PyTorch-Ignite 是一个用于 PyTorch 的高级库,旨在帮助开发者更快、更简洁地编写可复用的代码来进行深度学习实验。它由 PyTorch 社区开发,提供了一套灵活的抽象,用于构建和管理训练和验证循环,而无需牺牲 PyTorch 的灵活性和强大功能。
主要特点包括:
-
简洁的训练和验证循环:Ignite 提供了一个 Engine 类,用于封装训练和验证循环的逻辑,使代码更加简洁和易于理解。
-
易于扩展:通过 Events 和 Handlers,用户可以轻松地自定义训练过程,比如在训练的不同阶段添加日志记录、模型保存等。
-
指标和日志:Ignite 内置了许多常用的指标,方便评估模型性能。它也可以与流行的日志库(如 TensorBoard)集成,以便于跟踪实验。
-
复用和共享:它鼓励代码复用,并使得分享最佳实践变得更加容易。
-
社区支持:作为 PyTorch 生态系统的一部分,Ignite 享有活跃的社区支持和持续的发展。
Ignite 对于想要减少样板代码、更专注于模型开发的 PyTorch 用户来说是一个很好的选择。它不仅简化了开发过程,还保留了 PyTorch 的灵活性和强大功能。
一、介绍
这篇文章是对 PyTorch-Ignite 的全面介绍,旨在向深度学习爱好者、专业人士和研究人员展示 PyTorch-Ignite 的核心优势和功能。PyTorch-Ignite 与 PyTorch 保持一致的设计理念,致力于保持简单性、灵活性和可扩展性,同时确保高效性和可伸缩性。
在本教程中,我们将通过构建和评估一个简单的 MNIST 分类器来阐述 PyTorch-Ignite 的基本概念,这是一个理想的入门案例。我们假设读者已经具备 PyTorch 的基础知识。
PyTorch-Ignite:是什么以及为什么选择它?
PyTorch-Ignite 是一个高级库,专为在 PyTorch 中灵活且透明地训练和评估神经网络而设计。它旨在成为易用的高级功能和深度定制可能性的交汇点。通过推广最佳实践,PyTorch-Ignite 助力深度学习社区技术能力的提升。它的设计理念是让一切功能都易于用户理解和使用,而不是隐藏在一个全能的工具背后。
PyTorch-Ignite 采用了“自己动手”的方法,这一点对于研究领域尤为重要,因为研究本质上是充满不确定性的,重要的是在不阻碍流程的同时捕捉到研究的需求。
PyTorch + Ignite
PyTorch-Ignite 将 PyTorch 的原生抽象概念(如模块、优化器和数据加载器)以极简的方式封装,通过 Engine 这一控制反转的抽象概念实现了模型与训练框架的完全分离。Engine 负责运行任意函数,通常是训练或评估函数,并在整个过程中发出事件。
Engine 的灵活性得益于其内置的事件系统(由 Events 类实现),这大大促进了运行过程中每一步的互动。用户可以完全自定义运行期间的事件流程,从而实现高度定制化的训练体验。
总结来说,PyTorch-Ignite 提供了:
• 极其简单的引擎和事件系统,实现了训练循环的高度抽象。
• 开箱即用的度量指标,便于轻松评估模型性能。
• 内置的处理程序,用于构建训练管道、保存工件以及记录参数和指标。
选择 PyTorch-Ignite 的额外好处包括:
• 相较于纯 PyTorch,代码更少,同时保持了最大程度的控制性和简洁性。
• 更加模块化、结构化的代码设计。
关于 PyTorch-Ignite 的设计
PyTorch-Ignite 允许您构建应用程序,而不是专注于一个多功能的超级对象,而是侧重于弱耦合的组件,从而实现高级定制。
该库的设计指导原则包括:
• 预见未来可能出现的新软件或用例,而不是把一切都集中在一个单一的类中。
• 避免使用难以管理和维护的大量参数配置。
• 提供旨在最大化内聚性和最小化耦合性的工具。
• 保持简单。
二、快速入门示例
在这一部分,我们将使用 PyTorch-Ignite 构建和训练一个著名的 MNIST 数据集分类器。这个简单的例子将介绍 PyTorch-Ignite 背后的主要概念。
如需获取更多信息和关于 API 的详细信息,请参阅项目文档点击跳转。
安装pytorch-ignite模块
pip install pytorch-ignite
首先,我们定义了我们的模型、训练和验证数据集、优化器和损失函数:
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import SGD
from torch.utils.data import DataLoader
from torchvision.transforms import Compose, ToTensor, Normalize
from torchvision.datasets import MNIST
# transform to normalize the data
transform = Compose([ToTensor(), Normalize((0.1307,), (0.3081,))])
# Download and load the training data
trainset = MNIST("data", download=True, train=True, transform=transform)
train_loader = DataLoader(trainset, batch_size=128, shuffle=True)
# Download and load the test data
validationset = MNIST("data", train=False, transform=transform)
val_loader = DataLoader(validationset, batch_size=256, shuffle=False)
# Define a class of CNN model (as you want)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=-1)
device = "cuda"
# Define a model on move it on CUDA device
model = Net().to(device)
# Define a NLL loss
criterion = nn.NLLLoss()
# Define a SGD optimizer
optimizer = SGD(model.parameters(), lr=0.01, momentum=0.8)
上面的代码是纯粹的 PyTorch,并且通常由用户定义,对于任何流程来说都是必需的。
训练器和评估器的设置
模型的训练器是一个引擎,它多次循环遍历训练数据集并更新模型参数。让我们看看如何使用 PyTorch-Ignite 定义这样的训练器。为此,PyTorch-Ignite 引入了通用类 Engine,它是一个抽象概念,可以遍历提供的数据,执行处理函数并返回结果。构建训练器所需的唯一参数是 train_step 函数。
from ignite.engine import Engine
def train_step(engine, batch):
x, y = batch
x = x.to(device)
y = y.to(device)
model.train()
y_pred = model(x)
loss = criterion(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss
# Define a trainer engine
trainer = Engine(train_step)
