文章目录
- 资源
- SDXL-Lightning 论文
资源
SDXL-Lightning论文:https://arxiv.org/abs/2402.13929
gradio教程:https://blog.csdn.net/qq_21201267/article/details/131989242
SDXL-Lightning :https://huggingface.co/ByteDance/SDXL-Lightning
SDXL-Lightning实时出图:https://huggingface.co/spaces/radames/Real-Time-Text-to-Image-SDXL-Lightning
SDXL-Lightning demo自己体验代码:
import time
import gradio as gr
import torch
import base64
import io
from PIL import Image
from diffusers import StableDiffusionXLPipeline, UNet2DConditionModel, EulerDiscreteScheduler
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
base = "stabilityai/stable-diffusion-xl-base-1.0"
repo = "ByteDance/SDXL-Lightning"
ckpt = "sdxl_lightning_4step_unet.safetensors" # Use the correct ckpt for your step setting!
# Load model.
unet = UNet2DConditionModel.from_config(base, subfolder="unet").to("cuda", torch.float16)
unet.load_state_dict(load_file(hf_hub_download(repo, ckpt), device="cuda"))
pipe = StableDiffusionXLPipeline.from_pretrained(base, unet=unet, torch_dtype=torch.float16, variant="fp16").to("cuda")
# Ensure sampler uses "trailing" timesteps.
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing")
def get_image_from_text(prompt):
time1 = time.time()
# Ensure using the same inference steps as the loaded model and CFG set to 0.
image = pipe(prompt, num_inference_steps=4, guidance_scale=0).images[0]
print("time:", time.time() - time1)
return image
def generate(prompt):
result_image = get_image_from_text(prompt)
return result_image
gr.close_all()
demo = gr.Interface(fn=generate,
inputs=[gr.Textbox(label="提示词")],
outputs=[gr.Image(label="输出图片")],
title="文本生成图片",
description="输入提示词,使用SD模型生成图片",
