1.这是我用Python写的,目前无法给大家直接使用exe,因为编译后软件不能正常使用。但是py源码可以先开源,给大家学习一下,里面的代码,都有我的注释,需要你有编程基础就可以看懂,自己可以在这个基础上修改。主要作用回测一下,股票常见指数与月线级别涨跌幅和振幅,及上涨下跌胜率的之前关系。需要安装的第三方库pandas(数据处理)和qstock(提供股票数据来源)模块。数据化分析的基本步骤,有数据源——制定回测策略——数据处理——保存回测数据——通过数据,找到股票可靠的变化规律。
2.本代码可以,获取上证指数从1990到至今的月线数据,也可以自己定义回测数据的时间范围。支持数据的排序功能,比如你排序完成后,可以看到金额成交,涨幅等,最大靠前的月份是哪些??方便直观的去,进一步找股票的变化与时间的规律关系。
3.可以回测以下指数(‘上证指数’, ‘399001’, ‘深证综指’, ‘创业板指’, ‘上证50’, ‘上证180’,‘沪深300’,‘中证1000’, ‘中证500’, ‘科创50’, ‘科创100’, ‘北证50’)。你可以把指数代码,换成个股,这样个股就可以回测了,个股的回测要注意一下是否前复权处理,我这里只弄了指数,个股的大家自己研究。
4.回测后的数据可以在软件上显示,也可以保存为Excel表格数据,方便后面再研究与分析。在回测系统文件夹里面就可以看到。
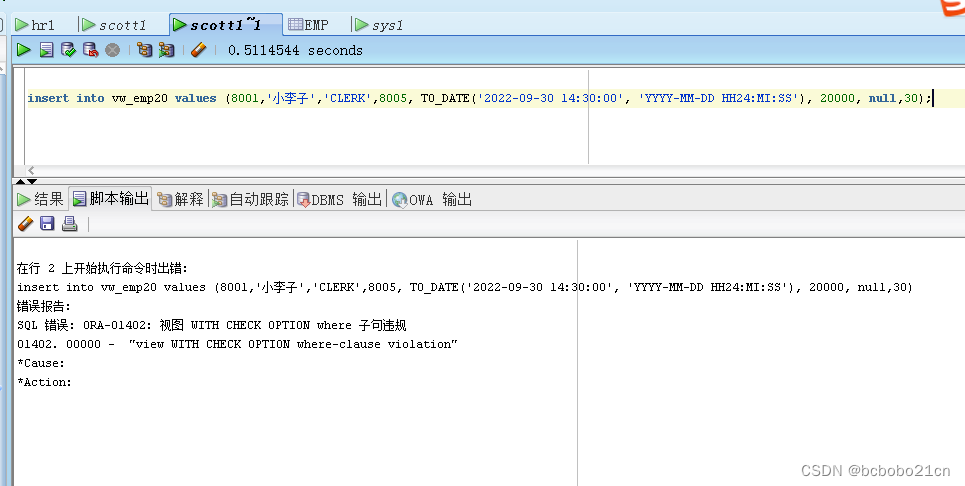
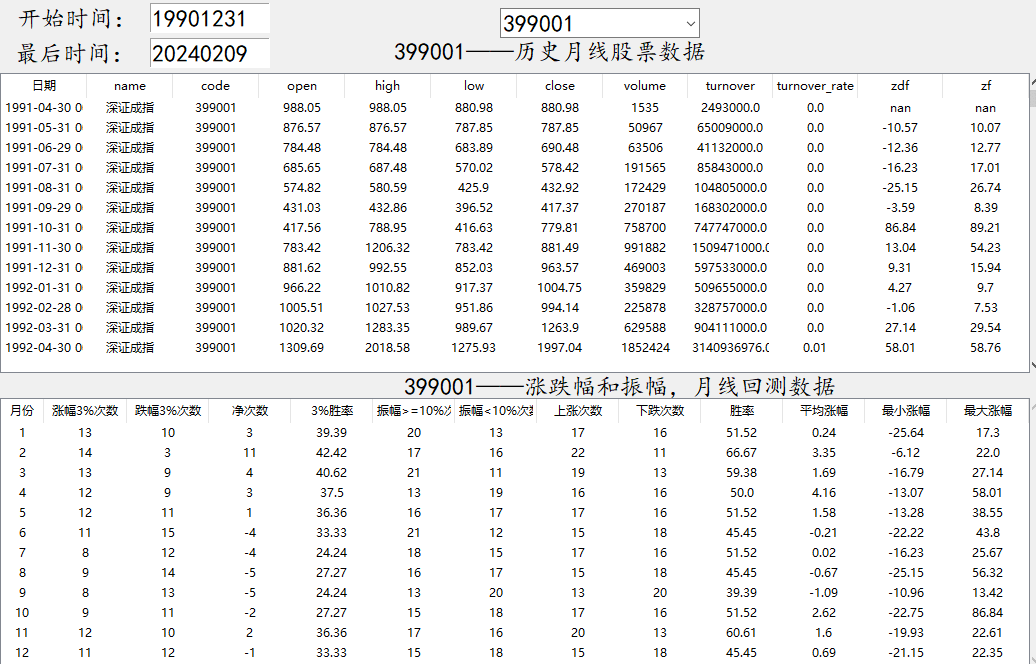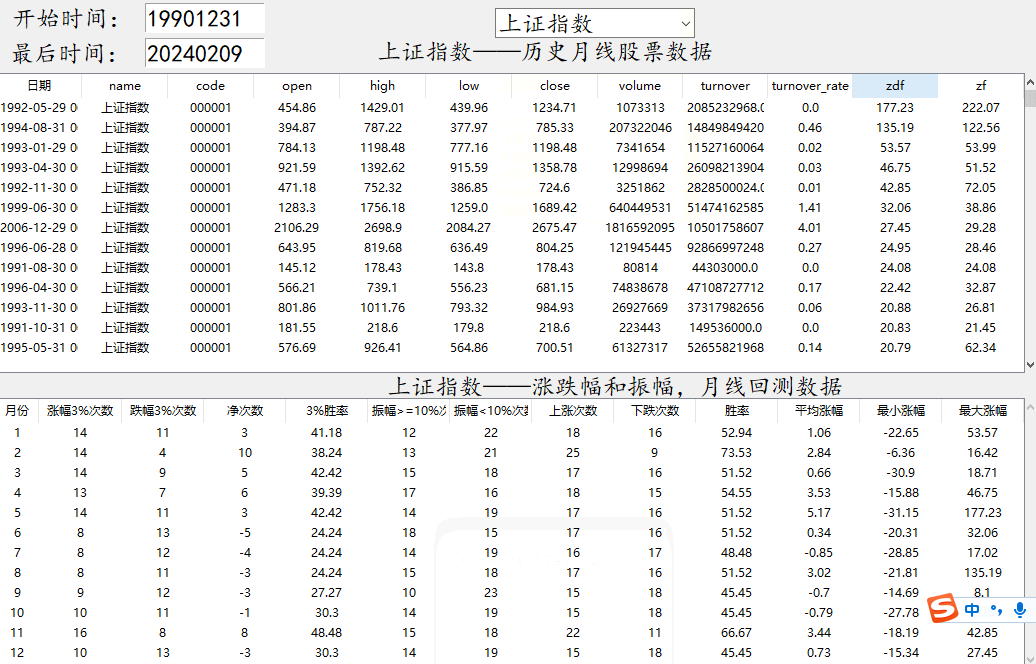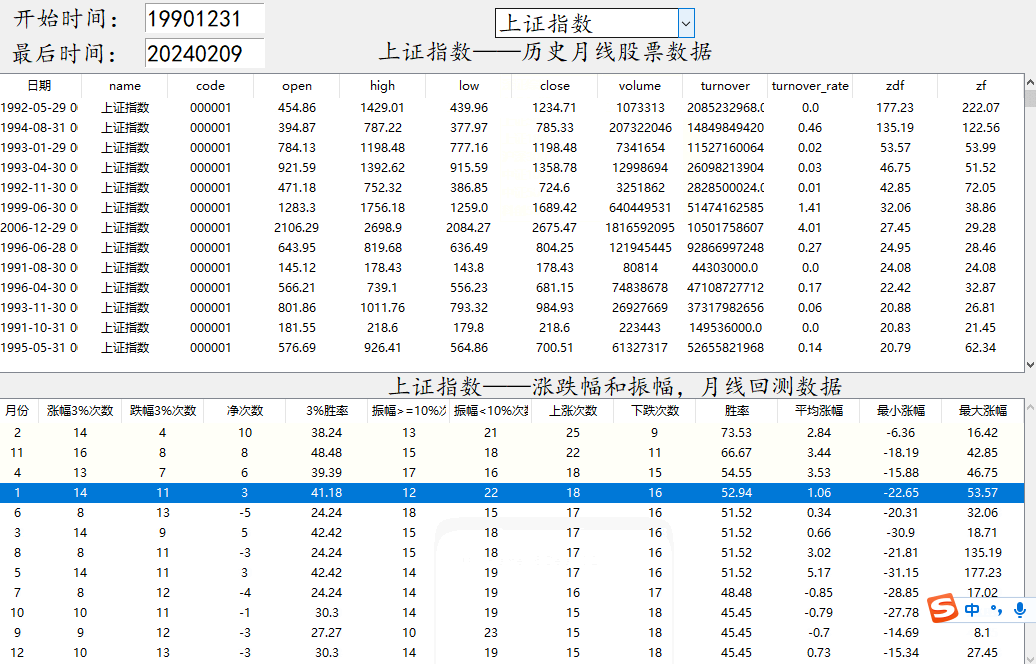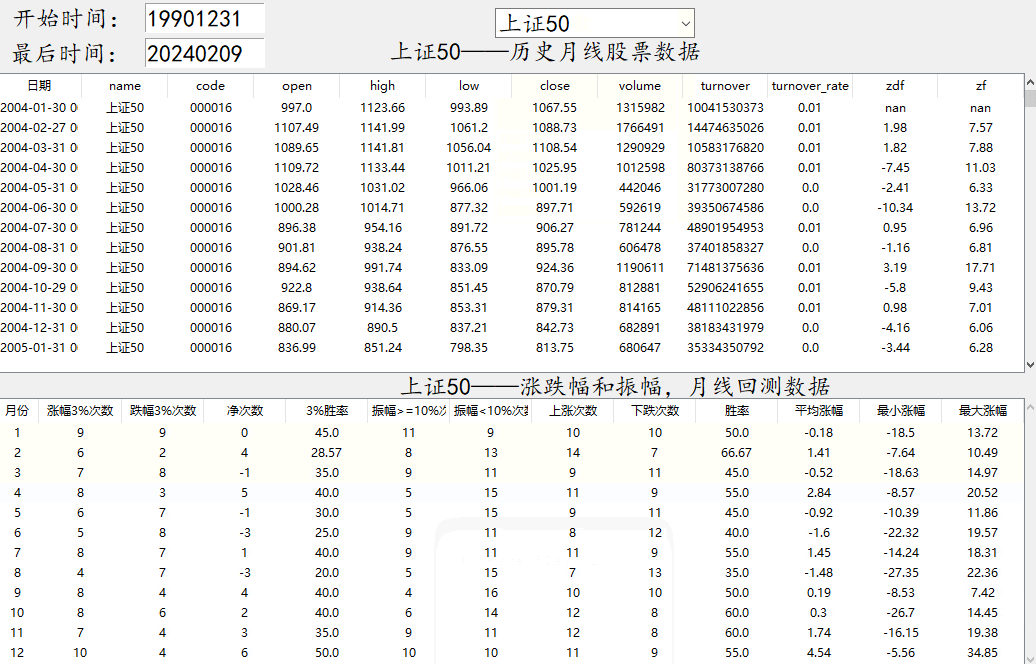
5.关于数据说明:软件上面的是指数的月线级别数据(高开低收,成交量,成交金额,涨跌幅,振幅),之所以显示数据,因为这是网页上采集的数据。为了保证数据的正确性,你可以随机挑选几个不同时间的数据,去和股票软件上的月线对照一下,看数据是否正确,数据如果不正确,回测也就没有意义了,最下面的是回测数据的结果。
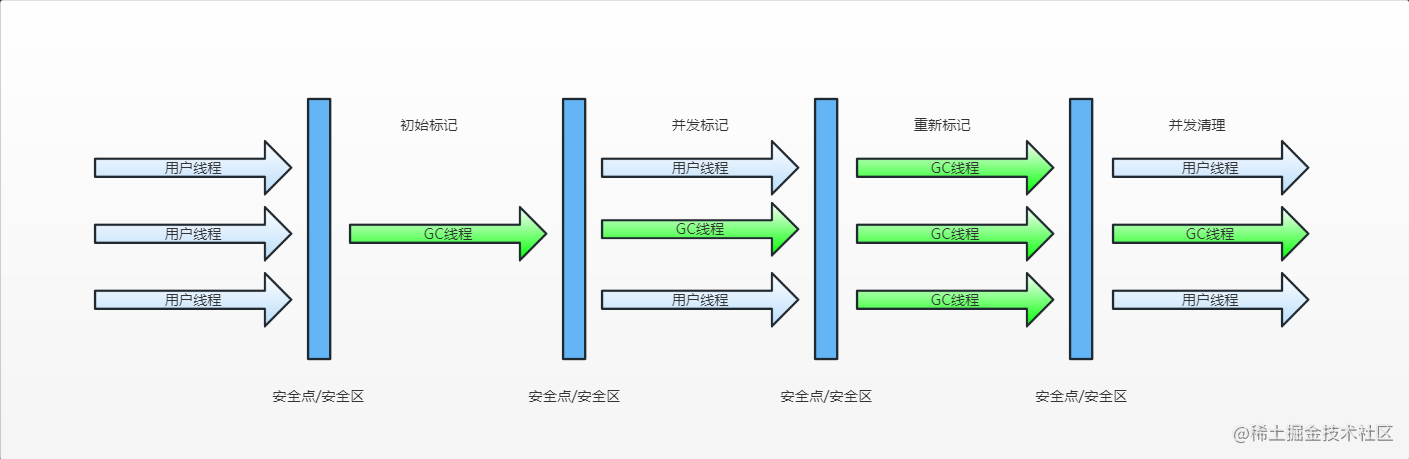
6.回测数据应用:回测数据有上涨次数(涨幅>=0),下跌次数,平均涨幅,涨幅3%的次数,胜率等给大家做综合数据分析,比如1990-2024年,这个期间,一月份上涨了多少次,下跌了多少次,从而判断一月份适不适合操作,平均涨幅是把所有一月份的所有涨跌幅相加,如果数值为正,那么就比较良好。你也可以看振幅,了解一下指数的历史波动情况,看振幅一定要看涨幅,这样可以知道是正向波动还是反向波动。振幅数据尽量不要单独拿着看,要配合着使用。另外时间的范围选取也很重要,既要全部测试,也有分阶段测试,以及分牛熊式测试,因为这些对回测的结果也是有影响的,实际运用中自行调节参数。
效果显示如下
# @Author : 小红牛
# 微信公众号:gxzfp888
import os
