写在前面
在这篇文章 我们看了使用dis_max查询来进行单值多字段场景下的查询,如下:
POST /blogs/_search
{
"query": {
"dis_max": {
"queries": [
{
"match": {
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
}
这里不知道你注意到没有,Brown fox我们重复写了N遍,即要查询的字段越多则重复写的次数也越多,想要解决这个问题,就可以使用本文要学习的multi_match了。
1:multi_match的三种方式
1.1:best_field
这种方式使用每个文档中字段的最高得分作为最终得分进行匹配,这和dis max query 是一样的效果,如下的查询:
DELETE blogs
PUT /blogs/_doc/1
{
"title": "Quick brown rabbits",
"body": "Brown rabbits are commonly seen."
}
PUT /blogs/_doc/2
{
"title": "Keeping pets healthy",
"body": "My quick brown fox eats rabbits on a regular basis"
}
POST /blogs/_search
{
"query": {
"dis_max": {
"tie_breaker": 0,
"queries": [
{
"match": {
"title": "Brown fox"
}
},
{
"match": {
"body": "Brown fox"
}
}
]
}
}
}

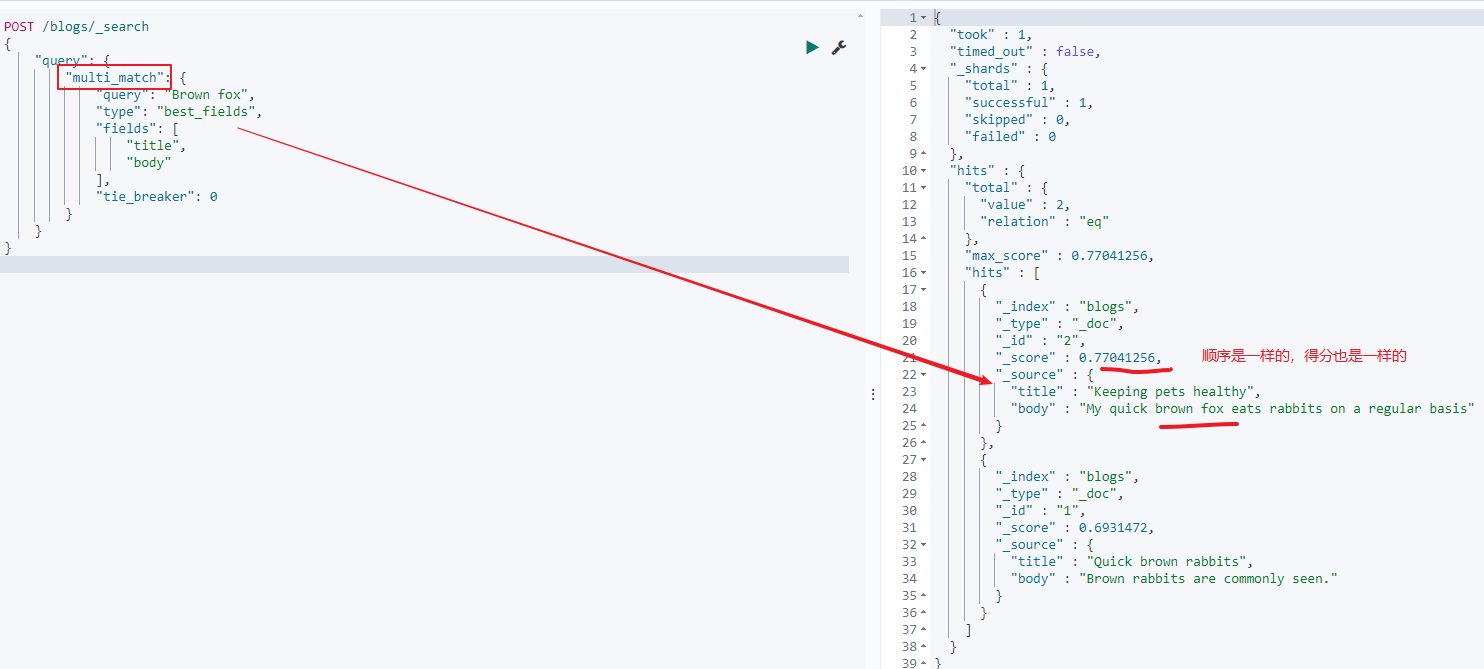
同样也可以使用multi_match的best_field来实现:
