🎈个人主页:豌豆射手^
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
【机器学习】包裹式特征选择之递归特征消除法
- 一 初步了解
- 1.1 概念
- 1.2 类比
- 二 具体步骤
- 2.1 选择模型
- 2.2 初始化:
- 2.3 模型训练:
- 2.4 特征重要性评估:
- 2.5 特征排序:
- 2.6 剔除特征:
- 2.7 更新特征集:
- 2.8 停止条件检查:
- 2.9 重复步骤:
- 三 优缺点以及适用场景
- 3.1 优点:
- 3.2 缺点:
- 3.3 适用场景:
- 四 代码示例及分析
- 总结
引言:
在机器学习中,特征选择是提高模型性能和泛化能力的关键步骤之一。
而包裹式特征选择方法中的递归特征消除法 (Recursive Feature Elimination,简称RFE)是一种有效的特征选择技术。
通过递归地剔除对模型性能贡献较小的特征,RFE能够选择出最佳的特征子集,从而提高模型的预测性能。
本文将介绍递归特征消除法的概念、具体步骤、优缺点以及适用场景,并提供代码示例进行详细分析。

一 初步了解
1.1 概念
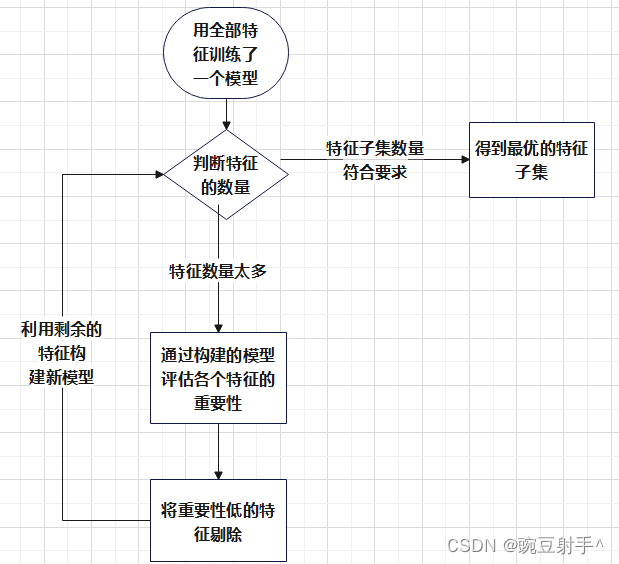
递归特征消除(RFE)是包裹式特征选择法中的一种方法,它通过反复构建模型并剔除最不重要的特征来选择最优特征子集。
首先,使用全部特征训练一个模型,然后根据特征的重要性评估移除最不重要的特征。
特征训练模型是指利用选定的特征集合来训练一个机器学习模型,以便对数据进行预测或分类,也就是用数据来训练了一个模型。
在特征选择的上下文中,特征集是经过筛选或选择的子集,通常包含数据集中最重要或最相关的特征。
这个过程迭代进行,每次更新特征集,直到达到预定的特征数量或其他停止条件。
递归地剔除特征的过程确保了最终选择的特征子集对于模型性能至关重要,有助于提高预测性能并减少特征的维度,增强模型的泛化能力。
流程图大概如下:
1.2 类比
假设你是一位园艺师,正在设计一座美丽的花园。
花园里的每一种植物都代表数据集中的一个特征。

现在,你的目标是选择一组最适合花园美感的植物组合,以确保花园在四季都充满色彩。
在这个情境中,递归特征消除(RFE)就像是你在挑选植物时的一种策略。
开始时,你选择了各种各样的植物,代表数据集中的所有特征。
然后,你根据每种植物对花园整体美感的贡献,决定是否保留或剔除某些植物。
也许有些植物的颜色并不和谐,或者有些植物在某个季节并不怎么引人注目。
于是,你将影响美感的的植物剔除了,然后用剩下的植物重新构建新的花园。(用剩下的特征构建新的模型)
再根据新的的花园中,剩下的每种植物对花园整体美感的贡献,又再次决定是否保留或剔除某些植物。
重复这个过程,你逐步剔除了这些对花园美感影响较小的植物,直到达到你心目中的理想花园,或者直到不能再提升花园的整体美感为止。
这个过程类似于递归特征消除的工作原理:
通过不断尝试和调整,逐步剔除对整体美感贡献较小的植物(特征),最终得到一个最优的植物组合,使得花园在四季都呈现出最美的景色。
这样,你就能更好地掌握花园设计的要诀,提高了花园整体美感的效果。
在这个类比中,重点强调了递归特征消除的迭代过程,其中每一轮剔除不重要的植物都伴随着重新构建花园的步骤。

