紧接着上篇SySeVR复现——Data preprocess(上)5、SySeVR复现——Data preprocess(上)_sliver呀的博客-CSDN博客
目录
5、训练Word2vec模型
6、token向量化且划分数据集
7、固定每一个切片的长度
5、训练Word2vec模型
对应create_w2vmodel.py :
## coding: utf-8
'''
This python file is used to tranfer the words in corpus to vector, and save the word2vec model under the path 'w2v_model'.
'''
import gc
import os
import pickle
from gensim.models import word2vec
'''
DirofCorpus class
-----------------------------
This class is used to make a generator to produce sentence for word2vec training
# Arguments
dirname: The src of corpus files
'''
class DirofCorpus(object): # 将分布在不同文件夹下的S
def __init__(self, dirname):
self.dirname = dirname
def __iter__(self):
for d in self.dirname:
for fn in os.listdir(d): # 遍历目录下文件,对语料库中的文件夹逐一处理,例如:CVE_2004_1151_PATCHED_sys32_ni_syscall.c
print(fn)
for filename in os.listdir(os.path.join(d, fn)): # 对每个文件夹下的四种SeVC逐一处理
samples = pickle.load(open(os.path.join(d, fn, filename), 'rb'))[0] # 获取SeVC文件的内容,并保存到变量sample中
for sample in samples:
yield sample # 生成器,暂时理解为return
del samples
gc.collect() # 垃圾回收机制
'''
generate_w2vmodel function
-----------------------------
This function is used to learning vectors from corpus, and save the model
# Arguments
decTokenFlawPath: String type, the src of corpus file
w2vModelPath: String type, the src of model file
size =30,iter=5
'''
def generate_w2vModel(decTokenFlawPath, w2vModelPath):
print("training...")
model = word2vec.Word2Vec(sentences=DirofCorpus(decTokenFlawPath), vector_size=30, alpha=0.01, window=5, min_count=0, max_vocab_size=None, sample=0.001, seed=1, workers=1, min_alpha=0.0001, sg=1, hs=0, negative=10)
model.save(w2vModelPath) # 模型保存
print(model.wv.index_to_key)
print(model.wv['int']) # model.wv['x']查询某个词的向量表示
print(model.wv.key_to_index)
def evaluate_w2vModel(w2vModelPath): # 模型评估
print("\nevaluating...")
model = word2vec.Word2Vec.load(w2vModelPath) # 加载模型
for sign in ['(', '+', '-', '*', 'main']: #
print(sign, ":")
print(model.wv.most_similar_cosmul(positive=[sign], topn=10)) # 求各个词与sign的相似度大小,取相似度最大的前十名
def main():
dec_tokenFlaw_path = ['.//file//corpus//'] # 语料库路径
w2v_model_path = ".//file//model//model.txt" # 模型保存路径
generate_w2vModel(dec_tokenFlaw_path, w2v_model_path) # 获取已训练好的word2vec模型
# evaluate_w2vModel(w2v_model_path)
print("success!")
if __name__ == "__main__":
main()
运行结果:

在对应文件夹下将训练好的Word2vec模型保存好,以便后面进行token的向量化。
6、token向量化且划分数据集
对应get_dl_input.py :
## coding: utf-8
'''
This python file is used to split database into 80% train set and 20% test set, tranfer the original code into vector, creating input file of deap learning model.
'''
from gensim.models import word2vec
import pickle
import os
import numpy as np
import random
import gc
import shutil
'''
generate_corpus function
-----------------------------
This function is used to create input of deep learning model
# Arguments
w2vModelPath: the path saves word2vec model
samples: the list of sample
'''
def generate_corpus(w2vModelPath, samples):
model = word2vec.Word2Vec.load(w2vModelPath) # 载入模型
print("begin generate input...")
dl_corpus = [[model.wv[word] for word in sample] for sample in samples] # 获取每一个token的向量
print("generate input success...")
