论文地址:Large Language Models for Generative Information Extraction: A Survey
前言
映像中,比较早地使用“大模型“”进行信息抽取的一篇论文是2022年发表的《Unified Structure Generation for Universal Information Extraction》,也是我们常说的UIE模型,其主要在T5-v1.1模型的基础上训练一个Text to structure 的UIE基座模型,然后在具体的业务上再进行Fine-tuning。T5也算是比较早期的的大语言模型了。
时至今日,chatgpt问世后,各种大模型也不断涌现。大模型在理解能力和生成能力上表现出了非凡的能力。也因为LLM有这么强大的能力,业界已经提出了许多工作来利用 LLM 的能力,并为基于生成范式的 IE 任务提供一些可行的解决方案。下面我们就跟着《Large Language Models for Generative Information Extraction: A Survey》来看看LLM在IE任务的一些任务上是如何实现的。
信息抽取回顾
信息提取 (IE) 是自然语言处理中的一个关键领域,它将纯文本转换为结构化知识。IE 是对各种下游任务的基本要求,例如知识图谱构建、知识推理和问答等。常见的IE任务主要包含命名实体识别NER,关系抽取RE,事件抽取EE。传统的信息抽取主要使用序列标注、指针抽取等方法从原文中提取(带有抽取元素location)。
LLM时代的信息抽取(生成式)
生成式的信息提取,可以建模成如下公式:
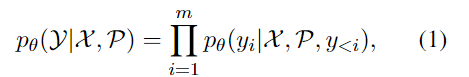
公式中的参数也比较好理解:
- θ \theta θ LLMs参数,可以固定也可以继续训练
- X X X 待提取的文本
- Y Y Y 预期生成后的结果
- P P P,LLM时代比较有特色的参数,就是基于输入 X X X的提示prompt或者说是指令instructions
目标就是最大化最大化这个条件概率。对于不同的IE子任务来说,虽然输入 X X X,但是最终期望LLM输出的结果 Y Y Y有所不同,:
- NER,NER包含两个子任务:实体识别出来和将识别出来的实体进行下一步的分类
- RE,实体识别使用关系抽取的基础,关系抽取可以根据具体的业务进行分类:1.关系分类,2.关系三元组的识别,识别头尾实体以及对应的关系;3.更加严格的识别头尾实体类型以及对应的关系
- EE,事件抽取可以分为两个子任务:1.事件检测(识别事件触发词以及触发词的类型);2.事件要素提取
下面看看使用LLM做几个任务的方法的概览如下:

NER
主流的方法在主流的数据集上的表现情况如下:
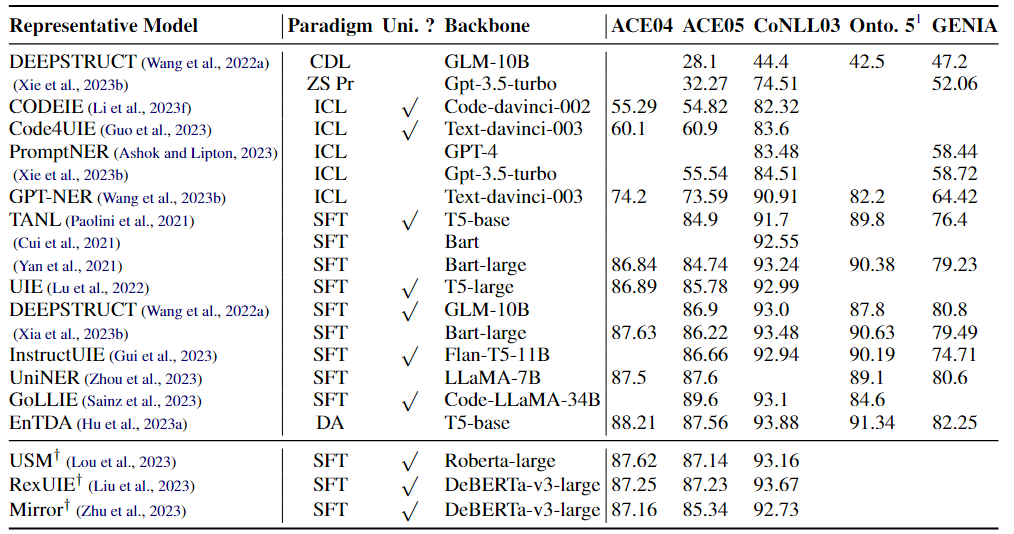
表说明:
- Cross-Domain Learning (CDL),跨领域学习
- Zero-Shot Prompting (ZS Pr),
- In-Context Learning (ICL)
- Supervised Fine-Tuning (SFT)
- Data Augmentation (DA).
