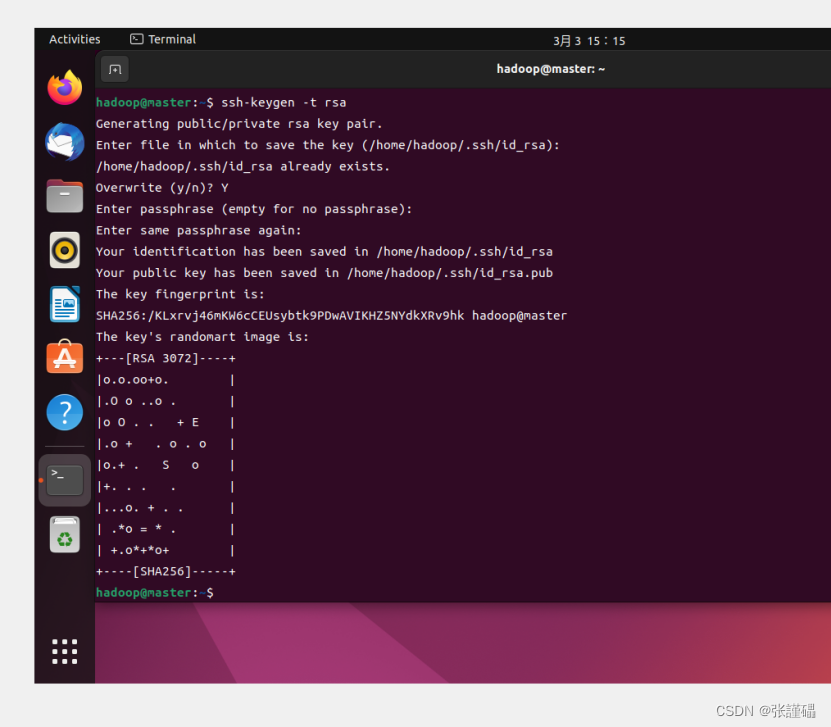
2)发送公钥 先发给自己(装完三个节点之后在发送给slave1、slave2)
将master节点上hadoop用户的公钥发给各个节点的hadoop用户(包括自己)
在这样说明一点,要将三台hadoop配置完毕之后在发送其它两台的,下面的代码
要在master节点下一行一行输入
正在途中还要输入yes,密码,
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@master
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave1(slave1节点装完在输入)
ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@slave2(slave2节点装完在输入)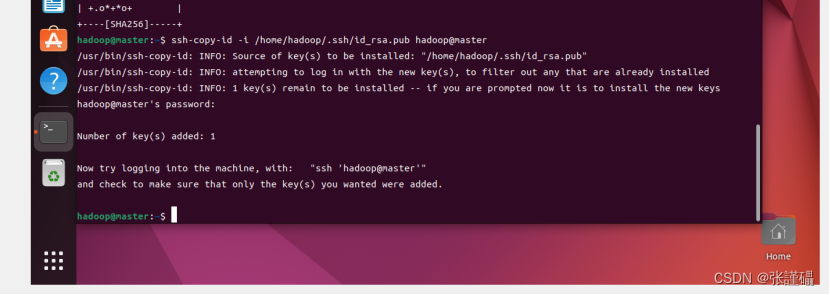


