原文:大语言模型推理加速技术:模型压缩篇 - 知乎
目录
简介
量化(Quantization)
LLM.int8()
GPTQ
SmoothQuant
AWQ
精简Attention
共享Attention参数
Multi-Query Attention
Grouped-Query Attention
稀疏Attention
Sliding Window Attention
StreamingLLM
投机采样
总结
本文是《大语言模型推理加速技术》系列的第二篇
《大语言模型推理加速技术:计算加速篇》
《大语言模型推理加速技术:模型压缩篇》
《大语言模型推理加速技术:推理框架篇》
简介

本篇介绍左边蓝色的部分,右边绿色的部分在上篇文章
在上一篇文章中我们介绍了不改变模型结构的条件下,加速模型推理的技术,即让模型“算得更快”。而这篇文章将介绍模型压缩的技术,即让模型“算得更少”。模型压缩技术主要分为两大类:
- 量化(Quantization):使用低精度(≤16位)存储模型权重。
- 精简Attention:通过一些变种的Attention算法减少模型计算量。
除此之外还有“投机采样”这种巧妙的采样方法也可以视为对大模型的压缩。而传统的几个压缩方法比如知识蒸馏和剪枝仍然处于学术探索的阶段,暂时没有成熟的落地实践可以参考,因此本篇不做介绍。
由于各大公司和学术团队都在“卷”大模型,大模型新技术层出不穷,本系列只能保证当前的信息有效性(2023年11月中旬)。另外由于本文是从工程角度出发,只会介绍工业界可落地的技术,一些前沿的学术成果可能并不包含在内,敬请谅解。
量化(Quantization)
量化(Quantization)是指使用精度更低的单位来表示模型的权重或中间层变量,以节省空间和加速模型推理速度。如果想系统性地了解模型量化的知识,强烈推荐MIT韩松教授的Efficient ML课程,课程里系统介绍了各种模型压缩技术。本文介绍的SmoothQuant和AWQ也是来自韩松教授的组。
从时机分类,量化分为:
- 训练时量化(Quantization-Aware Training, QAT),需要模型重新训练,
- 训练后量化(Post Training Quantization,PTQ),可以量化预训练好的模型。不需要重新训练。
由于大模型重新训练成本太高,大家一般使用的都是PTQ。一个例外是QLora,它是在Lora微调阶段进行量化,本篇暂不介绍,后面会出一篇文章详细Lora和相关的技术。
从量化后的数据类型分类,可以分为:
- 浮点数量化(Float Quantization):直接用低精度的浮点数单位表示原来的浮点数值,技术简单,目前大家已经默认使用FP16了,因为一般模型权重都是比较小的数值,并不需要FP32的范围和精度,而FP8则是最近一个比较热门的话题。由于浮点数量化比较简单,本文不做过多介绍。
- 整数量化(Integer Quantization):整数量化是将原来的浮点数值放缩后使用整数近似表示。是把矩阵的浮点数范围映射到整数的范围:
����=�����(��),�=���(|�|)2�−1
其中W是原始float矩阵,W_int是量化后的int矩阵,S是放缩的scale,计算方法是W的最大值除以整数INT-N能表示的最大值。这里假设了矩阵是以0对称的,非对称的量化还需要再加一个Bias。
在推理时,我们先用W_int进行推理,然后再根据S放缩回float结果。这种简单直接的量化方法我们叫做Round To Nearest (RTN),推理精度下降比较明显,目前和FP16一样都是被用来做Baseline,只不过FP16是上限Baseline,RTN是下限Baseline。
从量化的范围上,可以分为:
- 只量化权重(Weight Only):只量化模型权重,推理时是INT乘FLOAT
- 权重与激活同时量化(Weight and Activation):这里的激活实际是就是每一层的输入,对于矩阵乘法Y = WX,同时量化W和X,推理时是INT乘INT
目前Weight and Activation可以做到INT8(或者叫W8A8,Weight 8bit Activition 8bit)与FP16水平相当,而Weight Only方向INT4(W4A16)已经可以做到与FP16相差无几,INT3(W3A16)也很接近了。实际上,这两个方向并不是互斥的,我们完全可以同时应用两种方式,只是工程比较复杂,暂时还没有成熟的框架。
从量化粒度分类,可以分为:
- Tensor粒度(per-tensor):整个矩阵一起量化。
- Token粒度(per-token)和Channel粒度(per-channel):每行/每列单独量化,X的每一行代表一个Token,W的每一列代表一个Channel。
- Group粒度(per-group):两者的折衷,多行/多列分为一组,每组分别量化。