allow_flagging="never",
examples=["A girl smiling", "A beautiful sunset"])
demo.launch(share=True, server_name="0.0.0.0", server_port=7869)
SDXL-Lightning 论文
摘要
我们提出了一种扩散蒸馏方法,在基于SDXL的一步/少步1024px文本到图像生成中实现了新的最先进水平。我们的方法结合了渐进和对抗性蒸馏,以在质量和模式覆盖之间取得平衡。在本文中,我们讨论了理论分析、鉴别器设计、模型构建和训练技术。我们将我们的蒸馏SDXL-Lightning模型开源,包括LoRA和完整的UNet权重。
模型链接:https://huggingface.co/ByteDance/SDXL-Lightning
- 引言
扩散模型是一类新兴的生成模型,已在各种应用中取得了最先进的结果,如文本到图像、文本到视频和图像到视频等。然而,扩散模型的迭代生成过程缓慢且计算量大。如何更快地生成高质量样本是一个积极研究的领域,也是我们工作的主要焦点。
从概念上讲,生成涉及逐渐将样本在数据和噪声概率分布之间传输的概率流。扩散模型学习预测该流的任何位置的梯度。生成只是通过遵循流中预测的梯度,将样本从噪声分布传输到数据分布。由于流是复杂且弯曲的,生成必须一次小步骤地进行。形式上,流可以表示为常微分方程(ODE)。实践中,生成高质量数据样本需要超过50个推理步骤。
已经研究了不同的方法来减少推理步骤的数量。先前的研究提出了更好的ODE求解器来考虑流的弯曲性质。其他人提出了使流更直的公式。尽管如此,这些方法通常仍需要超过20个推理步骤。
另一方面,模型蒸馏可以在不到10个推理步骤下生成高质量的样本。它不是预测当前流位置的梯度,而是将模型更改为直接预测未来更远处的下一个流位置。现有方法可以在4或8个推理步骤下获得良好的结果,但是使用1或2个推理步骤仍然不符合生产要求。我们的方法属于模型蒸馏范畴,并且与现有方法相比获得了更优越的质量。
我们的方法结合了渐进蒸馏和对抗性蒸馏的优点。渐进蒸馏确保蒸馏模型遵循与原始模型相同的概率流,并具有相同的模式覆盖。然而,使用均方误差(MSE)损失的渐进蒸馏在8个推理步骤以下会产生模糊的结果,我们在论文中提供了理论分析。为了减轻这个问题,我们在蒸馏的每个阶段使用对抗损失,以在质量和模式覆盖之间取得平衡。渐进蒸馏还带来了另一个好处,即对于多步采样,我们的模型预测ODE轨迹上的下一个位置,而不是每次跳到ODE轨迹的端点,这更好地保留了原始模型行为,并促进了与LoRA模块和控制插件的更好兼容性。
此外,我们的论文提出了创新的鉴别器设计、损失目标和稳定的训练技术。具体来说,我们使用预训练的扩散UNet编码器作为鉴别器骨干,并完全在潜在空间中操作。我们提出了两个对抗损失目标来权衡样本质量和模式覆盖。我们研究了扩散计划和输出形式的影响。我们讨论了稳定对抗训练的技术。我们的蒸馏方法产生了支持1024px分辨率的一步/少步生成的新的最先进的SDXL模型。我们将我们的蒸馏模型开源为SDXL-Lightning。
2.4. 对抗性蒸馏
对抗性训练涉及一个最小最大化优化,其中包括一个旨在识别生成样本和真实样本的鉴别器网络,以及一个旨在欺骗鉴别器的生成器网络。最初提出为生成对抗网络(GANs),但它存在模式坍塌和不稳定性等问题。最近的研究发现,对抗目标可以纳入扩散训练和蒸馏中。SDXL-Turbo是使用对抗性扩散蒸馏的最新和最流行的开源模型。它遵循先前的工作,使用预训练的图像编码器DINOv2作为鉴别器骨干来加速训练。然而,这带来了几个限制。首先,使用现成的视觉编码器意味着它必须在像素空间而不是潜在空间中操作,这会显著增加计算、内存消耗和训练时间,使高分辨率的蒸馏变得不切实际。这很可能是SDXL-Turbo只支持最高512px分辨率的原因。其次,现成的视觉编码器只在t = 0时起作用。蒸馏模型必须被训练以跳到ODE轨迹端点x0,但由于一步推理的质量还不够好,再次为多步推理添加随机噪声。这种多步推理的方式显著改变了模型行为,使其与现有的LoRA模块和控制插件的兼容性降低。第三,现成的编码器可能很难找到适用于其他数据集(动漫、线条图等)和模态(视频、音频等)的编码器,这降低了蒸馏方法的泛化能力。最后,仅凭对抗目标本身不能强制模型遵循相同的概率流,因此不能强制模式覆盖。
