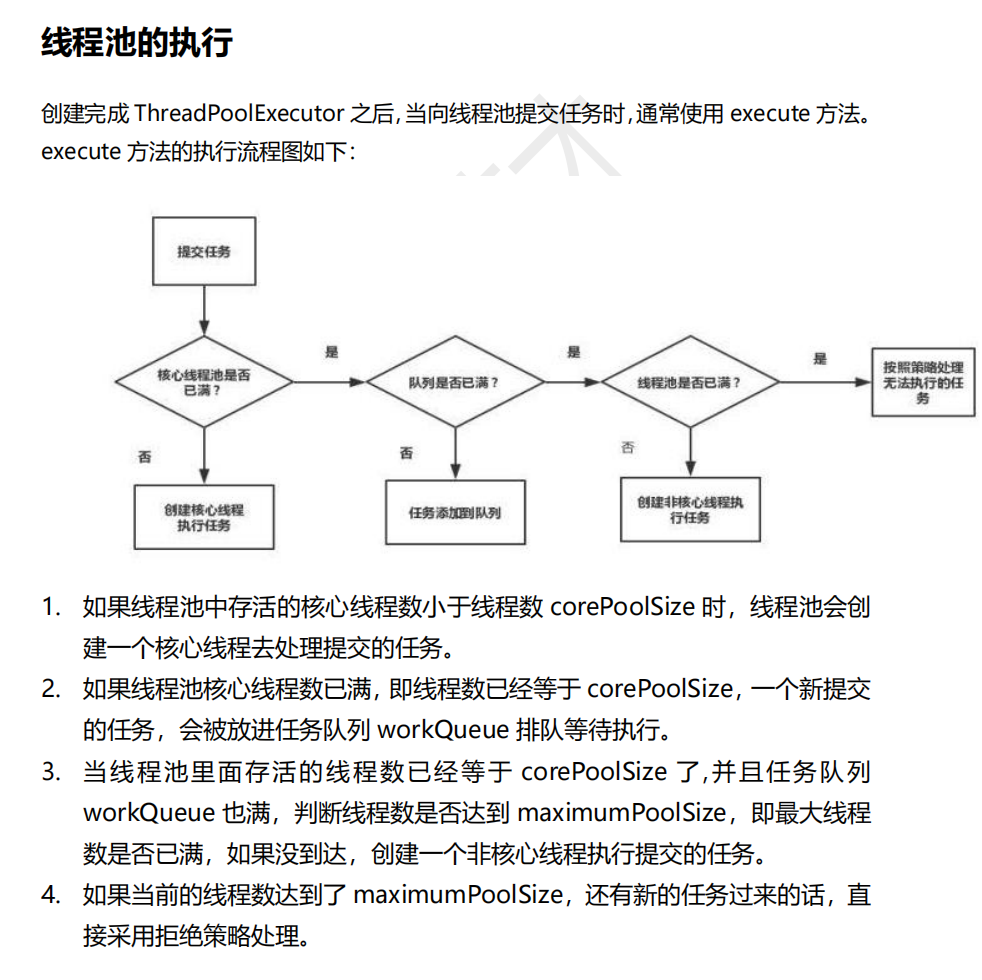
目录
- 聚合函数
- COUNT()函数的多种用法
- COUNT(*)
- COUNT(主键)
- COUNT(1)
- COUNT(常量)
- COUNT(非主键)
- COUNT(distinct(字段))
- COUNT()函数小结
- 字符函数
- length(str)函数:获取参数值的字节个数
- concat(str1,str2,...)函数:字符串拼接
- upper(str)、lower(str)函数:大小写转换
- substr(str,start,len)函数:截取字符串
- substring_index(str,delim,count)
- instr(str,要查找的子串)函数
- trim(str)函数
- lpad(str,len,填充字符)、rpad(str,len,填充字符)函数
- replace(str,子串,另一个字符串)函数
- concat_ws(separator,str1,str2,…)
- elt(n,str1,str2,str3,…)
- insert(str,pos,len,newstr)
- reverse(str)翻转字符串
- 数学函数
- round(x,保留位数)函数
- ceil(x)函数:向上取整
- floor(x)函数:向下取整
- truncate(x,D)函数
- mod(被除数,除数)函数
- pow(x,D)函数
- 绝对值函数:ABS()
- 圆周率函数:PI()
- 获取随机数:RAND()
- 时间/日期函数
- now()函数
- curdate()函数
- curtime()函数
- 获取日期和时间中的年、月、日、时、分、秒
- weekofyear()函数:获取当前时刻所属周数
- quarter()函数:获取当前时刻所属的季度
- str_to_date()函数:字符串转日期
- date_format()函数:日期转字符串
- date_add(日期,interval num 时间)函数
- last_day()函数:提取某个月最后一天的日期
- datediff(end_date,start_date)函数:计算两个时间相差的天数
- timestampdiff(unit,start_date,end_date)函数: 计算两个时间返回的年/月/天数;
- ADDDATE(d,n)
- ADDTIME(t,n)
- DATE_SUB(date,INTERVAL expr type)
- DAYNAME(d):返回日期 d 是星期几,如Monday,Tuesday
- DAYOFMONTH(d)、DAYOFWEEK(d)等
- NULLIF(expr1, expr2)
- 流程操作函数
- if(expr,v1,v2)函数
- ifnull()函数
- case…when函数的三种用法
- 1.等值判断:可以实现多条件的查询值赛选;
- 2.区间判断:类似于python中if-elif-else的效果;
- case … when和聚合函数联用
- 系统信息函数
- version()函数:查看MySQL系统版本信息号
- connection_id()函数:查看当前登入用户的连接次数数
- processlist:查看用户的连接信息
- database(),schema()函数
- user(),current_user(),system_user()函数
- 其它函数
- md5(str)函数 加密函数;
- encode(str,pswd_str)、decode(加密的字符串,pswd_str)函数
- uuid():生成唯一序列UUID
聚合函数
聚合函数通常会跟分组查询结合使用
