文章目录
- 一、前言
- 二、gymnasium 简单虚拟环境创建
- 1、gymnasium介绍
- 2、gymnasium 贪吃蛇简单示例
- 三、基于gymnasium创建的虚拟环境训练贪吃蛇Agent
- 1、虚拟环境
- 2、虚拟环境注册
- 3、训练程序
- 4、模型测试
- 三、卷积虚拟环境
- 1、卷积神经网络虚拟环境
- 2、训练代码
一、前言
大家好,未来的开发者们请上座
随着人工智能的发展,强化学习基本会再次来到人们眼前,遂想制作一下相关的教程。强化学习第一步基本离不开虚拟环境的搭建,下面用大家耳熟能详的贪吃蛇游戏为基础,制作一个Agent,完成对这个游戏的绝杀。
万里长城第二步:用python开发贪吃蛇智能体****加粗样式
二、gymnasium 简单虚拟环境创建
1、gymnasium介绍
gymnasium(此前称为gym)是一个由 OpenAI 开发的 Python 库,用于开发和比较强化学习算法。它提供了一组丰富的环境,模拟了各种任务,包括但不限于经典的控制问题、像素级游戏、机器人模拟等。
以下是gymnasium库的一些主要特点:
-
环境多样性:gymnasium包含了一系列不同的环境,每个环境都有其独特的观察空间(输入)和动作空间(输出)。这些环境涵盖了从简单的文本控制任务到复杂的三维视觉任务的广泛范围。
-
标准化API:gymnasium库提供了一个简单且统一的API来与这些环境交互。这使得研究人员和开发人员可以轻松地用相同的代码测试和比较不同的强化学习算法。
-
扩展性:用户可以创建自定义环境并将其集成到gymnasium框架中,这使得库能够适应各种不同的研究需求和应用场景。
-
评估标准:gymnasium环境通常包括预定义的评估标准,如累积回报或任务完成时间,这有助于在不同算法间进行公平的比较。
-
社区支持:由于gymnasium是由OpenAI推出并得到了强化学习社区的广泛支持,因此有大量的教程、论坛讨论和第三方资源可供学习和参考。
-
可视化和监控:gymnasium提供了工具来可视化智能体的性能,并允许监控和记录实验过程,便于分析和调试。
使用gymnasium的基本步骤通常包括:
导入gymnasium库。
创建一个环境实例。
初始化环境。
在一个循环中,根据当前观察值选择动作,执行动作,并接收环境的反馈(新的观察值、奖励、完成状态等)。
结束实验并关闭环境。
2、gymnasium 贪吃蛇简单示例
下面是贪吃蛇虚拟环境的一个简单的示例
在本次示例中,暂未进行任何训练。一切行为主要是从状态空间中随机抽取一个动作并执行。
下面是gymnasium创建的虚拟环境的三个核心函数介绍:
-
reset(): 这个函数用于重置环境到初始状态,并返回初始状态的观测值。在开始每个新的episode时,通常会调用这个函数来初始化环境。
-
step(action): 这个函数用于让Agent在环境中执行一个动作(action),并返回四个值:观测值(observation),奖励(reward),是否终止(done),以及额外信息(info)。Agent根据环境返回的信息来决定下一步的动作。
-
render(): 这个函数用于在屏幕上渲染当前环境的状态,通常用于可视化环境以便观察Agent的行为。不是所有的环境都支持渲染,具体取决于环境的实现。
下面是具体的示例代码
import time
import pygame
import sys
import random
import numpy as np
import gymnasium as gym
class SnakeEnv(gym.Env):
def __init__(self):
super().__init__()
# 初始化Pygame
pygame.init()
# 屏幕宽高
self.SCREEN_WIDTH=240
self.SCREEN_HEIGHT=240
#蛇的方块大小
self.snakeCell=10
# 创建窗口
self.screen = pygame.display.set_mode((self.SCREEN_WIDTH,self.SCREEN_HEIGHT))
pygame.display.set_caption('Snake_Game')
self.action_space=gym.spaces.Discrete(4) #动作空间为4
self.observation_space=gym.spaces.Box(low=0,high=7,shape=(self.SCREEN_WIDTH,self.SCREEN_HEIGHT),dtype=np.uint8)
# 重启
def reset(self):
"""
重置蛇和食物的位置
"""
# 蛇的初始位置
self.snake_head=[100,50]
self.snake_body=[[100,50],[100-self.snakeCell,50],[100-self.snakeCell*2,50]]
self.len=3
# 食物的初始位置
self.food_pos=[random.randint(1,self.SCREEN_WIDTH//10-1)*10,random.randint(1,self.SCREEN_HEIGHT//10-1)*10]