- Uni. ? 表示模型是否是统一的抽取模型(完成多种任务)
可以得出的结论是:
- few-shot和zero-shot相比于SFT和DA还是有比较大的差距;
- 即使都是用ICL,GPT-NER与其他同样使用ICL的方法相比差距小的有6%,大的能够达19%
- 相比于ICL,使用SFT的方法,即使使用的基座模型参数有的差距会有很大,但是最后的指标却差距不大
RE
一些主要的方法实现的效果如下:
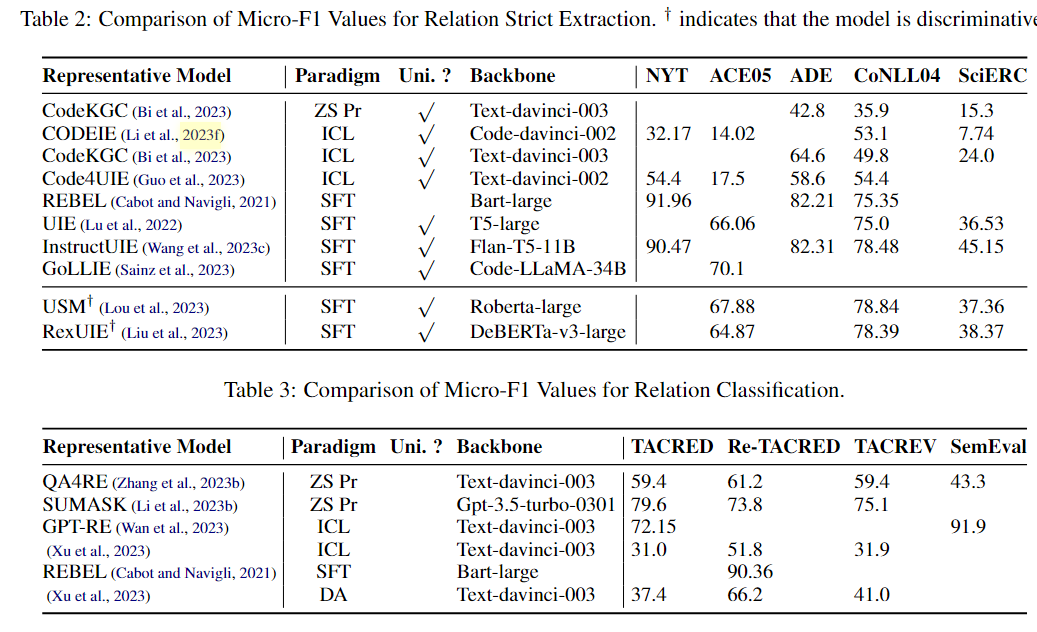
可以得出的结论是:
- 统一抽取的模型更偏向处理复杂的关系(头尾实体、实体类型,实体关系);
- 特定的任务则不是统一的抽取方式,不过解决的是比较简单关系分类;
- 与NER相比关系抽取的效果比NER差不少,提升的空间还很大
统一的信息抽取
该框架旨在为所有IE任务建模,获取IE的通用能力,并学习多个任务之间的依赖关系。现有的研究将这种Uni-IE划分为:natural language-based LLMs (NL-LLMs) 和 code-based LLMs (code-LLMs),参见下图:
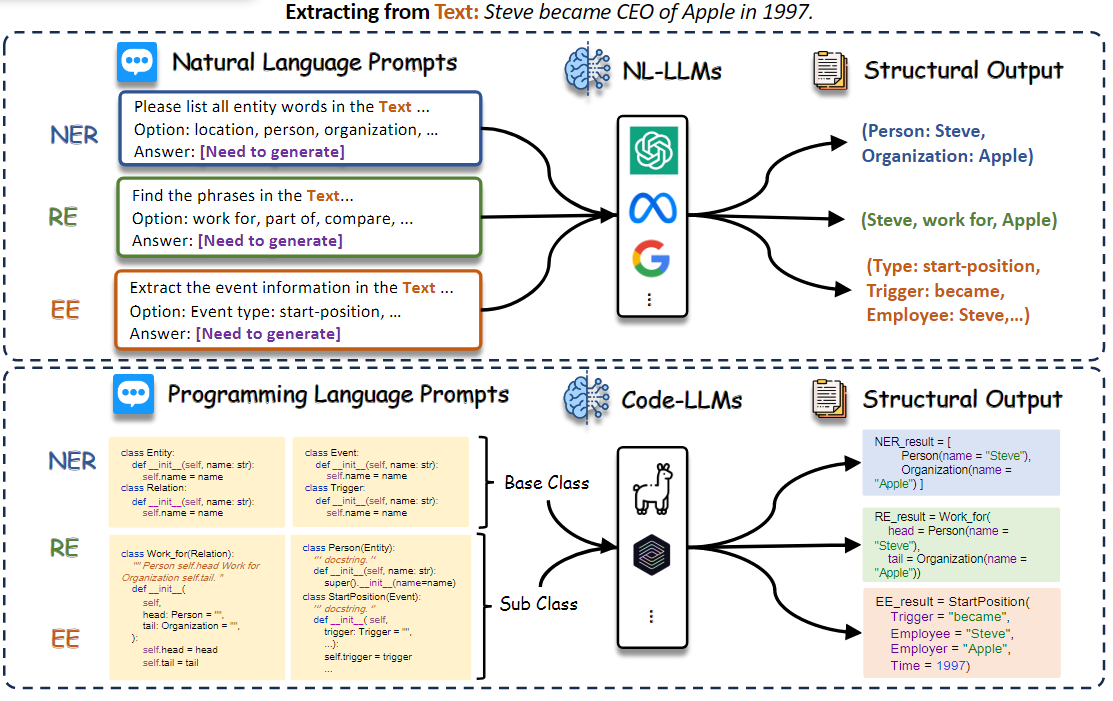
NL-LLMs:比较早的还是文中开头中提到的UIE模型,也就是一种text2structure结构。此外还有:InstructUIE、ChatIE等。
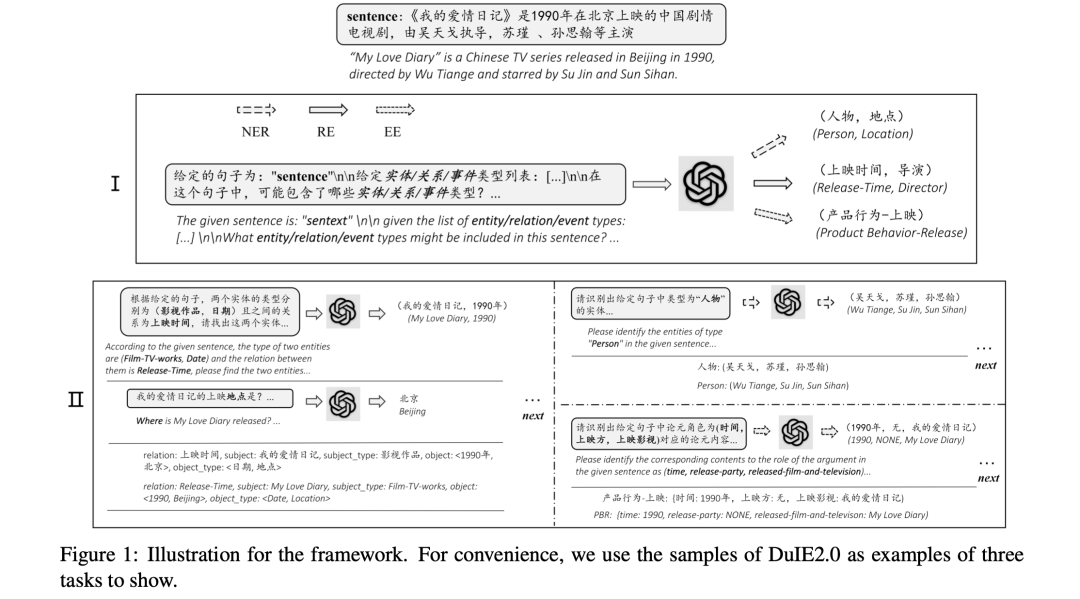
其中UIE《Unified Structure Generation for Universal Information Extraction》,提出一个统一的从文本到结构的生成框架,该框架可对外延结构进行编码,并通过结构化提取语言捕捉常见的IE能力。

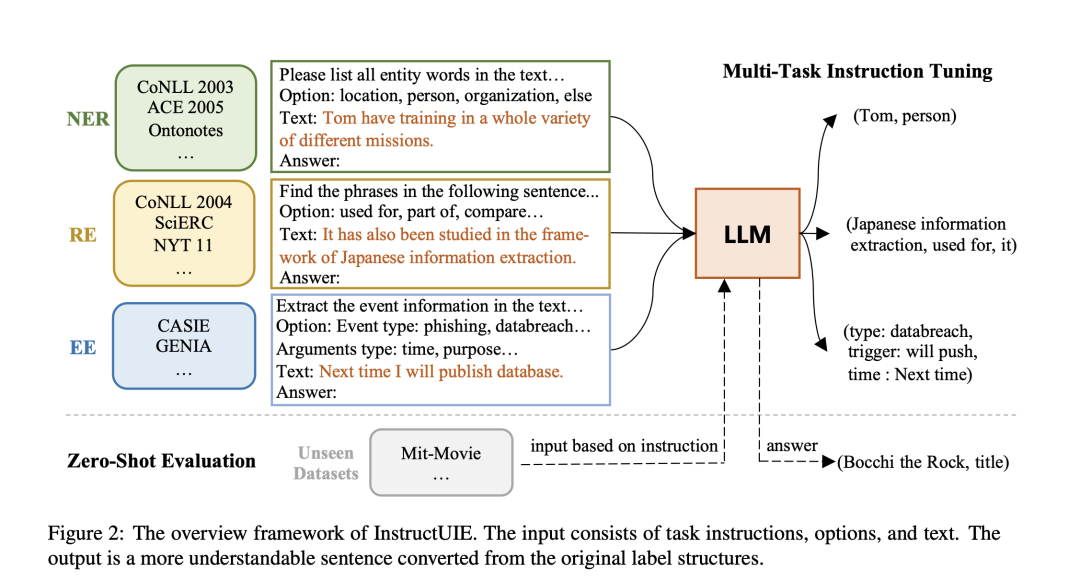
InstructUIE《InstructUIE: Multi-task Instruction Tuning for Unified Information Extraction》,通过结构化专家编写的指令来微调LLM,从而增强UIE,以一致地模拟不同的IE任务并捕捉任务间的依赖性.