import threading
from datetime import datetime
import tkinter as tk
from tkinter import ttk
import pandas as pd
import qstock as qs
os.makedirs('股票回测系统', exist_ok=True)
# 0.获取月线数据
def get_datas(start_time, end_time, symbol='上证指数'):
# 1.获取月线数据
# start = '19910601', end = '20240131'
df = qs.get_data(symbol, start=start_time, end=end_time, freq='M').sort_index()
# name code open high low close volume
# 2.计算指数的月线zdf涨跌幅和振幅zf
df['zdf'] = ((df['close'] - df['close'].shift(1)) * 100 / df['close'].shift(1)).round(2)
df['zf'] = ((df['high'] - df['low']) * 100 / df['close'].shift(1)).round(2)
# print('1.打印涨幅和振幅数据'.center(50, '-'))
# df = df.fillna(0) # 用0填充缺失值
dataframe_to_treeview(df, 0, 75, 1030, 300, column_name='日期')
# print(df)
return df
# 1.获取回测数据
def get_test_datas(symbol='上证指数'):
# start = '19910601', end = '20240131'
start = start_entry.get()
end = end_entry.get()
# print(start, end)
df = get_datas(start, end, symbol)
# 3.将日期index转化为月份显示
# print('2.月份数据'.center(50, '-'))
df['月份'] = df.index
df['月份'] = df['月份'].apply(lambda x: int(x.strftime('%m')))
# 删除包含缺失值的行
datas = df.dropna()
# print(datas)
# print('3.打印回测数据'.center(50, '-'))
columns = ['涨幅3%次数', '跌幅3%次数', '净次数', '3%胜率', '振幅>=10%次数', '振幅<10%次数',
'上涨次数', '下跌次数', '胜率', '平均涨幅', '最小涨幅', '最大涨幅']
# 2.生成回测数据
df2 = pd.DataFrame(index=sorted(datas['月份'].unique().tolist()),
