方法论
那对于我们专栏来说,在面对复杂的检索知识的时候,我更建议你通过理解记忆的方式进行学习。具体的方式有啥呢?我比较推荐问答的方式。也就是说,在学习每个知识点的时候,你可以一直问自己几个问题,比如,“这个知识点要解决什么问题?”“如果不用这个方法还有其他的解决方案吗?”“使用这个方法有副作用或者限制吗?”。
我们该如何建立自己的知识体系呢?一般来说,我会用这么两个小技巧:
对比和拆解。
在学习一个新知识点的时候,我们可以把它和之前学过的知识点对比,看看它们之间的相同点和不同点,为新、旧知识之间建立联系。那如果这个新知识点是一个比较复杂的知识点,我们可以试着把它拆解成多个小知识点,拆解之后,我们依然可以用对比的方法,让这些小知识点和旧知识建立联系。借助这两个小技巧,你就能将零散的知识点关联起来,从而形成一个自己的知识体系了。
我经常被问到三个问题:
- 有什么事情是你必须要做的?
- 哪些事情是只有你能做的?
- 哪些事情是别人可以帮你做的?
这就是一种时间管理的思路,隐含的意思是:
- 识别并且选择最重要的事情;
- 确定自己最擅长的事情,全力以赴地做好;
- 选择你的帮手,充分信任并授权。
(1)大数据架构方向
大数据架构方向涉及偏向大数据底层与大数据工具的一些工作。做这一方向的工作更注重的是:
Hadoop、Spark、Flink 等大数据框架的实现原理、部署、调优和稳定性问题;
在架构整合、数据流转和数据存储方面有比较深入的理解,能够流畅地落地应用;
熟知各种相关工具中该如何搭配组合才能够获取更高的效率,更加符合公司整体的业务场景。
从事这一方向的工作,需要具备以下技术。
大数据框架:Hadoop、Spark、Flink、高可用、高并发、并行计算等。
数据存储:Hive、HDFS、Cassandra、ClickHouse、Redis、MySQL、MongoDB 等。
数据流转:Kafka、RocketMQ、Flume 等。
(2)大数据分析方向
这里所说的大数据分析方向是一个广义上的大数据分析,在这个方向上,包含了各类算法工程师和数据分析师,一方面要熟练掌握本公司业务,一方面又具备良好的数学功底,能够使用数据有针对性的建设数据指标,对数据进行统计分析,通过各类数据挖掘算法探寻数据之间的规律,对业务进行预测和判断。
从事这一方向的工作,需要具备以下技术。
数据分析:ETL、SQL、Python、统计、概率论等。
数据挖掘:算法、机器学习、深度学习、聚类、分类、协同过滤等。
(3)大数据开发方向
大数据开发是大数据在公司内使各个环节得以打通和实施的桥梁和纽带,爬虫系统、服务器端开发、数据库开发、可视化平台建设等各个数据加工环节,都离不开大数据开发的身影。大数据开发需要具备 2 方面的能力:
要了解大数据各类工具的使用方法;
要具备良好的代码能力。
从事这一方向的工作,需要具备的技术有这些:数仓、推荐引擎、Java、Go、爬虫、实时、分布式等。
滴滴大数据体系
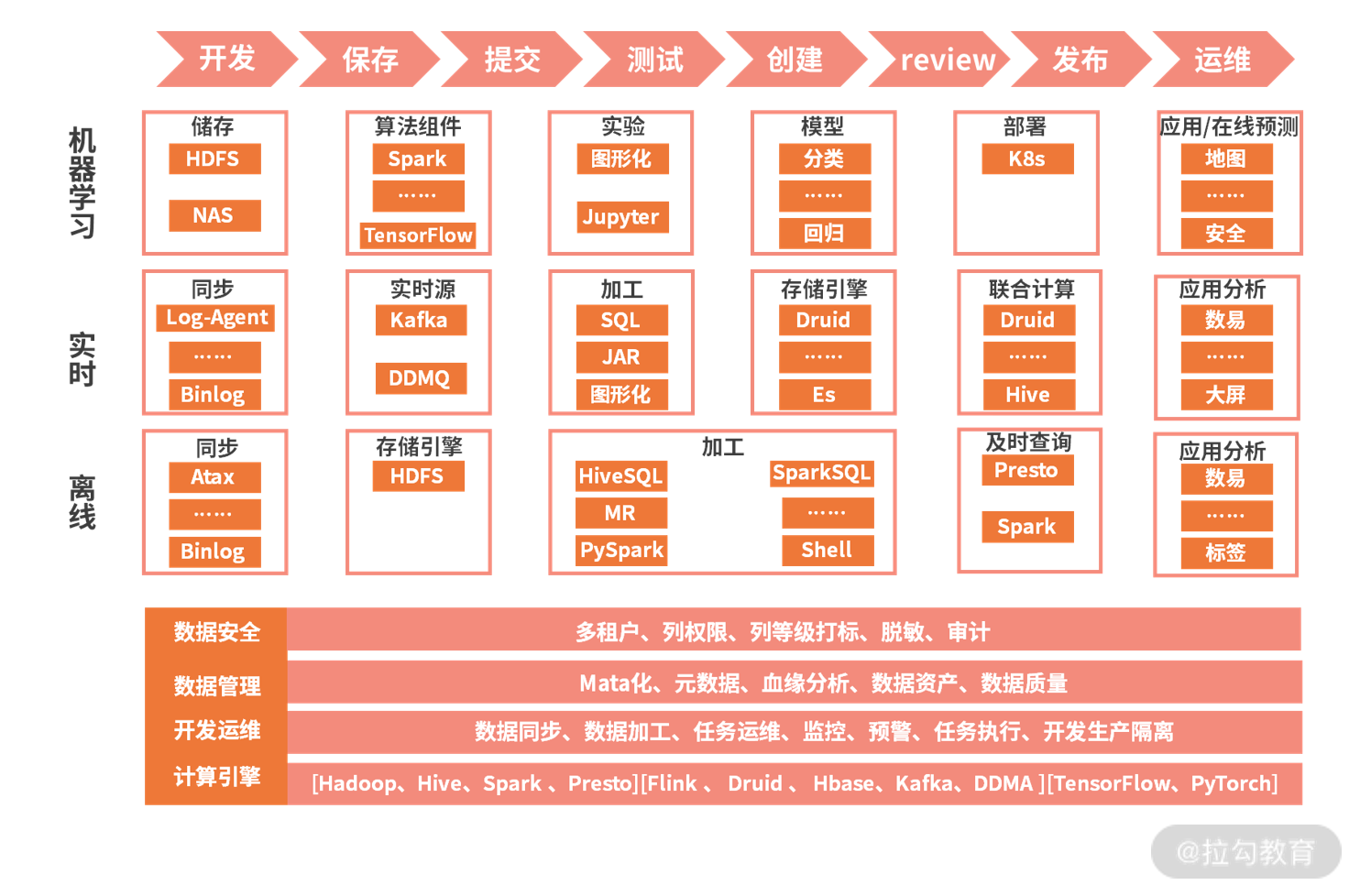
最上层的红色箭头标志展示的是一个基于大数据平台开发工程的发布流程,当然,这个流程跟大数据的关系并不是很大,任何一个工程基本都要遵照这个过程进行发布。
紧挨着的流程是机器学习部分,机器学习会涉及数据挖掘 / 数据分析 / 数据应用几个步骤。
再往下是实时计算解决方案和离线计算解决方案。
在架构图的最底层是相关的支持,包括了数据安全、数据管理、开发运维和计算引擎四个部分。
就滴滴公布的大数据发展历程来看。
滴滴大数据先经历了裸奔时代:引擎初建,即通过 Sqoop 从 MySQL 导入 Hadoop,用户通过命令行访问大数据;
然后逐步引进了相关的工具化建设,但是这个阶段的工具还处于各自为政、四分五裂的状态:租户管理、权限管理、任务调度等;
在那之后,逐步产生了平台化思维,开始搭建一站式的智能开发和生产平台,使其可以覆盖整个离线场景,并且内置开发和生产两套逻辑环境,规范数据开发、生产和发布流程;
最后,也就是最新的一套大数据架构,在一站式开发生产平台的基础上进行了更多的扩展,已经可以集离线开发、实时开发、机器学习于一体。
阿里云的大数据体系
飞天大数据平台和 AI 平台支撑了阿里巴巴所有的应用,是阿里巴巴 10 年大平台建设最佳实践的结晶,是阿里大数据生产的基石。下图是飞天大数据的产品架构:
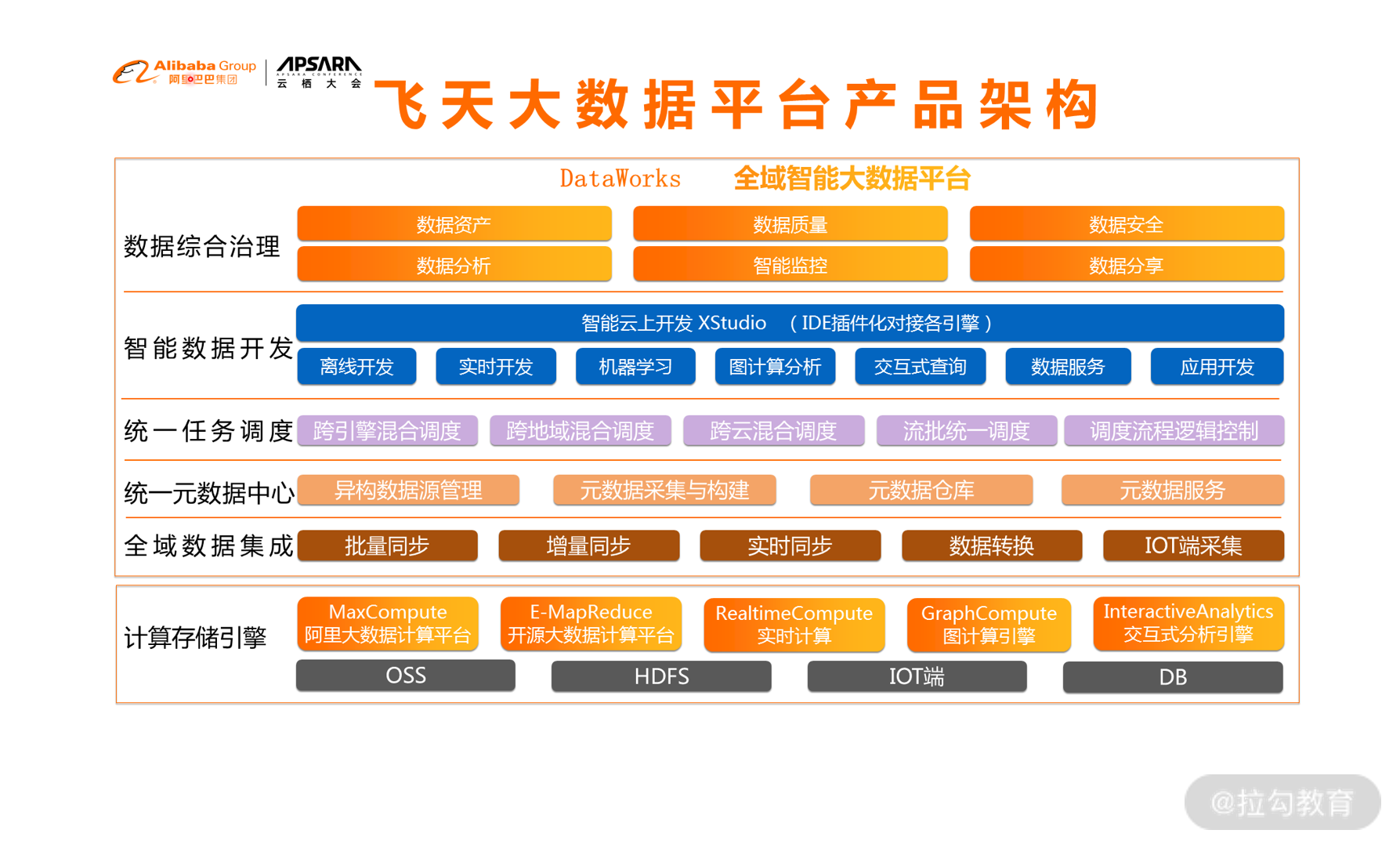
最下面是计算存储引擎,这里面包含了通用的存储和计算框架。存储方面,OSS 是阿里云的云存储系统,底层的 HDFS 文件存储系统,以及其他的各种 DB 系统;在计算框架方面,有 MapReduce 这种离线计算平台、实时计算平台、图计算引擎、交互式分析引擎等。
在存储和计算的基础上,是全域数据集成,这里面主要是对数据的各种采集和传输,支持批量同步、增量同步、实时同步等多种传输方式。
集成后的数据进入到统一元数据中心,统一进行任务调度。
再往上是开发层,通过结合各种算法和机器学习手段开发各种不同的应用。
最上面的数据综合治理,其实是在大数据全流程起到保障作用的一些模块,包含了智能监控、数据安全等模块。
美团的大数据体系
这是美团早些年公开的大数据体系架构:
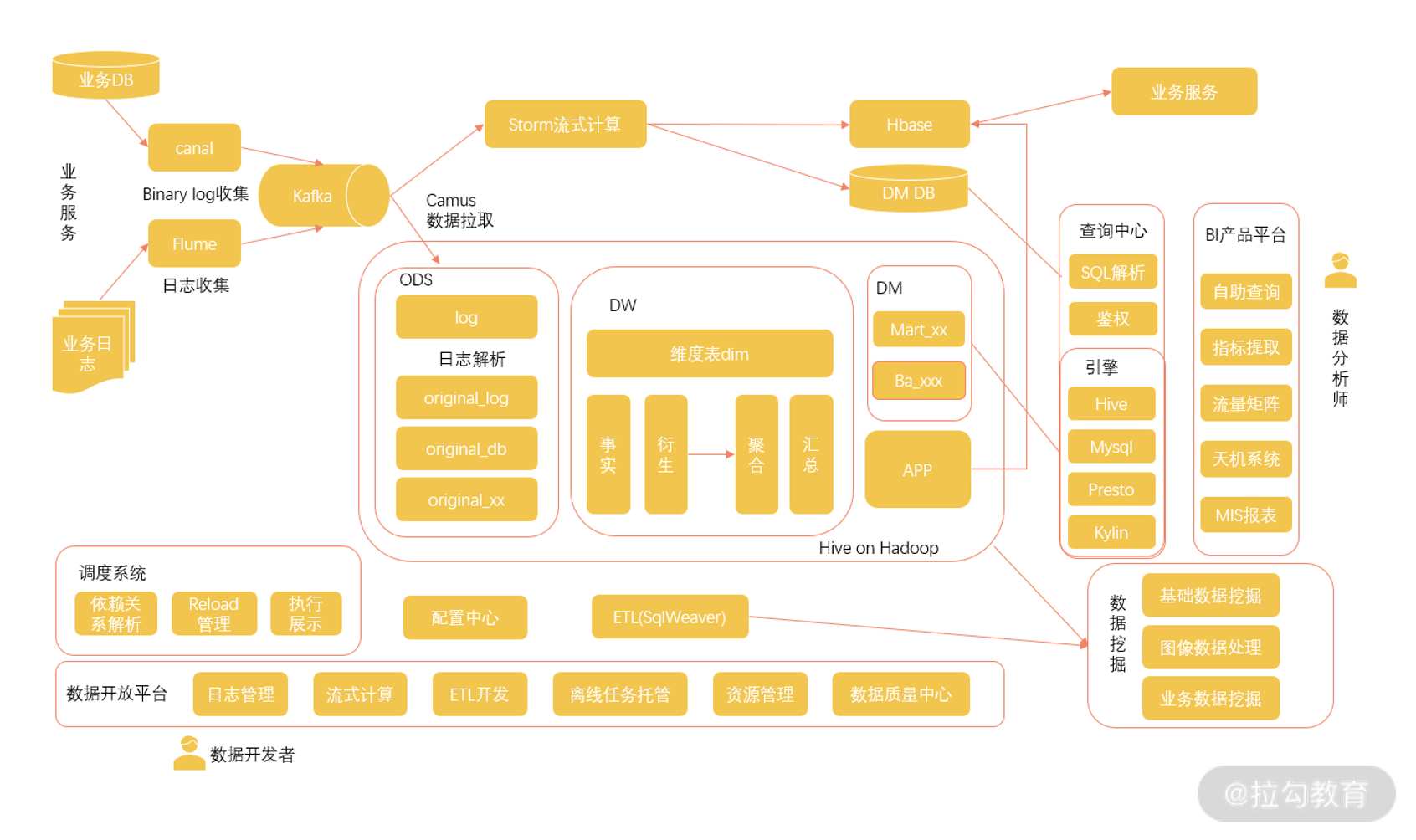
在图上我们可以看到。
最左侧是美团的各种业务服务,从这些业务的数据库和日志,可以通过数据传输、日志采集等手段对数据进行汇总,一方面对于计算需求,直接进入到 Storm 流式计算框架进行计算,把结果存储于 HBase 等各种数据库中,并在业务上应用;另一方面,数据汇总到Hadoop 框架的存储中心,经过各种解析和结构化存储在 Hive 表中,并在各种机器学习和数据挖掘项目中进行应用。
在底层,是围绕着 Hadoop 架构建设的调度系统、配置中心,以及数据开放平台。
在最右侧,是经过集成的查询中心和查询引擎,并通过平台化开发建立了一套数据分析产品平台。
Hadoop 的整体架构
经过了这么多年的开发与演进,Hadoop 早已成为一个庞大的系统,它的内部工作机制非常复杂,是一个结合了分布式理论与具体的工程开发的整体架构。对于没有什么经验的人来说,Hadoop 是极其难理解的。不过,我们这一专栏并不是要把 Hadoop 的运行机理讲清楚,而是明白 Hadoop 为我们提供了什么样的功能,在我们整个大数据流转的过程中可以发挥哪些作用就可以了。
关于 Hadoop 最朴素的原理,就是要使用大量的普通计算机处理大规模数据的存储和分析,而不是建造一台超级计算机。这里有两个问题需要解决。
计算机的故障问题。想象我们使用一个有一万台计算机组成的集群,其中一台计算机出现问题的可能性是很高的,所以在大规模计算机集群上要处理好故障问题,就要做到一台计算机出现问题不会影响整个集群。
数据的依赖关系。集群由若干台计算机组成,数据也是分布在不同的计算机上面,当你需要计算一个任务的时候,你所需要的数据可能要从若干台计算机进行读取,而你的计算过程也要分配到不同的计算机上。当你的任务分成若干个步骤形成相互依赖的关系时,如何让系统保持高效和正确的运行是一个很大的问题。
下图是 Hadoop 系统的一个架构图,虽然现在已经有了非常多的组件,但是其中最核心的两部分依然是底层的文件系统 HDFS和用于计算的 MapReduce。接下来,我们来看一下 Hadoop 系统中的一些重要组成部分。
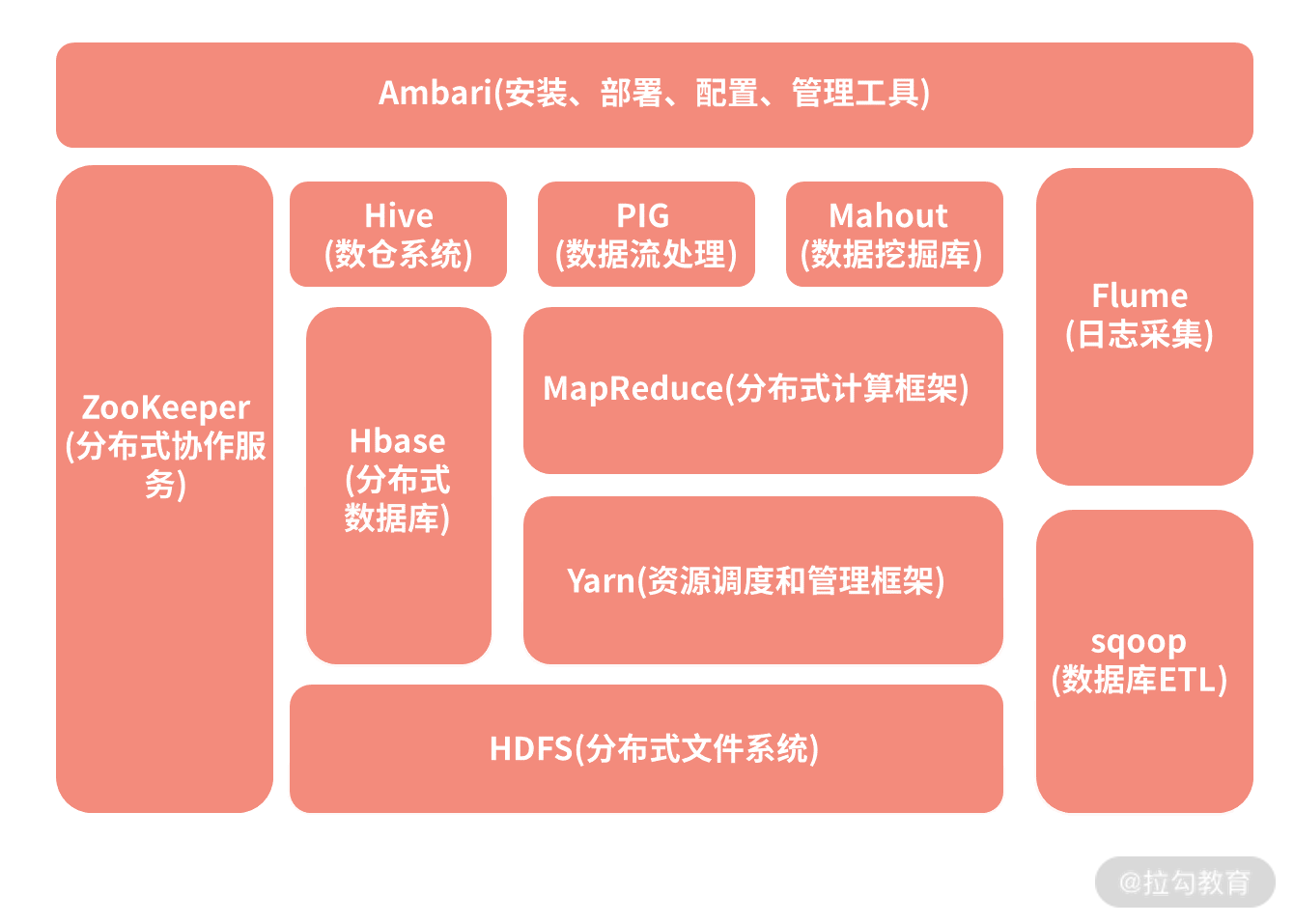
1.HDFS(分布式文件系统)
HDFS 是 Hadoop Distributed File System 的缩写,从名字就可以看出它是一个文件系统。它在 Hadoop 体系中帮助解决文件的底层存储问题,能够用来支持海量数据的磁盘存储,能够进行机器的线性扩充,只需要在集群中增加节点,存储能力就会同步增长。
不仅如此,HDFS 还具备非常强大的容错性能,其中的某些节点出现了故障不影响系统的使用,通常数据都有很多的副本。HDFS 屏蔽了那些存储的细节,并在客户端为大家提供了一套完整的文件管理命令,把底层的文件以一种结构化的目录形式展现给用户,我们可以像使用 Linux 文件操作命令一样使用 Hadoop 命令来访问对应的文件。
2.MapReduce(分布式计算框架)
思考一下我们刚刚进行过的人口普查,先把这个大任务按照地区划分成若干个小任务,每个地区找一名负责人,确保地区的划分不重不漏。然后由这个地区的负责人负责统计自己区域内的人员数量等信息,然后把所有人的统计结果汇总起来,就能得到全国的人口普查数据。如果说其中一个负责人有事情,不能完成,就可以换一个人继续进行这个地区的统计,而不会明显地影响全国的人口普查进度,这其实就是最朴素的 MapReduce 思想了。
在 Hadoop 中的 MapReduce 框架就解决了分布式计算的问题,包括其中的运算逻辑与数据依赖。在 MapReduce 的应用上,提供了一套编程模型,重点就是实现 map 函数和 reduce 函数:
map 函数用于组织和分割数据;
reduce 函数主要负责在分布式节点上的数据运算。
MapReduce 编程支持多种语言实现,比如 Java、Scala 等。
3.Hive(数仓系统)
在 HDFS 之上,Hive 是 Hadoop 体系的数据仓库工具,可以将结构化的数据文件映射成一个数据表,注意这里的重点是结构化的数据文件。在 HDFS 文件系统中可以存储结构化数据文件,也可以存储非结构化数据文件,而 Hive 是处理其中的结构化数据文件,它本身并不进行存储。
同时,Hive 提供了一套Hive SQL实现 MapReduce 计算,我们可以使用与 SQL 十分类似的 Hive SQL 对这些结构化的数据进行统计分析,所以从某种意义上来说 Hive 是对 MapReduce 进行包装后产生的工具。在公司中,Hive 是一个非常常用的数仓工具,很多公司都会把它当作基础数仓来使用。不过 Hive 也有一些不好用的地方,比如不能进行单条数据更新。
4.HBase(分布式数据库)
在存储方面,Hadoop 架构中还有一个 Hbase 数据库。HBase 是一个分布式高并发的K-V 数据库系统,它的底层当然也是由 HDFS 来支撑,而 HBase 通过对存储内容的重新组织,克服了HDFS 对小文件处理困难的问题,实现了数据的实时操作。
在互联网公司中,对于量级较大,且变动较多的数据通常适合使用 HBase 进行存取。比如说我之前所在的做内容的媒体公司,内容数据经常会发生更新等变动,我们对这些内容进行各种算法运算也经常需要单条或者小批量的存取,所以使用 HBase 来存储数据,非常方便。
5.Yarn(资源调度和管理框架)
在最早的 Hadoop 1.0 中其实是没有 Yarn 的,资源调度等功能都包装在 MapReduce 的 JobTracker 中,而 JobTracker 负担了太多的功能,接受任务、资源调度甚至是监控TaskTracker 的运行情况。当时存在一个问题,在集群规模非常大的时候会出现不稳定的情况,于是在 2.0 中对其进行了拆分,因此产生了独立的 Yarn。在拆分出 Yarn 之后,MapReduce 只负责计算,这也给后面其他计算框架替换 MapReduce 提供了方便,保障了 Hadoop 整个架构长盛不衰。
6.ZooKeeper(分布式协作服务)
ZooKeeper,直译是动物园管理员。这是因为很多项目都以动物的名字命名,而 ZooKeeper 最常用的场景是作为一个服务的注册管理中心。生产者把所提供的服务提交到 ZooKeeper 中,而消费者则去 ZooKeeper 中寻找自己需要的服务,从中获取生产者的信息,然后再去调用生产者的服务。
在我看来,ZooKeeper 像是一个锁,把控各种数据流转服务的中间环节,保障数据的一致性。比如说 HBase、Kafka 等都可以通过 ZooKeeper 进行注册。幸运的是在我们的开发过程中,不需要了解太多 ZooKeeper 的细节,主要是进行一些代码上的配置就可以了。
一口气讲了这么多 Hadoop 的组件,但是可以看到,在 Hadoop 的框架中还远远不止这些东西。不过最主要的、平时工作中接触最多的部分已经都有涉及。
下面我们来看一下 Hadoop 的一些优缺点。
Hadoop 的优点
强大的数据存储和处理能力。这个优点是显而易见的,也是最根本的。通过技术手段,Hadoop 实现了只需要增加一些普通的机器就可以获得强大的存储和运算能力。
隐藏了大量技术细节。使用 Hadoop 框架,我们不再需要关注那些复杂的并行计算、负载均衡等内容,只需要调用相关的 API 就可以实现大规模存储和计算。
良好的扩展能力。发展到今天,Hadoop 已经不是一个单一的解决方案,它提供了很多不同的组件,不限于我上面列出的这些。公司可以使用标准的方案,也可以根据自己的业务需求来进行细节上的调整甚至是自己的开发。比如说对于计算框架 MapReduce,在很多公司已经使用性能更好的 Spark 或者 Flink 进行了替换。
Hadoop 的缺点
实时性较差。由于 HDFS 存储底层都是在磁盘中进行的,以及原生的 MapReduce 的中间结果也都要存储在磁盘上,所以 Hadoop 的实时性不太好。
学习难度较大。虽然说 Hadoop 已经对很多复杂的技术进行了封装,但是仍然挡不住它是一个庞大而复杂的系统。尤其是其中的很多问题都需要在实践中不断摸索,要想学习整个体系几乎是很难在短时间内实现的。
大数据中的数据到底是从哪儿来的?
