文章目录
- 🐒个人主页
- 🏅JavaEE系列专栏
- 📖前言:
- 🎀多线程的优点、缺点
- 🐕并发编程的核心问题 :不可见性、乱序性、非原子性
- 🪀不可见性
- 🪀乱序性
- 🪀非原子性
- 🧸JMM(java内存模型)
- 🏅volatile关键字:保证可见性、禁止指令重排序
- 🐕CAS机制 (Conpare And Swap 比较并交换)
- 🐕CAS会产生ABA问题
- 🏨java中锁的分类
- 🪀乐观锁、悲观锁
- 🪀可重入锁
- 🪀读写锁 ReentrantReadwriteLock
- 🪀分段锁
- 🪀自旋锁
- 🪀共享锁、独占锁
- 🪀公平锁、非公平锁
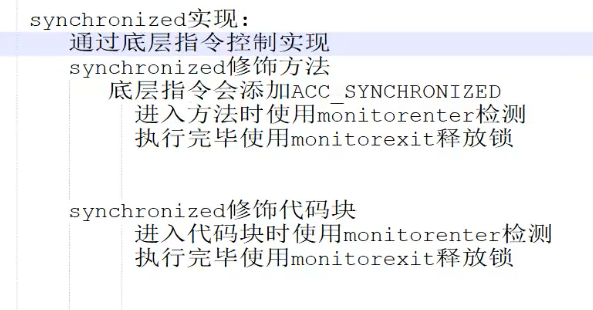
- 🪀针对synchronized锁的状态(底层monitorenter加锁、moniterexit释放锁)
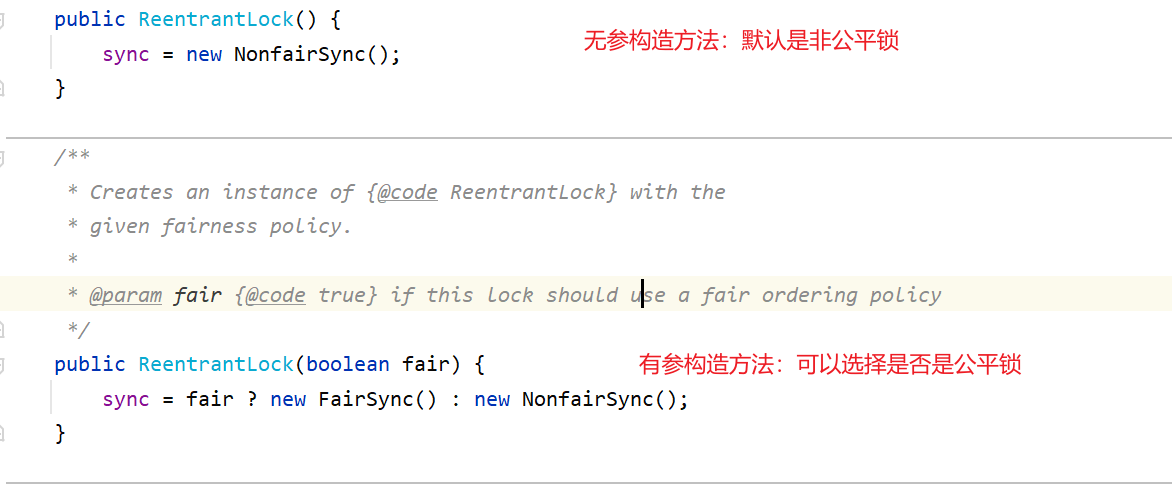
- 🪀ReentrantLock实现
- 🏅AQS (AbstractQueuedSynchronizer,抽象同步队列 在JUC并发包下)
- 🪂集合可以引申过来:ConcurrentHashMap
- 🪂集合可以引申过来:CopyOnWriteArrayList
- 🦓辅助类CountDownLatch
- 🎀线程池
- 🐕为什么要使用线程池?
- 🐕你通常是怎么创建线程池的?为啥不使用其他的类Executors?
- 🏨TreadPoolExecutor构造方法的七个参数
- 🪂线程池拒绝策略handler
- 🪂execute()与submit()的区别
- 🪂关闭线程池shutdown、shutdownNow
- 🎀ThreadLocal 本地线程变量
- 🐕什么原因造成ThreadLocal内存泄漏问题?如何解决?