3)测试免密登录
ssh master
(1)安装jdk和hadoop
先解压文件
输入代码
jdk-8u301-linux-x64.tar.gz 是文件名,要改成自己的文件名
hadoop-2.10.1.tar.gz 是文件名,要改成自己的文件名
tar -zxvf jdk-8u301-linux-x64.tar.gz
tar -zxvf hadoop-2.10.1.tar.gz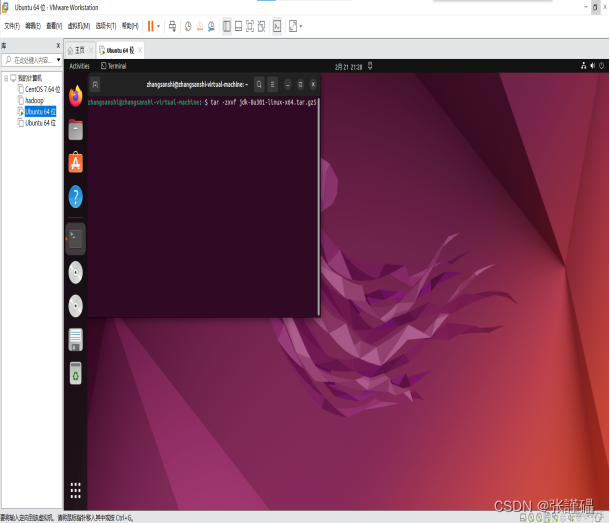

移动至/usr/local 路径下
移动jdk
sudo mv jdk1.8.0_301 /usr/local/jdk1.8.0移动hadoop
sudo mv hadoop-2.10.1 /usr/local/安装 vim 编辑器,不安装的话可以使用自带的 vi 编辑器
(功能相对少)
sudo apt install vim打开环境变量配置文件
sudo vim /etc/profile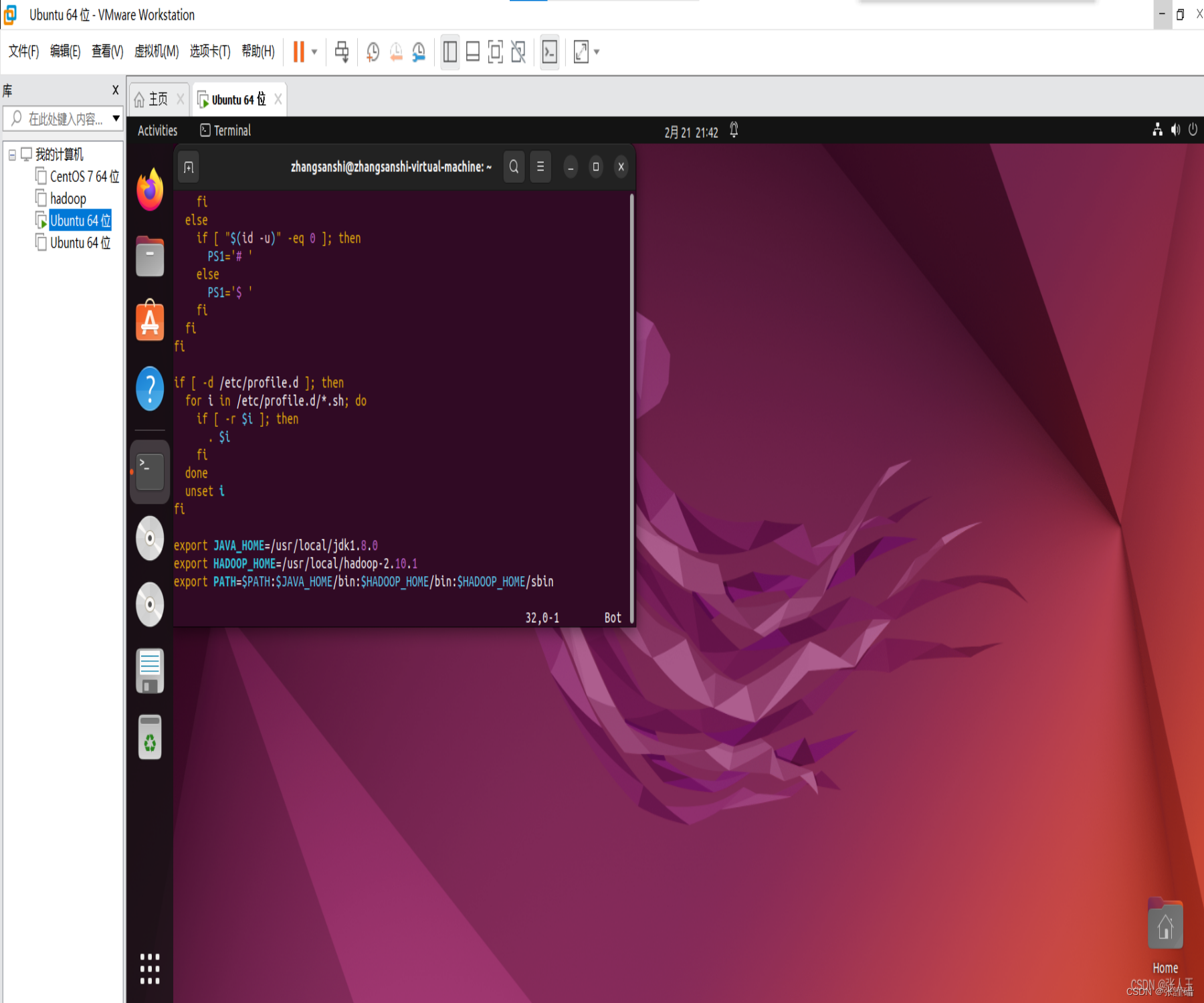
