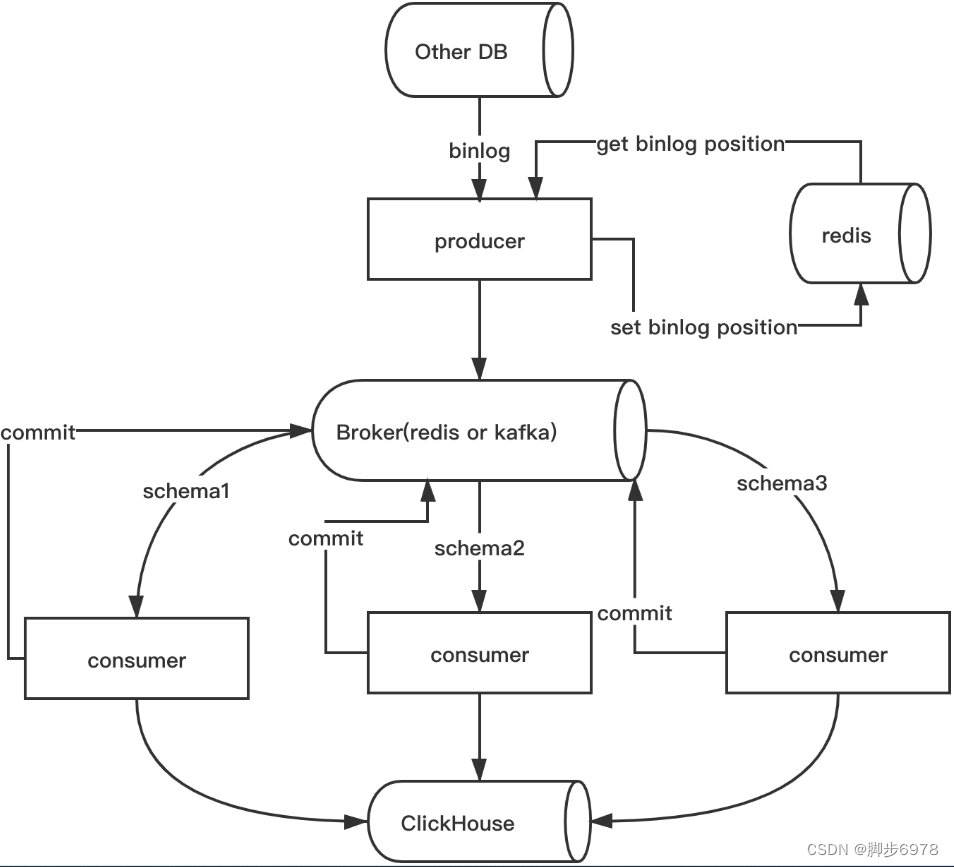
Synch
GitHub - long2ice/synch: Sync data from the other DB to ClickHouse(cluster)
环境:
| mysql5.7 | redis >= 5.0 | clickhouse21.2 | postgresql | python3 |
| binlog_format=row | XREAD | default | pg_config | synch |
1:安装clickhouse
rpm下载地址:
https://repo.yandex.ru/clickhouse/rpm/stable/x86_6
安装:rpm -ivh ./*.rpm
配置:
/etc/clickhouse-server/config.xml
/etc/clickhouse-server/users.xml
服务:
systemctl start clickhouse-server
客户端:
clickhouse-client
2:安装Python3
系统默认: Python 2.7.5安装:pip
yum -y install epel-release
yum install python-pip
pip --version
下载安装
wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tar.xz
cd Python-3.7.0
./configure --prefix=/usr/local/python3 --enable-shared --enable-optimizations
makemake install
环境变量
/etc/profile
export PYTHON_HOME=/usr/local/python3
export PATH=$PYTHON_HOME/bin:$PATH
异常及处理:
/usr/local/python3/bin/python3.7: error while loading shared libraries: libpython3.7m.so.1.0: cannot open shared object file: No such file or directory将python库的路径写到/etc/ld.so.conf配置中
vim /etc/ld.so.conf.d/python3.conf
/usr/local/python3/lib