return self._get_observation()
# 根据当前状态 和action 执行动作
def step(self,action):
# 定义动作到方向的映射
directionDict={'LEFT':[1,0],'RIGHT':[-1,0],'UP':[0,-1],'DOWN':[0,1]}
action_to_direction = {
0: "UP",
1: "DOWN",
2: "LEFT",
3: "RIGHT"
}
directionTarget=action_to_direction[action]
nextPosDelay=np.array(directionDict[directionTarget])*self.snakeCell #加的位置
self.snake_head=list(np.array(self.snake_body[0])+nextPosDelay)
if self.snake_head in self.snake_body:
return self._get_observation(), 0, True, False, {}
self.snake_body.insert(0,self.snake_head)
# 如果是吃到食物,就重新刷新果子,同时长度 +1
if self.food_pos == self.snake_head:
self.food_pos = [random.randrange(1, (self.SCREEN_WIDTH // 10)) * 10,
random.randrange(1, (self.SCREEN_HEIGHT // 10)) * 10]
self.len+=1
# 弹出
while self.len<len(self.snake_body):
self.snake_body.pop()
# 奖励
reward,done=self._get_reward()
truncated = True
return self._get_observation(), reward, truncated, done, {}
# 渲染
def render(self,mode="human"):
# 实现可视化
screen = self.screen
# 颜色定义
WHITE= (255,255,255)
GREEN = (0,255,0)
RED = (255,0,0)
# 清空屏幕
screen.fill(WHITE)
# 画蛇和食物
for pos in self.snake_body:
pygame.draw.rect(screen,GREEN,pygame.Rect(pos[0],pos[1],self.snakeCell,self.snakeCell))
pygame.draw.rect(screen,RED,pygame.Rect(self.food_pos[0],self.food_pos[1],self.snakeCell,self.snakeCell))
pygame.display.update()
# 获取奖励
def _get_reward(self):
# 计算奖励
reward = 0
done = False
# 检查蛇是否吃到食物
if self.snake_head:
reward+=10
# 检查蛇是否撞到墙壁或自身
head=self.snake_head
if head[0]<0 or head[0]>self.SCREEN_WIDTH-10 or head[1]<0 or head[1]>self.SCREEN_HEIGHT-10:
reward = -10
done = True
return reward,done
# 获取当前观察空间
def _get_observation(self):
# 获取窗口内容作为观察值
observation = pygame.display.get_surface()
# 将观察值调整为指定的宽度和高度
# observation = pygame.transform.scale(observation, (self.SCREEN_WIDTH, self.SCREEN_HEIGHT))
return observation
def main():
snakeEnv=Snake()
snakeEnv.reset()
done=False
while not done:
# 获取事件
for event in pygame.event.get():
# 处理退出事件
if event.type == pygame.QUIT:
pygame.quit()
done = True
# 从动作空间随机获取一个动作
action= snakeEnv.action_space.sample()
screen, reward, truncated, done,_=snakeEnv.step(action)
snakeEnv.render()
time.sleep(0.03)
if __name__=="__main__":
main()
程序运行截图:

三、基于gymnasium创建的虚拟环境训练贪吃蛇Agent
在上一步中,你已经创建出你要的虚拟环境了,现在让我们在这个创建好的环境中进行训练吧!
