文章目录
- 一、项目目录层级组织概念
- 1.1 cargo new 创建同名 的 Project 和 crate
- 1.2 多 crate 的 package
- 1.3 mod 模块
- 1.3.1 创建嵌套 mod
- 1.3.2 mod 树
- 1.3.3 用路径引用 mod
- 1.3.3.1 使用绝对还是相对?
- 1.3.4 代码可见性
- 1.3.4.1 pub 关键字
- 1.3.4.2 用 super 引用 mod
- 1.3.4.3 用 self 引用 mod
- 1.3.5 struct 和 enum 的可见性
- 1.3.6 把 mod 和文件分离: 拆分到单独文件或文件夹中
- 1.3.6.1 拆分到单独的文件中
- 1.3.6.2 拆分到单独的文件夹中
- 1.4 use
- 1.4.1 基本引入方式
- 1.4.1.1 绝对路径引入 mod
- 1.4.1.2 相对路径引入 mod 中的 fn
- 1.4.1.3 引入 mod 还是 fn
- 1.4.2 避免同名引入
- 1.4.2.1 模块::函数
- 1.4.2.2 as 别名引用
- 1.4.3 引入项再导出
- 1.4.4 使用第三方 crate
- 1.4.5 用 {} 简化引用方式
- 1.4.5.1 self
- 1.4.6 用 * 引入 mod 下的所有项
- 1.4.7 受限的可见性
- 1.4.7.1 限制可见性语法
- 1.4.7.2 一个综合例子
- 二、目录层级实战
- 2.1 单文件拆分为 services, clients, utils 等多个 mod
一、项目目录层级组织概念
cargo new 出来的是 Project 项目
project 中有多个 crate 包
crate 包有多个 mod 模块组成
1.1 cargo new 创建同名 的 Project 和 crate
通过 cargo new my-project 会创建一个 my-project 的 Project, 同时会创建一个同名(即 my-project) 的 crate. 该 crate 的根文件是 src/main.rs 如下所示:
src
├── main.rs
Cargo.toml
# cargo r
Hello, world!
通过 cargo new my-lib --lib 会创建一个 my-lib 的 Project, 同时会创建一个同名(即 my-lib) 的 crate. 该 crate 的根文件是 src/lib.rs, 如下所示:
src
├── lib.rs
Cargo.toml
# cargo r
error: a bin target must be available for `cargo run`
所以 Package 和 crate 容易混淆, 是因为用 cargo new 创建的是同名的.
1.2 多 crate 的 package
真实项目会包含多个 crate, 只能有一个 lib crate, 可以有多个 bin crate. 组织层级如下:
.
├── Cargo.toml
├── Cargo.lock
├── src
│ ├── main.rs
│ ├── lib.rs
│ └── bin
│ └── main1.rs
│ └── main2.rs
├── tests
│ └── some_integration_tests.rs
├── benches
│ └── simple_bench.rs
└── examples
└── simple_example.rs
说明如下:
- 唯一 lib crate: src/lib.rs
- 默认 bin crate: src/main.rs, 编译后生成和 Package 同名的 可执行程序
- 其他 bin crate: src/bin/main1.rs, src/bin/main2.rs, 分别生成一个和文件同名的 可执行程序
- 集成测试: tests 目录
- 性能测试: benches 目录
- 示例: examples 目录
1.3 mod 模块
用 mod 可以拆分代码, 按功能重组, 更易于维护.
1.3.1 创建嵌套 mod
cargo new --lib restaurant
src
└── lib.rs
// lib.rs 内容如下
// 餐厅前台, 用于吃饭
mod front_of_house {
// 招待客人
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
// 服务
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}
// 上述代码创建了三个 mod
// 用 mod 关键字可以创建新 mod
// mod 可以嵌套, 因为 招待客人 和 服务 都发生在前台, 所以嵌套, 模拟了真实场景
// mod 里定义了各种 rust 类型, 如fn, struct, enum, trait
// 所有 mod 都定义在同一个文件中
类似上述代码中所做的,使用模块,我们就能将功能相关的代码组织到一起,然后通过一个模块名称来说明这些代码为何被组织在一起。这样其它程序员在使用你的模块时,就可以更快地理解和上手。
1.3.2 mod 树
因为 src/main.rs 和 src/lib.rs 这两个文件形成了两个 crate. 而且这两个文件是 crate root (即 mod 树的顶层).
