算法简介
AlexNet是人工智能深度学习在CV领域的开山之作,是最先把深度卷积神经网络应用于图像分类领域的研究成果,对后面的诸多研究起到了巨大的引领作用,因此有必要学习这个算法并能够实现它。
主要的创新点在于:
- 首次使用GPU进行神经网络加速训练
- 使用使用了非饱和的激活函数ReLU,而不是传统的sigmoid和tanh
- 使用了数据增强手段抑制过拟合
- 提出了Dropout随机失活抑制过拟合
- 提出了LRN局部响应归一化
- 使用了重叠池化抑制过拟合
model.py代码讲解
import torch.nn as nn
import torch
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] 使用48个11*11的卷积核,步长为4,padding为2 output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # input[48, 55, 55] output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
model.py的全部代码如上
现在逐行进行分析
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] 使用48个11*11的卷积核,步长为4,padding为2 output[48, 55, 55]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # input[48, 55, 55] output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
class AlexNet(nn.Module):
定义了一个AlexNet的类,这个类继承了nn.Module
def init(self,num_classes=1000):
定义了类的初始化函数,它有个可选的参数 num_classes是我们这个神经网络在输出的分类数
super(AlexNet,self).__init()
这是为了调用父类的初始化函数
self.features = nn.Sequential()
这里非常重要,我们可以去Pytorch的官方文档上看看,
官方的解释是:
模块将按照传入构造函数的顺序添加到其中。另外,也可以传入一个有序字典的模块。Sequential的forward()方法接受任何输入,并将其转发给它包含的第一个模块。然后,对于每个后续模块,它将输出“链接”到输入,最终返回最后一个模块的输出。
Sequential相对于手动调用一系列模块的优势在于,它允许将整个容器视为单个模块,这样对Sequential执行的转换将应用于其存储的每个模块(它们分别是Sequential的注册子模块)。
Sequential和torch.nn.ModuleList之间有什么区别?ModuleList就像它的名字一样-用于存储Module的列表!另一方面,Sequential中的层以级联方式连接。
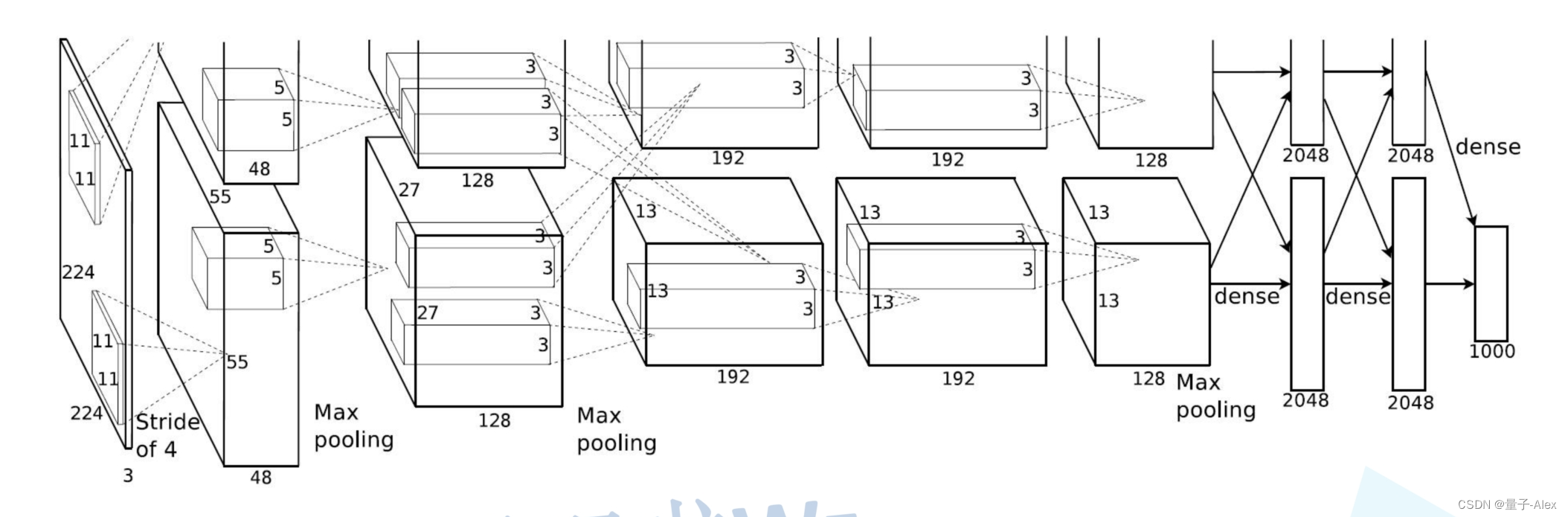
论文中的AlexNet网络结构图如下:
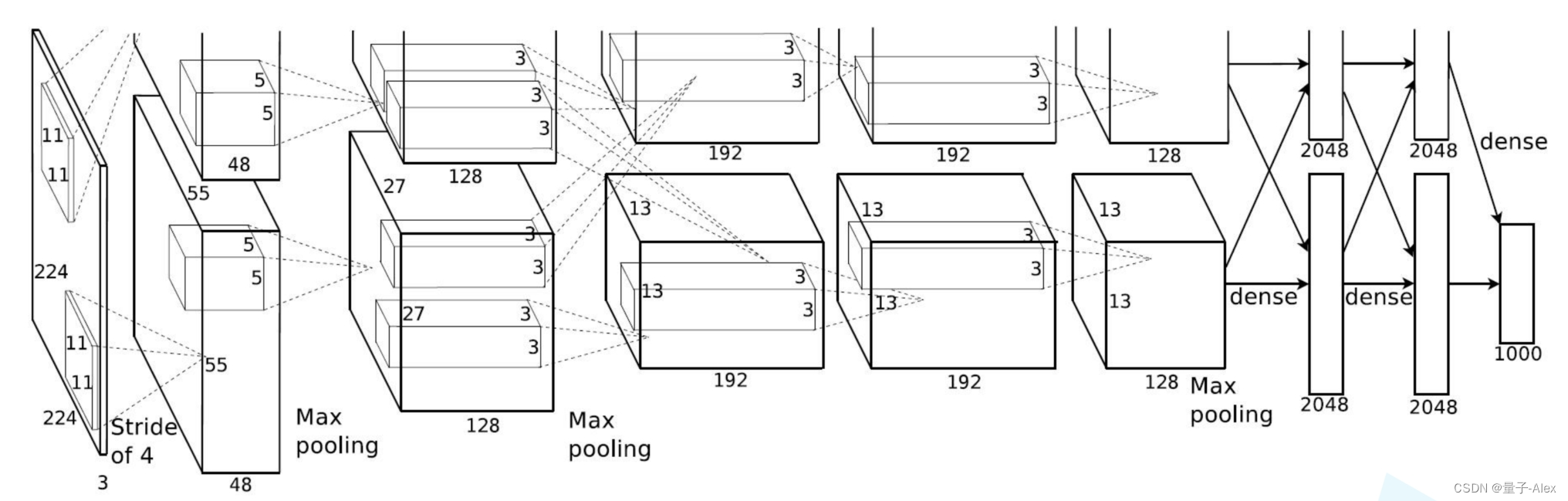
AlexNet是第一个网络结构开始变得更加复杂的神经网络模型(Lenet)只有两个卷积层和两个全连接层,而AlexNet有5个卷积层和3个全连接层,对于逐渐复杂的网络结构,我们可以利用Sequential函数搭建序列化的网络模块