POST /blogs/_search
{
"query": {
"multi_match": {
"query": "Brown fox",
"type": "best_fields",
"fields": [
"title",
"body"
],
"tie_breaker": 0
}
}
}
1.2:most_field
这种方式是某个文档匹配的字段越多,则得分越高,如下:
POST news/_bulk
{"index": {"_id": 1}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 2}}
{"f1":"aa", "f2": "bb", "f3": "cc"}
{"index": {"_id": 3}}
{"f1":"aa", "f2": "bb", "f3": "cc", "f4": "dd"}
POST /news/_search
{
"query": {
"multi_match": {
"query": "aa bb cc dd",
"type": "most_fields",
"fields": [
"f1",
"f2",
"f3",
"f4"
]
}
}
}
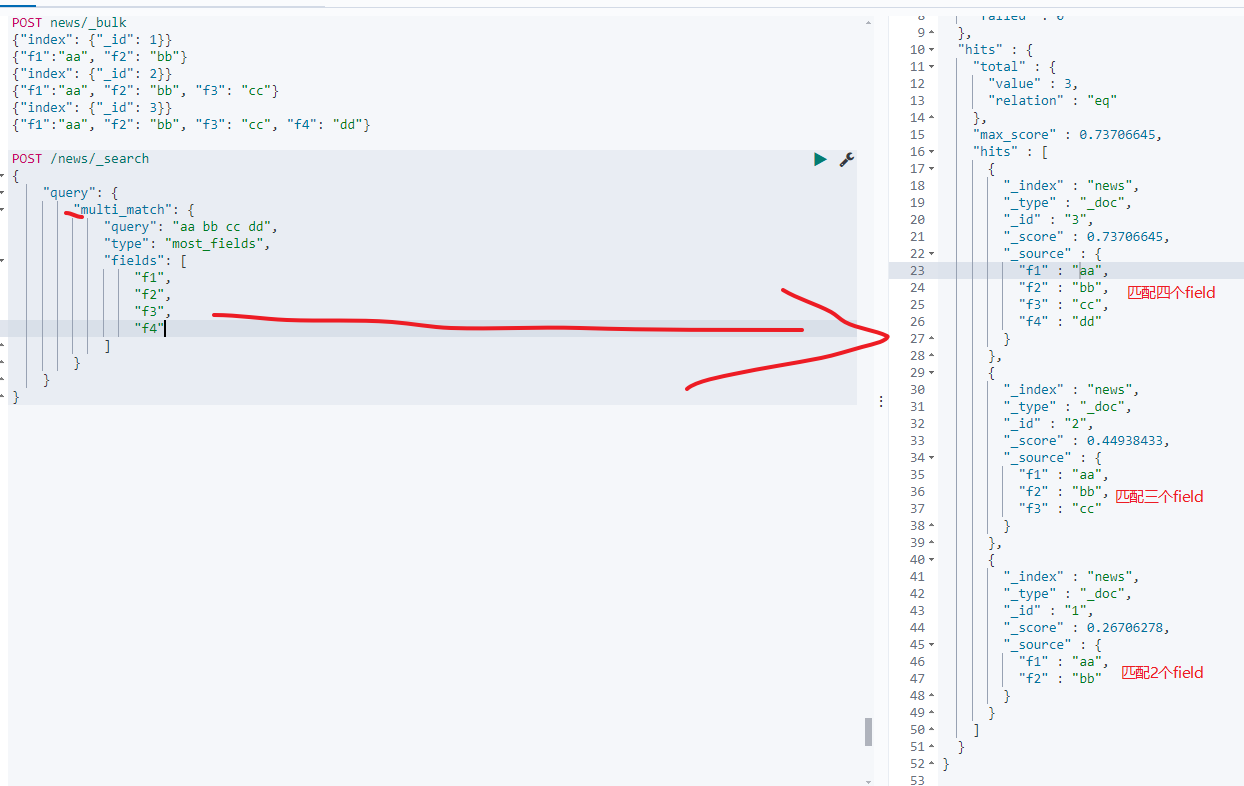
可以看到匹配的fields越多则越靠前。
其他特殊的情况分析。
- 如果没有任何匹配的field则不会匹配返回,如下:
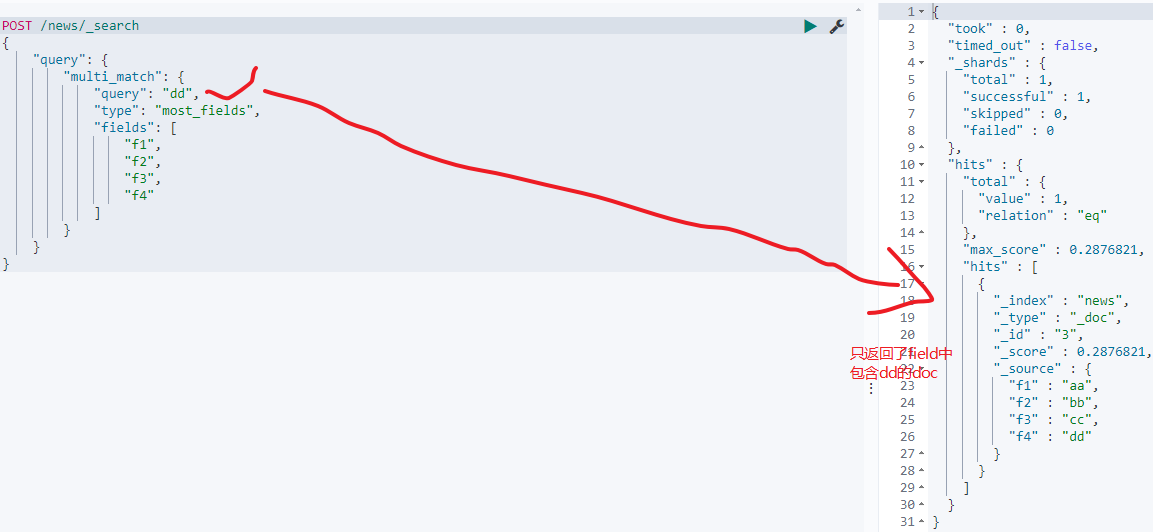
- 如果是field匹配的field数完全相同,且匹配的term数相同,则得分完全相同,如下:
DELETE news/
POST news/_bulk
{"index": {"_id": 1}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 2}}