如上例, lib.rs 中的其他三个 mod 成为了 mod 树的子模块. 例如 hosting 是 add_to_waitlist 的 父.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
1.3.3 用路径引用 mod
想要调用一个函数,就需要知道它的路径,在 rust 中,这种路径有两种形式:
- 绝对路径: 从 crate root 开始, 路径名以 package 名 或 crate 名, 作为开头.
- 相对路径: 从 当前 mod 开始, 路径名以 self, super, 或当前 mod 的标识符, 作为开头.
示例如下, 添加如下功能:
// 餐厅前台, 用于吃饭
mod front_of_house {
// 招待客人
pub mod hosting {
pub fn add_to_waitlist() {}
fn seat_at_table() {}
}
// 服务
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}
pub fn eat_at_resturant() {
// 绝对路径
crate::front_of_house::hosting::add_to_waitlist(); // 需要如下 pub 权限: pub mod hosting, pub fn add_to_waitlist
// 相对路径
front_of_house::hosting::add_to_waitlist();
self::front_of_house::hosting::add_to_waitlist();
}
1.3.3.1 使用绝对还是相对?
都可以, 视情况而定. 原则是: 当代码被挪动位置时,尽量减少引用路径的修改.
- 如果原来用的是绝对路径, 但现在 front_of_house 的绝对路径变了, 那得改. (例如把
front_of_house模块和eat_at_restaurant移动到一个模块customer_experience中)
crate
└── customer_experience
└── eat_at_restaurant
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
- 如果原来用的是相对路径, 但现在 eat_at_resturant 的绝对路径变了, 那也得改. (例如把
eat_at_restaurant移动到模块dining中)
crate
└── dining
└── eat_at_restaurant
└── front_of_house
├── hosting
│ ├── add_to_waitlist
如果不确定哪个更好, 可以优先考虑用绝对路径, 因为调用的地方, 和定义的地方, 往往是分离的, 而定义的地方较少的会变动.
1.3.4 代码可见性
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}
上述代码意料之外的报错了, hosting 不是 pub 的, 不可见.
error[E0603]: module `hosting` is private
--> src/main.rs:13:28
|
13 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/main.rs:6:5
|
6 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `my-project` (bin "my-project") due to 1 previous error
但为什么 mod front_of_house {} 可以访问呢? 是因为它和 fn eat_at_restaurant() 在同一个 crate root 作用域内. 同一个 mod 内的代码自然不存在可见性问题(所以我们之前的代码都没报过这个错误)
mod 不仅对组织代码很有用, 还能定义代码的可见性, 默认所有类型都是 private 的(fn, struct, enum, 甚至包括 mod).
重要的一点是: 在 rust 中, 父无法访问子, 但是子可以访问父. 即父 mod 完全无法访问 子 mod 的任何 private 项, 但是 子 mod 却可以访问 父 mod, 父父 mod 的 private 项.
1.3.4.1 pub 关键字
如果只改 hosting 为 pub, 还是会报错
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// cargo r
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:12:30
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
所以, mod 的可见性还不够, 还需要把 add_to_waitlist 标记为 pub. 这是因为 mod 的可见性, 仅仅是允许其他 mod 去引用它, 并不代表 mod 内部项的可见性. 如果想引用它的内部项, 还需要把对应的内部项也标记为 pub.
实际项目中, 一个 mod 需要对外暴露的 数据 和 fn, 往往非常少, 所以 rust 是这样设计的.
