👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

双十一美妆数据分析可视化 [聚类分析/线性回归/支持向量机]
目录
- 双十一美妆数据分析可视化 [聚类分析/线性回归/支持向量机]
- 一、课程设计任务
- 二、 研究方法与技术路线
- 2.1. 数据收集与准备:
- 2.2. 特征选择与标准化:
- 2.3. 聚类分析:
- 2.4. 线性回归建模:
- 2.5. 支持向量机建模:
- 2.6. 可视化分析:
- 三、基本分析可视化
- 3.1 准备来源
- 3.2 数据预处理
- 四、数据分析过程及方法
- 4.1 数据分析方法简介
- 4.2 数据分析过程
- 4.2.1 价格分布直方图
- 4.2.2 销售前10店铺饼状图
- 4.2.3 价格与评论数的散点图
- 4.2.4 每日销售折线图):
- 4.2.5 价格分布与销量柱状图
- 五、聚类模型分析
一、课程设计任务
-
数据准备:将使用提供的"双十一淘宝美妆数据.csv"文件,进行数据导入、数据去重、处理缺失值等预处理工作,确保数据质量。
-
特征选择与标准化:将选择适当的特征进行分析,并使用标准化技术将数据转化为可用于建模的格式。
-
聚类分析:将使用K均值聚类方法对数据进行聚类分析,确定最佳的K值,并解释聚类结果。
-
线性回归建模:将使用线性回归模型对数据进行建模,并进行模型训练和评估,以预测商品价格。
-
支持向量机建模:将使用支持向量机(SVM)模型对数据进行建模,并进行模型训练和评估,以预测商品价格。
-
可视化分析:将绘制柱状图、饼状图、散点图、折线图和热力图,以展示数据的不同角度分析结果。
-
项目报告:将撰写项目报告,包括数据分析过程、模型建立和评估、可视化分析以及对结果的解释和建议。
通过完成上述任务,将获得在数据分析和机器学习方面的实际经验,提高其问题解决和数据驱动决策的能力。此外,课程设计还将帮助更好地理解数据科学的应用,为未来的职业发展打下坚实的基础。
二、 研究方法与技术路线
在完成上述课程设计的任务时,学生需要采用一系列研究方法和技术,以确保项目能够顺利进行并取得令人满意的结果。
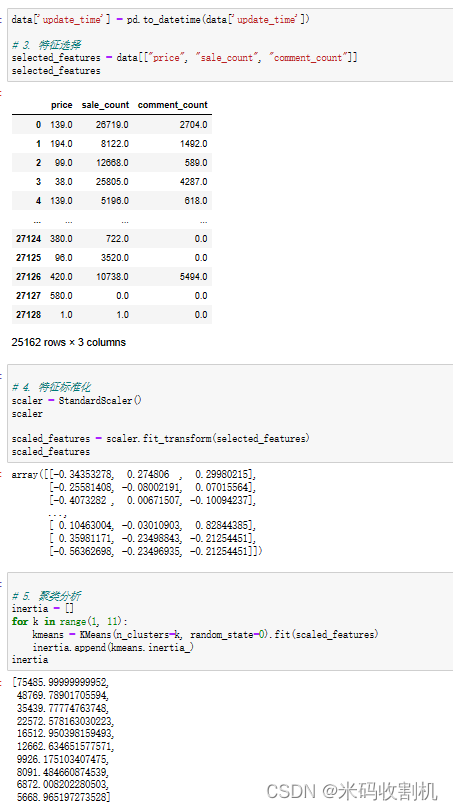
2.1. 数据收集与准备:
数据获取: 学生将从指定数据源中获取"双十一淘宝美妆数据.csv"文件。
数据导入: 使用Python的Pandas库,学生将数据导入到数据分析环境中,创建DataFrame以便后续处理。
数据清洗: 学生将执行数据去重操作,以去除重复的数据行。对于存在缺失值的列,可以选择填充或删除,确保数据质量。
数据转换: 学生将日期数据转换为datetime格式,以便进行时间序列分析。
2.2. 特征选择与标准化:
特征选择: 选择用于分析和建模的特征列,这里选择了"price"、“sale_count"和"comment_count”。
特征标准化: 使用Scikit Learn的StandardScaler,将对特征进行标准化,以保证模型的准确性。
2.3. 聚类分析:
K均值聚类: 使用Scikit Learn的KMeans算法进行聚类分析,寻找最佳的K值,以将数据分为不同的簇。