在文件末尾插入以下定义
export JAVA_HOME=/usr/local/jdk1.8.0
export HADOOP_HOME=/usr/local/hadoop-2.10.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin按Esc
然后输入
:wq
$ source /etc/profile
测试是否配置成功
测试Hadoop是否安装完成
hadoop version测试Java是否安装完成
java -version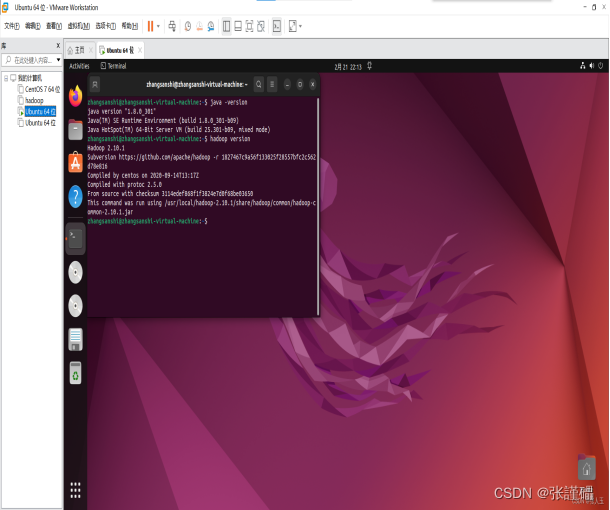
配置Hadoop
建立保存临时目录的路径
sudo mkdir -p /usr/data/hadoop/tmpHadoop 默认启动的时候使用的是系统下的 /temp 目录下,但 是在每一次重启的时候系统都会将其自动清空 ,如果没有临 时的储存目录有可能会在下一次启动 Hadoop 的时候出现 问题。