return dl_corpus
'''
get_dldata function
-----------------------------
This function is used to create input of deep learning model
# Arguments
filepath: the path saves data
dlTrainCorpusPath: the path saves train dataset
dlTestCorpusPath: the path saves test dataset
split: split ratio
seed: random number seed
'''
def get_dldata(filepath, dlTrainCorpusPath, dlTestCorpusPath, split=0.8, seed=113):
folders = os.listdir(filepath) # 获取保存vector的路径,以CVE文件为单位
np.random.seed(seed) # 设置随机数,使用np.random()生成的数据会打乱顺序
np.random.shuffle(folders) # 打乱CVE文件的顺序
folders_train = folders[:int(len(folders)*split)] # 把80%的打乱顺序的CVE文件作为训练集
folders_test = folders[int(len(folders)*split):] # 把20%的打乱顺序的CVE文件作为测试集
# 将分散于各个CVE文件中的四类SeVCs,重新汇集到一起
for mode in ["api", "arraysuse", "pointersuse", "integeroverflow"]: # 以SeVC的类型为单位进行处理
num = [] # 每一次拿哪几份,与N的值息息相关
N = 0 # 数据被划分为几份
if mode == "api":
N = 4
num = [0, 1, 2, 3, 4]
if mode == "arraysuse":
N = 2
num = [0, 1]
if mode == "integeroverflow":
N = 2
num = [0, 1]
if mode == "pointersuse":
N = 6
num = [0, 1, 2, 3, 4, 5]
for i in num: # 以切片类型为单位,逐一进行处理
train_set = [[], [], [], [], [], []] # 保存某一类SeVC的信息
ids = [] # 保存CVE文件名
for folder_train in folders_train[int(i*len(folders_train)/N) : int((i+1)*len(folders_train)/N)]: # 把整个训练集切分为N份
for filename in os.listdir(filepath + folder_train + '/'): # 对CVE文件中的4类SeVCs逐一处理,分别为:api、array、point、intege.
if mode in filename:
if folder_train not in os.listdir(dlTrainCorpusPath): # 将划分为测试集的数据保存到一起
folder_path = os.path.join(dlTrainCorpusPath, folder_train) # 获取路径
os.mkdir(folder_path) # 新建文件夹
shutil.copyfile(filepath + folder_train + '/'+filename , dlTrainCorpusPath + folder_train + '/'+filename) # 将文件夹复制到指定位置,注意每次复制的内容与当前filename中保存的数据有关,也就是说不是一次性把所有文件都复制过来
f = open(filepath + folder_train + '/' + filename, 'rb') # 以读取方式打开文件
data = pickle.load(f) # 载入文件内容,并赋给data变量
id_length = len(data[1]) #
for j in range(id_length): # 将CVE文件名保存到ids变量中
ids.append(folder_train)
for n in range(5): # 提取某一类SeVC文件内保存的信息,train_set内的元素,相同的信息保存在一起
train_set[n] = train_set[n] + data[n]
train_set[-1] = ids
if train_set[0] == []:
continue
f_train = open(dlTrainCorpusPath + mode + "_" + str(i)+ "_.pkl", 'wb') # 将某一类汇总好的信息,保存在一起
pickle.dump(train_set, f_train, protocol=pickle.HIGHEST_PROTOCOL)
f_train.close()
del train_set
gc.collect()
for mode in ["api", "arraysuse", "pointersuse", "integeroverflow"]: # 相似的处理方式,只是这一步是对测试函数进行处理
# N = 4 (未改前)
# num = [0, 1, 2, 3]
# if mode == "pointersuse":
# N = 8
# num = [4, 5]
num = [] # 每一次拿哪几份,与N的值息息相关
N = 0 # 数据被划分为几份
if mode == "api":
N = 4
num = [0, 1, 2, 3, 4]
if mode == "arraysuse":
N = 2
num = [0, 1]
if mode == "integeroverflow":
N = 2
num = [0, 1]
if mode == "pointersuse":
N = 6
num = [0, 1, 2, 3, 4, 5]
for i in num:
test_set = [[], [], [], [], [], []]
ids = []
for folder_test in folders_test[int(i*len(folders_test)/N) : int((i+1)*len(folders_test)/N)]:
for filename in os.listdir(filepath + folder_test + '/'):
if mode in filename:
if folder_test not in os.listdir(dlTestCorpusPath):
folder_path = os.path.join(dlTestCorpusPath, folder_test)
os.mkdir(folder_path)
shutil.copyfile(filepath + folder_test + '/'+filename , dlTestCorpusPath + folder_test + '/'+filename)
f = open(filepath + folder_test + '/' + filename, 'rb')
data = pickle.load(f)
id_length = len(data[1])
for j in range(id_length):
ids.append(folder_test)
for n in range(5):
test_set[n] = test_set[n] + data[n]
test_set[-1] = ids
if test_set[0] == []:
continue
f_test = open(dlTestCorpusPath + mode + "_" + str(i)+ ".pkl", 'wb')
pickle.dump(test_set, f_test, protocol=pickle.HIGHEST_PROTOCOL)
f_test.close()
del test_set
gc.collect()
if __name__ == "__main__":
CORPUSPATH = ".//file//corpus//" # 语料库路径
VECTORPATH = ".//file//vector//" # token对应的向量的保存路径
W2VPATH = ".//file//model//model.txt" # word2vec模型保存路径
print("turn the corpus into vectors...")