簇分析: 学生将对不同簇的特征进行分析,并解释簇的含义和特点。
2.4. 线性回归建模:
模型选择: 学生将选择线性回归模型,以建立商品价格与其他特征之间的关系。
模型训练: 使用Scikit Learn的LinearRegression,学生将对训练集进行模型训练。
模型评估: 学生将使用均方误差(MSE)等指标对模型性能进行评估。
2.5. 支持向量机建模:
模型选择: 学生将选择支持向量机(SVM)模型,以建立商品价格的预测模型。
模型训练: 使用Scikit Learn的SVR,学生将对训练集进行模型训练。
模型评估: 学生将使用均方误差(MSE)等指标对模型性能进行评估。
2.6. 可视化分析:
数据可视化: 学生将使用Matplotlib和Seaborn库绘制柱状图、饼状图、散点图、折线图和热力图,以传达数据的不同角度分析结果。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
三、基本分析可视化
3.1 准备来源
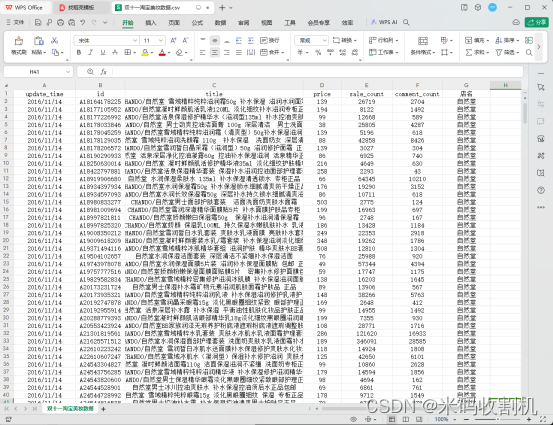
- 数据来源: 数据集来源于淘宝美妆产品在双十一购物节期间的销售和评论数据。
- 数据格式: 数据以CSV(逗号分隔值)格式存储,可以轻松导入到数据分析工具中进行处理。
- 数据字段说明: 数据集包含以下字段:
update_time(更新时间): 记录产品数据的更新时间,以日期格式表示。
id(产品ID): 每个美妆产品的唯一标识符。
title(产品标题): 包含了美妆产品的名称和描述信息。
price(产品价格): 产品的价格,以人民币(RMB)为单位。
sale_count(销售数量): 产品的销售数量,表示已售出的产品数量。
comment_count(评论数量): 产品收到的评论数量。
店名(店铺名称): 销售该美妆产品的店铺名称。
数据样本:
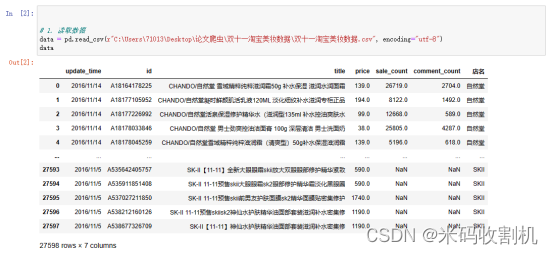
代码主要用于数据的导入和准备,其中的数据文件位于指定的文件路径双十一淘宝美妆数据\双十一淘宝美妆数据.csv。通过使用Python中的Pandas库中的pd.read_csv()函数,能够轻松地将CSV格式的数据读取到程序中进行后续的分析和处理。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
3.2 数据预处理
数据预处理是数据分析过程中的重要步骤,旨在清洗和准备原始数据,以使其适合后续的分析和建模工作。下面解释了上述代码中的数据预处理过程:
去重处理 (data.drop_duplicates(inplace=True)): 去重处理是为了删除数据集中的重复记录。在实际数据采集和整理中,常常会出现同一数据被多次记录的情况,这可能会导致分析结果的偏误。通过使用drop_duplicates()方法,代码会检查数据集中的每一行,如果发现有两行或多行数据内容完全相同的情况,就会删除其中的重复行。inplace=True参数表示在原始数据上进行修改,而不是创建一个新的数据副本。
