如何预估系统的瓶颈
- 1 CPU
- 1.1 CPU和同吞吐量
- 2 内存
- 3 磁盘IO
- 4 网络宽带
- 5 数据库服务器
- 6 APP服务端
CPU 使用率、内存占用、网络流量、磁盘 IO等指标,异常或者持续高位的情况下,都可能是系统瓶颈的表现。
1 CPU
CPU使用率正常在70%左右,如果持续90%左右,可能是CPU瓶颈。
代码问题。递归调用、死循环、并发运行了大量线程
大量磁盘I/O操作
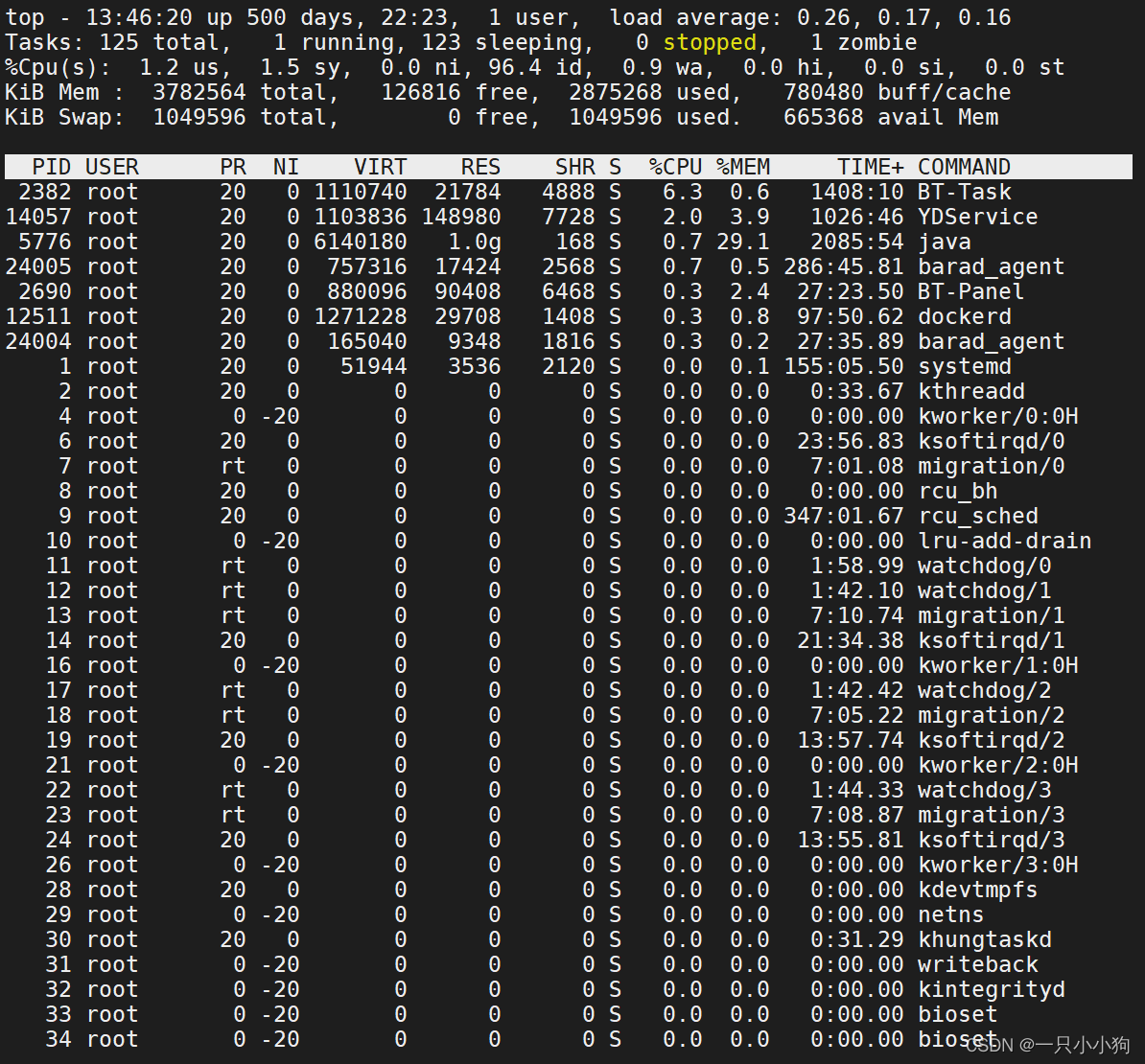
-
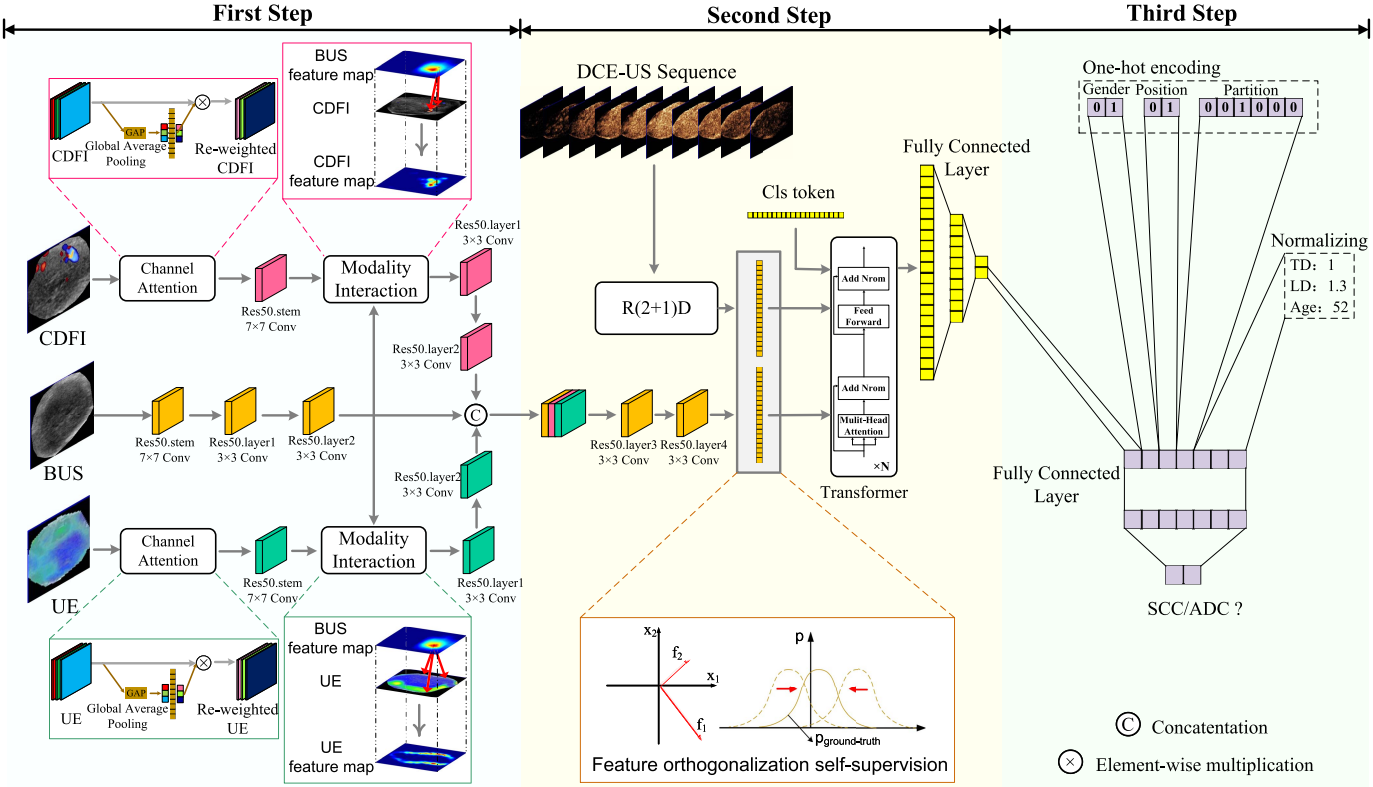
load average系统负载,即任务队列的平均长度。是指1分钟、5分钟、15分钟前到现在的平均值。(数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。) -
Tasks: 125 total是指125个进程在运行。zombie是僵尸数量 -
Cpu(s): 1.2%us用户空间占用CPU的百分比。96.4%id空闲CPU的百分比。0.9%wa等待I/O的CPU时间百分比。 -
Mem: 4045416k total总内存。396748k used已使用的内存。3648668k free空闲内存。102828k buffers缓存的内存。 -