1、虚拟环境
SnakeEnv2.py
import time
import pygame
import sys
import random
import numpy as np
import gymnasium as gym
from typing import Optional
class SnakeEnv(gym.Env):
metadata = {
"render_modes": ["human", "rgb_array"],
"render_fps": 30,
}
def __init__(self, render_mode="human"):
super().__init__()
# 初始化Pygame
pygame.init()
# 屏幕宽高
self.SCREEN_WIDTH = 100
self.SCREEN_HEIGHT = 100
# 蛇的方块大小
self.snakeCell = 10
# 游戏速度
self.speed = 12
self.clock = pygame.time.Clock()
# 创建窗口
self.screen = pygame.display.set_mode((self.SCREEN_WIDTH, self.SCREEN_HEIGHT))
pygame.display.set_caption('Snake_Game')
self.render_mode = render_mode
self.action_space = gym.spaces.Discrete(4) # 动作空间为4
self.observation_space = gym.spaces.Box(low=-1, high=1, shape=(self.SCREEN_WIDTH, self.SCREEN_HEIGHT),
dtype=np.float32)
# 初始化蛇和食物的位置等属性
# ...
self.num_timesepts = 0
# 重启
def reset(self, seed: Optional[int] = None, options: Optional[dict] = None):
"""
重置蛇和食物的位置
"""
super().reset(seed=seed)
self.curStep = 0 # 步数
# 蛇的初始位置
self.snake_next = [60, 50]
self.snake_body = [[60, 50], [60 - self.snakeCell, 50], [60 - self.snakeCell * 2, 50]]
self.len = 3
# 食物的初始位置
self.food_pos = [random.randint(1, self.SCREEN_WIDTH // 10 - 1) * 10,
random.randint(1, self.SCREEN_HEIGHT // 10 - 1) * 10]
info = {}
#
return self._get_observation(), info
# 根据当前状态 和action 执行动作
def step(self, action):
self.num_timesepts += 1 # 步骤统计加1
# 定义动作到方向的映射
directionDict = {'LEFT': [-1, 0], 'RIGHT': [1, 0], 'UP': [0, -1], 'DOWN': [0, 1]}
action_to_direction = {
0: "UP",
1: "DOWN",
2: "LEFT",
3: "RIGHT"
}
directionTarget = action_to_direction[action]
nextPosDelay = np.array(directionDict[directionTarget]) * self.snakeCell # 加的位置
# 输入action 获取到 snake_next 下一步
self.snake_next = list(np.array(self.snake_body[0]) + nextPosDelay)
if self.snake_next == self.snake_body[1]:
return self._get_observation(), -0.5, False, False, {}
# 奖励
reward, terminated = self._get_reward()
# 如果是吃到食物,就重新刷新果子,同时长度 +1
if self.food_pos == self.snake_next:
self.food_pos = [random.randrange(1, (self.SCREEN_WIDTH // 10-1)) * 10,
random.randrange(1, (self.SCREEN_HEIGHT // 10-1)) * 10]
