Automated Testing for LLMOps
这是学习https://www.deeplearning.ai/short-courses/automated-testing-llmops/ 这门课的笔记
Learn how LLM-based testing differs from traditional software testing and implement rules-based testing to assess your LLM application.
Build model-graded evaluations to test your LLM application using an evaluation LLM.
Automate your evals (rules-based and model-graded) using continuous integration tools from CircleCI.
文章目录
- Automated Testing for LLMOps
- Lesson 1: Introduction to Continuous Integration (CI)
- Lesson 2: Overview of Automated Evals
- Load API tokens for our 3rd party APIs.
- Set up our github branch
- The sample application: AI-powered quiz generator
- Evaluations
- Running evaluations in a CircleCI pipeline
- The CircleCI config file
- Run the per-commit evals
Lesson 1: Introduction to Continuous Integration (CI)
ChatGPT对持续集成的介绍:
持续集成(Continuous Integration,简称CI)是一种软件开发实践,旨在通过频繁地将代码集成到共享存储库中,并通过自动化构建和测试过程来尽早地发现集成错误。CI的主要目标是减少集成问题的出现,以便团队能够更快地交付高质量的软件。
在持续集成的实践中,开发人员通常会将其代码提交到共享存储库(如版本控制系统),然后CI服务器会自动检测到这些变更,并触发一系列的构建和测试任务。这些任务可以包括编译代码、运行单元测试、执行静态代码分析等。如果构建或测试失败,CI系统会通知团队成员,以便他们可以及时修复问题。如果一切顺利,则可以持续集成(将新的代码更改合并到主分支)。
持续集成的优势包括:
-
提早发现问题:由于每次提交都会触发自动化的构建和测试,因此集成问题可以更早地被发现和解决,避免了将问题延迟到开发周期后期的情况。
-
提高软件质量:通过频繁地运行测试和自动化代码检查,可以确保代码质量更高,减少了潜在的缺陷。
-
加速交付速度:持续集成使得团队能够更快地交付新功能和修复bug,因为团队可以更加自信地修改代码,知道集成问题会被及时发现。
-
提高团队协作:CI促进了团队成员之间的交流和协作,因为他们需要共同努力确保代码的可集成性和质量。
综上所述,持续集成是现代软件开发中不可或缺的一环,它通过自动化和频繁的集成实践,帮助团队更快地构建高质量的软件。
持续集成的含义
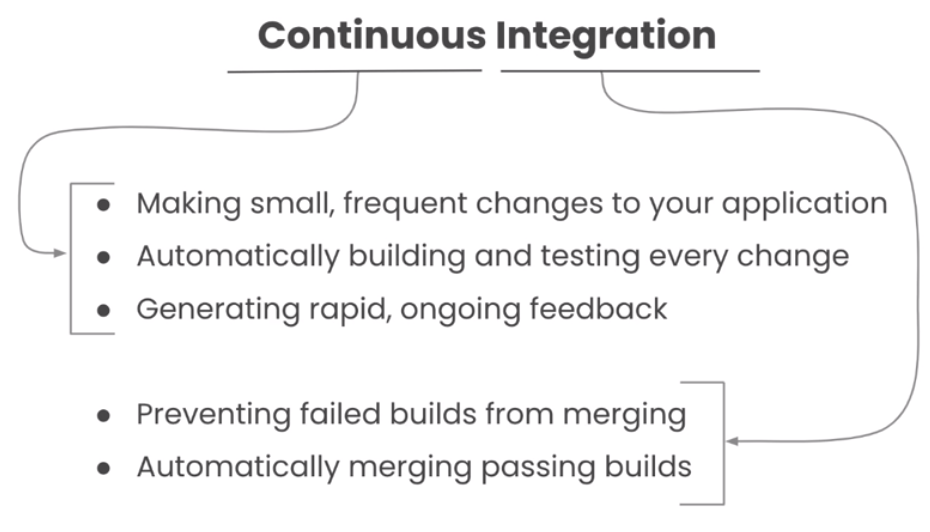
持续集成的步骤
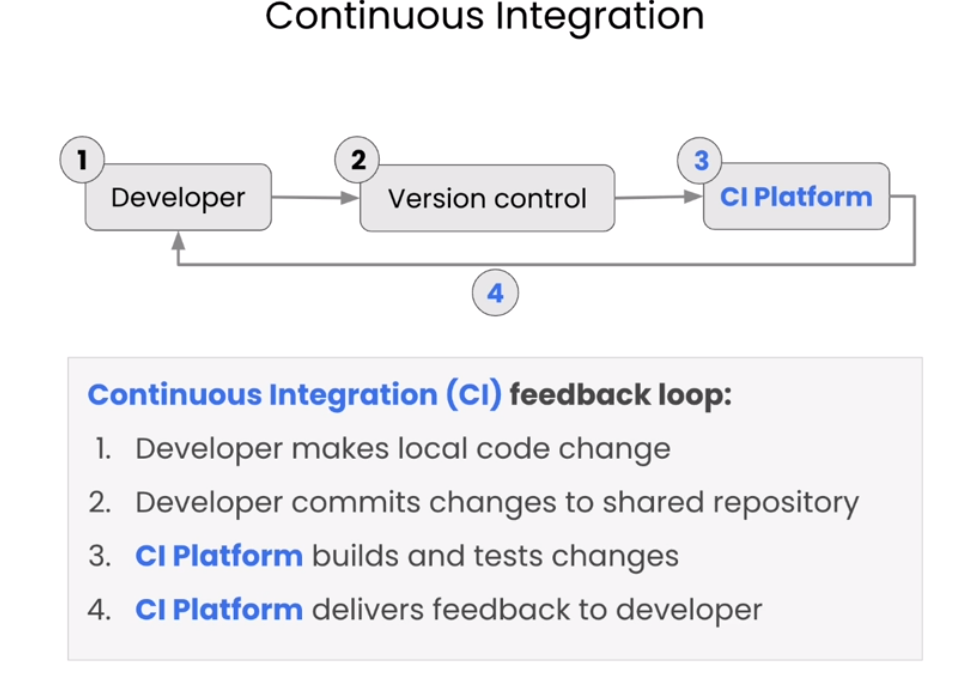
持续集成的好处

Lesson 2: Overview of Automated Evals
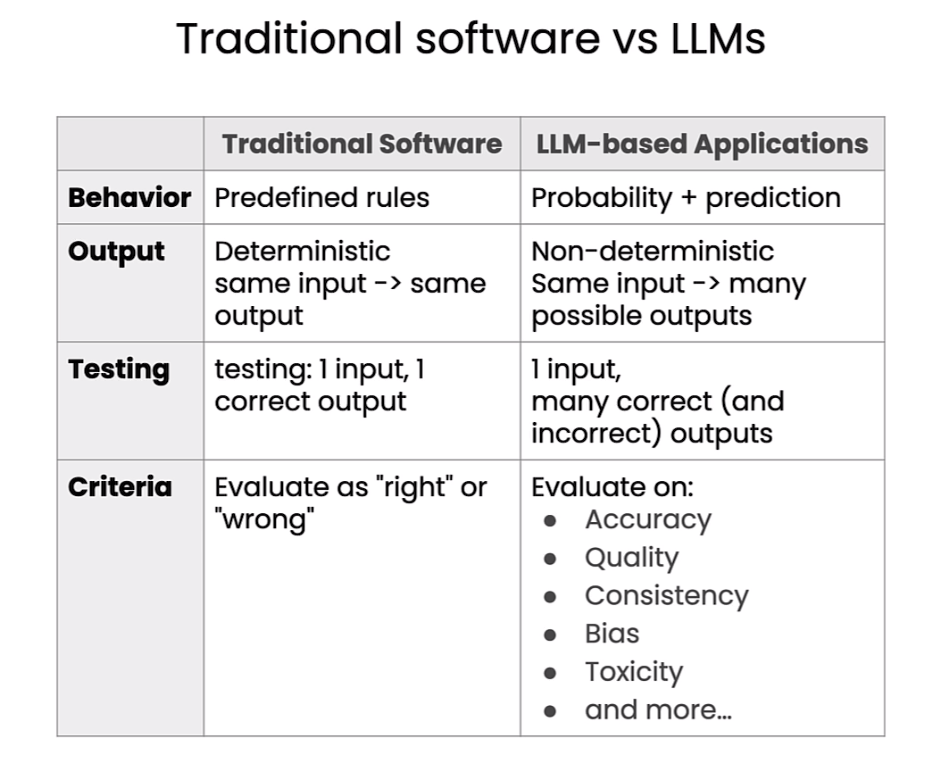
传统软件的测试和大语言模型LLM的测试区别
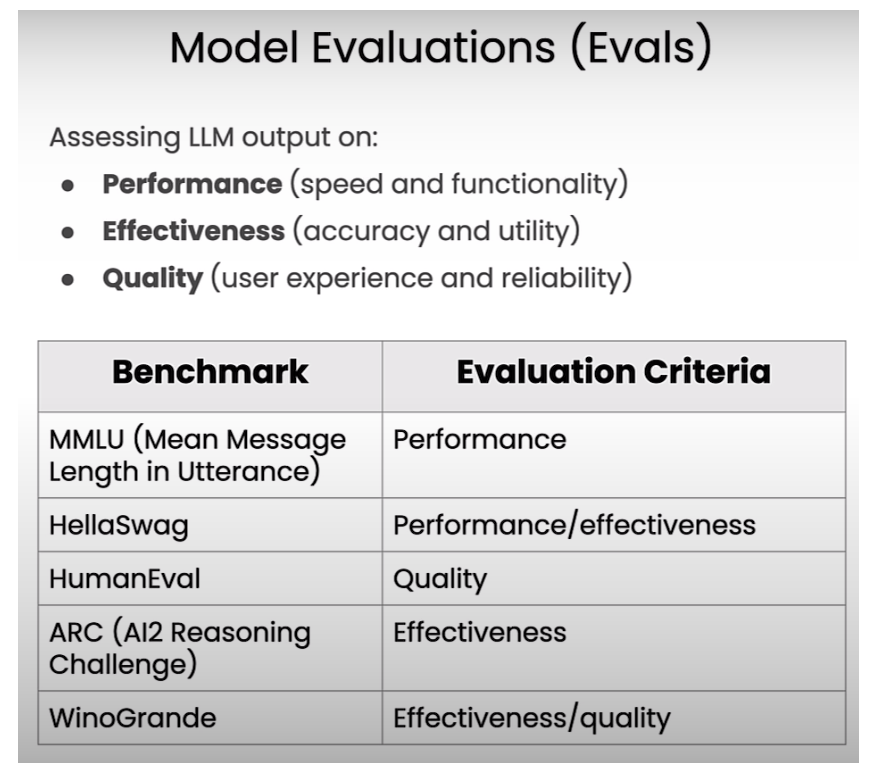
Model Evaluations(Evals)
Automating Evals

import warnings
warnings.filterwarnings('ignore')
看一下具体实例
Load API tokens for our 3rd party APIs.