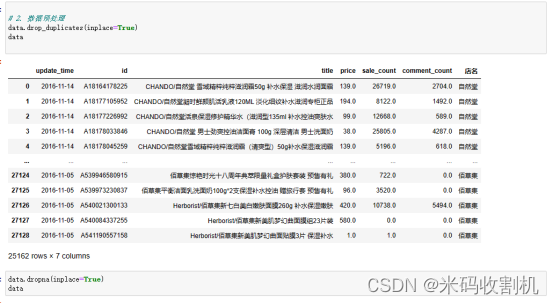
处理缺失值 (data.dropna(inplace=True)): 缺失值是指数据中某些字段或特征的取值为空或未知。处理缺失值的方式取决于数据的重要性和缺失值的原因。在这段代码中,使用dropna()方法删除了包含缺失值的行。这是因为如果数据行的某些字段缺失,那么在后续的分析中可能无法充分利用这些行。inplace=True参数表示在原始数据上进行修改。
日期数据格式转换 (data[‘update_time’] = pd.to_datetime(data[‘update_time’])): 在数据集中,update_time列存储了日期和时间的信息,但它通常以字符串的形式存在。为了能够在后续的时间序列分析中正确处理日期数据,需要将其转换为日期时间(datetime)格式。pd.to_datetime()函数将日期字符串转换为标准的日期时间格式,并将结果存储回update_time列中。这将允许进行基于时间的分析,如销售趋势的时间序列图。
综上所述,数据预处理的过程旨在确保数据集的质量,包括去除重复值、处理缺失值,以及对日期数据进行适当的格式转换。这些步骤有助于提高数据的可用性和准确性,使数据更适合进行进一步的分析和建模。预处理是数据分析的重要前提,它有助于消除数据中的噪音和问题,使分析结果更具可信度。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
四、数据分析过程及方法
4.1 数据分析方法简介
在本次研究中,致力于深入分析双十一淘宝美妆数据,以解密美妆市场的种种奥秘,为商家和消费者提供更为深刻的市场认识和决策依据。数据分析的过程首先涉及对美妆产品价格分布的细致研究。通过对价格分布的深入剖析,可以揭示出不同价格区间内商品的销售情况,进而洞察消费者对于价格的敏感度和购物偏好。这一步骤将为商家提供有力的定价策略建议,帮助其更好地调整价格,提高商品在市场中的竞争力。
其次,将关注销售排名前十的店铺,通过深入分析其销售表现,探究其成功的原因。这一研究方向有助于其他商家从成功案例中汲取经验教训,为制定更为有效的促销和经营策略提供启示。将通过综合考察店铺销售数据、用户评价以及其他相关指标,揭示出各店铺在双十一购物狂欢节中的亮眼表现,为整个美妆市场的竞争格局提供有益的参考。
4.2 数据分析过程
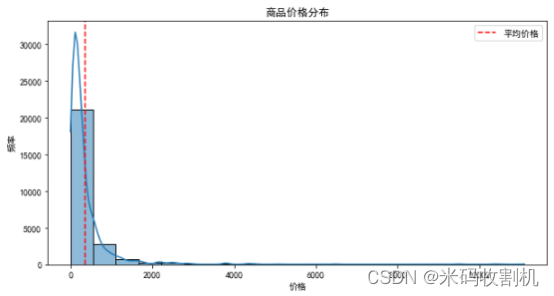
4.2.1 价格分布直方图
通过plt.hist函数绘制,展示了美妆产品价格的分布情况。
data[‘price’]表示使用数据集中的价格数据。
bins=20指定直方图的箱数为20,即将价格范围分成20个区间。
edgecolor='k’指定直方图边缘颜色为黑色。
plt.xlabel(“Price”)和plt.ylabel(“Frequency”)分别设置X轴和Y轴的标签。
plt.title(“Price Distribution”)设置图表标题为“价格分布”。
通过plt.show()展示图表。
👇👇👇 关注公众号,回复 “美妆数据分析” 获取源码👇👇👇
plt.hist(data['price'], bins=20, edgecolor='k')
