1.BeautifulSoup soup = BeautifulSoup(html,'html.parser') all_ico=soup.find(class_="DivTable")
2.xpath
trs = resp.xpath("//tbody[@id='cpdata']/tr")
hong = tr.xpath("./td[@class='chartball01' or @class='chartball20']/text()").extract()
这个意思是找到 tbody[@id='cpdata'] 这个东西 ,然后在里面找到[@class='chartball01]这个东西,然后extract()提取信息内容
3.re
img_name = re.findall('alt="(.*?)"',response)
这个意思是找到(.*?)这个里面的东西,在response,这个response是text
4.css
element3 = element2.find_element(By.CSS_SELECTOR,'a[target="_blank"]').click()
用css找到标签为a的target="_blank"这个东西,然后点击
如果是标签啥都不加,class用@,ID用#
下面是今天学习scrapy的成果:
先是复习创建一个scrapy(都是在命令里面)
1.scrapy startproject +名字(软件包的名字)
2.cd+名字-打开它
3.scrapy genspider +名字(爬虫的名字)+区域地址
4.scrapy crawl +名字(爬虫的名字)
在setting里面修改


今天不在命令里面跑了
在名字(软件包的名字)下建立一个 python文件

然后运行就OK
下面还有在管道里面的存储方法(存储为csv形式)
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class Caipiao2Pipeline:
def open_spider(self,spider):#开启文件
#打开
self.f = open("data2.csv",mode='a',encoding="utf-8") #self====>在这个class中定义一个对象
def close_spider(self,spider):#关闭文件
self.f.close()
def process_item(self, item, spider):
print("====>",item)
self.f.write(f"{item['qi']}")
self.f.write(',')
self.f.write(f"{item['hong']}")
self.f.write(',')
self.f.write(f"{item['lan']}")
self.f.write("\n")
# with open("data.csv",mode='a',encoding="utf-8") as f:
# f.write(f"{item['qi']}")
# f.write(',')
# f.write(f"{item['hong']}")
# f.write(',')
# f.write(f"{item['lan']}")
# f.write("\n")
return item