请注意,train_step 函数必须接受 engine 和 batch 参数。在上面的例子中,尽管 train_step 内部没有使用 engine,但我们可以轻松想象一个使用场景,在该场景中我们可能希望从 engine 中获取当前迭代、epoch 或自定义变量等信息。
同样地,模型评估可以通过一个引擎来完成,该引擎对验证数据集运行一次,并计算指标。
def validation_step(engine, batch):
model.eval()
with torch.no_grad():
x, y = batch[0], batch[1]
x = x.to("cuda")
y = y.to("cuda")
y_pred = model(x)
return y_pred, y
evaluator = Engine(validation_step)
这允许从最简单到最复杂的场景构建训练逻辑。
处理函数的输出类型(例如上面示例中的 loss 或 y_pred, y)并不受限制。这些函数可以返回用户想要的任何内容。输出被设置为引擎的内部对象 engine.state.output,并可以进一步用于任何类型的处理。
事件和处理器
为了提高引擎的灵活性,引入了一个可配置的事件系统,以便在运行的每一步上促进互动。具体来说,Engine 允许在运行期间触发的各种事件上添加处理器。当事件被触发时,附加的处理器(命名函数、lambda 表达式、类函数)将被执行。以下是默认触发内置事件的流程图:
fire_event(Events.STARTED)
while epoch < max_epochs:
fire_event(Events.EPOCH_STARTED)
# run once on data
for batch in data:
fire_event(Events.ITERATION_STARTED)
output = process_function(batch)
fire_event(Events.ITERATION_COMPLETED)
fire_event(Events.EPOCH_COMPLETED)
fire_event(Events.COMPLETED)
请注意,每个引擎(即训练器和评估器)都有自己的事件系统,这允许定义其自己的引擎处理逻辑。
使用事件和处理器,可以以非常直观的方式完全自定义引擎的运行:
from ignite.engine import Events
# Show a message when the training begins
@trainer.on(Events.STARTED)
def start_message():
print("Start training!")
# Handler can be want you want, here a lambda !
trainer.add_event_handler(
Events.COMPLETED,
lambda _: print("Training completed!")
)
# Run evaluator on val_loader every trainer's epoch completed
@trainer.on(Events.EPOCH_COMPLETED)
def run_validation():
evaluator.run(val_loader)
在上述代码中,run_validation 函数被附加到训练器上,并将在每个完成的 epoch 时触发,以启动使用评估器的模型验证。这表明可以嵌入引擎来创建复杂的流水线。
与回调相比,处理器提供了无与伦比的灵活性,因为它们可以是任何函数:例如,一个 lambda 表达式、一个简单的函数、一个类方法等。因此,我们不需要继承一个接口并重写其抽象方法,这可能会不必要地增加代码的体积和复杂性。
定制的可能性是无穷的,因为 PyTorch-Ignite 允许您掌握应用程序的工作流程。正如之前提到的,PyTorch-Ignite 中没有魔法或完全自动化的东西。
模型评估指标
指标是展示 PyTorch-Ignite 处理器是什么以及如何使用它们的另一个很好的例子。在我们的例子中,我们使用内置的 Accuracy 和 Loss 指标。
from ignite.metrics import Accuracy, Loss
# Accuracy and loss metrics are defined
val_metrics = {
"accuracy": Accuracy(),
"loss": Loss(criterion)
}
# Attach metrics to the evaluator
for name, metric in val_metrics.items():
metric.attach(evaluator, name)
PyTorch-Ignite 的指标可以优雅地相互结合使用。
from ignite.metrics import Precision, Recall
# Build F1 score
precision = Precision(average=False)
recall = Recall(average=False)
F1 = (precision * recall * 2 / (precision + recall)).mean()
# and attach it to evaluator
F1.attach(evaluator, "f1")
为了进一步简化操作,我们提供了辅助方法来创建类似上面所示的监督型引擎。因此,我们接下来将以这种方式定义一个新的评估器,它将应用于训练数据集。
from ignite.engine import create_supervised_evaluator
# Define another evaluator with default validation function and attach metrics
train_evaluator = create_supervised_evaluator(model, metrics=val_metrics, device="cuda")
# Run train_evaluator on train_loader every trainer's epoch completed
@trainer.on(Events.EPOCH_COMPLETED)
def run_train_validation():
train_evaluator.run(train_loader)
我们之所以需要两个不同的评估器(即评估器和训练评估器),是因为它们可以执行不同的处理器和逻辑。例如,如果我们想根据验证数据集的指标值来保存最佳模型,这个任务就由计算验证数据集指标的评估器来承担。
常用的训练处理器
从现在开始,我们设置了一个训练器,它会在每个 epoch 完成时调用评估器和训练评估器。因此,每个评估器都会运行并计算相应的指标。另外,能够显示这些指标的结果非常有助于我们了解训练过程。
借助引擎系统的定制能力,我们可以添加一些简单的处理器来实现这种日志记录:
@evaluator.on(Events.COMPLETED)
def log_validation_results():
metrics = evaluator.state.metrics
print("Validation Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f} Avg F1: {:.2f}"