我们的方法使用扩散模型的U-Net编码器作为鉴别器骨干。这使我们能够在潜在空间中有效地进行高分辨率模型的蒸馏,支持在所有时间步骤进行鉴别,并可泛化到所有数据集和模态。我们的方法还允许控制质量和模式覆盖之间的权衡,如后面3.2和3.4节所讨论的那样。
2.5. 其他蒸馏方法
我们简要讨论了我们的方法与其他蒸馏方法相比的优点。
一致性模型(CM)也需要在每个推理步骤中跳转到ODE轨迹的端点。这导致多步采样时模型行为的巨大变化,降低了与LoRA模块和插件的兼容性。该方法已应用于SDXL,但在8个步骤以下的生成质量较差。一致性轨迹模型(CTM)增加了对抗性损失,并支持跳转到任意流位置,但对抗性训练是在蒸馏后应用的,而不是在蒸馏过程中应用的,而且该方法尚未应用于大规模的文本到图像模型。
矫正流(RF)通过重复使用确定性数据和噪声对训练,使流变得直。然而,其少步生成质量仍然很差。此外,由于在蒸馏过程中模型只见过特定的数据和噪声对,它不再支持将数据与任意噪声配对,这影响了像SDEdit这样的图像编辑的能力。
得分蒸馏采样(SDS)已用于SDXL-Turbo来稳定对抗性训练,但其效果很小,并且不能单独作为蒸馏方法使用。变分得分蒸馏(VSD)最近在扩散蒸馏中使用。然而,在蒸馏过程中需要训练一个额外的负分布得分模型,而且像对抗训练中的鉴别器一样,它还涉及动态训练目标,这可能会对训练稳定性产生负面影响。没有开源模型供比较,我们的初步实验发现我们的方法达到了更好的质量。
2.6. LoRA
低秩适应(LoRA)是一种高效的微调技术。它只训练少量额外的参数,并已成为对现有文本到图像模型进行风格化模块训练的特别流行方法。
LCM-LoRA是首个表明模型蒸馏也可以作为LoRA模块进行训练的模型。这确保了最小的参数更改,并可以方便地插入到现有的生态系统中。
我们的工作受到这种方法的启发,我们提供了我们的蒸馏模型作为LoRA,以便进行方便的插拔,并且作为完整模型以获得更好的质量。
- 方法
3.1. 为什么使用MSE蒸馏失败
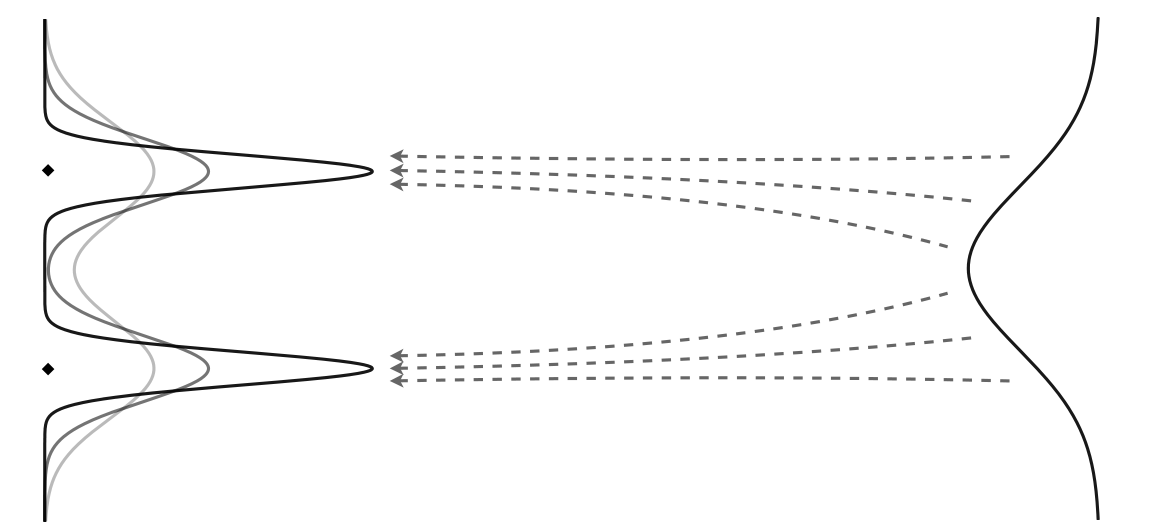
图1. 不同容量模型学习的多个可能流的示意图。针对少步生成的蒸馏学生模型无法具备与教师模型匹配的相同容量,导致使用MSE损失产生模糊结果。
学习到的概率流由数据集、前向函数、损失函数和模型容量确定。鉴于有限的训练样本,底层数据分布是模糊的。最大似然估计(MLE)是一种将均匀概率分配给观察到的样本,其他地方概率为零的分布。如果模型容量无限,它将学习到这种最大似然估计的流,并过度拟合以始终生成观察到的样本并生成没有新数据。实际上,扩散模型可以生成新数据,因为神经网络不是精确学习器。
当模型用于多步生成时,它被堆叠并具有更高的利普希茨常数和更多的非线性,以逼近更复杂的分布。但是当模型用于少步生成时,它不再具有足够的容量来很好地逼近相同的分布。这可以通过扩散模型在初始噪声上进行轻微更改而产生的结果发生非常明显的变化来证明,但是蒸馏模型的潜在遍历更加平滑。这解释了为什么使用MSE损失进行蒸馏会产生模糊的结果。学生模型简单地没有能力与教师相匹配。
此外,神经网络参数优化涉及复杂的景观。即使具有相同容量的模型也很难完全匹配输出,因为参数可能会卡在不同的局部最小值处。
我们发现其他距离度量,例如L1和感知损失,也会产生不理想的结果。另一方面,我们发现对抗目标对缓解这个问题是有效的。