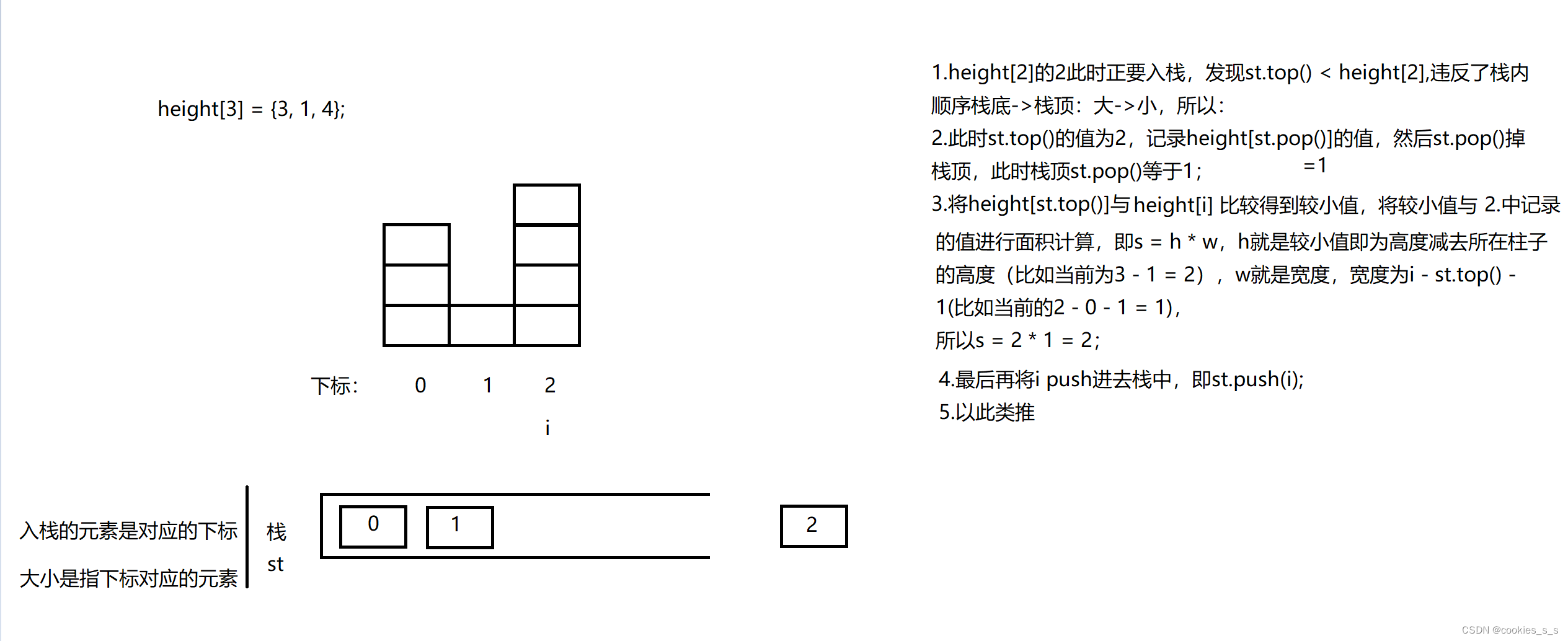
1.检索爬取内容案例。

2.找到最近更新的。(最新一般都可以直接运行)
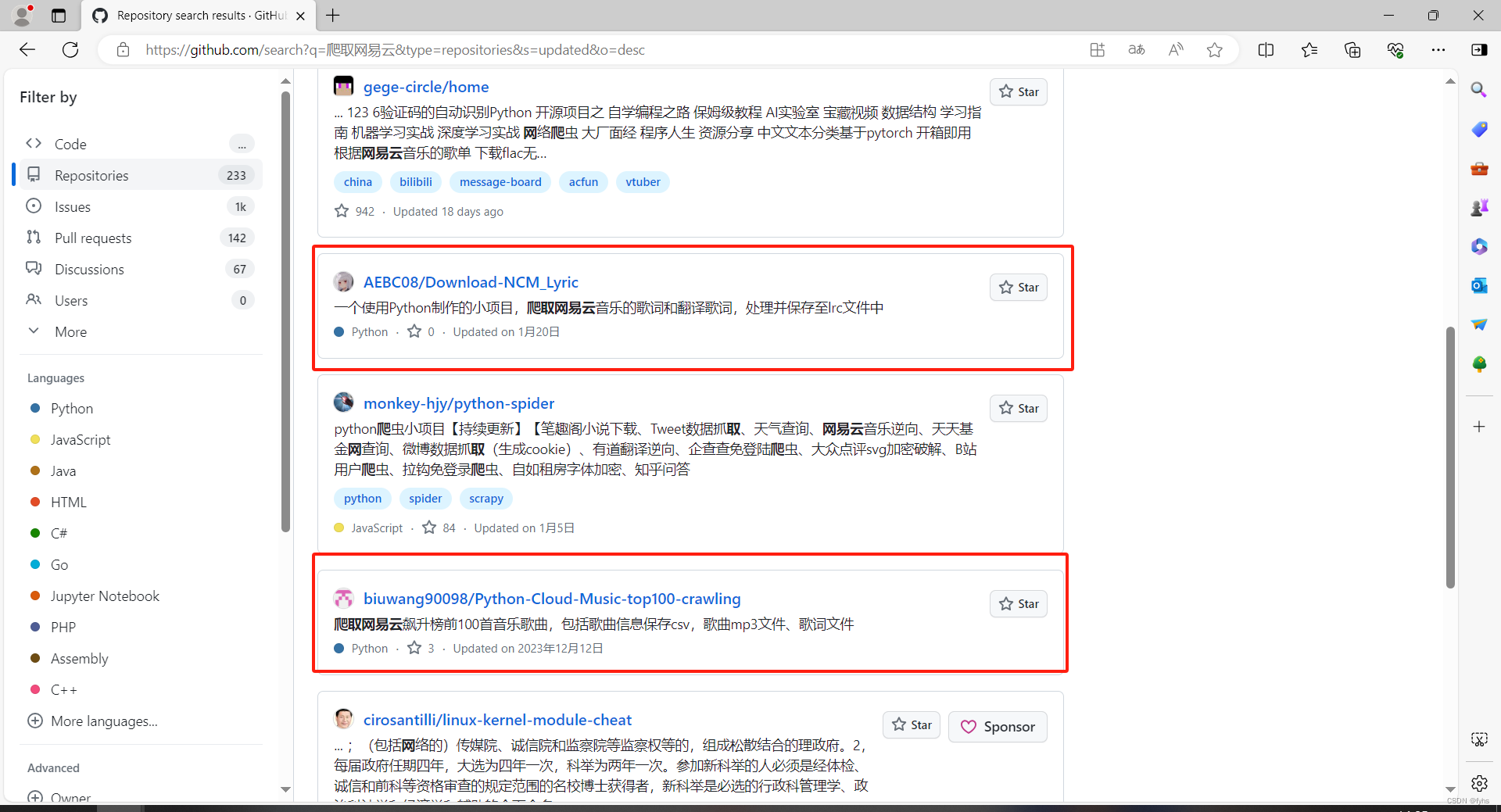
 3.选择适合自己的项目,目前测试下面画红圈的是可行的。
3.选择适合自己的项目,目前测试下面画红圈的是可行的。
4.方便大家查看就把代码粘贴出来了。
#图中画圈一代码
import requests
import os
import re
while True:
music_id = input("请输入歌曲id或歌曲链接: ")
if music_id.startswith("http"):
music_id = re.search(r"id=(\d+)", music_id).group(1)
get_lyric = requests.get(url="https://music.163.com/api/song/lyric", params={"id": music_id, "lv": 1, "kv": 1, "tv": -1}).json()
print(get_lyric)
if get_lyric.get("lrc").get("lyric") == "":
print("该歌曲没有歌词")
else:
if not os.path.exists("./OutLyric"):
os.makedirs("./OutLyric")
with open(f"./OutLyric/{music_id}.lrc", "w", encoding="utf-8") as save_lyric:
if get_lyric.get("tlyric").get("lyric") == "":
save_lyric.write(get_lyric.get("lrc").get("lyric"))
else:
zh_cn_lyric = re.sub(r'\[[^0-9]*:[^0-9.]*]\n', '', get_lyric.get("tlyric").get("lyric"))
save_lyric.write(f'{get_lyric.get("lrc").get("lyric")}\n{zh_cn_lyric}')
print(f"下载成功,可将该文件重命名至与歌曲相同的名字使用,lrc文件保存至./OutLyric/{music_id}.lrc")#图中画圈2代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests as rq
from requests import exceptions
from bs4 import BeautifulSoup as BS
import os
import re
import csv
SONG_NUM = 0
def getMusic(ID, path, num):
cloud = 'http://music.163.com/song/media/outer/url?id='
kv = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36'}
try:
url = cloud+ID+'.mp3'
tmp = rq.get(url, headers=kv)
tmp.raise_for_status()
print(num+"、歌曲正在下载...")
with open(path, 'wb') as f:
f.write(tmp.content)
f.close()
print(num+"、歌曲下载成功!")
except exceptions.HTTPError as e:
print(e)
except Exception as e:
print(e)
def getMusicText(ID, path, num):
muTextUrl = 'http://music.163.com/api/song/lyric?id=' + ID + '&lv=1&kv=1&tv=-1'
headers = {
'Referer': 'https://music.163.com',
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
try:
res = rq.get(muTextUrl, headers=headers)
res.raise_for_status()
false = False # 解决eval报错 name 'false' is not defined
true = True
null = None
lrc_dict = eval(res.text) # 转换为dict字典
lrc_dict = lrc_dict['lrc']
music_lyric = lrc_dict['lyric']
print(num+"、歌词正在下载...")