plt.xlabel("Price")
plt.ylabel("Frequency")
plt.title("Price Distribution")
plt.show()
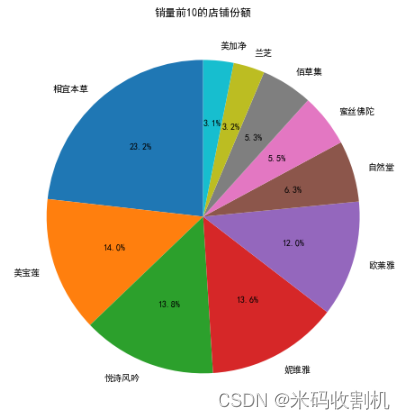
4.2.2 销售前10店铺饼状图
通过plt.pie函数展示了销售前10的店铺在总销售中的占比。
使用data.groupby(‘店名’)[‘sale_count’].sum().nlargest(10)获取销售前10店铺的销售总量。
autopct='%1.1f%%'表示显示百分比,并保留一位小数。
startangle=90表示饼状图的起始角度为90度。
plt.title(“Top 10 Shop Sales”)设置图表标题。
通过plt.show()展示饼状图。
top_10_shops = data.groupby('店名')['sale_count'].sum().nlargest(10)
plt.pie(top_10_shops, labels=top_10_shops.index, autopct='%1.1f%%', startangle=90)
plt.title("Top 10 Shop Sales")
plt.show()
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
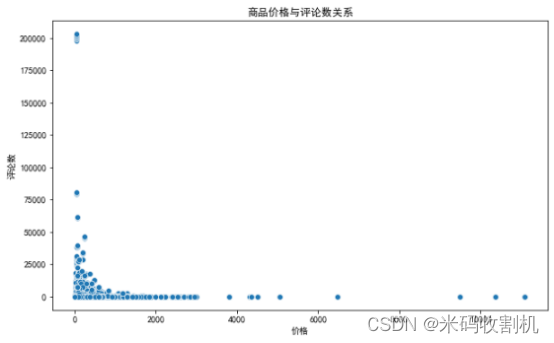
4.2.3 价格与评论数的散点图
使用Seaborn的sns.scatterplot函数,展示了商品价格与评论数之间的关系。
x='price’和y='comment_count’表示X轴和Y轴对应的数据列。
palette='Set1’指定颜色方案为Set1。
plt.xlabel(“Price”)和plt.ylabel(“Comments”)设置X轴和Y轴的标签。
plt.title(“Price vs. Comments”)设置图表标题。
通过plt.show()展示散点图。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
sns.scatterplot(x='price', y='comment_count', data=data, palette='Set1')
plt.xlabel("Price")
plt.ylabel("Comments")
plt.title("Price vs. Comments")
plt.show()
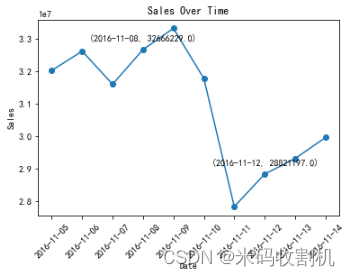
4.2.4 每日销售折线图):
通过折线图展示了每日销售量的变化趋势。
先将数据集中的时间数据转换为日期时间格式。
使用data.groupby(‘update_time’)[‘sale_count’].sum()计算每日销售总量。
plt.plot绘制折线图,marker='o’表示使用圆形标记。
plt.xlabel(“Date”)和plt.ylabel(“Sales”)设置X轴和Y轴的标签。