columns=columns)
# 设置索引名
df2.index.name = '月份'
# print(df2)
for name, group in datas.groupby('月份'):
# 取涨幅和振幅数据
get_zdf = group['zdf']
get_zf = group['zf']
# 上涨的个股次数
# print(f'group name: {name}月份')
# print(group[get_zdf > 3])
# print(f'次数: {group[get_zdf > 3].shape[0]}')
# 1.上涨+3%次数
df2.loc[name, '涨幅3%次数'] = group[get_zdf >= 3].shape[0]
# 下跌-3次数
df2.loc[name, '跌幅3%次数'] = group[get_zdf <= -3].shape[0]
df2.loc[name, '净次数'] = group[get_zdf >= 3].shape[0] - group[get_zdf <= -3].shape[0]
# 3%的胜率
win3 = (100 * group[get_zdf > 3].shape[0] / group.shape[0])
df2.loc[name, '3%胜率'] = round(win3, 2)
# 振幅+5%次数
df2.loc[name, '振幅>=10%次数'] = group[get_zf >= 10].shape[0]
# 振幅+5%次数
df2.loc[name, '振幅<10%次数'] = group[get_zf < 10].shape[0]
df2.loc[name, '上涨次数'] = group[get_zdf > 0].shape[0]
# 3.下跌次数
df2.loc[name, '下跌次数'] = group[get_zdf < 0].shape[0]
# 胜率
win = (100 * group[get_zdf > 0].shape[0] / group.shape[0])
df2.loc[name, '胜率'] = round(win, 2)
# 涨跌幅的均值
df2.loc[name, '平均涨幅'] = round(get_zdf.mean(), 2)
# 涨跌幅的最小值
df2.loc[name, '最小涨幅'] = get_zdf.min()
# 涨跌幅的最大值
df2.loc[name, '最大涨幅'] = get_zdf.max()
# df2.round(2)
# print(df2)
return df2
# 2.保存回测数据
def save_test_datas(test_datas, zhishu_name):
df3 = test_datas
# print(df3)
dataframe_to_treeview(test_datas, 0, 400, 1030, 270, column_name='月份', num=40)