Swap: 2097144k total交换空间。0k used已使用的交换空间。2097144k free空闲的交换空间。242456k cached缓存的交换空间。 -
PID进程ID。USER进程所有者(User)。PR优先级。NInice值。VIRT虚拟内存。VIRT=SWAP+RESRES物理内存。SHR共享内存。S进程状态。(D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程)%CPUCPU占用率。%MEM内存占用率。TIME+运行时间。COMMAND命令。
1.1 CPU和同吞吐量
在压力测试中:
吞吐量低、CPU占用率低。可能是因为出现了锁等待、并发任务出现了同步处理。
吞吐量低、CPU占用率高。可能是因为出现了CPU密集型的任务,比如复杂算法、压缩/解压、序列化/反序列化等。
吞吐量高、CPU占用率高。可能是服务端处理能力强。如果怕冲垮服务端,可以通过限流、熔断等手段来控制。
2 内存
在压力测试中,随着压测的请求增加,内存使用量也会增加,如果压测结束后一段时间,内存使用量没有下降,可能是内存泄漏。(此时就可以进行对场景下的代码进行定位优化)
3 磁盘IO
容量瓶颈:使用df -h命令查看磁盘容量,如果磁盘容量快满了,可能是磁盘容量瓶颈。
性能瓶颈:使用iostat命令查看磁盘性能,如果磁盘的平均等待时间超过了10ms,可能是磁盘性能瓶颈。比如:iostat -x 1 10
4 网络宽带
理论上网络宽带的真实传输速率只有网卡显示的8分之一。比如iftop命令可以查看网络流量。