二 具体步骤
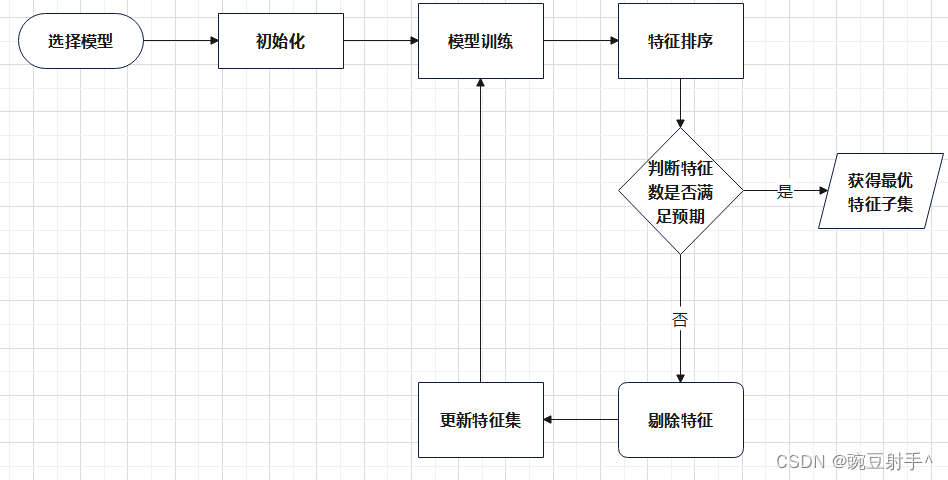
步骤流程图如下:
接下来,我将详细介绍每一个步骤的具体实现。
2.1 选择模型
首先,选择一个适合于特定任务的预测模型,例如线性回归、逻辑回归、支持向量机等。
这个模型将用于评估特征的重要性,并指导特征选择的过程。
2.2 初始化:
将所有特征包含在特征集合中,作为初始的特征子集。
2.3 模型训练:
使用选定的模型和所有特征来训练一个初始模型。
2.4 特征重要性评估:
利用已训练的模型,评估每个特征的重要性或对模型性能的贡献程度。
这可以通过不同的方法来完成,如特征权重、系数、信息增益等。
2.5 特征排序:
根据特征的重要性进行排序,确定哪些特征对模型的性能影响最大,哪些对模型性能影响较小。
2.6 剔除特征:
移除排序后的特征列表中最不重要的特征。可以根据实际需要选择一次剔除一个或多个特征。
剔除的特征通常是那些被认为对模型性能贡献较小的特征。
2.7 更新特征集:
在剔除特征后,更新特征集,形成一个新的特征子集。
2.8 停止条件检查:
检查是否满足停止条件,例如特征数量已达到预定值、模型性能已达到某个阈值等。
如果满足停止条件,则停止迭代;否则,回到第3步,继续进行下一轮迭代。
2.9 重复步骤:
重复步骤3到步骤8,直到满足停止条件为止。
每一轮迭代都会剔除对模型性能影响较小的特征,直到找到一个最优的特征子集。

三 优缺点以及适用场景
3.1 优点:
1 考虑特征间的相互关系:
RFE在剔除特征时会考虑到特征间的相互影响,从而更加准确地选择特征子集。
2 降低过拟合风险:
通过减少特征数量,RFE可以降低模型的复杂度,减少过拟合的风险。
3 提高模型性能:
通过选择最优的特征子集,RFE可以提高模型的性能和泛化能力。
4 无需事先假设特征分布:
RFE不需要对特征分布做出假设,适用于各种类型的数据。
3.2 缺点:
1 计算成本高:
对于特征数量较多的数据集,RFE需要反复训练模型,计算成本较高。
2 依赖模型选择:
RFE的性能取决于所选择的基础模型,选择不合适的模型可能导致特征选择效果不佳。
3 可能丢失信息:
在剔除特征的过程中,有可能剔除了一些对模型有潜在贡献的特征,导致丢失信息。
3.3 适用场景:
1 特征数量较多:
当数据集特征数量较多时,RFE可以帮助筛选出最重要的特征,减少特征的维度。
2 模型复杂度高:
当模型复杂度较高,存在过拟合风险时,RFE可以帮助减少特征数量,降低模型复杂度。
3 需要提高模型性能:
当模型性能需要提高时,RFE可以帮助选择最优的特征子集,提高模型的性能和泛化能力。
总的来说,递归特征消除法在特征选择方面具有一定的优势,尤其适用于特征数量较多、模型复杂度较高或需要提高模型性能的情况下。
然而,使用RFE时需要注意计算成本和模型选择的问题。