传感器
比如我们前面介绍的天气数据就需要放置很多传感器,用气压、温度、风力等传感器,不停地收集数据。在互联网公司的产品中也不乏基于传感器的数据采集:
手机上的指纹开屏;
使用指纹进行支付;
微信步数的采集;
各种手环和运动手表等还可以监测心率;
……
传感器采集主要依赖于各种各样的硬件设施,而在当前互联网中主要依赖硬件采集信息的还是比较少的。
爬虫采集
顾名思义,爬虫采集是通过一套程序去互联网上获取数据的方法。如果把一个互联网公司的数据划分成站内数据和站外数据,那么爬虫所获取的都属于站外数据。很多时候我们要做一些任务,只依赖自己的数据是不够的,而互联网上存在着大量开放的数据,通过爬虫系统可以获取很多有益于我们工作的数据。当然,使用爬虫来爬取数据一定要注意法律风险,很多公司的数据是禁止爬取的,在具体操作的时候一定不要触碰法律的红线。
日志采集
最重要的一种数据采集的方式就是日志采集。在这个移动互联网的时代,基本上每个互联网公司的输出都以手机 App 为主要的承载形式。阿里巴巴有淘宝、1688、饿了么等多个 App;字节跳动有抖音、今日头条、懂车帝等多个 App。用户在这些 App 上产生各种行为和活动,我们需要在代码中重点标记所需的行为记录,并把它们作为“日志”传输到服务器上。
跟硬件传感器相比,日志记录可以看作是一种软件传感器,依托手机 App 就可以实现,这通常是现在的互联网公司获取“站内数据”的主流方式。下图就是一个典型的日志采集场景:
用户在淘宝上浏览商品,点击下单支付,这些信息都通过日志的形式从前端传递到后端并通过网络输送到公司的服务器上,最终存储在数据库里。有了这些数据,公司又可以对用户进行分析,进一步推荐你可能感兴趣的商品并呈现在 App 的前端界面上。
在日志采集的数据中,通常又可以分成两种类型,一种称为事件,一种称为属性。
事件
事件是日志采集的重中之重,这里我们来详细介绍一下。在 App 中,用户的一种行为就被称为一个事件。如果把事件进行归类,我觉得可以分成三种基本事件:曝光事件、点击事件和用户停留事件。
(1)曝光事件
最简单的,一个 item 或者一个页面被展示出来,就称作曝光。在日志中记录曝光事件,就是记录每一个被展示出来的页面、商品或者内容。
(2)点击事件
而点击,则是用户在 App 中的点击行为。通常,App 中的各种页面都是通过点击进行跳转的,比如说上面的淘宝页面,你点击一次商品图片可以进入详情页,再点击一次加购可以加入购物车,然后点击支付可以进入到付款页面,依次类推,点击事件是用户行为转变的关键行为。
(3)用户停留事件
这个事件记录的是一个用户在某个页面,或者某种情况下停留的时间。比如说在抖音中,你在一个“美女视频”的播放中停留的时间比其他视频的停留时间都要长,我们就可以猜测你对“美女”更感兴趣。
有了上述的三种基本事件,同时综合这三种基本事件发生的不同场景,我们就可以测算各种数据指标。
在新闻推荐场景,使用新闻曝光和新闻点击可以计算某条新闻的点击率;
在视频场景,使用点击和用户停留时间可以计算观看完成比;
在交易场景,使用浏览点击和下单点击可以计算访购率。
属性
与事件的连贯性不同,属性的收集往往是一次性的。当我们打开 App 时,我们使用的手机型号、网络制式、App 版本等信息都作为属性一次性地收集起来。虽然说属性的收集过程比事件要简单,但是属性数据本身的价值并不比大量的事件低,所以,对于属性的日志收集也需要同等的对待。
数据埋点
在我们的公司中,实现日志采集所使用的手段被称为数据埋点。
通俗来说,数据埋点就是在我们 App 的前端,也就是 UI 层的代码中插入一段用于监视用户行为事件的代码。当用户在 App 上发生对应的行为时,就会触发这段代码,从而上传该埋点中事先已经定义好的事件信息。
当然,除了我们所熟知的手机 App,数据埋点还可以设定在 H5 页面、微信小程序等位置。通过埋点收集到的信息:
可以作为监控,看到 App 的长期表现;
也可以作为基础原料,进行复杂的运算,用于用户标签、渠道转化分析、个性推荐等。
数据埋点的困难
为了获取更多的流量,满足更多用户的需求,一个成熟的互联网公司往往有各种各样的用户渠道,因此,要想把数据埋点做好也有很多的困难。
来源众多。对于一款产品,可能有网页端、App 端,App 还分成安卓、iOS 甚至微软客户端,还有各种各样的小程序。这么多的来源,要把不同来源的同一处行为数据进行合并统计,而不同的来源开发语言不同,实现原理不同,埋点的难度可想而知。
页面众多。看似不起眼的一个 App,从你打开到浏览、下单、支付,这中间不知道要经过多少个页面,有多少种不同的形式,每个页面、每个形式又有若干种事件的组合,要想做好每一处埋点也不是一件容易的事情。
数据格式各不相同。不同的业务可能对于同一个页面的埋点存在不同的需求,数据埋点需要做到兼容并包、不重不漏,其实也是非常困难的。
说了这么多埋点的困难,那么埋点的方式有哪些呢?对于不同的方式,它们对于困难有什么解决方法,下面我们来看一下。
埋点方式
(1)手动埋点
说到埋点方式,最容易想到的当然就是手动埋点。前面也说过了,所谓的埋点就是程序员去增加一些代码,那么手动埋点自然是说程序员手动地去增加代码。这就意味着当有产品需求的时候,产品经理提出我们需要在某某页面、某某位置增加一个针对某某行为的埋点,然后程序员领取了这个需求,一顿操作上线这段代码。
这种埋点方式最大的好处就是没有其他的开发量,属于懒惰开发的一种情况,只有当需求提出的时候才去增加一个埋点。对于单个需求,开发比较迅速,但是它的缺点也显而易见,随着业务的增长,埋点的需求必然是一个接一个,永无止境,程序员做了大量相似的开发。而且每增加一个埋点,都需要从产品提出到需求沟通到程序员开发到上线走一遍,长期来说消耗是巨大的。
(2)半自动埋点
手动埋点耗时耗力,所以就要想着把流程改进一下。半自动的埋点通常出现在产品已经基本成熟的时期。程序员加班加点对于目前以及预期未来的业务流程进行了梳理,整理出一套常用的埋点方案,并把这套方案嵌入到业务代码中。当产品经理上线了一个与原有页面类似的新页面,不再需要程序员进行多余的开发,只需要调用之前的方案即可完成埋点。
不过,在半自动埋点的情况下,如果有一些全新的功能或者页面上线,还是需要进行开发的。
(3)全自动埋点
懒惰是进步的动力。全自动埋点与前面的两个理念完全不同,前面两种不管是手动还是半自动都是在有需求的时候才去埋点,而全自动埋点完全忽略了需求的存在,直接从最基本的事件和属性出发,把所有的东西都纳入埋点的范畴,事无巨细地记录下来,以后产品想要什么东西就自己去日志里统计就好了。
全自动埋点的优势显而易见,从根本上解决了埋点的需求,从此解放了双手,不再需要听什么埋点需求。但是缺点同样明显,开发一套如此完整的全自动埋点系统通常也极为困难,同时,收集全量信息,网络开销大、存储成本高,大部分没用的信息则会导致后续数据处理的速度缓慢。
不管采取何种埋点方案,有一点我希望提醒你。在处理埋点信息的时候一定要有一套统一的标准:同一个事件、同一个属性坚持只有一个埋点的原则,收集上来的日志由统一的部门进行汇总管理,进而统一数据口径。试想,如果对于同一个事件,不同的业务部门使用不同的埋点代码,由不同的部门进行计算,随着人员的变动和业务的更迭,最终将导致数据陷入永远无法核对清楚的困境,想想就是一种灾难。
进阶
为了更好地理解数据埋点采集日志与后续环节的关系,我在这里画了一张数据埋点的框架形式,当然,数据埋点的框架可以有很多种,这里只是作为一种说明。
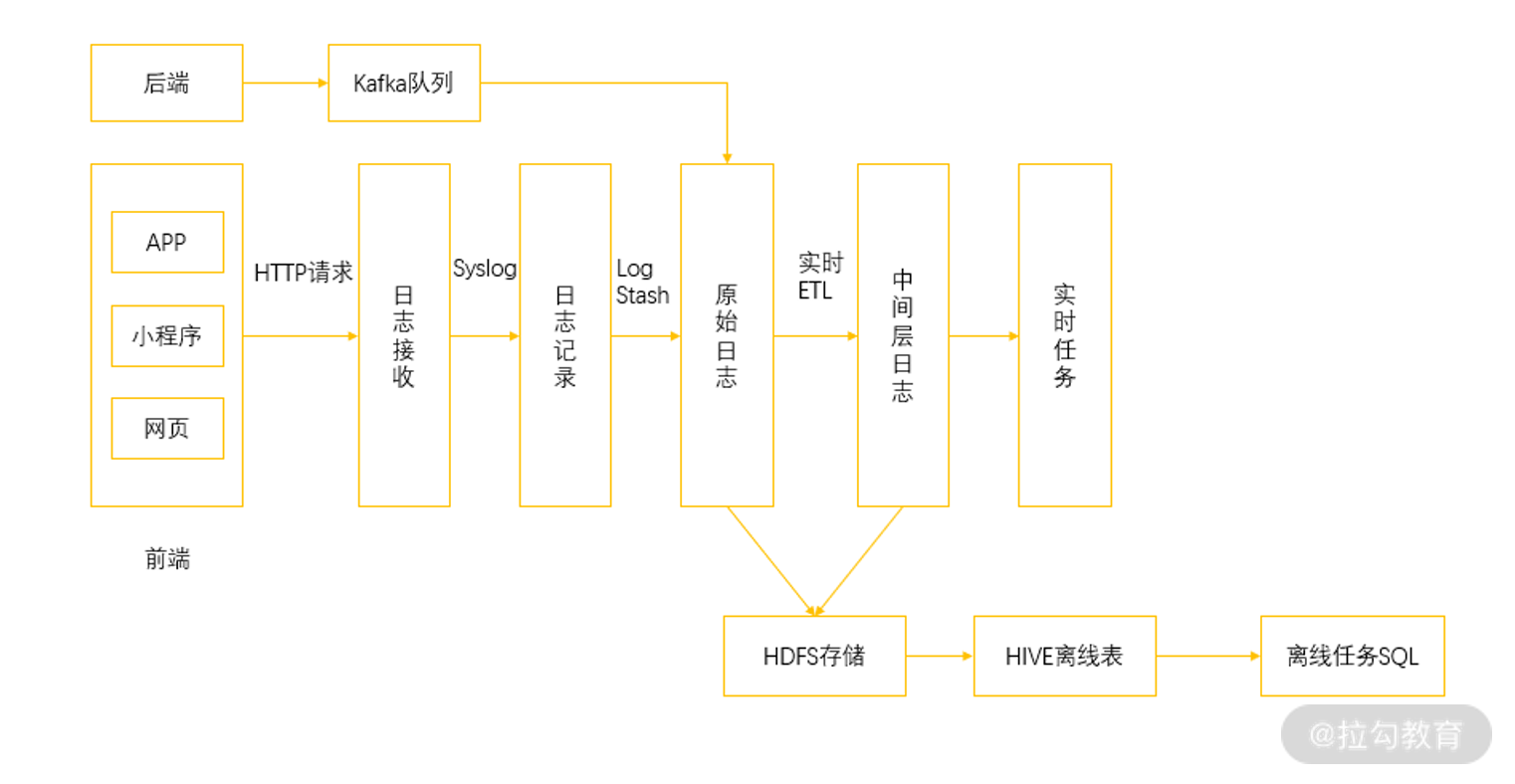
从上图,我们可以看到,在开发了埋点代码的前端环境中监控用户的行为,当用户产生行为的时候会通过 HTTP 请求把这些事件进行上报,进入到日志收集服务中。日志收集服务会把这些日志转发到日志记录服务中,日志记录服务通过简单的日志加工汇总成为原始日志。在这个位置,通过实时的 ETL 把原始日志处理成标准的格式,比如说汇总成我们所需要的用户 ID 与商品 ID的关联,以及是否有曝光、点击、下单、购买行为,并形成中间层日志,用于各种实时任务。
同时,原始日志和中间层日志通过 Kafka 消息队列同步到 HDFS 中以备后面的离线分析。在上面的一个分支则是后端服务的日志采集,直接通过 Kafka 队列收集信息。实际上,除了前端产生的日志,后端服务同样也会产生各种日志信息,不过这里多用于服务运行状态的检测。
总结
凡是要进行数据的处理,就不得不涉及数据的获取。在当下的互联网公司中,大部分都是以网页、App、小程序为数据源,通过用户的访问日志进行数据的收集。在收集数据的时候,有很多方法,也有很多困难,但是我的建议是尽量选择那些能够保障数据一致性的方法,这样在后续的数据处理、数据应用环节才能够更加快速有效。如果你的日志收集工作没有做好,后面的数据就会一团乱麻,那么大数据体系将无从提起。
HDFS 基础
前面我们已经简单介绍过 HDFS,它可以利用廉价的普通服务器作为其存储,组建一个大规模存储集群,为各类计算提供数据访问的基础。那么 HDFS 的文件系统比起一般的文件系统有什么特色呢?其实 HDFS 文件系统最大的特色就是它在分布式架构上的处理,同时 HDFS 的设计适合一次写入,多次读出的场景,且不支持文件的修改,所以不适合反复修改数据的场景。
HDFS 的架构
在了解 HDFS 的整体架构前我们先来理解一下 HDFS 里的一些小知识。
(1)数据块
HDFS 默认最基本的存储单位是 64MB 的数据块(在 2.x 版本中是 128MB),大小通过配置可调。对于存储空间未达到数据块大小的文件,不会占用整个数据块的存储空间。
(2)元数据节点(NameNode)
元数据节点算是 HDFS 中非常重要的一个概念,用于管理文件系统的命令空间,将所有文件和文件夹的元数据保存在文件系统树中,通过在硬盘保存避免丢失,采用文件命名空间镜像(fs image)及修改日志(edit log)方式保存。
(3)数据节点(DataNode)
数据节点即是真正数据存储的地方。
(4)从元数据节点(Secondary NameNode)
从字面来看像是元数据节点的备用节点,但实际不然,它和元数据节点负责不同的事情,主要负责将命名空间镜像与修改日志文件周期性合并,避免文件过大,合并过后文件会同步至元数据节点,同时本地保存一份,以便在出现故障时恢复。
整体架构图如下所示:
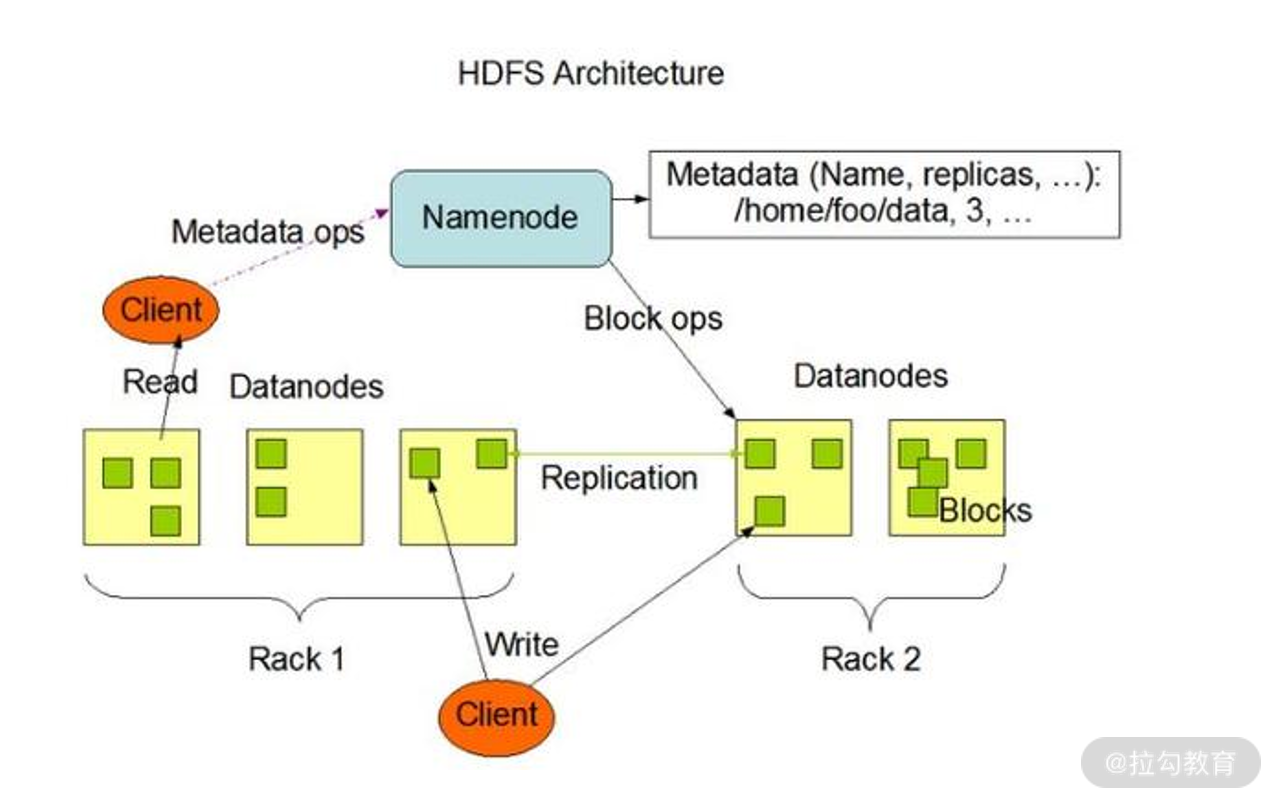
在架构图中,除了我们上述介绍的几种节点,还有一个 Client,即客户端。
客户端是我们平时用来和 HDFS 服务进行交互的部分,客户端中内置了一套文件操作命令来帮助我们访问 HDFS 服务,比如说我们上传文件、下载文件;
同时客户端还负责把我们上传的文件按前面说的数据块进行切分,以方便后续的存储;
因此,客户端当然也负责与 NameNode 和 DataNode 进行交互以获取文件位置或者读写文件操作等。
HDFS 的优缺点
1.优点
(1)高容错性。
在 HDFS 文件系统中,数据都会有多个副本。其中的某一个副本丢失(某一个节点的机器损坏)并不影响整体的使用,可以自动恢复。
(2)适合大数据处理。
数据规模:能够处理数据规模达到 GB、TB、甚至 PB 级别的数据;
文件规模:能够处理百万规模以上的文件数量,相当之大。
(3)提供数据一致性保障。
(4)任意一个节点所占用的资源较少,可以在廉价的机器上运行,支持线性扩张。
2.缺点
(1)不适合低延时数据访问,比如毫秒级的存储数据,是做不到的。
(2)无法高效地对大量小文件进行存储。
存储大量小文件的话,它会占用 NameNode 大量的内存来存储文件、目录和块信息。这样是不可取的,因为 NameNode 的内存总是有限的;
小文件存储的寻址时间会超过读取时间,它违反了 HDFS 的设计目标。
(3)不支持并发写入、文件随机修改。
对于一个文件,只能有一个线程写入,不可以多个线程同时写入。基本不能进行文件的修改,只支持数据的追加,如果想修改需要使用新文件覆盖整个旧的文件。
了解了 HDFS 的基本构成,下面进入我们的动手环节。因为 HDFS 已经集成在了 Hadoop 系统中,所以我们来尝试安装一个单节点的 Hadoop 系统,然后就可以进行 HDFS 操作了。
动手安装 Hadoop
首先介绍一下,我使用的机器操作系统是 Windows 10。因为 Hadoop 需要 Java 的支持,我们先看一下电脑上是否已经安装了 JDK,并且配置好了环境变量。
进入 CMD 命令提示符中,使用下面这个命令查看 Java 版本,如果显示正常,说明已经安装了 Java,并且配置了环境变量。
复制代码
C:\Users\userxxx>java -version
java version “1.8.0_231”
Java™ SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot™ 64-Bit Server VM (build 25.231-b11, mixed mode)
在 Windows 8 及以上版本,如果你的 Java JDK 安装在了 Program Files 路径下面,需要注意使用下面的方式来调整你的环境变量路径,否则我们的 Hadoop 配置会无法识别。
复制代码
用 “Progra~1” 替代 “Program Files”
用 “Progra~2” 替代 “Program Files(x86)”
由于在 Windows 系统下支持得并不是很好,原生的 3.2.1 版本可能需要做一些调整,我这里把调整好的项目放到了云盘上(提取码:k132),你可以下载我已经打包好的。
下载完,把文件解压到自己的电脑上,比如我这里是放在 D:\,打开 CMD 命令提示符,然后进入 Hadoop 的 bin 路径,如下所示:
复制代码
D:\hadoop-3.2.1\hadoop-3.2.1\bin>
使用命令 Hadoop Version,如果正常可以看到如下版本信息:
复制代码
Hadoop 3.2.1
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842
Compiled by rohithsharmaks on 2019-09-10T15:56Z
Compiled with protoc 2.5.0
From source with checksum 776eaf9eee9c0ffc370bcbc1888737
This command was run using /D:/hadoop-3.2.1/hadoop-3.2.1/share/hadoop/common/hadoop-common-3.2.1.jar
接下来我们需要修改几个配置文件,让 Hadoop 进行最基本的启动。
(1)修改 D:\hadoop-3.2.1\hadoop-3.2.1\etc\hadoop\core-site.xml 为:
复制代码
fs.defaultFS
hdfs://localhost:9820
(2)修改 D:\hadoop-3.2.1\hadoop-3.2.1\etc\hadoop\mapred-site.xml 为:
复制代码
mapreduce.framework.name
yarn
(3)修改 D:\hadoop-3.2.1\hadoop-3.2.1\etc\hadoop\hdfs-site.xml 为:
复制代码
dfs.replication
1
dfs.namenode.name.dir
file:///d:/hadoop-3.2.1/hadoop-3.2.1/data/dfs/namenode
dfs.datanode.data.dir
file:///d:/hadoop-3.2.1/hadoop-3.2.1/data/dfs/datanode
这里的 value 为 1 表明我们构建的系统只有一个节点,同时,定义了我们的 NameNode 根目录和 DataNode 根目录。
(4)修改 D:\hadoop-3.2.1\hadoop-3.2.1\etc\hadoop\yarn-site.xml 为:
复制代码
yarn.nodemanager.aux-services
mapreduce_shuffle
Yarn Node Manager Aux Service
然后输入 hadoop namenode -format,应该能看到这样的结果:
选择 Y,可以看到执行成功,如下图所示:
然后在 sbin 目录下输入 start-all,会有多个 CRM 窗口被创建,此时输入 jps,可以看到如下结果:
在浏览器中输入http://localhost:9870/dfshealth.html,你可以看到如下界面:
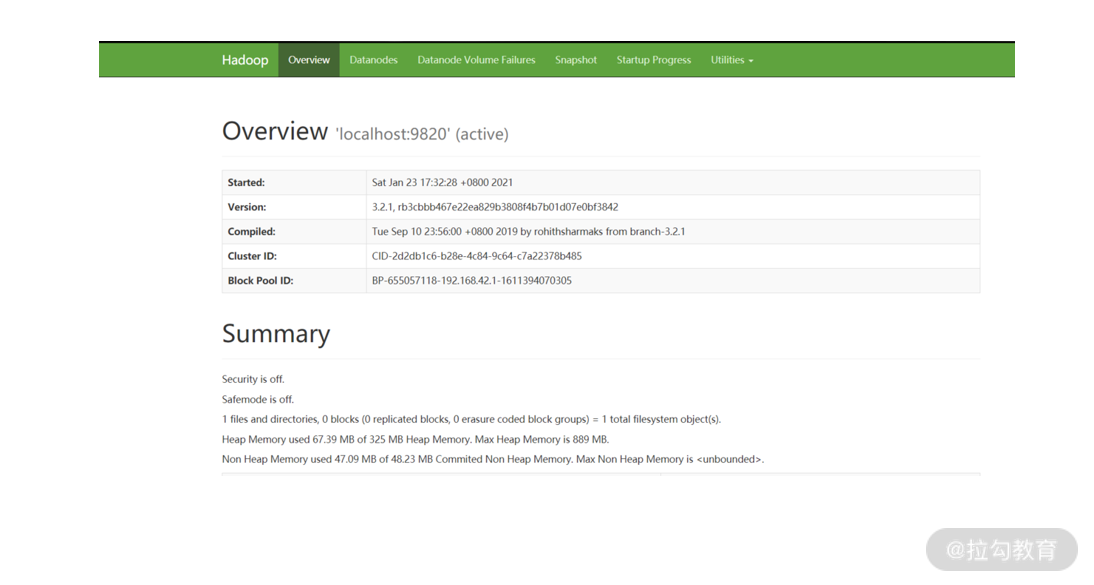
输入http://localhost:9864/datanode.html,你可以看到如下监控界面:
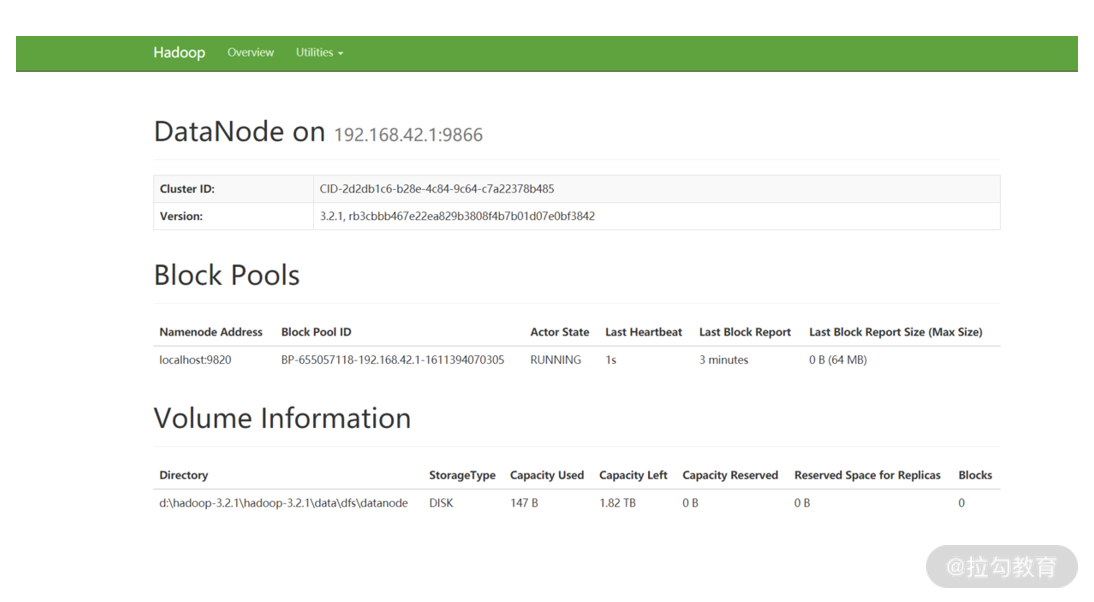
输入http://localhost:8088/cluster,你可以看到如下管理界面:

当年看到这些界面,说明已经部署成功了,我们已经创建了有 1 个节点的 Hadoop 系统。在课后,你可以尝试使用虚拟机来创建具有多个节点的 Hadoop 系统,那么在配置上会有什么不同呢,这个留给你自行探索。
如果你要关闭 Hadoop 服务,记得在 sbin 路径下使用命令:
复制代码
.\stop-all
接下来,我们使用已经部署好的 Hadoop 系统来进行一些 HDFS 的文件操作。
HDFS 简单使用
根据部署的服务,我们的 HDFS 根目录是 hdfs://localhost:9820,下面我们尝试在根目录下面创建子目录 user,如下命令所示:
复制代码
D:\hadoop-3.2.1\hadoop-3.2.1\bin>hadoop fs -mkdir hdfs://localhost:9820/user/
创建目录使用的是 mkdir,接着我们来列出根目录下面的详情,看是否创建成功了。详情如下所示:
复制代码
D:\hadoop-3.2.1\hadoop-3.2.1\bin>hadoop fs -ls hdfs://localhost:9820/
Found 1 items
drwxr-xr-x - LonnyHirsi supergroup 0 2021-01-23 17:49 hdfs://localhost:9820/user
可以看到,这里显示根目录下有一个项,就是我们刚创建的 user 目录。从这两个命令可以了解,HDFS 的文件操作命令与 Linux 的文件操作命令基本相同。
不过要注意,HDFS 中的路径只能一层一层创建,如果我们尝试下面的命令,会得到一个错误信息。
复制代码
D:\hadoop-3.2.1\hadoop-3.2.1\bin>hadoop fs -mkdir hdfs://localhost:9820/data/filedir