ldconfig
升级pip

3:安装synch
pip3 install synch
安装异常:
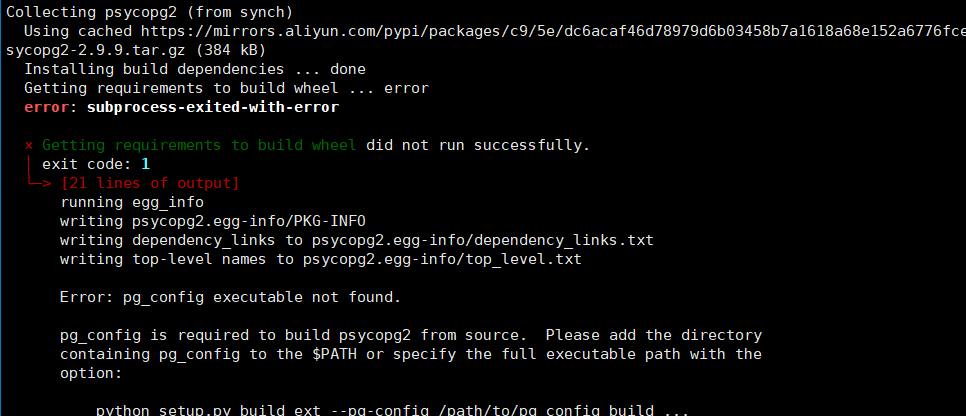
需要安装:PostgreSQL,
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install -y postgresql13-server
yum install postgresql-devel
psql --version
配置环境变量:
/usr/pgsql-13/bin/pg_config
export PATH=$PATH:/usr/pgsql-13/bin
安装成功:
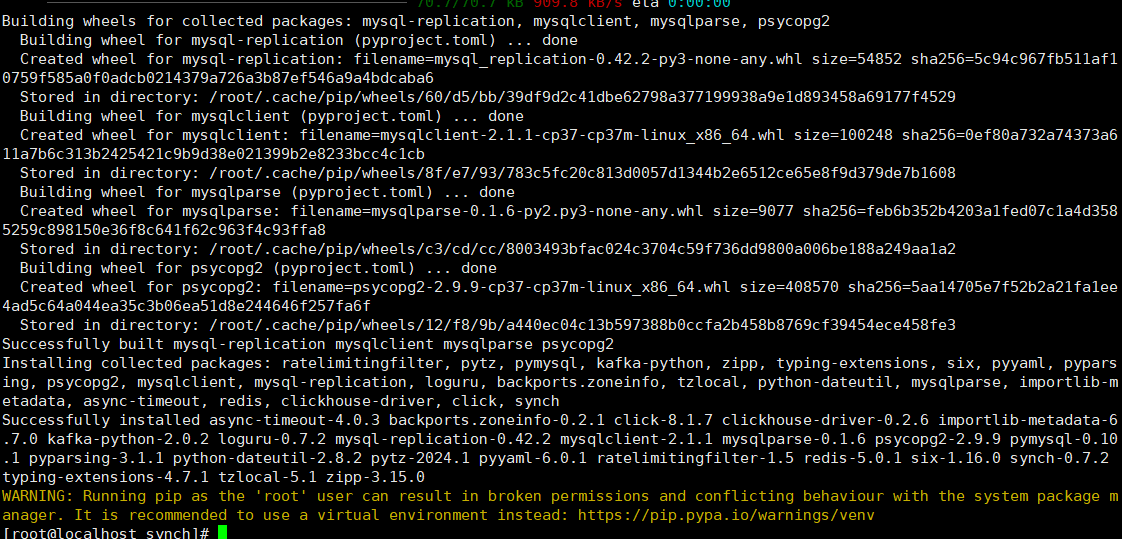
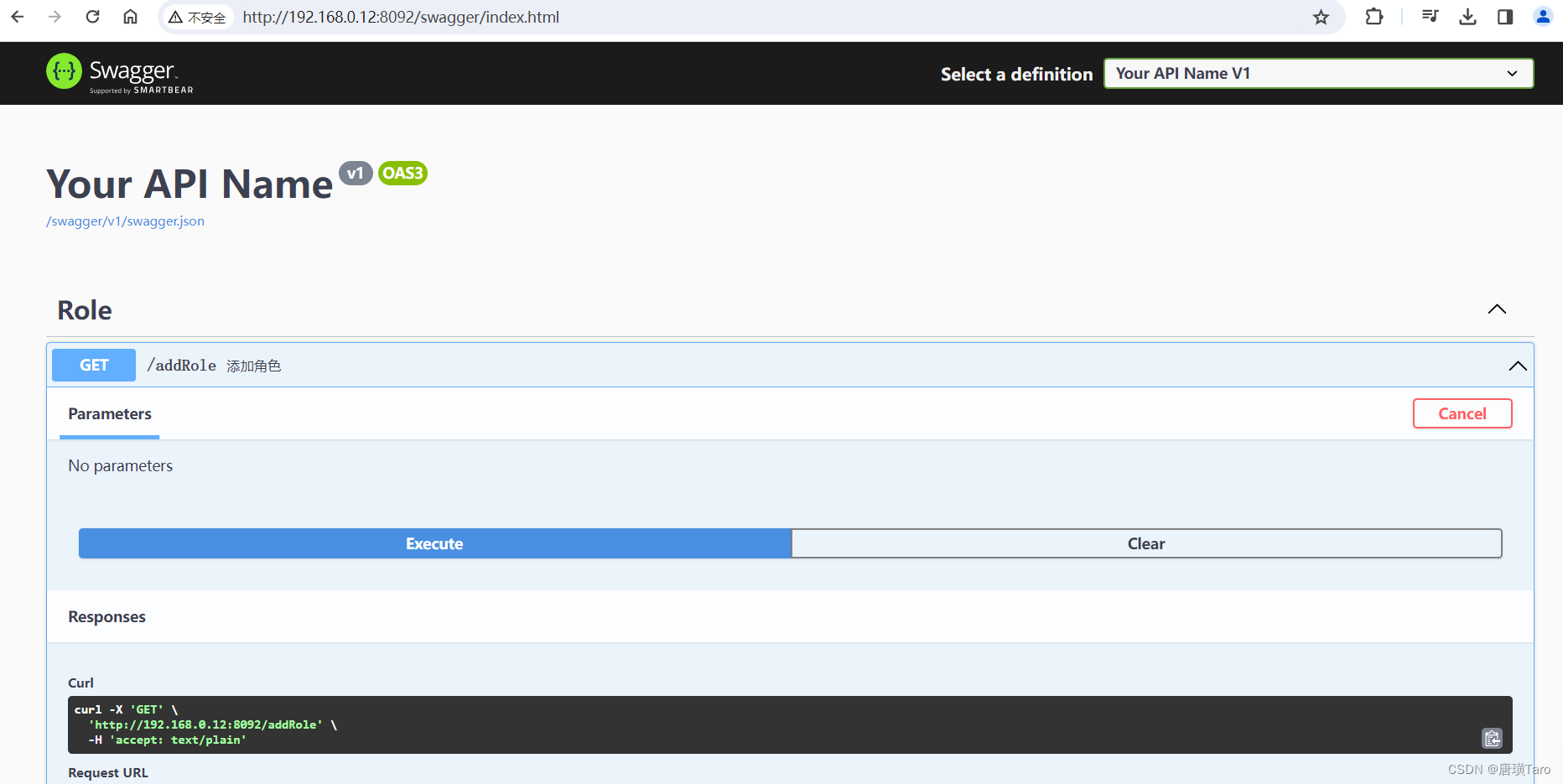
查看synch

配置synch.yaml
core:
debug: true # when set True, will display sql information.
insert_num: 1 # how many num to submit,recommend set 20000 when production
insert_interval: 1 # how many seconds to submit,recommend set 60 when production
# enable this will auto create database `synch` in ClickHouse and insert monitor data
monitoring: true
sentry:
environment: development
dsn:
redis:
host: 127.0.0.1
port: 6379
db: 0
password:
prefix: synch
queue_max_len: 200000 # stream max len, will delete redundant ones with FIFO
source_dbs:
- db_type: mysql
alias: mysql_db # must be unique
broker_type: redis # current support redis and kafka
server_id: 3
host: 127.0.0.1
port: 3306
user: root
password: "123456"
# optional, auto get from `show master status` when empty
init_binlog_file:
# optional, auto get from `show master status` when empty
init_binlog_pos:
skip_dmls: alert # dmls to skip
skip_delete_tables: # tables skip delete, format with schema.table
skip_update_tables: # tables skip update, format with schema.table
databases:
- database: crm
# optional, default true, auto create database when database in clickhouse not exists
auto_create: true
tables:
- table: user_log
# optional, default false, if your table has decimal column with nullable, there is a bug with full data etl will, see https://github.com/ClickHouse/ClickHouse/issues/7690.
skip_decimal: false # set it true will replace decimal with string type.
# optional, default true
auto_full_etl: true # auto do full etl at first when table not exists
# optional, default ReplacingMergeTree
clickhouse_engine: ReplacingMergeTree # current support MergeTree, CollapsingMergeTree, VersionedCollapsingMergeTree, ReplacingMergeTree
# optional
partition_by: # Table create partitioning by, like toYYYYMM(created_at).
