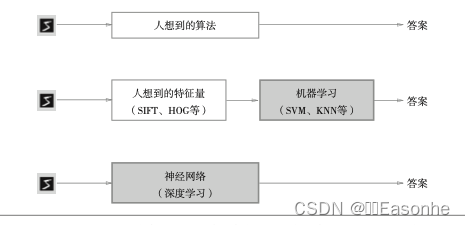
神经网络的学习(神经网络的学习阶段,不是我们学习神经网络)
从数据中学习
训练数据和测试数据
机器学习中,一般将数据分为训练数据和测试数据两部分来进行学习和 实验等。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试 数据评价训练得到的模型的实际能力。为了正确评价模型的泛化能力(指处理未被观察过的数据),就必须划分训练数据和测试数据。另外,训练数据也可以称为监督数据。只对某个数据集过度拟合的状态称为过拟合(over fitting)。避免过拟合也是机器学习的一个重要课题。
损失函数
神经网络的学习中所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数, 但一般用均方误差和交叉熵误差等。
均方误差
yk 是表示神经网络的输出,tk 表示监督数据,k 表示数据的维数,计算神经网络的输出和正确解监督数据的 各个元素之差的平方,再求总和
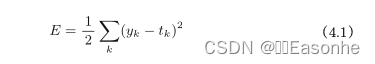
python实现:
def mean_squared_error(y, t):
return 0.5 * np.sum((y-t)**2)
交叉熵误差
log 表示以 e 为底数的自然对数(log e)。yk 是神经网络的输出,tk 是正确解标签

def cross_entropy_error(y, t):
delta = 1e-7
return -np.sum(t * np.log(y + delta)) # delta是微小值 当出现 np.log(0) 时,np.log(0) 会变为负无限大,这样一来就会导致后续计算无法进行。作为保护性对策,添加一个微小值可以防止负无限大的发生
mini-batch 学习
求所有训练数据的损失函数的总和,以交叉熵误差为例,可以写成
如果遇到大数据, 数据量会有几百万、几千万之多,这种情况下以全部数据为对象计算损失函数是不现实的。因此,我们从全部数据中选出一部分,作为全部数据的“近似”。神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小 批量),这种学习方式称为 mini-batch 学习。
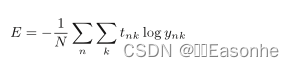
为何要设定损失函数
在进行神经网络的学习时,不能将识别精度作为指标。因为如果以 识别精度为指标,则参数的导数在绝大多数地方都会变为 0。假设某个神经网络正确识别出了 100 笔训练数据中的 32 笔,此时识别精度为 32 %。即便识别精 度有所改善,它的值也不会像 32.0123 . . . % 这样连续变化,而是变为 33 %、 34 % 这样的不连续的、离散的值。而如果把损失函数作为指标,则当前损 失函数的值可以表示为 0.92543 . . . 这样的值。并且,如果稍微改变一下参数 的值,对应的损失函数也会像 0.93432 . . . 这样发生连续性的变化。如果使用阶跃函数作为激活函数,神经网络的学习将无法进行。 如图4-4所示,阶跃函数的导数在绝大多数地方(除了0以外的地方)均为0。 也就是说,如果使用了阶跃函数,那么即便将损失函数作为指标,参数的微小变化也会被阶跃函数抹杀,导致损失函数的值不会产生任何变化。
数值微分
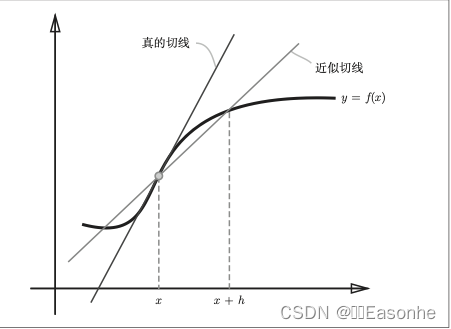
导数
基础不太清楚的可以自行学习下,这里就不写了
python的实现:
def numerical_diff(f, x):
h = 1e-4 # 0.0001
# 导数的形式是return (f(x+h) - f(x)) / h,这里的h不会无限接近0,所以数值微分含有误差。为了减小这个误差,我们可以计算 函数f在(x + h)和(x − h)之间的差分。因为这种计算方法以x为中心,计算它左右两边的差分,所以也称为中心差分(而 ( x + h ) 和 x 之间的差分称为前向差分
return (f(x+h) - f(x-h)) / (2*h)
偏导数
# 求x0 = 3, x1 = 4时,关于x0 的偏导数,此时把不求导数的变量的值先在函数定义的时候带进去,保持只有一个变量。
>>> def function_tmp1(x0):
... return x0*x0 + 4.0**2.0
>>> numerical_diff(function_tmp1, 3.0) 6.00000000000378
梯度
由全部变量的偏导数汇总 而成的向量称为梯度(gradient)
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x) # 生成和x形状相同的数组
for idx in range(x.size):
tmp_val = x[idx]
# f(x+h)的计算
x[idx] = tmp_val + h
fxh1 = f(x)
# f(x-h)的计算
x[idx] = tmp_val - h
fxh2 = f(x)
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
return grad
梯度法
在梯度法中,函数的取值从当前位置沿着梯 度方向前进一定距离,然后在新的地方重新求梯度,再沿着新梯度方向前进, 如此反复,不断地沿梯度方向前进。像这样,通过不断地沿梯度方向前进, 逐渐减小函数值的过程就是梯度法

η 表示更新量,在神经网络的学习中,称为学习率,学习率需要事先确定为某个值,比如 0.01 或 0.001。一般而言,这个值 过大或过小,都无法抵达一个“好的位置”。在神经网络的学习中,一般会 一边改变学习率的值,一边确认学习是否正确进行了。