mkdir: `hdfs://localhost:9820/data’: No such file or directory
这是因为我们的根目录下面还没有 data 目录。
除了这些命令,HDFS 的操作还有:
显示文件内容的 cat 命令;
上传文件的 put 命令;
下载文件的 get 命令;
移动文件的 mv 命令;
删除文件的 rm 命令;
……
如果你需要学习这部分内容可以找一本相关的书籍进行更深入的学习,在这个课程中我们就不再过多地进行介绍了。
总结
这一讲我们讲解了 HDFS 文件系统,它是 Hadoop 体系两大核心基石之一,主要负责存储的部分。另外一部分解决计算问题的 MapReduce 我们会在《11 | MapReduce 处理大数据的基本思想有哪些》详细介绍。
在介绍了 HDFS 的基础架构之后,我们安排了一个实践环节,也就是动手安装 Hadoop 系统,当然我们这里安装的是单机单节点,希望你也能够亲自去尝试一下,甚至是用虚拟机搭建一个小型的多机环境以熟悉 Hadoop 的实际情况,在此过程中有任何问题,都欢迎与我进行交流。
课程的最后,简单介绍了 HDFS 的一些使用命令,可以看到跟我们平时在 Linux 系统中使用的文件处理命令基本相同,HDFS 帮我们屏蔽了后端存储的细节,让我们能够顺畅地使用。
Hive 的体系架构
上面这张图来自早期的 Hive 架构文档,分成两大部分,左侧是 Hive 的主体,右侧是Hadoop 系统,右上是 MapReduce,右下是 HDFS,中间有几条线连接,说明了 Hive 与 Hadoop 两大核心的关系。
(1)UI
用户界面,我们也可以认为是一个客户端,这里主要负责与使用者的交互,我们通过 UI 向系统提交查询和其他操作。当然,在 Hive 中还封装了 ThriftServer,我们可以在开发中使用 Java、 Python 或者 C++ 等语言来访问 Server,从而调用 Hive。
(2)驱动器(Driver)
驱动器在接收 HiveQL 语句之后,创建会话来启动语句的执行,并监控执行的生命周期和进度。在图中可以看到,驱动器既负责与编译器的交互,又负责与执行引擎的交互。
(3)编译器(Compiler)
编译器接收驱动器传来的 HiveQL,并从元数据仓中获取所需要的元数据,然后对 HiveQL 语句进行编译,将其转化为可执行的计划,按照不同的执行步骤拆分成 MapReduce 和 HDFS 的各个阶段的操作并发送给驱动器。
(4)执行引擎(Execution Engine)
在编译和优化之后,执行器将执行任务。它对 Hadoop 的作业进行跟踪和交互,调度需要运行的任务。
(5)元数据仓(Metastore)
元数据指的是我们构建的 Hive 表的表名、表字段、表结构、分区、类型、存储路径等等,元数据通常存储在传统的关系型数据库中,比如 MySQL。
Hive 的优缺点
Hive 的优点有很多,我主要从以下几个方面为你讲解。
(1)简单易上手
只需要了解 SQL 语言就可以使用 Hive,降低了使用 MapReduce 进行数据分析的难度,很多互联网公司都会使用 Hive 进行日志分析,比如说淘宝、美团等等,使用 Hive 统计网站的 PV、UV 等信息,简单便捷。
(2)Hive 提供统一的元数据管理
通过元数据管理可以实现描述信息的格式化,使得数据可以共享给 Presto、Impala、SparkSQL 等 SQL 查询引擎。
(3)可扩展性好
跟 Hadoop 的其他组件一样,Hive 也具备良好的可扩展性,只需要添加机器就可以部署分布式的 Hive 集群。
(4)支持自定义函数(UDF)
SQL 的功能虽然非常多,足够支撑我们平时常用的统计方案,但是对于一些个性化的定制方案,使用 SQL 明显要麻烦很多,Hive 支持使用自定义函数的方式来加入自己编写的功能,方便了开发人员。
当然 Hive 也是有缺点的。
(1)速度较慢
由于 Hive 的底层数据仍然是存储在 HDFS 上的,所以速度比较慢,只适合离线查询。在写程序时一般也是使用 Hive 来一次性加载数据,不适合在代码中反复访问。
(2)不支持单条数据操作
这个仍然是跟 HDFS 的存储相关,我们不能任意修改 HDFS 里的数据,所以 Hive 也不行,要想修改数据只能整个文件进行替换。
HBase
跟 Hive 不同,HBase 是一个在 Hadoop 大数据体系中应用很多的NoSQL 数据库,HBase 源于谷歌发表的论文:Bigtable。HBase 同样利用 HDFS 作为底层存储,但是并不是简单地使用原本的数据,只是使用 HDFS 作为它的存储系统。也就是说,HBase 只是利用 Hadoop 的 HDFS 帮助其管理数据的持久化文件。HBase 提供实时处理数据的能力,弥补了早期 Hadoop只能离线处理数据的不足。
HBase 的表结构
下图是 HBase 的表结构:

(1)行键(Row Key)
这是我们一行数据的唯一标识,比如说我们平时的数据都会有一个唯一 ID,就可以用来作为 Row Key。但是需要注意的是,HBase 在存储 Row Key 的时候是按照字典顺序存放的,所以如果你的 Row Key 不是以分布均匀的数字或字母开头的,很可能造成存储集中在某一台机器上,这会大大降低查询效率,所以这种时候需要设计存储的 Row Key,比如在每个 ID 的前面都加一个 HASH 值来提升查询性能。
(2)列簇(Column Family)
可以看作是一组列,实际上一个列簇的作用也是用来管理若干个列,优化查询速度。所以列簇的名字要尽量短,同时对于经常需要一起查询的列放在一个列簇下面。比如说对于用户信息,一个用户的静态属性(姓名、年龄、电话、地址等)可以放在一个列簇下面,动态属性(点赞、收藏、评论等)可以放在一个列簇下面。HBase表中的列簇需要预先定义,而列不需要,如果要新增列簇就要先停用这个表。
(3)单元(Cell)
指的是一个确定的存储单元。通过 Row Key、列簇 、列名以及版本号来确定。
(4)时间戳(Timestamp)
用来标记前面说的一份数据的不同版本。
(5)区域(Region)
一个 Region 可以看作是多行数据的集合。当一个表的数据逐渐增多,需要进行分布式存储,那么这个表就会自动分裂成多个 Region,然后分配到不同的 RegionServer 上面去。
HBase 的优缺点
HBase 的优势在于实时计算,所有实时数据都直接存入 HBase 中,客户端通过 API 直接访问 HBase,实现实时计算。由于它使用的是NoSQL,或者说是列式结构,从而提高了查找性能,使其能运用于大数据场景,这是它跟 MapReduce 的区别。
除此之外,它还有其他优点。
容量大性能高。一张 HBase 表可以支持百亿行、数千列的存储,而查询效率不会有明显的变化。同时 HBase 还可以支持高并发的读写操作。
列存储,无须设定表结构。对于传统数据库,比如 MySQL 是按行来存储的,检索主要依赖于事前建立的索引,在数据量很大的时候增加列或者更新索引都是非常缓慢的,而 HBase 每一列都是单独存储的,每一行每一列的那一个单元都是独立的存储,也就是数据本身即是索引。也因为如此,列可以在写入数据的时候动态地进行添加,而不需要在创建表的时候就设定。在具体存储时,每一行可能有不同的列。
而 HBase 不能支持条件查询,也不能用 SQL 语句进行查询。在使用的时候,一般只能使用Row Key 来进行查询。
HBase 与 Hive 的使用
在实际的工作中,HBase 与 Hive 在我们的大数据架构中实际上处于不同的位置,通常搭配来进行使用。
由于 HBase 支持实时随机查询的特性,主要使用 HBase 进行大量的明细数据的随机实时查询。比如说以用户 ID 为 Key 的用户信息,以 Itemid 为 Key 的商品信息、各种交易明细等等。在数据收集上来之后通过解析实时流然后存储到 HBase 中,以备查询。而在查询 HBase 的时候一般也是对整条数据进行查询。
就我们前面已经介绍的,Hive 本身并不解决存储的问题,它只是把 HDFS 中的结构化数据进行了展示,而最核心的功能是实现了对这些结构化文件的查询。在日常的工作中,通常使用 Hive分区表来记录一个时间段内的数据,并进行离线的批量数据计算,比如统计分析各种数据指标。
由于同为 Hadoop 体系的重要工具,Hive 与 HBase 也提供了一些访问机制。有时候我们希望能够在 Hive 中查询 HBase 的数据,可以通过关联外表的形式,在 Hive 上创建一个指向对应Hbase 表的外部表。
总结
在这一讲中,我比较简要地介绍了 Hadoop 体系里使用比较广泛的两个工具:Hive 与 HBase。表面上,它们都与 HDFS 存储有很强的关系,但是也有非常多的不同之处。它们所实现的功能和解决的问题也有很大的区别。在这一讲中,我主要是讲了它们的基本结构、优缺点和适用情况,没有涉及具体的使用。
云服务的好处
1.节约成本
使用云服务最大的好处就在于能够帮助你节约成本。像我们在讲的大数据体系,要想独立构建这样一套完整的体系需要很多的服务器资源、网络资源以及人力成本,直接使用云服务省去了自己构建的麻烦,只需要根据需求去进行应用就好了。
2.可扩展性
除了节约成本,可扩展也是云服务的一大好处。就像前面说的例子,在搞活动的时候我们可能需要比平时多十倍的机器和带宽,而在剩下的时间里,不需要那么多资源。而云服务的供应商有着充足的资源,当我们需要的时候,按需求进行扩展,比如说只购买一天的量来应对特殊的情况,而且这种扩展的成本往往都非常低,云服务供应商可以提供很好的无缝衔接。
3.紧跟最新技术
理所应当,如果使用云服务你就不需要关心升级和更新。云服务供应商对于技术方面往往都会做很多种版本的支持,这样你可以根据自己的需要进行选择。它会帮你配置好各种复杂的依赖,即使你想使用最新的版本也基本上可以得到满足,而不需要自己去解决细节问题。当然,在云服务的背后有强大的技术团队来进行支撑。
4.流动性
由于所有的操作都可以云端进行,比如你可以把数据放在云存储上,运算也可以使用云计算,甚至连交易平台也使用云上的服务,所以你只需要一个能够联网的设备,比如说笔记本,或者是一个 iPad,就可以进行办公。云服务使得流动性变得更好,你可以随时随地根据自己的需求进行连接。
5.故障恢复
你的云端设备可以匹配最佳的企业系统,如果服务器发生故障,它将自动将故障转移到另一台服务器,不会损坏你本来服务器的稳定性。在小型组织的 IT 环境中,这项技术是绝对无法实现的,因为实施这种故障转移将耗费巨大资金,并且消耗很多的时间。
Kafka 的结构与概念
经过了简短的介绍,我们大致可以了解 Kafka 是什么了,在 Kafka 的基本结构中,有两个重要的参与者:
消息的生产者(Producer);
消息的消费者(Consumer)。
如下图所示,Kafka 集群在消息的生产者和消费者之间建立起了联系的机制,来保障消息的运输。生产者负责生产消息,将消息写入 Kafka 集群,而消费者从 Kafka 集群中拉取消息,也可以称为消费消息。Kafka 所要解决的就是如何来存储这些消息,如何进行集群调度实现负载均衡,如何保障通信等等问题。
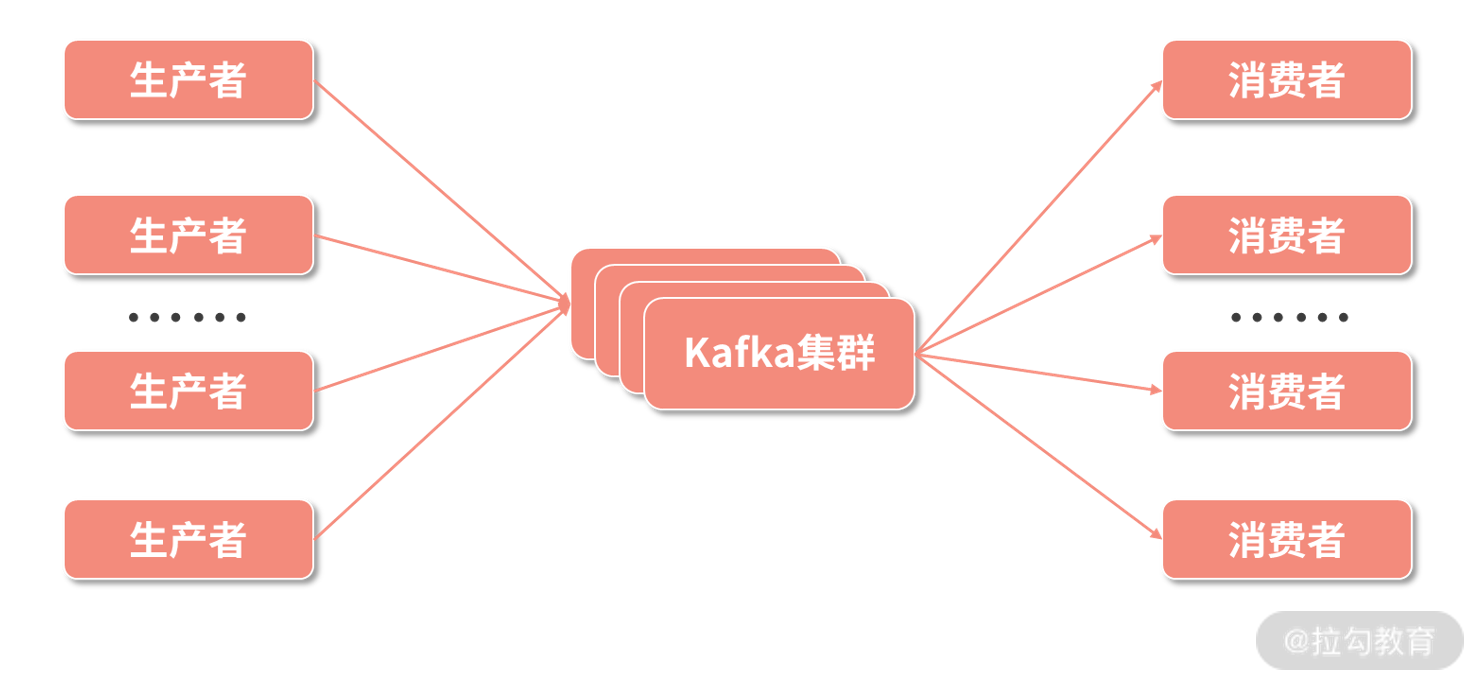
Kafka 集群的联系机制
接下来我们介绍几个 Kafka 中重要的概念。
1.生产者与消费者
生产者负责将消息发送给 Kafka,它可以是 App,可以是服务,也可以是各种 SDK。
而消费者则使用拉取的方式从 Kafka 中获取数据。
每一个消费者都属于一个特定的小组(Group),同一个主题(Topic)的一条消息只能被同一个消费组下某一个消费者消费,但不同消费组的消费者可同时消费该消息。依赖这个消费小组的理念,可以对 Kafka 中的消息进行控制,如果需要对消息进行多个消费者重复消费,那么就配置成多个消费组,而如果希望多个消费者共同处理一个消息源,那么就把这些消费者配置在一个消费组就可以了。
2.消息
消息就是 Kafka 中传输的最基本的单位,除去我们需要传输的数据,Kafka 还会给每条消息增加一个头部信息以对每一条消息进行标记,方便在 Kafka 中的处理。
3.主题(Topic)
上面我们说到了主题,在 Kafka 中,一个主题其实就是一组消息。在配置的时候一旦确定主题名称,生产者就可以把消息发送到某个主题中,消费者订阅这个主题,一旦主题中有数据就可以进行消费。
4.分区(Partition)和副本
在 Kafka 中,每个主题会被分成若干个分区。每个分区是一个有序的队列,是在物理上进行存储的一组消息,而一个分区会有若干个副本保障数据的可用性。从理论上来说,分区数越多系统的吞吐量越高,但是这需要根据集群的实际情况进行配置,看服务器是否能够支撑。与此同时,Kafka 对消息的缓存也受到分区和副本数量的限制。在 Kafka 的缓存策略上,一般是按时长进行缓存,比如说存储一个星期的数据,或者按分区的大小进行缓存。
5.偏移量
关于偏移量的概念,我们可以理解成一种消息的索引。因为 Kafka 是一个消息队列的服务,我们不能对数据进行随机读写,而是要按照顺序进行,所以需要给每条消息都分配一个按顺序递增的偏移量。这样消费者在消费数据的时候就可以通过制定偏移量来选择开始读取数据的位置。
在我们平时的数据开发工作中,更多的往往是作为生产者或者消费者来使用 Kafka,而不需要关注 Kafka 系统的部署和维护,感知比较明确的就是上面说到的这些概念,基本都是我们在代码中需要进行配置的。当然,在 Kafka 中还有一些基本组成部分,比如代理、ISR 以及对 ZooKeeper 的使用等,如果你对 Kafka 有更加深入的学习需求,可以进一步查看这些内容。在我们加入了上面这些组成元素之后,我们再来看一下 Kafka 的结构图。
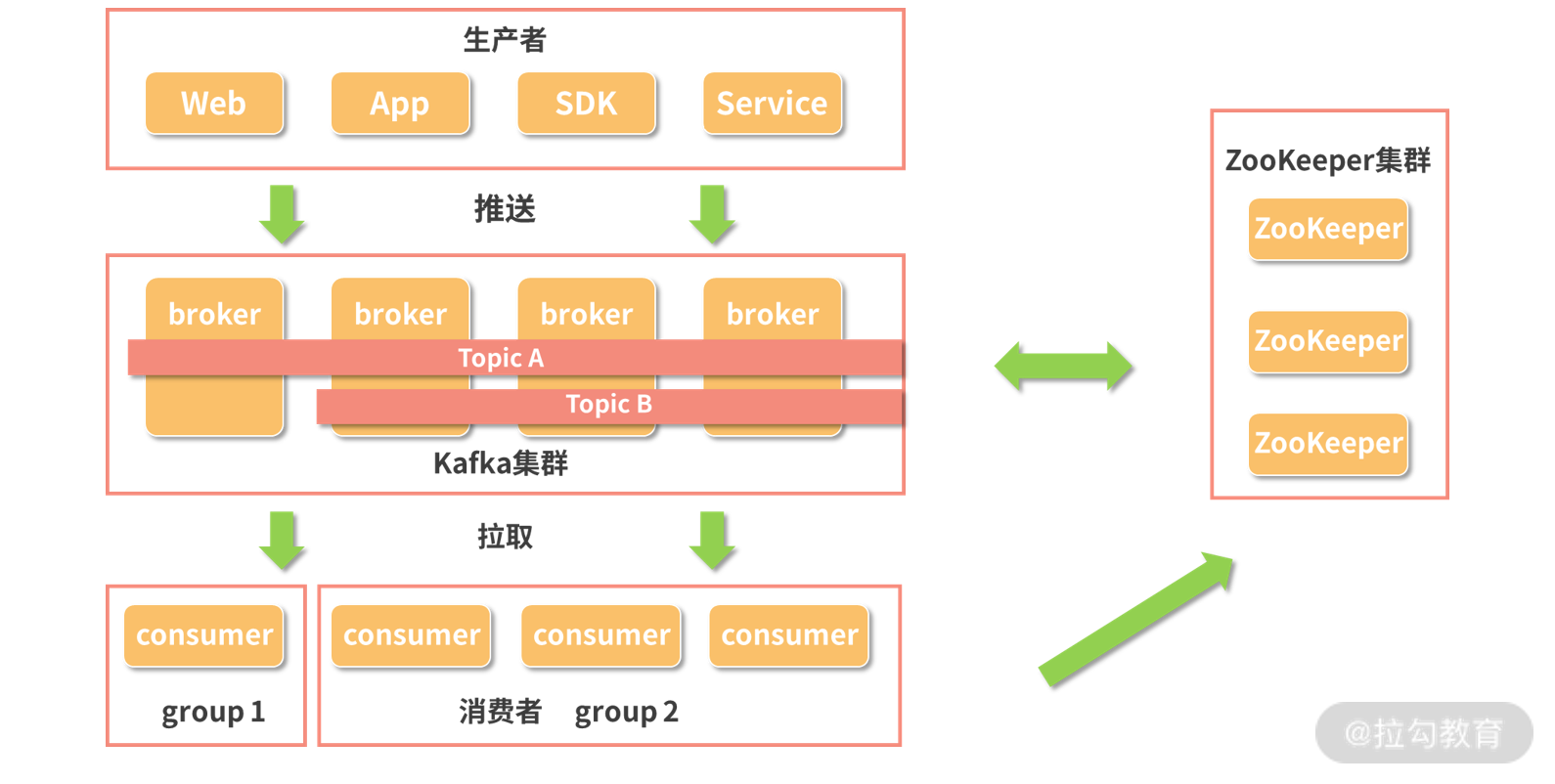
Kafka 的结构图
大致的流程为,生产者生产数据,然后把数据推送到 Kafka 集群中,并确定数据流的主题。Kafka 集群配合 ZooKeeper 集群完成调度、负载均衡、缓存等等功能,等待消费者消费数据。
Kafka 的特点
经过不断发展,Kafka 已经成为主流的消息队列工具,类似的工具还有 RabbitMQ、Redis 消息队列、ZeroMQ、RocketMQ 等等。
我们在前面说过,Kafka 最大的特色就是“削峰填谷”,这是它在应用上的特点,这里的谷和峰指的是数据流量的谷和峰,削峰填谷的含义即在数据生产方 A 和数据消费方 B 对数据流量的处理能力不同的时候,我们就可以使用 Kafka 作为中间传输的管道。那么在具体的设计上,Kafka 有什么特点呢,接下来让我们看一下。
1.消息持久化
Kafka 选择以文件系统来存储数据。很多消息系统为了提升大规模数据处理和快速传输的能力,并不会对数据进行持久化存储,或者只是缓存非常少量的数据,而 Kafka 会把数据存在磁盘上,一方面是磁盘的存储容量大,另外一方面是经过持久化的数据可以支持更多的应用,不管是实时的还是离线的,都可以进行支持。
2.处理速度快
为了获得高吞吐量,Kafka 可是下了不少功夫。我们知道硬盘是使用物理磁头来进行数据读写的,通常磁盘的速度都以转数来描述,比如 5400 转、7200 转。因为随机寻址的话,需要通过转动移动到下一个地址。但是由于 Kafka 是队列的形式,创造性地对磁盘顺序读写,大大增加了磁盘的使用效率,既获得了大存储量,又提高了速度。同时 Kafka 中还加入了很多其他方面的优化,比如通过数据压缩来增加吞吐量、支持每秒数百万级别的消息。
3.扩展性
与大数据体系中的其他组件一样,Kafka 也同样支持使用多台廉价服务器来组建一个大规模的消息系统,通过 ZooKeeper 的关联,Kafka 也非常易于进行水平扩展。
4.多客户端支持
前面我们也提到了,Kafka 支持非常多的开发语言,比如 Java、C/C++、Python、Go、Erlang、Node.js 等。
- Kafka Streams
Kafka 在 0.10 之后版本中引入 Kafka Streams,能够非常好地进行流处理。
什么是 Flume
简单介绍完了 Kafka,我们再来看一下另外一个工具 Flume。
我们先回忆一下数据采集的过程:作为前端用户使用的客户端,不管是 App、网页还是小程序,在用户使用的时候,会通过 HTTP 链接把用户的使用数据传输到后端服务器上,服务器上运行的服务把这些回传的数据通过日志的形式保存在服务器上,而从日志到我们将数据最终落入 HDFS 或者进入实时计算服务中间还需要一些传输。
当然,这个过程有很多种实现方法,比如说在 Java 开发中,我们可以借助 kafka-log4j-appender 类库把 log4j(日志记录类库)记录的日志同步到 Kafka 消息队列,由 Kafka 传输给下游任务。然而这种方式比较简陋,并不太适合大规模集群的处理,因此,这里就有一个日志采集工具,那就是 Flume。
Flume 是一个高可用、分布式的日志收集和传输的系统。Flume 有源(Source)、通道(Channel)和接收器(Sink)三个主要部分构成。这三个部分组成一个 Agent,每个 Agent都是独立运行的单位,而 Source、Channel、Sink 有各种不同的类型,可以根据需要进行选择:
Channel 可以把数据缓存在内存中,也可以写入磁盘;
Sink 可以把数据写入 HBase;
HDFS 也可以传输给 Kafka 甚至是另外一个 Agent 的 Source。
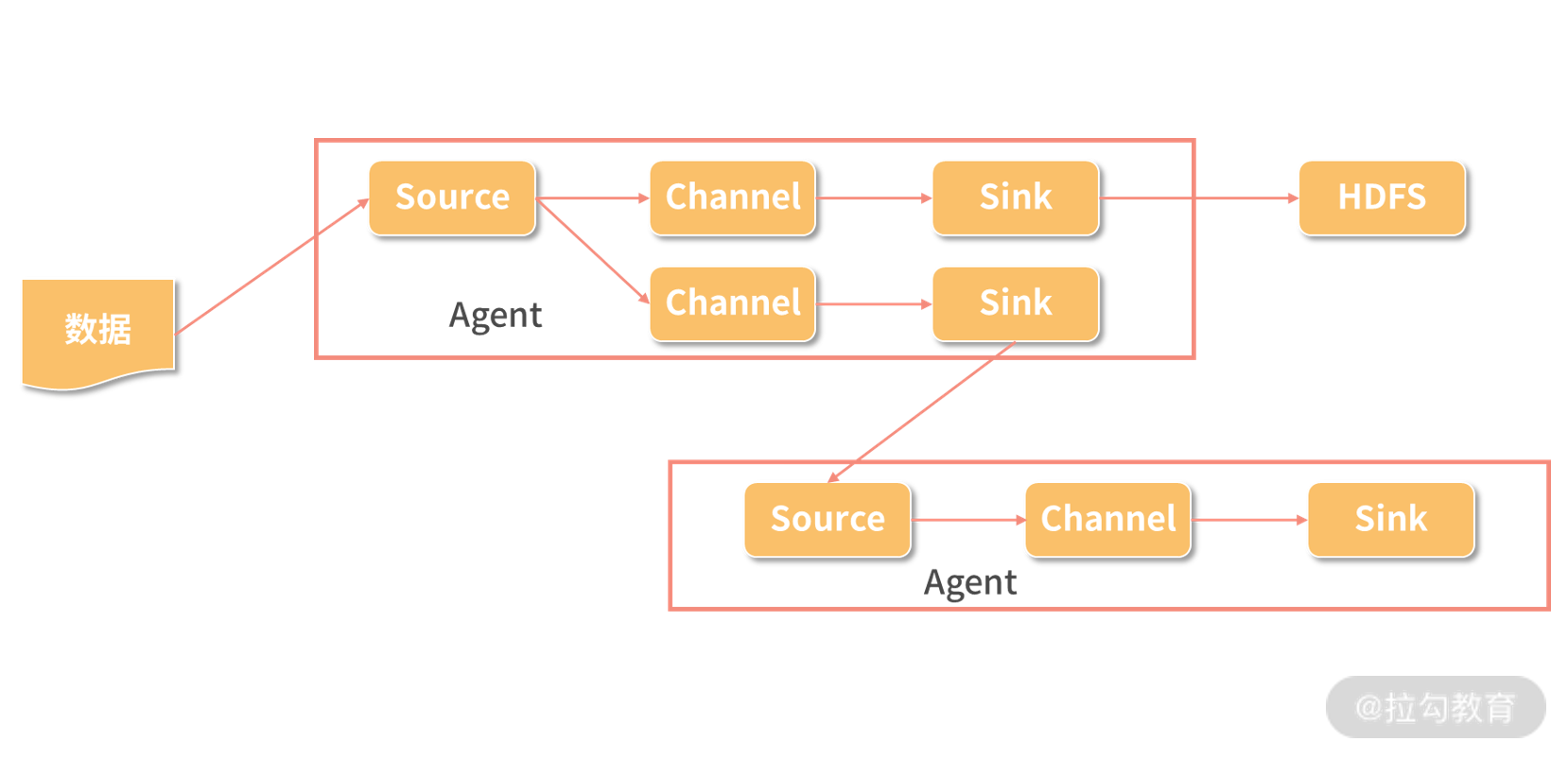
Flume 中的概念
1.源(Source)
Source 是负责接收输入数据的部分,Source 有两种工作模式:
主动去拉取数据;
等待数据传输过来。
在获取到数据之后,Source 把数据传输给 Channel。
2.通道(Channel)
Channel 是一个中间环节,是临时存储数据的部分,Channel 也可以使用不同的配置,比如使用内存、文件甚至是数据库来作为 Channel。
3.接收器(Sink)
Sink 则是封装好的输出部分,选择不同类型的 Sink,将会从 Channel 中获取数据并输出到不同的地方,比如向 HDFS 输出时就使用 HDFS Sink。
4.事件(Event)
Flume 中传递的一个数据单元即称为事件。
5.代理(Agent)
正如我们前面介绍的,一个代理就是一个独立的运行单元,由 Source、Channel 和 Sink 组成,一个 Agent 中可能有多个组件。
Kafka 与 Flume 的比较
可以看到,在数据传输方面,Flume 和 Kafka 的实现原理比较相似,但是这两个工具有着各自的侧重点。
Kafka 更侧重于数据的存储以及流数据的实时处理,是一个追求高吞吐量、高负载的消息队列。
而 Flume 则是侧重于数据的采集和传输,提供了很多种接口支持多种数据源的采集,但是 Flume 并不直接提供数据的持久化。