{"f1":"aa", "f2": "bb"}
POST /news/_search
{
"query": {
"multi_match": {
"query": "aa bb",
"type": "most_fields",
"fields": [
"f1",
"f2",
"f3",
"f4"
]
}
}
}
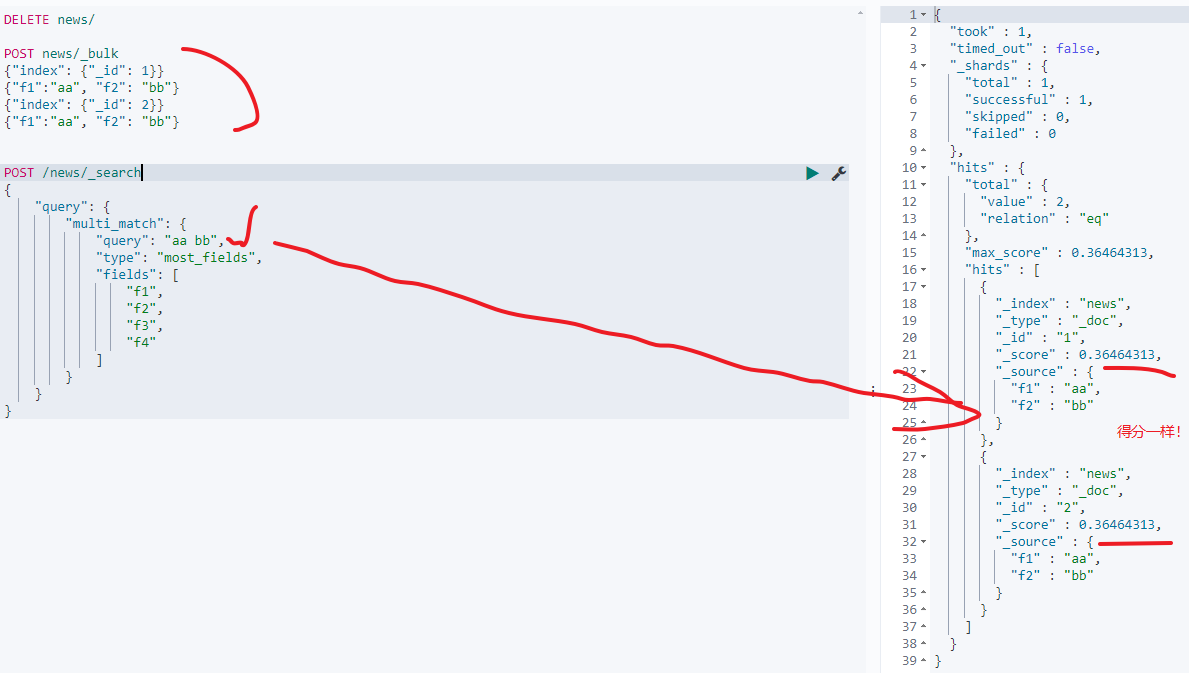
- 如果field匹配的field数完全相同,匹配的term越多,则得分越高,如下:
DELETE news/
POST news/_bulk
{"index": {"_id": 1}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 2}}
{"f1":"aa", "f2": "aa bb"}
POST /news/_search
{
"query": {
"multi_match": {
"query": "aa bb",
"type": "most_fields",
"fields": [
"f1",
"f2",
"f3",
"f4"
]
}
}
}
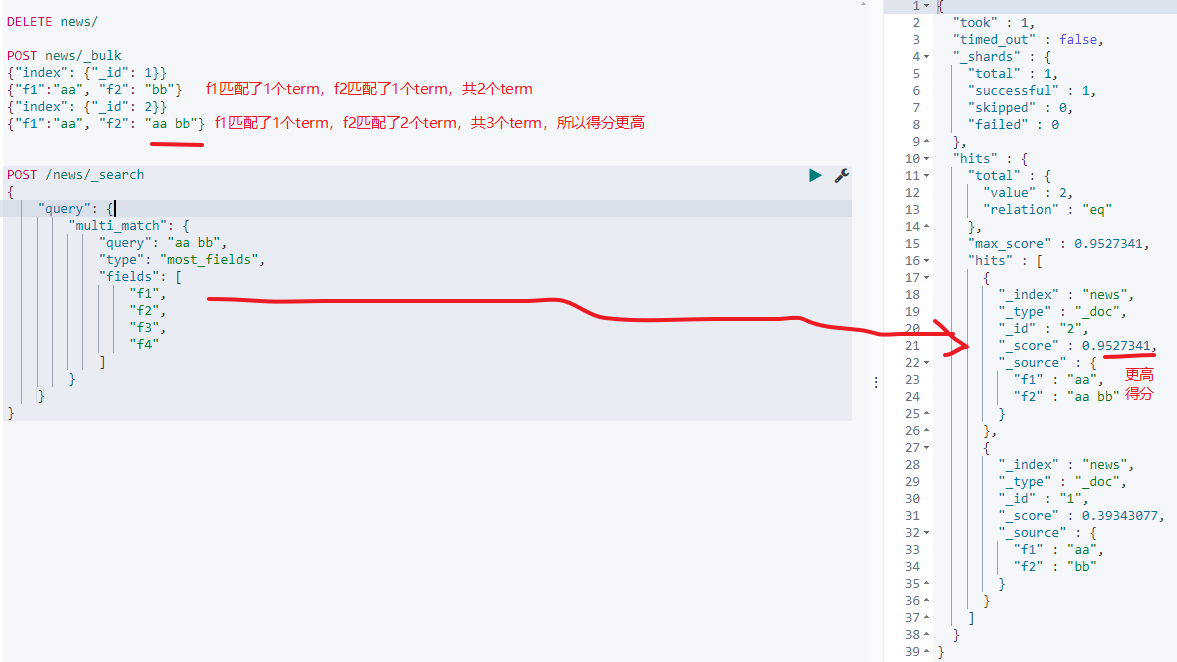
即匹配的field数优先,field数相同则按照总得分排优先级。
1.3:cross_field
这种匹配方式是将查询的字段作为一个整体来进行查询,每个要查询的词项都需要在文档中存在,才会匹配成功,如果是不使用multi_match的cross field的话我们也可以使用copy_to的方式,来将要查询的字段全部copy_to到同一个字段中,然后对该段进行普通的查询,如下:
DELETE news/
PUT news
{
"mappings": {
"properties": {
"f1": {
"type": "text",