self.len += 1
truncated = False
info = {}
# if self.render_mode == "human":
if self.render_mode == "human" and self.num_timesepts % 5000 > 4000 and self.num_timesepts > 10000:
self.render()
for event in pygame.event.get():
if event == pygame.QUIT:
pygame.quit()
sys.exit()
if not terminated:
self.snake_body.insert(0, self.snake_next)
# 弹出
while self.len < len(self.snake_body):
self.snake_body.pop()
return self._get_observation(), reward,terminated, truncated,{}
# 渲染
def render(self):
# 实现可视化
screen = self.screen
# 颜色定义
WHITE = (255, 255, 255)
GREEN = (0, 255, 0)
RED = (255, 0, 0)
# 清空屏幕
screen.fill(WHITE)
# 画蛇和食物
snakecolor = np.linspace(0.9, 0.5, len(self.snake_body), dtype=np.float32)
for i in range(len(self.snake_body)):
pos = self.snake_body[len(self.snake_body) - i - 1]
color = [int(round(component * snakecolor[i])) for component in GREEN]
pygame.draw.rect(screen, color, pygame.Rect(pos[0], pos[1], self.snakeCell, self.snakeCell))
pygame.draw.rect(screen, RED, pygame.Rect(self.food_pos[0], self.food_pos[1], self.snakeCell, self.snakeCell))
pygame.display.update()
self.clock.tick(self.speed)
def GetDic(self,p1,p2):
return np.linalg.norm(np.array(p1) - np.array(p2))
# 获取奖励
def _get_reward(self):
# 计算奖励
self.curStep += 1 # 步数
reward = 0
terminated = False
flag=0
# 正向激励
# 检查蛇是否吃到食物 ,吃到食物,就开始猛猛奖励
if self.snake_next == self.food_pos:
reward += 500 + pow(5, self.len)
self.curStep = 0
#print(reward)
# 负向激励
# 检查蛇是否撞到墙壁或自身,游戏结束就负向奖励
head = self.snake_next
if head[0] < 0 or head[0] > self.SCREEN_WIDTH-10 or head[1] < 0 or head[
1] > self.SCREEN_HEIGHT-10 or self.snake_next in self.snake_body or self.curStep>500:
reward -= 100 / self.len
terminated = True
self.curStep = 0
# 摸鱼步数超过一定值就开始负向奖励
if self.curStep > 100 * self.len:
reward -= 1 / self.len
# 中向激励
if self.GetDic(self.snake_next,self.food_pos)< self.GetDic(self.snake_body[0],self.food_pos):
reward += 2 / self.len * (self.SCREEN_WIDTH-self.GetDic(self.snake_body[0],self.food_pos)) /self.SCREEN_WIDTH # No upper limit might enable the agent to master shorter scenario faster and more firmly.
else:
reward -= 1 / self.len
#print(reward * 0.3)