🐒个人主页
🏅JavaEE系列专栏
📖前言:
本篇博客主要总结面试中对线程知识的考察点
🎀多线程的优点、缺点
提高了程序的响应速度,可以多个线程各自完成自己的工作,以提高硬件设备的利用率。
缺点:可能会出现多个线程资源争夺问题,引发死锁。
🐕并发编程的核心问题 :不可见性、乱序性、非原子性
🪀不可见性
一个线程在自己的工作内存中对共享变量的修改,另外一个线程不能立即看到 。
🪀乱序性
为了优化性能,CPU有时候会改变程序中语句的先后顺序,但基本的程序逻辑不受影响。
🪀非原子性
线程切换带来的非原子性问题,A线程执行时,被切换到B线程执行,之后再A线程执行。 如果解决?加锁,如果只是++的话,JUC并发包下的原子类也可以。
🧸JMM(java内存模型)
java内存模型规定了所有的变量都存储在主内存中,每个线程还有自己的工作内存。线程先将主内存中的共享变量复制到自己的工作内存中去,在自己的工作内存中处理数据,再将处理好的结果写入主内存。
🏅volatile关键字:保证可见性、禁止指令重排序
一旦共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,
1.保证了一个线程修改了此变量,其他线程会立即可见(通过《缓存一致性协议》),保证可见性。
2.禁止指令重排序
3.但是volitile不能保证原子性
🐕CAS机制 (Conpare And Swap 比较并交换)
该算法采用自旋的思想,是一种轻量级锁机制。是(不加锁)乐观锁的实现。
线程先从主内存中获取共享变量复制到工作内存中作为预估值,再处理共享变量,得出结果。此时将线程中的预估值与主内存的值进行比较:
1.如果一样,证明没有其他线程干扰,将结果写入主内存。
2.如果不一样,重新获取预估值,重新进行计算结果,再次进行比较…
CAS缺陷:
由于CAS实现的是乐观锁,他会以自旋的方式不断的进行尝试,而不会像synchronized进行线程阻塞,当大量的线程自旋时,容易把CPU跑满。
原子类的实现是volatile +CAS机制。原子类适合在低并发的情况下使用。
🐕CAS会产生ABA问题
就是一个线程预估值为A,来一个线程将内存值改为B,再有一个线程将内存值又改为A。就不确定内存中的值是否其他线程进行干扰过了。
解决方案:
使用有版本号的原子类AtomicABA 根据版本号来解决问题
🏨java中锁的分类
🪀乐观锁、悲观锁
乐观锁: 它乐观认为对同一个数据的并发操作不会产生线程安全问题,不加锁,它会采用自选的方式,不断的尝试更新数据
