项目简述
本文描述如何只使用opencv将车牌中的车牌号提取出来,整个过程大致分为三个过程:车牌定位,车牌号元素分割,模式匹配。

在做完这个实验后,我感触是,只用opencv的方式能使用的场景有限,不如用模型的方式适用的场景广,推荐还是使用模型去做。
下面我分别介绍这三个流程:
本文借鉴了 【OpenCV实战】简洁易懂的车牌号识别Python+OpenCV实现“超详解”(含代码)_车牌识别代码-CSDN博客
车牌定位
先定义一些公用的方法:
import cv2
import numpy as np
from matplotlib import pyplot as plt
import os
# plt显示彩色图片
def plt_show0(img):
#cv2与plt的图像通道不同:cv2为[b,g,r];plt为[r, g, b]
b,g,r = cv2.split(img)
img = cv2.merge([r, g, b])
plt.imshow(img)
plt.show()
# plt显示灰度图片
def plt_show_gray(img):
plt.imshow(img, cmap='gray')
plt.show()
# 图像去噪灰度处理
def gray_guss(image):
image = cv2.GaussianBlur(image, (3, 3), 0)
image_shape = image.shape
if len(image_shape) == 3:
gray_image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
return gray_image
else:
return image车牌灰度化
我们输入的图片

img_path = r'D:\tmp\cv\plate_number\car_3.jpg'
car = cv2.imread(img_path)
blur_car = gray_guss(car)
plt_show_gray(blur_car)灰度化是为了后面做sobel检测,灰度化的图片是:

sobel检测
Sobel_x = cv2.Sobel(blur_car, cv2.CV_16S, 1, 0)
将数据类型从CV_16S转化到CV_8U, 之所以sobel方法要用16S,是因为sobel在计算过程会产生负值,并且最大值会超过255。
absX = cv2.convertScaleAbs(Sobel_x)
寻找车牌位置
核心思想就是使用车牌的特征来寻找这牌的位置,比如说 车牌是长方形(长>宽),车牌一般不会 在图片的边缘上(拍照的习惯)等等,因此我们也看到的opecv方式的弊端,泛化能力比较差。
首先进行二值化
image = absX
ret, image = cv2.threshold(image, 0, 255, cv2.THRESH_OTSU)
然后我们使用闭操作,目的是让车牌形成一个白色的长方形,方便我们用车牌特征来匹配车牌的位置。
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 10))