df3.to_excel(f'股票回测系统/{zhishu_name}月线涨跌幅回测数据.xlsx')
# 3.1列表框数字+文本排序
def treeview_sort(tv, col, reverse):
l = [(tv.set(k, col), k) for k in tv.get_children('')]
# print(l)
# print(l[0][0])
# 1.处理数据里面的单位
if '元' in l[0][0]:
# 如果第一行的数据里存在 '元' 的文本
l.sort(key=lambda t: float(t[0].replace('元', '')), reverse=reverse) # 把单位去除后转数字再排序
else:
try:
# 优先尝试数字排序
l.sort(key=lambda t: float(t[0]), reverse=reverse)
except:
# 出错则普遍排序
l.sort(reverse=reverse)
# 这种排序根据首位字符来排序,不适合数字,会出现:1,11,2
# 这种不符合从大到小或从小到大的排序
# print(l)
# 移动数据
for index, (val, k) in enumerate(l):
# print(k)
tv.move(k, '', index)
tv.heading(col, command=lambda: treeview_sort(tv, col, not reverse))
# 3.2 df数据放到列表框
def dataframe_to_treeview(dfs, x1, y1, w, h, column_name='序号', num=80):
# 1.获取数据的列标题
a = dfs.columns.values.tolist()
a.insert(0, column_name)
# 添加一个宽度列表,组成字典
b = [80 for nums in range(len(a) - 1)]
# [50, 80, 80, 80, 80, 80]
b.insert(0, num)
df_titles = dict(zip(a, b))
# print(df_titles)
# 2.设置纵向滚动条
# xbar = tk.Scrollbar(root, orient='horizontal')
# xbar.place(x=x1, y=y1+h-3, width=w)
ybar = tk.Scrollbar(root, orient='vertical')
ybar.place(x=x1+w-3, y=y1, height=h)
# 3.创建Treeview
tree = ttk.Treeview(root, show='headings', yscrollcommand=ybar.set)
tree['columns'] = list(df_titles)
# 批量设置列属性
for title in df_titles:
# 加载列标题
tree.heading(title, text=title)