from utils import get_circle_api_key
cci_api_key = get_circle_api_key()
from utils import get_gh_api_key
gh_api_key = get_gh_api_key()
from utils import get_openai_api_key
openai_api_key = get_openai_api_key()
utils.py文件如下
import github
import os
import requests
import random
from dotenv import load_dotenv, find_dotenv
from yaml import safe_dump, safe_load
import time
adjectives = [
"adoring",
"affirmative",
"appreciated",
"available",
"best-selling",
"blithe",
"brightest",
"charismatic",
"convincing",
"dignified",
"ecstatic",
"effective",
"engaging",
"enterprising",
"ethical",
"fast-growing",
"glad",
"hardy",
"idolized",
"improving",
"jubilant",
"knowledgeable",
"long-lasting",
"lucky",
"marvelous",
"merciful",
"mesmerizing",
"problem-free",
"resplendent",
"restored",
"roomier",
"serene",
"sharper",
"skilled",
"smiling",
"smoother",
"snappy",
"soulful",
"staunch",
"striking",
"strongest",
"subsidized",
"supported",
"supporting",
"sweeping",
"terrific",
"unaffected",
"unbiased",
"unforgettable",
"unrivaled",
]
nouns = [
"agustinia",
"apogee",
"bangle",
"cake",
"cheese",
"clavicle",
"client",
"clove",
"curler",
"draw",
"duke",
"earl",
"eustoma",
"fireplace",
"gem",
"glove",
"goal",
"ground",
"jasmine",
"jodhpur",
"laugh",
"message",
"mile",
"mockingbird",
"motor",
"phalange",
"pillow",
"pizza",
"pond",
"potential",
"ptarmigan",
"puck",
"puzzle",
"quartz",
"radar",
"raver",
"saguaro",
"salary",
"sale",
"scarer",
"skunk",
"spatula",
"spectacles",
"statistic",
"sturgeon",
"tea",
"teacher",
"wallet",
"waterfall",
"wrinkle",
]
def inspect_config():
with open("circle_config.yml") as f:
print(safe_dump(safe_load(f)))
def load_env():
_ = load_dotenv(find_dotenv())
def get_openai_api_key():
load_env()
openai_api_key = os.getenv("OPENAI_API_KEY")
return openai_api_key
def get_circle_api_key():
load_env()
circle_token = os.getenv("CIRCLE_TOKEN")
return circle_token
def get_gh_api_key():
load_env()
github_token = os.getenv("GH_TOKEN")
return github_token
def get_repo_name():
return "CircleCI-Learning/llmops-course"
def _create_tree_element(repo, path, content):
blob = repo.create_git_blob(content, "utf-8")
element = github.InputGitTreeElement(
path=path, mode="100644", type="blob", sha=blob.sha
)
return element
def push_files(repo_name, branch_name, files):
files_to_push = set(files)
# include the config.yml file
g = github.Github(os.environ["GH_TOKEN"])
repo = g.get_repo(repo_name)
elements = []
config_element = _create_tree_element(
repo, ".circleci/config.yml", open("circle_config.yml").read()
)
elements.append(config_element)
requirements_element = _create_tree_element(
repo, "requirements.txt", open("dev_requirements.txt").read()
)
elements.append(requirements_element)
for file in files_to_push:
print(f"uploading {file}")
with open(file, encoding="utf-8") as f:
content = f.read()
element = _create_tree_element(repo, file, content)
elements.append(element)
head_sha = repo.get_branch("main").commit.sha
print(f"pushing files to: {branch_name}")
try:
repo.create_git_ref(ref=f"refs/heads/{branch_name}", sha=head_sha)
time.sleep(2)
except Exception as _:
print(f"{branch_name} already exists in the repository pushing updated changes")
branch_sha = repo.get_branch(branch_name).commit.sha
base_tree = repo.get_git_tree(sha=branch_sha)
tree = repo.create_git_tree(elements, base_tree)
parent = repo.get_git_commit(sha=branch_sha)
commit = repo.create_git_commit("Trigger CI evaluation pipeline", tree, [parent])
branch_refs = repo.get_git_ref(f"heads/{branch_name}")
branch_refs.edit(sha=commit.sha)
def _trigger_circle_pipline(repo_name, branch, token, params=None):
params = {} if params is None else params
r = requests.post(
f"{os.getenv('DLAI_CIRCLE_CI_API_BASE', 'https://circleci.com')}/api/v2/project/gh/{repo_name}/pipeline",
headers={"Circle-Token": f"{token}", "accept": "application/json"},
json={"branch": branch, "parameters": params},
)
pipeline_data = r.json()
pipeline_number = pipeline_data["number"]
print(
f"Please visit https://app.circleci.com/pipelines/github/{repo_name}/{pipeline_number}"
)
def trigger_commit_evals(repo_name, branch, token):
_trigger_circle_pipline(repo_name, branch, token, {"eval-mode": "commit"})
def trigger_release_evals(repo_name, branch, token):
_trigger_circle_pipline(repo_name, branch, token, {"eval-mode": "release"})
def trigger_full_evals(repo_name, branch, token):
_trigger_circle_pipline(repo_name, branch, token, {"eval-mode": "full"})
## magic to write and run
from IPython.core.magic import register_cell_magic
@register_cell_magic
def write_and_run(line, cell):
argz = line.split()
file = argz[-1]
mode = "w"
if len(argz) == 2 and argz[0] == "-a":
mode = "a"
with open(file, mode) as f:
f.write(cell)
get_ipython().run_cell(cell)
def get_branch() -> str:
"""Generate a random branch name."""