量化粒度,来自SmoothQuant的paper
本文所介绍的技术都是PTQ和整数量化,量化范围和粒度则各有不同。
LLM.int8()
首先我们要明确一点:LLM.int8()并不会加速模型推理,反而会使推理变慢,它更多的是为了节省空间。但是LLM.int8()激发了后续的很多研究(实际上本文讲的量化技术除了GPTQ都受到了它的启发),所以我们简单介绍一下。一句话总结作者的核心思想就是:有些特征很重要,我们用FP16单独计算,剩下的量化成INT8计算。
从名字里就能看出,LLM.int8()是使用INT8存储模型,但是单纯地使用RTN算法效果非常差,作者观察到:
- 在<3B的小模型上,RTN算法效果还可以,但是到>6B的大模型上,RTN忽然变得很差。
- 模型的Activation,即模型的中间层结果,也就是token的embedding,而embedding的每一维可以代表模型提取出的一个特征。
- 在大模型里,activation的某些维度的值变得很大,显著超过其他维,是离群特征(outlier feature)。
- 作者认为这些离群特征很重要,是大模型涌现(emergence)能力的体现。

大模型上忽然出现的离群特征导致量化效果变差,来自LLM.int8() paper
基于这个观察,作者提出我们可以把X里离群特征和W里对应的权重行提取出来,仍然使用FP16计算,只对剩下的普通特征进行W8A8量化:

LLM.int8()计算过程,来自LLM.int8() paper
通过离群特征单独计算的方式,LLM.int8()实现了和FP16相同的推理准确率。其对于离群特征的观察也是后续几个量化技术(SmoothQuant、AWQ、SqQR)的关键假设。
GPTQ
一句话总结GPTQ的核心思想:每量化一列参数就在其他所有列加一个“补偿”,以减少整体的精度误差。这个思想不是GPTQ独创的,而是从90年代初LeCun的OBD算法(Optimal Brain Damage)(最优脑损伤?),到OBS(Optimal Brain Surgeon)(最优脑外科医生?)到2022年的OBC(Optimal Brain Compression)(最优脑压缩,总算正常了一点)一路流传下来的模型压缩方法。
这些方法是通过完备的数学推导得来的:定义一个函数表示参数W的变化对Loss的影响, 将压缩问题转化为“在已知要把W_ij变为Quant(W_ij)的前提下,如何变化W_i的其他值使Loss的变化最小”这样一个条件约束的优化问题,经过泰勒展开和拉格朗日乘子,可以得到一个最优的公式。GPTQ的paper里也只是一笔带过它的数学推导(仅有的几个公式里,有一个公式还打错了……),详细的数学推导过程可以参考这篇知乎文章:GPTQ 模型量化 - 知乎。
OBQ的流程大致如下:对W的每一行分别量化,在量化第q行w_q时
- 根据以下公式找出对Loss影响最小的列,然后更新w_q,
��=argmin��(quant(��)−��)2[�−1]��
其中H是Loss对于W的Hessian矩阵。
- 对w_q剩下的参数进行更新以补偿量化误差
��=−��−quant(��)[�−1]��⋅[�−1]:,�
- 通过如下公式,在H^{-1}中剔除
�−1=(�−1−1[�−1]���:,�−1��,:−1)
重复三个步骤直到全部矩阵都被量化。由于第三步更新H涉及到矩阵乘法,是一个O(col^2)的复杂度,而我们量化每个值之后都需要更新一次H,共有row*col个值,因此整个操作的复杂度是O(row * col^3),对于大模型来说很难实现。
而GPTQ的作者们对OBQ算法实现了3个优化:
- 固定顺序:在OBQ中,每个行单独计算,因为每行里各元素的量化顺序不一样。但是GPTQ认为,量化的顺序并不重要,因为量化顺序越靠后,可供补偿的剩余元素就越少,即使把影响最大的元素放到最后量化,也没有剩下的元素来补偿它的误差了。因此我们完全可以对每一行都使用相同的顺序去量化,即整列一起量化。这样就把复杂度降到了O(col^3),降了一个维度。
- 懒惰批量更新:在更新H时,我们更新一个大的矩阵的每个元素,需要很多内存却不怎么需要算力,因此我们的计算速度被内存带宽限制住了。因此我们可以使用类似于缓存的策略,把矩阵分块缓存,在更新一列后只存在缓存中,整个block更新完再写回内存并更新整个H。
- Cholesky分解:OBQ方法受浮点数运算精度影响较大,我们观察到其实只需要H矩阵上三角形的信息,因此可以对H做Cholesky分解,既保留了精度又可以使用高效的分解Kernel。