就吞吐量和稳定性来说,Flume 不如 Kafka。所以在使用场景上,如果你需要在两个数据生产和消费速度不同的系统之间传输数据,比如实时产生的数据生产速度会经常发生变化,时段不同会有不同的峰值,如果直接写入 HDFS 可能会发生拥堵,在这种过程中加入 Kafka,就可以先把数据写入 Kafka,再用 Kafka 传输给下游。而对于Flume 则是提供了更多封装好的组件,也更加轻量级,最常用于日志的采集,省去了很多自己编写代码的工作。
由于 Kafka 和 Flume 各自的特点,在实际的工作中有很多是把Kafka 和 Flume 搭配进行使用,比如线上数据落到日志之后,使用 Flume 进行采集,然后传输给 Kafka,再由 Kafka 传输给计算框架 MapReduce、Spark、Flink 等,或者持久化存储到 HDFS 文件系统中。
MapReduce 的架构
如果理解了上面的小例子,你也就理解了 MapReduce 的基本理念。MapReduce 即是采用了这种分而治之的处理数据模式,将要进行的数据处理任务分成 Map(映射)和 Reduce(化简)这两个处理过程。
在 Map 操作中进行数据的读取和预处理,把国家划分成地区,然后一个负责人负责一个片区,这就是 Map。统计之后负责人一起汇总结果,这就是 Reduce。
这样做最大的好处就是可以把大规模数据分布到普通性能的服务器中进行预处理,然后将处理后的结果重新进行整合,从而得到需要的结果。当然,要让这么多机器共同完成一项任务,还有很多细节的问题需要处理。
除了计算本身,MapReduce 还解决了协调这些集群中的服务器的问题,比如在若干台机器中执行运算的顺序、计算压力的分配、操作的原子性等等,如果让我们自己去编写一套程序那将是一个非常复杂的系统。但是 MapReduce 解决了这些问题,我们只需要关注如何把问题拆解成 Map 部分和 Reduce 部分就可以了。
跟 HDFS 一样的,MapReduce 也是采用主从结构的架构,架构图如下所示:
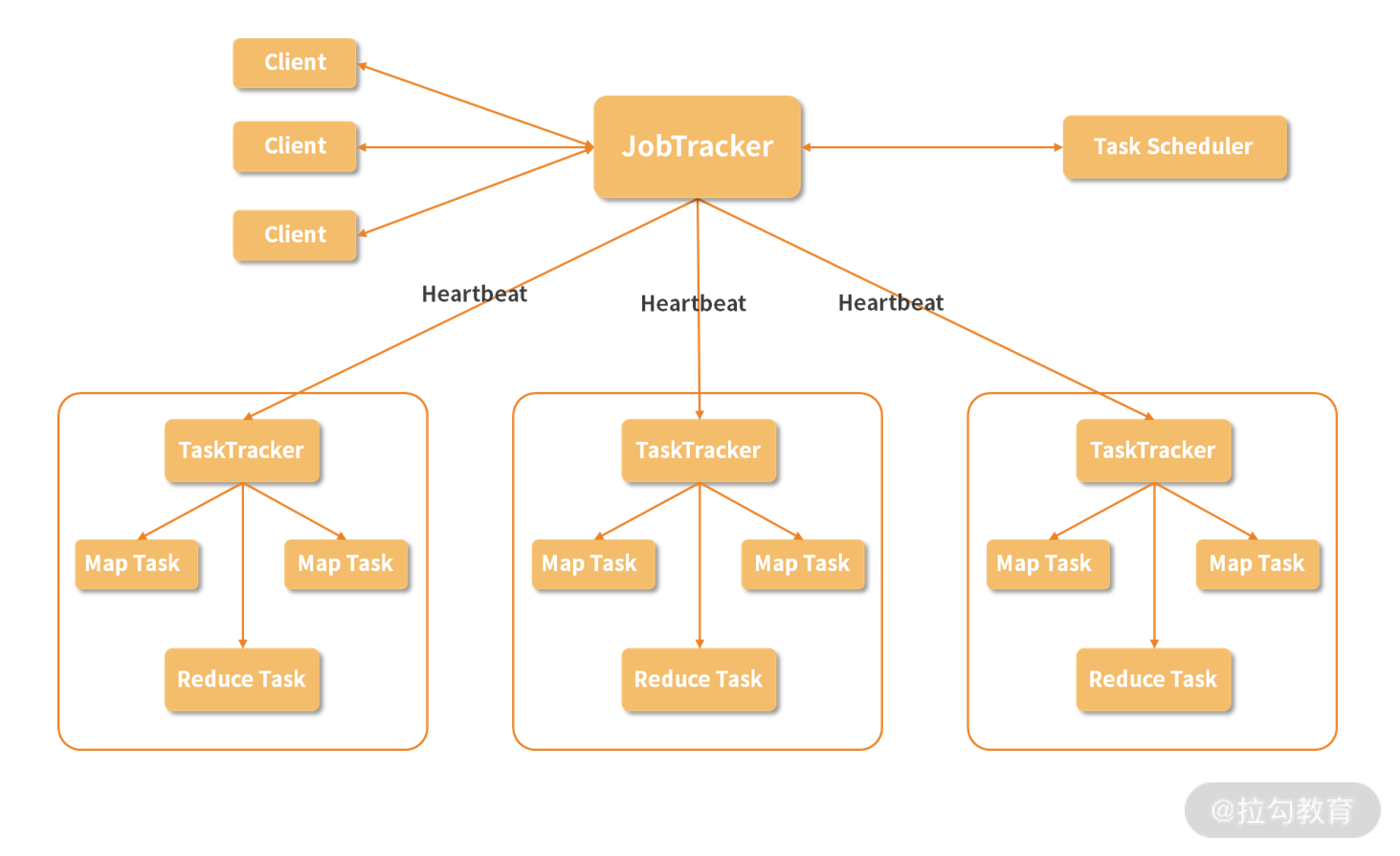
1.Job
Job 即是作业,一个 MapReduce 作业是用户提交的最小单位,比如说我们在下面即将动手运行的 WordCount 运算就可以称为一个作业。
2.Client
Client 就是客户端,是用户访问 MapReduce 的接口,通过 Client 把编写好的 MapReduce 程序提交到 JobTracker 上。
3.JobTracker
在 MapReduce 中,为了实现分布式的管理架构,使用了领导和随从的模式。而 JobTracker 就是这个体系中的领导。一个 MapReduce 集群只有一个JobTracker,这个节点负责下发作业,同时,它要收听来自很多 TaskTracker 的状态信息,从而决定如何分配工作。在这个集群中,JobTracker“既当爹又当妈”,而且只有一个,存在单点故障的可能,必须给它安排一个好点、稳定点的机器,不然如果它罢工了,将导致集群所有正在运行的任务全部失败。
4.TaskTracker
TaskTracker 在集群中则扮演了随从的角色,主要负责执行 JopTracker 分配的任务,同时 TaskTracker 通过 Heartbeat(心跳信息)汇报当前的状态,JobTracker 根据这些状态再进行任务的分配。随从是具体负责工作的,人多力量大,一个集群自然可以有多个 TaskTracker。在一个实际的节点上,会有一个 TaskTracker ,还有我们在 HDFS 环节介绍的 DataNode,这样,一个节点既是计算部分又是存储部分,在进行运算时,可以优先进行本机数据本机计算,从而提升效率。
5.Task
Task 称为任务,是在 MapReduce 实际计算时的最小单位,Task 有两种:MapTask 和ReduceTask,由 TaskTracker 进行启动。
6.Split
除了在图中出现的概念,还有一个 Split,称为一个划分,这是 MapReduce 处理的元数据信息,Split 会记录实际要处理的数据所在的位置、大小等等。在《07 | 专为解决大数据存储问题而产生的 HDFS》中,我们介绍了数据块的概念,Split 实际的数据就存储在 HDFS 的数据块中,通常我们会把 Split 的大小设置成与数据块大小一致,每次需要处理的数据存放在一个位置,这样可以减少不必要的网络传输,节约资源,提升计算速度。
了解完这么多概念,我们再回顾一下整个处理流程:
我们编写一个 MapReduce 程序,这可以称为一个 Job,在这个程序中往往包含较多的 Map 操作,和较少的 Reduce 操作;
通过 Client 把 Job 提交到 JobTracker 上,JobTracker 会根据当前集群中 TaskTracker 的状态,分配这些操作到具体的 TaskTracker上;
TaskTracker 启动相应的 MapTask 或者 ReduceTask 来执行运算。
在具体的运算中,MapTask 读取 Split 的数据,根据事先写好的程序对其中的每一条数据执行运算,比如说后面的单词计数代码,我们输入的是若干文本文件,Map 操作处理每一行文本,并为一行中的单词进行计数,然后把结果保存下来。而在 ReduceTask 中,获取之前 Map 的预处理结果,并对数据进行分组,比如说相同单词分为一组,然后进行加和运算。对于 Reduce 的输出结果,会存储三个副本。
MapReduce 的特点
1.简化了分布式程序的编写
就像我们前面介绍的,MapReduce 解决了很多分布式计算的底层问题,使得开发者不用关心复杂的调度和通信问题,只把精力放在如何实现 MapReduce 过程就可以了。
2.可扩展性强
这是大数据处理框架的通用特点,只需要使用普通的机器就可以解决大规模数据处理的问题,当资源不足时只需要增加普通的机器节点就可以解决问题。
3.容错性强
在集群中,避免不了各种节点的故障问题,但是 MapReduce 会自动地处理这些问题,屏蔽故障节点,使用正常的节点重新处理问题,这些都不需要使用者关心,直到任务处理完毕。
MapReduce 的硬伤
虽然说 MapReduce 有非常多的好处,但是它的硬伤同样明显。
1.学习成本高
虽然说 MapReduce 已经处理了大量的分布式问题,但是仅仅是统计一些数据也要完全理解 MapReduce 的思想,学习编写一个 MapReduce 程序,这对于很多人是非常不友好的。我们前面讲到的 Hive 就是为了减轻这种问题而产生的,但是 MapReduce 仍然是非常底层的技术,而且不是所有的算法都可以使用 MapReduce 来实现,很多功能无法使用这种并行的方式来解决。
2.时间成本过高
MapReduce 是纯粹的批处理模式,也就是说所有的数据都是事先已经存储好的,MapReduce 只是对这些数据进行批量的处理,这对于互联网中大量的流式数据无法给到很好的支持,如果我们想要处理今天的数据,要等到今天的数据都已经存储好再进行计算,而不能随来随算。同时, MapReduce 的所有中间结果都是存放在磁盘中的,网络传输这些数据和磁盘读写消耗了大量的时间。
动手环节
首先需要注意的是,我们的试验是在 Windows 10 中进行的,如果你使用的不是管理员账户,在运行 Hadoop 命令时没有创建符号表的权限,这会导致我们执行例子程序出错,可行的解决方式有两种:
因为默认管理员可以创建符号表,可以使用管理员命令行启动 Hadoop 的应用;
使用 win 键 + R 调出运行,输入 gpedit.msc,在【计算机配置】-【Windows 设置】-【安全设置】-【本地策略】-【用户权限分配】-【创建符号链接】中加入你使用的用户组,然后重启系统使之生效。
修改配置文件
在 D:\hadoop-3.2.1\hadoop-3.2.1\bin\ 目录下创建一个 input 文件夹,并创建 3 个 txt 文件,在每个 txt 文件中随便写一些内容,我这里写入:
f1.txt:hello world
f2.txt:hello hadoop
f3.txt:hello mapreduce
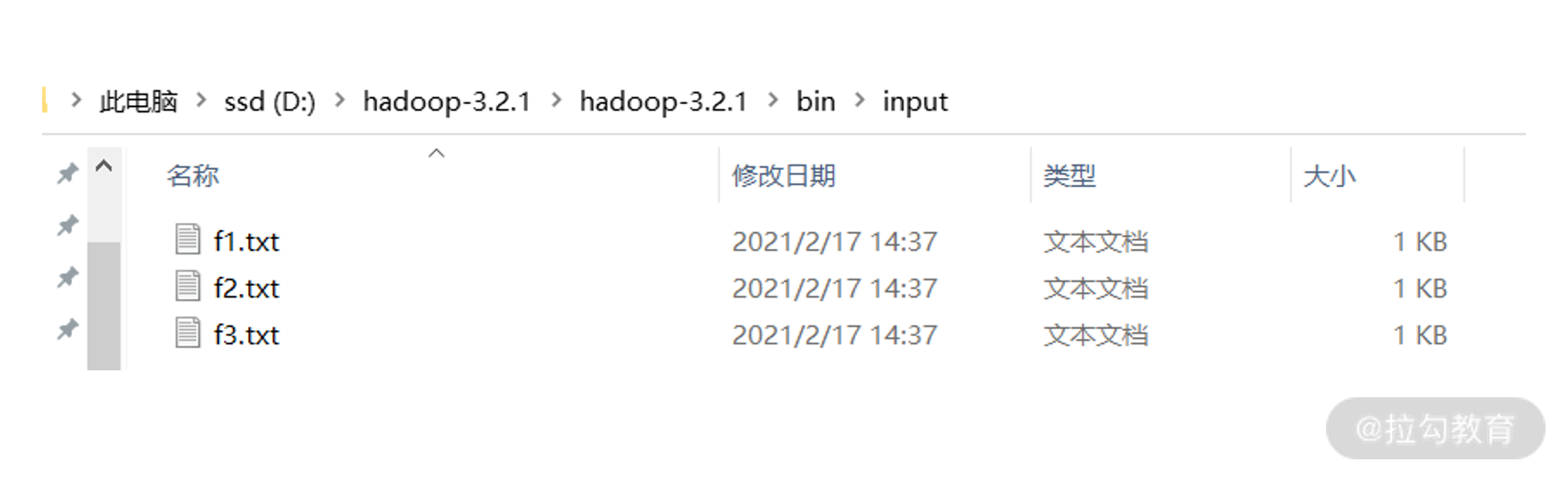
创建好之后,照着我们之前在 07 节中讲的方式启动 Hadoop,然后在 HDFS 上创建 input 路径:
复制代码
hadoop fs -mkdir /input
把刚才新建的三个文件从本地存储到 HDFS 中去:
复制代码
hadoop fs -put input/f1.txt /input
hadoop fs -put input/f2.txt /input
hadoop fs -put input/f3.txt /input
然后查看是否已经上传成功:
复制代码
hadoop fs -ls /input
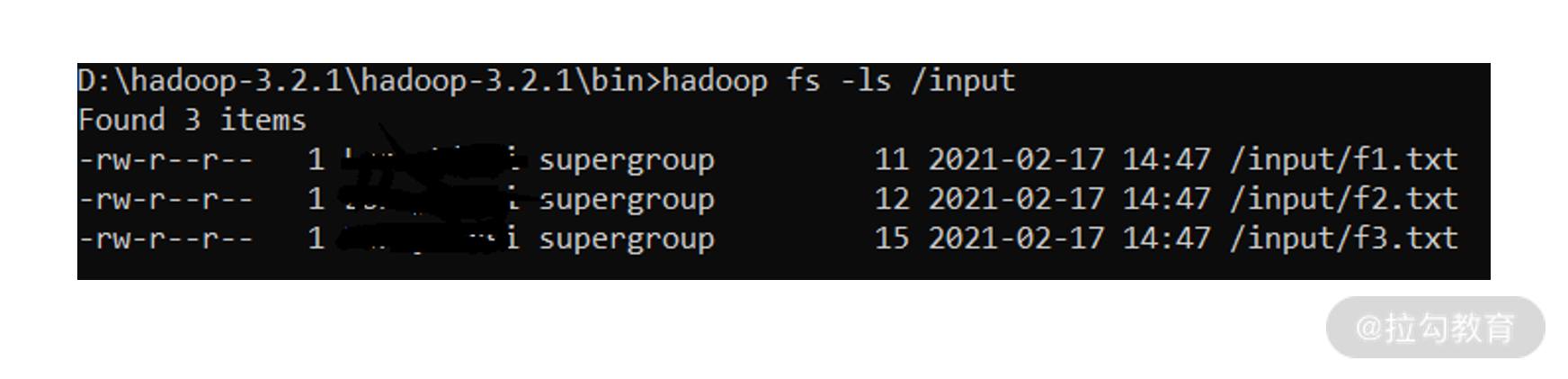
我们也可以通过前面介绍的监控页面(http://localhost:9870/dfshealth.html#tab-overview)来查看 HDFS 上的文件,通过最右侧 Utilities 下面的Browse the file system 即可。
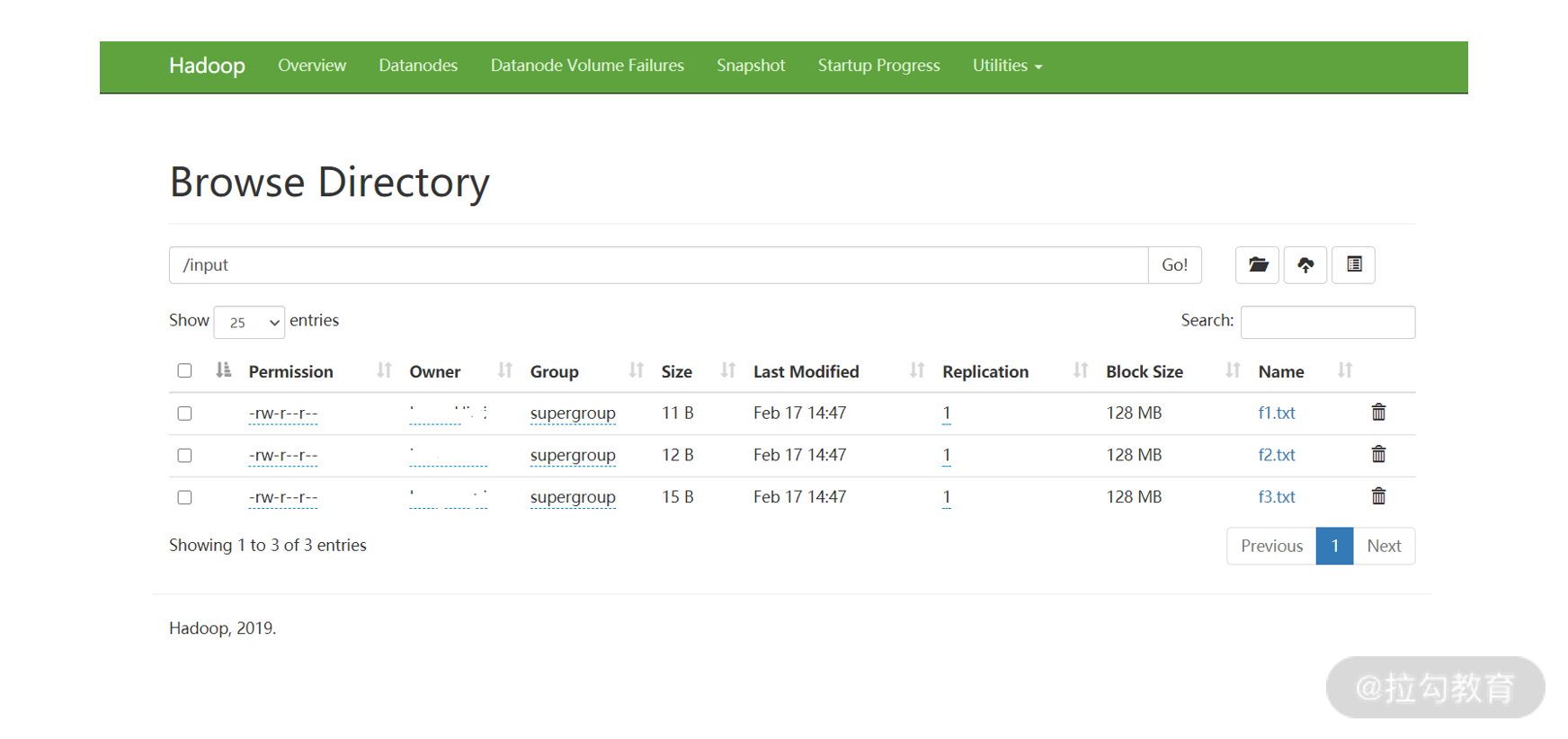
接下来我们使用命令来执行 WordCount 程序:
复制代码
hadoop jar …/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output
注意,jar 后面的第一个参数是要执行的 jar 包路径,第二个参数是选择 jar 包中的程序,第三个参数是 HDFS 上的输入目录,最后一个参数是输出目录,由于 WordCount 的代码中会去创建输出路径,所以我们不需要提前创建好。
如果执行成功,我们可以通过输出的日志看到 MapReduce 过程执行完成,如下图所示:
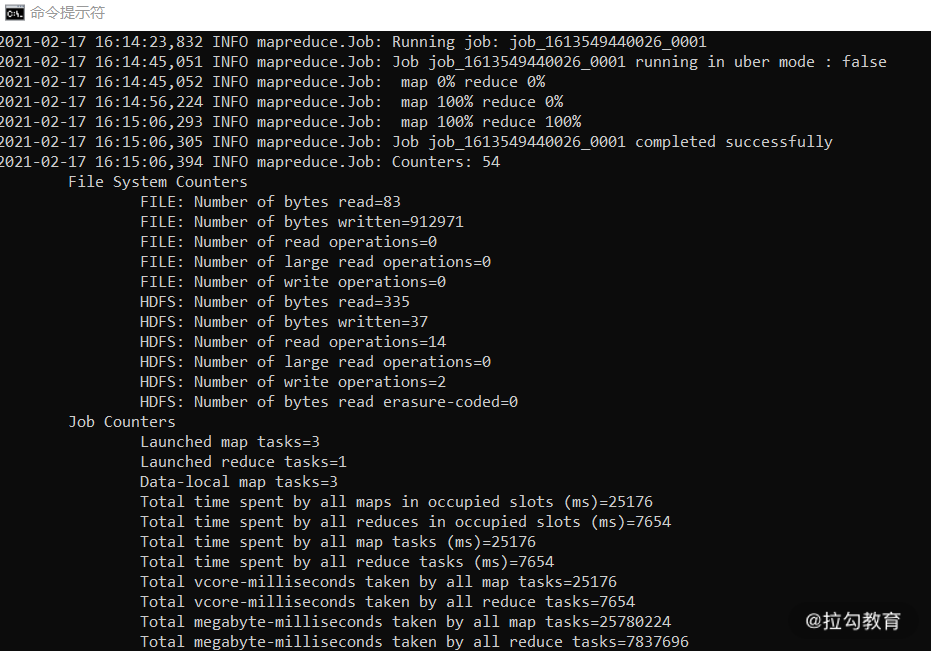
执行成功之后,我们查看 output 路径下的结果:
复制代码
hadoop fs -cat /output/part-r-00000
你可以看到如下结果:
复制代码
hadoop 1
hello 3
mapreduce 1
world 1
这一结果已经对我们文本中出现的单词数量进行了统计。
总结
这一讲,我们介绍了 Hadoop 中的另一个核心模块 MapReduce,并且动手运行了一个示例程序。MapReduce 的思想虽然非常强大,但是从 MapReduce 的硬伤可以看出来,MapReduce 已经不太适合互联网的需求,在实际的应用中,现在 MapReduce 已经被更加强大计算框架所替代,比如 Spark 和 Flink。
什么是 Spark
打开 Spark 的官网,我们看到的第一句话就是对 Spark 的定义:Spark 是用于大规模数据处理的通用分析引擎。当然,原文是英文的,这句是我翻译过来的。这句话非常简洁明了地讲解了 Spark 的功能,一个是针对大规模数据,一个是通用分析引擎。
让我们简单回顾一下 Spark 的发展历程。
在 2009 年,加州大学伯克利分校的 RAD 实验室(AMP 实验室前身)推出了 Spark 框架,并表明 Spark 是一个类似 MapReduce 的通用并行框架,可用来构建大型的、低延迟的数据分析应用程序。实验室的研究人员在使用 MapReduce 时发现它在迭代计算和交互计算上效率低下,于是开始设计 Spark。很快,Spark 在一些任务上的效率就已经比 MapReduce 提升了 10 倍以上。
这里需要提到 Spark 的一个特点,那就是低延迟。从一开始 Spark 就瞄准了低延迟这样一个目标,这也为它后来能够进入工业界并广泛地应用于生产奠定了基础。
在 2013 年的时候,Spark 项目加入了 Apache,并在 2014 年的 Gray sort Benchmark 比赛上全面超越了 Hadoop 拿下了当年的冠军。这个比赛是对 100TB 的数据进行排序操作:
Spark 使用了 206 台 EC2 机器在 23 分钟内完成了操作;
而 Hadoop 的 MapReduce 则使用了 2100 个机器并耗费了 72 分钟。
在后来的一段时间里,Spark 在互联网公司的大数据架构中逐渐成为主流计算框架。
Spark 的特色
在 Spark 的官网上我们也可以看到,Spark 的特色有五个方面。
(1)高速
Spark 使用了最新的 DAG 调度方案,查询、优化和物理执行引擎,在批处理和“流”处理上都表现优异。这里,我给“流”处理加了引号,在后面我们会解释为什么这里会加一个引号。在官方给出的示例中,在 Spark 框架中执行逻辑回归运算要比 MapReduce 快一百多倍。
(2)易用
Spark 提供了 80 多种高阶操作,构建应用更加方便。Spark 还提供了多种语言支持,使用 Java、Scala、Python、R 甚至是 SQL 都可以非常容易地编写 Spark 程序。
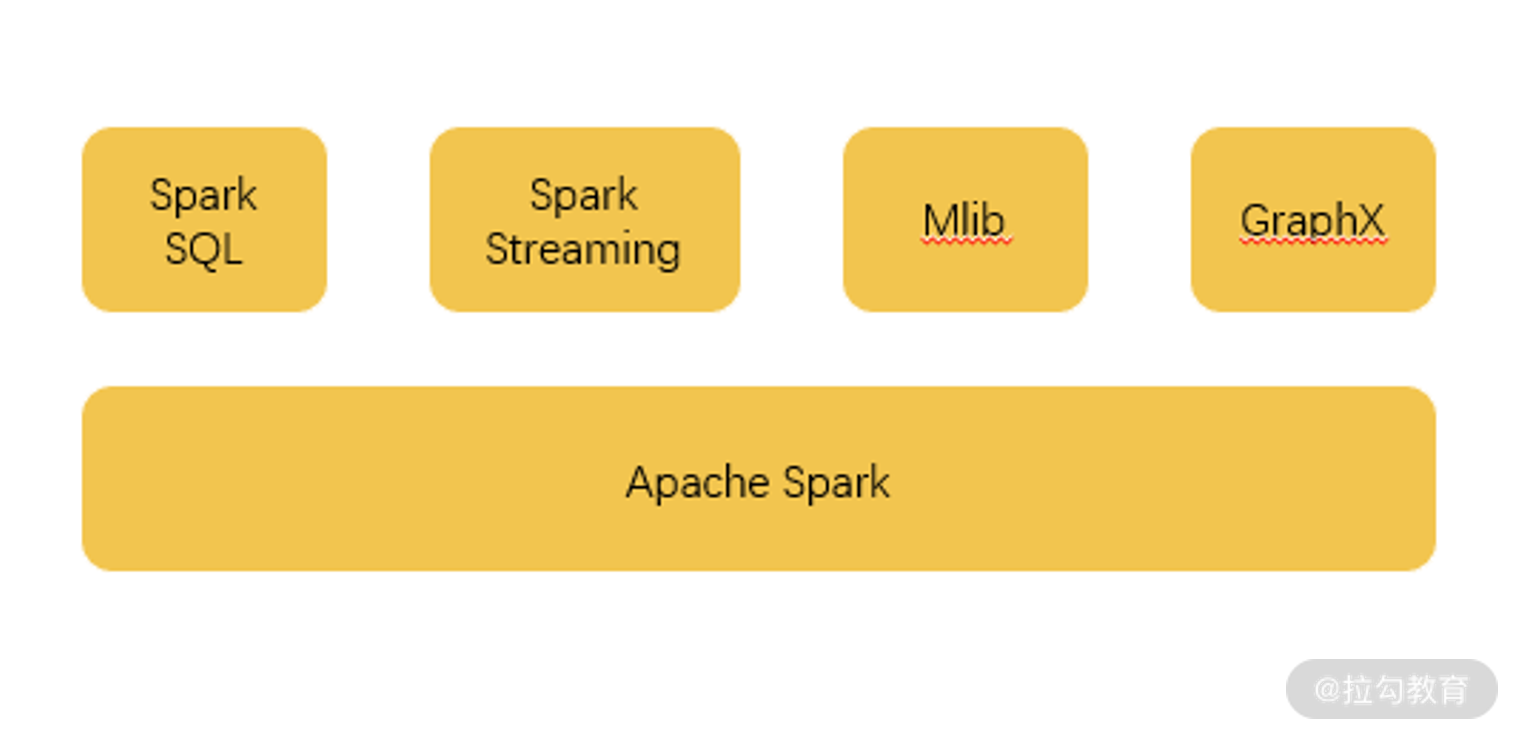
(3)通用
如下图所示,Spark 除了提供计算框架以外还整合了 SQL、流式处理,以及机器学习算法库和图操作算法库。其中 Spark SQL 支持使用 HiveQL 和 Spark 进行交互。
(4)多平台支持
Spark 本身是可以独立运行的,当然,它也可以运行在 Hadoop、Mesos、Kubernetes,甚至是云平台上。它还支持访问各种不同的数据源,比如 HDFS、HBase、Hive、Cassandra 都是可以的。
(5)内存化
这点在官网上没有,但是很重要。在运算流程上,Spark 和 MapReduce 基本上是一致的,但是有一个很大的不同就是中间结果的存储:
MapReduce 所有的中间结果都是保存在磁盘上;
而 Spark 的中间结果是保存在内存中的。
这你也就明白了为什么 Spark 的运算速度要快那么多,内存起到了很重要的作用,同样的,由于使用内存存储, Spark 处理的数据规模相对来说就会小一些,但是幸运的是现在内存也不是很贵,公司也都愿意多花点钱从而节约点时间。
Spark 基础
RDD
RDD 是 Resillient Distributed Dataset(弹性分布式数据集)的简称,它是 Spark 的一个基本数据结构,也是Spark 最核心的数据结构。
Spark 在运行时,会将 RDD 分割成不同的 Partition(分区),并把这些分区投放到不同的计算节点下面,进行并行运算。实际上,Spark 程序的整个生命流程,就是对这些数据的处理,创建 RDD、转换 RDD、调用 RDD 操作计算各种结果等。所以,理解了 RDD 的各种操作基本上就了解了 Spark 的核心,对这部分感兴趣的同学可以寻找更多的资料来进行学习。
两种操作
在我们的运算中,通常包含两种操作,一个是Transformation(转换操作),一个是Action(行动操作)。这两个操作最大的区别是 Spark 对它们的处理逻辑是不一样的。
对于转换操作,比如说 Filter(过滤),这些操作是对 RDD 本身的一些操作,其结果是数据的规模发生变化,而数据的类型或者说内容不会发生变化。
对于这种操作 Spark 是进行惰性运算,也就是说 Spark 只是记录下这个操作,而不会真的去执行它。只有当 Spark 遇到了行动操作,才会把之前的转换操作进行统一的处理,我们可以认为行动操作是一些产生结果的操作,它的输出是非 RDD 对象。这么做的好处是减少了不必要的存储开销,毕竟 Spark 是使用内存来进行中间结果的存储。
这么说可能有点迷茫了,我们写两行代码再来解释一下。
val RDD1 = sc.textFile(“data.txt”)
val RDD2 = RDD1.map(x => x+1)
val RDD3 = RDD2.filter(lambda x: “Python” in x)
val RDD4 = RDD3.reduceByKey((x,y) => x + y)
val RDD5 = RDD2.filter(lambda x: “Java” in x)
RDD5.count
根据这几行代码,我们可以得出如下图的一个执行逻辑。
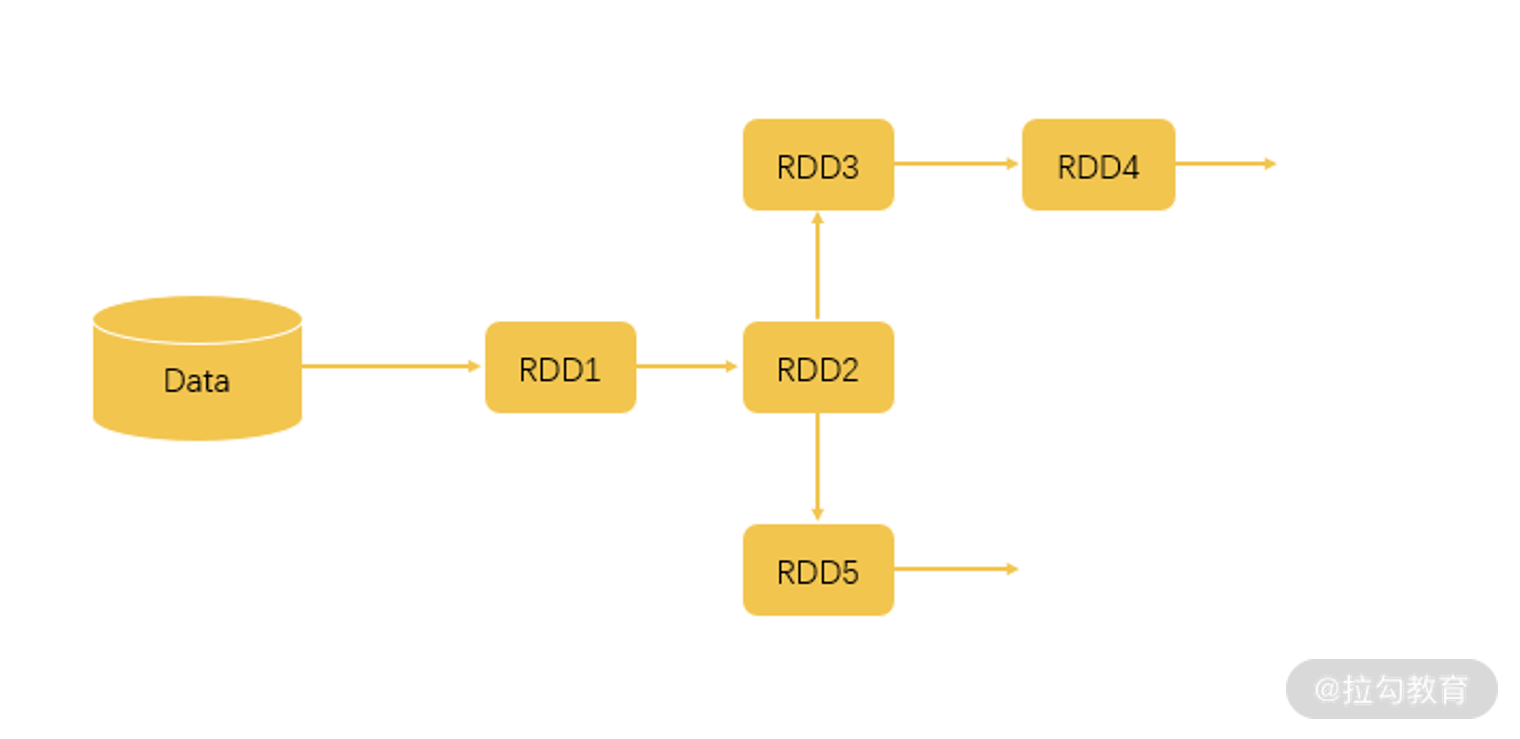
首先,我们从文件中读取数据,这时候形成 RDD1。
后面两步执行了 map、filter 和 reduceByKey 操作,map 操作给所有值加了 1,而 filter 操作过滤出带有 Python 的数据,reduceByKey 对 x 和 y 进行相加。这几个操作都属于 Transformation 操作,输出的结果都仍然是 RDD。
而最后一行执行了 count 操作,count 就是一个 Action 操作,它返回的是 RDD5 中的数据元素个数。
如果 Spark 对每一步都认真执行,那么第一步读取文件后,就已经把全量的数据存储在了内存中,但实际这并没有什么用,当 Spark 根据上面的执行逻辑分析了运算流程之后,会对 Transformation 操作进行整合,直到遇到 Action 操作才真正去进行运算。不知道这样解释,你有没有明白一些。
两种依赖关系
由于在 Spark 中流转的数据通常都是RDD 格式,从我们的代码可以看出,每一步生成的 RDD 都会依赖于上一步的 RDD,所以,具备上下联系的 RDD 产生的关系被称为依赖关系。
根据不同情况又分成窄依赖关系和宽依赖关系两种:
窄依赖关系指的是生成下级 RDD 不会引起数据在不同的分区(Partition)之间进行迁移(Shuffle);
宽依赖指的是要生成的 RDD 依赖于多个分区的数据,很明显这会导致处理速度的下降。
接下来,我们再来看一下 Spark 整体的运行架构。
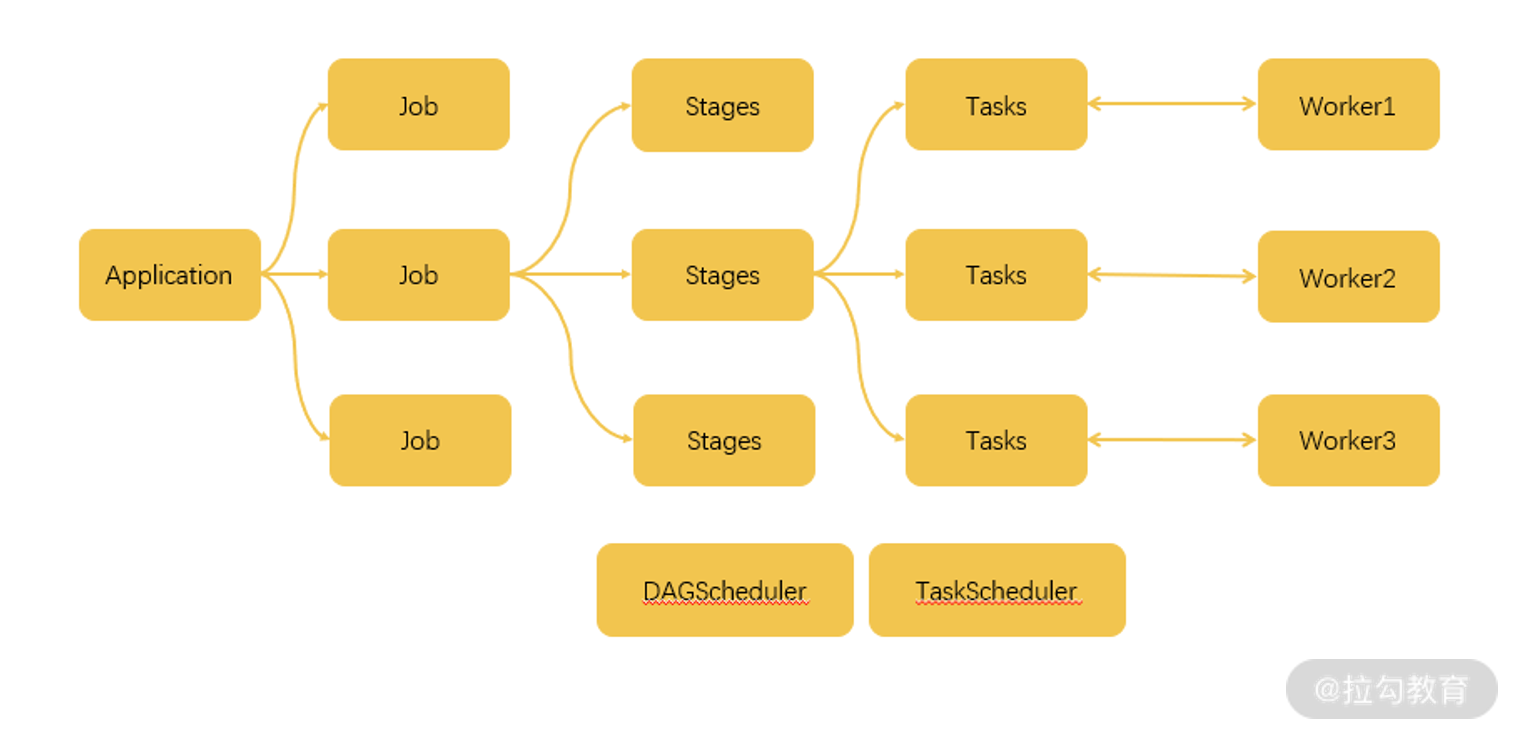
如上图,这是一个不太完整的运行架构,但是我们可以借此大概了解一下其中的概念。
当我们编写了一个 Spark 程序,也就是一个 Application 时:
这个 Application 以 Action 操作为界限,被划分成多个 Job;
一个 Job 以 Shuffle 为界限被划分成多个 Stage;
而一个 Stage 又会分成多个 Task,Stage 的划分和调度是由 DAGScheduler 来负责的,而 Task 由 TASKScheduler 来进行调度。
这些调度的终极目标就是根据依赖的关系找出开销最小的调度方法。最终,这些任务被分派到不同的 Worker 上进行运算。
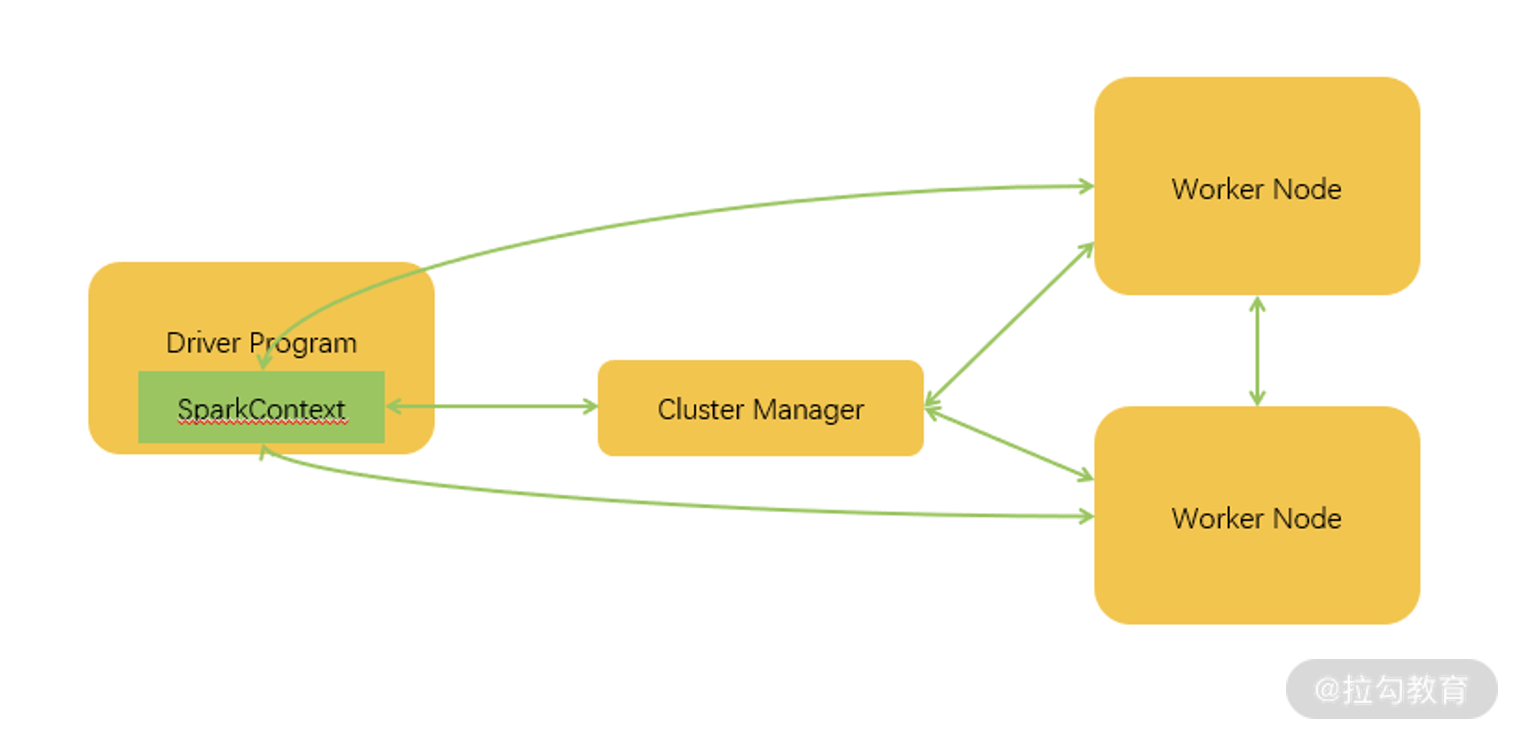