- SUM(字段):求和
- AVG(字段):求平均值
- MIN(字段):求最小值
- MAX(字段):求最大值
- COUNT(*):统计符合条件的记录总条数
COUNT()函数的多种用法
count(1)、count(*)、count(常量)、count(主键)、count(非主键)、count(distinct(字段)) 等多个函数
COUNT(*)
-
对于 MyISAM 引擎,会把表的总行数存在了磁盘上(存放在 information_schema 库中的 PARTITIONS 表中),在不加 where 条件时,执行 count(*) 时会直接返回这个总数,因此效率很高,但是在加 where 限定语句的时候 MySQL 需要对全表进行检索从而得出 count 的总数。
-
而 InnoDB 引擎并没有像 MyISAM 那样把表的总行数存储在磁盘,而是在执行 count(* )时,在不加 where 限定语句时,MySQL Server 层需要把数据从引擎里面读出来,然后逐行累加得出总数;如果加了 where 限定语句,需要根据 where 条件从引擎里面筛选出数据,然后累加得出总数。
COUNT(主键)
-
对于 MyISAM 引擎,不加 where 条件时,直接返回的表中保存的数据总行数值;加 where 条件时,需要走主键索引筛选出值后再统计;
-
对于 InnoDB 引擎,不加 where 条件时,count(id) 和 count(*) 的处理方式一样,MySQL优化器会选择最小树索引age 索引进行遍历统计;加 where 条件时,需要走主键索引筛选出值后再统计
COUNT(1)
对于 MyISAM 引擎,count(1) 和 count(*) 的 逻辑是一样的。
对于 InnoDB 引擎,按照官方文档,count(1) 和 count(*) 的处理方式一样,无性能差别
COUNT(常量)
count(常量)的执行逻辑和 count(1) 的逻辑是一样的,比如:count(5)、count(‘abc’)、count(‘.’)
COUNT(非主键)
只统计非主键字段值不为NULL的总数,不管在 InnoDB 引擎 还是在 MyISAM引擎中执行,非主键这个字段是否添加了索引直接影响了count() 统计扫描表的行数,从而影响统计的性能
COUNT(distinct(字段))
count(distinct(字段)) 其实是 count(字段) + distinct 的结果集,统计字段不为NULL,并且在字段值重复的情况下只统计一次
COUNT()函数小结
- count(expr)函数的参数 expr可以是任意的表达式,该函数用于统计在符合搜索条件的记录总数;
- count(expr)函数执行效率从低到高排序为:count(非主键字段) < count(主键) < count(1) ≈ count(*) ;
- 对于 count(1) 和 count() ,效率相当,建议尽量使用 count(),因为 MySQL 优化器会选择最小的索引树进行统计,把优化的问题交给 MySQL 优化器去解决就可以了;
- count(列字段) 只统计不为 NULL 的总行数,比如,count(name),当name字段值为NUll时,就不会被count;而其他的count,它返回检索到的行数,无论它们是否包含 NULL值;
- count(NULL) 总是返回 0;
- count(expr) 聚合函数在统计时,带与不带 where 条件实现原理具有差异性,性能也存在差异性;
- 在生产中,对于InnoDB 引擎,如果对数据总量不要求特别精确,可以使用 “show table status” 方式获取总行数;
- 因为 MySQL一直在快速发展,所以不同的版本实现可能存在差异,所以在研究技术的时候一定要注意版本差异;