python实现(使用这个函数可以求函数的极小值,顺利的话,还可以求函数的最小值。):
# 参数 f 是要进行最优化的函数,init_x 是初始值,lr 是学习率 learning rate,step_num 是梯度法的重复次数
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x
神经网络的梯度
损失函数关于权重参数的梯度,用数学式表示:
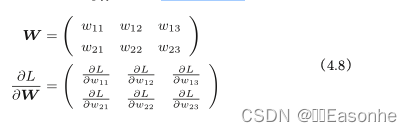
简单的神经网络梯度法的实现:
import sys, os
sys.path.append(os.pardir)
import numpy as np
from common.functions import softmax, cross_entropy_error
from common.gradient import numerical_gradient
class simpleNet:
def __init__(self):
self.W = np.random.randn(2,3) # 用高斯分布进行初始化 def predict(self, x):
return np.dot(x, self.W)
def loss(self, x, t):
z = self.predict(x)
y = softmax(z)
loss = cross_entropy_error(y, t)
return loss
例子:
>>> net = simpleNet()
>>> print(net.W) # 权重参数
[[ 0.47355232 0.9977393 0.84668094],
[ 0.85557411 0.03563661 0.69422093]])
>>> x = np.array([0.6, 0.9])
>>> p = net.predict(x)
>>> print(p)
[ 1.05414809 0.63071653 1.1328074]
>>> np.argmax(p) # 最大值的索引
2
>>> t = np.array([0, 0, 1]) # 正确解标签
>>> net.loss(x, t)
0.92806853663411326
# 求梯度(f(W) 的参数 W 是一个伪参数。因为 numerical_gradient(f, x) 会在内部执行 f(x), 为了与之兼容而定义了 f(W)))
>>> def f(W):
... return net.loss(x, t)
...
>>> dW = numerical_gradient(f, net.W)
>>> print(dW)
[[ 0.21924763 0.14356247 -0.36281009] # 结果表示如果将 w11 增加 h,那么损失函数的值会增加 0.2h(近似);果将 w23 增加 h,损失函数的值将减小 0.5h,故w23 应向正方向更新,w11 应向负方向更新
[ 0.32887144 0.2153437 -0.54421514]]。
学习算法的实现
神经网络的学习步骤
- 前提
神经网络存在合适的权重和偏置,调整权重和偏置以便拟合训练数据的 过程称为“学习”。神经网络的学习分成下面 4 个步骤。
- 步骤 1(mini-batch)
从训练数据中随机选出一部分数据,这部分数据称为 mini-batch。我们 的目标是减小 mini-batch 的损失函数的值。
- 步骤 2(计算梯度)
为了减小 mini-batch 的损失函数的值,需要求出各个权重参数的梯度。 梯度表示损失函数的值减小最多的方向。
- 步骤 3(更新参数)
将权重参数沿梯度方向进行微小更新。
- 步骤 4(重复)
重复步骤 1、步骤 2、步骤 3。
2层神经网络的类
以前面说的数字分类为例的神经网络类:
import sys, os
sys.path.append(os.pardir)
from common.functions import *
from common.gradient import numerical_gradient
class TwoLayerNet:
# 参数(输入层的神经元数、隐藏层的神经元数、输出层的神经元数)(中间三个,边上的两个不算)
# 因为进行手写数字识别时,输入图像的大小是 784(28 × 28),输出为 10 个类别, 所以指定参数 input_size=784、output_size=10
def __init__(self, input_size, hidden_size, output_size, weight_init_std=0.01):
# 初始化权重
# 保存神经网络的参数的字典型变量(实例变量)。
self.params = {}
# 第 1 层的权重(后面类推)
self.params['W1'] = weight_init_std * \ np.random.randn(input_size, hidden_size)
# 第 1 层的偏置(后面类推)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = weight_init_std * \ np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
# 进行识别(推理)
def predict(self, x):
W1, W2 = self.params['W1'], self.params['W2']
b1, b2 = self.params['b1'], self.params['b2']