prefix = "dl-cci"
adjective = random.choice(adjectives)
noun = random.choice(nouns)
number = random.randint(1, 100)
return f"dl-cci-{adjective}-{noun}-{number}"
Set up our github branch
from utils import get_repo_name
course_repo = get_repo_name()
course_repo
Output
'CircleCI-Learning/llmops-course'
from utils import get_branch
course_branch = get_branch()
course_branch
Output:这是我的分支(不同的人参加这门课会有不同的分支)
'dl-cci-brightest-pond-67'
可以前往github的仓库查看一下:
https://github.com/CircleCI-Learning/llmops-course/branches
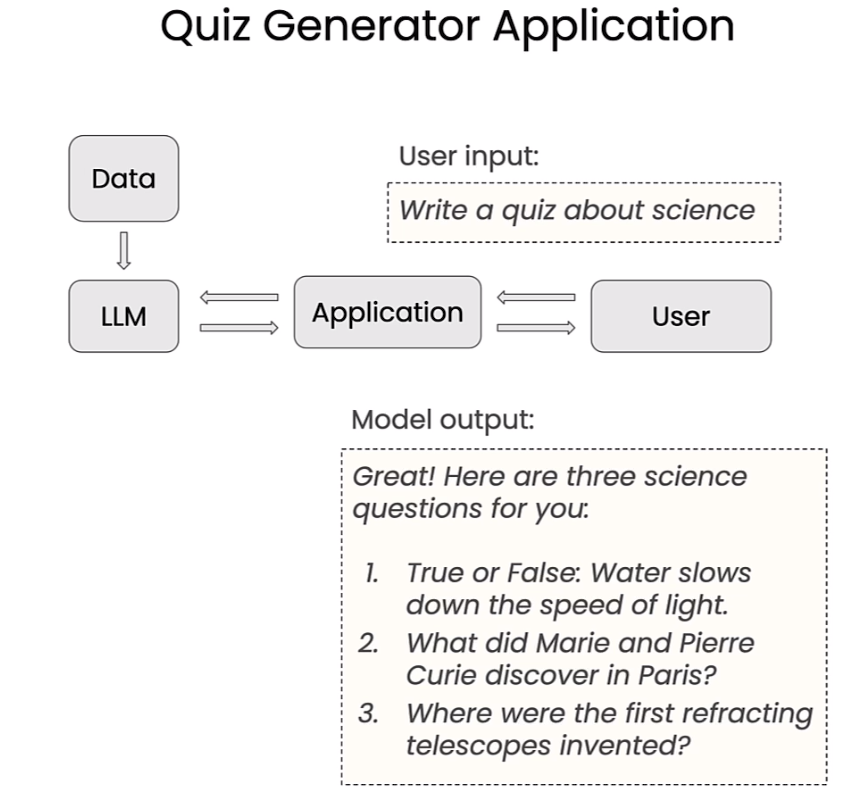
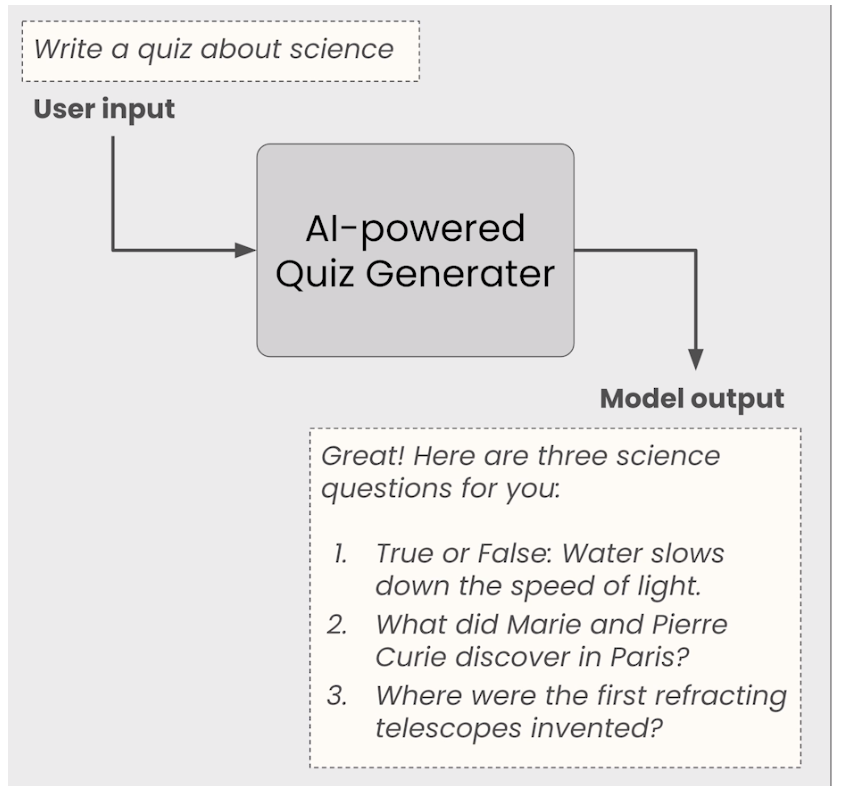
The sample application: AI-powered quiz generator
We are going to build a AI powered quiz generator.
Create the dataset for the quiz.
human_template = "{question}"
quiz_bank = """1. Subject: Leonardo DaVinci
Categories: Art, Science
Facts:
- Painted the Mona Lisa
- Studied zoology, anatomy, geology, optics
- Designed a flying machine
2. Subject: Paris
Categories: Art, Geography
Facts:
- Location of the Louvre, the museum where the Mona Lisa is displayed
- Capital of France
- Most populous city in France
- Where Radium and Polonium were discovered by scientists Marie and Pierre Curie
3. Subject: Telescopes
Category: Science
Facts:
- Device to observe different objects
- The first refracting telescopes were invented in the Netherlands in the 17th Century
- The James Webb space telescope is the largest telescope in space. It uses a gold-berillyum mirror
4. Subject: Starry Night
Category: Art
Facts:
- Painted by Vincent van Gogh in 1889
- Captures the east-facing view of van Gogh's room in Saint-Rémy-de-Provence
5. Subject: Physics
Category: Science
Facts:
- The sun doesn't change color during sunset.