比如这里我们首先定义了一个features模块
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2),
第一个卷积层 输入是2242243 48个1111的卷积核 步长是4,填充是2
输出是5555*48
nn.ReLU(inplace=True),ReLU激活函数
nn.MaxPool2d(kernel_size=3, stride=2),
定义一个最大池化层,使用3x3的池化核,步长为2。这将进一步减少特征图的尺寸。
nn.Conv2d(48, 128, kernel_size=5, padding=2),
又是一个卷积层,输入是272748 128个55的卷积核 填充是2,输出是2727*128
然后以此类推
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), 又是激活函数和池化,池化后输出 1313128
nn.Conv2d(128, 192, kernel_size=3, padding=1), 输入1313128 输出1313192
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1),输入1313192 输出1313192
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), 输入1313192
输出1313128
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), 输入1313128 输出 66128
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(128 * 6 * 6, 2048),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),
)
第二个模块,上一个是5层卷积层加3层池化层提取特征
下面这个模块就是全连接层做分类
首先是drouput随机失活抑制过拟合的操作
然后是 nn.Linear(128 * 6 * 6, 2048),12866的原因是全连接层是接着前面的最后一个也是第三个池化层,池化层的输出就是12866
后面再接两个全连接层,最后一个全连接层的输出就是对1000个类的预测结果
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def forward(self, x):
定义一个名为forward的方法,这是PyTorch中自定义神经网络层或模型的标准做法。这个方法描述了输入数据x通过网络的前向传播过程。
x = self.features(x)
将输入数据x传递给feature模块
x = torch.flatten(x, start_dim=1)
使用PyTorch的flatten函数将特征图x在指定的维度(start_dim=1,通常是指从第二个维度开始,即特征图的深度维度)展平。这通常是为了将多维的特征图转换为一维的张量,以便输入到全连接层。
这里要重点说明一下,在feature后输出的x是一个四维的参数(B,C,H,W)分别是batchsize channel 高、宽 而这个函数的意思是从第二维channel开始,对后三维 通道数、宽、高进行展开,转为一维的向量输入全连接层
x = self.classifier(x)
将展平后的特征x传递给classifier
return x
返回经过分类器处理后的输出。