我们再把视野放得稍微高一点,来看看运行架构。如上图所示,这里的 Driver 也就是我们在代码中常说的 main 函数,当它被执行时会创建一个 SparkContext 对象,这个对象会与服务器中的 Cluster Manager 进行通信,从而申请任务所需要的资源。当成功获得资源之后,它的 Task 会被分配到 Worker 的执行器中,从而处理对应的运算。
开发时需要注意的问题
正是由于 Spark 所具备的这些特性,在开发的时候也会引起一些问题。
(1)数据倾斜
由于 RDD 数据会被分配到不同的分区,存在常见的问题就是数据倾斜,某些分区分配了过多的数据,而另外的一些分区则分配了很少的数据,这会导致一些节点的运算过于缓慢。
(2)过多地使用 Action 操作
由于 Action 操作会引发真正的运算,并对数据进行缓存,所以,如果 Action 操作太多会造成内存的大量消耗,从而占用过多的资源。
(3)宽依赖过多
前面我们讲到,宽依赖会引发 Shuffle,将不同 Partition 的数据迁移到同一个 Partition 中去,所以这个操作也会消耗很多时间。
这几个问题是我们在开发一个 Spark 程序时需要注意的问题。
批处理与流处理
批处理
所谓的批处理,从字面意思理解,就是把一整块数据切分成一小块一小块,每一个小块称为一批。把一个小块数据分配给一个计算节点进行运算,这种情况称为批处理。
所以说,批处理针对的数据是一个有限集合,也就是有界数据,这些数据在处理之前就已经存储在我们的源数据地址,当我们要进行处理的时候直接从这个数据集进行读取就可以了。
流处理
与批处理相对的,流处理的数据是无界的,数据就像一条河里的水源源不断地从上游流到计算框架中,我们不知道数据的总量是多少,也不知道什么时候结束。更发散来考虑,当雨雪天气,水流可能激增,而干旱时节水流可能枯竭,这就是流处理所应对的情况。
我们最开始讲过的 Hadoop MapReduce 就是一个批处理计算框架,而 Spark 和 Flink 是混合计算框架,既可以进行批处理计算,也可以进行流处理计算。带着这两个概念,我们来看一下什么是 Flink。
什么是 Flink
我们在 Flink 的官网可以看到对 Flink 的精准描述:
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算,Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
其实 Flink 的产生时间跟 Spark 差不多,最早出现在 2008 年由柏林理工大学发起的研究项目中,并在 2014 年把代码捐赠给了 Apache 基金会。
同时,Flink 的功能与 Spark 也基本一致,都属于大数据计算框架,那么我们来看一下 Flink 有什么特色。
Flink 的特色
1.数据皆流
在 Flink 的构建思想上,把所有的数据都看作是流式数据,所有的处理方式都是流处理。对于事实上的批数据,只不过当成一种特殊的数据流,我们称之为有界流,也就是说这个流数据有开始有结束,我们可以等着这个流获取完全后统一进行计算。
对于在我们公司中真正的流数据,我们将其称为无界流,这个数据只有开始,没有结束。只要我们的业务还在运转,用户还在浏览我们的 App,查看、下单、支付数据就会源源不断地传送过来。处理这种数据,不光是汇总起来就完事了,很多时候还需要注意数据的顺序,比如说正常情况下肯定是先点击,再下单,最后支付。如果数据的顺序搞错了,已经有了支付,但是没有点击和下单,那这数据计算起来就乱了套了。
我们说 Flink 就是为了流处理而生,自然而然,Flink 的创建者也为流处理做了很多优化。在数据接收方面,Flink 与 Kafka 有异曲同工之妙,都是基于事件驱动的,也就是数据随来随处理,而 Spark 实现的流处理实际上是微批处理,只是把数据块划分的更小。同时,Flink 还有精确的时间控制和状态以保障一致性。
2.多平台支持
同 Spark 一样,Flink 可以作为单独的服务进行部署运行,也可以与 Hadoop、Mesos、Kubernetes 集成部署。
3.高速
同样的,Flink 也使用了内存作为计算的中间缓存。在前面我们已经知道,批处理由于是已经累积下来的数据,所以需要大吞吐量,而流处理是来即处理,需要的是低延迟。在 Flink 中,使用了一种缓存块机制来保障两种计算的速度。当缓存块的超时时间设置为 0,那么只要有数据就立即处理,适合处理无界数据,而当缓存块超时时间设置为无限大,那么就要等着数据结束才处理,这样更适合有界数据。
当然,在具体的工作中,开发人员可以根据业务场景对超时时间进行配置,以获取最佳状态。而这些中间存储,首先是会存在内存中,如果内容不够用再开启磁盘存储。
Flink 的组件架构
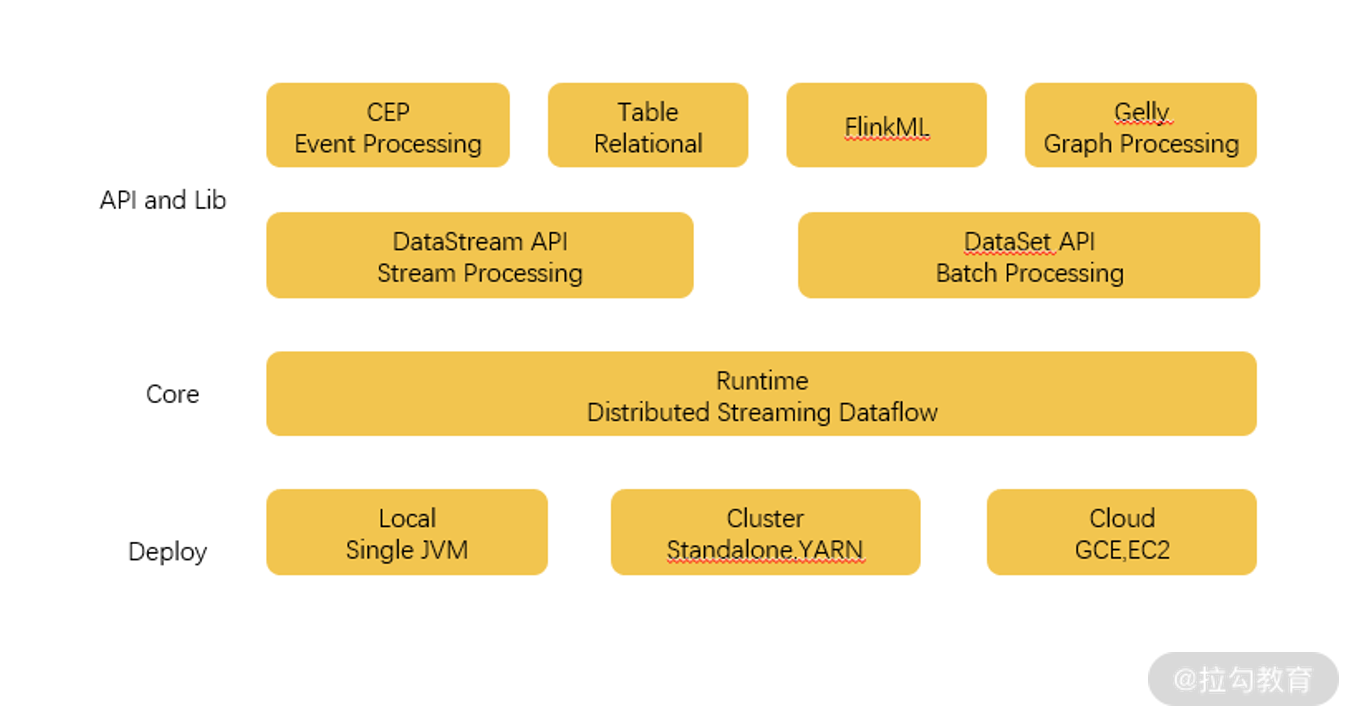
Flink 的组件架构图
与 Spark 类似,Flink 也实现了用一整套组件来支持整个体系的运转,如上图所示。
最底层是部署相关的组件,包括了支持本地单机部署、集群部署,以及云上部署的组件。
Core 核心层,是 Flink 实现的最关键组件,包括支持分布式的流处理运算,各种分配和调度系统都在这一部分实现,为更上层的 API 提供基础服务,这也为用户的方便使用奠定了基础。
API 和 Lib 层,提供了流处理和批处理计算的各种 API,以及针对特定的计算支持库,比如 FlinkML 就是和 SparkMlib 类似的机器学习库,而 Gelly 是和 GraphX 类似的图处理计算库。
看起来,Flink 与 Spark 似乎是没有什么太大的区别,那么下面我们来总结对比下 Spark 和 Flink。
Spark VS Flink
1.核心实现
在核心实现方面:
Spark 主要使用 Scala 语言编写而成;
而 Flink 早期是使用 Java 进行编写的,但是后期的很多更新也使用了 Scala 语言。
Scala 语言对大数据处理更加友好,但是做程序员的同学都知道,使用什么样的语言来编写程序其实对整个体系架构的影响并不是很大。
2.编程接口
在编程接口方面,Spark 和 Flink 就更加相似了。二者都提供了对各种编程语言的支持,包括 Java、Python、Scala 等,都可以用来编写 Spark 或者 Flink 程序。
3.计算模型
计算模型,或者我们也可以叫作设计理念,这是引发两者前进方向的最大区别点。
前面我们已经介绍过了,Flink 是把所有数据都看作流来进行处理,所以它本身对流式数据有着非常优秀的计算性能,在流计算方面做了大量的优化。
而 Spark 虽然也是混合计算框架,但是 Spark 的设计理念是批处理,也就是所有数据都是批数据。在处理流数据的时候使用了模拟的办法,把数据分割成更小的批来进行处理,从而模拟流式处理,所以在 Spark 中的流处理,我们也可以称为微批处理。所以,Spark 的迭代和优化只能无限接近真流处理,而无法称为真流处理。但是对于 Flink 则没有这样的情况。
有一种说法很妙——“我们可以认为 Flink 选择了‘batch on streaming’的架构,不同于 Spark 选择的‘streaming on batch’架构”。
当然,早期的 Flink 由于针对流处理进行的优化,也使得它在批处理方面仍然没有 Spark 性能良好,这也就引出了我们下面要介绍的流批一体技术。
流批一体
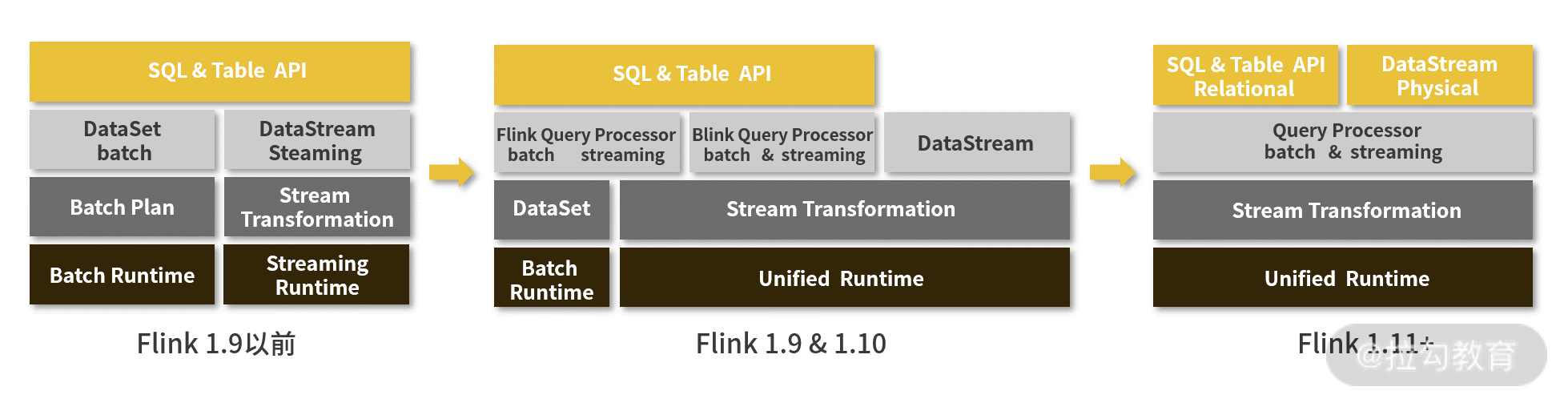
Flink 架构变化图
在 Flink 早期的时候,虽然说在思想上是把批处理当作流处理的一种特殊形式,但是实际上在处理的时候仍然是分开实现的,不管是 API 层还是 Core 层的 Runtime 都没能够实现完全统一。用户在进行流处理和批处理的时候要分别进行程序的编写,非常麻烦。
但是在 Flink 的 1.9 版本,Flink 开始完善流批一体,Flink SQL 率先实现了流批一体语义,使得用户只需学习、使用一套 SQL 就可以进行流批一体的开发,大幅节省开发成本。
但是只调整 SQL API 并不能解决用户的所有需求。一些定制化程度较高,比如需要精细化的操纵状态存储的作业还是需要继续使用 DataStream API。在常见的业务场景中,用户写了一份流计算作业后,一般还会再准备一个离线作业进行历史数据的批量回刷。但是 DataStream 虽然能很好地解决流计算场景的各种需求,但却缺乏对批处理的高效支持。
所以,在最近的两年内,Flink 主打流批一体的升级,从上面的架构图变化我们可以看出来,在最新的 1.11 版本,不管是 SQL 还是 DataStream API,都已经可以使用同一套编写规范,而只需要进行简单的选择就可以进行批处理或者流处理。
阿里巴巴在 2019 年初收购了 Flink 创始公司和团队 Ververica,开始投入更多资源在 Flink 生态和社区上。到了 2020 年,国内外主流科技公司几乎都已经选择了 Flink 作为其实时计算解决方案,我们看到 Flink 已经成为大数据业界实时计算的事实标准,在阿里巴巴公布的迭代计划中,Flink 会支持更加智能的流批融合,甚至是自动切换。
随着流批一体技术的实现,使用 Flink 的公司不再需要维护两套架构,部署两套代码,维护成本会进一步降低,我觉得 Flink 会变得更加普及,甚至是取代 Spark 成为新一代主流计算框架。
什么是数据挖掘
数据挖掘这个词或许我们经常会见到,但是到底什么是数据挖掘?有人觉得数据挖掘就是各种算法,有人觉得数据挖掘就是各种数据的计算。数据挖掘确实是一个涉及面非常广的词语,在我看来,数据挖掘更偏向于一种过程,而不是一种名词或者一个结果,比如说我们要为新闻网站上的新闻标注分类以方便用户查阅,当然可以让编辑或者运营人员人工地进行标注,也可以借助数据挖掘去发现分类与新闻的内在联系,从而为新闻自动标注类别。
所以所谓的数据挖掘就是以数据作为研究的对象,从数据中寻找价值,获取知识的过程,至于说机器学习算法,或者数据的统计分析,这些都是手段。
具体到一个公司的业务中,除了上面说的为新闻标注类别,以下这些都可以借助数据挖掘过程来分析和解决:
借助历史天气数据预测未来天气变化;
在异常交易行为中发现羊毛党;
为自媒体内容评判好坏;
预测一个商品在未来的流行趋势;
……
既然数据挖掘是一种过程,那么我们接下来就来看一下在实际的数据挖掘流程中,都分成哪些步骤。
数据挖掘的流程
在我刚开始工作的时候,虽然说也是处于数据挖掘的一环,但实际上我对数据挖掘的整体工作并没有什么概念。只是领导告诉我,某个指标需要计算一下,某些数据需要统计一下,我们要训练一个什么模型,我们需要做到多少的准确率等等。
随着工作经验的增长,我渐渐熟悉了这些环节,同时明白了数据挖掘的步骤,开始能够独立处理一个问题。实际上,在数据挖掘领域早已有比较成型的方法论,其中所列出的步骤与我的实际工作不谋而合。在这里,我们就介绍一个被称为 CRISP-DM 的数据挖掘流程方案,并通过一个小例子来实际感受一下,数据挖掘的流程是如何开展的。
CRISP-DM(cross-industry standard process for data mining),翻译过来的意思是跨行业数据挖掘标准流程,正如下图所示,在这个数据挖掘标准流程中包含了六个主要步骤,不过这六个步骤在整体上循环往复,但并不是按照单纯的顺序执行,其中还包含了很多关系,接下来我们就分别来介绍一下。
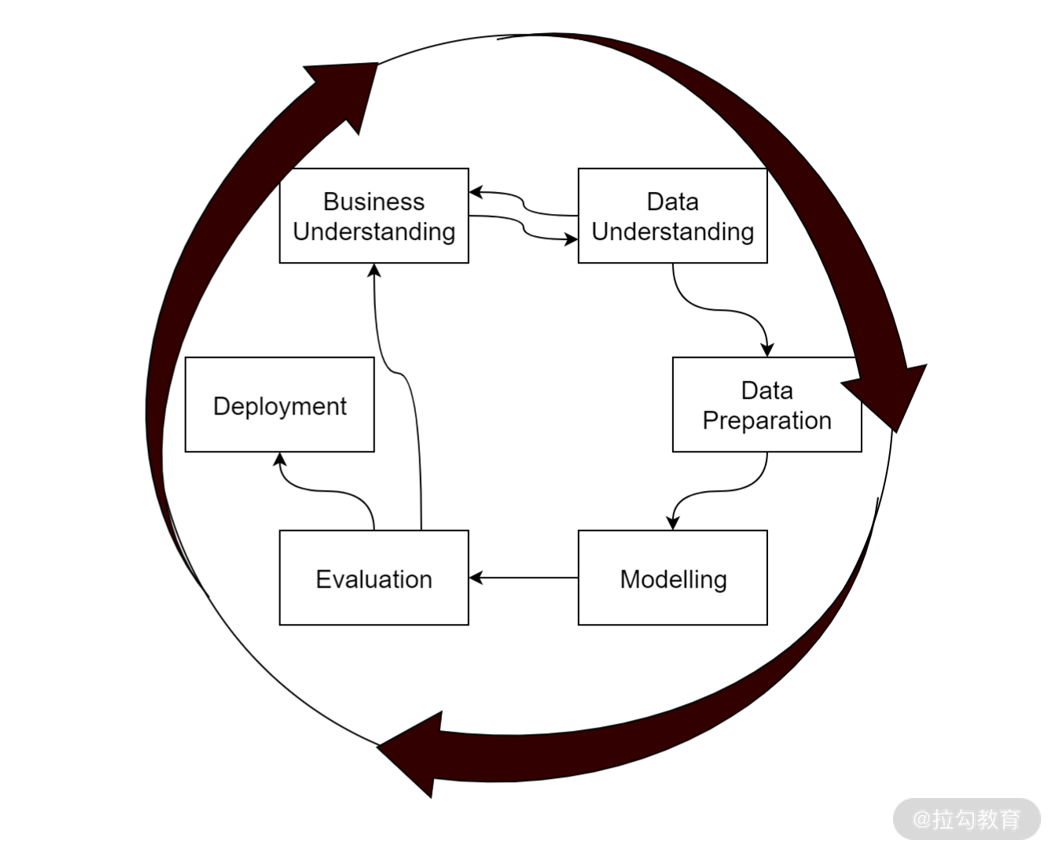
1.理解业务
以我们在拉勾教育做数据挖掘为例。为了保持内容的独创性,以吸引更多的用户购买,总编希望作者写的东西能够与一些主流网站上的内容存在一些差异,如果说每写一篇稿子,就让运营挨家挨户地去对比,那一定是费时费力,并且对比的效果很差,因为运营也没办法把那么多内容都看一遍,于是总编向我们发起了一个需求:比对作者写的文章与主流网站的文章是否存在一定的独创性。
我们收到了需求,接下来就要摩拳擦掌准备开始工作了。但是不要心急,这里说的工作可不是立马上手分析数据、写代码。作为一个合格的数据挖掘工程师,第一步我们需要理解业务,把业务逻辑搞明白。
需求有了,但是这个需求貌似并不明确。首先怎么定义文章具有独创性,这并不是通过技术手段可以量化的指标,我们就需要与总编沟通,确定如果两篇文章的相似度低于 5% 就认为是有独创性的。
之后我们可以把这个问题定义为一种文本抄袭检测,但是这个文本抄袭检测与一般的文本抄袭检测是否又有一些区别呢?比如说我们需要检测的是独创性,那么我们对比的粒度是否需要比较细;某些重点的文本是否需要一定不相同;一些引用和概念性介绍是否需要刨除;对于同一个作者的内容该如何处理等等。这些业务独特的需求我们也需要了解清楚,才能方便我们后面的处理。
理解业务看起来很虚,但是却是非常重要的环节,不要觉得理解业务是浪费时间的事情,认识清楚我们要完成的业务目标,能够为我们后面的提升效率、优化效果带来非常大的帮助。反之,如果你还没搞清楚业务的细节就上手开发,很可能所做的结果与业务的需求存在偏差,这时候就浪费了更多的时间,严重的还会给公司带来很大损失。
2.理解数据
在我们搞清楚业务需求之后,下一步就是要理解我们的数据。针对业务需求,我们需要什么样的数据,而我们公司中又有什么数据?哪些数据是一定要有的,哪些数据可以提升效果,但不是必需的?又有哪些数据是可有可无的?这些问题你需要在这个环节搞清楚。
比如说我们上面的“独创性”需求,至少需要拿到的是拉勾作者写的文本和需要对比的网站上的文本,除此以外,是否可以获得诸如作者名称、发布日期、文章分类等数据,针对细节需求,是否有充足的术语库供我们使用呢?这些数据是否存在一些错误,或者缺失?这些也都是需要考虑的问题。
如果说数据是完美的,那么工作起来自然简单,然而数据挖掘所需要解决的不仅仅是一个算法问题,而是在当前的条件下,在不完善的,甚至有错误的数据条件下,如何更好地输出结果。因此,理解数据也同样重要。如果对于某些需求,现有的数据无法支撑,那么还需要返回到理解业务的步骤,重新讨论业务需求。
3.准备数据
弄明白了我们的业务需求,搞清楚了我们手头的数据,接下来我们就要开始准备数据了。
在这个环节,我们需要针对具体的情况,也就是拿我们业务和数据本身的问题去做针对性的准备,把原始的数据经过清洗加工,转变成我们在后面的建模环节所需要的状态。对于我们“独创性”的需求,文本数据自然是不能够直接进行运算的,我们可能需要对文本做一些分词、关键词提取、过滤停用词的工作。如果要使用词向量,还需要训练一个词向量表。对于非文本数据,也需要检查异常值或者缺失值,看是否需要进行丢弃或者补全的操作。
4.构建模型
如果说,我们前面的步骤都已经有条不紊地完成了,那么在构建模型这一步将非常顺畅。构建模型所解决的基本上都属于技术问题了。面对我们的问题,如何选取对应的技术方案、使用哪种算法来解决我们的问题、如何优化以提升效果是构建模型阶段需要解决的问题。
我们常见的问题通常可以转化成分类、聚类、回归和关联分析四种问题,进而选择对应的算法构建模型。比如说我们的文本抄袭检测:
可以转化成分类问题,把相似和不相似看作是二分类,把文本数据转化成数值数据,使用分类算法构建分类模型;
可以把它转化为一个聚类问题,把文本进行聚类分析,根据聚类的距离来判定是否抄袭;
可以把多种方法组合起来使用。
很多时候,我们需要根据经验来选择使用何种方案,如果你还不能很好的判断,那么就有必要多做一些试验来对比效果。
5.模型评估
模型训练好了,我们还需要对模型进行评估,来确认我们的模型是否确实符合我们的预期、能够满足我们的业务需求、解决我们的业务问题。
从数学原理方面,我们有诸如准确率、召回率、F1 Score 等指标来评判一个模型的效果。同时,在公司中,很多时候我们还需要与业务人员共同进行人工抽样来确认效果。比如说我们构建好了检测文本相似性的模型,只有一个准确率 90% 的概率往往还不能直接使用,我们的效果还需要得到业务方,也就是总编的确认。不仅如此,由于我们训练使用的数据跟线上的数据肯定存在一些区别,在模型上线之后,仍然需要定期花时间来评估线上的效果。如果发现问题,可能需要对问题进行分析,看是否是个例还是大面积的问题。
6.部署上线
如果总编检查完了结果,并对我们工作的效果非常满意,那么我们就可以对模型进行部署上线了。
在部署的时候,我们更多地需要考虑一些工程问题。因为有时候我们的模型效果虽然没问题,但是运算速度可能太慢,或者需要太多的资源,而我们的服务器可能无法支持,或者我们的数据量太大处理不过来,又或者我们需要把服务集成到 App 上面,让用户在无网络时也可以使用等等。
7.下一次迭代
我们的抄袭检测服务终于可以上线了,然而数据挖掘流程并没有结束。可能是为了快速上线,也可能是由于当前的某些条件不具备,我们的第一版服务还存在着很大的优化空间,同时来自线上的日志收集也为我们准备了很多问题案例。在经过了一段时间之后,我们可能需要重新回到构建模型阶段,或者理解数据阶段,甚至是理解业务阶段,对我们的项目进行优化和迭代。
所以说,数据挖掘流程是一个循环往复的流程,虽然说按步骤进行了划分,但是这些步骤并不是绝对分隔的,每个步骤之间都有着千丝万缕的关系。
数据挖掘算法有什么特色
首先我们来看一下“算法”的定义:
算法是为求解一个问题需要遵循的、被清楚指定的简单指令的集合。
如果是没有接触过数据挖掘或者机器学习的同学,说到算法想到的可能是查找、排序、二叉树、动态规划等等。这些算法主要用于我们的数据在存储和运算过程中,通过精巧的设计计算过程达到优化时间复杂度和空间复杂度的目标,而且这些算法的结果是确定的,实施某一个算法,就可以获得对应的效率提升。
单纯从“算法”的定义来看,我们在数据挖掘中所使用的算法与其他的算法也没有什么区别,同样是为了求解问题而形成的指令集合。但不同的是,数据挖掘中的算法目标是要寻找存在于数据之中的知识,而且这些知识是不确定的,因此算法的结果也无从而知,可能会获得好的结果,也可能会获得不好的结果,在算法计算完成后我们还需要通过一些辅助方法来评估结果。
数据挖掘算法四大类
既然我们知道数据挖掘的算法是为了寻找数据中潜在的知识,那么数据挖掘的算法通常都有哪些类型呢?如果说按照这些算法所解决的问题来进行划分,大致可以分为分类问题、聚类问题、回归问题和关联分析问题。下面我们就来详细看一下。
1.分类
春天来了,我带着儿子在公园里闲逛,看到花圃里形状各异,五颜六色的小草和花朵,儿子撒开我的手蹲在那里仔细研究起来。儿子指着其中一朵黄色的花问,“爸爸,这个是什么花?”我定睛一看,这个简单,“这是郁金香。”“这个是什么花?”我回答,“这个红色的也是郁金香。”连续问了几个之后,他指着旁边的一朵说“这个也是郁金香。”
我们接着往前走,走到一片玉兰前面,儿子又问我“这树上的是什么花呀?”我说“这是玉兰花。”
上面这个人类幼崽的学习过程就是分类算法所处理的过程。分类算法就是对已经确定好结果的数据进行学习,从而对未知的新数据进行分类的算法。在这个例子中,我为部分数据提供确定的结果,儿子通过观察它们的特征和区别来对新的花朵进行判断,从而区分出一朵花是玉兰花还是郁金香花。我们前面说,数据挖掘的算法结果是不确定的,我们怎么知道学得怎么样呢?