为防止 Hadoop 运行时出现权限的问题,需要将/usr/data 目 录及其子目录的拥有者全部从 root 改为用户名。 (这里以本机用户名 silin 为例。)
sudo chown sillin:silin -R /usr/data(4)Hadoop分布式配置(master节点)
进入hadoop安装文件下的/etc/hadoop/文件夹中。
cd /usr/local/hadoop-2.10.1/etc/hadoop配置hadoop-env.sh脚本文件
将${JAVA_HOME}改为jdk的实际安装路径
vi hadoop-env.sh将${JAVA_HOME}改为jdk的实际安装路径
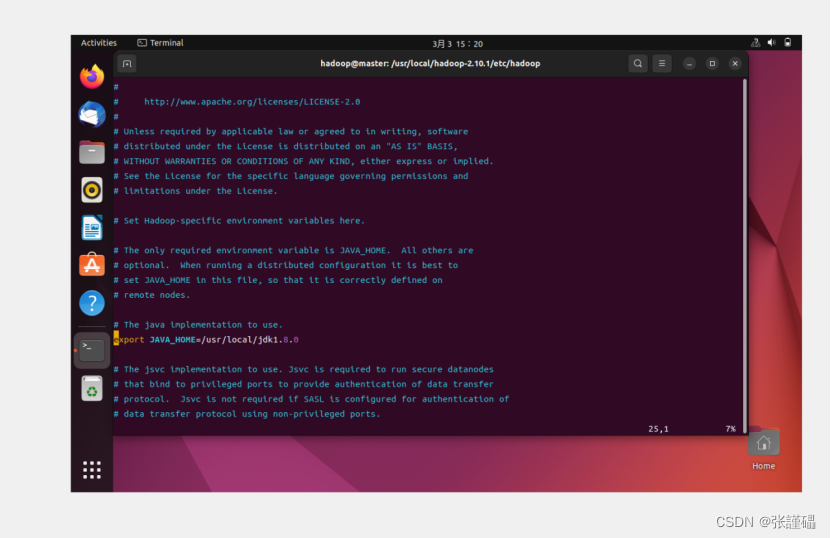
配置core-site.xml配置文件