.format(trainer.state.epoch, metrics["accuracy"], metrics["loss"], metrics["f1"]))
@train_evaluator.on(Events.COMPLETED)
def log_train_results():
metrics = train_evaluator.state.metrics
print(" Training Results - Epoch: {} Avg accuracy: {:.2f} Avg loss: {:.2f}"
.format(trainer.state.epoch, metrics["accuracy"], metrics["loss"]))
在这里,我们在 Events.COMPLETED 事件上附加了 log_validation_results 和 log_train_results 处理器,因为评估器和训练评估器将在验证数据集上运行一个 epoch。
让我们来看看如何为我们的应用程序添加一些其他有用的功能。
*PyTorch-Ignite 提供了一个 ProgressBar 处理器,用以显示引擎的进度。
from ignite.contrib.handlers import ProgressBar
ProgressBar().attach(trainer, output_transform=lambda x: {'batch loss': x})
* [ModelCheckpoint](https://pytorch.org/ignite/handlers.html#ignite.handlers.ModelCheckpoint)处理程序可用于定期保存具有属性state_dict的对象。
from ignite.handlers import ModelCheckpoint, global_step_from_engine
# Score function to select relevant metric, here f1
def score_function(engine):
return engine.state.metrics["f1"]
# Checkpoint to store n_saved best models wrt score function
model_checkpoint = ModelCheckpoint(
"quick-start-mnist-output",
n_saved=2,
filename_prefix="best",
score_function=score_function,
score_name="f1",
global_step_transform=global_step_from_engine(trainer),
)
# Save the model (if relevant) every epoch completed of evaluator
evaluator.add_event_handler(Events.COMPLETED, model_checkpoint, {"model": model})
*PyTorch-Ignite 为现代实验跟踪工具提供了包装器。例如,TensorBoardLogger 处理器可以在训练和验证过程中记录指标结果、模型参数、优化器参数、梯度等信息,以便于在 TensorBoard 中进行查看。
from ignite.contrib.handlers import TensorboardLogger
# Define a Tensorboard logger
tb_logger = TensorboardLogger(log_dir="quick-start-mnist-output")
# Attach handler to plot trainer's loss every 100 iterations
tb_logger.attach_output_handler(
trainer,
event_name=Events.ITERATION_COMPLETED(every=100),
tag="training",
output_transform=lambda loss: {"batchloss": loss},
)
# Attach handler to dump evaluator's metrics every epoch completed
for tag, evaluator in [("training", train_evaluator), ("validation", evaluator)]:
tb_logger.attach_output_handler(
evaluator,
event_name=Events.EPOCH_COMPLETED,
tag=tag,
metric_names="all",
global_step_transform=global_step_from_engine(trainer),
)
通过集成用户定义的函数,可以非常简单地扩展 TensorBoard 记录器的使用。例如,以下是在训练过程中展示图像和预测的方法:
import matplotlib.pyplot as plt
# Store predictions and scores using matplotlib
def predictions_gt_images_handler(engine, logger, *args, **kwargs):
x, _ = engine.state.batch
y_pred, y = engine.state.output
# y_pred is log softmax value
num_x = num_y = 8
le = num_x * num_y
probs, preds = torch.max(torch.exp(y_pred[:le]), dim=1)
fig = plt.figure(figsize=(20, 20))
for idx in range(le):
ax = fig.add_subplot(num_x, num_y, idx + 1, xticks=[], yticks=[])
ax.imshow(x[idx].squeeze(), cmap="Greys")
ax.set_title("{0} {1:.1f}% (label: {2})".format(
preds[idx],
probs[idx] * 100.0,
y[idx]),
color=("green" if preds[idx] == y[idx] else "red")
)
logger.writer.add_figure('predictions vs actuals', figure=fig, global_step=trainer.state.epoch)
# Attach custom function to evaluator at first iteration
tb_logger.attach(
evaluator,
log_handler=predictions_gt_images_handler,
event_name=Events.ITERATION_COMPLETED(once=1),
)
现在我们需要做的就是在 train_loader 提供的数据上运行训练器,并进行若干个 epoch 的训练。
trainer.run(train_loader, max_epochs=5)
# Once everything is done, let's close the logger
tb_logger.close()
Start training!