tree.column(title, width=df_titles[title], anchor='center')
# 3.设置点击执行排序操作
tree.heading(title, command=lambda _col=title: treeview_sort(tree, _col, False))
# 遍历DataFrame的每一行,并将它们添加到Treeview中
for index, row in dfs.iterrows():
datas = row.tolist()
datas.insert(0, index)
# print(datas)
# 添加行数据
tree.insert('', 'end', text='', values=datas)
# 将Treeview添加到主窗口
tree.place(x=x1, y=y1, width=w, height=h)
# xbar.config(command=tree.xview)
ybar.config(command=tree.yview)
# 4.绑定combobox综合事件,数据下载+保存+到列表框
# 传递带参数的线程
def work_thread(codes):
# print(codes) 上证指数
test_datas = get_test_datas(codes)
save_test_datas(test_datas, codes)
# 3.历史数据和回测标签
history_label = tk.Label(root, font=set_font, text=f'{codes}——历史月线股票数据')
history_label.place(x=300, y=40, width=500, height=25)
huice_label = tk.Label(root, font=set_font, text=f'{codes}——涨跌幅和振幅,月线回测数据')
huice_label.place(x=320, y=375, width=600, height=25)
def combobox_events(event):
# 获取选中的数据
selected_content = combo_box.get()
thread = threading.Thread(target=work_thread, args=(selected_content,))
# 设置守护线程,这样在主线程退出时会自动结束这个线程
thread.daemon = True
# 启动线程
thread.start()
if __name__ == '__main__':
root = tk.Tk()
set_font = ('楷体', 18)
root.title('小红牛股票指数回测系统——微信公众号:gxzfp888')
root.geometry('1050x690+200+10')
root.resizable(False, False)
# 1.下拉框
zhishu_names = ('上证指数', '399001', '深证综指', '创业板指', '上证50', '上证180',