悲观锁: 它悲观的认为对同一个数据的并发操作会产生线程安全问题,所以需要加锁进行干预
乐观锁适合“读多写少”的场景,悲观锁适合“读少写多”的场景
🪀可重入锁
就是一个加锁的方法可以调用进入另一个加锁的方法中去,两个方法可以共用同一把锁。可以在一定程度上避免死锁。
🪀读写锁 ReentrantReadwriteLock
可以实现读锁、写锁。读写可以使用一个锁实现。
特点:读读不互斥、读写互斥、写写互斥。
加读锁可以防止写,防止脏读。
🪀分段锁
1.8之后,分段锁是一种思想,减小锁的粒度, 将ConcurrentHashMap表每个区间的第一个节点当做锁对象,可以提高并发效率
🪀自旋锁
其实就是线程不断尝试获取锁的方式,不断的循环请求获取锁,直到抢到锁。会占用CPU资源。
例如:
原子类,需要改变主内存中的共享变量而不断尝试。
synchronized 加锁,其他线程不断获取锁,重复一定次数后会陷入阻塞。
🪀共享锁、独占锁
共享锁:多个线程共享一把锁,读写锁中的读锁,都是读操作时多个线程共享
独占锁:即排他锁,只允许一个线程使用该资源,写锁
🪀公平锁、非公平锁
公平锁:是指按照请求锁的顺序来分配锁,具有稳定获取锁的机会
非公平锁:不按照先来后到,谁抢到锁就是谁的。
对于synchronized是一种非公平锁。
而ReentrantLock默认是非公平锁,但是底层可以通过AQS机制来转化为公平锁
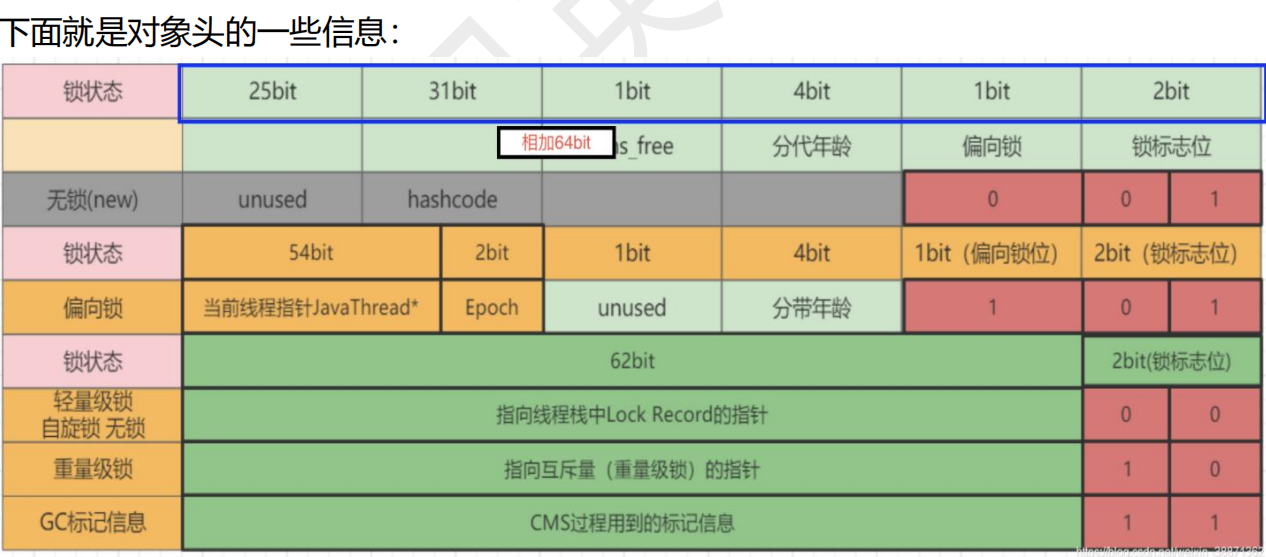
🪀针对synchronized锁的状态(底层monitorenter加锁、moniterexit释放锁)
锁的状态是根据对象头中的对象监视器来记录的,对象头Mark Word中记录对象的一些相关信息:hash值、分代年龄、锁的状态、偏向锁的线程id
无锁: 没有任何线程使用锁对象
偏向锁: 当前只有一个线程访问,那么锁对象会在对象头Mark Word中记录该线程id,下次自动获取锁,降低获取锁的难度。
轻量级锁: 当锁状态是偏向锁的时候,又有一个线程访问,此时锁的状态会升级成轻量级锁,其他线程会通过自旋的方式尝试获取锁,不会阻塞线程,提高性能。
重量级锁: 当锁的状态为轻量级锁时,线程自旋获取锁的次数达到一定次数时,锁的状态会升级成重量级锁。 会让自旋次数多的线程进入阻塞状态,以降低CPU的消耗
🪀ReentrantLock实现
。(ReentrantLock 中的内部抽象类sync继承了抽象同步队列AQS,里面定义了lock() 、unlock()方法)
