文章目录
- 前端复习
- SQL
- 数据库的分类
- 关系型数据库
- 非关系型数据库(NoSQL)
- 数据库的构成
- 软件架构
- MySQL内部数据组织方式
- SQL语言
- 登录数据库
- 数据库操作
- 查看库
- 创建库
- 删除库
- 修改库
- 数据库中表的操作
- 选择数据库
- 创建表
- 删除表
- 查看表
- 修改表
- 数据库中数据的操作
- 添加数据
- 查询数据
- 修改数据
- 删除数据
- 特殊关键字
- where(条件关键字)
- distinct(过滤关键字)
- limit(限制结果集关键字)
- as(取别名关键字)
- order by(排序关键字)
- group by(分组关键字)
- 聚合函数
- SQL语句的执行顺序
前端复习
- HTML
- 以标签为基础
- 主要负责页面上内容的搭建
- css
- 控制页面的样式,字体的大小,图片等等
- 主要控制样式,页面的布局
- 大
div套小div
- js
- 页面上动态内容的功能,比如点击按钮之后、完成验证码的校验等等
- html解析之后,在浏览器上以dom树的形式存在,即对dom树的增删改查
- vue
- 帮我们操作dom,我们只用操作数据,数据会自己写在页面上
- 插值表达式、v-bind/v-model/v-on/v-for
SQL
数据库的分类
关系型数据库
- 不仅可以存储数据,还可以存储数据与数据之间的关系。
常见的关系型数据库:
- Oracle
- MySQL
- MariaDB
- SQL Server
- DB2
- PostgreSQL
非关系型数据库(NoSQL)
- 对关系型数据库的补充,主要是用来做一些关系型数据库不擅长的事情。
- 关系型数据库的数据,一般是存储在磁盘上,所以速度比较慢。非关系型数据库一般是存在内存中的,所以性能比较好。
常见的非关系型数据库:
- Redis
- 最常用的非关系型数据库,数据存在内存,速度快,吞吐量高。
- Memcached
- Mongodb
- Hbase
关系型数据库和非关系型数据库的区别:
- 最本质的区别是::关系型数据库以
数据和数据之间存在的关系维护数据, 而非关系型数据库是指存储数据的时候数据和数据之间没有什么特定关系. - 在大多数时候,非关系型数据库是在传统关系型数据库基础上(其实已经基本上完全不同), 在功能上简化, 在数据存储结构上大大改变,在效率上提升, 通过减少用不到或很少用的功能,在能力弱化的同时也带来产品性能的大幅度提高。
- 但是本质上讲, 他们都是用来存储数据的. 而对于我们Java后端开发来讲, 我们在工作中基本上是以关系型数据库为主, 非关系型数据库为辅的用法.
数据库的构成
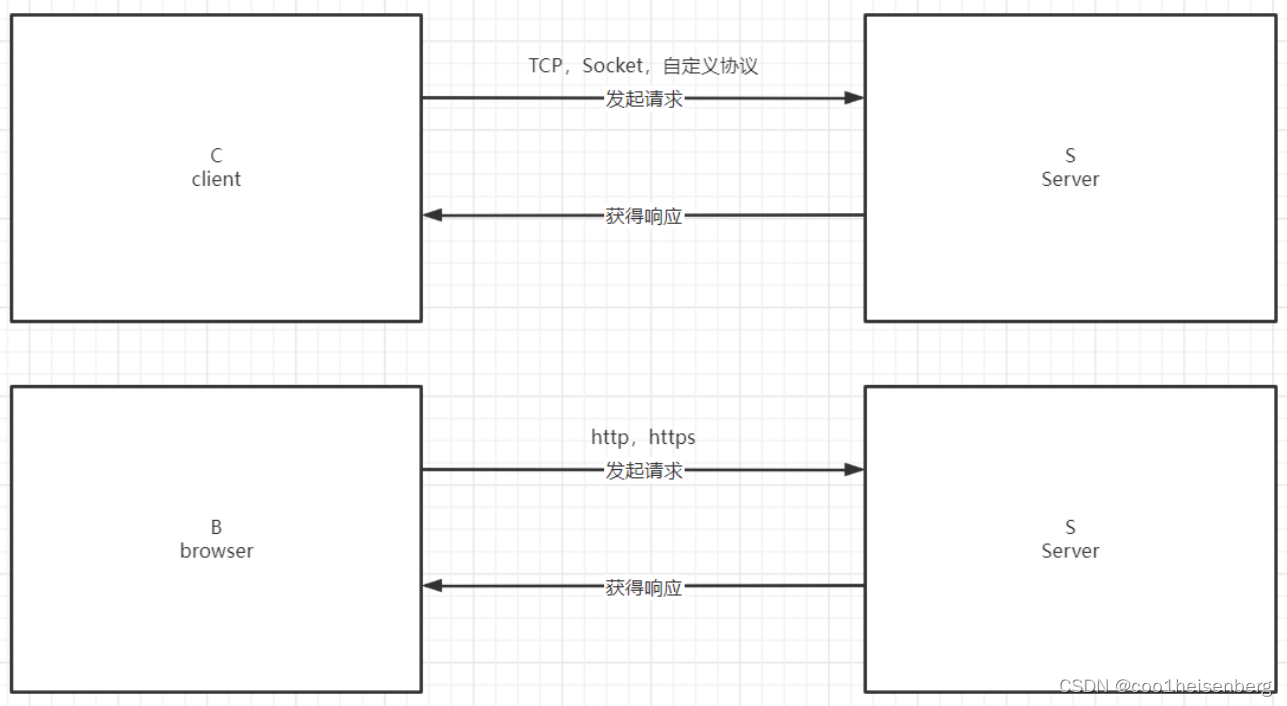
软件架构
- B/S:Browser-Server即浏览器和服务器, 即通过浏览器和服务器发起网络交互的数据请求.
- 常见的B/S架构: 淘宝、京东、拼多多、百度
- C/S:Client-Server即客户端和服务器, 即通过客户端和服务器发起网络交互的数据请求.
- 常见的C/S架构:英雄联盟、QQ、微信、数据库、手机app
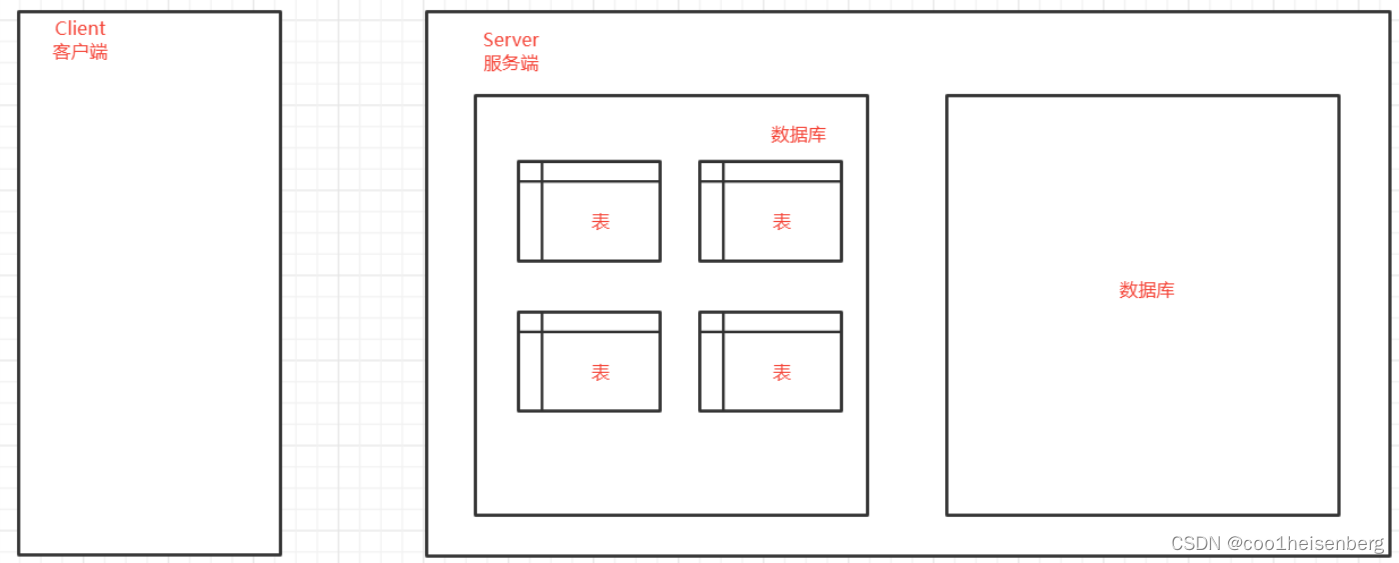
MySQL内部数据组织方式
- 数据库: 表示一份完整的数据仓库, 在这个数据仓库中分为多张不同的表。
- 表:表示某种特定类型数据的的结构化清单, 里面包含多条数据。
- 数据: 表中数据的基本单元。
SQL语言
登录数据库
$ mysql -uroot -p
输入密码(******)
数据库操作
查看库
查看所有的数据库
show databases;
模糊匹配查看相关的数据库
show databases like "system%";
-- test% 表示以test开头
-- %info 表示以info结尾
-- %info% 表示info可以出现在任意位置
查看当时创建数据库的命令
show create database test;
-- 查看当时创建数据库test的命令
注释:
1. 第一种注释
-- <注释的内容>
-- 两个‘-’后面一定要有一个空格
2. 第二种注释
#<注释的内容>
-- ‘#’后面可以不加空格
3. 第三种注释
/*
<注释的内容>
*/
注意:
- 不要删除系统自带的几个数据库