if reward<0:
#print(reward * 0.2)
pass
#print(reward* 0.2)
return reward * 0.2, terminated
# 获取当前观察空间
def _get_observation(self):
# 返回观察空间,也就是一个二维数组
obs = np.zeros((self.SCREEN_WIDTH, self.SCREEN_HEIGHT), dtype=np.float32)
obs[tuple(np.transpose(self.snake_body))] = np.linspace(0.8, 0.2, len(self.snake_body), dtype=np.float32)
obs[tuple(self.snake_body[0])] = 1.0
obs[tuple(self.food_pos)] = -1.0
return obs
def main():
snakeEnv = SnakeEnv()
snakeEnv.reset()
done = False
while not done:
# 获取事件
for event in pygame.event.get():
# 处理退出事件
if event.type == pygame.QUIT:
pygame.quit()
done = True
# 从动作空间随机获取一个动作
action = snakeEnv.action_space.sample()
screen, reward, truncated, done, _ = snakeEnv.step(action)
snakeEnv.render()
if __name__ == "__main__":
main()
2、虚拟环境注册
打开当前项目的site-packages

找到gymnasium
将其SnakeEnv2.py放置如下,并在init.py中添加调用注册函数
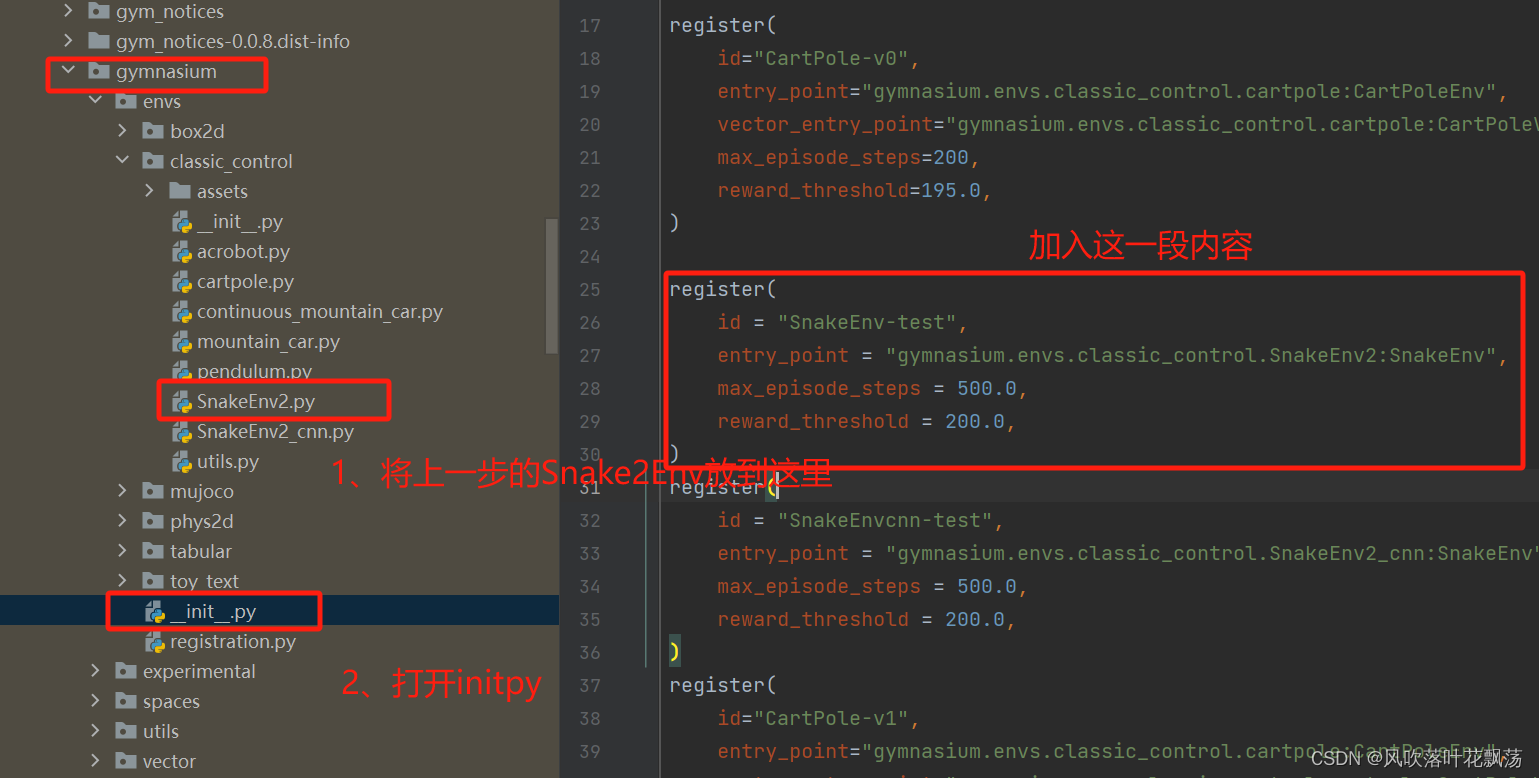
到这里就注册完毕,可以进行训练了
3、训练程序
snake_train.py 具体代码如下
# 1、导入必要的库并创建环境:
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import CheckpointCallback
import os
import sys
# Linear scheduler
def linear_schedule(initial_value, final_value=0.0):
if isinstance(initial_value, str):
initial_value = float(initial_value)
final_value = float(final_value)
assert (initial_value > 0.0)
def scheduler(progress):
return final_value + progress * (initial_value - final_value)
return scheduler
# 2、创建环境,例如 CartPole
env = gym.make('SnakeEnv-test',render_mode="human")
# 3、创建 PPO 模型并指定环境:
lr_schedule = linear_schedule(2.5e-2, 2.5e-6)
clip_range_schedule = linear_schedule(0.15, 0.025)
model = PPO("MlpPolicy", env, verbose=1, device="cuda",
n_steps=2048,
batch_size=512,
n_epochs=4,
gamma=0.94,
learning_rate=lr_schedule,
clip_range=clip_range_schedule,
)
# 4、训练模型:
# Set the save directory
num=1
save_dir="trained_models_mlp"
while True:
save_dir = "trained_models_mlp_{}".format(num)
if not os.path.exists(save_dir):
os.mkdir(save_dir)
break
else:
num +=1
checkpoint_interval = 30000 # checkpoint_interval * num_envs = total_steps_per_checkpoint
checkpoint_callback = CheckpointCallback(save_freq=checkpoint_interval, save_path=save_dir, name_prefix="ppo_snake")