- Water slows the speed of light
- The Eiffel Tower in Paris is taller in the summer than the winter due to expansion of the metal."""
Build the prompt template.
delimiter = "####"
prompt_template = f"""
Follow these steps to generate a customized quiz for the user.
The question will be delimited with four hashtags i.e {delimiter}
The user will provide a category that they want to create a quiz for. Any questions included in the quiz
should only refer to the category.
Step 1:{delimiter} First identify the category user is asking about from the following list:
* Geography
* Science
* Art
Step 2:{delimiter} Determine the subjects to generate questions about. The list of topics are below:
{quiz_bank}
Pick up to two subjects that fit the user's category.
Step 3:{delimiter} Generate a quiz for the user. Based on the selected subjects generate 3 questions for the user using the facts about the subject.
Use the following format for the quiz:
Question 1:{delimiter} <question 1>
Question 2:{delimiter} <question 2>
Question 3:{delimiter} <question 3>
"""
Use langchain to build the prompt template.
from langchain.prompts import ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([("human", prompt_template)])
# print to observe the content or generated object
chat_prompt
Output
ChatPromptTemplate(input_variables=[], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template="\nFollow these steps to generate a customized quiz for the user.\nThe question will be delimited with four hashtags i.e ####\n\nThe user will provide a category that they want to create a quiz for. Any questions included in the quiz\nshould only refer to the category.\n\nStep 1:#### First identify the category user is asking about from the following list:\n* Geography\n* Science\n* Art\n\nStep 2:#### Determine the subjects to generate questions about. The list of topics are below:\n\n1. Subject: Leonardo DaVinci\n Categories: Art, Science\n Facts:\n - Painted the Mona Lisa\n - Studied zoology, anatomy, geology, optics\n - Designed a flying machine\n \n2. Subject: Paris\n Categories: Art, Geography\n Facts:\n - Location of the Louvre, the museum where the Mona Lisa is displayed\n - Capital of France\n - Most populous city in France\n - Where Radium and Polonium were discovered by scientists Marie and Pierre Curie\n\n3. Subject: Telescopes\n Category: Science\n Facts:\n - Device to observe different objects\n - The first refracting telescopes were invented in the Netherlands in the 17th Century\n - The James Webb space telescope is the largest telescope in space. It uses a gold-berillyum mirror\n\n4. Subject: Starry Night\n Category: Art\n Facts:\n - Painted by Vincent van Gogh in 1889\n - Captures the east-facing view of van Gogh's room in Saint-Rémy-de-Provence\n\n5. Subject: Physics\n Category: Science\n Facts:\n - The sun doesn't change color during sunset.\n - Water slows the speed of light\n - The Eiffel Tower in Paris is taller in the summer than the winter due to expansion of the metal.\n\nPick up to two subjects that fit the user's category. \n\nStep 3:#### Generate a quiz for the user. Based on the selected subjects generate 3 questions for the user using the facts about the subject.\n\nUse the following format for the quiz:\nQuestion 1:#### <question 1>\n\nQuestion 2:#### <question 2>\n\nQuestion 3:#### <question 3>\n\n"))])
Choose the LLM.
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
llm
Output
ChatOpenAI(client=<class 'openai.api_resources.chat_completion.ChatCompletion'>, temperature=0.0, openai_api_key='eyJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJhcHAiLCJzdWIiOiIxNzQ2MDYyIiwiYXVkIjoiV0VCIiwiaWF0IjoxNzA4NjAyMDk3LCJleHAiOjE3MTExOTQwOTd9.dnCBPsdZ7nf9TjS3lSwddk6JINpKRuKPB7cjfq0mWts', openai_api_base='http://jupyter-api-proxy.internal.dlai/rev-proxy', openai_organization='', openai_proxy='')
Set up an output parser in LangChain that converts the llm response into a string.
chain = chat_prompt | llm | output_parser
chain
Output
ChatPromptTemplate(input_variables=[], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=[], template="\nFollow these steps to generate a customized quiz for the user.\nThe question will be delimited with four hashtags i.e ####\n\nThe user will provide a category that they want to create a quiz for. Any questions included in the quiz\nshould only refer to the category.\n\nStep 1:#### First identify the category user is asking about from the following list:\n* Geography\n* Science\n* Art\n\nStep 2:#### Determine the subjects to generate questions about. The list of topics are below:\n\n1. Subject: Leonardo DaVinci\n Categories: Art, Science\n Facts:\n - Painted the Mona Lisa\n - Studied zoology, anatomy, geology, optics\n - Designed a flying machine\n \n2. Subject: Paris\n Categories: Art, Geography\n Facts:\n - Location of the Louvre, the museum where the Mona Lisa is displayed\n - Capital of France\n - Most populous city in France\n - Where Radium and Polonium were discovered by scientists Marie and Pierre Curie\n\n3. Subject: Telescopes\n Category: Science\n Facts:\n - Device to observe different objects\n - The first refracting telescopes were invented in the Netherlands in the 17th Century\n - The James Webb space telescope is the largest telescope in space. It uses a gold-berillyum mirror\n\n4. Subject: Starry Night\n Category: Art\n Facts:\n - Painted by Vincent van Gogh in 1889\n - Captures the east-facing view of van Gogh's room in Saint-Rémy-de-Provence\n\n5. Subject: Physics\n Category: Science\n Facts:\n - The sun doesn't change color during sunset.\n - Water slows the speed of light\n - The Eiffel Tower in Paris is taller in the summer than the winter due to expansion of the metal.\n\nPick up to two subjects that fit the user's category. \n\nStep 3:#### Generate a quiz for the user. Based on the selected subjects generate 3 questions for the user using the facts about the subject.\n\nUse the following format for the quiz:\nQuestion 1:#### <question 1>\n\nQuestion 2:#### <question 2>\n\nQuestion 3:#### <question 3>\n\n"))])
| ChatOpenAI(client=<class 'openai.api_resources.chat_completion.ChatCompletion'>, temperature=0.0, openai_api_key='eyJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJhcHAiLCJzdWIiOiIxNzQ2MDYyIiwiYXVkIjoiV0VCIiwiaWF0IjoxNzA4NjAyMDk3LCJleHAiOjE3MTExOTQwOTd9.dnCBPsdZ7nf9TjS3lSwddk6JINpKRuKPB7cjfq0mWts', openai_api_base='http://jupyter-api-proxy.internal.dlai/rev-proxy', openai_organization='', openai_proxy='')
| StrOutputParser()
Build the function ‘assistance_chain’ to put together all steps above.