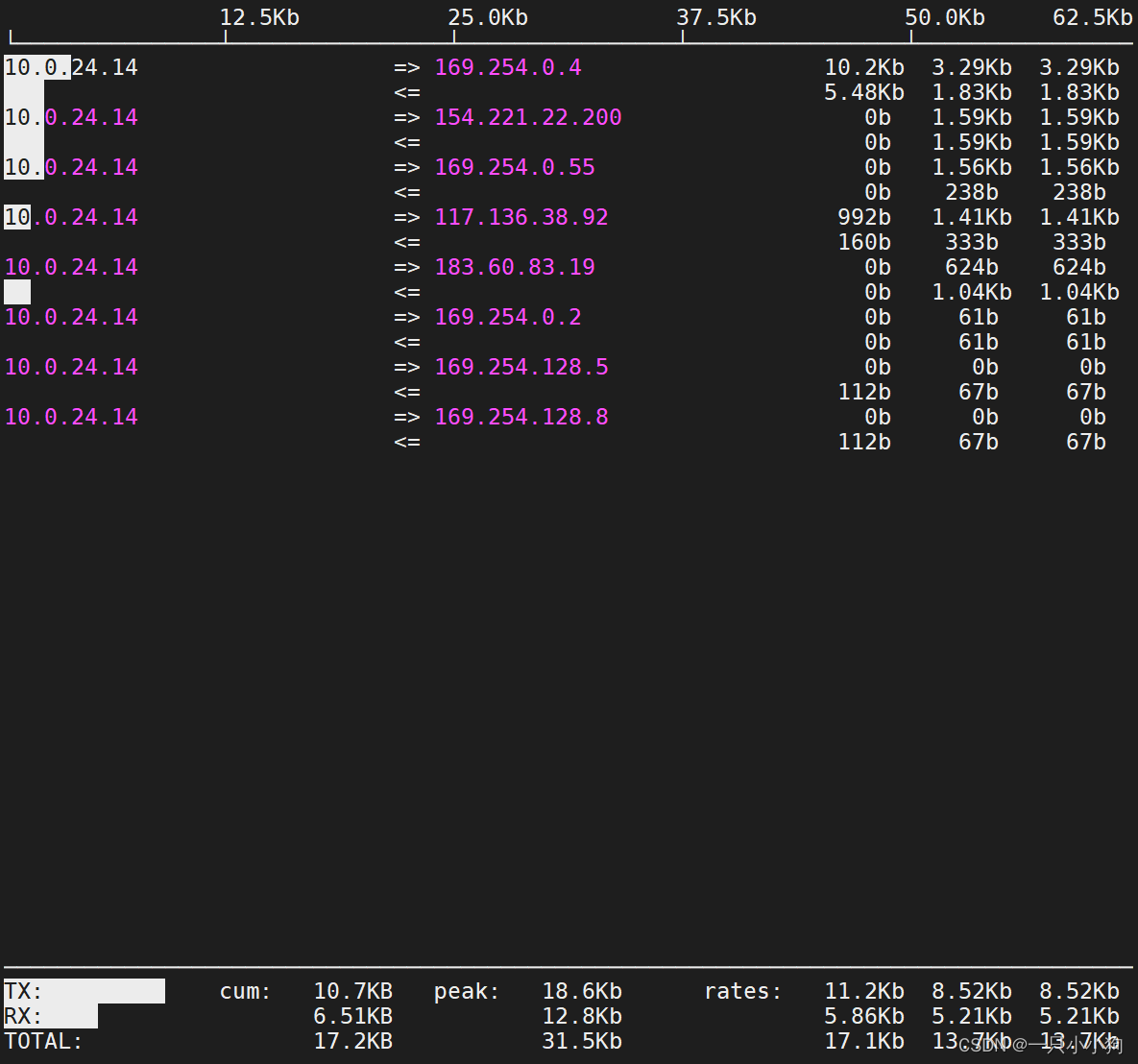
=>发送流量。<=接收流量。
TX 发送流量。 RX 接收流量。 TOTAL 总流量。
cum 开始命令至今的累计流量。 peak 峰值流量。 rates 速率(2s、10s、40s 的平均流量值)。
5 数据库服务器
开启慢查询日志和死锁日志、当前连接数据量、最大连接数量
6 APP服务端
JVM堆栈、线程池等
我的Github地址,欢迎大家加入我的开源项目,或者(在我的主页联系我)加入你们的开源项目,点点Github-Stars。
| \ | 开源项目名称 | 依赖类型 | 版本号 | 描述 |
|---|---|---|---|---|
| 1 | spring-boot-starter-trie | pom | 1.0.0-SNAPSHOT | 特定需求下查询速度远超开源检索工具,innodb下B+树或者ES中倒排索引无法与之比拟. |
| 2 | spring-boot-starter-trie | jar | 1.0.0-M1 | 提供了基于SpringCloud的服务节点,可以通过Nacos注册中心进行服务发现,实现了树的动态扩容与缩容,以及服务的动态上下线。 |
| 3 | Data-Provider | pom | 1.0.0-SNAPSHOT | 提供了多种数据源的查询,以及数据的类型同步,作为一个Jar可以依赖在其他服务上动态的提供数据。 |