# Writing the training logs from stdout to a file
original_stdout = sys.stdout
log_file_path = os.path.join(save_dir, "training_log.txt")
print('开始训练'+save_dir)
model.learn(
total_timesteps=int(200000),
callback=[checkpoint_callback]
)
# Restore stdout
sys.stdout = original_stdout
# Save the final model
model.save(os.path.join(save_dir, "ppo_snake_final.zip"))
4、模型测试
对训练好的模型进行测试,可以用如下代码
import time
import random
from sb3_contrib import MaskablePPO
from stable_baselines3 import PPO
from snakecnn23 import SnakeEnv
import pygame
MODEL_PATH=r'H:\AILab\RL\Snaker2\trained_models_cnn\ppo_snake_final'
# Load the trained model
model = MaskablePPO.load(MODEL_PATH)
snakeEnv = SnakeEnv()
for i in range(10):
obs,info=snakeEnv.reset()
terminated = False
while not terminated:
# 获取事件
for event in pygame.event.get():
if event == pygame.QUIT:
pygame.quit()
# 从动作空间随机获取一个动作
action ,_= model.predict(obs, action_masks=snakeEnv.get_action_mask())
prev_mask = snakeEnv.get_action_mask()
action_value=int(action.item())
obs, reward, terminated, truncated, _ = snakeEnv.step(action_value)
snakeEnv.render()
三、卷积虚拟环境
上面的是基于多层感知机,上限有限,可能效果不是很好,可以对其进行一点点改进
核心是修改
self.observation_space = gym.spaces.Box(low=0, high=255, shape=(self.SCREEN_WIDTH, self.SCREEN_HEIGHT,3),dtype=np.uint8)
和 _get_observation() 观察空间
改完这两个其他的基本不用变
1、卷积神经网络虚拟环境
import time
import pygame
import sys
import random
import numpy as np
import gymnasium as gym
from typing import Optional
class SnakeEnv(gym.Env):
metadata = {
"render_modes": ["human", "rgb_array"],
"render_fps": 30,
}
def __init__(self, render_mode="human"):
super().__init__()
# 初始化Pygame
pygame.init()
# 屏幕宽高
self.SCREEN_WIDTH = 84
self.SCREEN_HEIGHT = 84
# 蛇的方块大小
self.snakeCell = 7
# 游戏速度
self.speed = 12
self.clock = pygame.time.Clock()
# 创建窗口
self.screen = pygame.display.set_mode((self.SCREEN_WIDTH, self.SCREEN_HEIGHT))
pygame.display.set_caption('Snake_Game')
self.render_mode = render_mode
self.action_space = gym.spaces.Discrete(4) # 动作空间为4
self.observation_space = gym.spaces.Box(low=0, high=255, shape=(self.SCREEN_WIDTH, self.SCREEN_HEIGHT,3),
dtype=np.uint8)