所以改为如下, 即可通过编译
fn main() {
println!("Hello, world!");
}
mod front_of_house {
pub mod hosting { // pub
pub fn add_to_waitlist() {} // pub
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
// front_of_house::hosting::add_to_waitlist();
}
1.3.4.2 用 super 引用 mod
在 用路径引用mod 中,我们提到了相对路径有三种方式开始:self、super和 crate 或者模块名,其中第三种在前面已经讲到过,现在来看看通过 super 的方式引用模块项。
super 是父 mod, 示例如下:
fn serve_order() {}
// 厨房模块
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::serve_order();
}
fn cook_order() {}
}
嗯,我们的小餐馆又完善了,终于有厨房了!看来第一个客人也快可以有了。。。在厨房模块中,使用 super::serve_order 语法,调用了父模块(包根)中的 serve_order 函数。
那么你可能会问,为何不使用 crate::serve_order 的方式?额,其实也可以,不过如果你确定未来这种层级关系不会改变,那么 super::serve_order 的方式会更稳定,未来就算它们都不在包根了,依然无需修改引用路径。所以路径的选用,往往还是取决于场景,以及未来代码的可能走向。
1.3.4.3 用 self 引用 mod
self 其实就是引用自身模块中的项,也就是说和我们之前章节的代码类似,都调用同一模块中的内容,区别在于之前章节中直接通过名称调用即可,而 self,你得多此一举:
fn serve_order() {
self::back_of_house::cook_order();
back_of_house::cook_order();
}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
crate::serve_order();
}
pub fn cook_order() {}
}
是的,多此一举,因为完全可以直接调用 back_of_house,但是 self 还有一个大用处,在下一节中我们会讲。
1.3.5 struct 和 enum 的可见性
为何要把 struct 和 enum 的可见性单独拎出来讲呢?因为这两个家伙的成员字段拥有完全不同的可见性:
- 将 struct 设置为
pub,但它的所有字段依然是私有的 - 将 enum 设置为
pub,它的所有字段也将对外可见
原因在于,struct 和 enum 的使用方式不一样。如果 enum 的成员对外不可见,那该 enum 将一点用都没有,因此 enum 成员的可见性自动跟 enum 可见性保持一致,这样可以简化用户的使用。
而 struct 的应用场景比较复杂,其中的字段也往往部分在 A 处被使用,部分在 B 处被使用,因此无法确定成员的可见性,那索性就设置为全部不可见,将选择权交给程序员。
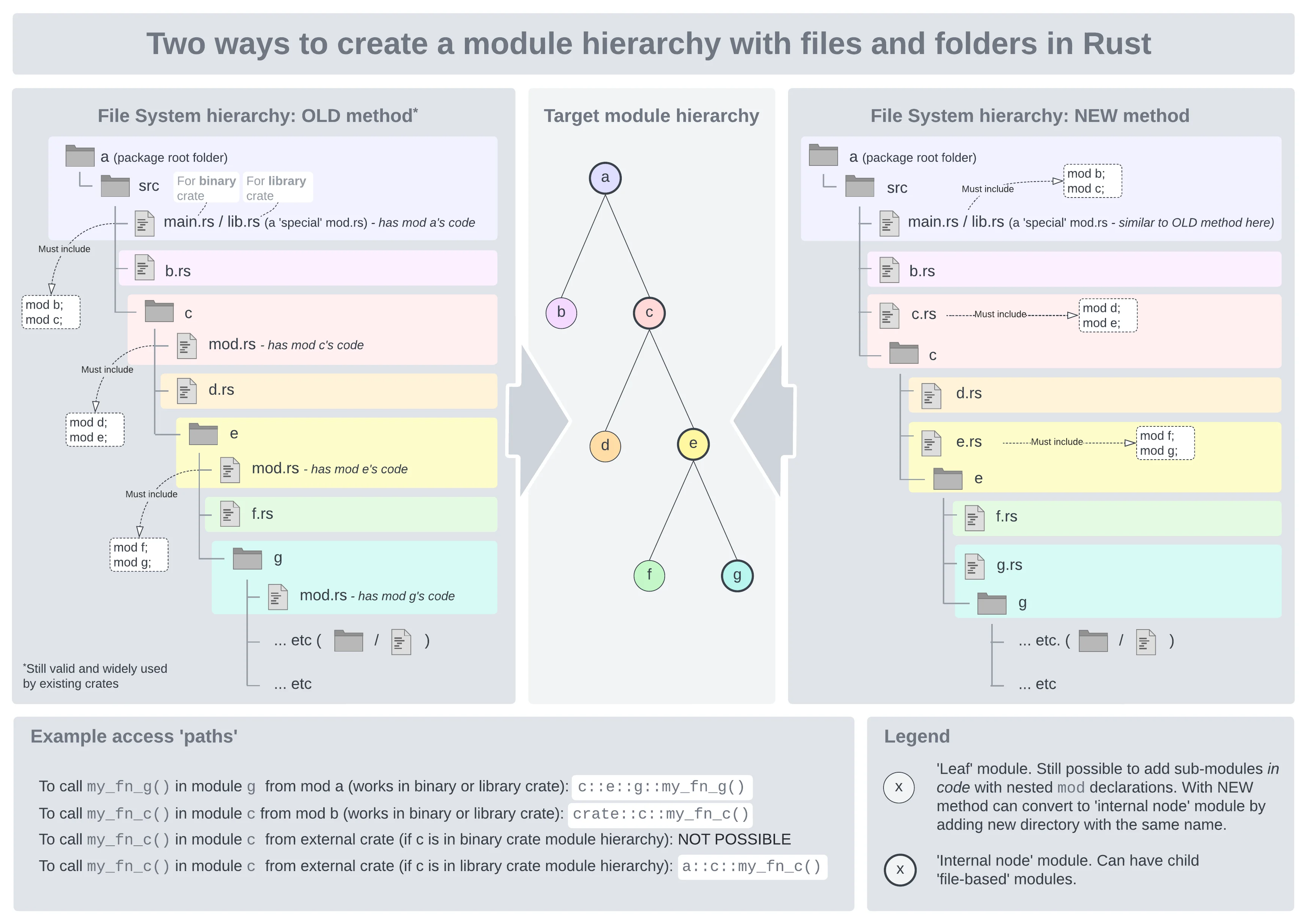
1.3.6 把 mod 和文件分离: 拆分到单独文件或文件夹中
首先回忆一下之前的例子, 我们所有的模块都定义在 src/lib.rs 中,如下:
src
└── lib.rs
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}
但是当模块变多或者变大时,需要将模块放入一个单独的文件中,让代码更好维护。
1.3.6.1 拆分到单独的文件中
现在,把 front_of_house 前厅分离出来,放入一个单独的文件中 src/front_of_house.rs:
src
├── front_of_house.rs
└── lib.rs
// src/front_of_house.rs 内容如下:
pub mod hosting {
pub fn add_to_waitlist() {}
}
// src/lib.rs 内容如下:
mod front_of_house; // 告诉 rust 从另一个 模块 front_of_hose 同名的文件中加载该模块的内容