GPTQ的三个优化,来自GPTQ的paper
经过这些优化后,GPTQ可以用一张A100在4小时内量化一个175B的模型,而原来的OBQ只能在1小时内量化一个50M的模型。在INT4精度下,GPTQ可以与FP16效果相当,而INT3下也只低了5%~10%。推理速度方面,GPTQ可以比FP16快3~5倍。
SmoothQuant
如果只量化Weight不量化Activation,在矩阵计算时我们就需要使用FP16INT8的矩阵乘法Kernel,这种Kernel的效率肯定是比两者同时量化后,使用INT8INT8 Kernel效率低的。但是Activation拥有大量的Outlier Feature(LLM.int8()的观察),而范围越大量化误差越大,所以有效地量化Activation一直是一个难题。
SmoothQuant作者提出:既然Activation难量化,Weight很容易量化,我们可不可以把两者平均一下,让他们都容易量化呢?即对于outlier features,我们在把Activation缩小a倍,Weight放大n倍,这样最终结果不变,但是Activation变得光滑(Smooth)了许多,量化误差大大减少了。

SmoothQuant原理,来自SmoothQuant paper
而且这样做不会影响模型的推理效率,因为:
- Weight的放大可以在离线阶段完成。
- 本层Activation的缩小可以被融合至上一层的计算中,不增加额外的Kernel调用。
作者的Benchmark显示,SmoothQuant后推理的Latency可以降低20%-40%,而且得益于需要的内存变少了,批量推理的Throughput可以提升数倍。
AWQ
AWQ和SmoothQuant师出同门(Ji Lin同时是两篇的共同一作),AWQ的思想和SmoothQuant一样,都是将W放大A缩小,但是SmoothQuant是per-tensor粒度的,整个矩阵共享放缩的scale。而AWQ是per-token/per-channel的,AWQ分析发现每个channel的scale只和对应activation的大小s_x有关,因此作者定义s = s_x^a,通过grid search来找到最优的a。
因为awq的量化只依赖校准集里activation的大小,于activation实际分布无关(与gptq不同),因此量化的质量要比gptq更好,但是同时作者指出,awq和gptq并不是矛盾的量化方法,我们完全可以同时使用awq和gptq。
精简Attention
除了降低计算精度外,我们也可以通过改变模型结构,精简一些Attention计算来减少模型的运算量,我把它们共享Attention和稀疏Attention两种:
- 共享Attention:在每一层的Attention计算我们都是用多个注意力头来计算,即Multi Head Attention,MHA。我们可以让这些注意力头共享一些参数来减少运算量。
- 稀疏Attention:我们提到过,Attention机制是一个O(N^2)的计算,即当前token要与前面所有token都计算注意力。然而可能并不是所有token都一样重要,所以我们可以跳过某些不重要的token,以减少计算量。
共享Attention参数

MHA, MQA和GQA,来自GQA的paper
和vLLM的观察类似,大模型的throughput被内存带宽限制住了,而内存中很大部分都是KVCache,我们可以通过在一层的多头Attention之间共享KV参数来减少KVCache的占用,提升throughput。
Multi-Query Attention
MQA是使所有头全部共享一组KV参数,对所有头的KV取平均后作为最终的参数。MQA可以讲推理thoughput提升数倍,但是推理质量下降比较明显。
Grouped-Query Attention
GQA是MHA和MQA两者的这种,将多头分为G个分组,每组之间共享KV参数,这样既可以实现MQA级别的推理速度,又可以维持MHA级别的推理质量。现在新模型基本都使用GQA架构了。
稀疏Attention
稀疏Attention就是不对前面的全部token做attention计算,只取其中一部分,使模型的计算量变少。
Sliding Window Attention
一个最直观的想法就是:离当前token越近的token越重要,因此我们可以只计算最近的L个token,把Attention的复杂度变为O(N),因为L为常数。这个方法由LongFormer团队提出。