"copy_to": "f_full"
},
"f2": {
"type": "text",
"copy_to": "f_full"
},
"f3": {
"type": "text",
"copy_to": "f_full"
}
}
}
}
POST news/_bulk
{"index": {"_id": 1}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 2}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 3}}
{"f1":"aa", "f2": "bb", "f3": "cc"}
POST /news/_search
{
"query": {
"match": {
"f_full": {
"query": "aa bb cc",
"operator": "and"
}
}
}
}

查询的是在f_full中包含aa,bb,cc的文档,但是copy_to的方式有一个缺点就是,会增加磁盘的负担,如果是使用cross_field可以等效的解决这个问题,如下:
DELETE news/
PUT news
{
"mappings": {
"properties": {
"f1": {
"type": "text",
"copy_to": "f_full"
},
"f2": {
"type": "text",
"copy_to": "f_full"
},
"f3": {
"type": "text",
"copy_to": "f_full"
}
}
}
}
POST news/_bulk
{"index": {"_id": 1}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 2}}
{"f1":"aa", "f2": "bb"}
{"index": {"_id": 3}}
{"f1":"aa", "f2": "bb", "f3": "cc"}
POST /news/_search
{
"query": {
"multi_match": {
"query": "aa bb cc",
"type": "cross_fields",
"fields": [
"f1",
"f2",
"f3"
],
"operator": "and"
}
},
"profile": "true"
}
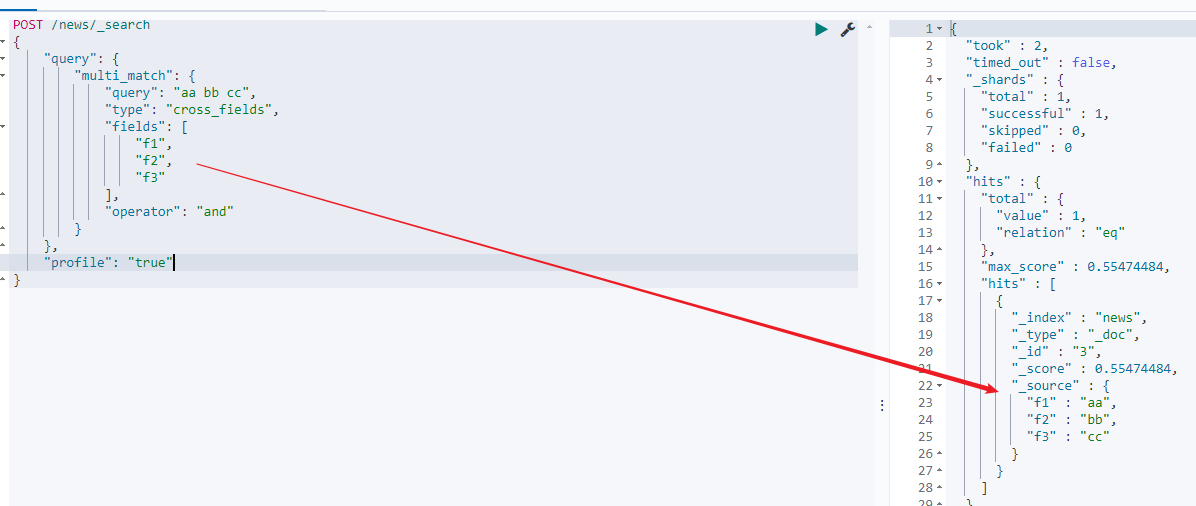
通过profile可以看到查询的方式是+(f2:aa | f3:aa | f1:aa) +(f2:bb | f3:bb | f1:bb) +(f2:cc | f3:cc | f1:cc),因为operator是and,所以同sql(f1 like '%aa%' or f2 like '%aa%' or f3 like '%aa%') and (f1 like '%bb%' or f2 like '%bb%' or f3 like '%bb%') and (f1 like '%cc%' or f2 like '%cc%' or f3 like '%cc%'),同样的如果是将operator改为or,则同sql(f1 like '%aa%' or f2 like '%aa%' or f3 like '%aa%') or (f1 like '%bb%' or f2 like '%bb%' or f3 like '%bb%') or (f1 like '%cc%' or f2 like '%cc%' or f3 like '%cc%')。
写在后面
参考文章列表
ES中的Multi_match深入解读:best_fields、most_fields、cross_fields用法一览 。