pub fn eat_at_restaurant() {
crate::front_of_house::hosting::add_to_waitlist(); // Absolute path
front_of_house::hosting::add_to_waitlist(); // Relative path
}
要注意, 和之前代码中 mod front_of_house {..} 的完整模块不同, 现在的代码中, mod 的声明和实现是分离的
- 实现是在 单独的 front_of_house.rs 文件中
- 然后通过 mod front_of_house 这条声明语句, 从该文件中把模块加载进来
- 所以可以认为, 模块 front_of_house 的定义还是在 src/lib.rs 中, 只不过模块的具体内容被移动到了 src/front_of_house.rs 文件中
1.3.6.2 拆分到单独的文件夹中
当一个模块有许多子模块时,我们也可以通过文件夹的方式来组织这些子模块。
例如, 上述例子中,我们可以创建一个目录 front_of_house,然后在文件夹里创建一个 mod.rs 和 hosting.rs 文件, 整体层级如下:
src
├── front_of_house
│ ├── hosting.rs
│ └── mod.rs
└── lib.rs
// src/lib.rs 内容如下:
mod front_of_house; // 引用另一个 front_of_house 模块的内容(来自 front_of_house.rs 或 front_of_house 文件夹)
pub fn eat_at_restaurant() {
crate::front_of_house::hosting::add_to_waitlist(); // Absolute path
front_of_house::hosting::add_to_waitlist(); // Relative path
}
// src/front_of_house/mod.rs 内容如下:
pub mod hosting; // 引用另一个 hosting 模块的内容(来自 hosting.rs 或 hosting 文件夹)
// src/front_of_house/hosting.rs 内容如下:
pub fn add_to_waitlist() {} // 没有用 mod 引用别人, 自己就是自己的内容
所以, mod 关键字类似于 golang 的 package 和 import 关键字的整合
- 像 package: 可以在同一个文件中定义 mod
- 像 import: 可以在不同文件中引用 mod
1.4 use
如果代码中,通篇都是 crate::front_of_house::hosting::add_to_waitlist 这样的函数调用形式,我不知道有谁会喜欢,也许靠代码行数赚工资的人会很喜欢,但是强迫症肯定受不了,悲伤的是程序员大多都有强迫症。。。
因此我们需要一个办法来简化这种使用方式,在 Rust 中,可以使用 use 关键字把路径提前引入到当前作用域中,随后的调用就可以省略该路径,极大地简化了代码。
1.4.1 基本引入方式
1.4.1.1 绝对路径引入 mod
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
hosting::add_to_waitlist();
hosting::add_to_waitlist();
}
这里,我们使用 use 和绝对路径的方式,将 hosting 模块引入到当前作用域中,然后只需通过 hosting::add_to_waitlist 的方式,即可调用目标模块中的函数,相比 crate::front_of_house::hosting::add_to_waitlist() 的方式要简单的多,那么还能更简单吗?
1.4.1.2 相对路径引入 mod 中的 fn
在下面代码中,我们不仅要使用相对路径进行引入,而且与上面引入 hosting 模块不同,直接引入该模块中的 add_to_waitlist 函数:
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
add_to_waitlist();
add_to_waitlist();
}
1.4.1.3 引入 mod 还是 fn
优先使用最细粒度(引入函数、结构体等)的引用方式,如果引起了某种麻烦(例如前面两种情况),再使用引入 mod 的方式。