- 在生产环境中,应尽量避免 count(expr)这种耗时操作,如果一定要进行统计,可以根据统计数据的精确度来区分采用什么方式统计;也可以在专业 DBA 的指导下进行,或者通过 explain 执行计划宏观看下count(expr) 操作会扫描多少数据行,如果对性能影响比较大,可以选择在离线库或者只读库中进行
字符函数
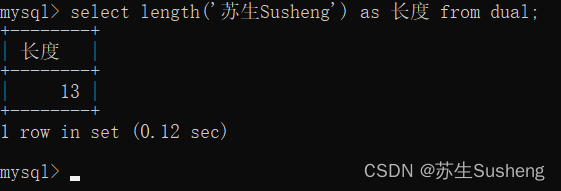
length(str)函数:获取参数值的字节个数
对于utf-8字符集来说,一个英文占1个字节;一个中文占3个字节;
对于gbk字符集来说,一个英文占1个字节;一个中文占2个字节;
select length('苏生Susheng') as 长度 from dual;
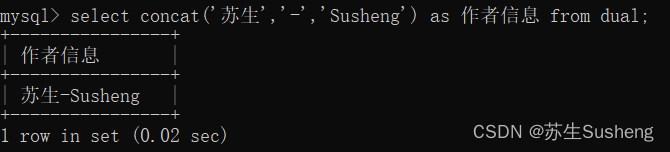
concat(str1,str2,…)函数:字符串拼接
通过输入的参数str1、str2等,将他们拼接成一个字符串。
select concat('苏生','-','Susheng') as 作者信息 from dual;
upper(str)、lower(str)函数:大小写转换
upper(str):将字符中的所有字母变为大写
lower(str)将字符中的所有字母变成小写
lcase(str)是 lower()的同义词,用法一样。
select upper('susheng') as 大写, lower('SUSHENG') as 小写 from dual;

substr(str,start,len)函数:截取字符串
str为输入字符串,从start位置开始截取字符串,len表示要截取的长度; 没有指定len长度:表示从start开始起,截取到字符串末尾。指定了len长度:表示从start开始起,截取len个长度。
mid(str,pos,len)是 substring(str,pos,len)的同义词,截取字符串功能,用法一样
select substr('我是CSDN的苏生,低调学习',8,2) as 截取输出 from dual;
 注:8是开始位置,此处起始位置,2是开始到结束位置的长度,并不是索引的结束位置
注:8是开始位置,此处起始位置,2是开始到结束位置的长度,并不是索引的结束位置
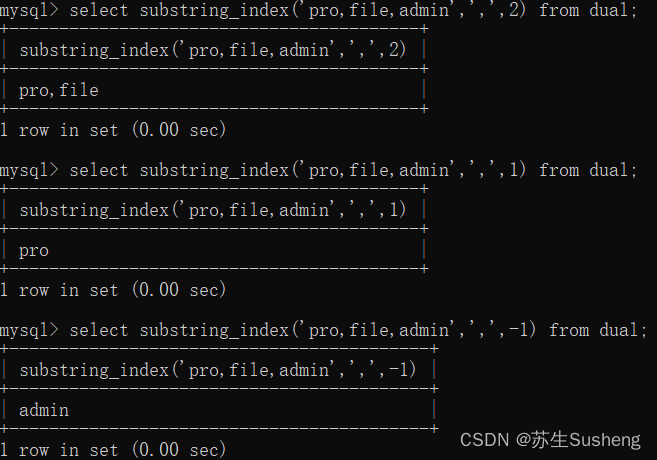
substring_index(str,delim,count)
在定界符 delim 以及count 出现前,从字符串str返回自字符串。若count为正值,则返回最终定界符(从左边开始)左边的一切内容。若count为负值,则返回定界符(从右边开始)右边的一切内容。
select substring_index('pro,file,admin',',',-1) from dual;
instr(str,要查找的子串)函数
- 返回子串第一次出现的索引,如果找不到,返回0;
- 当查找的子串存在于字符串中:返回该子串在字符串中【第一次】出现的索引。
- 当查找的子串不在字符串中:返回0
select instr('我是CSDN的苏生,低调学习','苏生') as 第一次出现 from dual;
select instr('我是CSDN的苏生,低调学习','书生') as 第一次出现 from dual;


trim(str)函数
去掉字符串前后的空格; 该函数只能去掉字符串前后的空格,不能去掉字符串中间的空格。
select trim(' 我是CSDN的苏生 低调学习 ') as 空格去除 from dual;

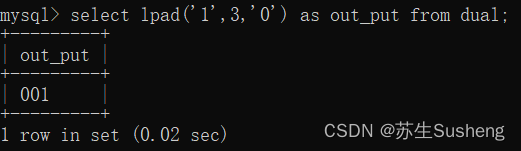