image = cv2.morphologyEx(image, cv2.MORPH_CLOSE, kernelX,iterations = 1)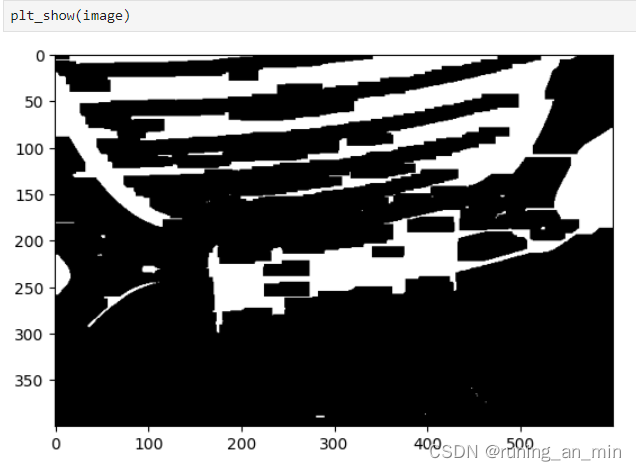
有点儿意思了,但是长方形内部还有些空隙,我们继续处理:
kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (50, 1))
kernelY = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 20))我们在x方向上做膨胀操作,目的是让白色填充满车牌
image = cv2.dilate(image, kernelX)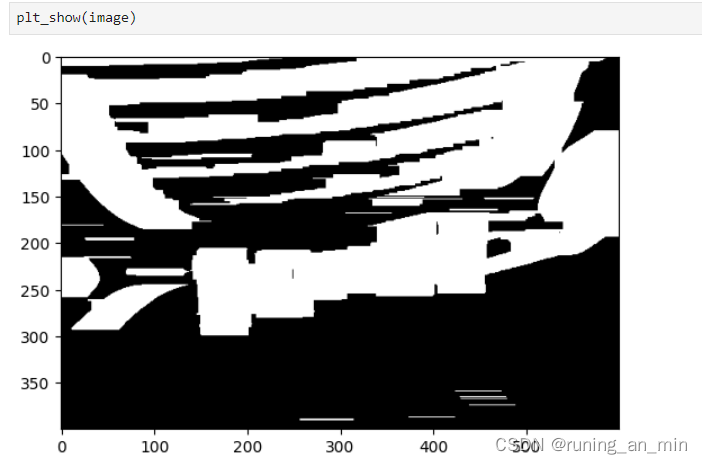
在y方向做腐蚀操作,目的是让车牌和其他白色区域分离开,方便后面的轮廓查找
image = cv2.erode(image, kernelX)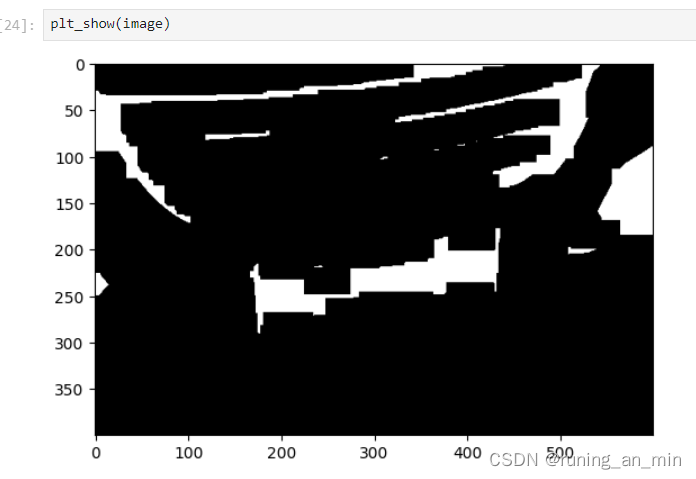
然后来一次中值滤波,去掉白色小块,只保留比较大的区域
image = cv2.medianBlur(image, 21) 
我们将所有的轮廓画出来,并计算一下面积:
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
car_operator = car.copy()
# 将所有区域取出来
data = {}
for index, item in enumerate(contours):
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
# 根据轮廓的形状特点,确定车牌的轮廓位置并截取图像
# if (weight > (height * 3.5)) and (weight < (height * 4)):
# image = car[y:y + height, x:x + weight]
# plt_show0(image)
area = cv2.contourArea(item)
data[index] = {'area': area, 'x':x, 'y':y, 'w':weight, 'h':height}
cv2.putText(car_operator, str(area), (x+10, y+height+30), cv2.FONT_HERSHEY_COMPLEX, 0.8, (0, 0, 255), 3)
cv2.rectangle(car_operator, (x, y), (x+weight, y+height), (0,255,0), 2)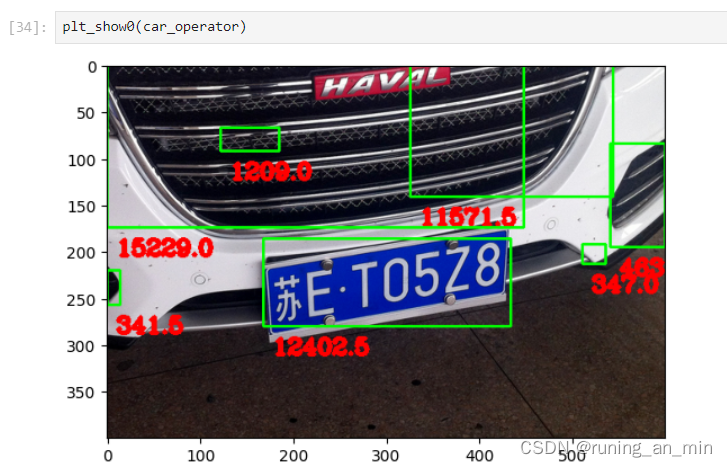
根据车牌的特征过滤一下轮廓,我这里只用了面积和位置,你可以增加一些其他特点,让代码具有更前的泛化能力。
result_key = -1
for k in data:
# 车牌在图片的中间位置,而不是边缘位置
if data[k]['x'] == 0 or data[k]['y'] == 0:
print(f"{k} is at the top or the left, pass.")