plt.title(“Sales Over Time”)设置图表标题。
plt.xticks(rotation=45)将X轴标签进行45度旋转。
通过plt.show()展示折线图。
data['update_time'] = pd.to_datetime(data['update_time'])
daily_sales = data.groupby('update_time')['sale_count'].sum()
plt.plot(daily_sales.index, daily_sales.values, marker='o')
(略)
plt.xlabel("Date")
plt.ylabel("Sales")
plt.title("Sales Over Time")
plt.xticks(rotation=45)
plt.show()
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
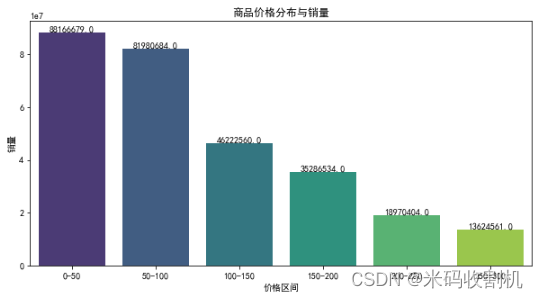
4.2.5 价格分布与销量柱状图
通过柱状图展示了不同价格区间内的商品销售情况。
使用pd.cut将商品价格分成不同区间,分别标记为’0-50’, ‘50-100’, …,并添加到数据集中。
使用data.groupby(‘price_bin’)[‘sale_count’].sum()计算每个价格区间的销售总量。
plt.bar绘制柱状图。
plt.xlabel(“Price Range”)和plt.ylabel(“Sales”)设置X轴和Y轴的标签。
plt.title(“Price vs. Sales”)设置图表标题。
通过plt.show()展示柱状图。
bins = [0, 50, 100, 150, 200, 250, 300]
labels = ['0-50', '50-100', '100-150', '150-200', '200-250', '250-300']
data['price_bin'] = pd.cut(data['price'], bins=bins, labels=labels)
price_sales = data.groupby('price_bin')['sale_count'].sum()
plt.bar(price_sales.index, price_sales.values)
plt.xlabel("Price Range")
plt.ylabel("Sales")
plt.title("Price vs. Sales")
plt.show()
这些图表通过不同角度展示了双十一淘宝美妆数据的多个方面,从价格分布到店铺销售排名,再到价格与评论数的关系,以及每日销售趋势和价格与销量的关系。这有助于深入理解美妆市场的特征,为商家和消费者提供了全面的市场洞察。
五、聚类模型分析
- 特征选择:在这一步,从给定的数据集中选择了三个特征,分别是产品的价格(“price”)、销量(“sale_count”)和评论数(“comment_count”)。这些特征被认为在分析和建模中具有重要的信息。