lpad(str,len,填充字符)、rpad(str,len,填充字符)函数
lpad(左填充):用指定的字符,实现对字符串左填充指定长度
rpad(右填充):用指定的字符,实现对字符串右填充指定长度
select lpad('1',3,'0') as out_put from dual;
select rpad('1.0',5,'0') as out_put from dual;
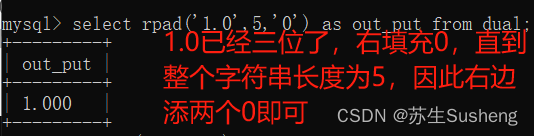 注:这里的填充len指的是用填充字符填充后的总长度,也就是若你的len选择5你的字符串含有位置为4则只能填充一个字符,也就是填充字符的第一个字符
注:这里的填充len指的是用填充字符填充后的总长度,也就是若你的len选择5你的字符串含有位置为4则只能填充一个字符,也就是填充字符的第一个字符
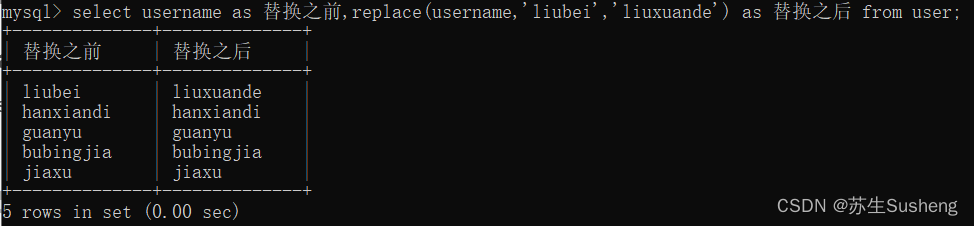
replace(str,子串,另一个字符串)函数
将字符串str中的字串,替换为另一个字符串
select username as 替换之前,replace(username,'liubei','liuxuande') as 替换之后 from user;
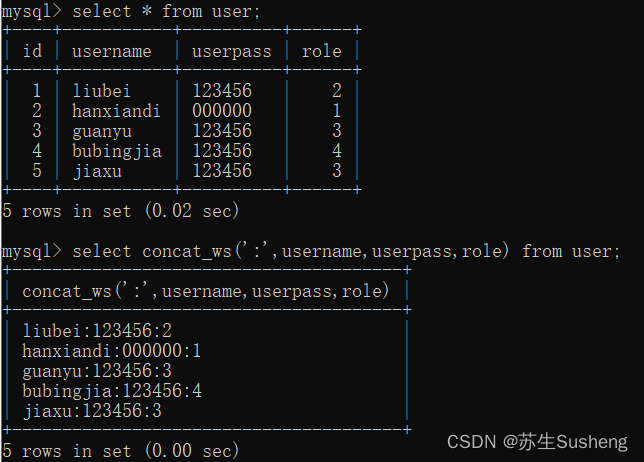
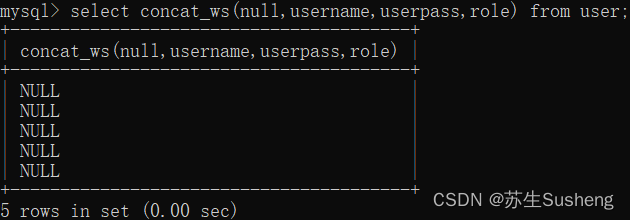
concat_ws(separator,str1,str2,…)
是concat()的特殊形式。第一个参数是其它参数的分隔符。
分隔符的位置放在要连接的两个字符串之间。
分隔符可以是一个字符串,也可以是其它参数。
如果分隔符为 null,则结果为 null。
函数会忽略任何分隔符参数后的 null 值。
select concat_ws(':',username,userpass,role) from user;
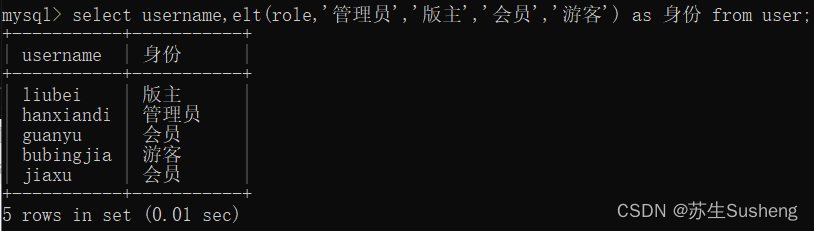
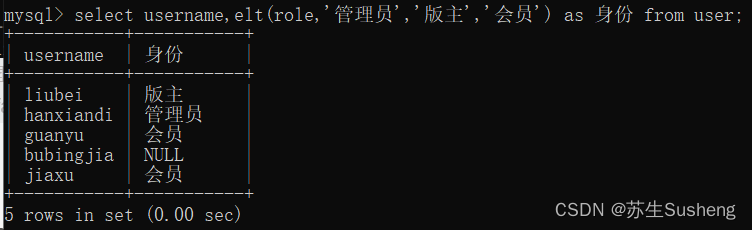
elt(n,str1,str2,str3,…)
若n=1,则返回值为str1若n=2,则返回值为 str2 ,以此类推。若n小于1或大于参数的数目,则返回值为 null 。
select username,elt(role,'管理员','版主','会员','游客') as 身份 from user;
select username,elt(role,'管理员','版主','会员','游客') as 身份 from user;
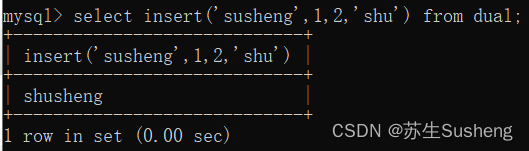
insert(str,pos,len,newstr)
- 返回字符串 str, 其子字符串起始于 pos 位置和长期被字符串 newstr取代的len 字符。
- 如果pos 超过字符串长度,则返回值为原始字符串。假如len的长度大于其它字符串的长度,则从位置pos开始替换。若任何一个参数为null,则返回值为null。
select insert('susheng',1,2,'shu') from dual;
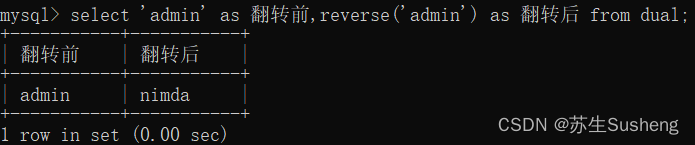
reverse(str)翻转字符串
select 'admin' as 翻转前,reverse('admin') as 翻转后 from dual;
数学函数
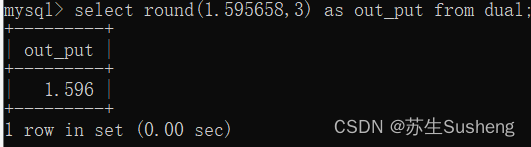
round(x,保留位数)函数
四舍五入; 当对正数进行四舍五入:按照正常的计算方式,四舍五入即可。当对负数进行四舍五入:先把符号丢到一边,对去掉负号后的正数进行四舍五入,完成以后,再把这个负号,补上即可。