再看看我儿子的行为,如果他没有见过其他的花,当我们看到一棵桃树的时候,他可能会指着桃花说“这个长在树上的花是玉兰花。”这就出现了欠拟合,他只通过判断是长在地上还是长在树上就决定了花的类别,这个时候我们需要告诉他更多的特征,比如说玉兰的花瓣更宽,更长之类的。
另外一种情况,他可能会指着一朵粉色的郁金香说“这个是粉色的,这个不是郁金香。”这时候就是出现了过拟合,他把条件限制得太死,这时候我们应该给他找更多郁金香,让他明白,颜色并不是判断郁金香的主要特征。
2.聚类
我们接着往前走,这时候儿子又问我“这个是什么树叶?那个是什么树叶?”我看着这些叶子,虽然它们确实不一样,可是这也超出了我的认知,我也不知道这是什么树呀。我只好跟儿子说,我也不知道这是什么树叶,不如我们把你捡的树叶分一分,然后从每一种里拿一片出来,等我们回家查查这是什么树叶。于是我跟儿子一起蹲在那里,对着之前捡的一兜树叶挑挑拣拣。这些带锯齿边的是一堆,那些小圆片是一堆,还有这种三个尖尖的是一堆,如此种种。
与分类不同,聚类算法只需要有一些数据,但是事先并不知道数据属于什么类别,通过对这些数据的学习,希望能够通过数据的差别寻找到潜在的类别,从而把已有的数据划分成几个类别,至于说这个类别具体是什么并不清楚。
3.回归
从公园回家,还没进门我就已经闻到了饭菜的香味。我跟儿子说:“我们先吃饭吧,吃完再查树叶。”儿子却不同意,说:“我不饿,我不饿,我不想吃饭。”我媳妇这时候冲了出来,“饭都不爱吃,你都已经比别的小朋友矮了,真不知道你能长多高!”这个问题。我们或许可以使用回归算法来分析一下,当然我们首先需要有一些数据,假设孩子的身高可能跟父母身高、孩子的性别,等等有关系,那么我们获取一百组父母的身高和孩子的身高、孩子的性别、孩子吃多少饭、喝多少奶、有多少运动量等等数据,就可以构建一个线性方程,通过已有的数据把系数算出来,然后把我自己的数据输入到这个方程中就可以算出一个数来了。
回归的计算其实跟分类类似,都是预先已经有了特征数据和结果数据,只不过分类的结果是一个确定的标签,而回归的结果是一个连续型数值。很多时候,我们甚至可以在回归方法和分类方法之间进行转化。
4.关联分析
正当我还在思索孩子能长多高的时候,我媳妇又说:“他不吃饭那就冲点奶粉喝吧,奶粉快喝完了,你去某东上买点。”于是我打开了某东的 App,搜索了奶粉,正当我准备下单的时候,下面弹出了一个优惠信息:买了该奶粉的人还买了 xxx 尿不湿,组合购买可省 xx 元,然后是一个组合链接。于是我问媳妇,“尿不湿还够不够,需不需要买了,这个一起买能便宜一点。”接下来,就是我买了一桶奶粉,两包尿不湿,通过关联分析,某东成功把我本次下单的客单价从 1xx 提升到了 2xx。
关联分析是从已知数据中寻找相关关系的一类算法,比如说我们这里的奶粉和尿不湿,只是找到这样的销售搭配关系,并把它推荐给正在购物的人,就可以提升业绩了。在商业分析,推荐系统,以及用户行为分析中,经常会用到关联分析方法。
不同算法适合的情况
1.分类算法
分类算法对数据的要求比较高,需要一定的数据量以及事先的标注结果,通常是要根据学习过去已有的数据,对新的数据做出类别预测,比如说给新闻分类。
常见的分类算法有最近邻算法 KNN、决策树算法、朴素贝叶斯、人工神经网络、支持向量机等等。
2.聚类算法
聚类算法也是要去划分类别,但是聚类算法对数据的要求会低一些,并不需要事先标注好的结果,而是通过算法模型来判定。聚类算法通常是针对已经确定的数据集合进行划分,比如说对于用户分群,有一堆用户的基础信息和行为数据,我们不太确定这些用户到底有多少类别,又该如何划分,这时候就可以使用聚类的方式。常见的聚类算法有 k-means 聚类、DBSCAN 聚类、SOM 聚类等等。
3.回归算法
如果你有一些数据,其中要去预测的结果并不是一个标签,而是一个连续数值,可以用一个函数近似地模拟特征与结果的关系,那么就考虑使用回归算法。比如说你知道广告投入和产品销量存在着一定的关系,通常是广告投入越大销量越高,你可以用过去几年的广告费用和产品销量构建起一个函数方程,然后把明年的广告预算放进去,就可以得到一个销量的预测值。常见的回归算法有线性回归、Logistic 回归等。
4.关联分析
关联分析主要用于寻找两个项之间的关系,并给出关联规则,比如我们提到的尿不湿和奶粉的关系,关联分析可能是需要最少人工调整的方法。常见的关联分析算法有 FP-Growth 算法和 Apriori 算法。
自然语言处理
自然语言也就是我们人类说的语言,我们使用语言进行交流、传递各种信息。在我们常见的应用中,比如今日头条中的新闻文本、淘宝中的商品描述、用户评论文本、喜马拉雅中的有声读物、知乎中的问答等等,自然语言几乎会出现在每一个地方。伴随着这些应用场景,深度学习基本上介入了所有的方面,并且取得了不错的效果。
1.自然语言基础处理
关于自然语言需要进行的一些基本操作,比如分词、词性标注、句法分析、实体识别等等,这些大多数是序列标注问题,主要是为了构建一些底层特征而进行的。
2.文本分类
文本分类可以说是应用最广泛,最容易理解,也最成熟的一项能力。对于新闻分类、评论的情感分析、广告和标题党的识别,非常多的任务可以使用文本分类的方式解决。
3.文本生成
比起文本分类,文本生成则要困难一些。使用文本生成可以给没有标题的内容生成一个新的标题,或者生成对应的摘要。之前 OpenAI 还使用最新的GPT 模型来续写哈利·波特,这些都属于文本生成,不过单纯文本生成的效果当前还很难达到工业级别的需求,在实际的工作中,对于这方面的需求往往需要增加很多辅助工作。
4.语音识别
语音识别其实分为两个步骤,第一步是要对音频中的音节进行分割然后识别出是什么音,第二步要把这个音转换成对应的文字,这时候就需要语言模型的介入,因为一个音可能对应很多的文字,加入语言模型可以让语音识别的效果更上一层楼,通过上下文关系来决定哪一个字。现在语音识别技术也已经非常成熟,有很多 App 都可以做到几乎实时录音转文字。
5.机器翻译
机器翻译就是使用计算机实现不同语言之间的翻译转换。语言与语言之间的转换有太多细节的特征,这正适合深度神经网络发挥它可以自行学习深层特征的能力。可以把循环神经网络、编解码器框架和注意力机制很快应用到机器翻译上来。如果你使用过十几年前的谷歌翻译,再看现在的谷歌翻译效果,真的是有天壤之别。
6.智能问答
智能问答也是当前非常火热的一个领域,比起前面的几项,智能问答更像是一种应用,其中会用到意图理解、文本分类、文本生成、文本匹配,甚至是知识图谱的相关知识,这里面自然也少不了深度学习的身影。
计算机视觉
看完自然语言处理相关的一些应用,别忘了我们的数据中还有很多图像相关的数据。比起语言,图像更加直观,但是图像的信息密度更低。在我们常见的 App 中,新闻会加入图像来还原事发的状况,电商网站也会加入图片和视频来吸引用户购买,更不用说像 B 站、抖音、爱奇艺这种几乎完全是视频构成的应用。深度学习在图像的处理方面,也发挥了强悍的能力。
1.图像识别
在图像识别方面,我们前面也讲过,深度学习模型的效果已经超越了人类的识别效果。跟图像识别相关的应用非常多,比如人脸识别、图像分类、物体检测。在交通违章上使用的车辆识别,车牌识别;在审核方面使用的图像色情低俗识别、暴力恐怖识别等等,都是图像识别在发挥着作用。
2.图像生成
图像生成方面,有很多有意思的应用,比如可以根据对不同的人脸学习,进而自动生成一些新的实际上并不存在的人脸;还可以进行风格的迁移,学习一张图的样式以及另一张图的绘制风格,进而生成一张新的图片;甚至是与自然语言处理结合,根据一段语言描述生成新的图片。
3.图像变换
图像变换主要是对原图像进行一些处理,使得原本不符合某些需求的图片质量提升,能够符合我们的需求。在这方面,有图像的智能裁剪、图像放缩、图像超分辨(让原本模糊的图片变得清晰)、图像去噪等等。
4.OCR
OCR 技术说的是识别图像中的文字,目前的 OCR 技术已经比较成熟,对于固定场景下的文本识别效果非常好,尤其是印刷体文本的识别基本上可以达到 100% 的准确率。
PEST 分析
PEST 是针对宏观环境的分析,所谓的PEST 指的是政治(Political)、经济(Economic)、社会(Social)和技术(Technological)这四大类主要的外部环境因素。
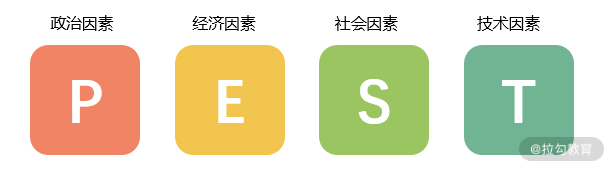
政治环境主要是看我们的国家现在是否鼓励相关的业务,有没有这方面的政策或者法规,比如说国家“十三五”规划指明全面推进互联网应用创新,促进互联网和经济社会融合发展,而且我们的“发现好货”也不会在政府重点监管和整治的范畴。
经济环境又可以分为宏观经济和微观经济。宏观指的是我们整个国家的经济情况,比如说我们国家是疫情期间唯一一个实现正增长的国家,而人口增速放缓、老龄化变得更加严重,家庭规模变小,人们不再喜欢囤积大量货物。而微观主要从一个人的角度出发,例如人们的收入逐步增加,储蓄规模有所下降,消费偏好变得更加多样性,比如这两年逐渐火爆的精酿啤酒就是一个典型的例子。
社会环境则是说跟社会的风俗习惯是否吻合,大家的教育水平是否能够接受我们的产品形态,符不符合大多数人的价值观,我们的产品有没有影响人们的宗教信仰等等。如果说我们的产品有可能挑战人们的价值观,或者说对社会中的风俗习惯有冲突,那估计就得重新考虑了。
技术环境当然就是说的我们的技术实力,首先是我们公司内部的技术水平和基础技术建设能不能支撑我们去做这个事情,在这里当然就是我们的大数据体系,其中的实时流处理、算法研究的能力等等,这些是否能满足“发现好货”这个产品的要求。如果不能,我们的产品是需要做降级方案还是说要去补全我们的技术能力,或者是说完全没有办法做,这就是需要考虑的问题。
PEST 分析从外部环境进行分析,考虑我们的产品在这种大环境下是否可以生存,如果跟大环境存在冲突那可能我们这个产品就没办法去做了。
SWOT 分析
在清楚了外部影响因素之后,我们应该再来确认自身的情况,这时候可以使用 SWOT 分析。来自麦肯锡咨询公司的 SWOT 分析,包括分析企业的优势(Strengths)、劣势(Weaknesses)、机会(Opportunities)和威胁(Threats)。
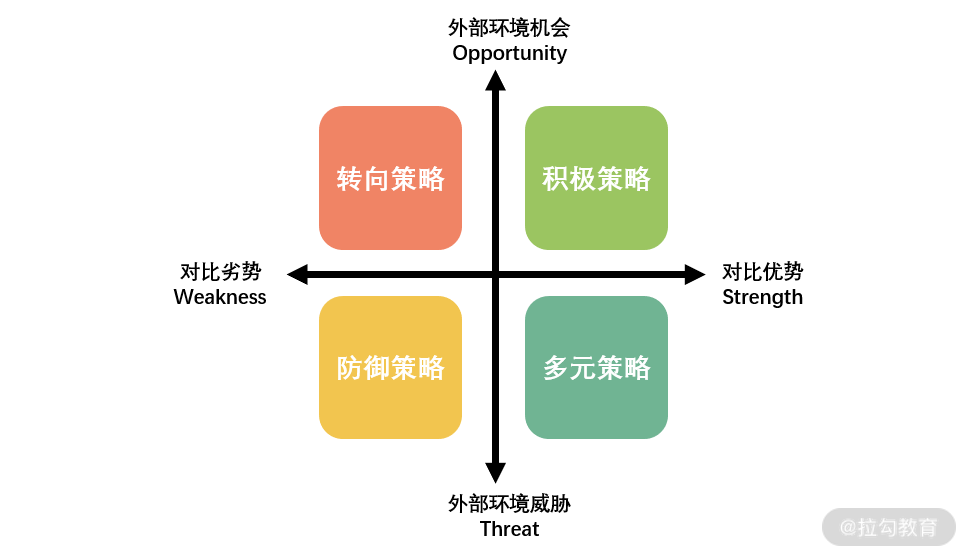
1.机会与威胁分析
所谓的机会与威胁分析,就是顺着我们上面的环境分析下来,看看在当前环境的情况下,如果要做一个“发现好货”的产品形态,我们的机遇有哪些,受到的环境的不利挑战又有哪些。比如说,当前的经济环境下人们对商品品质的追求有了更大的需求,这就是我们的机遇。把环境分析与我们的产品自身情况结合起来,可以帮助我们判断该采取什么样的产品策略。当然,对环境的分析除了我上面讲到的 PEST 分析,还有一个波特五力分析法,如果你有兴趣可以在课下了解。
2.优势与劣势分析
清楚了自身在环境中的情况,接下来我们还需要去看看市面上是否已经有类似的产品形态。因为我们是期望在一个泛品类的电商网站中构建一个“发现好货”的栏目,我们可以去找淘宝、京东等网站是否已经有这样的栏目存在,在一些公开的资料中有没有讲到这方面的东西,这也就是所谓的竞品分析。
优劣势分析就是针对我们要做的产品的整个生命链条与竞品做详细的对比。比如说我们要做一个这样的栏目,我们的优势在哪里,是已经具备了强大的货物筛选能力,还是说我们在价格上更有竞争力,我们的用户更倾向于高质量的商品。
我们的劣势在哪里,是不是物流没有京东的快,货物没有淘宝的齐全,一个产品不可能只有优势没有劣势,但是我们要清楚成功的关键要素是什么,如果我们在这些关键点上存在比较优势,那么我们的产品也许就更强一些,那在后面的运营上也可以趋利避害,强化我们的优势,规避我们的劣势。
当然,在前期分析中,我们的产品还没有上线,所以这些竞品分析也是站在潜在用户的角度去进行比较,与实际的情况可能存在一些差异。所以我们在进行竞品分析的过程中,需要对自身的资源和能力有足够清醒和深入的认识,这样才能更加准确客观。
人货场指标
在弄清楚了外部环境与竞品情况之后,我们对大的方向以及策略的制定有了一些想法,接下来我们就要进入具体的场景中来,明确我们要去做“发现好货”的栏目应该从哪些指标入手。
首先我们需要关注的是核心指标。任何一个产品的产生都应该有一个核心指标:
如果说我们的目标是吸引新用户,那么核心指标就是新用户转化率;
如果说我们的目标是让用户更多使用我们的 App,核心指标就是用户停留时长;
如果我们期望用户更多地了解我们的商品,那么核心指标就是人均浏览商品数。
对于我们“发现好货”的目标,我们期望能够通过这个栏目获得更高的现金流,那么我们可以把核心指标定为销售额,而销售额 = 流量 * 转化率 * 客单价,对于我们栏目相对固定的位置,流量也是相对固定的,所以我们期望通过把“好”的商品筛选出来放在这个栏目中,以提升转化率和客单价,因此我们的销售额指标是一个有限条件的销售额指标,也就是在流量一定的情况下,销售额更高。
核心指标是我们所追求的目标,要时刻关注,而对于我们在构建产品时,该如何围绕这个目标进行拆解呢,那么就需要对我们电商网站中的人货场指标进行拆分。
人
电商网站中所说的“人”,也就是我们的用户,具体到“发现好货”,我们应该了解:
所面向的潜在用户是什么样子的,比如说用户的基本属性、性别、年龄、收入状况等;
用户使用我们 App 的情况,新客、老客、高频用户还是低频用户,喜欢早上下单还是晚上下单;
用户的兴趣点,根据以往下单历史,喜欢健身,喜欢买各种吃的,还是喜欢买儿童玩具等等。
这些都属于用户相关的指标。通过“人”的指标,我们对“发现好货”所面向的人群有了一个基础的判断,了解了我们这个产品潜在的用户量有多少,也方便在后面运营的时候有针对性地引导客户。
货
“货”更加容易理解,那就是我们要售卖的东西。我们的“发现好货”栏目自然是需要对货相关的指标进行更加详细的盘点,其中包括商品的基础信息,如商品的品类、价格、优惠、库存、介绍、质量、款式、使用寿命等等;商品的历史情况,比如销量、点击率、转化率、退换货率等等。
场
“场”指的是交易发生的场所,在线下可能是商场、菜市场,而在我们的 App 中,则涉及从用户进来到成交退出的每一个环节。我们的“发现好货”栏目对于用户路径来说,第一个“场”是栏目所处的位置,然后是内页,紧接着是商品详情页,然后是购物车,最后是订单页。
与“场”相关的指标包括流量相关的路径,使用漏斗模型分析从初始进入的流量到最后转化的流量指标;还包括在每一个页面上的停留时长、热力统计、跳失率等等;以及与销售相关的,整体销售额、利润率等等。
经过对人货场指标的细化,我们就可以针对产品构建起人货场模型,也就是说确定针对的是哪一部分用户,对于这些潜在用户我们该选取什么样的商品放在栏目中,对于确定的人和货,在我们的场景中又该如何展示,如何排序能够获取更好的销售额。
可视化的建议
1.关于可视化图表的选型
每种可视化图形都有其适合的场景,或者说适合展示的数据,在这里我大概做了一些总结。
(1)类别比较
类别比较即是对不同类别的数据放在一起进行对比,突出的是不同数据的规模差异情况,这种可视化一般会用到柱形图、条形图、雷达图、词云图等等。
(2)数据关系
数据关系型图表主要是为了展示数据的不同变量之间的联系,比如说层次关系、网络关系、数值关联等等情况:
像数值关联分析需求,可以使用散点图、气泡图、曲面图等等;
当要对比的变量超过三个,可以考虑星形图、平行坐标系、矩阵散点图等等;
而层次关系可以考虑节点链接图、树形图、冰柱图、旭日图等等;
网络关系可以考虑桑基图、蜂箱图之类的图表形式。
(3)数据分布
数据分布类主要为了展示例如我们的产品在某些维度上出现的规律情况,这类建议使用直方图、密度曲线图、箱型图等等。
(4)时间序列
时间序列的数据通常是为了表现随着时间的变化,所展现出来的数据趋势,这类可选择的图形有折线图、面积图、雷达图、日历图、柱形图等等形式。
(5)局部整体
局部整体的数据展示通常是为了说明整体下的组成部分所占的比重情况,这种可以采用饼图、环形图、旭日图、矩形树状图等等。
(6)地理空间
最后一种说的是期望展示数据在地理空间方面的分布情况,通常使用地图作为底图,然后辅助以热力图或者散点图进行对比。
除了这里列出的这些,还有很多图表类型我并没有提到,你还需要在实际的应用中去摸索。
2.关于颜色的搭配
对于我这样对色彩敏感度较低,自己只能搞出一些奇奇怪怪配色的人来说,最好使用既定的色彩主题。好在我上面提到的几种可视化工具中也都提供了若干的色彩主题供大家使用,这些色彩主题都是由专业设计人员精心设计的,本身是有比较好的美观度,同时也省去了自己搭配色彩的苦恼。
其次,如果你觉得工具提供的配色不能满足你的需求,那么可以去一些配色网站上寻找你想要的配色方案,并应用到自己的可视化中。
最后一个方案,是使用公司提供的配色方案,一般公司的设计部门会有一套常用的公司配色方案。如果没有,你也可以从公司的网站、App 中寻找配色方案,并应用在你的汇报中。关于配色方面,总的原则就是一定要简洁明了,色彩种类不宜太多。当然,如果你非常精通配色可以忽略我说的这部分内容。
推荐系统
要构建推荐系统,我们先来看一下它应该有哪几个组成部分。推荐系统最基本的功能就是“匹配”,匹配每一个用户和每一个物品,以做到千人千面的效果。在这里我画了一个最简单的示意图:
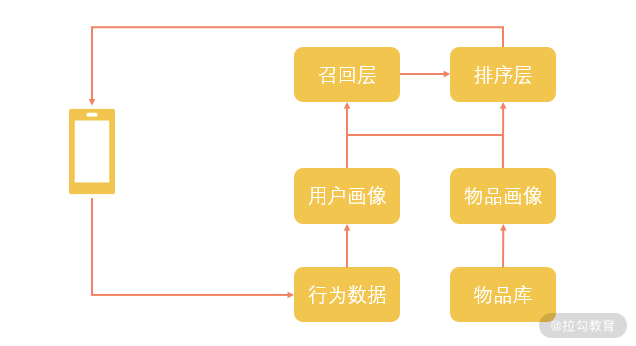
当用户在使用我们的 App 时,产生了大量的行为数据,这些数据通过日志的方式从手机传送到我们的服务器上,在服务器上又通过实时或者离线的方式同步到我们的数据处理平台上面。使用数据处理工具,比如说 Spark 或者 Flink,我们把这些行为数据加工成为用户画像的一部分。另一部分,则是对我们的物品信息进行各种挖掘和计算。
这里形成的用户画像和物品画像在召回层进行匹配,确定适合一个用户的物品有哪些,然后在排序层对这些物品的出现次序进行调整,当用户刷新页面的时候,他对应的物品列表就会被展示出来。这就是推荐系统完成的一个典型的推荐流程,当然,在这里面还有很多的细节和问题需要处理。
1.用户画像
在用户画像方面,基本上可以分成用户的基础属性、行为属性、兴趣属性、价值属性等几个维度:
基础属性主要是一些相对固定的信息,比如用户的年龄、性别、手机型号、网络状况等等,这类信息主要依赖用户自行填写或者直接收集;
行为属性通常是对用户使用行为统计计算得出的结果,比如说用户的购买行为、互动行为、喜欢什么时间段使用 App、收藏夹或者购物车都有些什么东西等等,通常这类属性使用 Hive 或者一些数据统计工具就可以完成计算;
兴趣属性通常是针对场景下的物品而言的,比如说用户有自驾的兴趣、有滑雪的兴趣,或者是亲子兴趣等等,这类属性会以物品属性为基础,其中可能有依赖统计获得的结果,也可能有使用数据挖掘算法获得的结果;
用户的价值属性,往往是针对我们的平台而言,对于电商平台,用户价值可能是消费能力、消费周期、消费频率等;对于内容型平台,用户价值则可能是使用时长、互动水平等,这类属性一般也是包含了统计特征和模型特征。
2.物品画像
通过对用户行为进行分析,我们对用户有了认知,但是想要去匹配用户与物品,我们还需要在物品方面进行理解。这里所说的物品,也就是要推荐的东西:
对于电商推荐来说就是商品信息;
对于内容推荐来说就是各种新闻、视频;
对于广告推荐来说就是各种广告信息。
物品本身通常是由文本、图片、视频等构成的,对于这些数据的处理往往就涉及我们的自然语言处理和计算机视觉相关的能力。
关于物品画像特征,首先也会有基础属性,通常是数据本身或者经过一些统计就可以得到的特征,比如名称、价格、上线时间、优惠信息这类的数据。
在基础属性之上,我们会使用算法对这些数据进行加工,以获得基础算法属性,比如说文本的关键词提取、实体识别、词向量,甚至是预训练模型、图像的美学判定、图像的物体识别、视频的关键帧提取等等。
这两层特征当然可以直接以特征的形式加入推荐召回和排序中,此外,我们会借助这些数据再进行更贴近业务的属性建设,比如说文本图像视频分类、情感分析、人脸检测、质量评级等等。
3.召回与排序
有了对用户和物品的描述,我们就可以在同一个空间内对用户和物品进行匹配了。
匹配的第一步是召回环节。如果我们要为一个用户匹配他最喜欢的新闻,最粗暴的方式当然是把时下所有的新闻画像都拿出来,然后挨个计算和用户的相似情况。但是新闻如此众多,在实践中这样进行计算会消耗大量的资源,更别提我们还有无数的用户都需要进行计算。召回环节所要解决的就是从庞大的候选池中快速地找到更可能与用户匹配的物品,缩小候选物品的范围,降低排序时的难度,如下图所示:
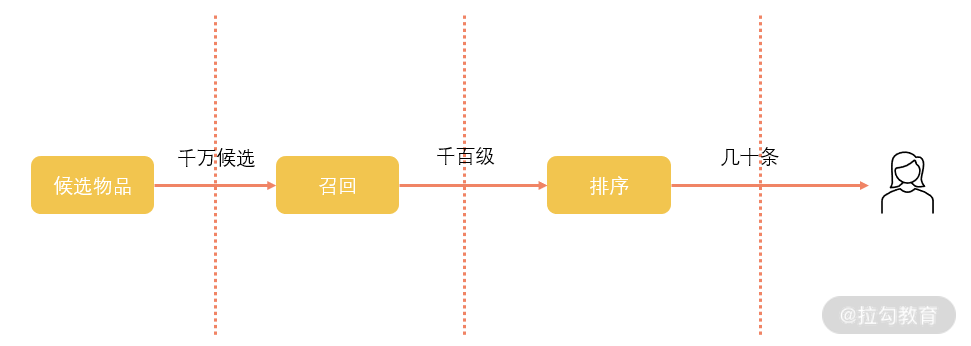
排序层在召回的结果上进行计算,因此排序的目标是使用更多的特征,以提升推荐的核心指标为目标,通常使用的是点击率预估,通过预测哪一个点击的概率更高,从而给出精准的排序列表。
在工业实践时,为了解决性能等问题,往往还会把这两个环节再进行细分,召回可以分为粗召回和细召回,粗召回主要是不关联用户,单纯地以物品特征作为召回特征,在细召回环节再与用户进行匹配。同样,排序环节也可以细分,分为粗排、精排以及重排,重排序环节往往是在最后环节做一些规则或者运营进行干预。
在推荐系统中,用户画像和物品画像通常也会被称为特征工程,当然这里的用户画像和物品画像除了应用在推荐系统中,还可以用在各种运营场景,比如分群和物品圈选,去做场景投放。在经历了特征工程之后,这些从数据中提纯加工后的特征经过召回和排序变成一个列表。对于每一个用户都会有一个自己的列表,当用户在手机 App 上刷新的时候,列表中的内容就会按顺序展示,等待用户的浏览点击,这就完成了一个推荐的流程,从庞大的候选中为用户匹配到最相关的物品。
常见推荐方法
根据对推荐系统使用特征的区别,我们大致可以把推荐分成下面几种情况。
1.基于协同过滤的推荐(Collaborative Filtering,CF)
这种方法最简单有效,协同过滤的基本思想就是相似用户所喜爱的东西也是相似的。协同过滤可以只根据用户行为来分析,根据用户浏览的内容来决定用户的相似度,然后为一个用户推荐与之相似的用户看过或者买过的东西。协同过滤虽然简单,但是对于用户行为较少的情况,协同过滤的效果也非常不稳定,如果是完全没有用户行为,那就更加束手无策。
2.基于内容的推荐(Content-Based,CB)
基于内容的推荐更多地依赖物品画像,比如我们为商品都标注上标签,如果你点过一个带有“自驾”标签的商品,那么基于内容的推荐会给你推送其他带有“自驾”标签的商品。这种方案不再需要大量的用户行为,但是需要好好对物品进行处理,能够完整、细粒度地刻画物品特征才能有较好的效果。
3.基于知识的推荐(Knowledge-Based,KB)
前面两种方法都是基于用户行为的推测,基于知识的推荐则是在明确需求与结果的情况下进行的。首先需要有明确的知识体系,比如说“下雨要打伞”这样的知识,然后用户告诉推荐系统“下雨了”,那么就可以给用户推荐雨伞。这种推荐不需要有之前的用户行为,但是要想总结这种知识则是非常困难的。当然,随着近些年知识图谱的发展,基于知识的推荐应用也变得越来越多。
4.混合型推荐
顾名思义,混合推荐就是结合上面几种不同的方案同时应用在一套推荐系统框架中。实际上,公司中所使用的推荐系统通常都是混合推荐系统,借助上面每一种推荐方案来解决不同场景下的问题。
冷启动问题
推荐系统虽然很美好,但是有一个问题始终绕不过去,这就是推荐系统的冷启动问题。由于我们上面讲的推荐系统是依赖用户行为计算的,那么对于没有行为的用户,或者刚刚产出的新闻或者商品没有对应的行为数据,没办法按照上面所讲的步骤进行用户与物品的匹配,这就是推荐冷启动问题。从冷启动对象来分,可以分成三种情况。
1.用户冷启动
这是指对于一个新用户,我们没有他的历史行为,也就很难去计算他的兴趣偏好、他的价值。对于新用户的解决方案,你可能见到过,比如当你刚注册一个应用的时候让你自己选择兴趣点;或者是利用一些边缘信息,比如用户的注册信息、手机型号、用户的网络制式;再者可以给用户推荐一些热门内容或者优质内容。
2.物品冷启动
物品的冷启动比起用户的来说可能会好一点,因为我们自己会掌握物品本身的信息,即便是这个物品还没有行为数据,我们可以根据基础属性以及算法结果给出一些匹配用户。如果在流量比较充足的情况下,给每一个新物品一定的基础曝光,让它产生一些用户行为,利用这部分行为数据再进行下一步计算。
3.系统冷启动
系统冷启动是说在一个全新的推荐场景,没有任何用户数据,只有部分物品数据。这种情况下,可以借助运营知识,先制定一些公认的规则,逐步累积数据,并随着用户的增长进行调整,直到系统相对稳定的状态。
如何做数据化运营
对于数据运营来说,最核心的工作就是制定人货场的匹配策略,所要解决的就是在什么样的“场景”下给什么样的“用户”展示什么样的“货物”以达到什么目标。
1.理解业务
运营动作往往都有一个明确的目标,比如说要拉新,或者要促活,或者要提升转化等等,因此数据化运营首先也需要对业务有深入的理解,清楚业务的目标与业务流程。
2.制定目标
在对业务的整体认知下,针对一次运营动作设定目标,比如说在暑期提高亲子类目商品的新客转化,以及本次的核心指标,比如新客转化的人数提升 10%。
3.细分拆解
有了目标和核心指标,接下来就需要对其进行细分拆解了,这也是数据化运营的一项核心能力。
针对上述目标我们来看一下,针对的用户群体为有亲子倾向的用户,同时是亲子商品的新用户,继续细分,这些新用户的消费区间是什么样子的,用户年龄是怎么分布的,除了亲子还有没有其他兴趣。
对于商品,则是亲子类目商品,继续细化,这些商品是益智类的卖得好还是娱乐类的卖得好,是品质高的卖得好还是便宜货卖得好。
对于场景,我们需要关注亲子类目商品可能出现的场景,比如说推荐场景、搜索场景、运营位场景等等。
对人货场三方面拆解完,还需要对其中的指标进行细化,清楚其中的哪些指标会与我们的核心指标相关。比如说,亲子用户在推荐场景下单的比例比搜索场景高,但是搜索场景的亲子用户复购率高。通过剥洋葱式的方法一层层拆分,将原本庞大的目标拆分成可操作的动作,进而确定我们的试验策略。
4.推进执行
根据既定的方案,下一步就是推动方案的落地实施。数据化运营项目往往是跨多个部门,涉及流程中的产品、运营、数仓、分析师、数据挖掘与算法工程师、后端研发,甚至是前端与设计人员,在执行环节仍然需要在以下两方面保持高度的关注:
进度的控制
实施效果的控制
5.检验结果
数据运营方案如期上线,但数据运营的工作还没有结束,还需要跟踪核心指标是否会随着我们的策略上线,朝着我们想要的方向变化。随着时间的流逝,如果确实朝着目标改变,那么说明策略有了效果,但是是否跟预期的目标一样多,或者这个变化是否稳定,以及还有没有其他可能的因素影响了结果?这些东西需要在回收结果的时候再次进行分析。
反过来,如果策略上线了,数据没有变化,或者甚至效果反而下降了,同样也需要去分析原因。有了这些分析的结果,我们即将进入下一个循环,调整策略,或者制定下一个目标。所以,上线并不是一个结束,而是下一个开始。
辅助运营的指标模型
1.RFM 模型
第一个指标体系是 RFM 模型,RFM 主要是针对用户的分析,一般对于用户价值的衡量和分析都可以以 RFM 模型为基础,不断地进行拆分和细化。
R(Recency):指的是最近一次交易的时间间隔。
F(Frequency):指的是用户的消费频率,一般是在一个时间范围内的消费频率。
M(Monetary):指的是消费的金额,同样,也是在一个时间范围内进行计算的。
根据 RFM 模型,我们首先可以对用户做出一层区分,这个用户是高价值用户还是低价值用户,是处在用户生命周期的头部还是尾部。对用户方面的理解通常可以以 RFM 模型为根基,做进一步的细化,最后筛选出我们运行需求的用户群。
2.AARRR 模型
第二个我要介绍的模型是 AARRR 模型。在 AARRR 模型对应着运营的五个环节,即获取(Acquisition)、激活(Activation)、留存(Retention)、收入(Revenue)、推荐(Referral)。
对于我们的 App,或者说每个产品功能,其实都具备这样的生命周期:
首先是通过各个渠道获得曝光,让用户知道这款产品,并能够吸引到我们的产品上来;
然后是去激活这些新用户,让他们开始使用我们的产品;
在对产品体验过以后,我们期望用户能够留存下来,而不是用完就流失了,我们希望用户能经常来使用我们的产品;
对于留下来的用户,还要引导他去付费,给我们带来收入;
最后,我们还期望用户能够主动去宣传我们的产品,把产品推荐给他的朋友使用。
这就是 AARRR 模型的全路径。在数据运营的目标中,基本上都可以拆分到这其中的一个或者多个环节里,围绕着这些环节去拓展你的指标,并制定相应的提升策略,便于我们全面地分析问题。
辅助运营的系统
作为数据驱动的重点应用,数据化运营在各个公司中也变得越来越重要。随着公司规模的不断扩大,数据化运营需求每天每时每刻都在不断地扩充,这不仅仅是运营人员的工作,也是产品、研发、算法、市场的共同追求。自然而然,大量的数据运营需求存在着很多的共性,为了让数据化运营更加精细,更加迅速,也产生了很多辅助运营的工具与系统。
我们前面所讲过的 Hive 当然可以直接拿来使用,数据分析、数据挖掘和数据可视化中的工具也可以用于数据化运营,但是这些工具相对于触达用户的运营策略有点过于底层,并且对于非研发人员的使用并不友好,所以,需要有更加面向运营的工具。这里我要讲的是圈人系统和选品系统。
在《19 | 如何快速搭建一个推荐系统?》中,我们提到了可以用用户画像和物品画像来辅助运营。这里我们所讲的工具,也是从用户画像和物品画像所衍生出来的。在推荐系统或者某些研发算法场景,我们所使用的用户画像和物品画像往往以特征数据的形式呈现,尤其是在现在深度模型流行的情况下,只需要把这些特征数据压缩成向量表示即可。这种形式的用户画像和物品画像对于神经网络来说是可以接受的,但是对于运营人员则没有任何意义。
在圈人和选品系统,主要使用的是用户画像和物品画像标签化的结果,而且标签通常都是有限个的,以方便运营人员查看。
圈人系统往往包含个体画像、群体画像的展示,包含用户分群功能,以及数据透视功能:
个体画像是对于单个用户的总体情况进行展示,主要用于运营抽样分析和检验圈人的实际情况;
群体画像则是对已有的标签所包含的人群分布进行展示,以方便运营人员圈选人群前进行观察和思考,比如说用户年龄段的分布情况,用户在兴趣维度上的分布等等。
圈人功能则是这个系统的主要功能,通过运营人员可以理解的标签,对用户进行圈选,以用于某个运营策略,比如我们上面要对亲子用户进行运营,这里就是用兴趣标签【亲子】即可筛选出对应的用户群。
最后的数据透视,则是对于圈出的用户群进行初步的分析,以确保圈出的结果和运营想要的一致,比如展示圈出人群的总数、性别比例、消费能力等等。在筛选完人群之后,通常可以把人群列表自动化对接到后续的功能上,比如说小场景的推荐,或者是定向 Push。
下图即是某圈人系统的界面,可以看到,所有用户画像都已经标签化,运营人员可以针对自己需要的人群标签进行选择,在右侧可以配置不同标签条件的与或非关系,从而生成所需要的人群列表。
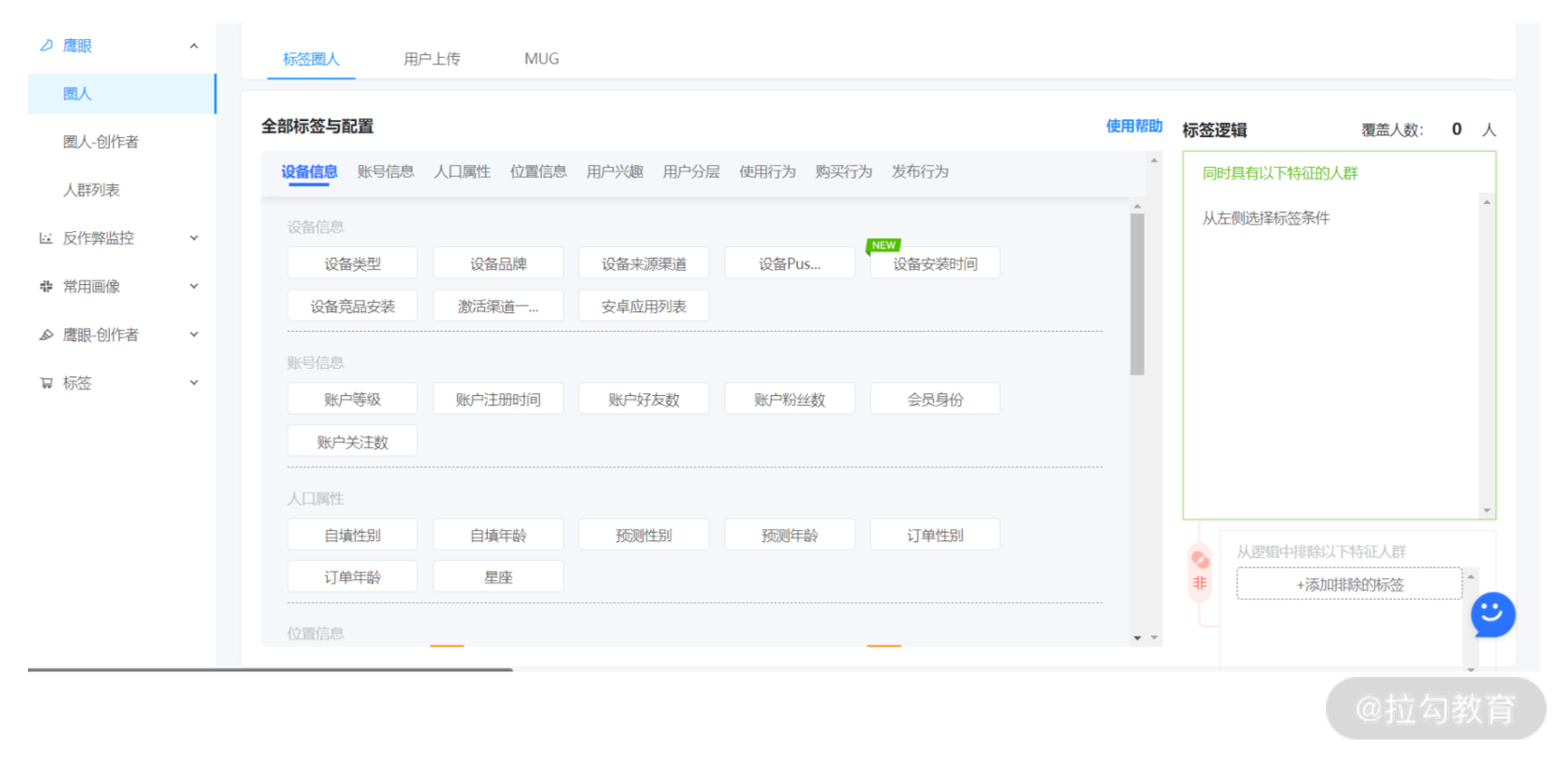
与圈人系统相对应的选品系统,亦是同样的逻辑。基于我们对物品的数据挖掘和分析,并把结果标签化为运营人员可理解的有限个标签,在同样的一个系统上进行单物品展示、属性总览,以及物品圈选和数据透视,通过运营人员对所需要物品的筛选,生成一个物品列表,等待使用。
通过对用户和物品筛选的平台化,辅助运营加速了对“人”和“货”的挑选过程,对已经筛选好的用户和物品,接下来就是投放到某个“场”,完成运营的执行动作。当然,对于投放环节也可以建设相应的平台来辅助运营,常见的有触达平台或者营销平台,有兴趣的同学可以在课下进行了解。
数据安全问题
我们的大数据体系之下囊括了各种各样的数据,从数据的生产开始,大量数据源源不断地进入我们的大数据平台中,被加以处理和利用。自然,大数据给很多公司带来了大量的收益,也给用户提供了很多便利的服务,为社会创造了很多价值,但是,与之伴随而来的,是各种各样的数据安全问题。在这里,我们先来看一下在大数据体系之下,或者说我们的公司中都会存在着什么样的数据安全问题。
1.硬件安全
首先是硬件方面的安全问题。比如说我们的硬盘、内存、CPU 等,虽然硬件的使用周期很长,但是这些设施长时间使用仍然会有故障出现,尤其是在大数据下,服务器数量众多,大公司或者云服务供应商动辄就有成千上万的服务器。除了本身的故障问题,还可能受到自然灾害、人为破坏的影响,如果硬件发生大面积的问题可能导致我们的服务出现问题。
2.平台安全
平台安全主要是指我们的大数据平台,其中用到很多工具,这些内部使用的平台工具虽然经过很多经验丰富的开发人员开发和使用,但是仍然难免存在着一些缺陷或者漏洞,以及在遇到一些攻击时,可能在某些环节产生数据泄露。
3.服务安全
第三个是提供服务时的安全问题。大数据平台当然不是只放在那里就可以了,我们使用大数据平台来建设公司内部的能力,从而能利用这些数据对外提供服务,包括我们对用户提供的服务和我们内部的服务,比如上节课讲到的圈人系统。对于这些服务,面临的安全风险就更多了,因为这些服务有很多对外暴露的地址、端口等访问方式,如果其中存在一些高风险漏洞就可能被不法分子利用。
4.流程安全
上面三种可以说都是基于数据的容纳场所的安全,不管是服务器还是大数据平台,数据在上面存储和流转,如果它们本身存在安全问题数据当然是不能幸免的。
但是在我们日常的工作中,数据并不只是在这里面存放,而是会有很多的人在使用这些数据。不管是数据分析师通过大数据平台进行分析,还是数据挖掘同学把数据转移到 GPU 机器上进行运算,都是使用数据的正常流程,但是在这些流程中,数据安全问题也非常值得关注,不然在数据经过几次复制转移之后,到底有多少数据流出去,到底有没有重要数据被泄露,已经没有人说得清楚了。
数据安全的技术方案
可以看到,在我们的公司中,面临的数据安全问题很多,所以要严加防范,那么在一般情况下都有什么样的技术方案来解决数据安全问题呢?