vi core-site.xml<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/data/hadoop/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hostname:9000</value>
</property>
</configuration>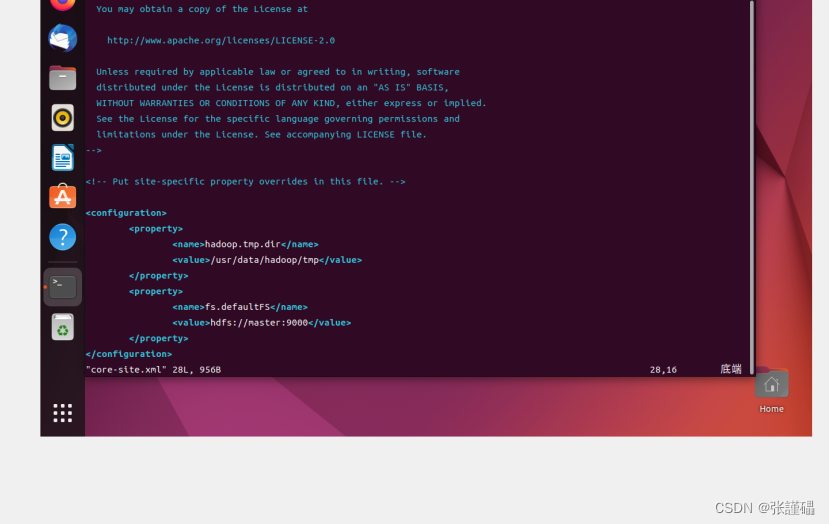
配置hdfs-site.xml的配置文件
vi hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>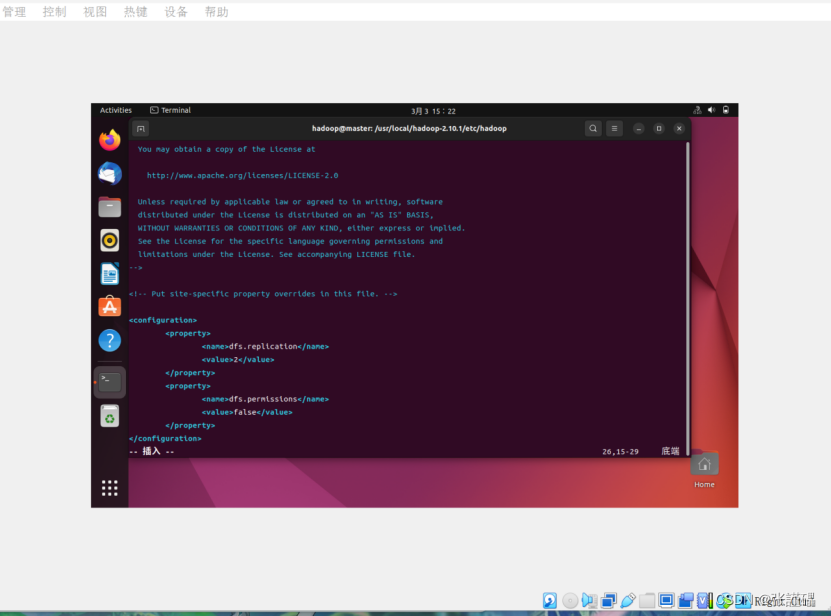
将mapred-site.xml.template更名为mapred-site.xml并编辑
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>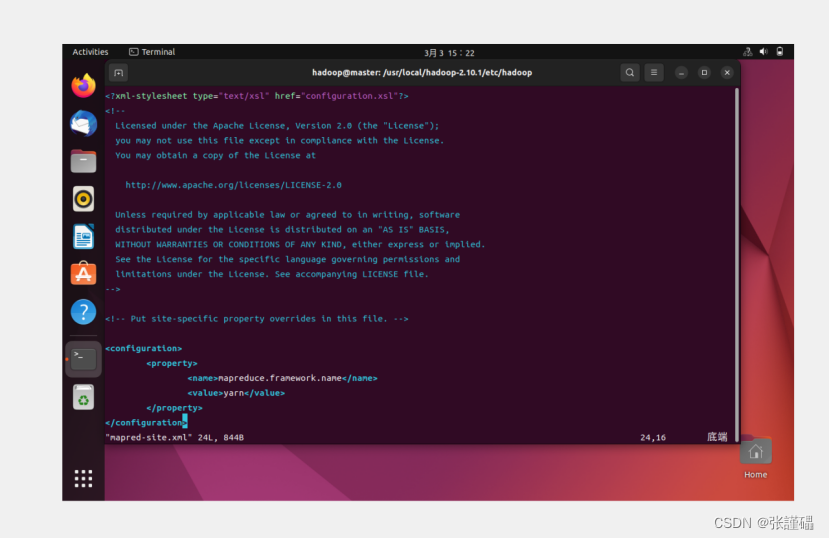
配置yarn-site.xml