select round(1.595658,3) as out_put from dual;
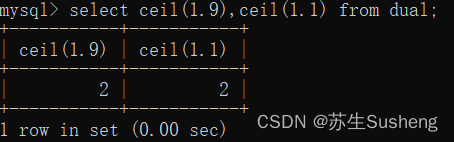
ceil(x)函数:向上取整
向上取整,返回>=该参数的最小整数。求的是大于等于这个数字的最小整数
select ceil(1.9),ceil(1.1) from dual;
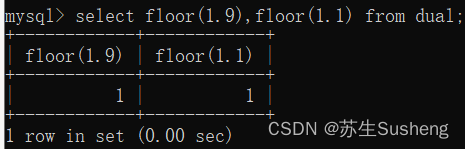
floor(x)函数:向下取整
向下取整,返回<=该参数的最大整数,求的是小于等于这个数字的最大整数。
select floor(1.9),floor(1.1) from dual;
truncate(x,D)函数
-
此函数叫截断函数,顾名思义就是就是截取不要的部分,然后删掉(断掉)它。在小数点的D位置处,截取数字直接删去数字,若在左边就是位置取整不使用任何法则。
-
把truncate当作小数点(.)x是要截取的数字。D为正数时是小数点的右侧部分,D为0时则不要小数部分,D为负数时是小数点左边部分,具体使用看例子演示。
select truncate(314159.2673525,5) as 截取之后 from dual;
select truncate(314159.2673525,0) as 截取之后 from dual;
select truncate(314159.2673525,-4) as 截取之后 from dual;
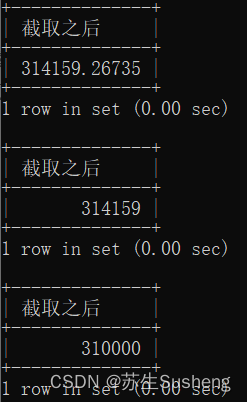
mod(被除数,除数)函数
取余; 当被除数为正数,结果就是正数。当被除数为负数,结果就是负数。
select mod(10,3) as out_put from dual;
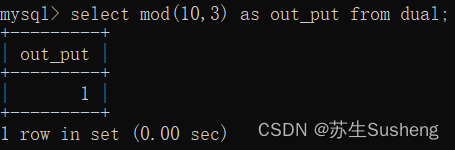
pow(x,D)函数
此函数是用于计算指数函数,x为底,D为指数
select pow(5,2) as 平方运算 from dual;
select pow(5,2) as 平方运算 from dual;
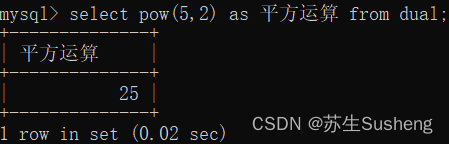
绝对值函数:ABS()
select abs(-99) from dual;
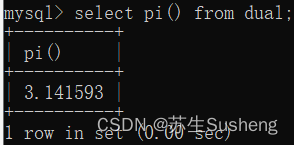
圆周率函数:PI()
获取随机数:RAND()
每次调用都会得到一个0-1之间的浮点数
select RAND(),RAND(),RAND(),RAND() from dual;

时间/日期函数
- DATE_FORMAT(“20000101”, ‘%Y-%m-%d’) – 2020-01-01
- DATE_FORMAT(“2000-01-01”, ‘%Y-%m-%d’) – 2020-01-01
- DATE_FORMAT(‘2000-05-07 05:06:07’, ‘%H:%i:%s’) – 05:06:07 (24小时制)
- DATE_FORMAT(‘2000-05-07 05:06:07’, ‘%h:%i:%s’) – 05:06:07 (12小时制)
- DATE_FORMAT(‘2000-05-07 05:06:07’, ‘%Y-%m-%d %H:%i:%s’) – 2000-05-07 05:06:07
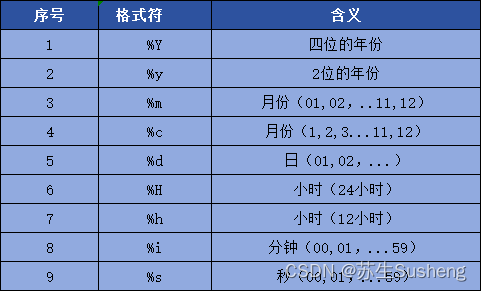
now()函数
select now() from dual;
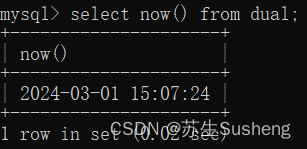