ChatIE《Zero-Shot Information Extraction via Chatting with ChatGPT》, 探索了如何在zero-shot提示中使用GPT3和ChatGPT等LLM,将任务转化为多轮问题解答问题.
Code-LLMs:LLM根据需要抽取的文本,将实体和关系放到代码的class中。例如:Code4UIE、CodeKGC、GoLLIE等。
Code4UIE《Retrieval-Augmented Code Generation for Universal Information Extraction》提出一个通用的检索增强代码生成框架,利用Python类来定义模式,并使用上下文学习来生成从文本中提取结构知识的代码

CodeKGC《CodeKGC: Code Language Model for Generative Knowledge Graph Construction》.利用代码中固有的结构知识,并采用模式感知提示和理性增强生成来提高性能。
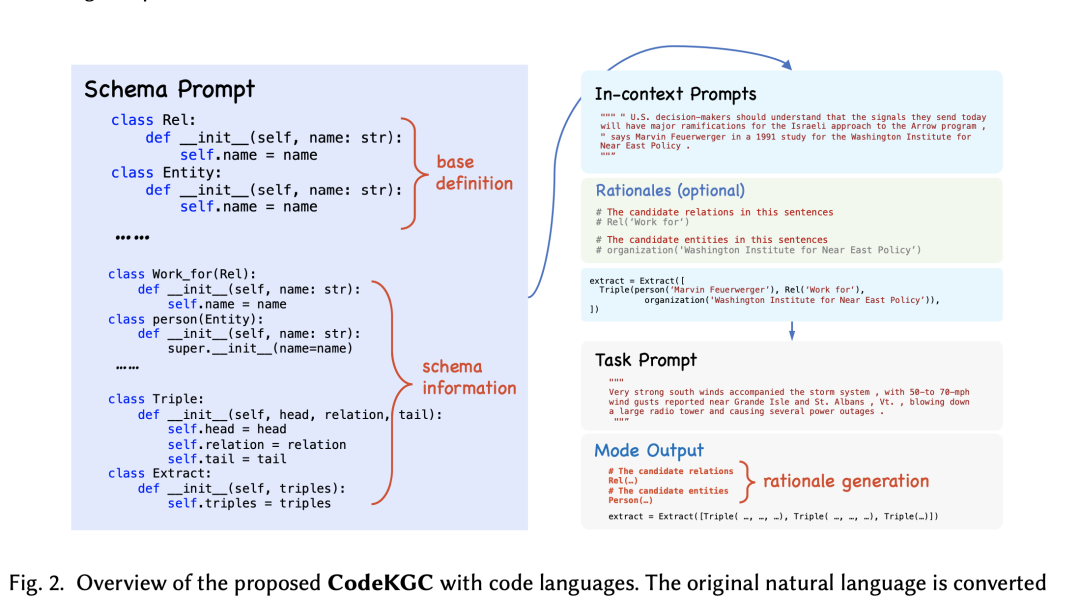
不过从上表面的表来看,对于大多数数据集,具有SFT的uni-IE模型在NER、RE和EE任务中优于任务特定模型。
按照学习范式进行分类
学习范式主要分为:SFT、Zero-Shot、Few-Shot、数据增强几类。
- SFT:输入所有训练数据来微调llm是最常见和最有前途的方法,它允许模型捕获数据中的底层结构模式,并很好地推广到看不见的IE任务。
- Few-Shot:只能访问有限数量的标记示例,这导致了过度拟合和难以捕获复杂关系等挑战。但与小型预训练模型相比,扩大llm的参数使它们具有惊人的泛化能力,使它们能够在少数场景中也能获得出色的性能。
- Zero-Shot:主要挑战在于使模型能够有效地泛化它尚未训练过的任务和领域,以及对齐预训练的LLM范式。由于大量的知识嵌入其中,llm在未知任务的zero-shot场景中表现出令人印象深刻的能力