从使用简洁性来说,引入函数自然是更甚一筹,但是在某些时候,引入模块会更好:
- 需要引入同一个模块的多个函数
- 作用域中存在同名函数
例如,如果想使用 HashMap,那么直接引入该结构体是比引入模块更好的选择,因为在 collections 模块中,我们只需要使用一个 HashMap 结构体:
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, 2);
}
1.4.2 避免同名引入
1.4.2.1 模块::函数
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
}
fn function2() -> io::Result<()> {
// --snip--
}
上面的例子给出了很好的解决方案,使用模块引入的方式,具体的 Result 通过 模块::Result 的方式进行调用。
可以看出,避免同名冲突的关键,就是使用父模块的方式来调用,除此之外,还可以给予引入的项起一个别名。
1.4.2.2 as 别名引用
对于同名冲突问题,还可以使用 as 关键字来解决,它可以赋予引入项一个全新的名称:
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
}
fn function2() -> IoResult<()> {
// --snip--
}
如上所示,首先通过 use std::io::Result 将 Result 引入到作用域,然后使用 as 给予它一个全新的名称 IoResult,这样就不会再产生冲突:
- Result 代表 std::fmt::Result
- IoResult 代表 std:io::Result
1.4.3 引入项再导出
在 Rust 中,pub use 语句被用于重新导出模块中的项(如函数、结构体、枚举、trait等),使得它们可以在当前模块的父模块中被访问。这样做通常是为了创建一个更加方便的公共API,或者重新组织模块结构而不破坏现有代码。
当你在一个模块中写 pub use 时,你不仅使得项在当前模块中可用,而且允许外部代码通过当前模块的路径来访问这些项。
// 在 some_module.rs 文件中
pub mod nested_module {
pub fn useful_function() {}
}
// 重新导出 `useful_function`,让外部代码可以直接通过 `some_module::useful_function` 来调用。
pub use nested_module::useful_function;
在这个例子中,useful_function 原本只能通过 some_module::nested_module::useful_function 的路径来访问。通过使用 pub use,它现在也可以通过 some_module::useful_function 的路径来访问。这样做简化了函数的访问路径,对于使用该模块的外部代码来说更加方便。
示例如下:
src
├── front_of_house.rs
└── lib.rs
// lib.rs 如下
mod front_of_house;
pub fn eat_at_restaurant() {
front_of_house::add_to_waitlist(); // 外部包可以直接访问 front_of_house mod 的 add_to_waitlist() fn, 而不需要经过中间的 hosting 了
}
// front_of_house.rs 如下
pub mod hosting {
pub fn add_to_waitlist() {}
}
pub use hosting::add_to_waitlist; // 重新导出 add_to_waitlist, 使得外部包可以直接访问 front_of_house mod 的 add_to_waitlist() fn, 而不需要经过中间的 hosting 了
1.4.4 使用第三方 crate
例如以 rand crate 为例, cargo add rand
use rand::Rng;
fn main() {
let secret_number = rand::thread_rng().gen_range(1..101);
}