continue
#
if data[k]['y'] + data[k]['h'] >= car_operator.shape[0]:
print(f"{k} is at hte bottom, pass.")
continue
if data[k]['x'] + data[k]['w'] >= car_operator.shape[1]:
print(f"{k} is at hte right, pass.")
continue
# 选取区域面积比较大(这个特点有点局限性,在我这个图片中比较合适)
if result_key == -1:
result_key = k
else:
if data[k]['area'] > data[result_key]['area']:
result_key = k
result_key
x,y,h,w = data[result_key]['x'],data[result_key]['y'],data[result_key]['h'], data[result_key]['w']
image = car[y:y + h, x:x + w]
字符分割
字符分割的目的是将车牌中的多个字符分割成单个的字符,这样我们就可以对单个字符做模式匹配或者是用模型来做分类,从而识别单个字符是那个数字或者是那个字符,也或者是那个汉字,我们也就达到了车牌识别的目的。
二值化
首先进行高斯模糊屏蔽掉一些细节,然后再进行二值化
gray_image = gray_guss(image)
ret, gray_image = cv2.threshold(gray_image, 0, 255, cv2.THRESH_OTSU)
找出字符的轮廓
我们对车牌进行开操作,目的让字符和边缘尽可能的分开
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
# gray_image = cv2.dilate(gray_image, kernel)
opening = cv2.morphologyEx(gray_image, cv2.MORPH_OPEN, kernel)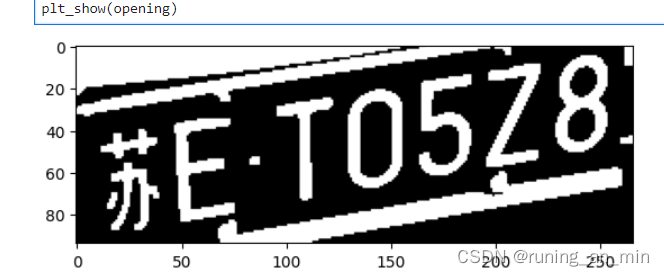
然后进行轮廓查找
img_copy = image.copy()
for item in contours:
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
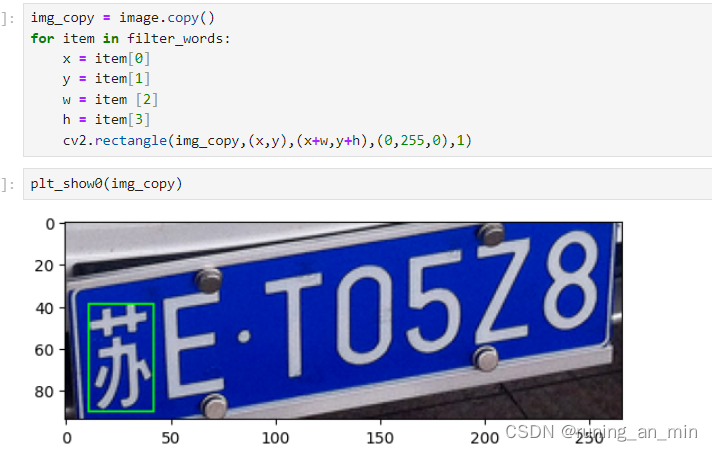
cv2.rectangle(img_copy,(x,y),(x+w,y+h),(0,255,0),1)
这里有一个问题,我们可以看到 苏 被分成两个轮廓了,这样肯定是不能进行匹配的,我试过对车牌进行膨胀操作,但是会导致E和车牌上的螺丝连在一起,最终导致E不能被识别。
这个实验中,我先处理的数字和字母,最后处理的汉字。
把所有的轮廓存储起来:
words = []
#对所有轮廓逐一操作
shape = image.shape
for item in contours:
word = []
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
word.append(x)
word.append(y)
word.append(weight)
word.append(height)
words.append(word)
# 排序,车牌号有顺序。words是一个嵌套列表
words = sorted(words,key=lambda s:s[0],reverse=False)先做一个初步过滤,去掉那些在边缘上的轮廓:
filter_words = []
for item in words:
x = item[0]
y = item[1]
w = item [2]
h = item[3]
if x == 0:
print('x==0', item)
continue
if y == 0:
print('y==0', item)
continue
if y + h >= shape[0]:
print('y+h', item)
continue
if x + w >= shape[1]:
print('x+w', item)
continue
filter_words.append(item)
