前言
Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看似更强大(嗯,看似):它生成的虚拟世界自主可控
第一部分 首个基础世界模型Genie
1.1 Genie是什么
Genie是第一个以无监督方式从未标记的互联网视频中训练的生成式交互环境(the first generative interactive environment trained in an unsupervised manner from unlabelled Internet video)的基础世界模型
其训练数据集包含超过200000小时公开可用的互联网游戏视频,尽管没有动作或文本注释的训练(没有任何动作标签数据),但可以通过学习到的潜在动作空间逐帧进行控制(Our approach, Genie, is trained from a large dataset of over 200,000 hours of publicly available Internet gaming videos and, despite training without action or text annotations, is controllable on a frame-by-frame basis via a learned latent action space)
因为互联网视频通常没有关于正在执行哪个动作、应该控制图像哪一部分的标签,但 Genie 能够专门从互联网视频中学习细粒度的控制
且尽管所用数据更多是 2D Platformer 游戏游戏和机器人视频,但可扩展到更大的互联网数据集
对于 Genie 而言,它不仅了解观察到的哪些部分通常是可控的,而且还能推断出在生成环境中一致的各种潜在动作。需要注意的是,相同的潜在动作如何在不同的 prompt 图像中产生相似的行为
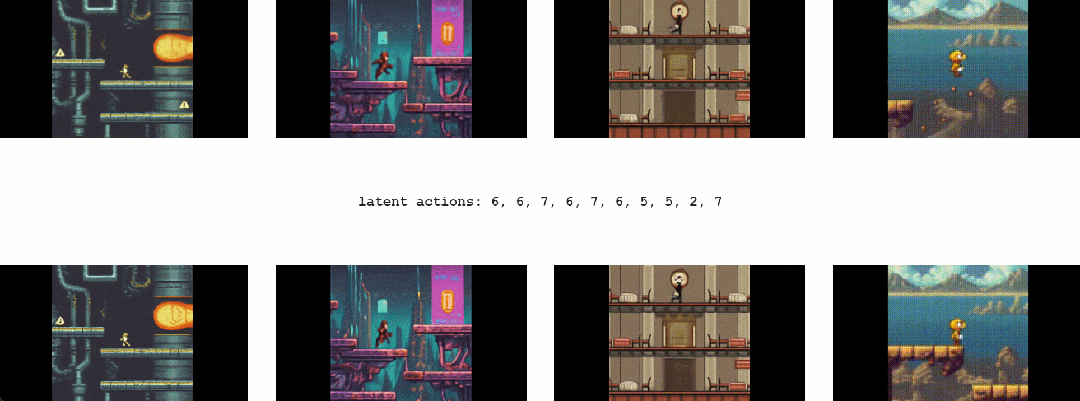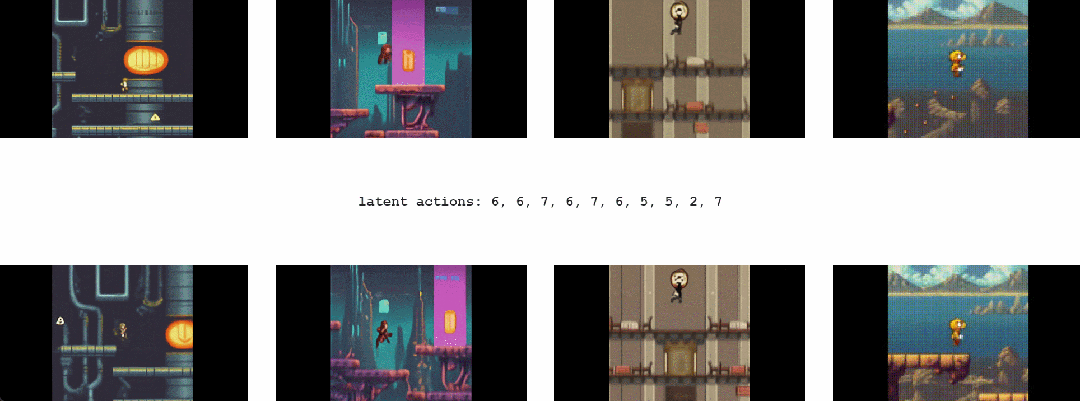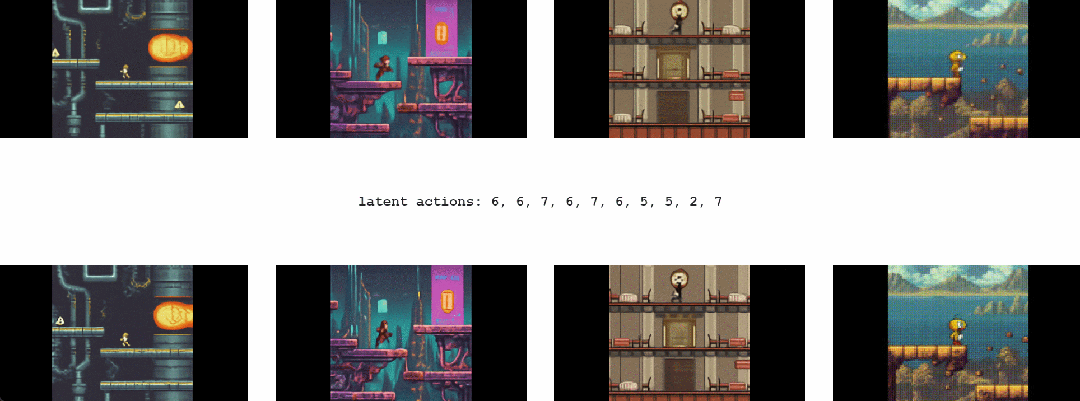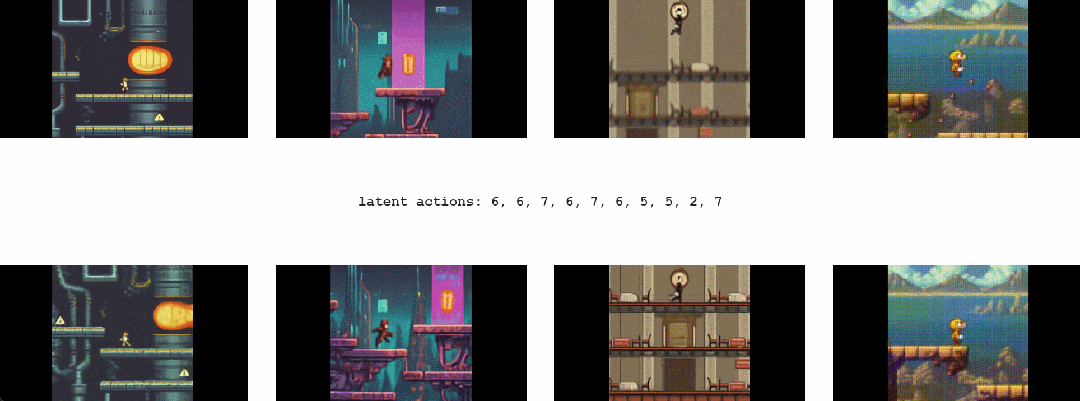
1.2 Genie能干啥
最终,只需要一张图像就可以创建一个全新的交互环境,例如,我们可以使用最先进的文本生成图像模型来生成起始帧,然后与 Genie 一起生成动态交互环境
在如下动图中,谷歌使用 Imagen2 生成了图像,再使用 Genie 将它们变为现实:

Genie 能做到的不止如此,它还可以应用到草图等人类设计相关的创作领域

或者,应用在真实世界的图像中:

此文,谷歌在 RT1 的无动作视频上训练了一个较小的 2.5B 模型。与 Platformers 的情况一样,具有相同潜在动作序列的轨迹通常会表现出相似的行为。
这表明 Genie 能够学习一致的动作空间,这可能适合训练机器人,打造通用化的具身智能

第二部分 技术揭秘:论文《Genie: Generative Interactive Environments》
Genie对应的论文为《Genie: Generative Interactive Environments》,其项目主页为:https://sites.google.com/view/genie-2024/home
论文的共同一作多达 6 人,其中包括华人学者石宇歌Yuge (Jimmy) Shi,她目前是谷歌 DeepMind 研究科学家,2023 年获得牛津大学机器学习博士学位
2.1 ST-transformer 架构
视频最多可以包含 𝑂(10^4 ) 个 token,而 Transformer 的二次内存成本对于视频生成的压力是比较大的,因此,Genie在所有模型组件中采用内存高效的 ST-transformer 架构