Rust 社区已经为我们贡献了大量高质量的第三方包,你可以在 crates.io 或者 lib.rs 中检索和使用,从目前来说查找包更推荐 lib.rs,搜索功能更强大,内容展示也更加合理,但是下载依赖包还是得用crates.io。
1.4.5 用 {} 简化引用方式
use std::io;
use std::io::Write;
可以简化为
use std::io::{self, Write};
1.4.5.1 self
上面使用到了模块章节提到的 self 关键字,用来替代模块自身,结合上一节中的 self,可以得出它在模块中的两个用途:
- use self::xxx,表示加载当前模块中的 xxx。此时 self 可省略
- use xxx::{self, yyy},表示,加载当前路径下模块 xxx 本身,以及模块 xxx 下的 yyy
1.4.6 用 * 引入 mod 下的所有项
对于之前一行一行引入 std::collections 的方式,我们还可以使用
use std::collections::*;
以上这种方式来引入 std::collections 模块下的所有公共项,这些公共项自然包含了 HashMap,HashSet 等想手动引入的集合类型。
当使用 * 来引入的时候要格外小心,因为你很难知道到底哪些被引入到了当前作用域中,有哪些会和你自己程序中的名称相冲突:
use std::collections::*;
struct HashMap;
fn main() {
let mut v = HashMap::new();
v.insert("a", 1);
}
以上代码中,std::collection::HashMap 被 * 引入到当前作用域,但是由于存在另一个同名的结构体,因此 HashMap::new 根本不存在,因为对于编译器来说,本地同名类型的优先级更高。
在实际项目中,这种引用方式往往用于快速写测试代码,它可以把所有东西一次性引入到 tests 模块中。
1.4.7 受限的可见性
在上一节中,我们学习了可见性这个概念,这也是模块体系中最为核心的概念,控制了模块中哪些内容可以被外部看见,但是在实际使用时,光被外面看到还不行,我们还想控制哪些人能看,这就是 Rust 提供的受限可见性。
例如,在 Rust 中,包是一个模块树,我们可以通过 pub(crate) item; 这种方式来实现:item 虽然是对外可见的,但是只在当前包内可见,外部包无法引用到该 item。
所以,如果我们想要让某一项可以在整个包中都可以被使用,那么有两种办法:
- 在包根中定义一个非
pub类型的X(父模块的项对子模块都是可见的,因此包根中的项对模块树上的所有模块都可见) - 在子模块中定义一个
pub类型的Y,同时通过use将其引入到包根
mod a {
pub mod b {
pub fn c() {
println!("{:?}",crate::X);
}
#[derive(Debug)]
pub struct Y;
}
}
#[derive(Debug)]
struct X;
use a::b::Y;
fn d() {
println!("{:?}",Y);
}
以上代码充分说明了之前两种办法的使用方式,但是有时我们会遇到这两种方法都不太好用的时候。例如希望对于某些特定的模块可见,但是对于其他模块又不可见:
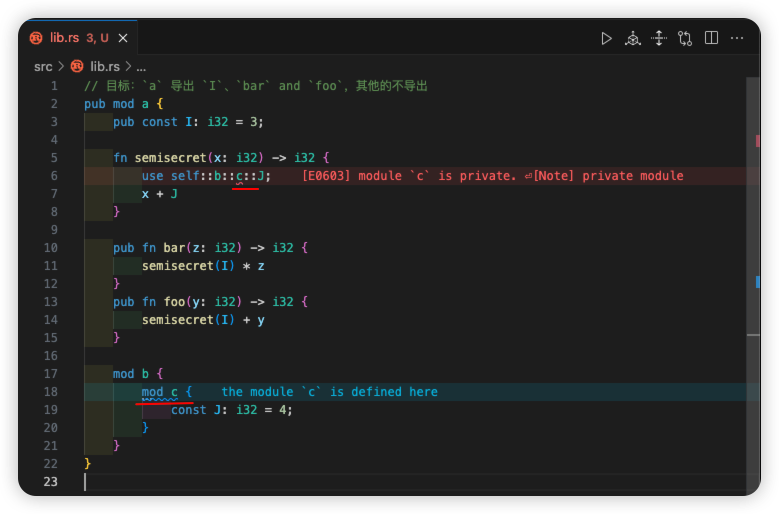
这段代码会报错,因为与父模块中的项对子模块可见相反,子模块中的项对父模块是不可见的。这里 semisecret 方法中,a -> b -> c 形成了父子模块链,那 c 中的 J 自然对 a 模块不可见。
如果使用之前的可见性方式,那么想保持 J 私有,同时让 a 继续使用 semisecret 函数的办法是将该函数移动到 c 模块中,然后用 pub use 将 semisecret 函数进行再导出:
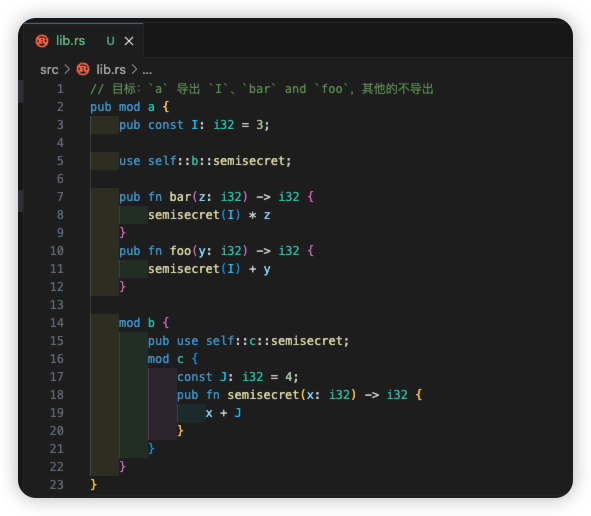
这段代码说实话问题不大,但是有些破坏了我们之前的逻辑,如果想保持代码逻辑,同时又只让 J 在 a 内可见该怎么办?
pub mod a {
pub const I: i32 = 3;
fn semisecret(x: i32) -> i32 {
use self::b::c::J;
x + J
}
pub fn bar(z: i32) -> i32 {
semisecret(I) * z
}
pub fn foo(y: i32) -> i32 {
semisecret(I) + y
}
mod b {