Validation Results - Epoch: 1 Avg accuracy: 0.94 Avg loss: 0.20 Avg F1: 0.94
Training Results - Epoch: 1 Avg accuracy: 0.94 Avg loss: 0.21
Validation Results - Epoch: 2 Avg accuracy: 0.96 Avg loss: 0.12 Avg F1: 0.96
Training Results - Epoch: 2 Avg accuracy: 0.96 Avg loss: 0.13
Validation Results - Epoch: 3 Avg accuracy: 0.97 Avg loss: 0.10 Avg F1: 0.97
Training Results - Epoch: 3 Avg accuracy: 0.97 Avg loss: 0.10
Validation Results - Epoch: 4 Avg accuracy: 0.98 Avg loss: 0.07 Avg F1: 0.98
Training Results - Epoch: 4 Avg accuracy: 0.97 Avg loss: 0.09
Validation Results - Epoch: 5 Avg accuracy: 0.98 Avg loss: 0.07 Avg F1: 0.98
Training Results - Epoch: 5 Avg accuracy: 0.98 Avg loss: 0.08
Training completed!
我们可以使用 TensorBoard 来检查结果。在 TensorBoard 中,我们可以看到两个标签页:“Scalars”和“Images”。
%load_ext tensorboard
%tensorboard --logdir=.
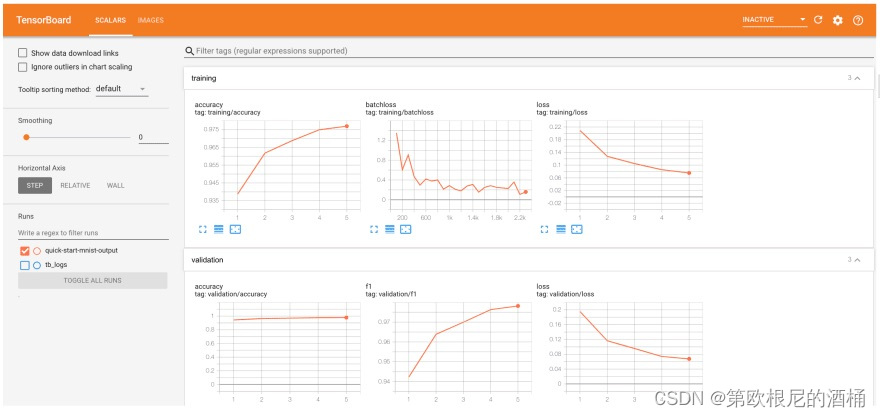 |  |
|---|
五个关键点
• 几乎所有的训练逻辑都可以通过编写 train_step 方法并基于此方法构建训练器来实现。
• 这个库的核心是 Engine 类,它能够在数据集上重复执行给定次数的循环,并执行处理函数。
• 一个高度可定制的事件系统使得在运行的每一步都能轻松与引擎互动。
• PyTorch-Ignite 提供了一系列内置的处理器和常用任务的指标。
• PyTorch-Ignite 容易扩展。
高级特性
在这一节中,我们将为经验丰富的用户介绍 PyTorch-Ignite 的一些高级特性。我们将更深入地讨论事件、处理器和指标,以及在 GPU 和 TPU 上的分布式计算。如果您是初学者,现在可以先跳过这部分,日后再回来阅读。
事件与处理器的强大功能
通过快速入门示例,我们已经见识到了事件和处理器在需要时执行任意数量函数的完美适用性。除此之外,我们还提供了几种方法来进一步扩展这些功能,包括:
• 内置事件的过滤功能
• 堆叠事件以共享操作
• 添加自定义事件,以超越内置标准事件
让我们更详细地探讨这些特性。
内置事件过滤器
用户可以简单地过滤掉事件,以跳过触发处理器。让我们创建一个虚拟的训练器:
from ignite.engine import Engine, Events
trainer = Engine(lambda e, batch: None)
让我们考虑一个用例,我们希望训练一个模型,并定期在几个开发数据集上运行其验证,例如 devset1 和 devset2:
# We run the validation on devset1 every 5 epochs
@trainer.on(Events.EPOCH_COMPLETED(every=5))
def run_validation1():
print("Epoch {}: Validation on devset 1".format(trainer.state.epoch))
# evaluator.run(devset1) # commented out for demo purposes
# We run another validation on devset2 every 10 epochs
@trainer.on(Events.EPOCH_COMPLETED(every=10))
def run_validation2():
print("Epoch {}: Validation on devset 2".format(trainer.state.epoch))
# evaluator.run(devset2) # commented out for demo purposes
train_data = [0, 1, 2, 3, 4]
trainer.run(train_data, max_epochs=50)
Epoch 5: Validation on devset 1
Epoch 10: Validation on devset 1
Epoch 10: Validation on devset 2
Epoch 15: Validation on devset 1
Epoch 20: Validation on devset 1
Epoch 20: Validation on devset 2
Epoch 25: Validation on devset 1
Epoch 30: Validation on devset 1
Epoch 30: Validation on devset 2
Epoch 35: Validation on devset 1
Epoch 40: Validation on devset 1
Epoch 40: Validation on devset 2
Epoch 45: Validation on devset 1
Epoch 50: Validation on devset 1
Epoch 50: Validation on devset 2
现在让我们考虑另一种情况,当我们达到特定的 epoch 或迭代时,我们想要进行一次性的变更。例如,让我们在第 5 个 epoch 将训练数据集从低分辨率图像更改为高分辨率图像:
def train_step(e, batch):
print("Epoch {} - {} : batch={}".format(e.state.epoch, e.state.iteration, batch))
trainer = Engine(train_step)
small_res_data = [0, 1, 2, ]
high_res_data = [10, 11, 12]
# We run the following handler once on 5-th epoch started
@trainer.on(Events.EPOCH_STARTED(once=5))