与传统的Transformer不同,每个token都会与其他所有token进行关注,ST-transformer包含 个时空块,其中交替出现空间和时间注意力层,然后是标准的前馈层FFW注意力块
- 空间层中的自注意力关注每个时间步内的
个token,而时间层中的自注意力关注跨越
个标记的
个时间步
- 与序列转换器类似,时间层假设具有因果结构和因果掩码。 重要的是,我们架构中计算复杂性的主导因素(即空间注意力层)与帧数呈线性关系,而不是二次关系,使其在具有一致动态的长时间交互视频生成中更加高效
Similar to sequence transformers, the temporal layer assumes a causal structure with a causal mask. Crucially, the dominating factor of computation complexity (i.e. the spatial attention layer) in our architecture scales linearly with the number of frames rather than quadratically, making it much more efficient for video generation with consistent dynamics over extended interactio - 此外,在ST块中,仅包含一个FFW在空间和时间组件之后,省略了post-spatial FFW,以便扩展模型的其他组件(we include only one FFW after both spatial and temporal components, omitting the post-spatial FFW to allow for scaling up other components of the model)
2.2 三个关键组件:视频Tokenizer、潜在动作模型、动态模型
Genie 包含三个关键组件,如下图所示
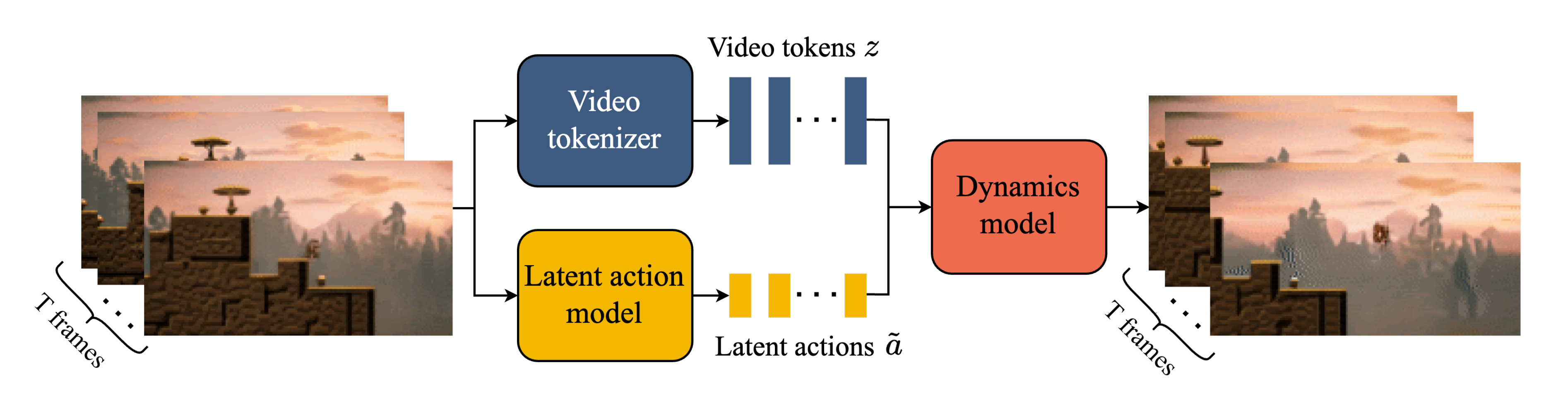
- 视频Tokenizer,用于将原始视频的一系列帧转换为离散 token 𝒛;
- 潜在动作模型(Latent Action Model,LAM),用于推断每对帧之间的潜在动作𝒂
- 一个自回归动力学模型MaskGIT,用于在给定潜在动作和过去帧 token的情况下,预测视频的下一帧
2.2.1 视频Tokenizer
在之前研究的基础上,谷歌将视频压缩为离散 token,以降低维度并实现更高质量的视频生成。实现过程中,谷歌使用了 VQ-VAE,其将视频的 𝑇 帧作为输入,从而为每个帧生成离散表示:
,其中𝐷 是离散潜在空间大小。分词器在整个视频序列上使用标准的 VQ-VQAE 进行训练

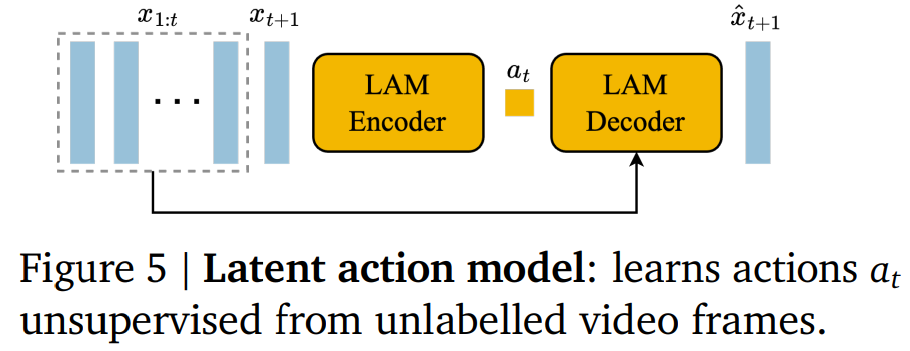
2.2.2 潜在动作模型
为了实现可控的视频生成,谷歌将前一帧所采取的动作作为未来帧预测的条件。然而,此类动作标签在互联网的视频中可用的很少,并且获取动作注释的成本会很高。相反,谷歌以完全无监督的方式学习潜在动作
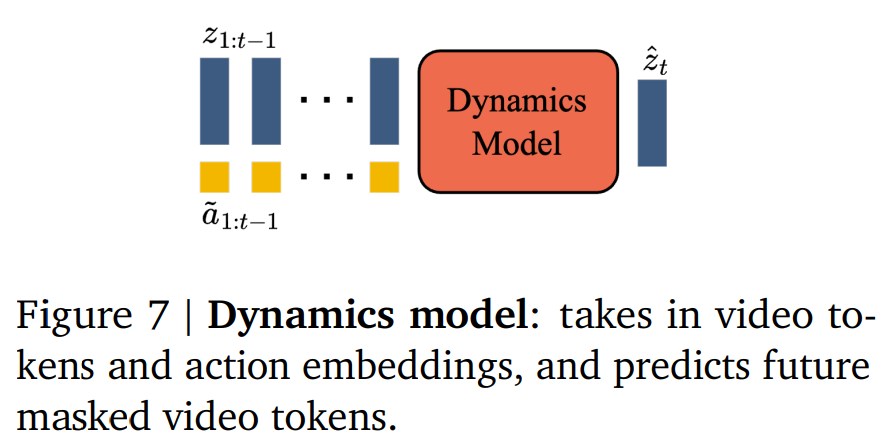
2.2.3 动态模型
是一个仅解码器的 MaskGIT transformer
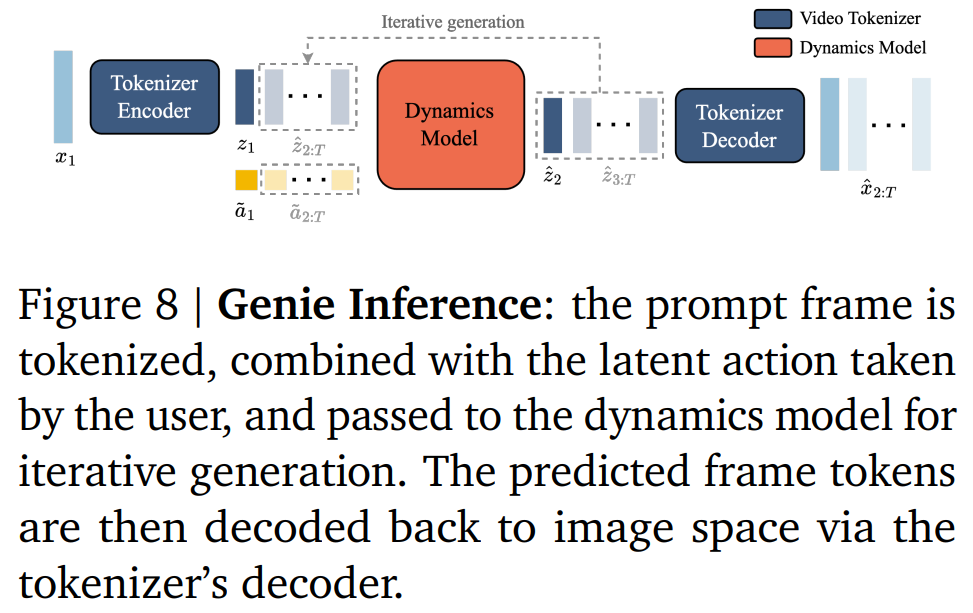
Genie 的推理过程如下所示
// 待更
参考文献与推荐阅读
- 刚刚,谷歌发布基础世界模型:11B参数,能生成可交互虚拟世界
- ..