pub(in crate::a) mod c {
pub(in crate::a) const J: i32 = 4;
}
}
}
通过 pub(in crate::a) 的方式,我们指定了模块 c 和常量 J 的可见范围都只是 a 模块中,a 之外的模块是完全访问不到它们的。
1.4.7.1 限制可见性语法
pub(crate) 或 pub(in crate::a) 就是限制可见性语法,前者是限制在整个包内可见,后者是通过绝对路径,限制在包内的某个模块内可见,总结一下:
pub意味着可见性无任何限制pub(crate)表示在当前包可见pub(self)在当前模块可见pub(super)在父模块可见pub(in <path>)表示在某个路径代表的模块中可见,其中path必须是父模块或者祖先模块
1.4.7.2 一个综合例子
// 一个名为 `my_mod` 的模块
mod my_mod {
// 模块中的项默认具有私有的可见性
fn private_function() {
println!("called `my_mod::private_function()`");
}
// 使用 `pub` 修饰语来改变默认可见性。
pub fn function() {
println!("called `my_mod::function()`");
}
// 在同一模块中,项可以访问其它项,即使它是私有的。
pub fn indirect_access() {
print!("called `my_mod::indirect_access()`, that\n> ");
private_function();
}
// 模块也可以嵌套
pub mod nested {
pub fn function() {
println!("called `my_mod::nested::function()`");
}
#[allow(dead_code)]
fn private_function() {
println!("called `my_mod::nested::private_function()`");
}
// 使用 `pub(in path)` 语法定义的函数只在给定的路径中可见。
// `path` 必须是父模块(parent module)或祖先模块(ancestor module)
pub(in crate::my_mod) fn public_function_in_my_mod() {
print!("called `my_mod::nested::public_function_in_my_mod()`, that\n > ");
public_function_in_nested()
}
// 使用 `pub(self)` 语法定义的函数则只在当前模块中可见。
pub(self) fn public_function_in_nested() {
println!("called `my_mod::nested::public_function_in_nested");
}
// 使用 `pub(super)` 语法定义的函数只在父模块中可见。
pub(super) fn public_function_in_super_mod() {
println!("called my_mod::nested::public_function_in_super_mod");
}
}
pub fn call_public_function_in_my_mod() {
print!("called `my_mod::call_public_funcion_in_my_mod()`, that\n> ");
nested::public_function_in_my_mod();
print!("> ");
nested::public_function_in_super_mod();
}
// `pub(crate)` 使得函数只在当前包中可见
pub(crate) fn public_function_in_crate() {
println!("called `my_mod::public_function_in_crate()");
}
// 嵌套模块的可见性遵循相同的规则
mod private_nested {
#[allow(dead_code)]
pub fn function() {
println!("called `my_mod::private_nested::function()`");