- 特征标准化:在机器学习中,不同特征的尺度可能会不同,这可能会影响某些算法的性能。因此,通过使用StandardScaler来进行特征标准化,将这三个特征的值标准化为均值为0,方差为1的标准正态分布。这个过程确保了特征在相同的尺度上进行比较,有助于聚类分析的准确性。
- 聚类分析:在这一步,使用K均值聚类算法(K Means)来对标准化后的特征数据进行聚类。聚类是一种无监督学习方法,它将相似的数据点划分为不同的簇,以便更好地理解数据的结构和模式。在这段代码中,使用了不同的簇数(从1到10),对每个簇数都拟合了K均值模型,并计算了每个簇数的模型内平方和(inertia),然后将这些值存储在inertia列表中。
肘部法则是一种常用的方法,用于确定最佳的簇数(K值)。它的思想是找到一个“肘部点”,即在该点之后增加簇数不再显著降低模型内平方和。通过绘制不同簇数下的模型内平方和并观察肘部点的位置,可以帮助选择合适的簇数,以便后续的分析或可视化更具有意义。
综上所述,这段代码通过选择重要的特征、对这些特征进行标准化,然后使用K均值聚类算法来探索数据中的簇结构,以便更好地理解数据并为进一步的分析和建模做准备。这是数据分析和机器学习流程中的重要步骤之一,用于发现数据中的模式和群集。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
-
plt.figure(figsize=(8, 6)) :这一行代码创建一个绘图窗口,并设置其大小为8x6英寸。这是为了确保绘制的图形具有适当的尺寸,以便查看和分析。
-
plt.plot(range(1, 11), inertia, marker=‘o’, linestyle=’ ‘) :这是绘制图形的主要部分。
range(1, 11) 创建了一个从1到10的整数序列,表示不同的簇数(K值),用作X轴上的刻度。
inertia 是一个列表,包含了不同簇数下对应的K均值模型的模型内平方和。
marker=‘o’ 指定了绘制的数据点使用圆圈标记,以使数据点更加可见。
linestyle=’ ’ 指定了绘制的线条的样式,这里使用虚线。 -
plt.xlabel(‘Number of clusters’) :设置X轴的标签为"Number of clusters",表示簇数。
-
plt.ylabel(‘Inertia’) :设置Y轴的标签为"Inertia",表示模型内平方和。
-
plt.title(‘Elbow Method for Optimal K’) :设置图形的标题为"Elbow Method for Optimal K",描述了这个图形的用途。
-
plt.show() :最后一行代码用于显示绘制出的肘部法则图形。
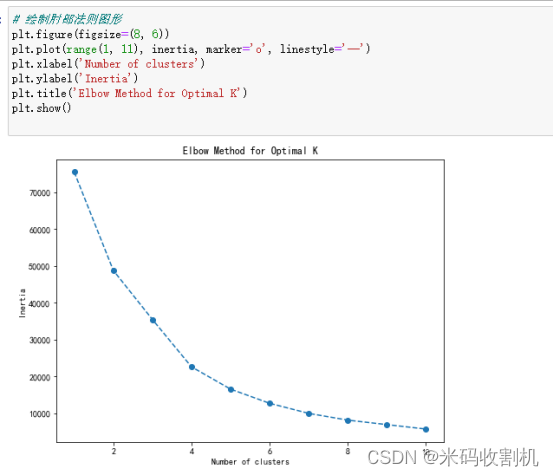
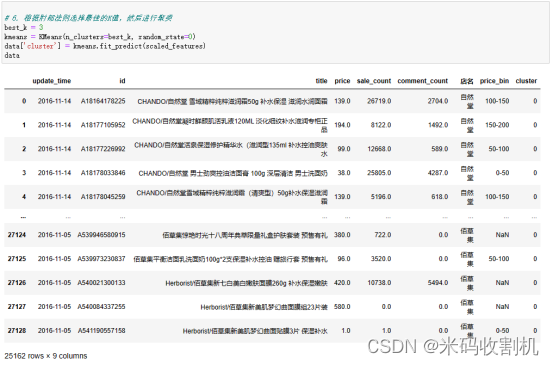
根据肘部法则选择最佳的K值,然后进行聚类:在这一步,选择了一个事先设定的最佳簇数K,这里为3,但实际上通常是通过肘部法则或其他评估方法来确定最佳的K值。接着,使用K均值聚类算法创建了一个K均值模型,并将数据中的样本分配到不同的簇中。聚类的结果被添加到数据中的一个名为’cluster’的新列中,以表示每个数据点所属的簇。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