a1 = np.dot(x, W1) + b1 z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2 y = softmax(a2)
return y
# x:输入数据, t:监督数据
# 计算损失函数的值
def loss(self, x, t):
y = self.predict(x)
return cross_entropy_error(y, t)
# 计算识别精度
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0])
return accuracy
# x:输入数据, t:监督数据
# 计算权重参数的梯度
def numerical_gradient(self, x, t):
loss_W = lambda W: self.loss(x, t)
# 保存梯度的字典型变量(numerical_gradient() 方法的返回值)
grads = {}
# 第 1 层权重的梯度(后面类推)
grads['W1'] = numerical_gradient(loss_W, self.params['W1'])
# 第 1 层偏置的梯度(后面类推)
grads['b1'] = numerical_gradient(loss_W, self.params['b1'])
grads['W2'] = numerical_gradient(loss_W, self.params['W2'])
grads['b2'] = numerical_gradient(loss_W, self.params['b2'])
return grads
使用:
# 因为进行手写数字识别时,输入图像的大小是 784(28 × 28),输出为 10 个类别,将隐藏层的个数 设置为一个合适的值即可。
net = TwoLayerNet(input_size=784, hidden_size=100, output_size=10) net.params['W1'].shape # (784, 100)
net.params['b1'].shape # (100,)
net.params['W2'].shape # (100, 10)
net.params['b2'].shape # (10,)
# 推理处理
x = np.random.rand(100, 784) # 伪输入数据(100笔)
y = net.predict(x)
# 计算梯度
x = np.random.rand(100, 784) # 伪输入数据(100笔)
t = np.random.rand(100, 10) # 伪正确解标签(100笔)
grads = net.numerical_gradient(x, t) # 计算梯度
grads['W1'].shape # (784, 100)
grads['b1'].shape # (100,)
grads['W2'].shape # (100, 10)
grads['b2'].shape # (10,)
mini-batch 的实现
import numpy as np
from dataset.mnist import load_mnist from two_layer_net import TwoLayerNet
(x_train, t_train), (x_test, t_test) = \ load_mnist(normalize=True, one_hot_ laobel = True)
train_loss_list = []
# 每个mini-batch是一个epoch
train_acc_list = []
test_acc_list = []
# 平均每个epoch的重复次数
iter_per_epoch = max(train_size / batch_size, 1)
# 超参数(人工设置的)梯度法的更新次数(循环的次数)
iters_num = 10000
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
for i in range(iters_num): # 获取mini-batch
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.numerical_gradient(x_batch, t_batch)
# grad = network.gradient(x_batch, t_batch) # 高速版!
# 更新参数
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
# 记录学习过程(每更新一次,都对训练数据计算损 失函数的值,并把该值添加到数组中)
loss = network.loss(x_batch, t_batch)
train_loss_list.append(loss)
# 计算每个epoch的识别精度
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
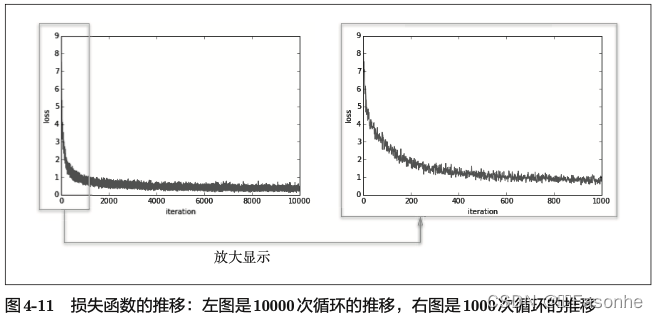
学习过程:
小结
• 机器学习中使用的数据集分为训练数据和测试数据。
• 神经网络用训练数据进行学习,并用测试数据评价学习到的模型的泛化能力。
• 神经网络的学习以损失函数为指标,更新权重参数,以使损失函数的值减小。
• 利用某个给定的微小值的差分求导数的过程,称为数值微分。
• 利用数值微分,可以计算权重参数的梯度。
• 数值微分虽然费时间,但是实现起来很简单。下一章中要实现的稍微复杂一些的误差反向传播法可以高速地计算梯度。