information_schemamysqlperformance_schemasys
创建库
创建一个数据库
create database db_test;
-- 注意:创建一个叫 db_test 的数据库,其中注意:库名,表名,列名均不区分大小写
-- 如果要写库名为dbTest,则可以把 dbTest 写成 db_test
创建一个数据库并指定字符集和指定校对规则
create database db_test character set utf8mb4 collate utf8mb4_bin;
-- mysql里面有一个字符集是utf8,但它是假的,是使用1-3个字节来存储数据,
-- 如果要使用utf8的编码,应该使用utf8mb4,utf8mb4是4个字节存储数据
-- 校对规则是用来比较大小的
-- _ci(case insensitive 大小写不敏感)
-- _cs(case sensitive 大小写敏感)
-- eg:utf8mb4_bin、utf8mb4_general_ci
eg:create database db_test2 character set utf8mb4 collate utf8mb4_ci;
-- 如果不指定一个字符集,则一般是默认的 latin1
-- latin1一般是不支持中文的
删除库
删除名称为db_test的数据库:
drop database db_test;
修改库
数据库中未提供改库名的操作,只提供修改字符集和校对规则。
修改指定库的字符集和校对规则:
alter database db_test character set utf8 collate utf8_bin;
数据库中表的操作
选择数据库
选择指定的数据库:
use db_test;
查看当前在什么库:
select database();
创建表
- Mysql中大小写不敏感
- 不要使用数据库来存储大文件
- 设计数据库字段的时候,一定要留有一定的冗余
create table table_name(字段名 字段类型);
-- 括号里面写有哪些列,以及列类型
eg:
create table test_time(id int, date1 date, time1 timestamp);
create table test_number(id int, float1 float(4,2));
字段类型:
-
数字(整数型)
-
tinyint:1字节。 -
int: 4字节。(直接用) -
bigint: 8字节。
-
-
数字(小数)
float(M,D):4字节。浮点型M:表示最大的长度D:表示小数位最大长度
double(M,D): 8字节。浮点型(直接用)decimal (M, D),dec: 压缩的“严格”定点数M+2 个字节。定点型。- 定点型就是用字符串来存储的
- eg:
float(4, 2):表示最多存储4位,小数位数最多2位。- 如果整数位多了,比如存了
100.23,则会报错 - 如果小数位多了,比如存了
10.233,则会四舍五入,变为10.23
- 如果整数位多了,比如存了
- 如果要存储货币,需要使用
decimal定点数来存,或者是字符串
-
日期
year:年(YYYY)。time: 时分秒(HH:MM:SS)。date: 年月日(YYYY-MM-DD)。(直接用)datetime: 年月日时分秒。(YYYY-MM-DD HH:MM:SS)。- 是用字符串存的,8个字节
timestamp: 年月日时分秒。(YYYY-MM-DD HH:MM:SS)。(直接用)- 是用时间戳存的。存的是从1970-01-01到现在的毫秒数
- 2038年这个时间戳就会用完
- 使用场景:操作/更新的时间
- 写表的时候默认会写两个:
begin_time、update_time
-
字符串
char(M): 定长字符串,设置了长度。- eg:
char(M)代表最长存储M个长度,如果没有存到M个长度,会往后面添加空格。取出来的时候,会去掉空格。
- eg:
varchar(M):变长字符串,会用1-2字节来存储长度。也就是实际长度+1(2)。最大长度65535字节。(直接用)- eg:存储
'ls',则是实际占用空间加上一个字节来存储现在的长度
- eg:存储
text:文本字符串,会用2字节来存储长度。最大长度65535字节,约64K。longtext:大文本字符串。会使用4字节存储长度。最大长度2^32,约4G。