curdate()函数
只返回系统当前的日期,不包含时间
select curdate() from dual;
curtime()函数
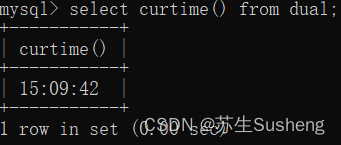
只返回当前的时间,不包含日期
select curtime() from dual;
获取日期和时间中的年、月、日、时、分、秒
- 获取年份:year()
- 获取月份:month()
- 获取日:day()
- 获取小时:hour()
- 获取分钟:minute()
- 获取秒数:second()
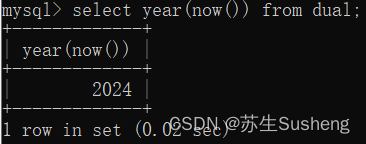
select year(now()) from dual;
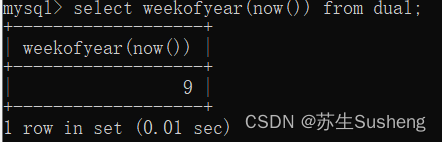
weekofyear()函数:获取当前时刻所属周数
select weekofyear(now()) from dual;
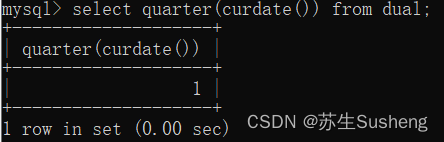
quarter()函数:获取当前时刻所属的季度
select quarter(curdate()) from dual;
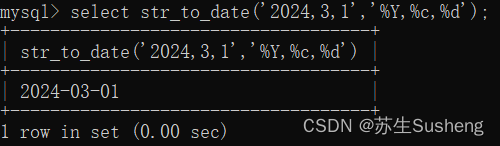
str_to_date()函数:字符串转日期
select str_to_date('2024,3,1','%Y,%c,%d');
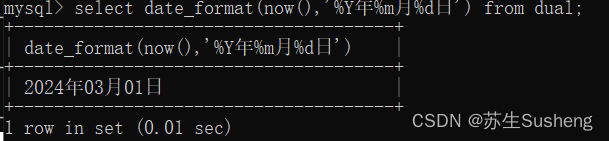
date_format()函数:日期转字符串
select date_format(now(),'%Y年%m月%d日') from dual;
date_add(日期,interval num 时间)函数
向前、向后偏移日期和时间,正号为向后,负号为向前,除此之外还有hour(小时),minute(分钟),second(秒)
select
curdate() as '当前时间',
date_add(curdate(),interval 1 year) as '一年后',
date_add(curdate(),interval 1 month) as '一个月后',
date_add(curdate(),interval 1 day) as '一天后'
from dual;

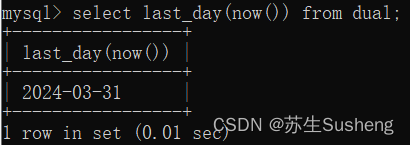
last_day()函数:提取某个月最后一天的日期
select last_day(now()) from dual;
datediff(end_date,start_date)函数:计算两个时间相差的天数
select datediff(curdate(),'2000-1-1') from dual;
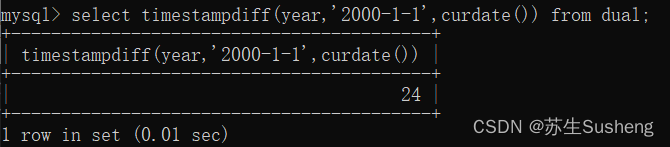
timestampdiff(unit,start_date,end_date)函数: 计算两个时间返回的年/月/天数;
unit参数是确定(start_date,end_date)结果的单位,表示为整数,以下是有效单位:
year:年份、month:月份、day:天、hour:小时、minute 分钟、second:秒、microsecond:微秒、week:周数、quarter:季度
select timestampdiff(year,'2000-1-1',curdate()) from dual;
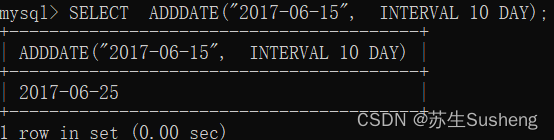
ADDDATE(d,n)
计算起始日期 d 加上 n 天的日期
SELECT ADDDATE("2017-06-15", INTERVAL 10 DAY);