# 初始化蛇和食物的位置等属性
# ...
self.num_timesepts = 0
# 重启
def reset(self, seed: Optional[int] = None, options: Optional[dict] = None):
"""
重置蛇和食物的位置
"""
super().reset(seed=seed)
self.curStep = 0 # 步数
# 蛇的初始位置
self.snake_next = [60, 50]
self.snake_body = [[60, 50], [60 - self.snakeCell, 50], [60 - self.snakeCell * 2, 50]]
self.len = 3
# 食物的初始位置
self.food_pos = [random.randint(1, self.SCREEN_WIDTH // 10 - 1) * 10,
random.randint(1, self.SCREEN_HEIGHT // 10 - 1) * 10]
info = {}
#
return self._get_observation(), info
# 根据当前状态 和action 执行动作
def step(self, action):
self.num_timesepts += 1 # 步骤统计加1
# 定义动作到方向的映射
directionDict = {'LEFT': [-1, 0], 'RIGHT': [1, 0], 'UP': [0, -1], 'DOWN': [0, 1]}
action_to_direction = {
0: "UP",
1: "DOWN",
2: "LEFT",
3: "RIGHT"
}
directionTarget = action_to_direction[action]
nextPosDelay = np.array(directionDict[directionTarget]) * self.snakeCell # 加的位置
# 输入action 获取到 snake_next 下一步
self.snake_next = list(np.array(self.snake_body[0]) + nextPosDelay)
if self.snake_next == self.snake_body[1]:
return self._get_observation(), -0.5, False, False, {}
# 奖励
reward, terminated = self._get_reward(action)
# 如果是吃到食物,就重新刷新果子,同时长度 +1
if self.food_pos == self.snake_next:
self.food_pos = [random.randrange(1, (self.SCREEN_WIDTH // 10-1)) * 10,
random.randrange(1, (self.SCREEN_HEIGHT // 10-1)) * 10]
self.len += 1
truncated = False
info = {}
# if self.render_mode == "human":
if self.render_mode == "human" and self.num_timesepts % 5000 > 4500 and self.num_timesepts > 10000:
self.render()
for event in pygame.event.get():
if event == pygame.QUIT:
pygame.quit()
sys.exit()
if not terminated:
self.snake_body.insert(0, self.snake_next)
# 弹出
while self.len < len(self.snake_body):
self.snake_body.pop()
return self._get_observation(), reward,terminated, truncated,{}
# 渲染
def render(self):
# 实现可视化
screen = self.screen
# 颜色定义
WHITE = (255, 255, 255)
GREEN = (0, 255, 0)
RED = (255, 0, 0)
# 清空屏幕
screen.fill(WHITE)
# 画蛇和食物
snakecolor = np.linspace(0.9, 0.5, len(self.snake_body), dtype=np.float32)
for i in range(len(self.snake_body)):
pos = self.snake_body[len(self.snake_body) - i - 1]
color = [int(round(component * snakecolor[i])) for component in GREEN]
pygame.draw.rect(screen, color, pygame.Rect(pos[0], pos[1], self.snakeCell, self.snakeCell))
pygame.draw.rect(screen, RED, pygame.Rect(self.food_pos[0], self.food_pos[1], self.snakeCell, self.snakeCell))
pygame.display.update()
self.clock.tick(self.speed)
def GetDic(self,p1,p2):
return np.linalg.norm(np.array(p1) - np.array(p2))
# 获取奖励
def _get_reward(self,action):
# 计算奖励
self.curStep += 1 # 步数
reward = 0
terminated = False
flag=0
# 正向激励
# 检查蛇是否吃到食物 ,吃到食物,就开始猛猛奖励
if self.snake_next == self.food_pos:
reward += 400 + pow(5, self.len)
self.curStep = 0
# print(reward)
#print(action)
# print(self.snake_body,self.food_pos,self.snake_next)
# 负向激励
# 检查蛇是否撞到墙壁或自身,游戏结束就负向奖励
head = self.snake_next
if head[0] < 0 or head[0] > self.SCREEN_WIDTH-10 or head[1] < 0 or head[
1] > self.SCREEN_HEIGHT-10 or self.snake_next in self.snake_body or self.curStep>500:
reward -= 200 / self.len
terminated = True
self.curStep = 0
# 摸鱼步数超过一定值就开始负向奖励
if self.curStep > 250 * self.len:
reward -= 1 / self.len
# 中向激励
if self.GetDic(self.snake_next,self.food_pos)< self.GetDic(self.snake_body[0],self.food_pos):
reward += 4 / self.len * (self.SCREEN_WIDTH-self.GetDic(self.snake_next,self.food_pos)) /self.SCREEN_WIDTH # No upper limit might enable the agent to master shorter scenario faster and more firmly.