写SQL,就是一个翻译的过程:
- 需要想好你的表名
- 需要想好要存的所有的数据
- 想好类型、字段名
- 写SQL
删除表
删除名为table_name的表:
drop table table_name;
查看表
查看所有表:
show tables;
查看表格结构(有哪些列):
desc table_name;
describe table_name;
查看表的创建语句:
show create table table_name;
修改表
不建议工作中修改表
修改表名:
rename table old_table_name to new_table_name;
alter table old_table_name rename to new_table_name;
修改表字符集 排序规则:
alter table table_name character set utf8mb4 collate utf8mb4_bin;
添加列:
alter table table_name add column column_name column_type;
删除列:
alter table table_name drop column column_name;
修改某列的类型:
alter table table_name modify column column_name column_type;
数据库中数据的操作
添加数据
插入数据
方式1:指定需要插入的列名,values需要与之对应。
insert into table_name (column1, column2, ......) values (value1, value2, ......)
方式2:不指定需要插入的列名。values,必须要写所有value,且与建表语句一一对应
insert into table_name values (value1, value2, ......)
方式3:使用set方式
insert into table_name set column1=value1, column2=value2,...;
可以插入多行:
insert into table_name values
(value1, value2, ......),(valuem,valuen,......),(valuem,valuen,......);
eg:
指定插入列:
-- 要在values后面写与之对应的值
-- 插入的类型一定要匹配
insert into student_test(id, name, age, address, remark)
values (1, "lihua", 20, "china", "None");
不指定插入的列:
-- 插入列的顺序与创建表的时候一致
insert into student_test values (2, "zhangsan", 19, "Asia", "None");
-- 插入 一条数据
insert into student_test set id=3,name="mike",age=21,address="china",remark="None";
-- 还可以一次插入多行,格式就是 在前面指定的
insert into student_test(id, name, age, address, remark) values
(4, "Jack", 20, "china", "None"), (5, "Bob", 25, "china", "None");
查询数据
查询语句:
-- 关键词 select ... from
select * from table_name;
-- * 代表选出所有列
-- 也可以写表中的列,多列使用, 分割
-- 比如 select id,name from students;
-- table_name 是表名
使用where关键词。where相当于是过滤器。
eg:
-- 找出name是 zs 的表记录
select * from table_name where name='ls';
-- 找出年龄大于 18岁的人
select * from table_name where age > 18;
修改数据
写update语句和delete语句一定要加where条件
更新满足条件的表记录,设置列值:
update table_name set column1=value1, column2=value2 [ where 条件];
eg:
update student_test set age = 18 where id = 4;
删除数据
删除满足条件的数据:
delete from table_name [WHERE 条件];
eg:
delete from student_test where id = 5;
特殊关键字
where(条件关键字)
- 使用
where关键字并指定查询条件|表达式, 从数据表中获得满足条件的数据内容 - 在
where后面写条件,其实就是筛选出符合条件的数据select就是把这些数据筛选出来展示update只更新符合条件的delete只删除符合条件的
- 使用位置:查询语句(select)、更新语句(update)、删除语句(delete)
一些重要的SQL运算符:
- 算数运算符
- 用在
select后面表示我要选择的数据怎么计算出来的 - 用在
where后面表示筛选数据
- 用在
| 运算符 | 作用 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取余 |
- 比较和逻辑运算符
| 运算符 | 作用 | 运算符 | 作用 |
|---|---|---|---|
| = | 等于 | <=> | 等于(可比较null) |
| != | 不等于 | <> | 不等于 |
| < | 小于 | > | 大于 |
| <= | 小于等于 | >= | 大于等于 |
| between and | 在闭区间内 | like | 通配符匹配(%:通配, _占位) |
| is null | 是否为null | is not null | 是否不为null |
| in | 不在列表内 | not in | 不在列表内 |
| and | 与 | && | 与 |
| or | 或 | || | 或 |
注:
=不能用来判断null_只能匹配一次
distinct(过滤关键字)
- 获取某个列的不重复值
- 语法:
select distinct <字段名> from <表名>;- 使用
distinct对数据表中一个或多个字段重复的数据进行过滤,重复的数据只返回其一条数据给用户。
- 使用
eg:
-- 返回所有的address
select address from student_test;
-- 返回不重复的 address
select distinct address from student_test;
limit(限制结果集关键字)
select <查询内容|列等> from <表名字> limit 记录数目;
select <查询内容|列等> from <表名字> limit 初始位置,记录数目;
select <查询内容|列等> from <表名字> limit 记录数目 offset 初始位置;
eg:
-- limit 限制了返回的最大数目
select * from student_test limit 2;
-- limit offset number1, number2
-- number1:表示偏移的数量(默认是从0开始的)
-- number2:表示限制的个数
-- 从第2个开始返回,限制返回2个
select * from student_test limit 2 offset 1;
select * from student_test limit 1,2;
as(取别名关键字)
as关键字用来为表和字段指定别名as可以省略
<内容> as <别名>
eg:
select address as dizhi from student_test;
order by(排序关键字)
select <查询内容|列等> from <表名字> order by <字段名> [asc|desc];
注:
order by对查询数据结果集进行排序- 不加排序模式: 升序排序(默认)
asc: 升序排序desc: 降序排序
order by也可以按照多个列排序- 如果第一列相同,就按照第二列进行排序。如果第二列相同,则按照第三列进行排序。以此类推
eg:
select * from student_test order by age desc;
select * from student_test order by age asc;