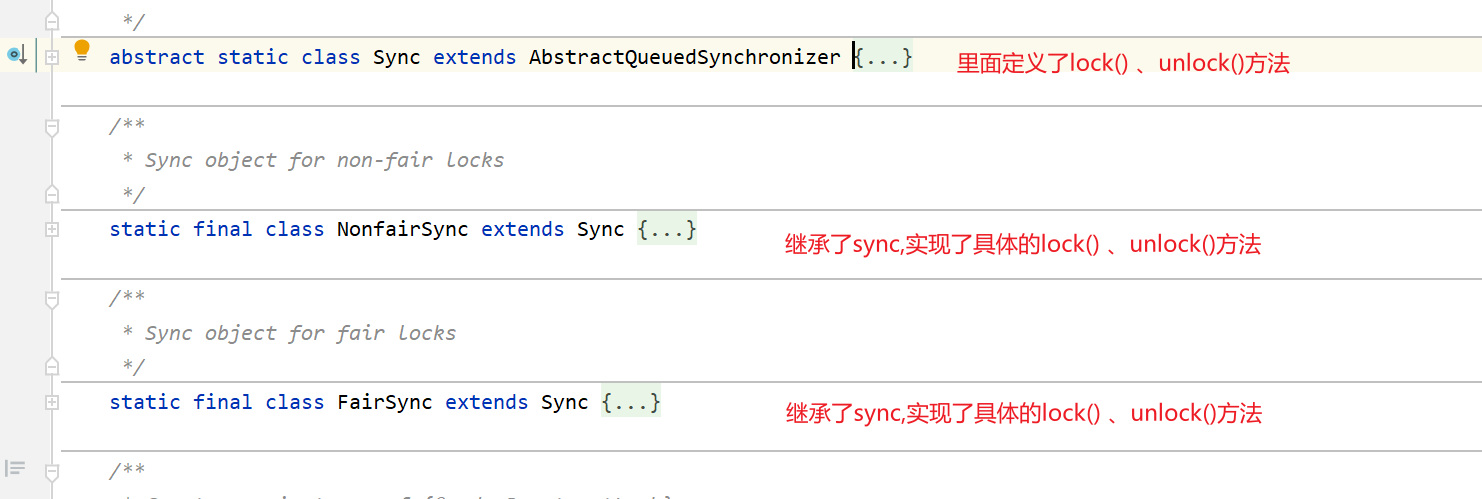
🏅AQS (AbstractQueuedSynchronizer,抽象同步队列 在JUC并发包下)
是一个底层同步的实现者,有很多的同步类都继承了它。(ReentrantLock 中的内部类sync继承了它)
AbstractQueuedSynchronizer中有一个volatile修饰的int 类型的变量记录锁的状态(线程是否访问)
AQS里面还有一个内部类Node (双向链表,里面存放线程)
AQS里面获取锁状态方法getState()、修改锁状态方法通过CAS机制进行状态的更新
🪂集合可以引申过来:ConcurrentHashMap
聊到hashMap k-v存储
双列集合,键不能重复,值可以重复。它只适合单线程使用,在多线程情况下会报“并发修改异常”。他的键是由一个哈希表+链表的数据结构实现的。哈希表的初始大小为
16 ,通过对象哈希值%(哈希表长度-1)或者(哈希表长度-1)& 对象哈希值 确定对象在哈希表中的存储位置。如果出现哈希冲突了,通过拉链法解决,形成链表。
当哈希表存储超过0.75时,会进行2倍扩容。当每个节点上链表长度阈值超过8并且哈希表长度>=64,链表将转化为红黑树。当链表长度阈值为6时,红黑树会再次退化成链表。
hashTable它是线程安全的,因为它在每个方法上都加了synchronized锁,哪怕是在读方法上同样也上锁。虽然很安全,但是每个方法只允许一个线程进入,并发访问效率就比较低,适合并发量低的情况下。
在JUC并发包下还有一个ConcurrentHashMap的类。它是线程安全的。它采用了 CAS机制 +synchronized来保证线程安全。它是给节点加锁,降低了锁的粒度。
🏅put()时,先用key计算节点在哈希表中的位置,
它会来判断当前位置上有没有节点(null),如果没有,就使用CAS机制尝试放入。
如果有,就使用第一个节点作为锁对象,用synchronized加锁。这样就可以降低锁的粒度,可以同时有多个线程同时进入put()方法中,提高了并发的效率。但是如果线程在同一个位置操作,那必须还得一个一个来。
concurrentHashMap与hashTable都不允许存储null键,null值。
代码不允许,在源码中if(key==null ||value==null ) 抛出一个空指针异常。
为什么不允许存储键为null或值为null?