LongFormer示例,来自LongFormer paper
除了图中(b)的普通Sliding window外,Long Former还发现我们可以再固定选择一些全局Token代表当前的任务(图中的(d)),比如BERT模型使用[CLS]这个特殊Token代表当前是分类任务,我们可以把这类全局Token加进来,复杂度仍为O(N)。
StreamingLLM
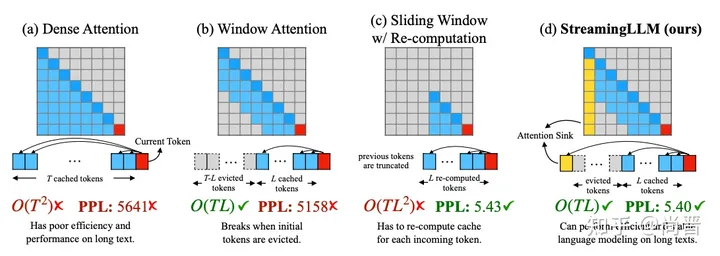
StreamLLM paper中介绍的几种稀疏Attention
StreamingLLM又是韩松教授的团队的作品,StreamingLLM团队发现,SlidingWindow(图中的b)一旦超出了max_len长度,向前滑动了一步,即第一个token被移除KVCache后,模型推理的质量就大幅下降。即使是原始的Dense Attention(图中的a),一旦Sequence长度超过模型训练的长度,推理质量也大幅下降。
而一种有效的在长序列中维持推理质量的方法是滑窗+重计算,即把最近的L的token作为全新的prompt送给模型推理(图中的c)。它和普通滑窗的区别是最近的几个token被视为初始token,没有前文的影响。但是这个方法需要O(TL^2)的计算,仍然是平方精度。
作者认为方法c效果好的原因是模型很“需要”一些初始token:
- 从数学角度看,SoftMax函数输出的概率总和一定为1,因此在序列较短时,初始token一定会被分配很高的概率。
- 从直觉角度,前面的token的“曝光度”比靠后的token要大,所以一定是最初的token更重要。
于是作者尝试在滑窗机制的基础上,永远保留前四个token,这样即保持了线性的复杂度,又维持了模型的推理质量。
而且根据作者的观察,前四个token是什么并不很重要,我们可以把前四个token随便换成随机的token,模型的推理质量也只下降一点点,因此证实了作者的观点:并不是前几个token的信息重要,只是模型很需要有前面的token的存在而已。
投机采样
虽然投机采样Speculative Sampling并不会改变模型结构,但我认为它仍然算是一个模型压缩方法。我们在上一篇文章说过,Attention优化的难点就是它是一个复杂度为O(N^2)且无法并发的计算。前面的稀疏Attention就是降低Attention的复杂度,而投机采样就是让Decoding阶段可以并发。
投机采样的思想是,不是每个token的生成都很难,前面的几个token生成比较容易,可以让小模型代劳,小模型先生成一部分token后再由大模型验证。
投机采样的流程大致如下,假设我们有一个和大模型近似的小模型:
- 小模型对prompt进行推理n次,生成n个token,记录所有的logits。
- 将prompt和生成的n个token组成新的prompt,一起送进大模型推理一次,得到推理结果的logits。
- 将大模型和小模型的logits做对比,如果发现所有推理结果一致,则保留这些token,重复1。
- 如果发现第k个token不一致,则保留第1…k-1个token,大模型重新推理第k个token,重复1。
这个算法乍看起来是一个近似算法,但是它巧妙的是它是数学完备的,我们可以保证最终输出的结果和直接使用大模型推理的结果严格一致。
本质上投机采样是利用了大模型推理n个token需要推理n次,而验证结果只需要推理1次。这有点像是算法竞赛中常用的二分法:有些问题直接贪心算法解需要O(N),而验证一个结果只需要O(1),这样我们就可以用二分法把它的复杂度降为O(logN)。
总结
本文总结大模型推理加速技术中的模型压缩技术(韩松教授yyds,再次强烈推荐他的EfficientML课程),与上一篇文章共同完成了对当前主流大模型推理加速技术的介绍。总结来看,这些优化技术可谓是五花八门,百家齐鸣,有的是基于扎实的工程技术,比如Kernel优化,有的是基于对大模型的独特见解,比如LLM.int8()中的Outlier Features和StreamingLLM的初始token重要性,有的是基于其他领域的成熟经验,比如vLLM借用操作系统的paged memory,LongFormer的滑动窗口算法等,还有的基于严格的数学推导,比如GPTQ和投机采样。
结尾升华一下:不得不感叹层出不穷的新技术意味着全世界都在“卷”大模型,也感慨只有在计算机这样一个开放,开源的领域(OpenAI除外),我们这些非科研工作者才能时刻追赶上最前沿的技术。相信未来几年大语言模型领域还会出现很多革命性的技术,让开源模型也能追上OpenAI的脚步。
升华完回归正题:“纸上谈兵”地介绍完这些技术后,我们下一步将转向应用,我将在下一篇文章中评测几个主流的推理框架,介绍它们所应用的技术和推理加速的效果。但是这个不会很快发出来,一个是因为这个需要耗的时间比较久,还有个是因为我还有一篇C++和一篇Apache Arrow的文章拖了很久没发,推理框架要等这两篇发完之后再发,敬请期待~
编辑于 2023-11-17 22:13・IP 属地上海