filter_words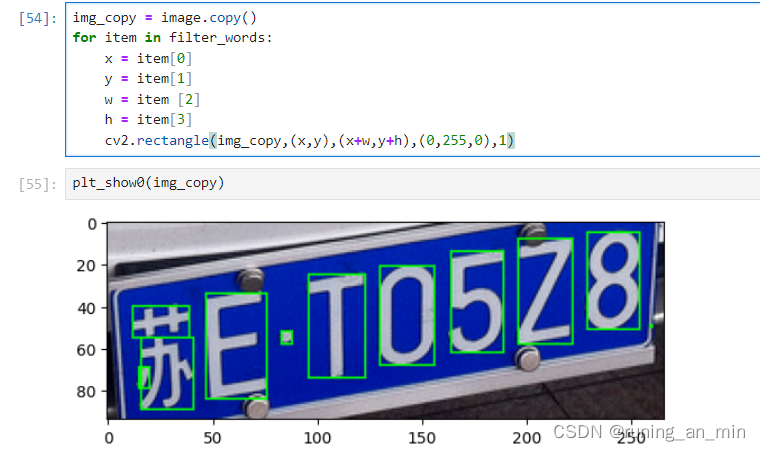
查找数字和字母
然后按照字符的长宽比例筛选出 字母和数字:
word_images = []
i = 0
success_word = []
#word中存放轮廓的起始点和宽高
for word in filter_words:
# 筛选字符的轮廓
# 高> 宽*1.5 高< 宽*3.5 高大于25
print(word)
if (word[3] > (word[2] * 1.5)) and (word[2] > 20 or (word[2] >= 7 and word[3] > 50)):
i = i+1
print(r'---')
splite_image = gray_image[word[1]:word[1] + word[3], word[0]:word[0] + word[2]]
word_images.append(splite_image)
success_word.append(word)
print(i)
# print(words)
for i,j in enumerate(word_images):
plt.subplot(1,7,i+1)
plt.imshow(word_images[i],cmap='gray')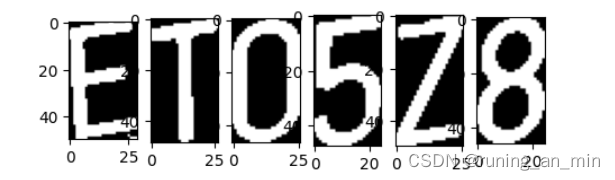
查找汉字
先切割出汉字
sucess_img = gray_image[:, :x]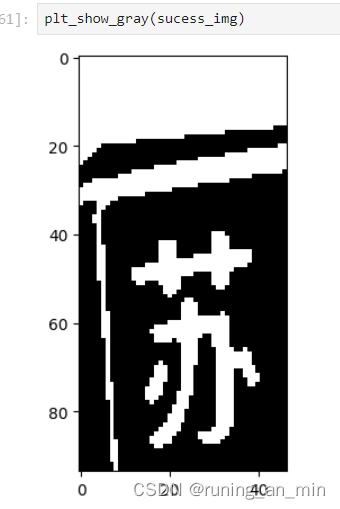
然后进行膨胀操作,让苏的两部分连在一起
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
sucess_img = cv2.dilate(sucess_img, kernel)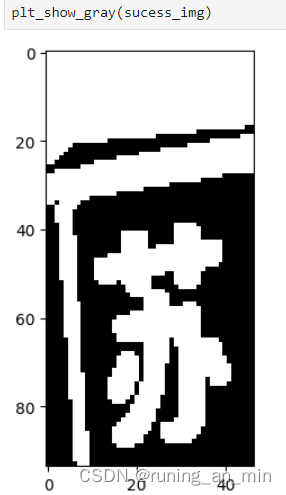
然后进行轮廓查找
contours, hierarchy = cv2.findContours(sucess_img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
img_copy = image.copy()
for item in contours:
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
cv2.rectangle(img_copy,(x,y),(x+w,y+h),(0,255,0),1)
然后和上文一样,利用长宽特征过滤出有用的轮廓
s_words = []
#对所有轮廓逐一操作
shape = image.shape
for item in contours:
word = []
rect = cv2.boundingRect(item)
x = rect[0]
y = rect[1]
weight = rect[2]
height = rect[3]
word.append(x)
word.append(y)
word.append(weight)
word.append(height)
s_words.append(word)
# 排序,车牌号有顺序。words是一个嵌套列表
s_words = sorted(s_words,key=lambda s:s[0],reverse=False)
filter_words = []
for item in s_words:
x = item[0]
y = item[1]
w = item [2]
h = item[3]
if x == 0:
print('x==0', item)
continue
if y == 0:
print('y==0', item)
continue
if y + h >= shape[0]:
print('y+h', item)
continue
if x + w >= shape[1]:
print('x+w', item)
continue
filter_words.append(item)
splite_image = gray_image[filter_words[-1][1]:filter_words[-1][1] + filter_words[-1][3], filter_words[-1][0]:filter_words[-1][0] + filter_words[-1][2]]