for corpusfiles in os.listdir(CORPUSPATH): # 对语料库中的CVE文件单独进行处理,例如:CVE_2004_1151_PATCHED_sys32_ni_syscall.c
print(corpusfiles)
if corpusfiles not in os.listdir(VECTORPATH): # 每一个CVE语料库文件生成对应的向量文件,token转化为向量,并保存
folder_path = os.path.join(VECTORPATH, corpusfiles) # 获取向量保存路径
os.mkdir(folder_path) # 新建对应文件夹
for corpusfile in os.listdir(CORPUSPATH + corpusfiles): # 对CVE文件中保存的四种SeVC的token序列单独处理
corpus_path = os.path.join(CORPUSPATH, corpusfiles, corpusfile) # 获取要处理的token序列的路径
f_corpus = open(corpus_path, 'rb') # 以读取模式打开保存SeVC token的文件
data = pickle.load(f_corpus) # 将文件内容提取出来,并保存到变量data中
f_corpus.close() # 关闭f_corpus对象
data[0] = generate_corpus(W2VPATH, data[0]) # 将切片中的token转化为向量
vector_path = os.path.join(VECTORPATH, corpusfiles, corpusfile) # token对应的向量的保存路径
f_vector = open(vector_path, 'wb') # 以写入模式打开文件
pickle.dump(data, f_vector, protocol=pickle.HIGHEST_PROTOCOL) # 对token序列对应的向量进行保存
f_vector.close() # 关闭f_vecctor对象
print("w2v over...")
print("spliting the train set and test set...")
dlTrainCorpusPath = ".//dataset//raw_train//"
dlTestCorpusPath = ".//dataset//raw_test//"
get_dldata(VECTORPATH, dlTrainCorpusPath, dlTestCorpusPath)
print("success!")
运行结果:
(1)将数据划分为训练集和测试集:

(2)将各个CVE文件切片进行汇总,只分为四类切片

打开api_0.pkl,可以看到保存的是向量形式的token: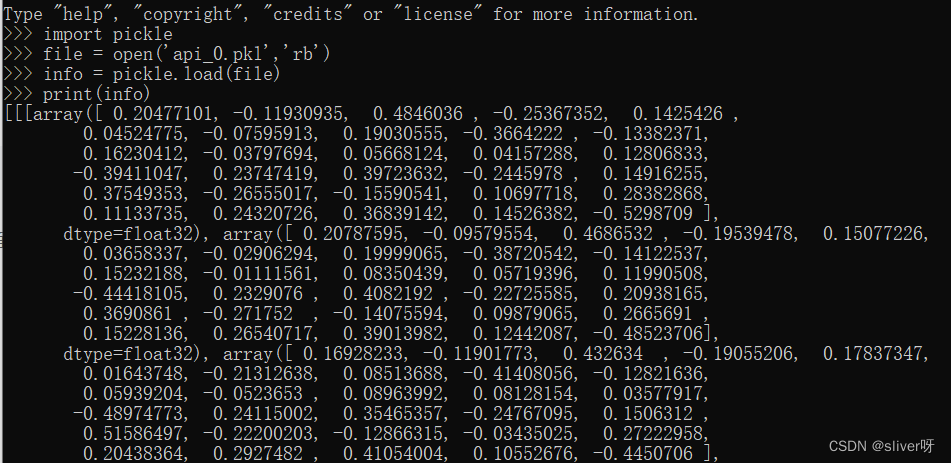
7、固定每一个切片的长度
对应dealrawdata.py :
## coding: utf-8
'''
This python file is used to train data in CNN model
'''
from __future__ import absolute_import
from __future__ import print_function
import pickle
import _pickle as cPickle
import numpy as np
import random
import time
import math
import os
from collections import Counter
from imblearn.ensemble import _easy_ensemble
from imblearn.over_sampling import ADASYN
from imblearn.over_sampling import SMOTE
np.random.seed(1337) # for reproducibility
'''
dealrawdata function
-----------------------------
This function is used to cut the dataset, do shuffle and save into pkl file.
# Arguments
raw_traindataSet_path: String type, the raw data path of train set
raw_testdataSet_path: String type, the raw data path of test set
traindataSet_path: String type, the data path to save train set
testdataSet_path: String type, the data path to save test set
batch_size: Int type, the mini-batch size
maxlen: Int type, the max length of data
vector_dim: Int type, the number of data vector's dim
'''
def dealrawdata(raw_traindataSet_path, raw_testdataSet_path, traindataSet_path, testdataSet_path, batch_size, maxlen, vector_dim):
print("Loading data...")
