如有错误,恳请指出。
文章目录
paper:《Vehicle Detection from 3D Lidar Using Fully Convolutional Network》
对于64线激光雷达全范围扫描出来的点云进行特征图的构建。对于具体的点(xyz坐标),其在水平方向上可以通过θ=arctan(y/x)来求出,其垂直方向上可以通过 φ = arcsin ( z / ( x 2 + y 2 + z 2 ) ) φ=\arcsin(z/(x^2+y^2+z^2)) φ=arcsin(z/(x2+y2+z2))求出。也就是说,全范围上点云可以看成是一个圆柱状坐标分布,通过其水平和垂直上的方向角确定其在一个二维特征平面(point map)上的具体位置。其位置所在值有其深度信息( d = s q r t ( x 2 + y 2 ) d=sqrt(x^2+y^2) d=sqrt(x2+y2))与高度信息z来表示。也就是说,二维特征图point map上的每个位置对于着每个点在柱坐标上的位置,其channels为2,有深度信息d和高度信息z填充。如果点在某个位置重合,则取较近点位置,一般来说填充的两个chnnel值不会为0。
获得点云场景的二维特征后,就可以使用卷积神经网络来提取特征处理,其结构图如下所示。通过卷积核(4x2)下采样提取全局特征再进行上采样(4x2)与相同尺寸的特征图进行拼接,这样可以有效提高小目标检测率(这里VeloFCN没有说明具体的维度信息),最后再进行一个上采样分别为分类和回归构建与原尺寸(point map)一致的特征图,分别进行分类任务和回归任务。由于这里的具体场景应用是基于检测车辆,所以objectness map的通道数为2;而VeloFCN采取的是八个角点回归,所以对于着24个输出vector,既bounding box map的通道数为24;基于这两个feature map与像素点进行逐点的损失计算和预测。
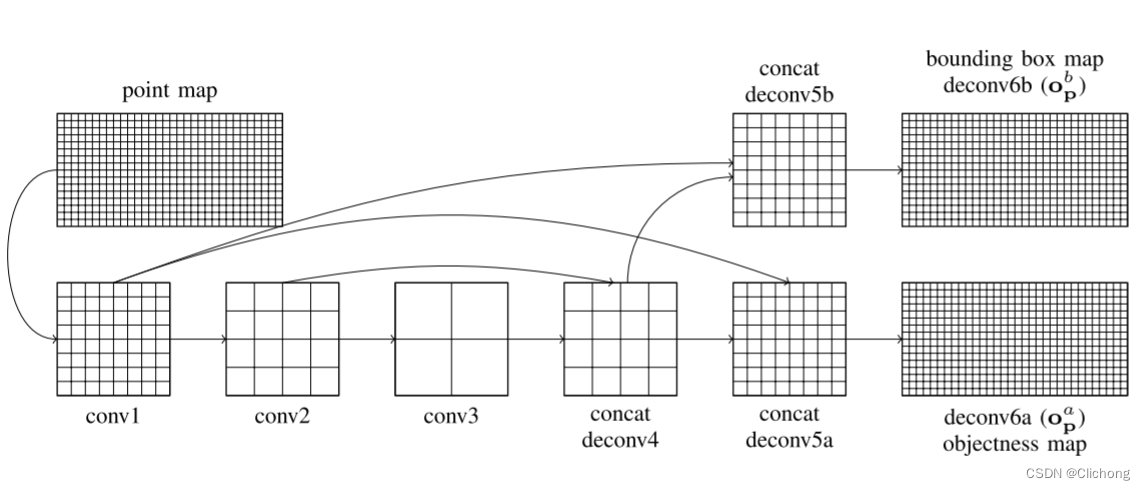
此外,在具体回归标注框过程中,对每个点云需要预测的ground truth的某个角点是:cp’=R(cp-p),其中p表示当前所在点,cp是标注框角点,cp’表示更改的标注框角点。这样在bounding box map上每个点特征需要预测的vector就是:bp’=(cp’1, cp’2, …, cp’8),利用这样的预测编码方式可以有效的减小3D标注框在预测时的搜索范围(这里感觉paper里面写得不太清晰,理解有误的话请指正一下)。
在训练过程中,VeloFCN还利用到了一些常见的训练策略,比如正负样本不平衡(对样本的代价损失进行重加权,即对正样本的权重大,负样本的权重小)以及扫描点远近不平衡(考虑正样本的平均扫描点数和样本本身扫描点数,当正样本的扫描点数大于平均扫描点数时,说明样本离激光雷达较近,损失函数权重较小;反之,则较大,以增强对远处目标的检测能力)。最后就是回归损失与分类损失的叠加,而这种直接预测角点的损失构造方式,感觉精度不会太高,但可以直接投影回去点云的坐标系中进行推理判断。既在推理阶段,可以直接将预测的编码形式进行反变换获取到实际点云坐标中的边界框中,利用非极大值抑制处理,筛选出置信度最高的目标框作为最后的检测结果。
![LeetCode[105]从前序与中序遍历序列构造二叉树](https://img-blog.csdnimg.cn/2cc76c2418674ff88fe5e6eec1966e61.png)



![[附源码]Python计算机毕业设计jspm计算机学院党员积分管理系统](https://img-blog.csdnimg.cn/9f0a1c15c3534d3e9ba0b0c6e9c07f0b.png)
![[附源码]java毕业设计柠檬电动车租赁系统](https://img-blog.csdnimg.cn/afe6f10e98eb4cc1964a16a52a08e940.png)