为了消除歧义,因为如果值为null,不知道是原本Map中没有找到,还是本身就是null.。键同样也是这个道理,会不清楚传进去的键是因为其他原因报错导致的,还是本身就准备传进去一个为null的键。
🪂集合可以引申过来:CopyOnWriteArrayList
单列集合List
ArrayList 底层是数组实现的 ,可以存储重复元素,它是有序的(按添加顺序) , 可以实现动态扩容, 默认大小为10 , 可以进行1.5倍扩容,它是线程不安全的。
Vector 他是线程安全的 ,与ArrayList类似,默认大小为10 ,可以进行2倍扩容,它给每个方法上都加了synchronized锁。虽然它是安全的,但是锁是添加到方法上的,并发访问效率很低,适合并发量不大的情况。
JUC并发包下,CopyOnWriiteArrayList认为读取方法也加锁会造成浪费,因为读是不改变数据的。
它的读操作是不加锁的,并且为了尽可能的提高读的效率。对于改变数据的操作(插入 更新 )会先把原本数据复制到本地副本数组中进行修改,不影响原本数组,所以在写的过程中,也可以读数据。最后将修改好的本地副本数组直接替换为原本数组即可。(写的过程是加锁的,在方法里面使用了ReentrantLock锁,进行数组复制操作…)
它适合读多写少的场景。
CopyOnWriteArraySet底层基于CopyOnWriiteArrayList实现,线程安全的,不能存储重复的数据。
🦓辅助类CountDownLatch
它允许一个线程等待其他线程执行完成后再执行,底层是通过AQS来实现的。刚创建一个CountDownLatch对象时,指定一个初始化state表示需要等 待线程的数量,每当一个线程执行完成后 ,AQS的内部·state数量就减1。
🎀线程池
池:一个容器,将实现创建好的对象放到容器里面,待到使用的时候,不需要在去重新创建对象了,直接从池子里面拿,节省了创建对象的时间。用完不销毁,还放入池子中。
🐕为什么要使用线程池?
以前创建线程的时候,是直接创建线程,使用完后再销毁线程。如果线程比较多(测试5000个数据库连接对象),那么频繁的创建、销毁线程非常占时间,而使用线程池,可以省去频繁创建对象带来的时间开销,直接使用池子里面的,用完不销毁,在放入池子中,速度非常快。
🐕你通常是怎么创建线程池的?为啥不使用其他的类Executors?
通常使用TreadPoolExecutor类创建线程池的,为啥使用这个是因为我参考了《《阿里巴巴 java 开发规范》中推荐使用TreadPoolExecutor来创建线程,而不使用Executors来创建线程。因为TreadPoolExecutor类的构造方法中有七个参数配置,可以准确的配置对象的数量、最大等待的数量、拒绝策略…