第一种是传统的 with open
第二种是,开始运行,之后在管道里会运行一个方法, open_spider 在这里面打开文件
下面所有代码和成果
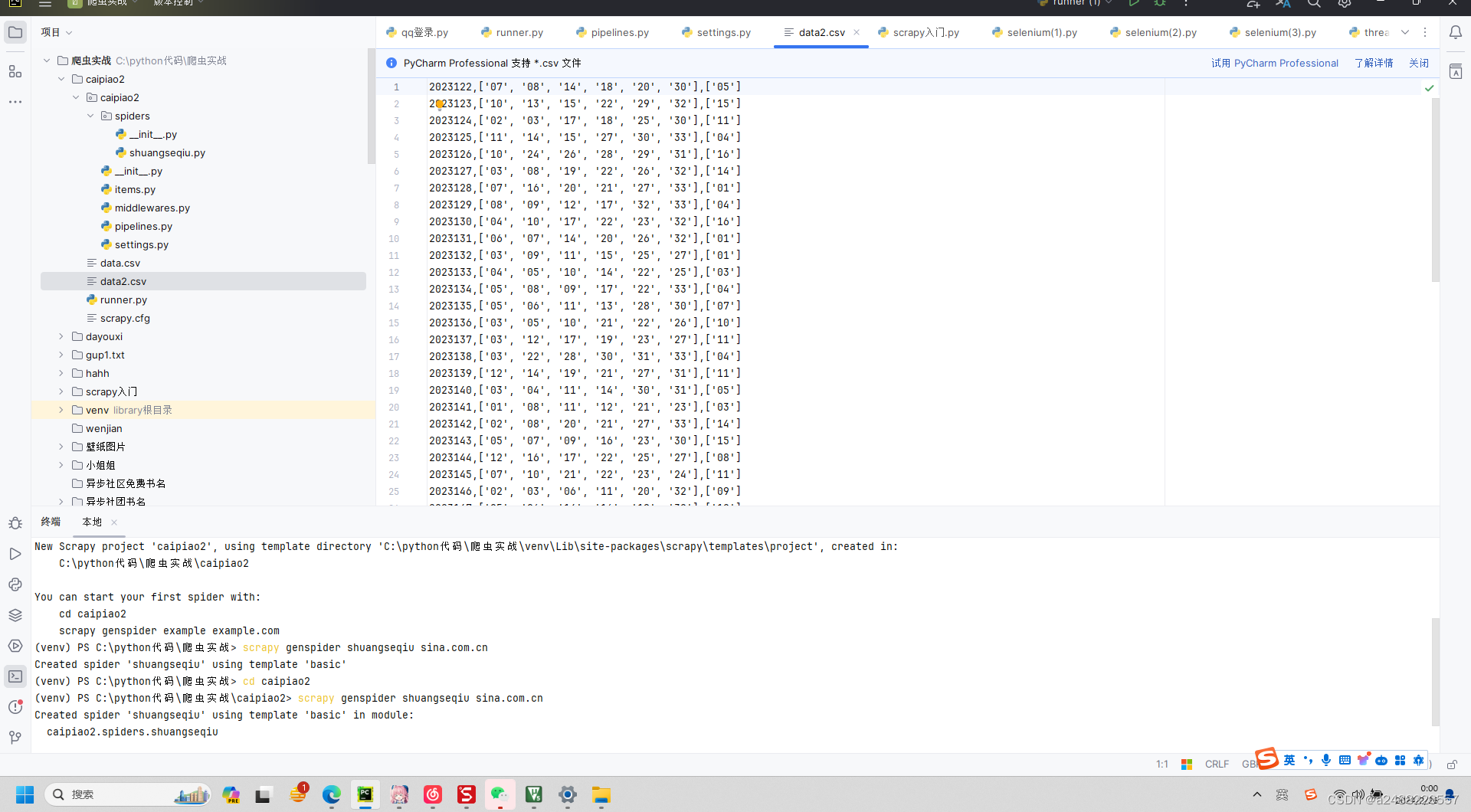
这个是爬虫函数
import scrapy
class ShuangseqiuSpider(scrapy.Spider):
name = "shuangseqiu"
allowed_domains = ["sina.com.cn"]
start_urls = ["https://view.lottery.sina.com.cn/lotto/pc_zst/index?lottoType=ssq&actionType=chzs&type=50&dpc=1"]
def parse(self, resp,**kwargs):
#提取
trs = resp.xpath("//tbody[@id='cpdata']/tr")
for tr in trs: #每一行
qi = tr.xpath("./td[1]/text()").extract_first()
hong = tr.xpath("./td[@class='chartball01' or @class='chartball20']/text()").extract()
lan = tr.xpath("./td[@class='chartball02']/text()").extract()
#存储
yield {
"qi":qi,
"hong":hong,
"lan":lan
}
这个是管道函数
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class Caipiao2Pipeline:
def open_spider(self,spider):#开启文件
#打开
self.f = open("data2.csv",mode='a',encoding="utf-8") #self====>在这个class中定义一个对象
def close_spider(self,spider):#关闭文件
self.f.close()
def process_item(self, item, spider):
print("====>",item)
self.f.write(f"{item['qi']}")
self.f.write(',')
self.f.write(f"{item['hong']}")
self.f.write(',')
self.f.write(f"{item['lan']}")
self.f.write("\n")
# with open("data.csv",mode='a',encoding="utf-8") as f:
# f.write(f"{item['qi']}")
# f.write(',')
# f.write(f"{item['hong']}")
# f.write(',')
# f.write(f"{item['lan']}")
# f.write("\n")
return item
这个是启动函数:
from scrapy.cmdline import execute
if __name__ =="__main__":
execute("scrapy crawl shuangseqiu".split())