group by(分组关键字)
- 按照某个、某些字段分组
select <查询内容|列等> from <表名字> group by <字段名...>
group by后,select中只能写group by后面的列- 还可以写一些聚合函数
group_concat()函数会把每个分组的字段值都拼接显示出来having可以让我们对分组后的各组数据过滤。(一般和分组+聚合函数配合使用)round(x, d):x 指要处理的数,d 是指保留几位小数min、max、sum、avg、count
- 当
select后 既有表结构本身的字段,又有需要使用聚合函数(count()、sum()、avg()、max()、min()等)的字段,就要用到group by分组
eg:
select group_concat(name),address from student_test group by address;
-->
+--------------------+---------+
| group_concat(name) | address |
+--------------------+---------+
| zhangsan | Asia |
| lihua,mike,Jack | china |
+--------------------+---------+
select group_concat(name),age,address from student_test
group by age having address = "china";
-->
+--------------------+------+---------+
| group_concat(name) | age | address |
+--------------------+------+---------+
| lihua | 20 | china |
| mike | 21 | china |
+--------------------+------+---------+
group by的特点:
group by代表分组的意思,把值相同的分到一组select后面的列,只能写group by后面的列,或者聚合函数- 如果
group by后面有多个列,会首先按照第一个列进行分组,第一个列相同,再按照第二个列进行分组 - 如果
select后面可以看出来是哪一列聚合,group by后面可以写1 2
eg:select class, count(*) from students group by class;
可以写成select class, count(*) from students group by 1; where与having的区别:where是原始数据进行过滤having是分组之后进行过滤
聚合函数
聚合函数一般用来计算列相关的指定值. 通常和分组一起使用
| 函数 | 作用 | 函数 | 作用 |
|---|---|---|---|
| count | 计数 | sum | 和 |
| avg | 平均值 | max | 最大值 |
| min | 最小值 |
count(*)与count(column_name)的区别:
count(*):纯粹计算有多少行count(column_name):计算非null的行数
SQL语句的执行顺序
- SQL语句的关键字是有顺序的,需要按照下面的顺序来写
select column_name, ... from table_name, ...
[where ...][group by ...][having ...][order by ...][limit ...]
(5) SELECT column_name, ...:标识出来筛选的列
(1) FROM table_name, ...:打开表
(2) [WHERE ...]:过滤
(3) [GROUP BY ...]:分组
(4) [HAVING ...]:对分组后的数据进行筛选
(6) [ORDER BY ...]:对数据进行排序
(7) [Limit ...]:限制





![[pdf]《软件方法》2024版部分公开-共196页](https://img-blog.csdnimg.cn/img_convert/91683a8fcb2497986c7c4d401d473610.png)