vi yarn-site.xml<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hostname</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>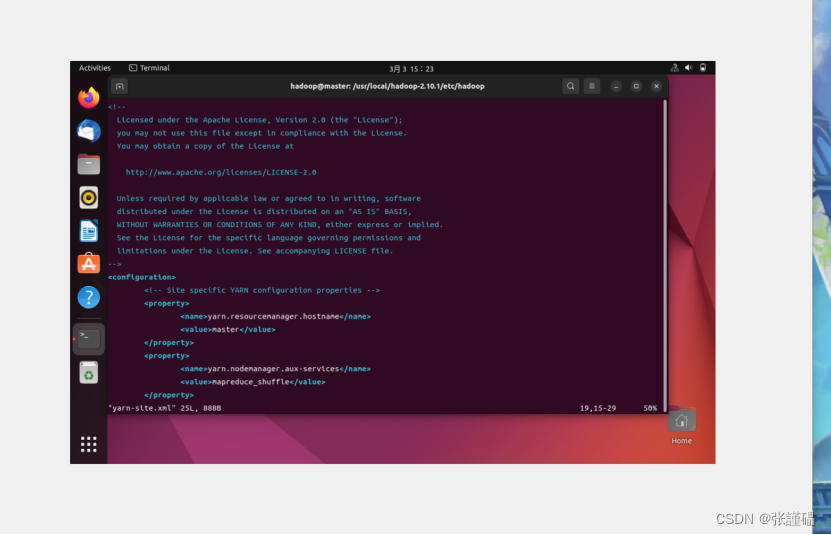
vi slaves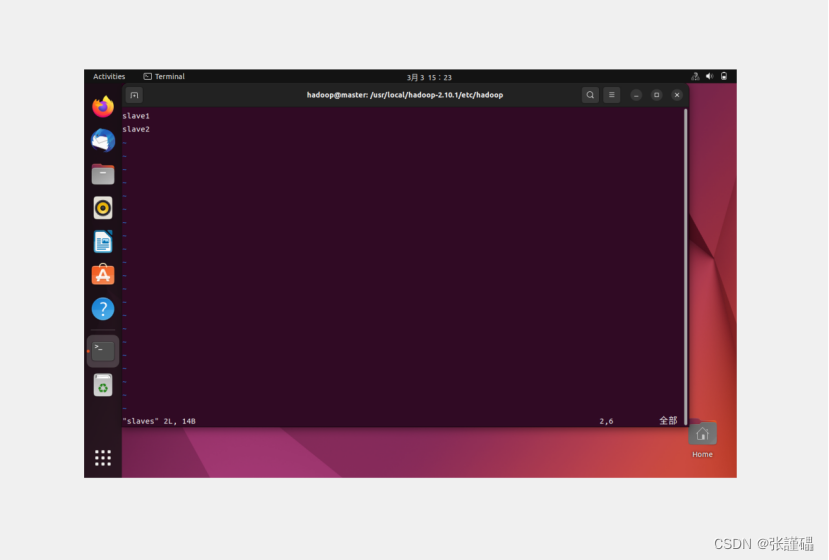
到这里master节点就完成了
但是我们需要配置三个节点
要用到虚拟机里面的复制


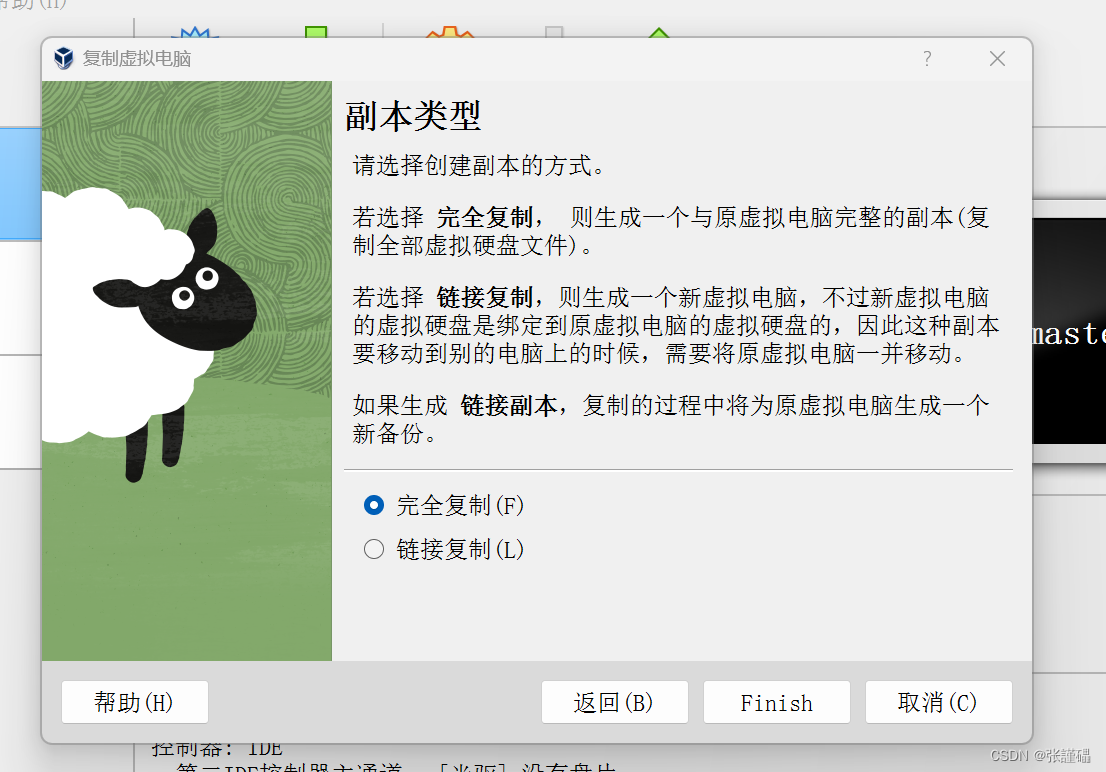
一定要选完全复制
点击完成就行了
复制两份
要改里面的hostname,和hostname的文件
(5)格式化namenode
hdfs namenode -format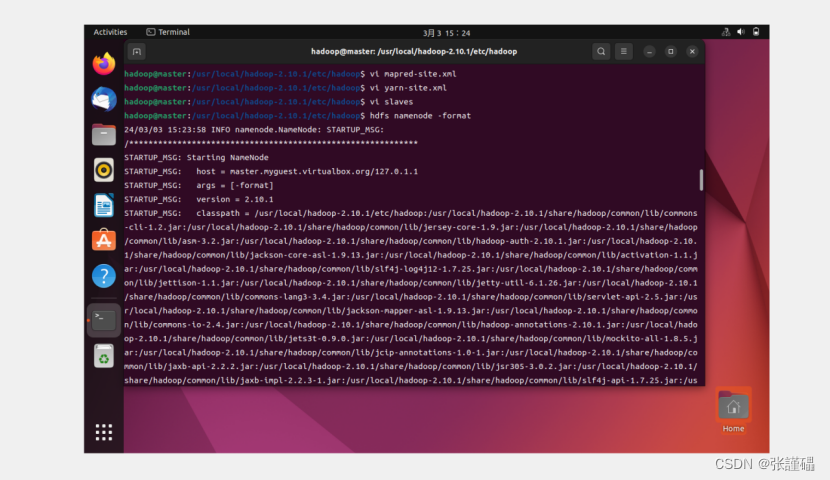