根据聚类结果将数据集中的样本分为三个不同的子集,分别是低价格高销量的商品(cluster 0),在价格、销量和评论上表现平均的商品(cluster 1),和高价格低销量的商品(cluster 2)。然后,通过 print 语句展示了每个子集中的示例数据,以便分析者和其他人可以更好地理解每个簇的特征。

👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
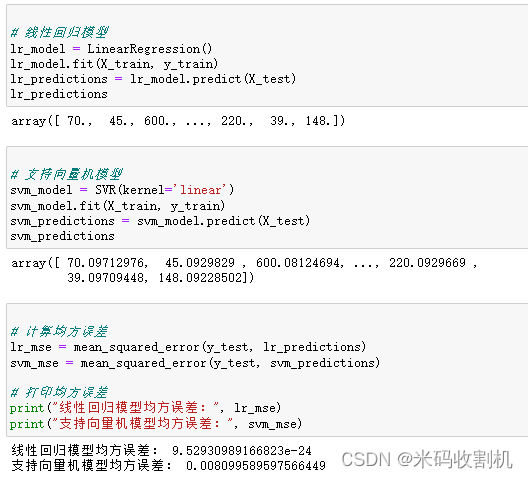
两幅散点图的目的是帮助分析者直观地了解模型的性能,特别是模型的预测值与真实值之间的差异。通过观察散点图,可以快速评估模型的预测准确度和偏差,以确定模型是否足够拟合数据。如果点在图中接近一条对角线,则表示模型的预测结果与真实值接近;反之,如果点分散或呈现明显的模式,则可能需要进一步改进模型。此外,通过比较线性回归模型和支持向量机模型的散点图,可以比较两个模型的性能,找出哪个模型更适合解决特定的问题。
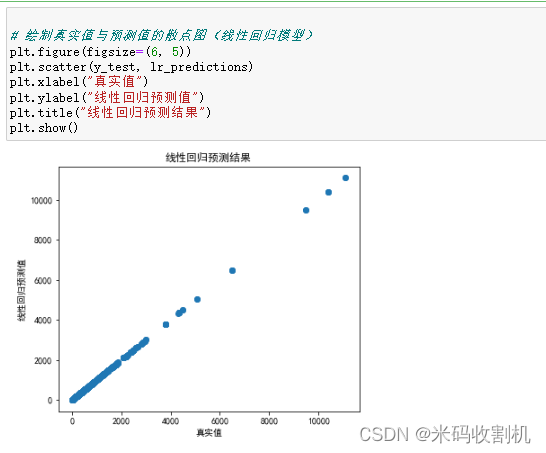
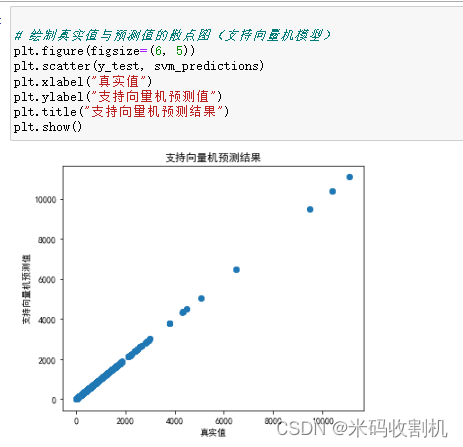
plt.figure(figsize=(6, 5)) :这一行代码创建了一个绘图窗口,并设置其大小为6x5英寸,以确保绘制的图形具有适当的尺寸。
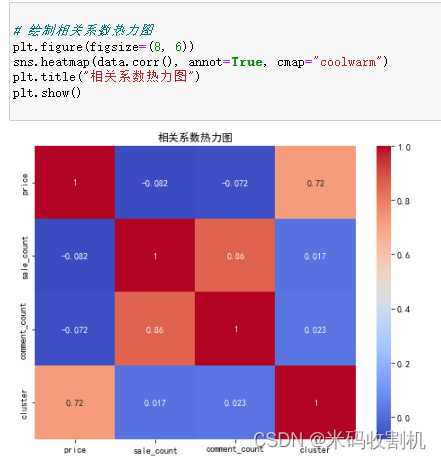
sns.heatmap(X_train, cmap=“YlGnBu”) :使用Seaborn库中的 heatmap 函数绘制特征热力图。特征热力图以矩阵的形式展示了特征之间的相关性,颜色深浅表示相关性的强弱。在这里, X_train 是训练集中的特征数据,而 cmap=“YlGnBu” 指定了颜色地图,以蓝绿色为基调,用于可视化相关性。
plt.title(“特征热力图 训练集”) :设置图形的标题为"特征热力图 训练集",以描述图形的内容。
plt.show() :最后一行代码用于显示绘制出的特征热力图。
接下来,对于测试集(X_test)的特征热力图,代码结构与训练集的特征热力图相似,但针对测试集的数据进行了相同的操作。这段代码的目的是帮助分析者和数据科学家更好地理解特征之间的相关性,尤其是在训练集和测试集上进行比较,以确保模型的泛化性能。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇
通过观察热力图,分析者可以识别出哪些特征之间存在强烈的正相关性或负相关性,以及哪些特征对目标变量的影响较大。这有助于指导后续的特征工程、模型选择和解释。此外,相关系数热力图也可以用于检查多重共线性,即多个特征之间存在高度相关性的情况,以避免过多冗余的特征。因此,这段代码在整个数据分析和建模过程中具有关键作用,有助于深入理解数据的内在结构和特征之间的关系。
👇👇👇 关注公众号,回复 “聚类美妆分析” 获取源码👇👇👇