def change_train_dataset():
print("Epoch {}: Change training dataset".format(trainer.state.epoch))
trainer.set_data(high_res_data)
trainer.run(small_res_data, max_epochs=10)
Epoch 1 - 1 : batch=0
Epoch 1 - 2 : batch=1
Epoch 1 - 3 : batch=2
Epoch 2 - 4 : batch=0
Epoch 2 - 5 : batch=1
Epoch 2 - 6 : batch=2
Epoch 3 - 7 : batch=0
Epoch 3 - 8 : batch=1
Epoch 3 - 9 : batch=2
Epoch 4 - 10 : batch=0
Epoch 4 - 11 : batch=1
Epoch 4 - 12 : batch=2
Epoch 5: Change training dataset
Epoch 5 - 13 : batch=10
Epoch 5 - 14 : batch=11
Epoch 5 - 15 : batch=12
Epoch 6 - 16 : batch=10
Epoch 6 - 17 : batch=11
Epoch 6 - 18 : batch=12
Epoch 7 - 19 : batch=10
Epoch 7 - 20 : batch=11
Epoch 7 - 21 : batch=12
Epoch 8 - 22 : batch=10
Epoch 8 - 23 : batch=11
Epoch 8 - 24 : batch=12
Epoch 9 - 25 : batch=10
Epoch 9 - 26 : batch=11
Epoch 9 - 27 : batch=12
Epoch 10 - 28 : batch=10
Epoch 10 - 29 : batch=11
Epoch 10 - 30 : batch=12
现在,让我们来考虑另一种情景,我们希望能够触发一个具有完全定制化逻辑的处理器。例如,我们想在训练损失达到某个特定条件时,导出模型的梯度:
# Let's predefine for simplicity training losses
train_losses = [2.0, 1.9, 1.7, 1.5, 1.6, 1.2, 0.9, 0.8, 1.0, 0.8, 0.7, 0.4, 0.2, 0.1, 0.1, 0.01]
trainer = Engine(lambda e, batch: train_losses[e.state.iteration - 1])
# We define our custom logic when to execute a handler
def custom_event_filter(trainer, event):
if 0.1 < trainer.state.output < 1.0:
return True
return False
# We run the following handler every iteration completed under our custom_event_filter condition:
@trainer.on(Events.ITERATION_COMPLETED(event_filter=custom_event_filter))
def dump_model_grads():
print("{} - loss={}: dump model grads".format(trainer.state.iteration, trainer.state.output))
train_data = [0, ]
trainer.run(train_data, max_epochs=len(train_losses))
7 - loss=0.9: dump model grads
8 - loss=0.8: dump model grads
10 - loss=0.8: dump model grads
11 - loss=0.7: dump model grads
12 - loss=0.4: dump model grads
13 - loss=0.2: dump model grads
堆叠事件以实现共享操作
用户可以在不同类型的事件上触发相同的处理器。例如,我们可以设置每隔 3 个 epoch 对模型进行一次验证,并在训练结束时再进行一次验证:
trainer = Engine(lambda e, batch: None)
@trainer.on(Events.EPOCH_COMPLETED(every=3) | Events.COMPLETED)
def run_validation():
print("Epoch {} - event={}: Validation".format(trainer.state.epoch, trainer.last_event_name))
# evaluator.run(devset)
train_data = [0, 1, 2, 3, 4]
trainer.run(train_data, max_epochs=20)
Epoch 3 - event=epoch_completed: Validation
Epoch 6 - event=epoch_completed: Validation
Epoch 9 - event=epoch_completed: Validation
Epoch 12 - event=epoch_completed: Validation
Epoch 15 - event=epoch_completed: Validation
Epoch 18 - event=epoch_completed: Validation
Epoch 20 - event=completed: Validation
添加自定义事件
用户可以添加自己的事件,以超越内置的标准事件。例如,我们可以定义与反向传播和优化器步骤调用相关的新事件。这可以帮助我们以可配置的方式在这些事件上附加特定的处理器。
from ignite.engine import EventEnum
class BackpropEvents(EventEnum):
BACKWARD_STARTED = 'backward_started'
BACKWARD_COMPLETED = 'backward_completed'
OPTIM_STEP_COMPLETED = 'optim_step_completed'
def update(engine, batch):