for filename in os.listdir(raw_traindataSet_path): # 获取各类型SeVC的pkl文件(训练集)
if not (filename.endswith(".pkl")): #
continue
print(filename)
X_train, train_labels, funcs, filenames, testcases = load_data_binary(raw_traindataSet_path + filename, batch_size, maxlen=maxlen, vector_dim=vector_dim) # 使切片的长度一致,也就是每个切片的token数都一样
f_train = open(traindataSet_path + filename, 'wb') # 以写入模式打开文件
pickle.dump([X_train, train_labels, funcs, filenames, testcases], f_train) # 将整理后的切片信息保存到文件中
f_train.close() # 关闭文件对象
for filename in os.listdir(raw_testdataSet_path): # # 获取各类型SeVC的pkl文件(测试集)
# if not ("api" in filename): 源文件这里有if语句,这样做只会将api相关的SeVC进行转换,why?
# continue
# print(filename)
if not (filename.endswith(".pkl")):
continue
print(filename)
X_test, test_labels, funcs, filenames, testcases = load_data_binary(raw_testdataSet_path + filename, batch_size, maxlen=maxlen, vector_dim=vector_dim)
f_test = open(testdataSet_path + filename, 'wb')
pickle.dump([X_test, test_labels, funcs, filenames, testcases], f_test)
f_test.close()
def load_data_binary(dataSetpath, batch_size, maxlen=None, vector_dim=30, seed=113):
#load data
f1 = open(dataSetpath, 'rb') # 以读取模式打开保存向量化SeVC的文件(一类SeVC,是被划分为多个文件了的)
X, ids, focus, funcs, filenames, test_cases = pickle.load(f1)
# X:保存的是切片的向量信息,一个CVE文件中所有SeVCs的切片向量
# ids:切片的标签,有漏洞 or 无漏洞(0 or 1)
# focus:保存的是SyVC的在token序列中的位置
# funcs:不确定是不是SyVC
# filename:切片的头部信息
# test_case:保存的是切片来自哪个文件
f1.close()
cut_count = 0 # 保存token数超过500,需要进行截取的SeVC个数
fill_0_count = 0 # 记录token数小于500个,需进行填充操作的SeVC个数
no_change_count = 0 # # 记录token数等于500,不需进行任何处理的SeVC个数
fill_0 = [0]*vector_dim # 生成一阶张量(向量),与token的维数是相对应的
totallen = 0 # 记录整个pkl文件中,所有SeVC的长度,也就是一共有多少个token
if maxlen:
new_X = [] # 用于保存处理后的切片向量,一个pkl文件中切片向量都是保存在new_X中
for x, i, focu, func, file_name, test_case in zip(X, ids, focus, funcs, filenames, test_cases): # 对每一个向量化后的SeVC单独进行处理,也就是说一个CVE文件中可能存在多个SeVC
if len(x) < maxlen: # 某一个SeVC含有的向量少于规定的最大向量个数,多于部分补零
x = x + [fill_0] * (maxlen - len(x)) # [fill_0]是二阶张量(矩阵),它是用来代表需要填充token的个数
new_X.append(x) # 将当前处理的SeVC保存到变量nex_X中
fill_0_count += 1 # 记录token数小于500个,需进行填充操作的SeVC个数
elif len(x) == maxlen: # 某一个SeVC中含有的向量等于规定的最大向量个数
new_X.append(x) # 将当前处理的SeVC保存到变量nex_X中
no_change_count += 1 # 记录token数等于500,不需进行任何处理的SeVC个数
else: # 某一个SeVC中含有的向量多于规定的最大向量个数,设置一个开始点和结束点,然后进行切片处理
startpoint = int(focu - round(maxlen / 2.0)) # round():四舍五入,切片起始点
endpoint = int(startpoint + maxlen) # 切片结束点
if startpoint < 0: # 起始点小于0,取SeVC的前500个token
startpoint = 0
endpoint = maxlen
if endpoint >= len(x): # 结束点大于500,取SeVC最后的500个token
startpoint = -maxlen
endpoint = None
new_X.append(x[startpoint:endpoint]) # 对SeVC进行切片处理,并保存到new_X变量中
cut_count += 1 # 保存token数超过500,需要进行截取的SeVC个数
totallen = totallen + 500 # 保存整个pkl文件的token个数
X = new_X
print(totallen)
return X, ids, funcs, filenames, test_cases
if __name__ == "__main__":
batchSize = 32 #
# vectorDim = 40 # 填充零的位置的维数,好奇:token向量化后的维数明显是30维,为什么用40维的数据去填充??
vectorDim = 30
maxLen = 500 # 每一个切片SeVC能够拥有的最大向量个数,也就是一个SeVC中最多有500个token,每一个token进行向量化后的维度为30维
raw_traindataSetPath = ".//dataset//raw_train//" # get_dl_input.py生成的训练集保存地址
raw_testdataSetPath = ".//dataset//raw_test//" # get_dl_input.py生成的测试集保存地址
traindataSetPath = ".//dataset//train/" # 固定原始向量的长度,训练集保存地址
testdataSetPath = ".//dataset//test/" # 固定原始向量的长度,测试集保存地址
dealrawdata(raw_traindataSetPath, raw_testdataSetPath, traindataSetPath, testdataSetPath, batchSize, maxLen, vectorDim)
运行结果:


该部分各个文件的大致流程是这样,可能细节还有待完善。