- 数据增强:数据增强包括生成有意义和多样化的数据,以有效地增强训练示例或信息,同时避免引入不现实的、误导性的和偏移的模式。
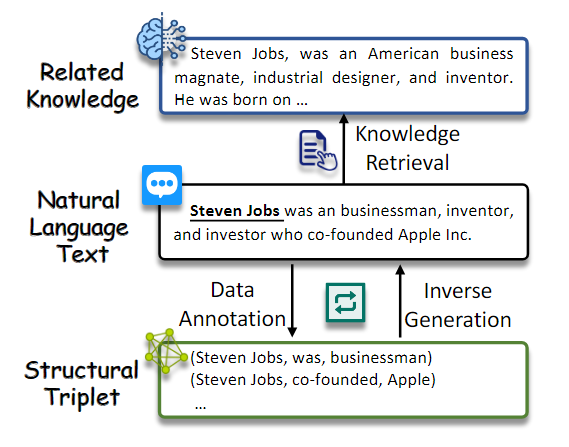
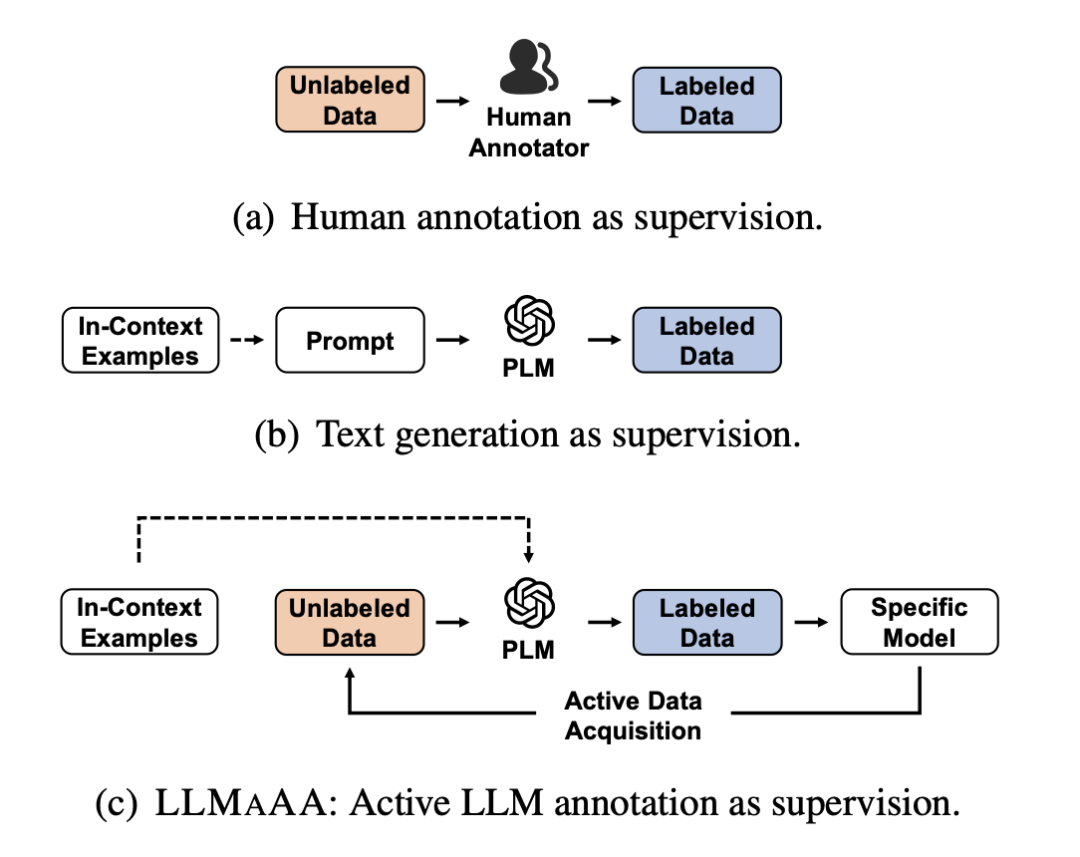
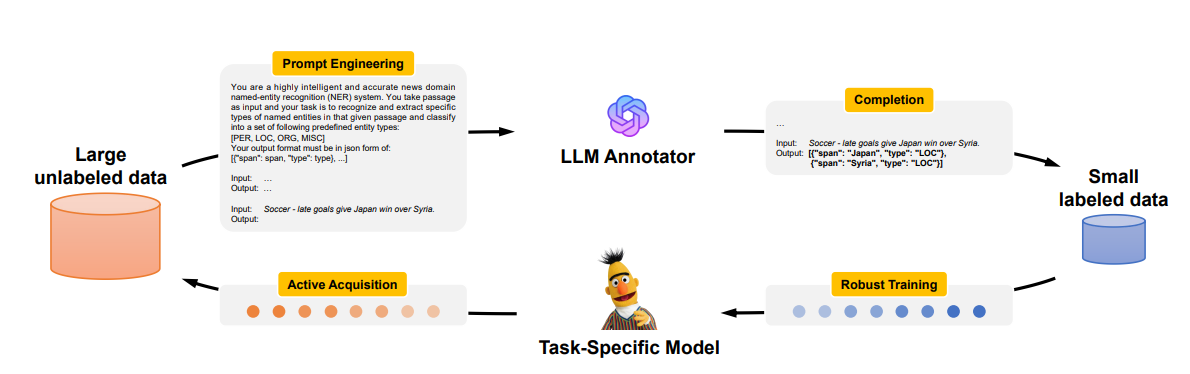
特别要说的是数据增强这块,信息抽取最大的问题就是训练数据的问题,数据增强生成有意义的多样化数据,以有效增强训练示例或信息,同时避免引入不切实际、误导性和偏移的模式。主流方法可大致分为3种策略:
-
数据标注,使用LLM直接生成带有标签的数据;
LLMaAA《LLMaAA: Making Large Language Models as Active Annotators》,通过在主动学习环路中使用LLMs作为标注器来提高准确性和数据效率,从而优化标注和训练过程.