# optional
settings: # Table create settings, like index_granularity=8192
# optional
sign_column: sign # need when clickhouse_engine=CollapsingMergeTree and VersionedCollapsingMergeTree, no need real in source db, will auto generate in clickhouse
# optional
version_column: # need when clickhouse_engine=VersionedCollapsingMergeTree and ReplacingMergeTree(optional), need real in source db, usually is `updated_at` with auto update.
- table: deptinfo
- table: user
clickhouse:
hosts:
- 127.0.0.1:9000
user: default
password: ''
cluster_name: #perftest_3shards_1replicas
distributed_suffix: ###_all # distributed tables suffix, available in cluster
#kafka:
# servers:
# - kafka:9092
# topic_prefix: synch
# enable this to send error report, comment or delete these if not.
mail:
mailhost: smtp.gmail.com
fromaddr: long2ice@gmail.com
toaddrs:
- long2ice@gmail.com
user: long2ice@gmail.com
password: "123456"
subject: "[synch] Error logging report"4:测试
1:create 。。 if not exists
synch -c /etc/synch.yaml --alias mysql_db etl --schema crm --table user
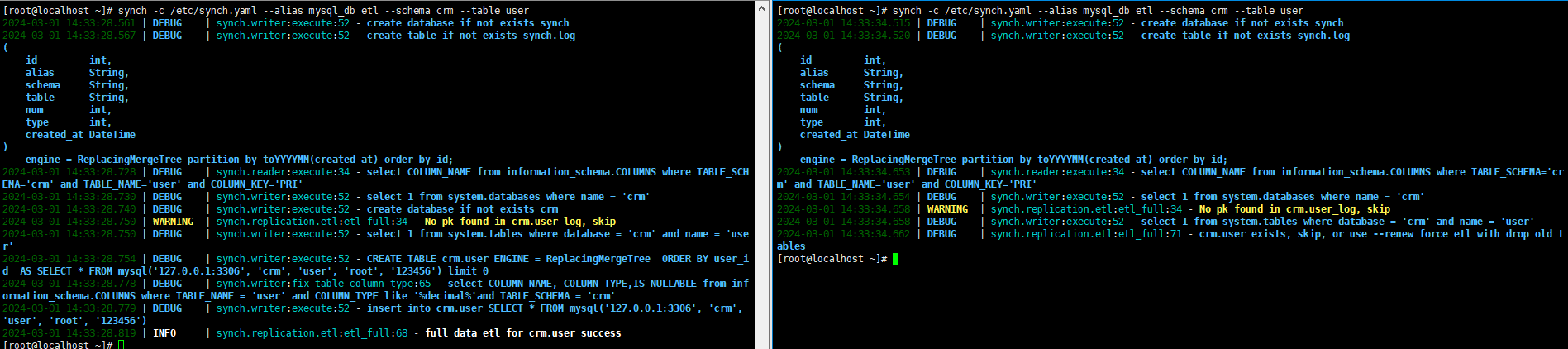
2:生产
监听源库并将变动数据写入消息队列。
synch --alias mysql_db produce
3:消费
从消息队列中消费数据并插入 ClickHouse,使用
--skip-error跳过错误消息。 配置auto_full_etl = True的时候会首先尝试做一次全量复制。消费数据库
crm并插入到ClickHouse:synch --alias mysql_db consume --schema crm

5:安装supervisord守护进程
yum install supervisor
配置
[program:mysql-to-ck-produce]
process_name=%(program_name)s
command=/usr/local/python3/bin/synch -c /etc/synch.yaml --alias mysql_db produce
autostart=true
autorestart=true
redirect_stderr=true
stdout_logfile=/var/log/supervisor/%(program_name)s.log
stdout_logfile_maxbytes=2048MB
stdout_logfile_backups=20
stopwaitsecs=3600
[program:mysql-to-ck-consume-crm]
process_name=%(program_name)s
command=/usr/local/python3/bin/synch -c /etc/synch.yaml --alias mysql_db consume --schema crm
autostart=true
autorestart=true
redirect_stderr=true
stdout_logfile=/var/log/supervisor/%(program_name)s.log
stdout_logfile_maxbytes=2048MB
stdout_logfile_backups=20
stopwaitsecs=3600服务:
systemctl restart supervisord
日志:
/var/log/supervisor
mysql-to-ck-consume-crm.log mysql-to-ck-produce.log supervisord.log