1.安全分级
首先我们可以对数据的安全等级进行划分,比如说:
用户的真实信息为最高密级;
用户的相关信息为次高密级;
用户的行为信息为一般密级;
公开信息为最低密级。
依照制定好的数据安全等级,在不同的环节给予不同的处理方案,比如说在数据的存储方面,给高安全等级的数据增加更多安全硬件设施;在权限审核上更加严格等等。
有了比较明确的安全等级,也方便对数据安全问题进行监控,一旦发生数据不合规的数据传输,方便确认风险大小。如果没有明确的安全等级,对我们的大数据中所有数据一致管理,要浪费很多资源不说,同时在发生问题时也很难确认该如何处理。
2.权限认证
在大数据体系中,会有很多环节和工具涉及数据的存储和应用,同时,在公司中还有很多的系统会涉及这些数据的使用。在公司层面统一一套权限认证的标准,对于不同安全等级的数据,对使用方采取统一的权限管理,不管是个人使用还是系统使用,都可以接入这个权限认证体系,这样既可以节省数据流转时各种烦琐的申请和审批手续,又可以对数据的应用情况了如指掌。在大数据工具中,有一个通用权限认证解决方案:Kerberos,可以为我们前面提到的很多大数据工具提供权限认证服务。
3.资源隔离
资源隔离方面,通常采用的是多租户方案,也就是在一套硬件上,为不同安全等级的数据建设多套架构服务,比如说对于大数据中的存储 HBase,对高安全等级的数据使用一套单独的 HBase存储,对低等级的数据采用另外一套Hbase存储。这样在操作的时候都是分隔开的,也方便对数据的监控。
4.数据加密
数据加密很容易理解,也是很早就有的技术了。简单来说,加密技术就是通过一些变换算法,把原本的数据处理成不可读或者没有意义的数据,只有加密人本身知道如何将加密后的数据还原。
之前去平遥古城,那里的日升昌票号是中国第一家银行,他们的汇票就已经在采用加密技术,比如把 1 到 12 个月用文字“谨防假票冒取,勿忘细视书章”进行替代。
对于不同安全等级的数据,我们可以采用不同等级的加密技术,同时在数据的传输和存储环节也有不同的加密方案。加密技术是一门涉及很广的课程,现代密码技术一般分为对称加密和非对称加密,如果对这方面感兴趣的同学可以去学习一下密码学。
5.数据备份
数据备份主要是防止发生大面积的网络问题、数据丢失情况,以及人为破坏或者自然灾害等不可以预料的问题。针对不同安全等级的数据,我们也可以采取不同的备份策略,比如对于安全级别高的数据采取实时的多存储方案,对于低安全级别的数据定期进行备份等。
6.数据脱敏
数据脱敏一般是对数据监控环节进行的。对于安全级别较高的数据可以认为是敏感数据,比如说用户的姓名、手机号等,但是在数据传输或者使用过程中,往往会跟其他部分混杂在一起。在对数据的流转进行监控的过程中,如果发现涉及敏感数据,可以对数据进行替换、隐藏等等操作,以防止敏感数据泄露。这种方案一般是针对数据对外开放的时候采取的措施。
7.分享水印
针对数据分享时候的安全问题,除了脱敏还可以采用水印技术。不管是内部的可视化平台,还是对于可分享的文件、图片或者 PPT 等资源,统一加入水印来标记。在一些公司分享的资料中,你经常会看到一些可见的水印标记,当然,对于数据也可以加入一些隐藏水印,达到安全防护的作用。水印技术虽然不能防止数据泄露,但是能够通过水印追踪负责人,属于一种事后手段。
除了这里所讲到的技术手段,公司在面对数据安全问题的时候,还需要配合管理手段来建立一套比较完善的数据安全管理机制,对公司内的人员进行宣传教育,提高大家的防范意识,并且在数据生产、数据存储、数据传输、数据应用等环节进行事前的保障、事中的监控、事后的追踪。
什么是数据中台
很多公司饱受这些问题的困扰,想要改进却不知从何入手。这个时候,数据中台概念横空出世。说起数据中台的提出还有一个小插曲,据说早在 14 年,马云去参观芬兰的游戏公司 supercell,这个只有不到 500 人的公司通过一个中台组织负责开发游戏引擎、素材、算法等等,而具体的游戏业务都可以复用这些东西,创造了诸如《部落冲突》《海岛奇兵》《皇室战争》等多款策略游戏。回来之后马云受其启发,在阿里推出中台战略,推动 “大中台,小前台” 的组织调整。
说了这么多,到底什么是数据中台呢?有一个公开的定义是通过数据技术,对海量数据进行采集、计算、存储、加工,同时统一标准和口径。这个定义乍看似乎并没有什么特别的地方,感觉跟一个统一的数仓并没有什么区别,但是实际上这句话只是对于数据中台中技术方面的解读,从《阿里巴巴数据中台实践》的资料中我们可以看到,数据中台所承载的功能是数据业务化,链接所有数据,赋能业务,数据中台距离业务更近,能更快速地响应业务和应用开发的需求,可追溯,更精准。
所以,除了技术方面的采集、计算、存储、加工等能力,数据中台更多的是要有业务能力,考虑业务的需求,而不是单纯做技术方面改进,如何通过对数据的统一管理进而提升业务目标是数据中台最需要考虑的事情。
数据中台解决的问题
1.统一数据汇集
要做数据中台,首先就需要有数据汇集的能力。如果说每一个业务都是一条高速公路,那么数据中台就是交通枢纽站。各个业务所需要的数据,所产生的数据都流入数据中台,由数据中台对这些数据进行统一管理,这样一旦有项目需求即可从数据中台获取,而不需要再一个业务一个业务去了解沟通。数据汇集可能涉及大数据中的数据采集、计算、存储等各种工具。
2.统一数据管理
数据只是单纯汇集起来并不能够说是数据中台,在数据中台需要有良好的数据管理能力。数据管理就是需要对现有的数据有很好的理解能力,现在有多少数据、不同业务所汇集的数据是否存在联系、数据的分布、数据的趋势如何等等,在这个环节,对统一数据进行整理分析以及可视化,除了前面的存储、计算还会涉及可视化、数据分析等。
3.统一数据研发
数据研发是面向业务所进行的数据加工。我们大数据的课程就是建立在数据有价值的基础上,所有的环节也都是为了从数据中获取价值而构建。从业务需求的角度考虑,对数据进行加工,从大数据中萃取业务价值,比如说提供统一的标签体系解决我们开头讲的小故事中的问题,就是数据研发所需要处理的事情。在这个环节,会涉及数据挖掘相关的技术。
4.统一数据服务
基于对数据的汇集、管理以及研发,数据中台是对全局数据最为了解的部门。同时,为了赋能业务,数据中台同时也要清楚地知道业务所需要的,并提供统一的数据服务以方便业务应用。对于一些通用的数据能力,比如说推荐系统、搜索系统也可以建设成统一数据服务,只需要为业务方提供自由的配置即可在需要的位置上线。
经过了上面几个步骤,数据中台自然而然解决了我们在工作中经常遇到的几个问题。
部门协作:一个项目往往涉及多个部门的数据,甚至是由多个部门合作共同完成,每一个项目都需要一次沟通协调,需要对当前各部门的现状和数据进行一番梳理,项目需求其实都比较类似,只不过有时候是这个部门主导,有时候是那个部门主导。在数据中台的支持下,项目主导者都可以在数据中台完成对各部门所需数据的了解,减少沟通成本,加强部门协作。
重复造轮子:对于一个公司内部的应用,往往都存在着很大的关联性,比如说字节跳动的抖音、火山视频、西瓜视频都是以视频型内容为主的 App,里面关于数据的采集、存储、计算、搜索、推荐、用户画像及内容画像必然极为相似,数据中台则可以为其提供统一的数据服务,只需要一套开发人员,如果每个应用都单独建设将浪费很多人力,且生产出来的东西都是重复的东西。通过数据中台的功能复用,业务部门也可以更加聚焦在精细化运营上,专注于自己的业务特色。
效率问题:在公司中一个项目的数据链路很长,比如在我之前的工作中,发现推荐出来的内容缺少了电视节目,首先从推荐查到自己的推荐池数据,然后又找到内容生产平台,最后发现是数据源头所取的数据表字段发生了变化,耗费了大量的时间。数据中台对数据统一采集和管理,使得此类经常出现的问题得以抽象出统一的解决方案,并在数据中台即可完成整个流程,大大增加了工作效率。
避免落入中台战略坑
自从阿里巴巴推出了数据中台的概念,并将数据中台在公司内部进行大力推广和应用,无数的 CTO、CEO 开始纷纷效仿。数据中台既然这么香,那是不是每一个公司都需要有一个数据中台呢?答案是否定的。数据中台的理想虽然很好,但不是每一个公司都有需要,而且也不是每一个公司都可以做成,我觉得在做数据中台的时候至少要考虑以下三个问题。
1.是否有明确的业务需求
业务需求是搞数据中台的基础,如果说你的业务很单一,或者只有两三个重复业务,数据流程不复杂,业务部门不会交叉折叠,那么大概率你是不需要搞什么数据中台,如果硬生生搞出来一个没有业务使用的中台,那只是徒增公司负担。
2.是否有强有力的推动者
只有需求还不足以支撑我们启动数据中台计划。由于数据中台是贯穿公司全部业务的,且工程量巨大,首先是需要投入大量的人力和资金,同时还需要各个部门共同配合来完成。如果说这样的项目没有自上而下的强力推动者,往往会半途而废,即便是勉强完成,也一定是缺斤少两,只是有一个数据中台的样子,而其可用性则会大打折扣。
3.是否有明确的组织和制度
强有力的推动者可以保障数据中台项目的启动和落成,但是后续的使用和规范则需要有明确的组织和制度进行保障。数据中台不是一个一次性的项目,需要不断地进行迭代和升级。随着业务的扩充、技术的发展,负责数据中台的组织也需要不断地提升自己的能力。在使用方面,如果没有良好的制度,随着时间的流逝,数据中台可能又会变成一个废弃的项目。
因此,数据中台对于公司的问题是一个很好的解决方案,但不是所有的公司问题都可以通过数据中台来解决。不要让数据中台成为 KPI 或者 OKR 的产物;也不要说公司业务缺乏发展动力,搞一个数据中台缓解老板的焦虑。数据中台不仅仅是一个技术型的项目,更多关系到公司文化、制度、组织多方面的协调,这些方面的能力都要具备才有可能完成数据中台的建设,否则可能就是一个消耗公司资金的累赘。
实时流计算
在初次接触实时流计算业务场景时,不可避免地会遇到种种难题,比如以下几点。
需要统计的时间窗口很长,数据量也很大。比如“相同设备在 3 个月内注册事件的次数”,此时,如果你想实时计算获得结果,就不能够通过遍历数据库的方式来实现了。
需要统计的变量,其值域非常大。比如“同一用户在 6 个月内使用不同 IP 个数”,如果是数亿用户和数亿 IP,你还能够用集合来记录这些不同的值吗?更何况,还需要在指定的时间范围内进行计算。
一次完整的业务,可能需要计算数十个甚至数百个特征。比如,实时风控系统中,风控模型的输入便是如此。为了保证用户体验,风控系统必须在数秒甚至数百毫秒内返回。
有些问题的算法,天然就很复杂,数据量又很大,如何做到实时计算呢?比如,社交网络的二度关联分析,还有许多复杂的统计学习和机器学习模型。
甚至有些时候,产品和开发人员都不清楚,是否需要或者能够,使用实时流计算技术。或许难以置信,但这样的公司和开发人员,真的不在少数。
如果想切实解决这些难题,就需要透过现象看本质。我认为,之所以会出现上面的种种难题,主要是因为以下五种原因:
一是,缺乏对实时流计算技术以及它的适用场景的整体认识;
二是,不知道如何用“流”来实现各种业务逻辑的异步和高并发计算;
三是,不知道如何针对“流”这种独特的数据模式,设计实时算法;
四是,对各种流计算框架的认识只停留在 API 调用层面,而没有理解其背后的设计原理,也就是“流”这种计算模式的,核心概念和关键技术点;
五是,缺少对一些已有案例的借鉴和思考。
如何解决实时流计算问题?
既然明确了问题,接下来我们应该怎样克服呢?我认为可以从系统架构和实时算法两个方面来突破。
系统架构
从架构师的角度看,要为产品设计一个好的实现方案,既要有足够的技术储备,也要充分理解具体的业务问题。通过分析各类实时业务场景,我们可以发现,大多数方案都是基于“流计算”技术的。
“流计算”本质上是一种“异步”编程方法。业务数据像“流水”一样,通过“管道”,也就是“队列”,持续不断地流到各个环节的子系统中,然后由各个环节的子系统独立处理。所以,为了更快地处理“流”,可以通过增加管道的数量,来提高流计算系统的并行处理能力。
目前,开源的流计算框架虽然有许多(比如 Storm、Spark Streaming、Samza 和 Flink),但其实这些主流框架背后,都有着一套类似的设计思路和架构模式。它们都涉及流数据状态、流信息状态、反向压力、消息可靠性等概念。先行理解这套设计思路和架构模式,可以帮助你快速掌握,所有主流流计算框架的工作原理。
实时算法
系统架构提供了整体的计算框架,但要实现具体的业务功能,还需要针对“流数据”设计合适的算法。 毕竟,与传统“块数据”相比,“流数据”需要连续不断并且实时地进行处理。
对于实时流计算中的算法,最最核心的问题,在于解决“大数据量”和“实时计算”之间的矛盾。数据量一大,几乎所有事情都会变得复杂和缓慢。“大数据量”的问题,集中在四个方面:时间窗口很长、业务请求量很大、内存受限、数据跨网络访问。
为了实现“实时计算”的效果,需要你针对算法做非常精心的设计。所幸的是,这些算法的设计和实现也是有规律可循的。 你只需要掌握几种特定类型的算法,比如计数、求和、均值、方差、直方图、分位数、HyperLogLog 等。而对于更加复杂的算法,如果不能直接进行实时计算,那我们可以通过 Lambda 架构来解决!
实时流计算技术应用场景
图 1 是某打车软件公司交通热点路段分析及可视化系统的示意图。
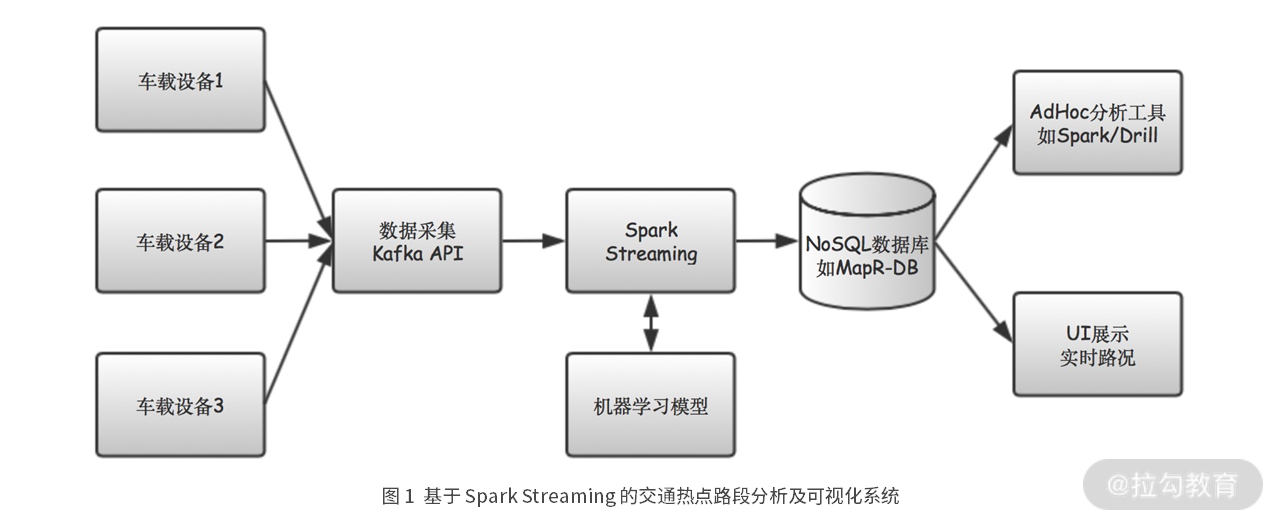
在这个系统中,从车载设备上发出的数据,被一个基于 Kafka API 的数据采集模块接收,然后发送到 Spark Streaming 模块进行处理,并且还使用机器学习模型进行分析,然后分析的结果以 JSON 的形式存储到数据库中,并提供给可视化模块进行展示和分析。
我们再来看另一个金融风控的例子。图 2 是一个基于 Flink 的实时欺诈检测平台。
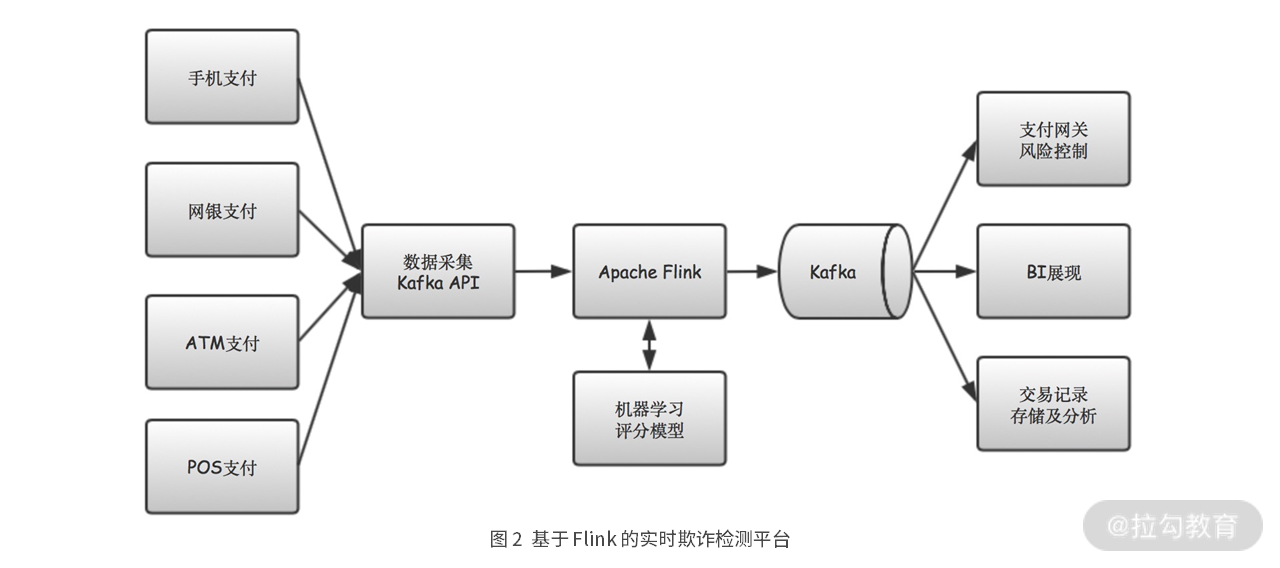
在这个平台中,从手机等各种支付渠道产生的交易数据,被数据采集服务器收集起来,并发送到Kafka。然后 Flink 从 Kafka 中将交易数据取出来,采用基于机器学习的风控模型,进行风险分析和评估。然后分析的结果再次发送到 Kafka,后续支付网关就可以根据这些交易的欺诈风险等级,来允许或阻止交易进行。
实时流计算系统通用架构
比较上面两个场景的流计算系统组成,我们不难发现这些系统,都包含了五个部分:数据采集、数据传输、数据处理、数据存储和数据展现。
事实上,也正是这五个部分,构成了一般通用的实时流计算系统,它们之间的组成关系如下图 3 所示。
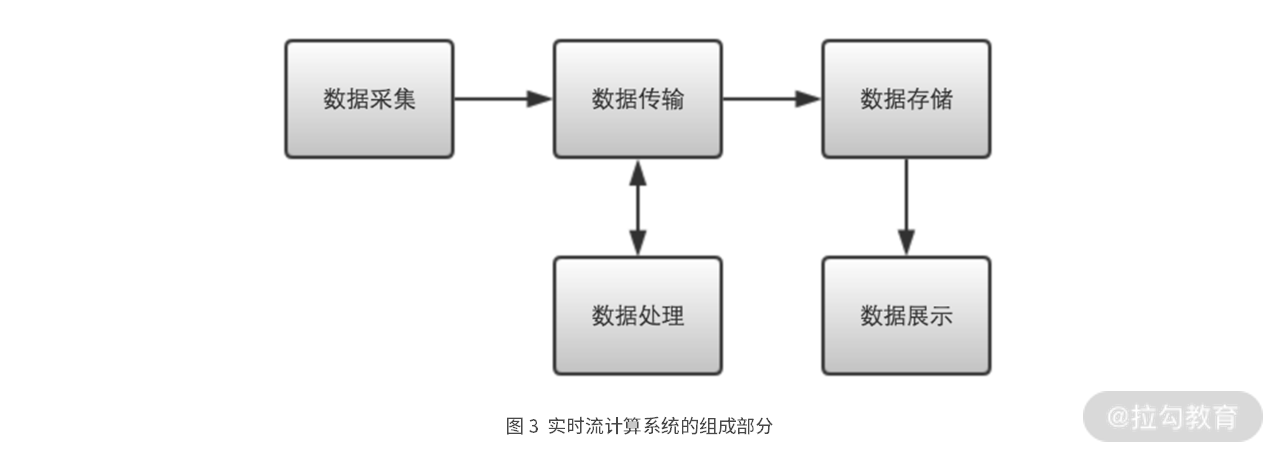
在上图 3 中,数据采集模块用于接收来自各种数据源的数据,比如互联网上的各种移动设备、物联网上的各种传感器,内部网络中部署在各个服务模块上的日志代理等。数据采集模块收集到这些数据后,对数据进行一定整理,再将数据发送到数据传输模块。
数据传输模块通常是消息中间件,比如 Kafka,之后再由数据处理模块从数据传输模块中取出数据来进行处理。数据处理模块是流计算系统的核心,在这个模块中会实现流计算应用的各种业务功能。
之后,计算结果被重新发送到数据传输模块,并由数据存储模块取出后,保存到各种类型的数据库中。最后,数据展示模块会通过 API 或者 UI 的方式对结果进行展示。
下面我来逐一详细介绍下通用架构的五个部分。
数据采集
俗话说“巧妇难为无米之炊”,有数据了,我们才能进行流计算,所以我们先来看看应该怎样采集数据。
数据采集,就是从各种数据源收集数据的过程,比如浏览器、手机、工业传感器、日志代理等。怎样开发一个数据采集服务呢?最简单的方式,就是用 Spring Boot 开发一个 REST 服务,这样,我们就可以用 HTTP 请求的方式,从浏览器、手机等终端设备,将数据发送到数据采集服务器。
这么一看,数据采集服务器似乎很简单!其实不然,这中间还是有很多问题需要认真考虑。如果考虑不周的话,很可能你花冤枉钱买了许多服务器,但是系统的性能却依旧十分可怜。
为了避免在以后的开发中出现这种问题,这里我想跟你分享下我在日常开发 Web 服务时考虑的五个关键点。
第一点是吞吐量。我们一般用 TPS(Transactions Per Second),也就是每秒处理事务数,来描述系统的吞吐量。当吞吐量要求不高时,选择的余地往往更大些。你可以随意采用阻塞 IO ,或非阻塞 IO 的编程框架。但是当吞吐量要求很高时,通常就只能选择非阻塞 IO 的编程框架了。如果采用阻塞 IO 方式时,需要开启数千个线程,才能使吞吐量最大化,就可以考虑换成非阻塞 IO 的方案了。
第二点是时延。当吞吐量和时延同时有性能要求时,我一般是先保证能够满足时延要求,然后在此基础上,再尽可能提高吞吐量。如果一个服务实例的吞吐量,满足不了要求,就部署多个服务实例。对于互联网上的应用,如果吞吐量很大,为保证时延,还需要使用类似于 CDN 的方案。
第三点是发送方式。数据可以逐条发送,也可以批次发送。相比逐条发送而言,批次发送每次的网络 IO 耗时更多,为了提升接收服务器的吞吐能力,我一般也会采用 Netty 这样的非阻塞 IO 框架。
第四点是连接方式。使用长连接还是短连接,一般由具体的场景决定。当有大量连接需要维持时,就需要使用非阻塞 IO 服务器框架,比如 Netty。而当连接数量较少时,采用长连接和连接池的方案,一般也会非常显著提升请求处理的性能。
第五点是连接数量。如果数据源相对固定,比如微服务之间的调用,那我们可以采用长连接配合连接池的方案,这样一般会非常显著地提升请求处理的性能。但当数据源很多或经常变化时,应该将连接保持时间(Keep Alive Timeout)设置为一个合理的值。
总的来说,在大多数情况下,数据接收服务器选择诸如 Netty 的非阻塞 IO 方案,都会更加合适。
数据采集之后,我们一般还需要做些简单的处理,比如提取出感兴趣的字段,或者对字段进行调整等,然后再将调整好的字段,组成格式统一的数据,比如 JSON、AVRO、Protobuf 等。最后将整理好的数据,发往到数据传输系统。
数据传输
我们这里说的数据传输,是指流数据在各个模块间流转的过程。
流计算系统中,一般是采用消息中间件进行数据传输的,比如 Apache Kafka、RabbitMQ 等,在微服务系统中一般是采用 HTTP 或 RPC 的方式进行数据传输。这是流计算系统与微服务系统最明显的区别。
在选择消息中间件时,你需要重点考虑五个方面的问题:吞吐量、时延、高可用、持久化和水平扩展。为什么呢?