(9)启动(第一次启动需要输入yes)
start-dfs.sh
start-yarn.sh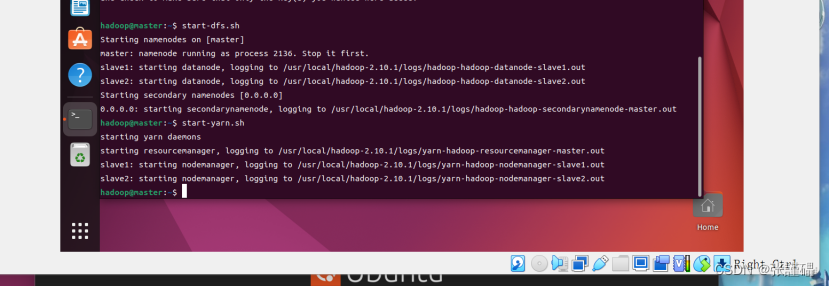
输入jps确认
jps
Master节点

Slave1节点
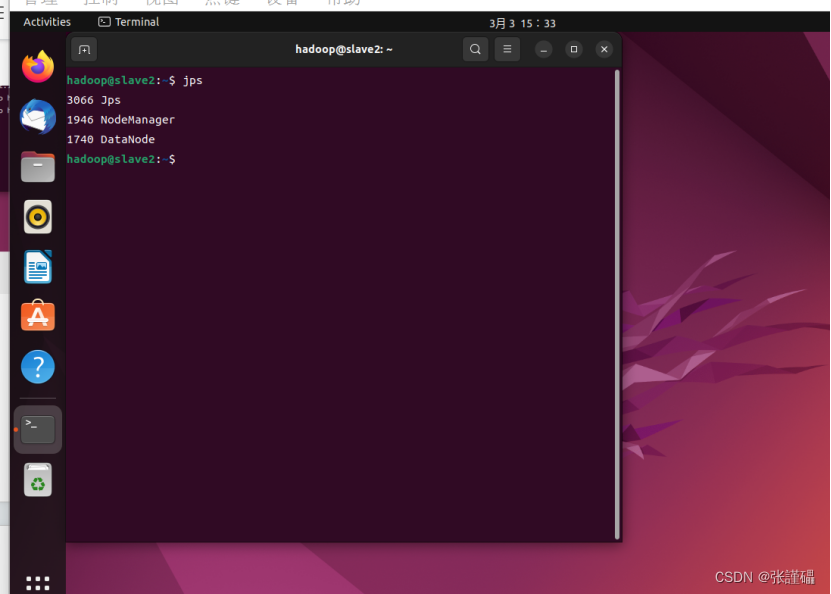
Slave2节点

参考链接:
在ubuntu上安装hadoop完分布式-CSDN博客
在Centos7下安装Hadoop的完全分布_在ubantu上下载hadoop-CSDN博客
如何在Ubuntu下安装伪分布hadoop_ubantu hadoop伪分布式-CSDN博客








![Sqli-labs靶场第21、22关详解[Sqli-labs-less-21、22]自动化注入-SQLmap工具注入|sqlmap跑base64加密](https://img-blog.csdnimg.cn/direct/f52ab93e68be4d2087c09d7501fe5407.png)