elif self.curStep>50 and self.GetDic(self.snake_next,self.food_pos)>= self.GetDic(self.snake_body[0],self.food_pos):
reward -= 2 / self.len * self.GetDic(self.snake_next,self.food_pos) /self.SCREEN_WIDTH
#print(reward * 0.3)
if reward<0:
#print(reward * 0.2)
pass
# print(reward* 0.2)
return reward * 0.2, terminated
# 获取当前观察空间
def _get_observation(self):
obs = np.zeros((self.SCREEN_WIDTH//self.snakeCell, self.SCREEN_HEIGHT//self.snakeCell), dtype=np.uint8)
# Set the snake body to gray with linearly decreasing intensity from head to tail.
newsnake=np.array(self.snake_body)//7
obs[tuple(np.transpose(newsnake))] = np.linspace(200, 50, len(newsnake), dtype=np.uint8)
# Stack single layer into 3-channel-image.
obs = np.stack((obs, obs, obs), axis=-1)
# Set the snake head to green and the tail to blue
obs[tuple(newsnake[0])] = [0, 255, 0]
obs[tuple(newsnake[-1])] = [255, 0, 0]
# Set the food to red
obs[np.array(self.food_pos)//7] = [0, 0, 255]
# Enlarge the observation to 84x84
obs = np.repeat(np.repeat(obs, self.snakeCell, axis=0), self.snakeCell, axis=1)
return obs
def main():
snakeEnv = SnakeEnv()
snakeEnv.reset()
done = False
while not done:
# 获取事件
for event in pygame.event.get():
# 处理退出事件
if event.type == pygame.QUIT:
pygame.quit()
done = True
# 从动作空间随机获取一个动作
action = snakeEnv.action_space.sample()
screen, reward, truncated, done, _ = snakeEnv.step(action)
snakeEnv.render()
if __name__ == "__main__":
main()
2、训练代码
核心是修改算法名,之前用MlpPolicy,现在改为CnnPolicy
其余不变
# 1、导入必要的库并创建环境:
import gymnasium as gym
from stable_baselines3 import PPO
from stable_baselines3.common.callbacks import CheckpointCallback
import os
import sys
# Linear scheduler
from stable_baselines3 import PPO
def linear_schedule(initial_value, final_value=0.0):
if isinstance(initial_value, str):
initial_value = float(initial_value)
final_value = float(final_value)
assert (initial_value > 0.0)
def scheduler(progress):
return final_value + progress * (initial_value - final_value)
return scheduler
LOG_DIR = "logs"
os.makedirs(LOG_DIR, exist_ok=True)
# 2、创建环境,例如 CartPole
env = gym.make('SnakeEnvcnn-test',render_mode="human")
# 3、创建 PPO 模型并指定环境:
lr_schedule = linear_schedule(2.5e-3, 2.5e-6)
clip_range_schedule = linear_schedule(0.15, 0.025)
model = PPO( "CnnPolicy",
env,
device="cuda",
verbose=1,
n_steps=2048,
batch_size=512,
n_epochs=4,
gamma=0.94,
learning_rate=lr_schedule,
clip_range=clip_range_schedule,
tensorboard_log=LOG_DIR
)
# 4、训练模型:
# Set the save directory
num=1
save_dir="trained_models_cnn"
while True:
save_dir = "trained_models_cnn_{}".format(num)
if not os.path.exists(save_dir):
os.mkdir(save_dir)
break
else:
num +=1
checkpoint_interval = 30000 # checkpoint_interval * num_envs = total_steps_per_checkpoint
checkpoint_callback = CheckpointCallback(save_freq=checkpoint_interval, save_path=save_dir, name_prefix="ppo_snake")
# Writing the training logs from stdout to a file
original_stdout = sys.stdout
log_file_path = os.path.join(save_dir, "training_log.txt")
print('开始训练'+save_dir)
model.learn(
total_timesteps=int(200000),
callback=[checkpoint_callback]
)
# Restore stdout
sys.stdout = original_stdout
# Save the final model
model.save(os.path.join(save_dir, "ppo_snake_final.zip"))
# 5、测试训练好的模型:
obs = env.reset()
for i in range(1000):
action, _states = model.predict(obs, deterministic=True)
observation, reward, terminated, truncated, info = env.step(action)
env.render()
if terminated:
obs = env.reset()
env.close()