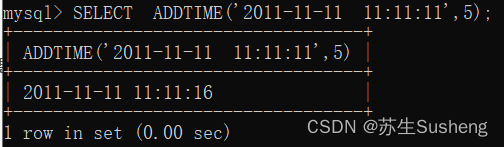
ADDTIME(t,n)
n 是一个时间表达式,时间 t 加上时间表达式 n
# 加5秒
SELECT ADDTIME('2011-11-11 11:11:11',5);
DATE_SUB(date,INTERVAL expr type)
函数从日期减去指定的时间间隔。
SELECT DATE_SUB('2024-3-1',INTERVAL 2 DAY) AS OrderPayDate FROM dual;

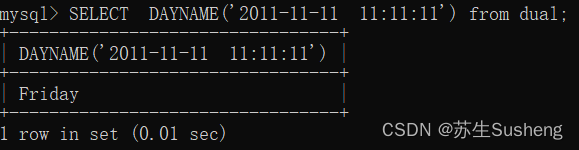
DAYNAME(d):返回日期 d 是星期几,如Monday,Tuesday
SELECT DAYNAME('2011-11-11 11:11:11') from dual;
DAYOFMONTH(d)、DAYOFWEEK(d)等
DAYOFMONTH(d):计算日期 d 是本月的第几天
DAYOFWEEK(d):日期 d 今天是星期几,1 星期日,2 星期一,以此类推
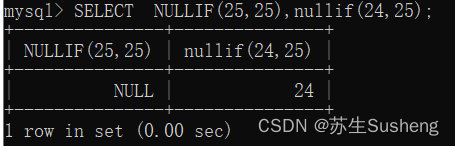
NULLIF(expr1, expr2)
比较两个字符串,如果字符串 expr1 与 expr2 相等返回 NULL,否则返回 expr1
SELECT NULLIF(25,25),nullif(24,25);
流程操作函数
if(expr,v1,v2)函数
实现if-else的效果,如果expr是true,返回v1。如果expr是false,返回v2
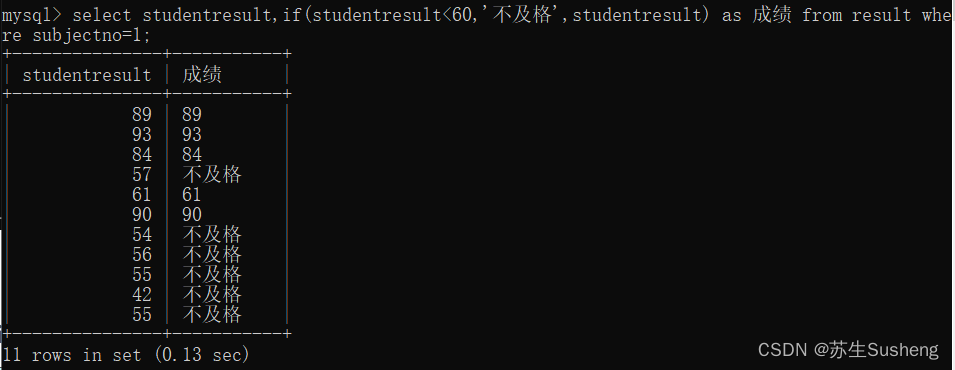
select studentresult,if(studentresult<60,'不及格',studentresult) as 成绩 from result where subjectno=1;
ifnull()函数
判断值是否为null,是null用指定值填充;如果v1不为NULL,返回v2。否则返回v1
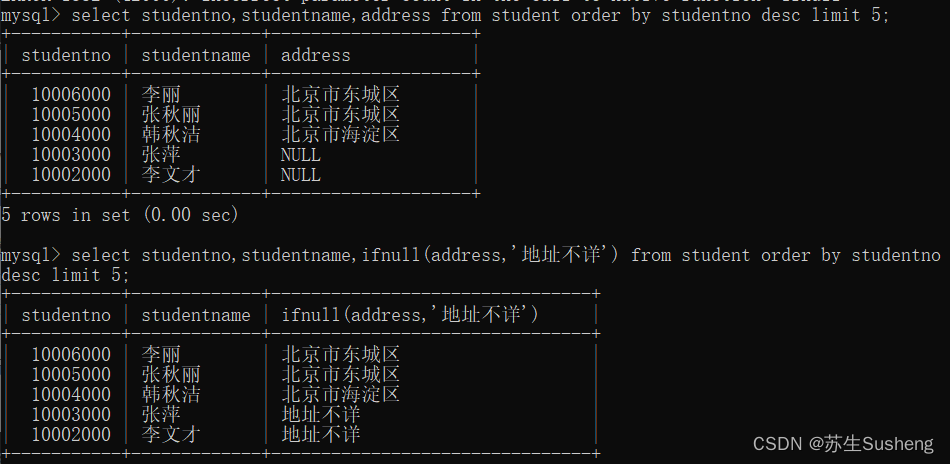
select studentno,studentname,ifnull(address,'地址不详') from student order by studentno desc limit 5;
case…when函数的三种用法
1.等值判断:可以实现多条件的查询值赛选;
case 要判断的字段或表达式
when 常量1 then 要显示的值1或语句1
when 常量2 then 要显示的值2或语句2
…
else 要显示的值n或语句n
end
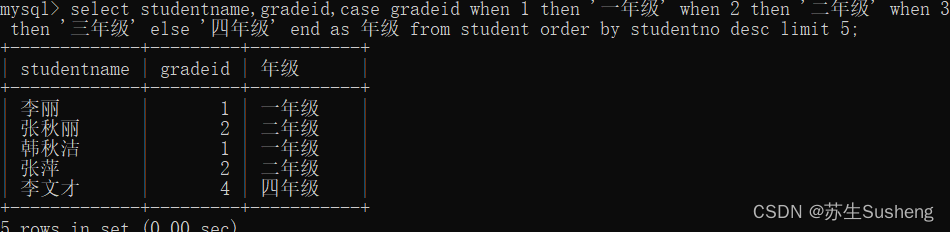
select studentname,gradeid,case gradeid when 1 then '一年级' when 2 then '二年级' when 3 then '三年级' else '四年级' end as 年级 from student order by studentno desc limit 5;
2.区间判断:类似于python中if-elif-else的效果;
case
when 条件1 then 要显示的值1或语句1
when 条件2 then 要显示的值2或语句2
…
else 要显示的值n或语句n
end
select studentresult ,case when studentresult <60 then '不及格' when studentresult >= 60 and studentresult < 80 then '及格' else '优秀' end as 档次 from result where subjectno = 1;