# ...
# loss = criterion(y_pred, y)
engine.fire_event(BackpropEvents.BACKWARD_STARTED)
# loss.backward()
engine.fire_event(BackpropEvents.BACKWARD_COMPLETED)
# optimizer.step()
engine.fire_event(BackpropEvents.OPTIM_STEP_COMPLETED)
# ...
trainer = Engine(update)
trainer.register_events(*BackpropEvents)
def function_before_backprop():
print("{} - before backprop".format(trainer.state.iteration))
trainer.add_event_handler(BackpropEvents.BACKWARD_STARTED, function_before_backprop)
def function_after_backprop():
print("{} - after backprop".format(trainer.state.iteration))
trainer.add_event_handler(BackpropEvents.BACKWARD_COMPLETED, function_after_backprop)
train_data = [0, 1, 2, 3, 4]
trainer.run(train_data, max_epochs=2)
1 - before backprop
1 - after backprop
2 - before backprop
2 - after backprop
3 - before backprop
3 - after backprop
4 - before backprop
4 - after backprop
5 - before backprop
5 - after backprop
6 - before backprop
6 - after backprop
7 - before backprop
7 - after backprop
8 - before backprop
8 - after backprop
9 - before backprop
9 - after backprop
10 - before backprop
10 - after backprop
即用型指标
PyTorch-Ignite 提供了一整套专为多种深度学习任务(如分类、回归、分割等)设计的指标。这些指标中的大多数能够在线计算感兴趣的数据,无需存储模型的整个输出历史。
* 分类任务:精确度、召回率、准确率、混淆矩阵等。
* 分割任务:Dice 系数、IoU、mIOU 等。
* 约 20 种回归指标,例如均方误差(MSE)、平均绝对误差(MAE)、中位绝对误差等。
* 能够存储每个 epoch 的整个输出历史的指标
* 可以与 scikit-learn 的指标结合使用,如 EpochMetric、AveragePrecision、ROC_AUC 等。
* 易于组合,可用于构建自定义指标。
* 易于扩展,用于创建自定义指标。
PyTorch-Ignite 提供的完整指标列表可以在 ignite.metrics 和 ignite.contrib.metrics 这两个部分找到。
提供了两种类型的公共 API:
* 将指标附加到 Engine 上。
* 指标的 reset、update、compute 方法。
关于 reset、update、compute 公共 API 的详细信息
我们将使用 Accuracy 指标的一个简单示例来演示这个 API。这个 API 的核心思想是,在每次 update 调用时,我们会在内部累积一些计数器。指标的值在每次 compute 调用时被计算,并且在每次 reset 调用时重置计数器。
import torch
from ignite.metrics import Accuracy
acc = Accuracy()
# Start accumulation
acc.reset()
y_target = torch.tensor([0, 1, 2, 1,])
# y_pred is logits computed by the model
y_pred = torch.tensor([
[10.0, 0.1, -1.0], # correct
[2.0, -1.0, -2.0], # incorrect
[1.0, -1.0, 4.0], # correct
[0.0, 5.0, -1.0], # correct
])
acc.update((y_pred, y_target))
# Compute accuracy on 4 samples
print("After 1st update, accuracy=", acc.compute())
y_target = torch.tensor([1, 2, 0, 2])
# y_pred is logits computed by the model
y_pred = torch.tensor([
[2.0, 1.0, -1.0], # incorrect
[0.0, 1.0, -2.0], # incorrect
[2.6, 1.0, -4.0], # correct
[1.0, -3.0, 2.0], # correct
])
acc.update((y_pred, y_target))
# Compute accuracy on 8 samples
print("After 2nd update, accuracy=", acc.compute())
After 1st update, accuracy= 0.75
After 2nd update, accuracy= 0.625
可组合指标
用户可以轻松地使用现有指标通过算术运算或 PyTorch 方法来组合自己的指标。例如,可以直接编码定义为100 * (1.0 - 准确率)的误差指标:
import torch
from ignite.metrics import Accuracy
acc = Accuracy()
error = 100.0 * (1.0 - acc)
# Start accumulation
acc.reset()
y_target = torch.tensor([0, 1, 2, 1,])
# y_pred is logits computed by the model
y_pred = torch.tensor([
[10.0, 0.1, -1.0], # correct
[2.0, -1.0, -2.0], # incorrect
[1.0, -1.0, 4.0], # correct
[0.0, 5.0, -1.0], # correct
])
acc.update((y_pred, y_target))
# Compute error on 4 samples
print("After 1st update, error=", error.compute())
y_target = torch.tensor([1, 2, 0, 2])