with open(path, 'w', encoding="utf-8") as f:
f.write(music_lyric)
f.close()
print(num+"、歌词下载成功!")
except exceptions.HTTPError as e:
print(e)
except Exception as e:
print(e)
def create_csv_head():
headers = ['song_num', 'song_name', 'singer', 'song_duration']
with open("./music/musicMsg.csv", "a", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=headers)
head = {'song_num': '榜单序号', 'song_name': '歌曲名称',
'singer': '歌手', 'song_duration': '歌曲时长'}
writer.writerow(head)
def save_musicMsg(music_dict):
headers = ['song_num', 'song_name', 'singer', 'song_duration']
with open("./music/musicMsg.csv", "a", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=headers)
writer.writerow(music_dict)
def split_Msg(msg):
msg = msg.split('"')
item = msg[1]
return item
def getMusicMsg(ID):
global SONG_NUM
song_url = 'https://music.163.com/song?id=' + ID
headers = {
'Referer': 'https://music.163.com',
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
try:
s = rq.session()
res = s.get(song_url, headers=headers)
soup = BS(res.content, 'lxml')
# 获取歌手
singer = str(soup.find('meta', {'property': 'og:music:artist'}))
singer = split_Msg(singer)
# 获取歌曲名
song_name = str(soup.find('meta', {'property': 'og:title'}))
song_name = split_Msg(song_name)
# 获取歌曲时长
song_duration = str(soup.find('meta', {'property': 'music:duration'}))
song_duration = split_Msg(song_duration)
m, s = divmod(int(song_duration), 60)
song_duration = ("%02d:%02d" % (m, s))
music_dict = {
'song_num': SONG_NUM,
'song_name': song_name,
'singer': singer,
'song_duration': song_duration
}
save_musicMsg(music_dict)
# 歌曲名中/\\替换为空
if '/' in song_name or '\\' in song_name or ':' in song_name:
song_name = song_name.replace('/', '')
song_name = song_name.replace('\\', '')
song_name = song_name.replace(':', '')
# 歌手名中/\\替换为&
if '/' in singer or '\\' in singer or ':' in singer:
singer = singer.replace('/', '&')
singer = singer.replace('\\', '&')
singer = singer.replace(':', '')
dirName = singer+'-'+song_name
print(dirName)
return dirName
except exceptions.HTTPError as e:
print(e)
except Exception as e:
print(e)
def getMusicList():
headers = {
'Referer': 'https://music.163.com',
'Host': 'music.163.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}
base_url = 'https://music.163.com/discover/toplist'
s = rq.session()
url = base_url
response = s.get(url, headers=headers)
soup = BS(response.content, "lxml")
main = soup.find('ul', {'class': 'f-hide'})
ls = main.find_all('a')
songID_dic = {} # key song_name ,value songID
print('一共有'+str(len(ls))+'首歌')
a = 1
for music in ls:
name = music.text
ID = str(music['href'].replace('/song?id=', ''))
name = name+'_'+str(a)
a += 1
songID_dic[name] = ID
print("Name:{:30}\tID{:^10}".format(name, ID))
print('一共有'+str(len(songID_dic))+'')
return songID_dic
def main():
global SONG_NUM
songID_dic = getMusicList()
rootDir = 'music'
if os.path.exists(rootDir):
print(rootDir+"文件夹已存在")
else:
os.mkdir(rootDir)
print("创建文件夹"+rootDir)
create_csv_head()
for item in songID_dic:
item_clear = item.split('_')[0]
SONG_NUM += 1
dirName = getMusicMsg(songID_dic[item])
if dirName[-2:-1] == '.':
dirName = dirName.replace('.', '·')
musicDir = './'+rootDir+'/' + dirName
if os.path.exists(musicDir):
print(musicDir+"文件夹已存在")
else:
os.mkdir(musicDir)
print("创建文件夹"+musicDir)
if len(item_clear) > 75:
item_clear = item_clear[:70]+'···'
elif '.' in item_clear:
item_clear = item_clear.replace('.', '·')
print(item_clear, end=" \n")
mp3_path = musicDir+'/'+item_clear+'.mp3'
m4a_path = musicDir+'/'+item_clear+'.m4a'
lyric_path = musicDir+'/'+item_clear+'.txt'
num = str(SONG_NUM)
print('='*50)
getMusic(songID_dic[item], mp3_path, num)
getMusic(songID_dic[item], m4a_path, num)
print('*'*50)
getMusicText(songID_dic[item], lyric_path, num)
print('='*50)
if __name__ == '__main__':
main()
# getMusicList()
# getMusicText("1994955842", "path")
# getMusicMsg("1998931166")