这是因为,吞吐量和时延,通常是由产品和业务需求决定的。比如,产品要求系统能够支持 10K 的 TPS,并且 99% 消息的时延不能超过 100ms,那我们部署的消息中间,吞吐量一定要显著超过 10K,时延要显著低于 100ms,因为还需要留出非常大的空间,来处理业务逻辑。
而高可用和持久化,则是保证我们系统,能够正确稳定运行的重要因素。
高可用是指消息中间件的一个或多个节点,在发生故障时,仍然能够持续提供正常服务。比如双 11 的零点,大家都在拼命剁手,此时如果因为一个节点磁盘写满,而导致整个系统不能下单,那真的就是瞬间错失一个亿的小目标了。
持久化则是指消息中间件里的消息,写入磁盘等存储介质后,重启时消息不会丢失。比如在消息中间件 Kafka 中,同一份数据在不同的物理节点上,保存多个副本,即使一个节点的数据,完全丢失,也能够通过其他节点上的数据副本,恢复出原来的数据。
水平扩展也是个非常重要的考量因素。当业务量逐渐增加时,原先的消息中间件处理能力逐渐跟不上,这时需要增加新的节点,以提升消息中间件的处理能力。比如 Kafka 可以通过增加 Kafka 节点和 topic 分区数的方式水平扩展处理能力。
总的来说,数据传输系统就像人体的血管,承载了实时流计算系统中数据的传输。一个高吞吐、低时延、支持高可用和持久化,且能水平扩展的数据传输系统,是构建优秀实时流计算应用的基础。目前,像 Kafka 和 Pulsar 都是不错的数据传输系统选择。
数据处理
接下来,我们来看下流计算系统的核心模块,即数据处理。为什么说数据处理,是流计算系统的核心呢?这是因为在数据处理模块,我们将实现各种业务功能,比如数据过滤、聚合计算、CEP、模型训练等。
我们构建实时流计算系统的目的,就是为了解决具体的业务问题。总的来说,这些业务问题可以分为以下四类。
第一类是数据转化。数据转化包括对流数据的抽取、清洗、转换和加载。比如使用 filter 函数过滤出符合条件的流数据,使用 map 函数给流数据增加新的字段。再比如更复杂的 Flink SQL CDC,也属于数据转化的内容。
第二类是在流数据上,统计各种指标,比如计数、求和、均值、标准差、极值、聚合、关联、直方图等。
第三类是模式匹配。模式匹配是指在流数据上,寻找预先设定的事件序列模式。比如我们常说的 CEP,也就是复杂事件处理,就属于模式匹配。
第四类是模型学习和预测。基于流的模型学习算法,可以实时动态地训练或更新模型参数,继而根据模型做出预测,能更加准确地描述数据背后当时正在发生的事情。
数据处理是流计算的核心,也是一个流计算应用开发人员最应该掌握的知识点。这部分的内容是非常丰富且有一定难度的,我将在本课程的模块三中,对数据处理问题进行详细讲解。
数据存储
使用实时流计算技术,一顿操作猛如虎,结果不记录,或者不输出结果的话,那就是算了个寂寞。所以数据处理过程中,必然会涉及,数据存储的问题。而数据存储,是一个非常麻烦的问题,特别是在实时流计算领域,这种大数据、低时延、高吞吐的场景,对我们的数据存储方案,挑战是非常大的。
不知道你是否考虑过这个问题,为什么软件行业,有那么多不同种类的数据库?MySQL、MongoDB、Redis、HBase、ElasticSearch、CockroachDB……随便想一下,就可以列举出数十种数据库。
这是因为每种数据库,其实都有其擅长的使用场景,没有一种数据库能够在所有场景下都能胜任,所以我在这里先抛砖引玉,针对实时流计算中几种最常见的场景,讲解下应该选择怎样的存储方案。
在实时风控场景下,我们经常需要计算诸如“过去一天同一设备上登录的不同用户数”这种类型的查询。在数据量较小时,使用传统关系型数据库和结构化查询语言是个不错的选择。
但当数据量变得很大后,这种基于关系型数据库的方案会变得越来越吃力,直到最后根本不可能在实时级别的时延内完成计算。这个时候,如果采用像 Redis 这样的 NoSQL 数据库并结合优化的算法设计,就能够做到实时查询,并获得更高的吞吐能力。所以相比传统 SQL 数据库,实时流计算中会更多地使用 NoSQL 数据库。
很多时候,我们需要将实时流计算的状态或者结果存储下来,以供其他服务根据一个或多个健,来查询一条特定的,实时计算记录。那这个时候,我们可以选择像 MongoDB 这样的 NoSQL 数据库。当然,这个时候如果在 MongoDB 之上,再配上一个 Redis 缓存也是极好的。
还有些时候,我们需要在 UI 上展现实时流计算的结果。不知道其他人是怎样想的,反正在我这个后端开发眼里,那些产品同学总喜欢在 UI 上设计一些“莫名其妙”的交互式查询,比如任意可选的查询条件和查询方式。那这个时候,我们选择的存储方案,就一定不能太“僵硬”,此时采用像 ElasticSearch 这样搜索引擎一类的存储方案,一定是个明智的选择。
总的来说,在相对复杂的业务场景下,实时流计算可能只是系统中的一个环节。我们需要针对不同的计算类型和查询目的,选择合适的存储方案。当一种数据库满足不了业务的需求时,我们还会将相同的数据,存入多种不同的存储。毕竟到目前为止,还没有一种能称之为“银弹”的数据库。
数据展现
最后就是数据展现模块了,数据展现是将数据呈现给最终用户的过程。
数据展现的形式,可以是 API,也可以是 UI。
API 相对简单,比如用 Spring Boot 就很容易开发一个 REST API 服务。
UI 目前越来越多的是采用 Web UI 的方式。
基于 Web 的 UI 有很多优点。一方面,其部署和访问都非常简单,只需要启动 Web 服务,然后在浏览器访问即可。另一方面,各种丰富的前端框架和数据可视化框架,为开发提供了更多的便利和选择,比如前端常用的框架,就有 React、Vue、Angular 等,然后常用的数据可视化框架,则有 ECharts、D3.js 等。
由于数据展示,更加偏向于前端(包括 UI 设计、JS、CSS 和 HTML 等),这与实时流计算的主体,并无太强关联,所以我在本课程中,不会专门讨论数据展示的内容。
小结
今天,我依据几种不同场景的流计算系统,总结了一个通用的流计算系统架构,然后带你了解了这个架构中各个模块在整个系统中起到的作用。
相信你在以后开发实时流计算应用时,十有八九会用到上面这种架构,并且一定会碰到我跟你讲的这些问题,尤其是数据采集、数据处理和数据存储三个模块。
数据采集模块的难点,一定会在高并发和高吞吐场景下暴露出来,这点需要你对 NIO 和异步编程有非常深刻的理解。
数据处理模块的难点,则主要表现在与业务的贴合。这要求你对流计算能够解决哪些问题有比较深刻的理解,并需要熟练掌握解决这些问题的算法。
数据存储模块的难点,则主要表现在能否根据具体的使用场景,选择最合适的存储方案。而实时流计算中,会涉及多种不同类型的数据存储问题。
为什么在讲流计算之前,要先讲异步和高并发的问题呢?
其一,是因为“流”本质是异步的,可以说“流计算”也是一种形式的异步编程。
其二,是因为对于一个流计算系统而言,其起点一定是数据采集,没数据就什么事情都做不了,而数据采集通常就会涉及 IO 问题,如何设计一个高性能的 IO 密集型应用,异步和并发编程既是过不去的坎,也是我们掌握高性能 Java 编程的基础。
所以,在这个课时中,我们就从数据采集模块切入,通过开发一个高性能的数据采集模块,从实战中理解 NIO、异步和高并发的原理。这样,当你以后开发高性能服务时,比如需要支持数万甚至数百万并发连接的 Web 服务时,就知道如何充分发挥出硬件资源的能力,就可以用最低的硬件成本,来达到业务的性能要求。
为了更方便地说明问题,我们今天的讨论,以从互联网上采集数据为例。具体来说,如下图 1 所示,数据通过 REST 接口,从手机或网页端,发送到数据采集服务器。
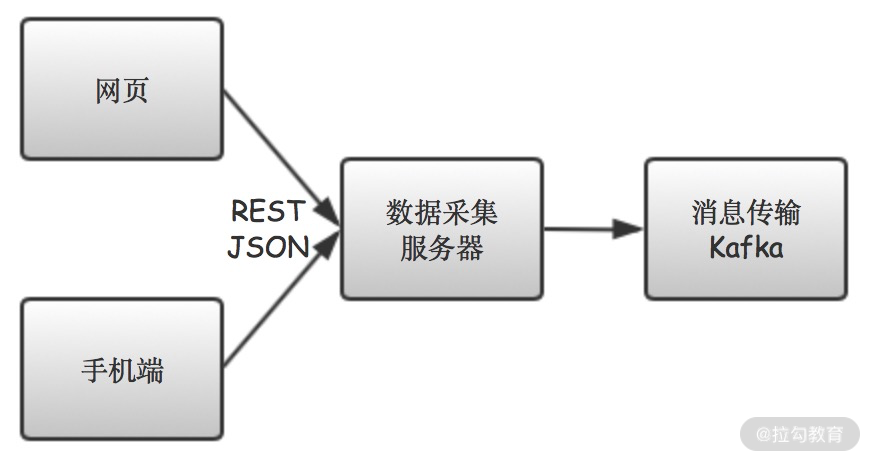
图 1 基于 REST 协议的数据采集服务器
BIO 连接器的问题
由于是面向互联网采集数据,所以我们要实现的数据采集服务器,就是一个常见的 Web 服务。说到 Web 服务开发,作为 Java 开发人员,十有八九会用到 Tomcat。毕竟 Tomcat 一直是 Spring 生态的默认 Web 服务器,使用面是非常广的。
但使用 Tomcat 需要注意一个问题。在 Tomcat 7 及之前的版本中, Tomcat 默认使用的是 BIO 连接器, BIO 连接器的工作原理如下图 2 所示。
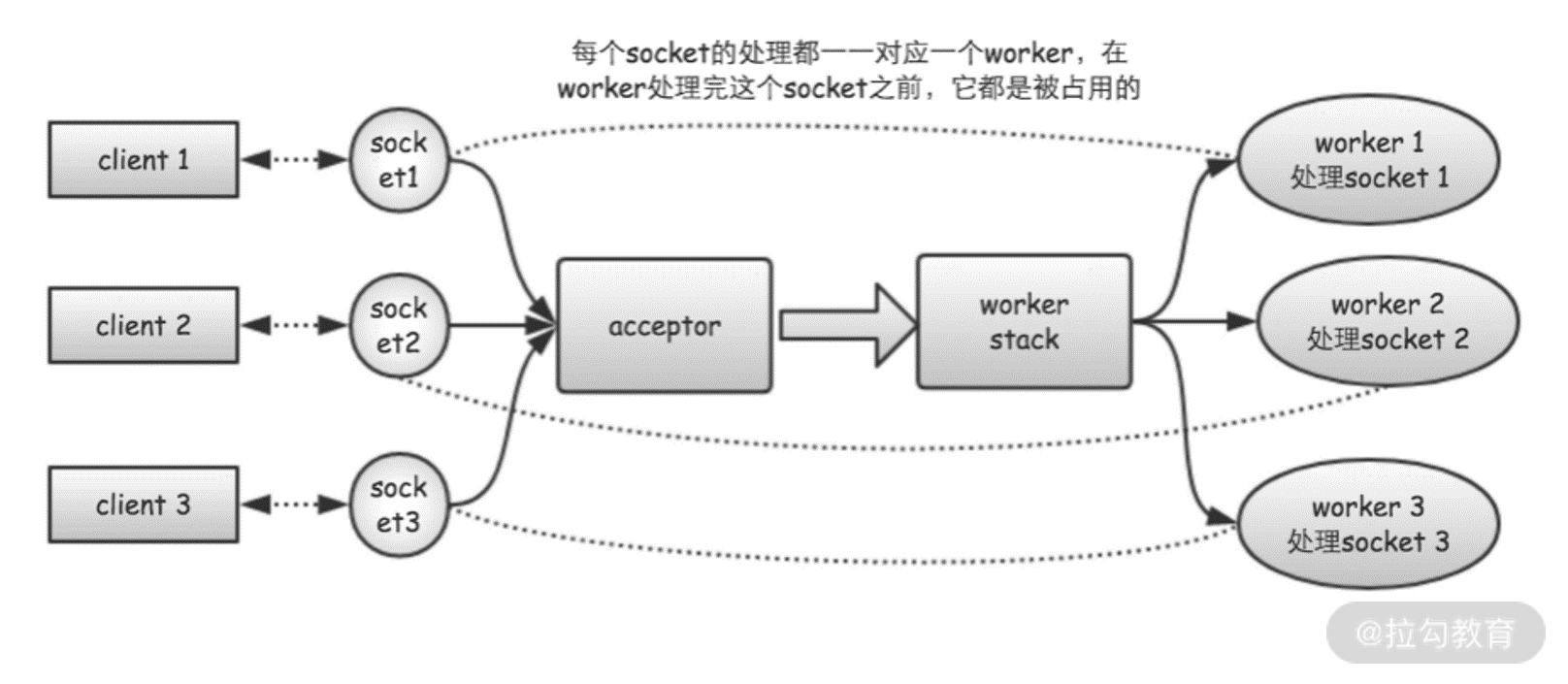
图 2 BIO连接器工作原理
当使用 BIO 连接器时,Tomcat 会为每个客户端请求,分配一个独立的工作线程进行处理。这样,如果有 100 个客户端同时发送请求,就需要同时创建 100 个工作线程。如果有 1 万个客户端同时请求,就需要创建 1 万个工作线程。而如果是 100 万个客户端同时请求呢?是不是需要创建 100 万个工作线程?
所以,BIO 连接器的最大问题是它的工作线程和请求连接是一一对应耦合起来的。当同时建立的请求连接数比较少时,使用 BIO 连接器是合适的,因为这个时候线程数是够用的。但考虑下,像 BATJ 等大厂的使用场景,哪家不是成万上亿的用户,哪家不是数十万、数百万的并发连接。在这些场景下,使用 BIO 连接器就根本行不通了。
所以,我们需要采取新的方案,这就是 Tomcat NIO 连接器。
使用 NIO 支持百万连接
毫无意外的是,从 Tomcat 8 开始,Tomcat 已经将 NIO 设置成了它的默认连接器。所以,如果你此时还在使用 Tomcat 7 或之前的版本的话,需要检查下你的服务器,究竟使用的是哪种连接器。
图 3 NIO连接器工作原理
图 3 是 NIO 连接器的工作原理。可以看出,NIO 连接器相比 BIO 连接器,主要做出了两大改进。
一是,使用“队列”将请求接收器和工作线程隔开;
二是,引入选择器来更加精细地管理连接套接字。
NIO 连接器的这两点改进,带来了两个非常大的好处。
一方面,将请求接收器和工作线程隔离开,可以让接收器和工作线程,各自尽其所能地工作,从而更加充分地使用 IO 和 CPU 资源。
另一方面,NIO 连接器能够保持的并发连接数,不再受限于工作线程数量,这样无须分配大量线程,数据接收服务器就能支持大量并发连接了。
所以,使用 NIO 连接器,我们解决了百万并发连接的问题。但想要实现一个高性能的数据采集服务器,光使用 NIO 连接器还不够。因为当系统支持百万并发连接时,也就意味着我们的系统是一个吞吐量非常高的系统。这就要求我们在实现业务逻辑时,需要更加精细地使用 CPU 和 IO 资源。否则,千辛万苦改成 NIO 的努力,就都白白浪费了。
如何优化 IO 和 CPU 都密集的任务
考虑实际的应用场景,当数据采集服务器在接收到数据后,往往还需要做三件事情:
一是,对数据进行解码;
二是,对数据进行规整化,包括字段提取、类型统一、过滤无效数据等;
三是,将规整化的数据发送到下游,比如消息中间件 Kafka。
在这三个步骤中,1 和 2 主要是纯粹的 CPU 计算,占用的是 CPU 资源,而 3 则是 IO 输出,占用的是 IO 资源。每接收到一条数据,我们都会执行以上三个步骤,所以也就构成了类似于图 4 所示的这种循环。
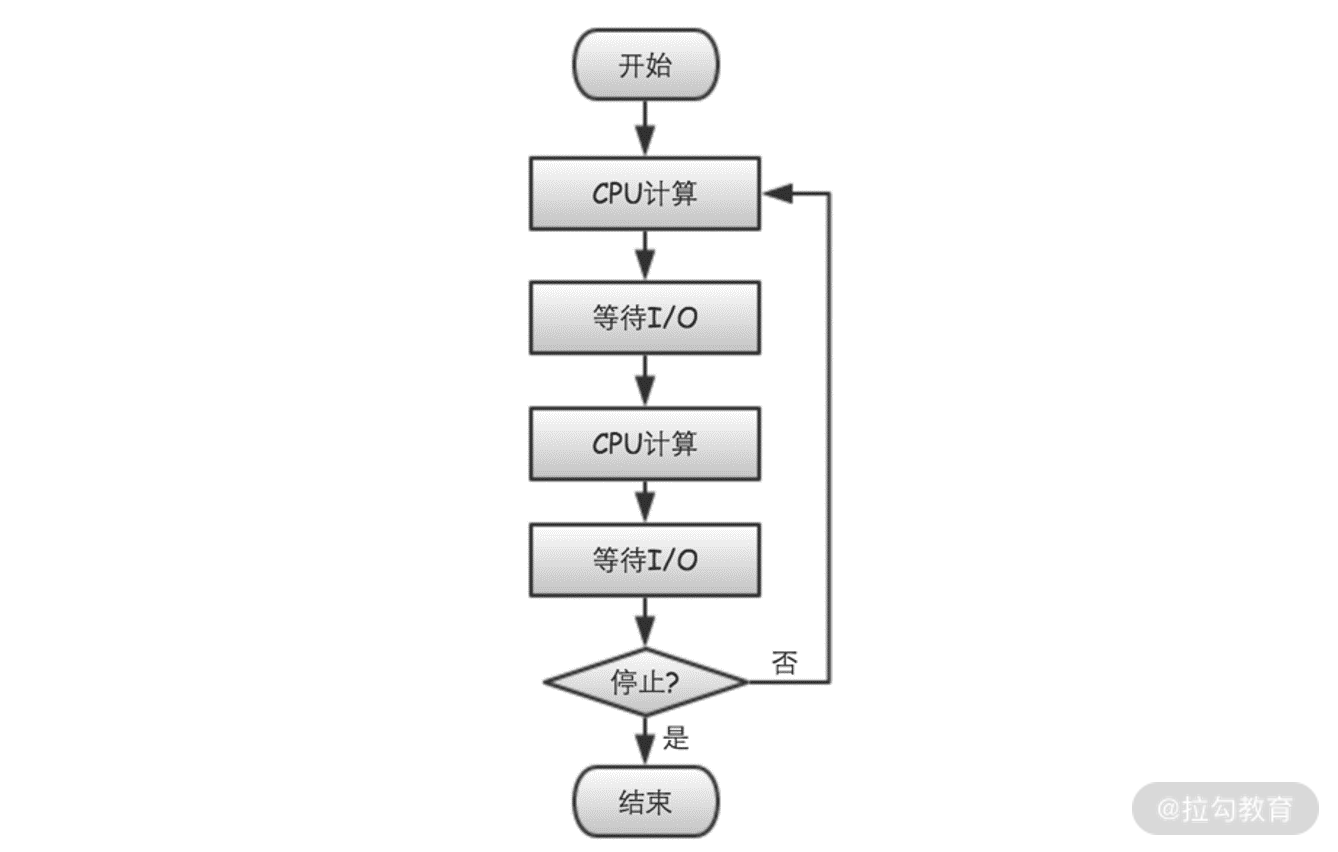
图 4 CPU和IO都密集型任务
从图 4 可以看出,数据采集服务器是一个对 CPU 和 IO 资源的使用都比较密集的场景。为什么我们会强调这种CPU 和 IO 的使用都比较密集的情况呢?因为这是破解“NIO 和异步”为什么比“BIO 和同步”程序,性能更优的关键所在!下面我们就来详细分析下。
如果想提高 IO 利用率,一种简单且行之有效的方式,是使用更多的线程。这是因为当线程执行到涉及 IO 操作或 sleep 之类的函数时,会触发系统调用。线程执行系统调用,会从用户态进入内核态,之后在其准备从内核态返回用户态时,操作系统将触发一次线程调度的机会。对于正在执行 IO 操作的线程,操作系统很有可能将其调度出去。这是因为触发 IO 请求的线程,通常需要等待 IO 操作完成,操作系统就会暂时让其在一旁等着,先调度其他线程执行。当 IO 请求的数据准备好之后,线程才再次获得被调度的机会,然后继续之前的执行流程。
但是,是不是能够一直将线程的数量增加下去呢?不是的!如果线程过多,操作系统就会频繁地进行线程调度和上下文切换,这样 CPU 会浪费很多的时间在线程调度和上下文切换上,使得用于有效计算的时间变少,从而造成另一种形式的 CPU 资源浪费。
所以,针对 IO 和 CPU 都密集的任务,其优化思路是,尽可能让 CPU 不把时间浪费在等待 IO 完成上,同时尽可能降低操作系统消耗在线程调度上的时间。
那具体如何做到这两点呢?这就是接下来要讲的,“NIO”结合“异步”方法了。
NIO 结合异步编程
既然要说异步,那什么是异步?举个生活中的例子。当我们做饭时,在把米和水放到电饭锅,并按下电源开关后,不会干巴巴站在一旁等米饭煮熟,而是会利用这段时间去炒菜。当电饭锅的米饭煮熟之后,它会发出嘟嘟的声音,通知我们米饭已经煮好。同时,这个时候我们的菜肴,也差不多做好了。
在这个例子中,我们没有等待电饭锅煮饭,而是让其在饭熟后提醒我们,这种做事方式就是“异步”的。反过来,如果我们一直等到米饭煮熟之后再做菜,这就是“同步”的做事方式。
对应到程序中,我们的角色就相当于 CPU ,电饭锅煮饭的过程,就相当于一次耗时的 IO 操作,而炒菜的过程,就相当于在执行一段算法。很显然,异步的方式能更加有效地使用 CPU 资源。
那在 Java 中,应该怎样完美地将 NIO 和异步编程结合起来呢?这里我采用了 Netty 框架,和 CompletableFuture 异步编程工具类。具体可以看看这段代码(完整代码):
Executor decoderExecutor = ExecutorHelper.createExecutor(2, "decoder");
Executor ectExecutor = ExecutorHelper.createExecutor(8, "ect");
Executor senderExecutor = ExecutorHelper.createExecutor(2, "sender");
@Override
protected void channelRead0(ChannelHandlerContext ctx, HttpRequest req) throws Exception {
CompletableFuture
.supplyAsync(() -> this.decode(ctx, req), this.decoderExecutor)
.thenApplyAsync(e -> this.doExtractCleanTransform(ctx, req, e), this.ectExecutor)
.thenApplyAsync(e -> this.send(ctx, req, e), this.senderExecutor);
}
在上面的代码中,由于 Netty 框架本身已经处理好 NIO 的问题,所以我们的工作重点放在实现“异步”处理上。Netty 框架里的 channelRead0 函数,是实现业务逻辑的地方,于是我在这个函数中,将请求处理逻辑细分为,解码(decode)、规整化(doExtractCleanTransform)、发送(send)三个步骤,然后使用 CompletableFuture 类的方法,将这三个步骤串联起来,构成了最终的异步调用链。
至此,我们终于将数据采集服务的整个请求处理过程,都彻彻底底地异步化。所有 CPU 密集型任务和 IO 密集性任务都被隔离开,在各自分配的线程里独立运行,彼此互不影响。这样, CPU 和 IO 资源,都能够得到充分利用,程序的性能也能够彻底释放出来。

监控数据来源
端上访问
我们一般可以通过以下几个方式获取端上访问的数据:
用户体验监控:Web 页面中的白屏时间、DOM 元素/资源加载耗时、文档网络耗时;App 的卡顿率、崩溃率、热启动加载时长等。
日志:在 Web 页面中,如果出现脚本错误,则需要将相应的异常信息通过日志的方式上报服务器;App 也会有相应的日志输出,但移动端更关注系统崩溃或出现异常时的日志信息。
端到端:指的是用户端(Web/App)到后端服务器的请求情况,比如访问量、成功率、响应时间等。通过端到端观测时,我们还需要了解端上所处的地区、网络环境、响应状态码等信息,才能更好地掌握用户真实的使用情况。
可用率:因运营商和地区的不同,会导致访问端上时有一些差异,比如访问是否可用、响应耗时长短等。这与 CDN、DNS 等公共资源有莫大的关系。
应用程序
当端上发起请求后,一般会到达应用程序。这里是代码运行,以及处理用户请求的地方。在应用程序中,我们可能会集成各种第三方组件,比如常见的 Kafka、Redis、MySQL。应用程序的执行效率最终会通过端上响应情况反映出来,直接影响到用户的使用体验。
如果我们想要提升程序的响应速度,就不得不关注以下几个指标:
执行情况:我们常说的响应时间、QPS 等,都可以反映应用程序的执行情况。针对端上的请求,或者我们的定时任务,应用程序的执行情况就十分关键。执行情况越差,用户的直观体验也会越差。在组件级别,像 MySQL 中的慢查询监控,Kafka 中的 Lag 监控等,也可以反映应用程序的执行情况。
资源消耗:应用程序部署后,会消耗一定的资源,例如内存级别的 Redis 会消耗大量的内存,Kakfa 则因为要进行磁盘写入所以会要求较好的 I/O。我们的应用程序会区分 I/O 密集型和 CPU 密集型,它们所对应的资源消耗是不同的。
VM 指标监控:指的是 JVM 监控,比如 GC 时间、线程数、FGC/YGC 耗时等信息。当然,其他语言也有其独特的统计指标信息。
容量:指单个系统可最大承受的容量。容量也是一个非常重要的指标,当应用访问量到达阈值时,我们一般会对这个应用的访问容量进行扩缩容。
服务关系:随着分布式系统架构的流行,我们在监控单体应用的基础上,还必须考虑应用之间的调用关系和调用速度,比如是否会存在两个服务之间的相互循环引用,下游服务出现问题是否会干扰整个流程的执行,又或是服务之间的响应时长、上下游服务的依赖程度等。
应用日志:应用日志应该是我们再熟悉不过的内容了。我们开发的应用程序,会记录下自身的日志,第三方组件也会有相应的日志,比如 MySQL 的进程日志、慢查询日志等。充分利用应用日志,可以大幅提高我们的排错能力。
健康情况:当前服务是否存活、服务运行是否稳定等,这也是十分关键的指标。我们在 ES 中可以看到服务的状态(RED、YELLOW、GREEN)。
业务监控
业务监控也是可观测系统中一个重要的内容,如果你只是让应用程序稳定运行那肯定是远远不够的。因此,我们常常会对具体业务产生的数据进行监控,例如网站系统中我们会关注 PV、UV 等参数;在支付系统中,我们则会关注创建订单量、成单量等。
业务指标能很好地体现出系统是否稳定。任何系统,如果出现了问题,最先受到影响的肯定是业务指标。当然,如果影响不是特别大,那就说明对这个指标进行监控的意义也不是很大。
业务指标也可以衡量上线后的成效。如果我们需要通过 A/B Test 了解用户更偏好哪一种模式,可以分别观察两种模式下的业务指标来比对用户喜好。再或者,我们可以通过业务指标得出的结论,在上线前进行一些改进(例如选择用户更偏好的模式)来提高成单率。
核心业务指标的设定因具体的业务和场景而异,因此开发人员也需要对业务和代码有一定的了解。
基础设施
基础监控我想你也不陌生。我们的应用程序/组件一般都是运行在云主机、操作系统上的,如果基础设施出现了严重问题,会影响到云主机和操作系统,进而牵连应用程序/组件的正常运行。
为了避免这种情况,我们会对基础设施进行监控,以保证它们可以良好地运行着。
我们一般会从 2 个方向监控:
资源利用:这个很好理解,像 I/O 使用率、CPU 利用率、内存使用率、磁盘使用率、网络使用率、负载等都属于资源利用的范畴。
通信情况:这里是指主机与主机之间的网络情况。通信是互联网中最重要的基石之一,如果两台主机之间出现如网络延迟时间大、丢包率高这样的网络问题,会导致业务受阻。
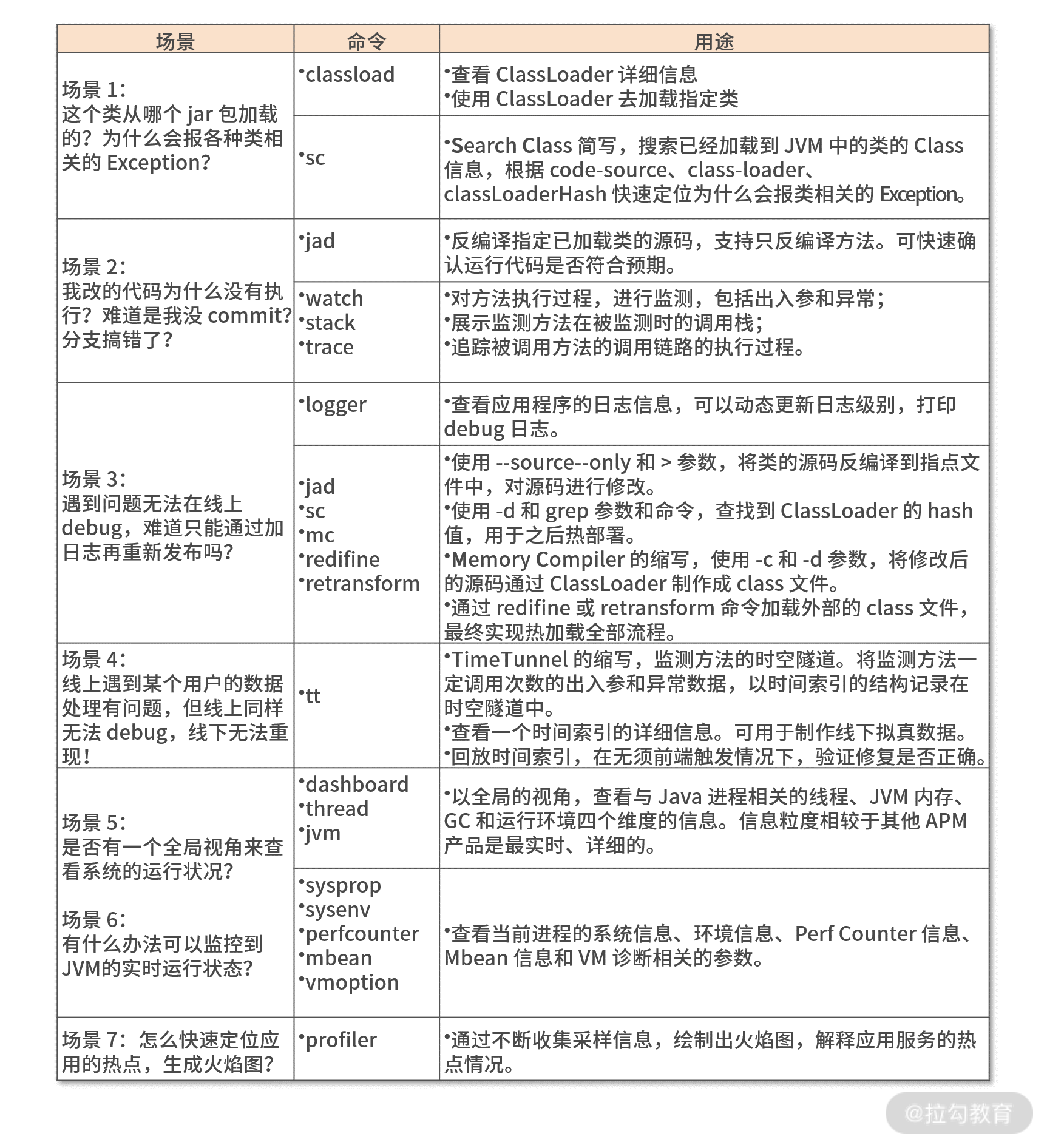
Arthas 的核心应用场景如下。
场景 1:这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
场景 2:我改的代码为什么没有执行?难道是我没 commit?分支搞错了?
场景 3:遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
场景 4:线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
场景 5:是否有一个全局视角来查看系统的运行状况?
场景 6:有什么办法可以监控到 JVM 的实时运行状态?
场景 7:怎么快速定位应用的热点,生成火焰图?



![LeetCode 刷题 [C++] 第55题.跳跃游戏](https://img-blog.csdnimg.cn/direct/f9de59740cf34fdaa21bfd0d1de589b3.png)