word_images.insert(0, splite_image)
for i,j in enumerate(word_images):
plt.subplot(1,7,i+1)
plt.imshow(word_images[i],cmap='gray')
plt.show()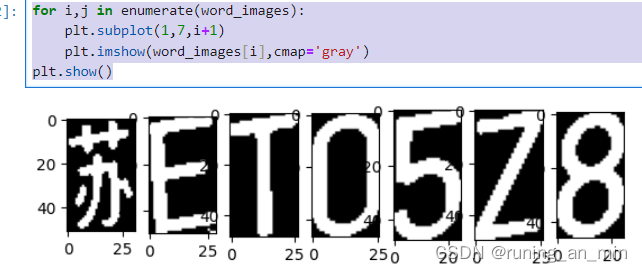
模式匹配
这里需要先获取待匹配的图片,也就是代码中的refer1文件夹,有需要的可以到QQ群中找我要,QQ群地址在文章的最后。
#模版匹配
# 准备模板(template[0-9]为数字模板;)
template = ['0','1','2','3','4','5','6','7','8','9',
'A','B','C','D','E','F','G','H','J','K','L','M','N','P','Q','R','S','T','U','V','W','X','Y','Z',
'藏','川','鄂','甘','赣','贵','桂','黑','沪','吉','冀','津','晋','京','辽','鲁','蒙','闽','宁',
'青','琼','陕','苏','皖','湘','新','渝','豫','粤','云','浙']
# 读取一个文件夹下的所有图片,输入参数是文件名,返回模板文件地址列表
def read_directory(directory_name):
referImg_list = []
for filename in os.listdir(directory_name):
referImg_list.append(directory_name + "/" + filename)
return referImg_list
# 获得中文模板列表(只匹配车牌的第一个字符)
def get_chinese_words_list():
chinese_words_list = []
for i in range(34,64):
#将模板存放在字典中
c_word = read_directory('./refer1/'+ template[i])
chinese_words_list.append(c_word)
return chinese_words_list
chinese_words_list = get_chinese_words_list()
# 获得英文模板列表(只匹配车牌的第二个字符)
def get_eng_words_list():
eng_words_list = []
for i in range(10,34):
e_word = read_directory('./refer1/'+ template[i])
eng_words_list.append(e_word)
return eng_words_list
eng_words_list = get_eng_words_list()
# 获得英文和数字模板列表(匹配车牌后面的字符)
def get_eng_num_words_list():
eng_num_words_list = []
for i in range(0,34):
word = read_directory('./refer1/'+ template[i])
eng_num_words_list.append(word)
return eng_num_words_list
eng_num_words_list = get_eng_num_words_list()
# 读取一个模板地址与图片进行匹配,返回得分
def template_score(template,image):
#将模板进行格式转换
template_img=cv2.imdecode(np.fromfile(template,dtype=np.uint8),1)
template_img = cv2.cvtColor(template_img, cv2.COLOR_RGB2GRAY)
#模板图像阈值化处理——获得黑白图
ret, template_img = cv2.threshold(template_img, 0, 255, cv2.THRESH_OTSU)