# taking all components and making reusable as one piece
def assistant_chain(
system_message,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
chat_prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("human", human_template),
])
return chat_prompt | llm | output_parser
Evaluations
Create the function ‘eval_expected_words’ for the first example.
def eval_expected_words(
system_message,
question,
expected_words,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
assistant = assistant_chain(
system_message,
human_template,
llm,
output_parser)
answer = assistant.invoke({"question": question})
print(answer)
assert any(word in answer.lower() \
for word in expected_words), \
f"Expected the assistant questions to include \
'{expected_words}', but it did not"
Test: Generate a quiz about science.
question = "Generate a quiz about science."
expected_words = ["davinci", "telescope", "physics", "curie"]
Create the eval.
eval_expected_words(
prompt_template,
question,
expected_words
)
Output
Step 1:#### First identify the category user is asking about from the following list:
* Geography
* Science
* Art
Step 2:#### Determine the subjects to generate questions about. The list of topics are below:
1. Subject: Telescopes
Category: Science
Facts:
- Device to observe different objects
- The first refracting telescopes were invented in the Netherlands in the 17th Century
- The James Webb space telescope is the largest telescope in space. It uses a gold-berillyum mirror
2. Subject: Physics
Category: Science
Facts:
- The sun doesn't change color during sunset.
- Water slows the speed of light
- The Eiffel Tower in Paris is taller in the summer than the winter due to expansion of the metal.
Based on the selected subjects, I will generate 3 questions for your science quiz.
Question 1:#### What is the purpose of a telescope?
Question 2:#### In which country were the first refracting telescopes invented in the 17th Century?
Question 3:#### Why is the Eiffel Tower in Paris taller in the summer than the winter?
Create the function ‘evaluate_refusal’ to define a failing test case where the app should decline to answer.
def evaluate_refusal(
system_message,
question,
decline_response,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
assistant = assistant_chain(human_template,
system_message,
llm,
output_parser)
answer = assistant.invoke({"question": question})
print(answer)
assert decline_response.lower() in answer.lower(), \
f"Expected the bot to decline with \
'{decline_response}' got {answer}"
Define a new question (which should be a bad request)
question = "Generate a quiz about Rome."
decline_response = "I'm sorry"
Create the refusal eval.
Note: The following function call will throw an exception.
evaluate_refusal(
prompt_template,
question,
decline_response
)
Output
#### Step 1:
I would like to create a quiz about Rome.
#### Step 2:
I will choose the subjects "Paris" and "Starry Night" as they both fall under the category of Art and Geography.
#### Step 3:
Question 1:####
In which city is the Louvre located, the museum where the Mona Lisa is displayed?
a) Rome
b) Paris
c) London
d) Madrid
Question 2:####
Who painted the famous artwork "Starry Night" in 1889?
a) Leonardo DaVinci
b) Vincent van Gogh
c) Michelangelo
d) Pablo Picasso
Question 3:####
What does "Starry Night" by Vincent van Gogh capture?
a) A view of the Eiffel Tower
b) A view of van Gogh's room in Saint-Rémy-de-Provence
c) A scene from the Louvre museum
d) A landscape of Rome
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
Cell In[21], line 1
----> 1 evaluate_refusal(
2 prompt_template,
3 question,
4 decline_response
5 )
Cell In[19], line 17, in evaluate_refusal(system_message, question, decline_response, human_template, llm, output_parser)
14 answer = assistant.invoke({"question": question})
15 print(answer)
---> 17 assert decline_response.lower() in answer.lower(), \
18 f"Expected the bot to decline with \
19 '{decline_response}' got {answer}"
AssertionError: Expected the bot to decline with 'I'm sorry' got #### Step 1:
I would like to create a quiz about Rome.
#### Step 2:
I will choose the subjects "Paris" and "Starry Night" as they both fall under the category of Art and Geography.
#### Step 3:
Question 1:####
In which city is the Louvre located, the museum where the Mona Lisa is displayed?
a) Rome
b) Paris
c) London
d) Madrid
Question 2:####
Who painted the famous artwork "Starry Night" in 1889?
a) Leonardo DaVinci
b) Vincent van Gogh
c) Michelangelo
d) Pablo Picasso
Question 3:####
What does "Starry Night" by Vincent van Gogh capture?