# y_pred is logits computed by the model
y_pred = torch.tensor([
[2.0, 1.0, -1.0], # incorrect
[0.0, 1.0, -2.0], # incorrect
[2.6, 1.0, -4.0], # correct
[1.0, -3.0, 2.0], # correct
])
acc.update((y_pred, y_target))
# Compute err on 8 samples
print("After 2nd update, error=", error.compute())
After 1st update, error= 25.0
After 2nd update, error= 37.5
如果无法通过基础指标的算术运算来表达自定义指标,请遵循此指南来实现自定义指标。
开箱即用的处理器
PyTorch-Ignite 提供了各种常见的处理器,以简化应用程序代码的编写:
* 常用训练处理器:Checkpoint(检查点)、EarlyStopping(提前终止)、Timer(计时器)、TerminateOnNan(遇到 NaN 时终止)
* 优化器参数调度(如学习率、动量等)
* 结合多种调度器、添加热身阶段、循环调度、分段线性调度等!详见示例。
* 时间性能分析
* 日志记录到实验跟踪系统:
* Tensorboard、Visdom、MLflow、Polyaxon、Neptune、Trains 等。
PyTorch-Ignite 提供的处理器的完整列表可以在 ignite.handlers 和 ignite.contrib.handlers 这两部分找到。
常见训练处理器
利用开箱即用的 Checkpoint(检查点)处理器,用户可以轻松地将训练状态或最佳模型保存到文件系统或云存储中。
EarlyStopping(提前终止)和 TerminateOnNan(遇到 NaN 时终止)有助于在训练过程中发生过拟合或发散时及时停止训练。
所有这些功能都可以轻松地一个接一个地添加到训练器中,或者通过辅助方法进行添加。
下面我们来看一个使用辅助方法的示例。
import torch
import torch.nn as nn
import torch.optim as optim
from ignite.engine import create_supervised_trainer, create_supervised_evaluator, Events
from ignite.metrics import Accuracy
import ignite.contrib.engines.common as common
train_data = [[torch.rand(2, 4), torch.randint(0, 5, size=(2, ))] for _ in range(10)]
val_data = [[torch.rand(2, 4), torch.randint(0, 5, size=(2, ))] for _ in range(10)]
epoch_length = len(train_data)
model = nn.Linear(4, 5)
optimizer = optim.SGD(model.parameters(), lr=0.01)
# step_size is expressed in iterations
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=epoch_length, gamma=0.88)
# Let's define some dummy trainer and evaluator
trainer = create_supervised_trainer(model, optimizer, nn.CrossEntropyLoss())
evaluator = create_supervised_evaluator(model, metrics={"accuracy": Accuracy()})
@trainer.on(Events.EPOCH_COMPLETED)
def run_validation():
evaluator.run(val_data)
# training state to save
to_save = {
"trainer": trainer, "model": model,
"optimizer": optimizer, "lr_scheduler": lr_scheduler
}
metric_names = ["batch loss", ]
common.setup_common_training_handlers(
trainer=trainer,
to_save=to_save,
output_path="checkpoints",
save_every_iters=epoch_length,
lr_scheduler=lr_scheduler,
output_names=metric_names,
with_pbars=True,
)
tb_logger = common.setup_tb_logging("tb_logs", trainer, optimizer, evaluators=evaluator)
common.save_best_model_by_val_score(
"best_models",
evaluator=evaluator,
model=model,
metric_name="accuracy",
n_saved=2,
trainer=trainer,
tag="val",
)
trainer.run(train_data, max_epochs=5)
tb_logger.close()
HBox(children=(FloatProgress(value=0.0, max=5.0), HTML(value='')))
ls -all "checkpoints"
ls -all "best_models"
ls -all "tb_logs"
total 12
drwxr-xr-x 2 root root 4096 Aug 31 11:27 .
drwxr-xr-x 1 root root 4096 Aug 31 11:27 ..
-rw------- 1 root root 1657 Aug 31 11:27 training_checkpoint_50.pt
total 16
drwxr-xr-x 2 root root 4096 Aug 31 11:27 .
drwxr-xr-x 1 root root 4096 Aug 31 11:27 ..
-rw------- 1 root root 1145 Aug 31 11:27 'best_model_2_val_accuracy=0.3000.pt'
-rw------- 1 root root 1145 Aug 31 11:27 'best_model_3_val_accuracy=0.3000.pt'
total 12
drwxr-xr-x 2 root root 4096 Aug 31 11:27 .
drwxr-xr-x 1 root root 4096 Aug 31 11:27 ..