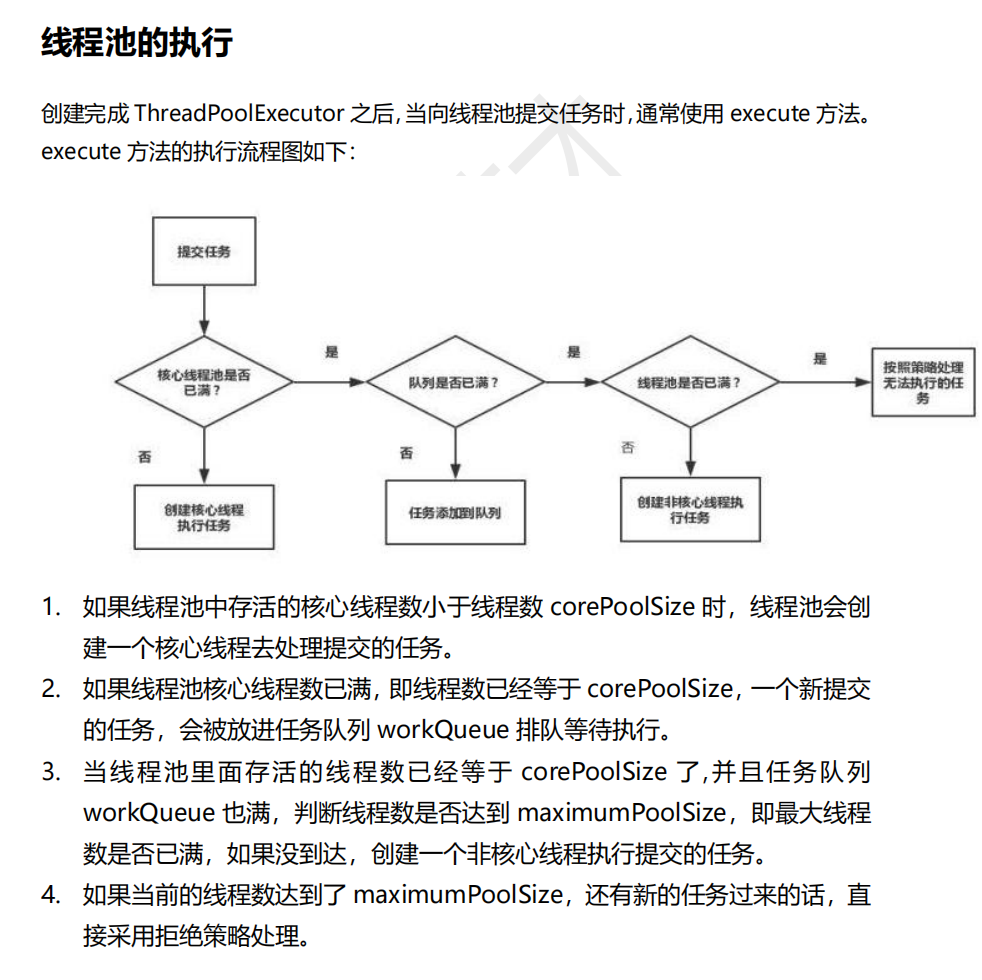
🏨TreadPoolExecutor构造方法的七个参数
1.corePoolSize 核心池子中对象的数量
2. maximumPoolSize线程池最大线程对象数量
3. keepAliveTime非核心池对象多长空闲时间后销毁
4. unit:存活时间的单位
5. workQueue:阻塞队列,用于存放等待的线程
6. treadFactory线程工厂,主要用来创建线程
7. handler拒绝策略,表示拒绝处理任务时的策略
🪂线程池拒绝策略handler
- AbortPolicy 抛出异常
- CallerRunsPolicy 只要线程池未关闭,如果该任务被拒绝了,则由提交该任务的线程来执行此任务(例如main线程)
- DiscardOleddestPolicy 丢弃队列中等待时间最长的任务
- DiscardPolicy 直接丢弃任务,不予理会
🪂execute()与submit()的区别
execute( “实现Runnable接口任务” )返回值 void 适合不需要关注返回值的场景,
submit( “实现Callable接口任务” ) 返回值 Future 适合需要关注返回值的场景
🪂关闭线程池shutdown、shutdownNow
shutdown() 等待所有的任务执行完成,关闭线程池,在此期间不接受新的任务。
shutdownNow() 紧急关闭线程池,立即终止正在执行的线程,返回没有执行完任务的列表
🎀ThreadLocal 本地线程变量
是用来给每一个线程提供一个线程副本变量,使得每个线程中的变量是相互隔离的。
在ThreadLocal 底层源码中,它的内部维护了一个ThreadLocalMap内部类,如果为线程创建副本变量,就会判断该线程是否存在ThreadLocalMap
每个线程都有一个ThreadLocalMap属性,以ThreadLocal对象作为键,副本变量作为值。如果该线程已经有了ThreadLocalMap,那么就直接在Map中添加这个 ThreadLocal键 ,副本变量值 即可
🐕什么原因造成ThreadLocal内存泄漏问题?如何解决?
当本地变量不再使用时,由于ThreadLocalMap中这个vaule值还与外界保持着引用关系(强引用),这样一来,垃圾回收器就无法回收这个ThreadLocalMap对象了。
解决办法:
用完后就删除threadLocal.remove();
下次垃圾回收时,就可以回收ThreadLocalMap了。