四 代码示例及分析
我们可以通过Python中的scikit-learn模块实现递归特征消除,在这个模块中,实现递归特征消除法的具体方法是使用RFE(Recursive Feature Elimination)类。
通过该类,可以将基础模型(如SVM分类器)和要选择的特征数量作为参数,然后利用递归的方式不断剔除特征,最终得到最佳的特征子集。
下面是具体步骤:
1 导入库 (Import Libraries):
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.svm import SVC
这些代码导入了三个scikit-learn库中的模块:make_classification 用于生成分类数据集,RFE用于递归特征消除,SVC 是支持向量机的实现。
2 生成一个示例数据集 (Generate Example Dataset):
X, y = make_classification(n_samples=100, n_features=10, random_state=42)
使用 make_classification 函数生成一个包含 100 个样本和 10 个特征的分类数据集,并将特征矩阵赋值给 X,目标变量赋值给 y。
3 创建一个SVM分类器作为基础模型 (Create SVM Classifier as Base Model):
svc = SVC(kernel="linear")
创建一个基于线性核函数的支持向量机(SVM)分类器,将其实例化并赋值给变量 svc。
4 使用RFE进行特征选择,选择5个最重要的特征 (Use RFE for Feature Selection, Select 5 Most Important Features):
rfe = RFE(estimator=svc, n_features_to_select=5, step=1)
创建一个 RFE 对象,指定基础模型为 svc,要选择的特征数量为 5,步长为 1。
5 对数据进行特征选择 (Perform Feature Selection on Data):
rfe.fit(X, y)
调用 RFE 对象的 fit 方法,使用数据 X 和目标变量 y 进行特征选择。
6 输出所选特征的排名 (Print Feature Rankings):
print("Feature Ranking:", rfe.ranking_)
打印输出所选特征的排名,即每个特征在RFE过程中的重要性排序,排名越低表示特征越重要。
7 输出所选特征 (Print Selected Features):
selected_features = [f"Feature {i+1}" for i in range(len(rfe.ranking_)) if rfe.support_[i]]
print("Selected Features:", selected_features)
使用列表推导式和条件判断,确定被选中的特征,并打印输出它们的名称。 rfe.support_ 返回一个布尔类型的数组,指示哪些特征被选中。
运行结果如下:
Feature Ranking: [1 1 1 1 1 6 5 4 3 2]
Selected Features: ['Feature 1', 'Feature 2', 'Feature 3', 'Feature 4', 'Feature 5']
这表示在特征选择过程中,前五个特征被选为最重要的特征,它们的排名为 1,而其余特征的排名分别为 2 到 6。
被选中的特征分别是 ‘Feature 1’, ‘Feature 2’, ‘Feature 3’, ‘Feature 4’, 和
‘Feature 5’。
完整代码 :
# 导入库
from sklearn.datasets import make_classification
from sklearn.feature_selection import RFE
from sklearn.svm import SVC
# 生成一个示例数据集
X, y = make_classification(n_samples=100, n_features=10, random_state=42)
# 创建一个SVM分类器作为基础模型
svc = SVC(kernel="linear")
# 使用RFE进行特征选择,选择5个最重要的特征
rfe = RFE(estimator=svc, n_features_to_select=5, step=1)
# 对数据进行特征选择
rfe.fit(X, y)
# 输出所选特征的排名
print("Feature Ranking:", rfe.ranking_)
# 输出所选特征
selected_features = [f"Feature {i+1}" for i in range(len(rfe.ranking_)) if rfe.support_[i]]
print("Selected Features:", selected_features)

总结
递归特征消除法(RFE)作为一种包裹式特征选择方法,在特征选择中具有一定的优势。
通过递归地剔除对模型性能贡献较小的特征,RFE能够选择出最佳的特征子集,从而提高模型的预测性能。
然而,RFE也存在一些缺点,例如计算开销较大、对于大规模数据集可能不太适用等。
因此,在使用RFE时需要根据具体情况权衡其优缺点,并结合实际场景做出合适的选择。
这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是豌豆射手^,让我们我们下次再见