case … when和聚合函数联用
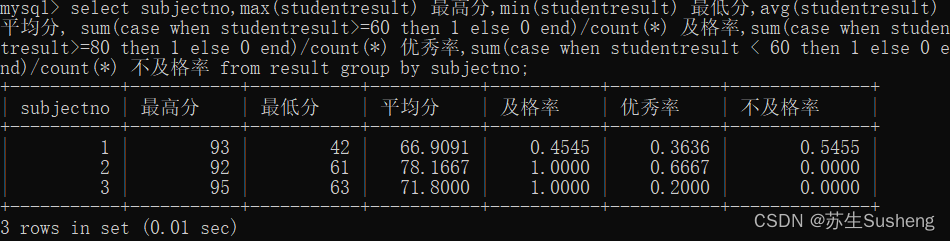
select
subjectno,
max(studentresult) 最高分,
min(studentresult) 最低分,
avg(studentresult) 平均分,
sum(case when studentresult>=60 then 1 else 0 end)/count(*) 及格率,
sum(case when studentresult>=80 then 1 else 0 end)/count(*) 优秀率,
sum(case when studentresult < 60 then 1 else 0 end)/count(*) 不及格率
from result group by subjectno;
系统信息函数
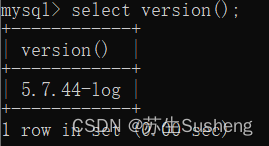
version()函数:查看MySQL系统版本信息号
select version() from dual;
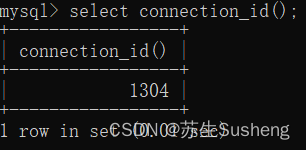
connection_id()函数:查看当前登入用户的连接次数数
直接调用CONNECTION_ID()函数–不需任何参数–就可以看到当下连接MySQL服务器的连接次数,不同时间段该函数返回值可能是不一样的
select connection_id();
processlist:查看用户的连接信息
show processlist;

- Id列:登录MySQL的用户标识,是系统自动分配的CONNECTION ID;
- User列:显示当前的“用户名”;
- Host列:显示执行这个语句的IP,用来追踪出现问题语句的用户;
- db列:显示这个进程目前连接的是哪个数据库;
- Command列:显示当前连接执行的命令,一般是休眠(Sleep)、查询(Query)、连接(Connect);
- Time列:显示这个状态持续的时间,单位是秒;
- State列:显示使用当前连接的SQL语句的状态,包含有:Copying to tmptable、Sorting result、Sending data等状态;
- Info列:显示当前SQL的内容,如果语句过长可能无法显示完全。
database(),schema()函数
查看当前使用的数据库
select database(),schema();

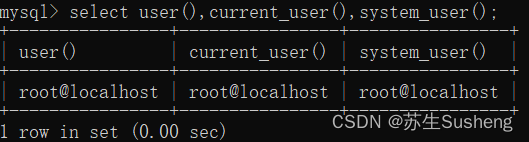
user(),current_user(),system_user()函数
获取当前用户
select user(),current_user(),system_user();
其它函数
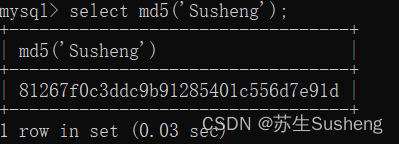
md5(str)函数 加密函数;
- 参数为字符串,该函数为字符串算出一个MD5 128比特校验和
- 返回值以32位16进制数字的二进制字符串形式返回
- str为NULL,返回NULL
- select md5(‘Susheng’);
encode(str,pswd_str)、decode(加密的字符串,pswd_str)函数
加密:encode(被加密的密码,密码);
解密:decode(encode(被加密的密码,密码),密码); //也可以用上面返回的二进制字符串
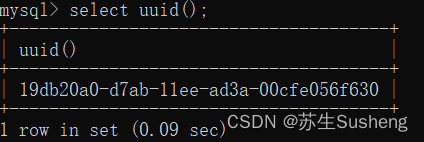
uuid():生成唯一序列UUID
select uuid();