-
知识检索,该策略从 LLM 中检索 IE 的相关知识;
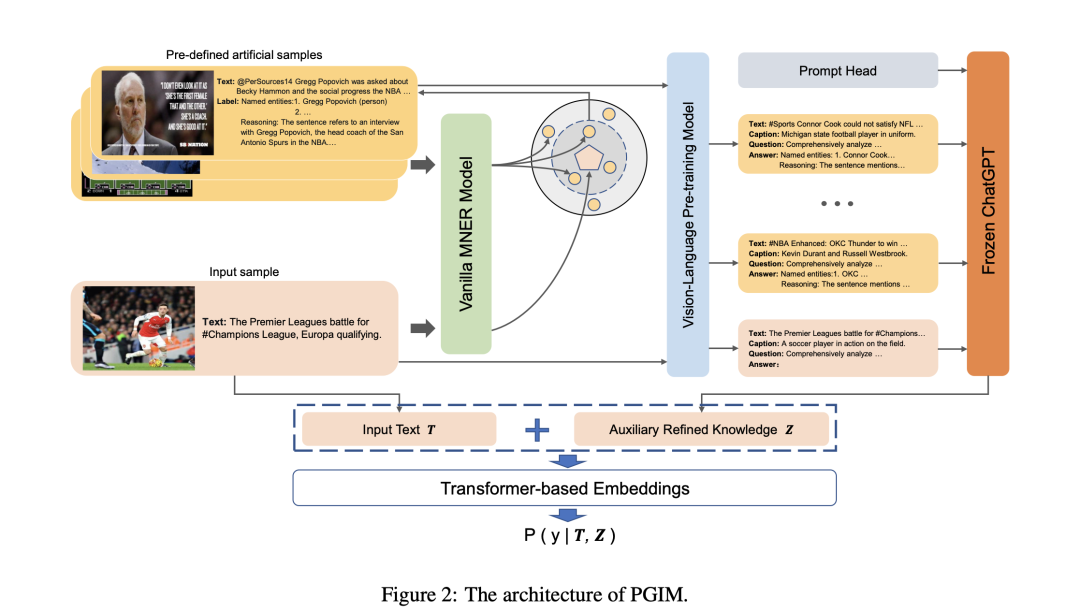
PGIM《Prompting ChatGPT in MNER: Enhanced Multimodal Named Entity Recognition with Auxiliary Refined Knowledge》 为多模态NER提出了一个两阶段框架,利用ChatGPT作为隐式知识库,启发式地检索辅助知识,以提高实体预判词的效率。
-
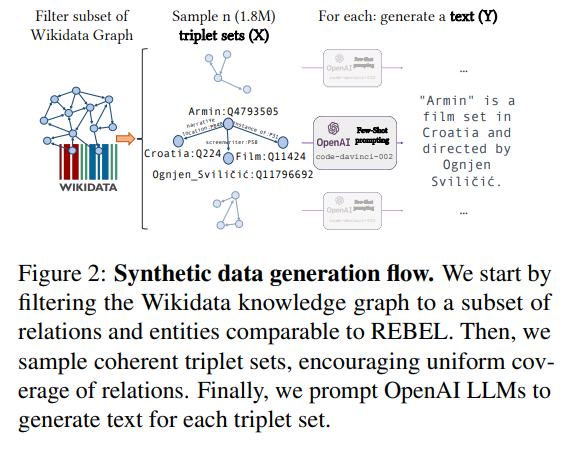
反向生成,这种策略促使LLM根据作为输入的结构数据生成自然文本或问题,与LLM的训练范式保持一致。
SynthIE《Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and The Case of Information Extraction》 使用输入的结构数据生成自然文本。
未来方向

想把 LLM应用到实际的IE系统中还为时过早,也就意味着会有更多的机会和提升。例如:
- 真正意义上的Universal IE, 进一步开发能够灵活适应不同领域和任务的通用IE框架是一个很有前途的研究方向;
- Low-Resource IE;
- Prompt Design for IE, 更好的prompt和instructions设计方式
- Open IE,比较大的挑战
总结
总的来说,使用LLM做信息抽取与传统的方法还是存在比较大的差距。但LLM能够为超痛的信息抽取pipline赋能,至于未来LLM在信息抽取领域发展的什么程度,例如模型参数量级在很少的情况下使用一些sft数据就能够达到很好的效果下,那岂不是美哉。
Reference
1.2024开篇之大模型遇见信息抽取:常见数据增强、形式化语言及可练手小模型开源项目