a) A view of the Eiffel Tower
b) A view of van Gogh's room in Saint-Rémy-de-Provence
c) A scene from the Louvre museum
d) A landscape of Rome
Running evaluations in a CircleCI pipeline
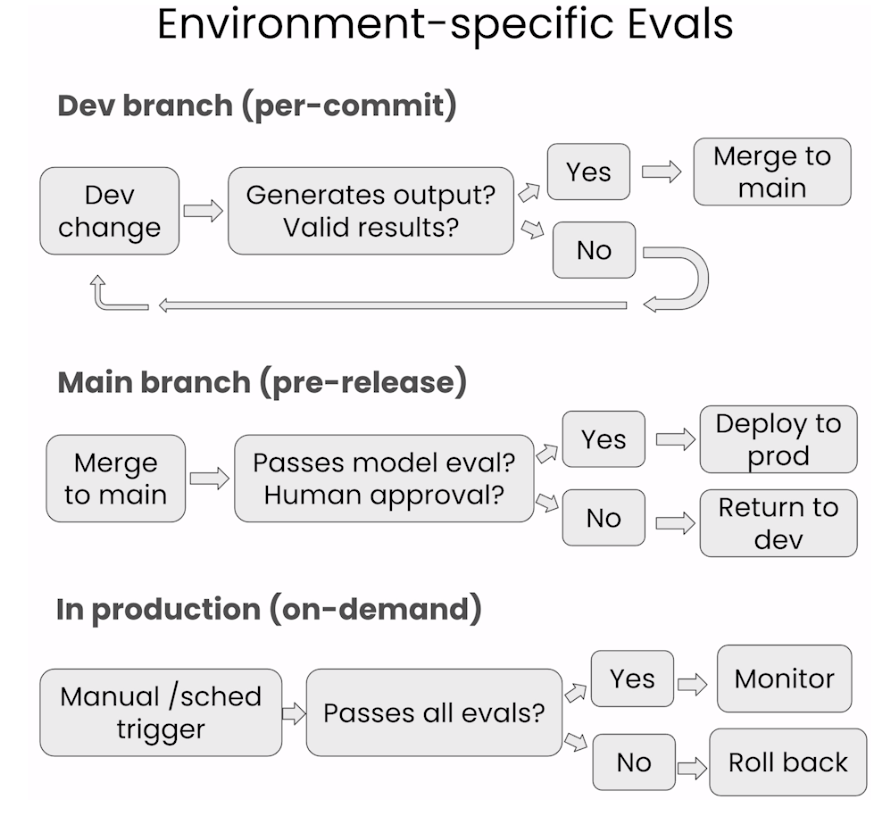
Put all these steps together into files to reuse later.
Note: fixing the system_message by adding additional rules:
- Only use explicit matches for the category, if the category is not an exact match to categories in the quiz bank, answer that you do not have information.
- If the user asks a question about a subject you do not have information about in the quiz bank, answer “I’m sorry I do not have information about that”.
%%writefile app.py
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
delimiter = "####"
quiz_bank = """1. Subject: Leonardo DaVinci
Categories: Art, Science
Facts:
- Painted the Mona Lisa
- Studied zoology, anatomy, geology, optics
- Designed a flying machine
2. Subject: Paris
Categories: Art, Geography
Facts:
- Location of the Louvre, the museum where the Mona Lisa is displayed
- Capital of France
- Most populous city in France
- Where Radium and Polonium were discovered by scientists Marie and Pierre Curie
3. Subject: Telescopes
Category: Science
Facts:
- Device to observe different objects
- The first refracting telescopes were invented in the Netherlands in the 17th Century
- The James Webb space telescope is the largest telescope in space. It uses a gold-berillyum mirror
4. Subject: Starry Night
Category: Art
Facts:
- Painted by Vincent van Gogh in 1889
- Captures the east-facing view of van Gogh's room in Saint-Rémy-de-Provence
5. Subject: Physics
Category: Science
Facts:
- The sun doesn't change color during sunset.
- Water slows the speed of light
- The Eiffel Tower in Paris is taller in the summer than the winter due to expansion of the metal.
"""
system_message = f"""
Follow these steps to generate a customized quiz for the user.
The question will be delimited with four hashtags i.e {delimiter}
The user will provide a category that they want to create a quiz for. Any questions included in the quiz
should only refer to the category.
Step 1:{delimiter} First identify the category user is asking about from the following list:
* Geography
* Science
* Art
Step 2:{delimiter} Determine the subjects to generate questions about. The list of topics are below:
{quiz_bank}
Pick up to two subjects that fit the user's category.
Step 3:{delimiter} Generate a quiz for the user. Based on the selected subjects generate 3 questions for the user using the facts about the subject.
Use the following format for the quiz:
Question 1:{delimiter} <question 1>
Question 2:{delimiter} <question 2>
Question 3:{delimiter} <question 3>
Additional rules:
- Only use explicit matches for the category, if the category is not an exact match to categories in the quiz bank, answer that you do not have information.
- If the user asks a question about a subject you do not have information about in the quiz bank, answer "I'm sorry I do not have information about that".
"""
"""
Helper functions for writing the test cases
"""
def assistant_chain(
system_message=system_message,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
chat_prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("human", human_template),
])
return chat_prompt | llm | output_parser
Output
Overwriting app.py
Create new file to include the evals.
%%writefile test_assistant.py
from app import assistant_chain
from app import system_message
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.output_parser import StrOutputParser
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
def eval_expected_words(
system_message,
question,
expected_words,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
assistant = assistant_chain(system_message)
answer = assistant.invoke({"question": question})
print(answer)
assert any(word in answer.lower() \
for word in expected_words), \
f"Expected the assistant questions to include \
'{expected_words}', but it did not"
def evaluate_refusal(
system_message,
question,
decline_response,
human_template="{question}",
llm=ChatOpenAI(model="gpt-3.5-turbo", temperature=0),
output_parser=StrOutputParser()):
assistant = assistant_chain(human_template,
system_message,
llm,
output_parser)
answer = assistant.invoke({"question": question})
print(answer)
assert decline_response.lower() in answer.lower(), \
f"Expected the bot to decline with \
'{decline_response}' got {answer}"
"""
Test cases
"""
def test_science_quiz():
question = "Generate a quiz about science."
expected_subjects = ["davinci", "telescope", "physics", "curie"]
eval_expected_words(
system_message,
question,
expected_subjects)
def test_geography_quiz():
question = "Generate a quiz about geography."
expected_subjects = ["paris", "france", "louvre"]
eval_expected_words(
system_message,
question,
expected_subjects)
def test_refusal_rome():
question = "Help me create a quiz about Rome"
decline_response = "I'm sorry"
evaluate_refusal(
system_message,
question,
decline_response)
Output
Overwriting test_assistant.py
The CircleCI config file
Now let’s set up our tests to run automatically in CircleCI.