# height, width = template_img.shape
# image_ = image.copy()
# image_ = cv2.resize(image_, (width, height))
image_ = image.copy()
#获得待检测图片的尺寸
height, width = image_.shape
# 将模板resize至与图像一样大小
template_img = cv2.resize(template_img, (width, height))
# 模板匹配,返回匹配得分
result = cv2.matchTemplate(image_, template_img, cv2.TM_CCOEFF)
return result[0][0]
# 对分割得到的字符逐一匹配
def template_matching(word_images):
results = []
for index,word_image in enumerate(word_images):
if index==0:
best_score = []
for chinese_words in chinese_words_list:
score = []
for chinese_word in chinese_words:
result = template_score(chinese_word,word_image)
score.append(result)
best_score.append(max(score))
i = best_score.index(max(best_score))
# print(template[34+i])
r = template[34+i]
results.append(r)
continue
if index==1:
best_score = []
for eng_word_list in eng_words_list:
score = []
for eng_word in eng_word_list:
result = template_score(eng_word,word_image)
score.append(result)
best_score.append(max(score))
i = best_score.index(max(best_score))
# print(template[10+i])
r = template[10+i]
results.append(r)
continue
else:
best_score = []
for eng_num_word_list in eng_num_words_list:
score = []
for eng_num_word in eng_num_word_list:
result = template_score(eng_num_word,word_image)
score.append(result)
best_score.append(max(score))
i = best_score.index(max(best_score))
# print(template[i])
r = template[i]
results.append(r)
continue
return results输出结果
word_images_ = word_images.copy()
# 调用函数获得结果
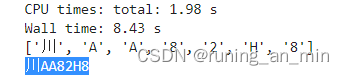
%time result = template_matching(word_images_)
print(result)
# "".join(result)函数将列表转换为拼接好的字符串,方便结果显示
print( "".join(result))
总体上这个方式的局限性比较大,距离应用在实际场景还有很大的差距,可以当做opencv的练手来玩。

这个车牌是可以识别出字符和数字部分

这个图片,车牌都定位不到,待优化的地方还是有很多的,后面可以用yolo试试
####
祝你好运
# 有问题可以进群聊聊
614809646 qq群->数字人和tts,运维、开发等等
####





![LeetCode 刷题 [C++] 第54题.螺旋矩阵](https://img-blog.csdnimg.cn/direct/6847102da86441d39ab18f4058bb6eb0.png)