'沪深300','中证1000', '中证500', '科创50', '科创100', '北证50')
combo_box = ttk.Combobox(root, values=zhishu_names, font=set_font)
combo_box.place(x=500, y=10, width=200, height=30)
# 显示 Combobox 控件
combo_box.current(0) # 设置默认选中项
# 为 Combobox 组件绑定事件,当进行选择时,触发事件
combo_box.bind("<<ComboboxSelected>>", combobox_events)
# 2.开始时间标签和输入框
start_label = tk.Label(root, font=set_font, text='开始时间:')
start_label.place(x=2, y=5, width=150, height=30)
start_entry_var = tk.StringVar()
start_entry = tk.Entry(root, highlightcolor='red',
textvariable=start_entry_var, font=set_font)
start_entry.place(x=150, y=5, width=120, height=30)
start_entry_var.set('19901231')
formatted_date = datetime.now().strftime("%Y%m%d")
end_label = tk.Label(root, font=set_font, text='最后时间:')
end_label.place(x=0, y=40, width=150, height=30)
end_entry_var = tk.StringVar()
end_entry = tk.Entry(root, highlightcolor='red',
textvariable=end_entry_var, font=set_font)
end_entry.place(x=150, y=40, width=120, height=30)
end_entry_var.set(formatted_date)
root.mainloop()
-!! 完毕 ,感谢您的收看!!-
----------★★历史博文集合★★----------
股软件 龙虎榜小红牛分析系统 资金大单系统
通达信主附图指标改选股器 通达信自定义数据系统
小红牛股票数据共享 其他股软 Ex系统
通达信小技巧 通达信指标编写教程 Tdx指标公式
龙虎榜教程 游资盈亏数据 产业链上下游
量化教程 指标回测 Python 股学堂







![[云原生] k8s之pod容器](https://img-blog.csdnimg.cn/direct/aecdf4f49ede42bfaf5a6b958003a41f.png)