-rw-r--r-- 1 root root 325 Aug 31 11:27 events.out.tfevents.1598873224.3aa7adc24d3d.115.1
在上述代码中,common.setup_common_training_handlers 方法添加了 TerminateOnNan 处理器,添加了一个处理器来使用以迭代表示的 lr_scheduler(学习率调度器),添加了训练状态的检查点,将批量损失输出作为用于日志记录的指数移动平均指标,还为训练器添加了一个进度条。
接下来,common.setup_tb_logging 方法返回一个 TensorBoard 日志记录器,它被自动配置为记录训练器的指标(即批量损失)、优化器的学习率以及评估器的指标。
最后,common.save_best_model_by_val_score 设置了一个处理器,用于根据验证精度指标保存最佳的两个模型。
分布式和 XLA 设备支持
PyTorch 提供了一个分布式通信包,用于编写和运行多个设备和机器上的并行应用程序。
原生接口提供了常用的集体操作,并允许使用 torch DistributedDataParallel 模块和众所周知的 mpi、gloo 和 nccl 后端,无缝地处理多 CPU 和多 GPU 计算。
最近,用户还可以在 XLA 设备(如 TPU)上运行 PyTorch,使用 torch_xla 包。
然而,编写在 GPU 和 TPU 上工作的分布式训练代码并非易事,因为一些 API 的特殊性。
PyTorch-Ignite 在 0.4 版本中引入的 ignite.distributed 包的目的是统一原生 torch.distributed API、XLA 设备上的 torch_xla API 的代码,同时还支持其他分布式框架(如 Horovod)。
为了使分布式配置设置更加简单,引入了 Parallel 上下文管理器:
import ignite.distributed as idist
def training(local_rank, config, **kwargs):
print(idist.get_rank(), ': run with config:', config, '- backend=', idist.backend())
# do the training ...
backend = 'gloo' # or "nccl" or "xla-tpu"
dist_configs = {'nproc_per_node': 2}
# dist_configs["start_method"] = "fork" # If using Jupyter Notebook
config = {'c': 12345}
with idist.Parallel(backend=backend, **dist_configs) as parallel:
parallel.run(training, config, a=1, b=2)
2020-08-31 11:27:07,128 ignite.distributed.launcher.Parallel INFO: Initialized distributed launcher with backend: 'gloo'
2020-08-31 11:27:07,128 ignite.distributed.launcher.Parallel INFO: - Parameters to spawn processes:
nproc_per_node: 2
nnodes: 1
node_rank: 0
2020-08-31 11:27:07,128 ignite.distributed.launcher.Parallel INFO: Spawn function '<function training at 0x7f32b8ac9d08>' in 2 processes
0 : run with config: {'c': 12345} - backend= gloo
1 : run with config: {'c': 12345} - backend= gloo
2020-08-31 11:27:09,959 ignite.distributed.launcher.Parallel INFO: End of run
上述代码只需稍作修改,就可以在 GPU、单节点多 GPU、单个或多个 TPU 等上运行。它可以通过 torch.distributed.launch 工具执行,或者通过 Python 来生成所需数量的进程。更多详细信息,请参阅文档。
此外,像 auto_model()、auto_optim() 和 auto_dataloader() 这样的方法有助于以透明的方式将提供的模型、优化器和数据加载器适配到现有配置中:
# main.py
import ignite.distributed as idist
def training(local_rank, config, **kwargs):
print(idist.get_rank(), ": run with config:", config, "- backend=", idist.backend())
train_loader = idist.auto_dataloader(dataset, batch_size=32, num_workers=12, shuffle=True, **kwargs)
# batch size, num_workers and sampler are automatically adapted to existing configuration
# ...
model = resnet50()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# if training with Nvidia/Apex for Automatic Mixed Precision (AMP)
# model, optimizer = amp.initialize(model, optimizer, opt_level=opt_level)
model = idist.auto_model(model)
# model is DDP or DP or just itself according to existing configuration
# ...
optimizer = idist.auto_optim(optimizer)
# optimizer is itself, except XLA configuration and overrides `step()` method.
# User can safely call `optimizer.step()` (behind `xm.optimizer_step(optimizier)` is performed)
backend = "nccl" # torch native distributed configuration on multiple GPUs
# backend = "xla-tpu" # XLA TPUs distributed configuration
# backend = None # no distributed configuration
with idist.Parallel(backend=backend, **dist_configs) as parallel:
parallel.run(training, config, a=1, b=2)
请注意,这些 auto_* 方法是可选的;用户可以自由地使用其中一些方法,并在需要时手动设置代码的某些部分。这种方法的优势在于没有必然的对象补丁和覆盖。
关于 PyTorch-Ignite 提供的分布式助手的更多细节可以在文档中找到。关于在 CIFAR10 上训练的完整示例可以在这里找到。
一个详细的带有分布式助手的教程已经发布在这里。
三、More
要了解更多关于 PyTorch-Ignite 的信息,请查看官方网站:https://pytorch-ignite.ai,以及官方的教程和操作指南。
官方还提供了 PyTorch-Ignite 代码生成器应用程序:https://code-generator.pytorch-ignite.ai/,以便在不需要从头开始编写一切的情况下开始处理任务。
PyTorch-Ignite 的代码可在 GitHub 上获得:https://github.com/pytorch/ignite。