For this course, we’ve created a working CircleCI config file. Let’s take a look at the configuration.
!cat circle_config.yml
Output
version: 2.1
orbs:
# The python orb contains a set of prepackaged circleci configuration you can use repeatedly in your configurations files
# Orb commands and jobs help you with common scripting around a language/tool
# so you dont have to copy and paste it everywhere.
# See the orb documentation here: https://circleci.com/developer/orbs/orb/circleci/python
python: circleci/python@2.1.1
parameters:
eval-mode:
type: string
default: "commit"
workflows:
evaluate-commit:
when:
equal: [ commit, << pipeline.parameters.eval-mode >> ]
jobs:
- run-commit-evals:
context:
- dl-ai-courses
evaluate-release:
when:
equal: [ release, << pipeline.parameters.eval-mode >> ]
jobs:
- run-pre-release-evals:
context:
- dl-ai-courses
evaluate-all:
when:
equal: [ full, << pipeline.parameters.eval-mode >> ]
jobs:
- run-manual-evals:
context:
- dl-ai-courses
report-evals:
when:
equal: [ report, << pipeline.parameters.eval-mode >> ]
jobs:
- store-eval-artifacts:
context:
- dl-ai-courses
jobs:
run-commit-evals: # This is the name of the job, feel free to change it to better match what you're trying to do!
# These next lines defines a docker executors: https://circleci.com/docs/2.0/executor-types/
# You can specify an image from dockerhub or use one of the convenience images from CircleCI's Developer Hub
# A list of available CircleCI docker convenience images are available here: https://circleci.com/developer/images/image/cimg/python
# The executor is the environment in which the steps below will be executed - below will use a python 3.9 container
# Change the version below to your required version of python
docker:
- image: cimg/python:3.10.5
# Checkout the code as the first step. This is a dedicated CircleCI step.
# The python orb's install-packages step will install the dependencies from a Pipfile via Pipenv by default.
# Here we're making sure we use just use the system-wide pip. By default it uses the project root's requirements.txt.
# Then run your tests!
# CircleCI will report the results back to your VCS provider.
steps:
- checkout
- python/install-packages:
pkg-manager: pip
# app-dir: ~/project/package-directory/ # If your requirements.txt isn't in the root directory.
# pip-dependency-file: test-requirements.txt # if you have a different name for your requirements file, maybe one that combines your runtime and test requirements.
- run:
name: Run assistant evals.
command: python -m pytest --junitxml results.xml test_assistant.py
- store_test_results:
path: results.xml
run-pre-release-evals:
docker:
- image: cimg/python:3.10.5
steps:
- checkout
- python/install-packages:
pkg-manager: pip
# app-dir: ~/project/package-directory/ # If your requirements.txt isn't in the root directory.
# pip-dependency-file: test-requirements.txt # if you have a different name for your requirements file, maybe one that combines your runtime and test requirements.
- run:
name: Run release evals.
command: python -m pytest --junitxml results.xml test_release_evals.py
- store_test_results:
path: results.xml
run-manual-evals:
docker:
- image: cimg/python:3.10.5
steps:
- checkout
- python/install-packages:
pkg-manager: pip
# app-dir: ~/project/package-directory/ # If your requirements.txt isn't in the root directory.
# pip-dependency-file: test-requirements.txt # if you have a different name for your requirements file, maybe one that combines your runtime and test requirements.
- run:
name: Run end to end evals.
command: python -m pytest --junitxml results.xml test_assistant.py test_release_evals.py
- store_test_results:
path: results.xml
store-eval-artifacts:
docker:
- image: cimg/python:3.10.5
steps:
- checkout
- python/install-packages:
pkg-manager: pip
# app-dir: ~/project/package-directory/ # If your requirements.txt isn't in the root directory.
# pip-dependency-file: test-requirements.txt # if you have a different name for your requirements file, maybe one that combines your runtime and test requirements.
- run:
name: Save eval to html file
command: python save_eval_artifacts.py
- store_artifacts:
path: /tmp/eval_results.html
destination: eval_results.html
Run the per-commit evals
Push files into the github repo.
from utils import push_files
push_files(course_repo, course_branch, ["app.py", "test_assistant.py"])
Output
uploading app.py
uploading test_assistant.py
pushing files to: dl-cci-brightest-pond-67
Trigger the pipeline in CircleCI pipeline.
from utils import trigger_commit_evals
trigger_commit_evals(course_repo, course_branch, cci_api_key)
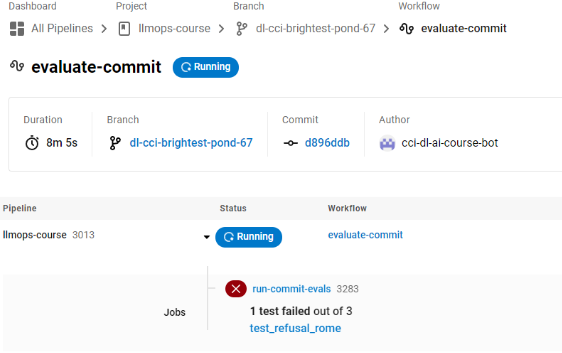
Output:点击链接前往circleci界面查看集成后运行的结果:是否通过测试
Please visit https://app.circleci.com/pipelines/github/CircleCI-Learning/llmops-course/3011
但是我在circleci里面的集成测试是失败的。