}
}
}
fn function() {
println!("called `function()`");
}
fn main() {
// 模块机制消除了相同名字的项之间的歧义。
function();
my_mod::function();
// 公有项,包括嵌套模块内的,都可以在父模块外部访问。
my_mod::indirect_access();
my_mod::nested::function();
my_mod::call_public_function_in_my_mod();
// pub(crate) 项可以在同一个 crate 中的任何地方访问
my_mod::public_function_in_crate();
// pub(in path) 项只能在指定的模块中访问
// 报错!函数 `public_function_in_my_mod` 是私有的
// my_mod::nested::public_function_in_my_mod();
// 试一试 ^ 取消该行的注释
// 模块的私有项不能直接访问,即便它是嵌套在公有模块内部的
// 报错!`private_function` 是私有的
// my_mod::private_function();
// 试一试 ^ 取消此行注释
// 报错!`private_function` 是私有的
// my_mod::nested::private_function();
// 试一试 ^ 取消此行的注释
// 报错! `private_nested` 是私有的
// my_mod::private_nested::function();
// 试一试 ^ 取消此行的注释
}
二、目录层级实战
2.1 单文件拆分为 services, clients, utils 等多个 mod
main.rs 调用 service 和 util, service 调用 client, client 调用 util, 应该怎么实现呢?
实现方式如下:每个 services 模块中的函数都能够通过 crate::utils 和 crate::clients 调用 utils 和 clients 模块中的函数。main.rs 也相应地调用 services 模块中的函数。
src/
|-- main.rs
|-- clients/
| |-- mod.rs
|-- utils/
| |-- mod.rs
|-- services/
| |-- mod.rs
main.rs
mod services;
mod utils;
mod clients;
use clap::Parser;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
let arg = services::Arg::parse();
services::f1().await?;
Ok(())
}
clients/mod.rs
use serde::Serialize;
use reqwest::StatusCode;
pub async fn http_post<T: Serialize>(addr: String, body: T) -> Result<(), reqwest::Error> {
// ... 函数内容保持不变
}
utils/mod.rs
pub fn parse_str_to_timestamp(date_string: &str) -> Result<i64, chrono::ParseError> {
// ... 函数内容保持不变
}
service/mod.rs: 关键是 use ceate::clients 可以从 root crate 访问绝对路径
use crate::clients;
use crate::utils;
#[derive(Parser, Debug, Clone)]
pub struct Arg {
// ... 结构体内容保持不变
}
pub async fn f1(arg: Arg) -> Result<(), sqlx::Error> {
clients.a();
utils.b();
// ... 函数内容保持不变,确保调用 utils 和 clients 的函数
}
pub async fn f2(arg: Arg) -> Result<(), sqlx::Error> {
// ... 函数内容保持不变,确保调用 utils 和 clients 的函数
}